superset
Jun 27, 2022
利用商业性可视化工具有如:Tableau、DataV、FineReport、FineBI等可以简捷灵活地进行数据可视化工作,但是需要收费购买;利用前端可视化组件如:ECharts、D3、Three.js等也可以做出丰富的图表页面,但是要求一定的技术基础。开源可视化分析工具如:Bokeh、Matplotlib、Metabase、Superset等首先是无软件成本的,其次是要考虑它们的便捷性。
利用商业性可视化工具有如:Tableau、DataV、FineReport、FineBI等可以简捷灵活地进行数据可视化工作,但是需要收费购买;利用前端可视化组件如:ECharts、D3、Three.js等也可以做出丰富的图表页面,但是要求一定的技术基础。开源可视化分析工具如:Bokeh、Matplotlib、Metabase、Superset等首先是无软件成本的,其次是要考虑它们的便捷性。
MySQL 默认开启事务自动提交模式,即除非显式的开启事务(BEGIN 或 START TRANSACTION),否则每条 SOL 语句都会被当做一个单独的事务自动执行。但有些情况下,我们需要关闭事务自动提交来保证数据的一致性。下面主要介绍如何设置事务自动提交模式。
S锁:共享锁 加了S锁的记录,允许其他事务再加S锁,不允许其他事务再加X锁 select…lock in share mode X锁:排他锁 加了X锁的记录,不允许其他事务再加S锁或者X锁 select…for update
什么是MaxCompute 大数据计算服务(MaxCompute,原名ODPS open data processing service)是一种快速、完全托管的GB/TB/PB级数据仓库解决方案。MaxCompute为您提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决海量数据计算问题,有效降低企业成本,并保障数据安全。
kafka-console-consumer.sh 脚本是一个简易的消费者控制台。该 shell 脚本的功能通过调用 kafka.tools 包下的 ConsoleConsumer 类,并将提供的命令行参数全部传给该类实现。
VALUE与VALUES都是正确的,经过验证,这两个也是可以混合着用的,只是两者对不同语句插入数量的执行效率各不相同。 可以看出在插入单行时,使用VALUES比较快 插入多行时,用VALUE比较快 https://blog.csdn.net/qq_26683009/article/details/52526834
https://github.com/mongodb/mongo https://github.com/mongodb/mongo-go-driver go get go.mongodb.org/mongo-driver/mongo
Kafka中的每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序号,用于partition唯一标识一条消息。
日志 如果一个topic的名称为”my_topic”,它有2个partitions,那么日志将会保存在my_topic_0和my_topic_1两个目录中;日志文件中保存了一序列”log entries”(日志条目),每个log entry格式为”4个字节的数字N表示消息的长度” + “N个字节的消息内容”;每个日志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置..每个partition在物理存储层面,有多个log file组成(称为segment).segment file的命名为”最小offset”.kafka.例如”00000000000.kafka”;其中”最小offset”表示此segment中起始消息的offset.
1.2.1、邻接表 业界最常使用的方案恐怕就是“邻接表”了,简而言之,“邻接表”的每条数据都存储了“上级数据ID”。 我们使用的Redis数据结构是 Hash,Redis的key为企业ID(depttree:企业ID),field 为 部门ID,field 对应的value是 该部门ID对应的上级部门ID。
对象存储oss和aws的sdk 协议不一样, oss协议Region直接拼写在url上 aws是单独的 Region表示OSS的数据中心所在的地域,Endpoint表示OSS对外服务的访问域名。本文主要介绍Region与Endpoint的对应关系。
作者:繁星亮与鲍包包 链接:https://www.zhihu.com/question/21536660/answer/33279921 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://blog.csdn.net/yvhqbat/article/details/115717052 网关启动 MinIO内部已经实现了GCS、S3、NAS等几个网关,支持的网关列表如下:
go-redis模块自带连接池,所有参数都是可选的 poolsize 连接池的大小 https://blog.csdn.net/pengpengzhou/article/details/105385666 redis 命中率是80%
很多使用Elasticsearch的同学会关心数据存储在ES中的存储容量,会有这样的疑问:xxTB的数据入到ES会使用多少存储空间。这个问题其实很难直接回答的,只有数据写入ES后,才能观察到实际的存储空间。比如同样是1TB的数据,写入ES的存储空间可能差距会非常大,可能小到只有300~400GB,也可能多到6-7TB,为什么会造成这么大的差距呢?究其原因,我们来探究下Elasticsearch中的数据是如何存储。文章中我以Elasticsearch 2.3版本为示例,对应的lucene版本是5.5,Elasticsearch现在已经来到了6.5版本,数字类型、列存等存储结构有些变化,但基本的概念变化不多,文章中的内容依然适用。
MySql 更新死锁问题 Deadlock found when trying to get lock; try restarting transaction#
查询时的权重提升 是可以用来影响相关度的主要工具,任意类型的查询都能接受 boost 参数。将 boost 设置为 2 ,并不代表最终的评分 _score 是原值的两倍;实际的权重值会经过归一化和一些其他内部优化过程。尽管如此,它确实想要表明一个提升值为 2 的句子的重要性是提升值为 1 语句的两倍。
https://www.elastic.co/cn/blog/practical-bm25-part-1-how-shards-affect-relevance-scoring-in-elasticsearch
explain为mysql提供语句的执行计划信息。可以应用在select、delete、insert、update和place语句上。explain的执行计划,只是作为语句执行过程的一个参考,实际执行的过程不一定和计划完全一致,但是执行计划中透露出的讯息却可以帮助选择更好的索引和写出更优化的查询语句。
https://dev.mysql.com/doc/dev/mysql-server/latest/ https://mariadb.org/wp-content/uploads/2018/02/Deep-Dive_-InnoDB-Transactions-and-Write-Paths.pdf https://publications.sba-research.org/publications/WSDF2012_InnoDB.pdf https://mariadb.com/kb/en/query-optimizations/ https://jorgenloland.blogspot.com/ https://blog.csdn.net/mysql_lover/ http://mysqlserverteam.com/ http://mysql.taobao.org/monthly/ https://blog.csdn.net/fly2nn https://blog.jcole.us/innodb/ https://www.orczhou.com/ https://github.com/hedengcheng/tech
服务器的日志一直报Packet for query is too large (7632997 > 4194304). You can change this value on the server by setting the max_allowed_packet’ variable.的解决方法
两个consumer反复重新加入group中,而他们的group是同一个,猜测是两个consumer使用同一个groupid导致,相互影响。
我们把Kafka比作Linux的内核,Confluent就相当于Linux的某个发行版。Confluent提供了Kafka没有的组件和功能,比如完善的跨数据中心数据备份以及集群监控解决方案。
Minio (https://github.com/minio/minio)提供对象存储服务,兼容了 AWS S3 存储协议,用于非结构化的数据存。非结构化对象,比如图像,音、视频,日志文件,备份镜像…等等管理不方便,不定长,大小变化大、类型多,云端的访问复杂,minio就是来解决这种场景的。非结构化的文件从数KB到5TB都能很好的支持。开源并且用Go语言开发,有web操作界面,我们可以用它来搭建兼容S3协议的存储云服务。
golang:unsupported Scan, storing driver.Value type []uint8 into type *time.Time
https://doris.apache.org/master/zh-CN/getting-started/basic-usage.html 在复合分区中:
https://neo4j.com/cloud/aura/?utm_program=na-prospecting&utm_source=google&utm_medium=cpc&utm_campaign=na-search-aura-professional&utm_adgroup=keywords&gclid=EAIaIQobChMIjsW6jsnV8QIVhKyWCh0C8QL9EAAYASAAEgIOVvD_BwE
Ardb中的二维空间索引实现从原理上说,可以简化为GeoHash + Sorted Set。 在比较早的时候写过一篇英文原理介绍在这里, 这里用中文再介绍一次。
https://github.com/kvakil/sqlvm https://dl.acm.org/doi/10.1145/2463676.2463686 https://www.microsoft.com/en-us/research/publication/sqlvm-performance-isolation-in-multi-tenant-relational-database-as-a-service/
在20年前就有NAS-网络附加存储这个东西,本质上也就是使用TCP/IP协议的以太网文件服务器。当时如果想要大规模的存储,就会让服务器将数据保存到NAS这个上面,但是NAS价格及其昂贵,并且扩展比较困难,NAS也就不适用于高速发展的互联网应用。 这个时候谷歌摒弃了之前的观念“移动存储到计算”,采取了“移动计算到存储的观念”,将计算和存储耦合了,因为当时的网络速度对比现在来说慢了几百倍,网络速度跟不上我们的需要。在在典型的MapReduce部署中计算和存储都在同一个集群中进行,比如后续的hadoop。这里其实也就是用本地IO速度来替换网络传输速度。 我们的网络速度也越来越快,我们的瓶颈不再是网络速度,但是我们的磁盘I/O速度却没有明显的速度增长,计算和存储融合的架构缺点也再逐渐暴露:
枚举类型使用陷阱
超级不推荐在mysql中设置某一字段类型为enum,但是存的值为数字,比如‘0’,‘1’,‘2’;
解释1:你会混淆,因为enum可以通过角标取值,但它的角标是从1开始,对于不熟悉这个字段的人这里会出错
解释2:enum类型的字段对于0与‘0’有非常大的区别,如果你是用0当角标做操作,因它没有这个角标,所要会报错;如果你使用‘0’这个值去取枚举值,并做插入操作,你会发现它竟然会成功,但是插入的结果是一个“空”(不是null)
解释3:enum类型对于php等弱语言类型的支持很差,弱语言类型打引号和不打引号的值可能是同一类型,但是对于mysql中enum类型的字段来说,那就不一定是一回事了
结论:总之,不要拿mysql的enum类型取存一些数字;如果你一定要使用这个字段去存数字,请把这个字段定义为int,然后在java代码中使用枚举类做一个对于这个字段值范围的一个限定!
CREATE TABLE test4 (
id BIGINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
brand VARCHAR(255) NOT NULL,
color ENUM(‘RED’,’GREEN’,’BLUE’)
) ENGINE = InnoDB;
MySQL 5.5/5.6/5.7三个大版本 在MySQL上述三个大版本中,默认时间戳(Timestamp)类型的取值范围为’1970-01-01 00:00:01’ UTC 至’2038-01-19 03:14:07’ UTC,数据精确到秒级别,该取值范围包含约22亿个数值,因此在MySQL内部使用4个字节INT类型来存放时间戳数据: 1、在存储时间戳数据时,先将本地时区时间转换为UTC时区时间,再将UTC时区时间转换为INT格式的毫秒值(使用UNIX_TIMESTAMP函数),然后存放到数据库中。 2、在读取时间戳数据时,先将INT格式的毫秒值转换为UTC时区时间(使用FROM_UNIXTIME函数),然后再转换为本地时区时间,最后返回给客户端。
WHERE ( order_amount != null and order_amount != ‘’ and received_amount != null and received_amount != ‘’ ) 查询结果,一条也没有! 在SQL中逻辑表达式的可能值包括TRUE、FALSE和UNKNOWN,它们被称之为三值逻辑。
TINYINT 1个字节 SMALLINT 2个字节 MEDIUMINT 3个字节 INT, INTEGER 4个字节 BIGINT 8个字节 FLOAT(p) 如果0 <= p <= 24为4个字节, 如果25 <= p <= 53为8个字节 FLOAT 4个字节 DOUBLE [PRECISION], item REAL 4个字节 DECIMAL(M,D), NUMERIC(M,D) 变长(0-4个字节) BIT(M) 大约(M+7)/8个字节 https://blog.csdn.net/free_ant/article/details/52936722
//SELECT TABLE_SCHEMA, TABLE_NAME FROM INFORMATION_SCHEMA.TABLES; //SELECT * FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA=’schema’ AND TABLE_NAME=’table’; //SHOW FULL COLUMNS FROM ‘table’; //show create table ‘table’; sqlingo 就是通过SHOW FULL COLUMNS FROM ‘table’; 来获取表结构生成orm的结构体,来保证代码和数据库的一致性的。
EXPLAIN SELECT MAX(year) FROM st_sch_recruit_info info
Golang的Redis库,用到最多的恐怕是 redigo 和 go-redis。其中 redigo 不支持对集群的访问。 在一个负载比较高的Redis Cluster中,如果允许对slave节点进行读操作将极大的提高集群的吞吐能力。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/preload-fielddata.html#preload-fielddata
在Redlock之前,很多人对于分布式锁的实现都是基于单个Redis节点的。而Redlock是基于多个Redis节点(都是Master)的一种实现。为了能理解Redlock,我们首先需要把简单的基于单Redis节点的算法描述清楚,因为它是Redlock的基础。
SHOW PROCESSLIST显示正在运行(用户运行线程)的线程(或SHOW FULL PROCESSLIST显示更多信息)
https://dev.mysql.com/doc/refman/8.0/en/innodb-online-ddl-operations.html
// 查询一条记录时, 不能使用类似if err := db.QueryRow().Scan(&…); err != nil {}的处理方式 // 因为查询单条数据时, 可能返回var ErrNoRows = errors.New(“sql: no rows in result set”)该种错误信息 // 而这属于正常错误
所有查询出来的字段都不允许有NULL, 避免该方式最好的办法就是建表字段时, 不要设置类似DEFAULT NULL属性
// 还有一些无法避免的情况, 比如下面这个查询
// 该种查询, 如果不存在, 返回值为NULL, 而非0, 针对该种简单的查询, 直接使用HAVING子句即可
// 具体的查询, 需要在编码的过程中自行处理
var age int32
err = db.QueryRow(`
SELECT
SUM(age) age
FROM user
WHERE id = ?
HAVING age <> NULL
`, 10).Scan(&age)
switch {
case err == sql.ErrNoRows:
case err != nil:
fmt.Println(err)
}
fmt.Println(age) } <!-- more --> https://studygolang.com/articles/9957
https://www.alexedwards.net/blog/how-to-manage-database-timeouts-and-cancellations-in-go https://medium.com/@rocketlaunchr.cloud/canceling-mysql-in-go-827ed8f83b30
if() 把salary表中的女改成男,男改成女: update salary set sex = if( sex = ‘男’,’女’,’男’); if(true,a,b), if(false,a,b) 这个就是第一个如果是true,就等于a,false就等于b,有点像三元表达式 ifnull(null, a),ifnull(a,b), ifnull里有两个数,如果第一个不是null,是a非null,就都等于a, 如果a=Null,就都为a。 https://www.cnblogs.com/jiangshengxiang/p/9263429.html
游标(Cursor)它使用户可逐行访问由SQL Server返回的结果集。 使用游标(cursor)的一个主要的原因就是把集合操作转换成单个记录处理方式。 优点 1、允许程序对由查询语句select返回的行集合中的每一行执行相同或不同的操作,而不是对整个行集合执行同一个操作。
如何保证orm 和数据库的一致性,可以通过 show tables; 获取所有的数据库 然后 show databases from xxx; 获取所有的表 然后用 SHOW FULL COLUMNS FROM xxx; 获取表的所有列详细信息
upsert(update or insert), 即更新或写入。 MySQL中实现upsert操作方式: 思路:通过判断插入的记录里是否存在主键索引或唯一索引冲突,来决定是插入还是更新。当出现主键索引或唯一索引冲突时则进行update操作,否则进行insert操作。 实现:使用 ON DUPLICATE KEY UPDATE insert into demo(a,b,c,d,e,f) values(1,1,1,2,2,2) ON DUPLICATE KEY UPDATE a=2,b=2,c=3,d=4,e=5,f=6; 因为已经存在由abc三列组成唯一索引数据:1,1,1,本次又写入demo(a,b,c,d,e,f) values(1,1,1,2,2,2),会造成唯一索引冲突。 因此,会触发ON DUPLICATE KEY 后面的 UPDATE a=2,b=2,c=3,d=4,e=5,f=6操作。 至此,已经实现upsert功能。请记住 ON DUPLICATE KEY UPDATE的用法。
索引条件下推(Index Condition Pushdown),简称ICP。MySQL5.6新添加,用于优化数据的查询。 当你不使用ICP,通过使用非主键索引(普通索引or二级索引)进行查询,存储引擎通过索引检索数据,然后返回给MySQL服务器,服务器再判断是否符合条件。 使用ICP,当存在索引的列做为判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。 官方文档 2.适用场景 当需要整表扫描,e.g.:range,ref,eq_ref…. 适用InnoDB引擎和MyISAM引擎查询(5.6版本不适用分区查询,5.7版本可以用于分区表查询)。 InnoDB引擎仅仅适用二级索引。(原因InnoDB聚簇索引将整行数据读到InnoDB缓冲区)。 子查询条件不能下推。触发条件不能下推,调用存储过程条件不能下推。
mapping则又可以分为动态映射(dynamic mapping)和静态(显式)映射(explicit mapping)和精确(严格)映射(strict mappings),具体由dynamic属性控制。
https://blog.jcole.us/innodb/ https://blog.jcole.us/2013/01/03/a-quick-introduction-to-innodb-ruby/ https://blog.jcole.us/innodb/ https://blog.jcole.us/2013/01/10/the-physical-structure-of-records-in-innodb/
https://hejtao.com/2019/09/20/2019-9-20/#qi-dong-xuan-xiang-he-xi-tong-bian-liang
https://dev.mysql.com/doc/refman/5.6/en/innodb-online-ddl-operations.html
对于InnoDB表空间来说,表空间是有多个区组成的。其中的每个区都由物理位置上连续的64个页组成,因为每个页的大小为16K,所以一个区的大小是1M。
由于MySQL 5.6引入了在线DDL,因此ALTER TABLE命令可以选择指定ALGORITHM = INPLACE或ALGORITHM = COPY. overview of online DDL指出,默认情况下,尽可能使用INPLACE,并暗示(没有说明)INPLACE算法比COPY算法便宜.
https://juejin.cn/book/6844733769996304392/section/6844733770042441736
在MySQL里面update一条记录,语法都正确的,但记录并没有被更新…
update apps set owner_code=’43212’ and owner_name=’李四’ where owner_code=’13245’ and owner_name=’张三’;
CREATE TABLE t_enum_example ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(10) DEFAULT NULL, color enum(‘blue’,’green’,’red’) DEFAULT NULL, PRIMARY KEY (id) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1;
https://github.com/go-redis/redis https://github.com/gomodule/redigo
阿里云对象存储OSS(Object Storage Service)为您提供基于网络的数据存取服务。使用OSS,您可以通过网络随时存储和调用包括文本、图片、音视频在内的各类数据文件。
会出现问题总结 消息队列造成系统可用性降低 系统复杂性增加 消息丢失问题 消息重复消费 消费顺序问题 会出现问题总结 消息队列造成系统可用性降低 系统复杂性增加 消息丢失问题 消息重复消费 消费顺序问题 千万注意!使用消息队列时一定要考虑这些问题,否则可能会造成不可估量的后果!!
问题前要:对于一个字段,它的更新操作很频繁,那么应该使用普通索引还是唯一索引? 结论: 如果业务能够保证唯一性应该尽量选择普通索引而不是唯一索引 从查询和更新两方面说明:
https://time.geekbang.org/column/article/168963 https://tech.meituan.com/2014/06/30/mysql-index.html
热 key 指的是那些在一段时间内访问频次比较高的键值,具体到业务上,商品的限时抢购、瞬时的新闻热点或某个全局性的资源,都极有可能产生热点 key。
设计定位方案的话,我们可以从 Redis 请求路径上的节点来着手,比如在客户端、中间层和服务端,具体来说如下:
比如像MHA,它自己也必须搭建成Master-Slave架构,有种跌入了递归深渊的感觉。为了更好地解决外部HA模块的高可用,一致性协议进入了视野,ZooKeeper方案应运而生,用一套ZooKeeper来管理HA,系统也变得越来越复杂。
https://github.com/apache/kylin/tree/kylin-on-parquet-v2 https://cwiki.apache.org/confluence/display/KYLIN/Design+Architecture
https://gocn.vip/topics/10794 TiDB 是一款分布式 HTAP 数据库,它目前有两种存储节点,分别是 TiKV 和 TiFlash。TiKV 采用了行式存储,更适合 TP 类型的业务;而 TiFlash 采用列式存储,擅长 AP 类型的业务。TiFlash 通过 raft 协议从 TiKV 节点实时同步数据,拥有毫秒级别的延迟,以及非常优秀的数据分析性能。它支持实时同步 TiKV 的数据更新,以及支持在线 DDL。我们把 TiFlash 作为 Raft Learner 融合进 TiDB 的 raft 体系,将两种节点整合在一个数据库集群中,上层统一通过 TiDB 节点查询,使得 TiDB 成为一款真正的 HTAP 数据库。 https://dev.to/spindriftboi/concurrency-in-go-using-goroutines-and-wait-groups-edi
from pyspark.sql import SparkSession, HiveContext
_SPARK_HOST = “spark://spark-master:7077” _APP_NAME = “test”
spark = SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()
data = [ (1,”3”,”145”), (1,”4”,”146”), (1,”5”,”25”), (1,”6”,”26”), (2,”32”,”32”), (2,”8”,”134”), (2,”8”,”134”), (2,”9”,”137”) ] df = spark.createDataFrame(data, [‘id’, “test_id”, ‘camera_id’])
df.registerTempTable(‘test_hive’) sqlContext.sql(“create table default.write_test select * from test_hive”) https://blog.csdn.net/u011412768/article/details/93426353
客户端发送一条查询给服务器。 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。 MySQL根据优化器生成的执行计划,再调用存储引擎的API来执行查询。 将结果返回给客户端。 https://juejin.im/post/5b7036de6fb9a009c40997eb
Redis大key的一些场景及问题大key场景Redis使用者应该都遇到过大key相关的场景,比如:1、热门话题下评论、答案排序场景。2、大V的粉丝列表。3、使用不恰当,或者对业务预估不准确、不及时进行处理垃圾数据等。大key问题由于Redis主线程为单线程模型,大key也会带来一些问题,如:1、集群模式在slot分片均匀情况下,会出现数据和查询倾斜情况,部分有大key的Redis节点占用内存多,QPS高。2、大key相关的删除或者自动过期时,会出现qps突降或者突升的情况,极端情况下,会造成主从复制异常,Redis服务阻塞无法响应请求。大key的体积与删除耗时可参考下表:key类型 field数量耗时Hash~100万~1000msList~100万~1000msSet~100万~1000msSorted Set~100万~1000msRedis 4.0之前的大key的发现与删除方法1、redis-rdb-tools工具。redis实例上执行bgsave,然后对dump出来的rdb文件进行分析,找到其中的大KEY。2、redis-cli –bigkeys命令。可以找到某个实例5种数据类型(String、hash、list、set、zset)的最大key。3、自定义的扫描脚本,以Python脚本居多,方法与redis-cli –bigkeys类似。4、debug object key命令。可以查看某个key序列化后的长度,每次只能查找单个key的信息。官方不推荐。redis-rdb-tools工具 关于rdb工具的详细介绍请查看链接https://github.com/sripathikrishnan/redis-rdb-tools,在此只介绍内存相关的使用方法。基本的命令为 rdb -c memory dump.rdb (其中dump.rdb为Redis实例的rdb文件,可通过bgsave生成)。输出结果如下:database,type,key,size_in_bytes,encoding,num_elements,len_largest_element0,hash,hello1,1050,ziplist,86,22,0,hash,hello2,2517,ziplist,222,8,0,hash,hello3,2523,ziplist,156,12,0,hash,hello4,62020,hashtable,776,32,0,hash,hello5,71420,hashtable,1168,12,可以看到输出的信息包括数据类型,key、内存大小、编码类型等。Rdb工具优点在于获取的key信息详细、可选参数多、支持定制化需求,结果信息可选择json或csv格式,后续处理方便,其缺点是需要离线操作,获取结果时间较长。redis-cli –bigkeys命令Redis-cli –bigkeys是redis-cli自带的一个命令。它对整个redis进行扫描,寻找较大的key,并打印统计结果。例如redis-cli -p 6379 –bigkeys#Scanning the entire keyspace to find biggest keys as well as#average sizes per key type. You can use -i 0.1 to sleep 0.1 sec#per 100 SCAN commands (not usually needed).[00.72%] Biggest hash found so far ‘hello6’ with 43 fields[02.81%] Biggest string found so far ‘hello7’ with 31 bytes[05.15%] Biggest string found so far ‘hello8’ with 32 bytes[26.94%] Biggest hash found so far ‘hello9’ with 1795 fields[32.00%] Biggest hash found so far ‘hello10’ with 4671 fields[35.55%] Biggest string found so far ‘hello11’ with 36 bytes——– summary ——-Sampled 293070 keys in the keyspace!Total key length in bytes is 8731143 (avg len 29.79)Biggest string found ‘hello11’ has 36 bytesBiggest hash found ‘hello10’ has 4671 fields238027 strings with 2300436 bytes (81.22% of keys, avg size 9.66)0 lists with 0 items (00.00% of keys, avg size 0.00)0 sets with 0 members (00.00% of keys, avg size 0.00)55043 hashs with 289965 fields (18.78% of keys, avg size 5.27)0 zsets with 0 members (00.00% of keys, avg size 0.00)我们可以看到打印结果分为两部分,扫描过程部分,只显示了扫描到当前阶段里最大的key。summary部分给出了每种数据结构中最大的Key以及统计信息。redis-cli –bigkeys的优点是可以在线扫描,不阻塞服务;缺点是信息较少,内容不够精确。扫描结果中只有string类型是以字节长度为衡量标准的。List、set、zset等都是以元素个数作为衡量标准,元素个数多不能说明占用内存就一定多。自定义Python扫描脚本通过strlen、hlen、scard等命令获取字节大小或者元素个数,扫描结果比redis-cli –keys更精细,但是缺点和redis-cli –keys一样,不赘述。总之,之前的方法要么是用时较长离线解析,或者是不够详细的抽样扫描,离理想的以内存为维度的在线扫描获取详细信息有一定距离。由于在redis4.0前,没有lazy free机制;针对扫描出来的大key,DBA只能通过hscan、sscan、zscan方式渐进删除若干个元素;但面对过期删除键的场景,这种取巧的删除就无能为力。我们只能祈祷自动清理过期key刚好在系统低峰时,降低对业务的影响。Redis 4.0之后的大key的发现与删除方法Redis 4.0引入了memory usage命令和lazyfree机制,不管是对大key的发现,还是解决大key删除或者过期造成的阻塞问题都有明显的提升。下面我们从源码(摘自Redis 5.0.4版本)来理解memory usage和lazyfree的特点。memory usage{“memory”,memoryCommand,-2,”rR”,0,NULL,0,0,0,0,0}(server.c285⾏)void memoryCommand(client c) {/…//计算key大小是通过抽样部分field来估算总大小。/elseif(!strcasecmp(c->argv[1]->ptr,”usage”) &&c->argc >=3) { size_t usage = objectComputeSize(dictGetVal(de),samples);/…/ }}(object.c1299⾏)从上述源码看到memory usage是通过调用objectComputeSize来计算key的大小。我们来看objectComputeSize函数的逻辑。#defineOBJ_COMPUTE_SIZE_DEF_SAMPLES 5 / Default sample size. /size_tobjectComputeSize(robj *o, size_t sample_size){/…代码对数据类型进行了分类,此处只取hash类型说明//…//循环抽样个field,累加获取抽样样本内存值,默认抽样样本为5/while((de = dictNext(di)) != NULL && samples < sample_size) { ele = dictGetKey(de); ele2 = dictGetVal(de); elesize += sdsAllocSize(ele) + sdsAllocSize(ele2);elesize +=sizeof(structdictEntry); samples++; } dictReleaseIterator(di);/根据上一步计算的抽样样本内存值除以样本量,再乘以总的filed个数计算总内存值/if(samples) asize += (double)elesize/samplesdictSize(d);/…/ }(object.c779⾏)由此,我们发现memory usage默认抽样5个field来循环累加计算整个key的内存大小,样本的数量决定了key的内存大小的准确性和计算成本,样本越大,循环次数越多,计算结果更精确,性能消耗也越多。我们可以通过Python脚本在集群低峰时扫描Redis,用较小的代价去获取所有key的内存大小。以下为部分伪代码,可根据实际情况设置大key阈值进行预警。forkeyinr.scan_iter(count=1000):redis-cli =’/usr/bin/redis-cli’configcmd =’%s -h %s -p %s memory usage %s’% (redis-cli, rip,rport,key) keymemory = commands.getoutput(configcmd)lazyfree机制Lazyfree的原理是在删除的时候只进行逻辑删除,把key释放操作放在bio(Background I/O)单独的子线程处理中,减少删除大key对redis主线程的阻塞,有效地避免因删除大key带来的性能问题。在此提一下bio线程,很多人把Redis通常理解为单线程内存数据库, 其实不然。Redis将最主要的网络收发和执行命令等操作都放在了主工作线程,然而除此之外还有几个bio后台线程,从源码中可以看到有处理关闭文件和刷盘的后台线程,以及Redis4.0新增加的lazyfree线程。/* Background job opcodes /#defineBIO_LAZY_FREE 2/ Deferred objects freeing. /(bio.h38⾏)下面我们以unlink命令为例,来理解lazyfree的实现原理。{“unlink”,unlinkCommand,-2,”wF”,0,NULL,1,-1,1,0,0},(server.c137⾏)void unlinkCommand(client *c) {delGenericCommand(c,1);}(db.c490⾏)通过这几段源码可以看出del命令和unlink命令都是调用delGenericCommand,唯一的差别在于第二个参数不一样。这个参数就是异步删除参数。/ This command implements DEL and LAZYDEL. /void delGenericCommand(client *c, intlazy) {/…/int deleted =lazy? dbAsyncDelete(c->db,c->argv[j]) :dbSyncDelete(c->db,c->argv[j]);/…/}(db.c468⾏)可以看到delGenericCommand函数根据lazy参数来决定是同步删除还是异步删除。当执行unlink命令时,传入lazy参数值1,调用异步删除函数dbAsyncDelete。否则执行del命令传入参数值0,调用同步删除函数dbSyncDelete。我们重点来看异步删除dbAsyncDelete的实现逻辑:#defineLAZYFREE_THRESHOLD 64/定义后台删除的阈值,key的元素大于该阈值时才真正丢给后台线程去删除/intdbAsyncDelete(redisDb *db, robj *key){/…//lazyfreeGetFreeEffort来获取val对象所包含的元素个数/size_tfree_effort = lazyfreeGetFreeEffort(val);/ 对删除key进行判断,满足阈值条件时进行后台删除 /if(free_effort > LAZYFREE_THRESHOLD && val->refcount ==1) {atomicIncr(lazyfree_objects,1);bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL);/将删除对象放入BIO_LAZY_FREE后台线程任务队列/dictSetVal(db->dict,de,NULL);/将第一步获取到的val值设置为null/ }/…/}(lazyfree.c53⾏)上面提到了当删除key满足阈值条件时,会将key放入BIO_LAZY_FREE后台线程任务队列。接下来我们来看BIO_LAZY_FREE后台线程。/…/elseif(type == BIO_LAZY_FREE) {if(job->arg1)/ 后台删除对象函数,调用decrRefCount减少key的引用计数,引用计数为0时会真正的释放资源 / lazyfreeFreeObjectFromBioThread(job->arg1);elseif(job->arg2 && job->arg3)/ 后台清空数据库字典,调用dictRelease循环遍历数据库字典删除所有key / lazyfreeFreeDatabaseFromBioThread(job->arg2,job->arg3);elseif(job->arg3)/ 后台删除key-slots映射表,在Redis集群模式下会用*/ lazyfreeFreeSlotsMapFromBioThread(job->arg3);}(bio.c197⾏)unlink命令的逻辑可以总结为:执行unlink调用delGenericCommand函数传入lazy参数值1,来调用异步删除函数dbAsyncDelete,将满足阈值的大key放入BIO_LAZY_FREE后台线程任务队列进行异步删除。类似的后台删除命令还有flushdb async、flushall async。它们的原理都是获取删除标识进行判断,然后调用异步删除函数emptyDbAsnyc来清空数据库。这些命令具体的实现逻辑可自行查看flushdbCommand部分源码,在此不做赘述。除了主动的大key删除和数据库清空操作外,过期key驱逐引发的删除操作也会阻塞Redis服务。因此Redis4.0除了增加上述三个后台删除的命令外,还增加了4个后台删除配置项,分别为slave-lazy-flush、lazyfree-lazy-eviction、lazyfree-lazy-expire和lazyfree-lazy-server-del。slave-lazy-flush:slave接收完RDB文件后清空数据选项。建议大家开启slave-lazy-flush,这样可减少slave节点flush操作时间,从而降低主从全量同步耗时的可能性。lazyfree-lazy-eviction:内存用满逐出选项。若开启此选项可能导致淘汰key的内存释放不够及时,内存超用。lazyfree-lazy-expire:过期key删除选项。建议开启。lazyfree-lazy-server-del:内部删除选项,比如rename命令将oldkey修改为一个已存在的newkey时,会先将newkey删除掉。如果newkey是一个大key,可能会引起阻塞删除。建议开启。上述四个后台删除相关的参数实现逻辑差异不大,都是通过参数选项进行判断,从而选择是否采用dbAsyncDelete或者emptyDbAsync进行异步删除。总结在某些业务场景下,Redis大key的问题是难以避免的,但是,memory usage命令和lazyfree机制分别提供了内存维度的抽样算法和异步删除优化功能,这些特性有助于我们在实际业务中更好的预防大key的产生和解决大key造成的阻塞。关于Redis内核的优化思路也可从Redis作者Antirez的博客中窥测一二,他提出”Lazy Redis is better Redis”、”Slow commands threading”(允许在不同的线程中执行慢操作命令),异步化应该是Redis优化的主要方向。Redis作为个推消息推送的一项重要的基础服务,性能的好坏至关重要。个推将Redis版本从2.8升级到5.0后,有效地解决了部分大key删除或过期造成的阻塞问题。未来,个推将会持续关注Redis 5.0及后续的Redis 6.0,与大家共同探讨如何更好地使用Redis。参考文档: 1、http://antirez.com/news/932、http://antirez.com/news/126
Pgsql 一、 PostgreSQL 的稳定性极强, Innodb 等引擎在崩溃、断电之类的灾难场景下抗打击能力有了长足进步,然而很多 MySQL 用户都遇到过Server级的数据库丢失的场景——mysql系统库是MyISAM的,相比之下,PG数据库这方面要好一些。 二、任何系统都有它的性能极限,在高并发读写,负载逼近极限下,PG的性能指标仍可以维持双曲线甚至对数曲线,到顶峰之后不再下降,而 MySQL 明显出现一个波峰后下滑(5.5版本之后,在企业级版本中有个插件可以改善很多,不过需要付费)。 三、PG 多年来在 GIS 领域处于优势地位,因为它有丰富的几何类型,实际上不止几何类型,PG有大量字典、数组、bitmap 等数据类型,相比之下mysql就差很多,instagram就是因为PG的空间数据库扩展POSTGIS远远强于MYSQL的my spatial而采用PGSQL的。 四、PG 的“无锁定”特性非常突出,甚至包括 vacuum 这样的整理数据空间的操作,这个和PGSQL的MVCC实现有关系。 五、PG 的可以使用函数和条件索引,这使得PG数据库的调优非常灵活,mysql就没有这个功能,条件索引在web应用中很重要。 六、PG有极其强悍的 SQL 编程能力(9.x 图灵完备,支持递归!),有非常丰富的统计函数和统计语法支持,比如分析函数(ORACLE的叫法,PG里叫window函数),还可以用多种语言来写存储过程,对于R的支持也很好 TiDB 在架构上将计算和存储层进行高度的抽象和分离,对混合负载的场景通过 IO 优先级队列,智能副本调度,行列混合存储等技术使其变为可能。TiDB 作为开源的分布式关系数据库,其特点是几乎可以 100% 兼容 MySQL 接口,也兼容 MySQL 的语法和协议,在保证不丧失 ACID 事务的前提下,能够弹性伸缩,高可用,可以同时处理 OLTP 和 OLAP 工作负载,不再需要 ETL。 OceanBase采用的是share-nothing的分布式架构,每个OBServer都是对等的,管理不同的数据分区。单机的存储引擎采取读写分离的架构,将当前更新的动态数据存入内存称为MemTable,存量的基线数据存在磁盘,称为SSTable。 一个Partition的所有数据(基线数据+增量数据+事务日志)都放在一个OBServer中,因此针对一个Partition的读写操作不会有跨机的操作,数据的写入也分布到多点并行执行。
1.Mongodb bson文档型数据库,整个数据都存在磁盘中,hbase是列式数据库,集群部署时每个familycolumn保存在单独的hdfs文件中。
流处理系统需要能优雅地处理反压(backpressure)问题。反压通常产生于这样的场景:短时负载高峰导致系统接收数据的速率远高于它处理数据的速率。许多日常问题都会导致反压,例如,垃圾回收停顿可能会导致流入的数据快速堆积,或者遇到大促或秒杀活动导致流量陡增。反压如果不能得到正确的处理,可能会导致资源耗尽甚至系统崩溃。 Storm 是通过监控 Bolt 中的接收队列负载情况,如果超过高水位值就会将反压信息写到 Zookeeper ,Zookeeper 上的 watch 会通知该拓扑的所有 Worker 都进入反压状态,最后 Spout 停止发送 tuple。具体实现可以看这个 JIRA STORM-886。
https://blog.csdn.net/qq_35688140/article/details/89600106 1、UDF:用户定义(普通)函数,只对单行数值产生作用; 继承UDF类,添加方法 evaluate()
InfluxDB存储引擎Time Structured Merge Tree——本质上和LSM无异,只是结合了列存储压缩,其中引入fb的float压缩,字串字典压缩等
http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/36632.pdf http://vldb.org/pvldb/vol5/p1436_alexanderhall_vldb2012.pdf https://druid.apache.org/druid-powered.html https://medium.com/airbnb-engineering/druid-airbnb-data-platform-601c312f2a4c https://druid.apache.org/druid.html
flink的sink是flink三大逻辑结构之一(source,transform,sink),功能就是负责把flink处理后的数据输出到外部系统中,flink 的sink和source的代码结构类似。 Source 数据源 —- > Compute 计算 —–> sink 落库
https://www.influxdata.com/blog/influxdb-markedly-outperforms-opentsdb-in-time-series-data-metrics-benchmark/
https://oss.oetiker.ch/rrdtool/doc/index.en.html https://oss.oetiker.ch/rrdtool/
块存储、文件存储、对象存储这三者的本质差别是什么? 作者:木头龙 链接:https://www.zhihu.com/question/21536660/answer/1159036357 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
etcd raft是目前使用最广泛的raft库,如果想深入了解raft请直接阅读论文 “In Search of an Understandable Consensus Algorithm”(https://raft.github.io/raft.pdf), etcd raft在etcd, Kubernetes, Docker Swarm, Cloud Foundry Diego, CockroachDB, TiDB, Project Calico, Flannel等分布式系统中都有应用,在生成环境得到了验证。 传统raft库的实现都是单体设计(集成了存储层、消息序列化、网络层等), etcd raft继承了简约的设计理念,只实现了最核心的raft算法, 这样更加的灵活。etcd将网络、日志存储、快照等功能分开,通过独立的模块实现,用户可以在需要时调用。etcd自身实现了自己的一套raft配套库:etcd-wal(用于存储日志),snap(用于存储快照),MemoryStorage(用于存储当前日志、快照、状态等信息以供raft核心程序使用)。 https://raft.github.io/raft.pdf 集群中最核心内容是保证数据一致性,那么如何保证数据一致性?在业界有很多算法、协议,例如:Paxos,Raft。 Raft协议相比之前协议Paxos等,算是年轻协议,而且Raft协议比较简单,容易实现。
https://dev.mysql.com/doc/refman/5.7/en/gis-wkb-functions.html https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/36726.pdf https://dev.mysql.com/doc/internals/en/binlog-row-image.html https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html https://dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html https://dev.mysql.com/doc/refman/5.7/en/binary-log.html https://dev.mysql.com/doc/refman/5.7/en/mysqlbinlog.html https://dev.mysql.com/doc/internals/en/binary-log.html
Apache Parquet是一种能够有效存储嵌套数据的列式存储格式。 Parquet文件由一个文件头(header),一个或多个紧随其后的文件块(block),以及一个用于结尾的文件尾(footer)构成。文件头仅包含 Parquet文件的每个文件块负责存储一个行组,行组由列块组成,且一个列块负责存储一列数据。每个列块中的的数据以页为单位 为什么我们选择parquet 前用的hadoop,一直有个疑惑。当时没有细究,昨天突然想到,就又顺着看了下,经过调整,原来在presto中要用1分钟的,现在基本可以秒级别出结果,和presto无关,和文件存储格式有关,hdfs默认存的是文本格式,所以hive,presto,都是在文本格式上做计算,hadoop本身是全表扫,只是分布式而以,所以我们之前用的就是分布式的全表扫而以,没有发挥出数据仓库该有的功能,列式存储,天然擅长分析,千万级别的表,count,sum,group by ,秒出结果!!
golang操作数据库,是通过database/sql包,以及第三方的实现了database/sql/driver接口的数据库驱动包来共同完成的。
ysql中set autocommit=0与start transaction区别 set autocommit=0指事务非自动提交,自此句执行以后,每个SQL语句或者语句块所在的事务都需要显示”commit”才能提交事务。
什么是binlog MySQL的binlog日志是由MySQL server层生成的日志,用来记录MysSQL内部增删改查等对mysql数据库有更新的内容的记录(对数据库的改动),对数据库的查询select或show等不会被binlog日志记录。binlog以event形式记录,还包含语句所执行的消耗的时间,binlog是事务安全型的
在线数据库的维护中,总会涉及到研发修改表结构的情况,修改一些小表影响很小,而修改大表时,往往影响业务的正常运转,如表数据量超过500W,1000W,甚至过亿时
索引(Index)是帮助MySQL高效获取数据的数据结构。MyISAM和Innodb都使用了B+树这种数据结构做为索引。
MySQL 从5.0.3开始支持XA分布式事务,且只有InnoDB存储引擎支持。MySQL Connector/J 从5.0.0版本之后开始直接提供对XA的支持 在DTP模型中,mysql属于资源管理器(RM)。而一个完整的分布式事务中,一般会存在多个RM,由事务管理器TM来统一进行协调。因此,这里所说的mysql对XA分布式事务的支持,一般指的是单台mysql实例如何执行自己的事务分支。 MySQL XA 事务SQL语法 https://dev.mysql.com/doc/refman/5.7/en/xa-statements.html
ru(least recently used)是一种缓存置换算法。即在缓存有限的情况下,如果有新的数据需要加载进缓存,则需要将最不可能被继续访问的缓存剔除掉。因为缓存是否可能被访问到没法做预测,所以基于如下假设实现该算法:
https://github.com/vesoft-inc/nebula?utm_source=go https://gocn.vip/topics/10164 http://blog.itpub.net/69952037/viewspace-2683907/ 从社交网络谈起 下面这张图是一个社交网络场景,每个用户可以发微博、分享微博或评论他人的微博。这些都是最基本的增删改查,也是大多数研发人员对数据库做的常见操作。而在研发人员的日常工作中除了要把用户的基本信息录入数据库外,还需找到与该用户相关联的信息,方便去对单个的用户进行下一步的分析,比如说:我们发现张三的账户里有很多关于 AI 和音乐的内容,那么我们可以据此推测出他可能是一名程序员,从而推送他可能感兴趣的内容。
如果缓存失效,瞬间大量请求可能会直接访问数据库,请问如何在代码层面应该怎么处理? 近有人问我这个问题,我个人没有这方面的实战经验。我个人的想法是,由于访问数据库并写入缓存需要一定的时间。可能导致较早的部分请求直接读取数据库,当这部分数据要写入缓存时,判断缓存是否存在,不存在则写入,存在则不写入,并返回结果。 if ($cache) { return $cache; } else { $data = read database; if (!$cache) write $cache $data; return $data; }
Squirrel(松鼠)是美团技术团队基于Redis Cluster打造的缓存系统。 https://www.cnblogs.com/meituantech/p/9376472.html https://tech.meituan.com/2018/03/16/redis-high-concurrency-optimization.html Root Cause 定位
一个表有3000万记录,假如有一列占8位字节的字段,根据这一列建索引的话索引树的高度是多少? 平时这也只关注MySQL索引一般都是都是用B+Tree来存储维护索引的,还有一些复合索引的最左匹配原则等等,还真没有实际关注过始即然用到索引能提升
当redis中key数量越大,keys 命令执行越慢,而且最重要的会阻塞服务器,对单线程的redis来说,简直是灾难,终于找到了替代命令scan。
SCAN cursor [MATCH pattern] [COUNT count]
https://gocn.vip/topics/10121 分布式概念 分布式实际上就是单一的本地一体解决方案,在硬件或者资源上不够业务需求,而采取的一种分散式多节点,可以扩容资源的一种解决思路。它研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给多个计算机进行处理,最后把这些计算结果综合起来得到最终的结果。
https://gocn.vip/topics/10104 一、需求分析 AI 技术在 vivo 内部应用越来越广泛,其中特征数据扮演着至关重要的角色,用于离线训练、在线预估等场景,我们需要设计一个系统解决各种特征数据可靠高效存储的问题。
https://ruby-china.org/topics/28094 内网中 60% 开放了 redis6379 端口的主机处于可以被利用的危险状态,因为都是一些默认配置造成的 Redis 默认情况下,会绑定在 0.0.0.0:6379,这样将会将 Redis 服务暴露到公网上,如果在没有开启认证的情况下,可以导致任意用户在可以访问目标服务器的情况下未授权访问 Redis 以及读取 Redis 的数据。攻击者在未授权访问 Redis 的情况下可以利用 Redis 的相关方法,可以成功在 Redis 服务器上写入公钥,进而可以使用对应私钥直接登录目标服务器。 入侵特征:
什么是HTTP缓存 HTTP 缓存可以说是HTTP性能优化中简单高效的一种优化方式了,缓存是一种保存资源副本并在下次请求时直接使用该副本的技术,当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。 一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,节省网络流量,并且由于缓存文件可以重复利用,降低网络负荷,提高客户端响应。 所以,学会利用HTTP缓存是很有必要的 在此,我会向大家系统的介绍HTTP缓存机制,期望对各位正确的理解HTTP缓存有所帮助。
https://draveness.me/whys-the-database-data-loss 数据库管理系统在今天已经是软件的重要组成部分,开源的 MySQL、PostgreSQL 以及商业化的 Oracle 等数据库已经随处可见,几乎所有的服务都需要依赖数据库管理系统存储数据。
一、dynamo特点介绍 dynamo 的中文意思是发电机,意思是像发电机一样,提供源源不断的服务。它是Amazon提供的一个分布式Key/Value存储的NoSQL 数据库,完全托管在云端,支持文档和键值存储模型。
强一致性、顺序一致性、弱一致性和共识 原创chao2016 发布于2018-07-21 21:57:37 阅读数 12831 收藏 展开
mysqldump -u root -p -q -e -t webgps4 dn_location2 > dn_location2.sql mysqldump -u root -p -q -e -t –single-transaction webgps4 dn_location2 > dn_location2.sql source dn_location2.sql 以上是导入导出数据的语句,该方法15分钟导出1.6亿条记录,导出的文件中平均7070条记录拼成一个insert语句,通过source进行批量插入,导入1.6亿条数据耗时将近5小时。平均速度:3200W条/h。后来尝试加上–single-transaction参数,结果影响不大。另外,若在导出时增加-w参数,表示对导出数据进行筛选,那么导入导出的速度基本不变,筛选出的数据量越大,时间越慢而已。对于其中的参数这里进行说明: –quick,-q 该选项在导出大表时很有用,它强制 mysqldump 从服务器查询取得记录直接输出而不是取得所有记录后将它们缓存到内存中。
一.索引是什么? 索引是数据库中用来提高查询效率的技术,类似于目录。如果不使用索引,数据会零散的保存在磁盘块中,查询数据需要挨个遍历每一个磁盘块,直到找到数据为止,使用索引后会将磁盘块以树桩结构保存,查询数据时会大大降低磁盘块的访问数量,从而提高查询效率。如果表中的数据很少,使用索引反而会降低查询效率。并且索引会占用磁盘空间,一般只针对查询时常用的字段创建索引。索引分为聚集索引和非聚集索引,通过主键创建的索引称为聚集索引,聚集索引中保存数据,只要给表添加主键约束,则会自动创建聚集索引;通过非主键字段创建的索引称为非聚集索引,非聚集索引中没有数据。还可以通过多个字段来创建复合索引。
mysql可以实现,同一个数据库中,不同的表应用不同的存储引擎, mysql主从数据库里同一张表,数据引擎也可以不一样 1、先看看mysql当前默认存储引擎
在使用msyql进行模糊查询的时候,很自然的会用到like语句,通常情况下,在数据量小的时候,不容易看出查询的效率,但在数据量达到百万级,千万级的时候,查询的效率就很容易显现出来。这个时候查询的效率就显得很重要!
Redis的持久化过程中并不需要我们开发人员过多的参与,我们要做的是什么呢?除了深入了解RDB和AOF的作用原理,剩下的就是根据实际情况来制定合适的策略了,再复杂一点,也就是定制一个高可用的,数据安全的策略了。
Mysql最常用的三种备份工具分别是mysqldump、Xtrabackup(innobackupex工具)、lvm-snapshot快照。
ACID事务 传统的数据库系统依赖于将工作捆绑到具有 ACID 属性的事务中。如此,他们就通过牺牲可用性或者分区容忍性来保证一致性。ACID 是以下单词的缩写:
物化视图是包括一个查询结果的数据库对象,它是远程数据的的本地副本,或者用来生成基于数据表求和的汇总表。物化视图存储基于远程表的数据,也可以称为快照(类似于MSSQL Server中的snapshot,静态快照) [1] 。对于复制,物化视图允许你在本地维护远程数据的副本,这些副本是只读的。如果你想修改本地副本,必须用高级复制的功能。当你想从一个表或视图中抽取数据时,你可以用从物化视图中抽取。对于数据仓库,创建的物化视图通常情况下是聚合视图,单一表聚合视图和连接视图。(这个是基于本地的基表或者视图的聚合)。物化视图,说白了,就是物理表,只不过这张表通过oracle的内部机制可以定期更新,将一些大的耗时的表连接用物化视图实现,会提高查询的效率。当然要打开查询重写选项 1、创建方式(Build Methods):Build Immediate 和Build Deferred两种。Build Immediate 是在创建物化视图的时候就生成数据,而Build Deferred则在创建时不生成数据,以后根据需要再生成数据。默认为Build Immediate 。 2、查询重写(Query Rewrite):Enable Query Rewrite和Disable Query Rewrite两种。分别指出创建的物化视图是否支持查询重写。查询重写是指当对物化视图的基表进行查询时,Oracle会自动判断能否通过查询物化视图来得到结果,如果可以,则避免了聚集或连接操作,而直接从已经计算好的物化视图中读取数据。默认为Disable Query Rewrite。 3、刷新(Refresh):指当基表发生了DML操作后,物化视图何时采用哪种方式和基表进行同步。刷新的模式有两种:On Demand和On Commit。On Demand指物化视图在用户需要的时候进行刷新,可以手工通过DBMS_MVIEW.REFRESH等方法来进行刷新,也可以通过JOB定时进行刷新。On Commit指物化视图在对基表的DML操作提交的同时进行刷新。刷新的方法有四种:Fast 、Complete 、Force和Never。Fast 刷新采用增量刷新,只刷新自上次刷新以后进行的修改。Complete 刷新对整个物化视图进行完全的刷新。如果选择Force方式,则Oracle在刷新时会去判断是否可以进行快速刷新,如果可以则采用FAST方式,否则采用Complete 的方式。Never指物化视图不进行任何刷新。默认值是Force On Demand。 在建立物化视图的时候可以指定Order by 语句,使生成的数据按照一定的顺序进行保存。不过这个语句不会写入物化视图的定义中,而且对以后的刷新也无效。 4、物化视图日志:如果需要进行快速刷新,则需要建立物化视图日志。物化视图日志根据不同物化视图的快速刷新的需要,可以建立为RowID或Primary Key类型的。还可以选择是否包括Sequence、Including New Values以及指定列的列表。 可以指明On PreBuild Table语句将物化视图建立在一个已经存在的表上。这种情况下,物化视图和表必须同名。当删除物化视图时,不会删除同名的表。这种物化视图的查询重写要求参数Query_Rewrite_integerity必须设置为 trusted或者stale_tolerated。 5、物化视图可以进行分区。而且基于分区的物化视图可以支持分区变化跟踪(PCT)。具有这种特性的物化视图,当基表进行了分区维护操作后,仍然可以进行快速刷新操作。对于聚集物化视图,可以在Group by 列表中使用Cube或RollUp,来建立不同等级的聚集物化视图。
xtrabackup : 这个备份工具是挺好的,但是有缺陷,只可以备份innodb;但是我们也需要备份myisam,然后就出来了一个工具:innobackupex 一、innobackupex 备份: 1.1 查看数据目录:
从MySQL5.5开始,MySQL以插件的形式支持半同步复制。如何理解半同步呢?首先我们来看看异步,全同步的概念
MySQL数据库是轻量级、开源数据库的佼佼者,其功能和管理,健壮性与Oracle相比还是有相当的差距。因此有很多功能强大第三方的衍生产品,如percona-toolkit,XtraBackup等等。percona-toolkit是一组高级命令行工具的集合,可以查看当前服务的摘要信息,磁盘检测,分析慢查询日志,查找重复索引,实现表同步等等。这个工具套件对DBA及运维人员着实不可多得。 https://www.percona.com/doc/percona-toolkit/2.1/pt-heartbeat.html https://github.com/percona/percona-toolkit 1、percona-toolkit的主要功能 Verify MySQL replication integrity by checking master and replica data consistency Efficiently archive rows Find duplicate indexes Summarize MySQL servers Analyze queries from logs and tcpdump Collect vital system information when problems occur
实现Exactly Once的一种方法是让下游系统具有幂等处理特性,而在Kafka Stream中,Kafka Producer本身就是“下游”系统,因此如果能让Producer具有幂等处理特性,那就可以让Kafka Stream在一定程度上支持Exactly once语义。 为了实现Producer的幂等语义,Kafka引入了Producer ID(即PID)和Sequence Number。每个新的Producer在初始化的时候会被分配一个唯一的PID,该PID对用户完全透明而不会暴露给用户。
在说Kafka的事务之前,先要说一下Kafka中幂等的实现。幂等和事务是Kafka 0.11.0.0版本引入的两个特性,以此来实现EOS(exactly once semantics,精确一次处理语义)。
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
mysql中可以使用explain关键字来查看sql语句的执行计划。 最左前缀原则主要使用在联合索引中 数据库版本Mysql5.5.53 例如abc联合索引,只有当a或者ab或者abc为条件时才能触发索引,这当然是毋容置疑的,但是我测试了发现ac也是会触发联合索引的,这是为什么呢?
设计一个缓存系统,不得不要考虑的问题就是:缓存穿透、缓存击穿与失效时的雪崩效应。 缓存穿透 缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
redis 4.0 以后开始支持扩展模块,redis-cell 是一个用rust语言编写的基于令牌桶算法的的限流模块,提供原子性的限流功能,并允许突发流量,可以很方便的应用于分布式环境中。 https://github.com/brandur/redis-cell 令牌桶算法的原理是定义一个按一定速率产生token的桶,每次去桶中申请token,若桶中没有足够的token则申请失败,否则成功。在请求不多的情况下,桶中的token基本会饱和,此时若流量激增,并不会马上拒绝请求,所以这种算法允许一定的流量激增。
在Redis中执行Lua脚本有两种方法:eval和evalsha。 http://redisdoc.com/script/eval.html https://redisbook.readthedocs.io/en/latest/feature/scripting.html 1.1 eval# Copy eval 脚本内容 key个数 key列表 参数列表 下面例子使用了key列表和参数列表来为Lua脚本提供更多的灵活性:
在Stream之前,Redis PUB/SUB亦可可实现消息的传递及广播,但消息不支持持久化,不记录消费端状态,并且“Fire and Forgot”,可靠性无法保证。 stream与pub/sub的比较:
redis 4.0 新特性
Redis 4.0在2017年7月发布为GA。包含几个重大改进:更好的复制(PSYNC2),线程DEL / FLUSH,混合RDB + AOF格式,活动内存碎片整理,内存使用和性能改进。目前小版本更新到4.0.6
一、主从数据同步机制
PSYNC2: 新的一种主从复制同步机制。
PSYNC1:2.8~4.0之前版本的同步为PSYNC1
1、psync1因为网络中断或者阻塞导致主从中断,恢复后必须重新到主节点dump一份全量数据同步到从节点。psync2再中断恢复后只需要同步复制延迟的那部分数据。
2、psync1在重启从节点需要重新全量同步数据。psync2只部分同步增量数据。
3、在PSYNC1 当复制为链式复制的时候,如 A>B>C 主节点为A。当A出现问题,C节点不能正常复制B节点的数据。当提升B为主节点,C需要全量同步B的数据。在PSYNC2:PSYNC2解决了链式复制之间的关联性。A出现问题不影响C节点,B提升为主C不需要全量同步。
4、在使用星形复制。如一主两从。A>B , A>C 主节点为A。当A出现问题,B提升为主节点,C 重新指向主节点B。使用同步机制PSYNC2,C节点只做增量同步即可。在使用sentinel故障转移可以较少数据重新同步的延迟时间,避免大redis同步出现的网络带宽占满。
二、命令优化
线程DEL / FLUSH 优化
Redis现在可以在不同的线程中删除后台的key而不会阻塞服务器。 新的UNLINK命令与DEL相同,但是以非阻塞的方式工作。但是在key过期的内部依然使用了DEL。 类似地,为了让整个数据集或单个数据库异步释放,在“FLUSHALL”和“FLUSHDB”中添加了“ASYNC”选项。(手动清除大的key 可以使用unlink,不阻塞)
三、慢日志记录客户端来源IP地址,这个小功能对于故障排查很有用处。
四、混合RDB + AOF格式
混合RDB + AOF格式: 混合的RDB-AOF格式。 如果启用,则在重写AOF文件时使用新格式:重写使用更紧凑和更快的方式来生成RDB格式,并将AOF流附加到文件。 这允许在使用AOF持久性时更快地重写和重新加载。(目前相对于2.8没啥用)
五、新的管理命令
1、MEMORY 能够执行不同类型的内存分析:内存问题的故障排除(使用MEMORY DOCTOR,类似于LATENCY DOCTOR),报告单个键使用的内存量,更深入地报告Redis内存使用情况 。
查看键值 使用 memory MEMORY USAGE key
memory统计分析 MEMORY STATS
MEMORY MALLOC-STATS
MEMORY PURGE
2、SWAPDB 能够完全立即(无延迟)替换同实例下的两个Redis数据库(目前我们业务没啥用)
六、
内存使用和性能改进:
1、Redis现在使用更少的内存来存储相同数量的数据。
2、Redis现在可以对使用的内存进行碎片整理,并逐渐回收空间(这个功能依然是试用阶段,可以通过参数不开启即可)
以上列举功能为4.0的重要更新,也是对我们目前redis大有改善,所列举的功能已经和亚运测试过。业务上还没有预发测试。 更多4.0版本信息 https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
建议:新的边缘业务redis上线使用redis4.0 。先进行预发功能连通测试。一段时间后,根据实际使用情况推进redis4.0更新。
一,Memory
Redis4.0新增的内存管理分析工具 memory command
二,Lazy Free
解决单key大value 删除时导致的短暂阻塞问题 删除大key时,使用unlink进行快速删除 解除关联 后台fork子进程删除
三,Psync2
升级psync1 解决副本集重启 全量同步问题 减少同步数据和时间
稳定版 (5.0) Redis 5.0 是第一个加入流数据类型(stream data type )的版本,sorted sets blocking pop operations, LFU/LRU info in RDB, Cluster manager inside redis-cli, active defragmentation V2, HyperLogLogs improvements and many other improvements. Redis 5 was release as GA in October 2018.
2.3.0 is the latest release. The current stable version is 2.3.0. http://kafka.apache.org/downloads Kafka 2.0.0引入了线程协议的变化。通过遵循下面建议的滚动升级计划,您可以保证在升级期间不会出现停机。
XA是由X/Open组织提出的分布式事务的规范。 XA规范主要定义了(全局)事务管理器(TM)和(局 部)资源管理器(RM)之间的接口。主流的关系型 数据库产品都是实现了XA接口的。 XA接口是双向的系统接口,在事务管理器 (TM)以及一个或多个资源管理器(RM)之 间形成通信桥梁。 XA之所以需要引入事务管理器是因为,在分布 式系统中,从理论上讲两台机器理论上无法达 到一致的状态,需要引入一个单点进行协调。 由全局事务管理器管理和协调的事务,可以跨 越多个资源(如数据库或JMS队列)和进程。 全局事务管理器一般使用 XA 二阶段提交协议 与数据库进行交互。
https://mariadb.com/kb/zh-cn/mariadb-mariadbmysql/ MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。
update一行的时候的时候不是in-place的修改,而是产生一个行的新版本,在新行上修改,最后有点类似copy on write array,在提交的时候切换到新版本。好处是不影响现有数据的读取,一致性好。
第 1 步:阅读数据结构实现 刚开始阅读 Redis 源码的时候, 最好从数据结构的相关文件开始读起, 因为这些文件和 Redis 中的其他部分耦合最少, 并且这些文件所实现的数据结构在大部分算法书上都可以了解到, 所以从这些文件开始读是最轻松的、难度也是最低的。 下表列出了 Redis 源码中, 各个数据结构的实现文件:
系统的物理内存是有限的,而对内存的需求是变化的, 程序的动态性越强,内存管理就越重要,选择合适的内存管理算法会带来明显的性能提升。 比如nginx, 它在每个连接accept后会malloc一块内存,作为整个连接生命周期内的内存池。 当HTTP请求到达的时候,又会malloc一块当前请求阶段的内存池, 因此对malloc的分配速度有一定的依赖关系。(而apache的内存池是有父子关系的,请求阶段的内存池会和连接阶段的使用相同的分配器,如果连接内存池释放则请求阶段的子内存池也会自动释放)。 内存管理可以分为三个层次,自底向上分别是:
“Instant ADD COLUMN”,即“瞬加字段功能” 鹅厂工程师通过扩展MySQL InnoDB的存储格式,可以把原来几个小时才能完成的给表加字段命令,在1秒之内执行完成,更新TB级的表都是毛毛雨,有效地提高了数据库的管理效率,降低运维成本。 随着MySQL新版本的发布,陈福荣和梁飞龙将该特性提交到MySQL 8.0.12
InnoDB引擎对FULLTEXT索引的支持是MySQL5.6新引入的特性,之前只有MyISAM引擎支持FULLTEXT索引。对于FULLTEXT索引的内容可以使用MATCH()…AGAINST语法进行查询。
myisam使用的堆组织表(Heap Organize Table, HOT),没有聚集索引的概念,使用B-tree索引的存储格式,显示都是随机顺序。
innodb表是索引组织表(Index Organized Table, IOT),它的索引则是采用 clustered index 方式,因此主键会按照顺序存储,每次有记录有更新时,会重新整理更新其主键。因此无论是直接从 myisam 表转换过来的,还是后来插入的记录,显示时都会按照主键的顺序。
堆表(heap table)数据插入时时存储位置是随机的,主要是数据库内部块的空闲情况决定,获取数据是按照命中率计算,全表扫表时不见得先插入的数据先查到。
KEYS 的速度非常快,但在一个大的数据库中使用它仍然可能造成性能问题,如果你需要从一个数据集中查找特定的 key ,你最好还是用 Redis 的集合结构(set)来代替。 Keys模糊匹配,请大家在实际运用的时候忽略掉。因为Keys会引发Redis锁,并且增加Redis的CPU占用,情况是很恶劣的 由于执行keys命令,redis会锁定,如果数据庞大的话可能需要几秒或更长,对于生产服务器上锁定几秒这绝对是灾难了 如果有这种需求的话可以自己对键值做索引,比如把各种键值存到不同的set里面,分类建立索引,这样就可以很快的得到数据,但是这样也存在一个明显的缺点,就是浪费宝贵的空间,要知道这可是内存空间啊,所以还是要合理考虑,当然也可以想办法,比如对于有规律的键值,可以存储他们的始末值等等。 2.8版本之后SCAN命令已经可用,允许使用游标从keyspace中检索键。对比KEYS命令,虽然SCAN无法一次性返回所有匹配结果,但是却规避了阻塞系统这个高风险,从而也让一些操作可以放在主节点上执行。 SCAN 命令是一个基于游标的迭代器。SCAN 命令每次被调用之后, 都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。同时,使用SCAN,用户还可以使用keyname模式和count选项对命令进行调整。SCAN相关命令还包括SSCAN 命令、HSCAN 命令和 ZSCAN 命令,分别用于集合、哈希键及有续集等。 另一方面,使用redis的时候一定要注意控制key,对于key的命令要制定一个完善的方案,这样才能对redis里面的数据可控,避免出现没用数据长时间占据数据库这种情况,也可以避免上面说的这种查询键值的操作。
在内存有限的情况下,扩展一部分外存作为虚拟内存,真正的内存只存储当前运行时所用得到信息。这无疑极大地扩充了内存的功能,极大地提高了计算机的并发度。虚拟页式存储管理,则是将进程所需空间划分为多个页面,内存中只存放当前所需页面,其余页面放入外存的管理方式
LRU全称是Least Recently Used,即最近最久未使用的意思。 LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。 1.1.2. 实现 LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。 具体实现如下:
Redis本身仅支持单实例,内存一般最多10~20GB。这无法支撑大型线上业务系统的需求。而且也造成资源的利用率过低——毕竟现在服务器内存动辄100~200GB。 1.1 客户端分片 这种方案将分片工作放在业务程序端,程序代码根据预先设置的路由规则,直接对多个Redis实例进行分布式访问。这样的好处是,不依赖于第三方分布式中间件,实现方法和代码都自己掌控,可随时调整,不用担心踩到坑。 这实际上是一种静态分片技术。Redis实例的增减,都得手工调整分片程序。基于此分片机制的开源产品,现在仍不多见。 这种分片机制的性能比代理式更好(少了一个中间分发环节)。但缺点是升级麻烦,对研发人员的个人依赖性强——需要有较强的程序开发能力做后盾。如果主力程序员离职,可能新的负责人,会选择重写一遍。 所以,这种方式下,可运维性较差。出现故障,定位和解决都得研发和运维配合着解决,故障时间变长。 这种方案,难以进行标准化运维,不太适合中小公司(除非有足够的DevOPS)。 1.2 代理分片 这种方案,将分片工作交给专门的代理程序来做。代理程序接收到来自业务程序的数据请求,根据路由规则,将这些请求分发给正确的Redis实例并返回给业务程序。 这种机制下,一般会选用第三方代理程序(而不是自己研发),因为后端有多个Redis实例,所以这类程序又称为分布式中间件。 这样的好处是,业务程序不用关心后端Redis实例,运维起来也方便。虽然会因此带来些性能损耗,但对于Redis这种内存读写型应用,相对而言是能容忍的。 这是我们推荐的集群实现方案。像基于该机制的开源产品Twemproxy,便是其中代表之一,应用非常广泛。 1.3 Redis Cluster 在这种机制下,没有中心节点(和代理模式的重要不同之处)。所以,一切开心和不开心的事情,都将基于此而展开。 Redis Cluster将所有Key映射到16384个Slot中,集群中每个Redis实例负责一部分,业务程序通过集成的Redis Cluster客户端进行操作。客户端可以向任一实例发出请求,如果所需数据不在该实例中,则该实例引导客户端自动去对应实例读写数据。 Redis Cluster的成员管理(节点名称、IP、端口、状态、角色)等,都通过节点之间两两通讯,定期交换并更新。 由此可见,这是一种非常“重”的方案。已经不是Redis单实例的“简单、可依赖”了。可能这也是延期多年之后,才近期发布的原因之一。 这令人想起一段历史。因为Memcache不支持持久化,所以有人写了一个Membase,后来改名叫Couchbase,说是支持Auto Rebalance,好几年了,至今都没多少家公司在使用。 这是个令人忧心忡忡的方案。为解决仲裁等集群管理的问题,Oracle RAC还会使用存储设备的一块空间。而Redis Cluster,是一种完全的去中心化…… 本方案目前不推荐使用,从了解的情况来看,线上业务的实际应用也并不多见。
当一个服务操作访问不同的数据库资源,又希望对它们的访问具有事务特性时,就需要采用分布式事务来协调所有的事务参与者。 在一个跨服务的分布式事务中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调用的那个服务 X/Open XA 协议 最早的分布式事务模型是 X/Open 国际联盟提出的 X/Open Distributed Transaction Processing(DTP)模型,也就是大家常说的 X/Open XA 协议,简称XA 协议
DTP 模型中包含一个全局事务管理器(TM,Transaction Manager)和多个资源管理器(RM,Resource Manager)。全局事务管理器负责管理全局事务状态与参与的资源,协同资源一起提交或回滚;资源管理器则负责具体的资源操作。
https://raft.github.io/#implementations NewSQL 是对各种新的可扩展/高性能数据库的简称,这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。 NewSQL是指这样一类新式的关系型数据库管理系统,针对OLTP(读-写)工作负载,追求提供和NoSQL系统相同的扩展性能,且仍然保持ACID和SQL等特性(scalable and ACID and (relational and/or sql -access))。 NewSQL一词是由451 Group的分析师Matthew Aslett在研究论文中提出的。它代指对老牌数据库厂商做出挑战的一类新型数据库系统。 NoSQL将改变数据的定义范围。它不再是原始的数据类型,如整数、浮点。数据可能是整个文件。NoSQL可能会吓到DBA,因为他们担心失去他们自己的领域。 NoSQL数据库是非关系的、水平可扩展、分布式并且是开源的。MongoDB的创始人Dwight Merriman表示NoSQL可作为一个Web应用服务器、内容管理器、结构化的事件日志、移动应用程序的服务器端和文件存储的后备存储。 分三类: 新架构 第一类型的NewSQL系统是全新的数据库平台,它们均采取了不同的设计方法。它们大概分两类: (1) 这类数据库工作在一个分布式集群的节点上,其中每个节点拥有一个数据子集。 SQL查询被分成查询片段发送给自己所在的数据的节点上执行。这些数据库可以通过添加额外的节点来线性扩展。现有的这类数据库有: Google Spanner, VoltDB, Clustrix, NuoDB. (2) 这些数据库系统通常有一个单一的主节点的数据源。它们有一组节点用来做事务处理,这些节点接到特定的SQL查询后,会把它所需的所有数据从主节点上取回来后执行SQL查询,再返回结果。 SQL引擎 第二类是高度优化的SQL存储引擎。这些系统提供了MySQL相同的编程接口,但扩展性比内置的引擎InnoDB更好。这类数据库系统有:TokuDB, MemSQL。 透明分片 这类系统提供了分片的中间件层,数据库自动分割在多个节点运行。这类数据库包扩:ScaleBase,dbShards, Scalearc。 NoSQL数据库在以下环境中会体现出明显的优势:
https://github.com/github/gh-ost 2016年8月份,shlomi-noach在GitHub Engineering发文宣布gh-ost开源。gh-ost是什么?一个不依赖触发器实现的在线表结构变更工具.
Hive是一个SQL解析引擎,将SQL语句转译成MR Job,然后再Hadoop平台上运行,达到快速开发的目的。 • Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。本质就是Hadoop的目录/文件,达到了元数据与数据存储分离的目的 • Hive本身不存储数据,它完全依赖HDFS和MapReduce。 • Hive的内容是读多写少,不支持对数据的改写和删除 • Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性: – 列分隔符 – 行分隔符 – 读取文件数据的方法 1. 查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
Nathan Marz的大作Big Data: Principles and best practices of scalable real-time data systems介绍了Labmda Architecture的概念,用于在大数据架构中,如何让real-time与batch job更好地结合起来,以达成对大数据的实时处理。
由于索引是采用 B 树结构存储的,所以对应的索引项并不会被删除,经过一段时间的增删改操作后,数据库中就会出现大量的存储碎片, 这和磁盘碎片、内存碎片产生原理是类似的,这些存储碎片不仅占用了存储空间,而且降低了数据库运行的速度。如果发现索引中存在过多的存储碎片的话就要进行 “碎片整理”了,最方便的“碎片整理” 手段就是重建索引, 重建索引会将先前创建的索引删除然后重新创建索引,主流数据库管理系统都提供了重建索引的功能,比如 REINDEX、REBUILD 等,如果使用的数据库管理系统没有提供重建索引的功能,可以首先用DROP INDEX语句删除索引,然后用ALTER TABLE 语句重新创建索引。
一、Phoenix 介绍: Phoenix提供了类标准Sql的方式进行操作Hbase的数据。 Phoenix 操作hbase有两种方式,创建表,创建视图。 区别如下: 创建表的话,就可以对HBase进行插入,查询,删除操作。 视图的话,一般就只可以进行查询操作。 虽然看起来表的功能比视图更强大一些。但就像是mysql等关系型数据库一样,删除视图操作不会影响原始表的结构。同时Phoenix的视图也支持创建二级索引相关的。 因为使用phoenix 创建表后,会自动和hbase建立关联映射。当你使用phoenix删除和hbase之间的关系时,就会将hbase中的表也删掉了,并将与之关联的索引表一并删除。 二、phoenix 常用命令 温馨提示:笔者开启了Kerberos安全认证机制,因此第一步是先对机器进行Kerberos认证;如果开启了用户访问hbase表权限相关的,通过phoenix查询hbase中的表需要开通该用户拥有访问hbase 系统表相关的权限。 注:phoenix会将没有用双引号的表名列名等转化成大写,所以如果表名跟列名为小写需用双引号括起来。 2.1 进入phoenix 命令行 [root@hdp39 ~]# cd /usr/hdp/2.5.3.0-37/phoenix/bin [root@hdp39 bin]# ./sqlline.py hdp39,hdp40,hdp41:2181 (集群采用的安全模式为kerberos,因而执行这条命令前进行kinit的用户必须拥有操作Hbase相关的权限) 2.2、help 查看内置命令 2.3、!tables List all the tables in the database
Master High Availability又称MHA,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的软件。MySQL故障切换过程中,MHA能够做到在30秒之内自动完成数据库的故障切换操作,并在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
Xtrabackup是一个对InnoDB做数据备份的工具,支持在线热备份(备份时不影响数据读写),是商业备份工具InnoDB Hotbackup的一个很好的替代品。它能对InnoDB和XtraDB存储引擎的数据库非阻塞地备份(对于MyISAM的备份同样需要加表锁)。XtraBackup支持所有的Percona Server、MySQL、MariaDB和Drizzle。 xtrabackup有两个主要的工具:xtrabackup、innobackupex
https://dev.mysql.com/doc/refman/5.7/en/spatial-function-reference.html
1.理解下MySql GIS空间数据字段类型
 1.一个点:POINT(15 20)
请注意,点坐标无指定分隔逗号。
2.一根线条,例如有四点组成的线条: LINESTRING(0 0,10 10,20 25,50 60)
请注意,点坐标对用逗号分隔。
3.一个多边形,例如一个外环和一个内环组成的多边形:POLYGON((0 0,10 0,10 10 10 0 0),(5 5 7 5 7 7 5 7 5 5))
4.多点集合,例如三个点的值:MultIPOINT(0 0,20 20,60 60)
5.多线集合,例如两根线条的集合:MULTILINESTRING((10 10,20 20),(15 15,30 15))
6.多边形集合,例如两个多边形值的集合:MULTIPOLYGON(((0 0,10 0,10 10 10,0 0)),((5 5 7 5 7 7 5 7 5 5)))
7.集合,例如两个点和一条线段的集合:GeometryCollection(POINT(10 10),POINT(30 30),LINESTRING(15 15,20 20))
2.添加测试数据
表t_pot 存储点信息,t_polygon存储几何信息
t_pot 创建语句(由于这里使用的是mysql 5.7的数据库,所以用InnoDB数据引擎,较低版本的数据库需要采用MyISAM )
CREATE TABLE
1.一个点:POINT(15 20)
请注意,点坐标无指定分隔逗号。
2.一根线条,例如有四点组成的线条: LINESTRING(0 0,10 10,20 25,50 60)
请注意,点坐标对用逗号分隔。
3.一个多边形,例如一个外环和一个内环组成的多边形:POLYGON((0 0,10 0,10 10 10 0 0),(5 5 7 5 7 7 5 7 5 5))
4.多点集合,例如三个点的值:MultIPOINT(0 0,20 20,60 60)
5.多线集合,例如两根线条的集合:MULTILINESTRING((10 10,20 20),(15 15,30 15))
6.多边形集合,例如两个多边形值的集合:MULTIPOLYGON(((0 0,10 0,10 10 10,0 0)),((5 5 7 5 7 7 5 7 5 5)))
7.集合,例如两个点和一条线段的集合:GeometryCollection(POINT(10 10),POINT(30 30),LINESTRING(15 15,20 20))
2.添加测试数据
表t_pot 存储点信息,t_polygon存储几何信息
t_pot 创建语句(由于这里使用的是mysql 5.7的数据库,所以用InnoDB数据引擎,较低版本的数据库需要采用MyISAM )
CREATE TABLE t_pot (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(255) DEFAULT NULL,
pot point DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
往t_pot表中添加测试数据
INSERT INTO t_pot VALUES (‘1’, ‘A’, GeomFromText(‘POINT(0 0)’));
INSERT INTO t_pot VALUES (‘2’, ‘B’, GeomFromText(‘POINT(0 2)’));
INSERT INTO t_pot VALUES (‘3’, ‘C’, GeomFromText(‘POINT(2 0)’));
INSERT INTO t_pot VALUES (‘4’, ‘D’, GeomFromText(‘POINT(2 2)’));
t_polygon创建语句
CREATE TABLE t_polygon (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(255) DEFAULT NULL,
pgn polygon DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
往t_polygon表中添加测试数据
INSERT INTO t_polygon VALUES (‘1’, ‘ABCD’, GeomFromText(‘POLYGON((0 0, 2 0, 2 2, 0 2, 0 0))’));
INSERT INTO t_polygon VALUES (‘2’, ‘AEGF’, GeomFromText(‘POLYGON((0 0, 4 0, 4 4, 0 4, 0 0))’));
INSERT INTO t_polygon VALUES (‘3’, ‘CEGFBD’, GeomFromText(‘POLYGON((0 2, 0 4, 4 4, 4 0, 2 0, 2 2, 0 2))’));
INSERT INTO t_polygon VALUES (‘4’, ‘AHJIK’, GeomFromText(‘POLYGON((0 0, 0 6, 6 6, 6 0, 0 0), (2 2, 4 4, 4 2, 2 2))’));
INSERT INTO t_polygon VALUES (‘5’, ‘DGK’, GeomFromText(‘POLYGON((2 2, 4 4, 4 2, 2 2))’));
INSERT INTO t_polygon VALUES (‘6’, ‘GKJ’, GeomFromText(‘POLYGON((4 4, 4 2, 6 6, 4 4))’));
INSERT INTO t_polygon VALUES (‘7’, ‘ADF’, GeomFromText(‘POLYGON((0 0, 2 2, 4 0, 0 0))’));
INSERT INTO t_polygon VALUES (‘8’, ‘LDK’, GeomFromText(‘POLYGON((1 1, 2 2, 4 2, 1 1))’));
t_pot表中的点坐标数据没有什么好解释的,下面对t_polygon数据进行说明
下面是表中对应的坐标点位置:
ABDC:POLYGON((0 0, 2 0, 2 2, 0 2, 0 0)) 面积为4的正方形
AEGF:POLYGON((0 0, 4 0, 4 4, 0 4, 0 0)) 面积为16的正方形
CEGFBD:POLYGON((0 2, 0 4, 4 4, 4 0, 2 0, 2 2, 0 2)) 面积为16的正方形 - 面积为4的正方形
DGK:POLYGON((2 2, 4 4, 4 2, 2 2))面积为2的直角等腰三角形
AHJIK:POLYGON((0 0, 0 6, 6 6, 6 0, 0 0), (2 2, 4 4, 4 2, 2 2)) 面积为36的正方形 - 面积为2的三角形DGK
GKJ :POLYGON((4 4, 4 2, 6 6, 4 4)) 面积为2的三角形
ADF :POLYGON((0 0, 2 2, 4 0, 0 0))面积为4的等腰三角形
LDK:POLYGON((1 1, 2 2, 4 2, 1 1))面积为1的三角形
3.测试SQL语句
ST_GEOMFROMTEXT文本数据转成空间数据,所以下面看着就乱码了(Navicate中是不乱码)
mysql> SELECT ST_GEOMFROMTEXT(“POINT(1 2)”);
+——————————-+
| ST_GEOMFROMTEXT(“POINT(1 2)”) |
+——————————-+
| ð? @ |
+——————————-+
1 row in set (0.00 sec)
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
SDE的全称是spatial database engine(空间数据引擎),之所以称之为引擎,是因为所有的空间数据IO都需要通过它来管理。它属于中间件技术,位于客户端和数据库之间,其本身并不能够存储空间数据(存储是由数据库完成),它的作用可以理解为将数据库中的对象(表、视图等)抽象成上层GIS应用可以认识的概念,例如feature、feature class等。 ARCSDE保存了一系统数据库对象,用于管理空间信息,这些对象统称为资料档案库(Repository)。以基于ORACLE数据库的ARCSDE为例,资料档案库包含SDE用户下的数据字典表、存储过程、以及数个.dll文件。数据字典表,用以存储要素类、要素类字段、要素类投影、要素类范围等元数据信息,而存储过程和.dll用于实现对空间数据的GIS运算和操作,例如用于计算polygon周长的方法。 文已经说过,ARCSDE并不能够存储空间数据,数据都是存储在RDBMS(关系型数据库)(实际上并不限于RDBMS,ARCSDE也支持非关系型数据库和HADOOP。但现在只谈它与ORACLE SPATIAL的关系,因此,此处说RDBMS)中。以矢量数据为例,它既可以以二近制形式存储为一个BLOB对象,也可以使用RDBMS或ARCSDE提供的矢量数据类型。
创建kafka topic 查看所有topic列表 查看指定topic信息 控制台向topic生产数据 控制台消费topic的数据 查看topic某分区偏移量最大(小)值 增加topic分区数 删除topic,慎用,只会删除zookeeper中的元数据,消息文件须手动删除 查看topic消费进度
Apache Calcite是面向Hadoop新的查询引擎,它提供了标准的SQL语言、多种查询优化和连接各种数据源的能力,除此之外,Calcite还提供了OLAP和流处理的查询引擎。正是有了这些诸多特性,Calcite项目在Hadoop中越来越引入注目,并被众多项目集成。
Canel,Databus,Puma等,这些都是需要部署server和client的。其中server端是由这些工具实现,配置了就可以读binlog,而client端是需要我们动手编写程序的,远没有达到我即插即用的期望和懒人的标准。 再来看看flume,只需要写一个配置文件,就可以完成数据同步的操作。官网:http://flume.apache.org/FlumeUserGuide.html#flume-sources。它的数据源默认是没有读取binlog日志实现的,也没有读数据库表的官方实现,只能用开源的自定义source:https://github.com/keedio/flume-ng-sql-source 同步的格式 原作者的插件flume-ng-sql-source只支持csv的格式,如果开始同步之后,数据库表需要增减字段,则会给开发者造成很大的困扰。所以我添加了一个分支版本,用来将数据以JSON的格式,同步到kafka,字段语义更加清晰。 sql-json插件包下载地址:https://github.com/yucy/flume-ng-sql-source-json/releases/download/1.0/flume-ng-sql-source-json-1.0.jar 将此jar包下载之后,和相应的数据库驱动包,一起放到flume的lib目录之下即可。 处理机制 flume-ng-sql-source在【status.file.name】文件中记录读取数据库表的偏移量,进程重启后,可以接着上次的进度,继续增量读表。 启动说明 说明:启动命令里的【YYYYMM=201711】,会传入到flume.properties里面,替换${YYYYMM} [test@localhost ~]$ YYYYMM=201711 bin/flume-ng agent -c conf -f conf/flume.properties -n sync & -c:表示配置文件的目录,在此我们配置了flume-env.sh,也在conf目录下; -f:指定配置文件,这个配置文件必须在全局选项的–conf参数定义的目录下,就是说这个配置文件要在前面配置的conf目录下面; -n:表示要启动的agent的名称,也就是我们flume.properties配置文件里面,配置项的前缀,这里我们配的前缀是【sync】; flume的配置说明 flume-env.sh # 配置JVM堆内存和java运行参数,配置-DpropertiesImplementation参数是为了在flume.properties配置文件中使用环境变量 export JAVA_OPTS=”-Xms512m -Xmx512m -Dcom.sun.management.jmxremote -DpropertiesImplementation=org.apache.flume.node.EnvVarResolverProperties” 关于propertiesImplementation参数的官方说明:http://flume.apache.org/FlumeUserGuide.html#using-environment-variables-in-configuration-files flume.properties canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
https://github.com/zendesk/maxwell 组件下载地址:https://github.com/zendesk/maxwell/releases/download/v1.10.7/maxwell-1.10.7.tar.gz 给mysql授权(只针对于maxwell库的操作) 其中user01为数据库用户名 666666为数据库密码 GRANT ALL on maxwell.* to ‘user01’@’%’ identified by ‘666666’; GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on . to ‘user01’@’%’; 执行maxwell命令行(注:maxwell默认是把监听的mysql的binlog日志发送到kafka的主题叫maxwell的topic上的)
一、Flume简介 flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。 但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.9.4. 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以 及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
内存管理可以分为三个层次,自底向上分别是: 操作系统内核的内存管理 glibc层使用系统调用维护的内存管理算法 应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化, 比如使用引用计数std::shared_ptr,apache的内存池方式等等。 应具有以下特性: 额外的空间损耗尽量少 分配速度尽可能快 尽量避免内存碎片 缓存本地化友好 通用性,兼容性,可移植性,易调试 目前大部分服务端程序使用glibc提供的malloc/free系列函数,而glibc使用的ptmalloc2在性能上远远弱后于google的tcmalloc和facebook的jemalloc。 而且后两者只需要使用LD_PRELOAD环境变量启动程序即可,甚至并不需要重新编译。 glibc ptmalloc2 ptmalloc2即是我们当前使用的glibc malloc版本。 ptmalloc原理 x86_64 下 Linux 进程的默认地址空间, 对 heap 的操作, 操作系统提供了brk()系统调用,设置了Heap的上边界; 对 mmap 映射区域的操作,操作系 统 供了 mmap()和 munmap()函数。 因为系统调用的代价很高,不可能每次申请内存都从内核分配空间,尤其是对于小内存分配。 而且因为mmap的区域容易被munmap释放,所以一般大内存采用mmap(),小内存使用brk()。 多线程支持 Ptmalloc2有一个主分配区(main arena), 有多个非主分配区。 非主分配区只能使用mmap向操作系统批发申请HEAP_MAX_SIZE(64位系统为64MB)大小的虚拟内存。 当某个线程调用malloc的时候,会先查看线程私有变量中是否已经存在一个分配区,如果存在则尝试加锁,如果加锁失败则遍历arena链表试图获取一个没加锁的arena, 如果依然获取不到则创建一个新的非主分配区。 free()的时候也要获取锁。分配小块内存容易产生碎片,ptmalloc在整理合并的时候也要对arena做加锁操作。在线程多的时候,锁的开销就会增大。 ptmalloc内存管理 用户请求分配的内存在ptmalloc中使用chunk表示, 每个chunk至少需要8个字节额外的开销。 用户free掉的内存不会马上归还操作系统,ptmalloc会统一管理heap和mmap区域的空闲chunk,避免了频繁的系统调用。 ptmalloc 将相似大小的 chunk 用双向链表链接起来, 这样的一个链表被称为一个 bin。Ptmalloc 一共 维护了 128 个 bin,并使用一个数组来存储这些 bin 数组中的第一个为 unsorted bin, 数组中从 2 开始编号的前 64 个 bin 称为 small bins, 同一个small bin中的chunk具有相同的大小。small bins后面的bin被称作large bins。
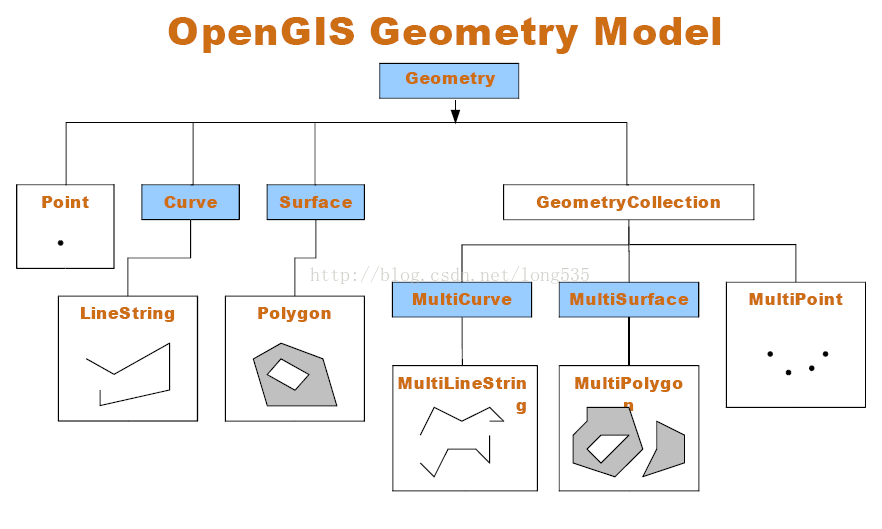
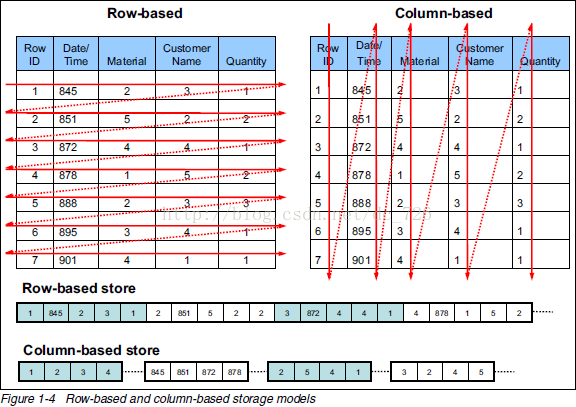
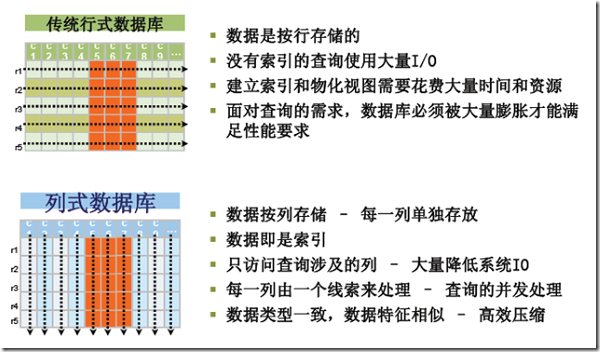
列式存储(Column-based)是相对于传统关系型数据库的行式存储(Row-based)来说的。简单来说两者的区别就是如何组织表。
将表放入存储系统中有两种方法,而我们绝大部分是采用行存储的。行存储法是将各行放入连续的物理位置,这很像传统的记录和文件系统。列存储法是将数据按照列存储到数据库中,与行存储类似,
MySQL Proxy处于客户端应用程序和MySQL服务器之间,通过截断、改变并转发客户端和后端数据库之间的通信来实现其功能,这和WinGate之类的网络代理服务器的基本思想是一样的。代理服务器是和TCP/IP协议打交道,而要理解MySQL Proxy的工作机制,同样要清楚MySQL客户端和服务器之间的通信协议,MySQL Protocol包括认证和查询两个基本过程: 认证过程包括: 客户端向服务器发起连接请求 服务器向客户端发送握手信息 客户端向服务器发送认证请求 服务器向客户端发送认证结果 如果认证通过,则进入查询过程: 客户端向服务器发起查询请求 服务器向客户端返回查询结果 当然,这只是一个粗略的描述,每个过程中发送的包都是有固定格式的,想详细了解MySQL Protocol的同学,可以去这里看看。MySQL Proxy要做的,就是介入协议的各个过程。首先MySQL Proxy以服务器的身份接受客户端请求,根据配置对这些请求进行分析处理,然后以客户端的身份转发给相应的后端数据库服务器,再接受服务器的信息,返回给客户端。所以MySQL Proxy需要同时实现客户端和服务器的协议。 由于要对客户端发送过来的SQL语句进行分析,还需要包含一个SQL解析器。可以说MySQL Proxy相当于一个轻量级的MySQL了,实际上,MySQL Proxy的admin server是可以接受SQL来查询状态信息的。 MySQL Proxy通过lua脚本来控制连接转发的机制。主要的函数都是配合MySQL Protocol各个过程的,这一点从函数名上就能看出来: connect_server() read_handshake() read_auth() read_auth_result() read_query() read_query_result() 至于为什么采用lua脚本语言,我想这是因为MySQL Proxy中采用了wormhole存储引擎的关系吧,这个虫洞存储引擎很有意思,数据的存储格式就是一段lua脚本 通过这几个入口函数我们可以控制mysql-proxy的一些行为。
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control) (注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control)。MVCC最大的好处,相信也是耳熟能详:读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能,这也是为什么现阶段,几乎所有的RDBMS,都支持了MVCC。
LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。 那么为什么这是一个好的方法呢?这个问题的本质还是磁盘随机操作慢,顺序读写快的老问题。这二种操作存在巨大的差距,无论是磁盘还是SSD。 顺序读写磁盘(不管是SATA还是SSD)快于随机读写主存,而且快至少三个数量级。这说明我们要避免随机读写,最好设计成顺序读写。
隐式类型转换有无法命中索引的风险,在高并发、大数据量的情况下,命不中索引带来的后果非常严重。将数据库拖死,继而整个系统崩溃,对于大规模系统损失惨重。
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
1.什么时候写binlog 在说明什么时候写binlog前,先简单介绍下binlog的用途。binlog是二进制日志文件,用于记录mysql的数据更新或者潜在更新(比如DELETE语句执行删除而实际并没有符合条件的数据),在mysql主从复制中就是依靠的binlog。在mysql中开启binlog需要设置my.cnf中的log_bin参数,另外也可以通过binlog_do_db 指定要记录binlog的数据库和binlog_ignore_db指定不记录binlog的数据库。对运行中的mysql要启用binlog可以通过命令SET SQL_LOG_BIN=1来设置。设置完成,我们就可以来测试binlog了。
c++ https://github.com/hyrise/sql-parser http://torpedro.github.io/tech/c++/sql/parser/2016/02/27/c++-sql-parser.html https://github.com/hyrise/sql-parser/tree/master/example http://www.sqlparser.com/sql-parser-c.php jave https://github.com/JSQLParser/JSqlParser go https://github.com/xwb1989/sqlparser GSP(全称General SQL Parser)。他是一款专业的SQL引擎,适用于各种数据库。 http://www.sqlparser.com/ 一、检查语法
mysql -uroot -p1 查询是否支持binlog, 如下OFF代表不支持 mysql> show variables like ‘log_bin’; +—————+——-+ | Variable_name | Value | +—————+——-+ | log_bin | OFF | +—————+——-+ 1 row in set (0.00 sec) .查看my.cnf路径 mysql –help –verbose | grep my.cnf /etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf 默认mac 没有my.cnf 不要修改/usr/local/Cellar/mysql/5.7.13/support-files/my-default.cnf 否则会导致mysqld启动失败,各种权限错误 新建文件my.cnf并添加如下内容
log-bin = mysql-bin #开启binlog binlog-format = ROW #选择row模式 server_id = 1 #配置mysql replication需要定义,不能和canal的slaveId重复 出现如下错误: eror: Found option without preceding group in config file: /Users/gukey/.my.cnf at line: 1 说明不符合格式要求,修改my.cnf [client] socket=/usr/local/var/mysql/mysql.sock [mysqld] socket=/usr/local/var/mysql/mysql.sock
log-bin = mysql-bin #开启binlog binlog-format = ROW #选择row模式 server_id = 1
$/usr/local/Cellar/mysql/5.7.13/support-files/mysql.server start Starting MySQL . ERROR! The server quit without updating PID file (/usr/local/var/mysql/bogon.pid).
目录 1 交互过程 1.1 握手认证阶段 1.2 命令执行阶段 2 基本类型 2.1 整型值 2.2 字符串(以NULL结尾)(Null-Terminated String) 2.3 二进制数据(长度编码)(Length Coded Binary) 2.4 字符串(长度编码)(Length Coded String) 3 报文结构 3.1 消息头 3.1.1 报文长度 3.1.2 序号 3.2 消息体 4 报文类型 4.1 登陆认证交互报文 4.1.1 握手初始化报文(服务器 -> 客户端) 4.1.2 登陆认证报文(客户端 -> 服务器) 4.2 客户端命令请求报文(客户端 -> 服务器) 4.2.1 COM_QUIT 消息报文 4.2.2 COM_INIT_DB 消息报文 4.2.3 COM_QUERY 消息报文 4.2.4 COM_FIELD_LIST 消息报文 4.2.5 COM_CREATE_DB 消息报文 4.2.6 COM_DROP_DB 消息报文 4.2.7 COM_REFRESH 消息报文 4.2.8 COM_SHUTDOWN 消息报文 4.2.9 COM_STATISTICS 消息报文 4.2.10 COM_PROCESS_INFO 消息报文 4.2.11 COM_PROCESS_KILL 消息报文 4.2.12 COM_DEBUG 消息报文 4.2.13 COM_PING 消息报文 4.2.14 COM_CHANGE_USER 消息报文 4.2.15 COM_BINLOG_DUMP 消息报文 4.2.16 COM_TABLE_DUMP 消息报文 4.2.17 COM_REGISTER_SLAVE 消息报文 4.2.18 COM_PREPARE 消息报文 4.2.19 COM_EXECUTE 消息报文 4.2.20 COM_LONG_DATA 消息报文 4.2.21 COM_CLOSE_STMT 消息报文 4.2.22 COM_RESET_STMT 消息报文 4.2.23 COM_SET_OPTION 消息报文 4.2.24 COM_FETCH_STMT 消息报文 4.3 服务器响应报文(服务器 -> 客户端) 4.3.1 OK 响应报文 4.3.2 Error 响应报文 4.3.3 Result Set 消息 4.3.4 Result Set Header 结构 4.3.5 Field 结构 4.3.6 EOF 结构 4.3.7 Row Data 结构 4.3.8 Row Data 结构(二进制数据) 4.3.9 PREPARE_OK 响应报文(Prepared Statement) 4.3.10 Parameter 响应报文(Prepared Statement) 5 参考资料 1 交互过程 MySQL客户端与服务器的交互主要分为两个阶段:握手认证阶段和命令执行阶段。
数据库中间件的核心目的之一就是尽可能透明的线性扩展数据库能力。其主要功能介绍参考(http://www.onexsoft.com/zh/oneproxy.html)。 但是透明只是相对的,下面就简要叙述OneProxy的每个功能点及其限制。
在mysql工作中接触最多的就是mysql replication,mysql在复制方面还是会有一些常规问题,比如主库宕机或者从库宕机有可能会导致复制中断,通常需要进行人为修复,或者很多时候需要把一个从库提升为主库,但对从库和主库的数据一致性不能保证一样。这种情况下就需要使用percona-toolkit工具的pt-table-checksum组件来检查主从数据的一致性;如果发现不一致的数据,可以通过pt-table-sync修复;还可以通过pt-heartbeat监控主从复制延迟。当然如果数据量小,slave只是当做一个备份使用,那么出现数据不一致完全可以重做,或者通过其他方法解决。如果数据量非常大,重做就是非常蛋碎的一件事情了。比如说,线上数据库做了主从同步环境,数据库在进行了迁移后,需要对mysql迁移(Replication)后的数据一致性进行校验,但又不能对生产环境使用造成影响,pt-table-checksum成为了绝佳也是唯一的检查工具。
需求缘起 大部分互联网的业务都是“读多写少”的场景,数据库层面,读性能往往成为瓶颈。业界通常采用“一主多从,读写分离,冗余多个读库”的数据库架构来提升数据库的读性能。 这种架构的一个潜在缺点是,业务方有可能读取到并不是最新的旧数据: (1)系统先对DB-master进行了一个写操作,写主库 (2)很短的时间内并发进行了一个读操作,读从库,此时主从同步没有完成,故读取到了一个旧数据 (3)主从同步完成 有没有办法解决或者缓解这类“由于主从延时导致读取到旧数据”的问题呢,这是本文要集中讨论的问题。
原来的libmysql用的好好的,为什么还要搞一个mysqlnd出来呢? 原因一: license问题 libmysql是MYSQL AB公司开发的,现在已经是Oracle集团所属的了,它使用MYSQL license发布。 This ultimately led to MySQL support being disabled by default in PHP mysqlnd 是php的一部分,使用PHP license发布。 从此 licensing 的问题就算是解决了。 原因二:编译问题 使用libmysql的时候,如果要正常编译php,必须首先安装好mysql。 如果是单纯的一台WEB服务器,装个mysql似乎有点浪费了。 mysqlnd的话,就不必安装mysql,直接可用。 原因三:性能问题 由于mysqlnd是一个php扩展,使用了php memory management system,在内存使用方面效率相当高。 举个例子: 使用libmysql的时候,mysql结果集中的每一行都在内存中储存了二次 ! 使用mysqlnd,结果集只会储存一次。 而且它还服从于php.ini中memory_limit的设置。 Using MySQL Native Driver leads to comparable or better performance than using MySQL Client Library。 mysqlnd的新特性 1 改进的persistent connection。 2 特殊函数 mysqli_fetch_all()
https://downloads.mysql.com/archives/proxy/ mysql-proxy是官方提供的mysql中间件产品可以实现负载平衡,读写分离,failover等,但其不支持大数据量的分库分表且性能较差。下面介绍几款能代替其的mysql开源中间件产品,Atlas,cobar,tddl,让我们看看它们各自有些什么优点和新特性吧。
https://dev.mysql.com/doc/refman/8.0/en/index-hints.html 1,为什么引入Hint? Hint是Oracle数据库中很有特色的一个功能,是很多DBA优化中经常采用的一个手段。那为什么Oracle会考虑引入优化器呢?基于代价的优化器是很聪明的,在绝大多数情况下它会选择正确的优化器,减轻DBA的负担。 但有时它也聪明反被聪明误,选择了很差的执行计划,使某个语句的执行变得奇慢无比。此时就需要DBA进行人为的干预,告诉优化器使用指定的存取路径或连接类型生成执行计划,从而使语句高效地运行。Hint就是Oracle提供的一种机制,用来告诉优化器按照告诉它的方式生成执行计划。 2,不要过分依赖Hint 当遇到SQL执行计划不好的情况,应优先考虑统计信息等问题,而不是直接加Hint了事。如果统计信息无误,应该考虑物理结构是否合理,即没有合适的索引。只有在最后仍然不能SQL按优化的执行计划执行时,才考虑Hint。 毕竟使用Hint,需要应用系统修改代码,Hint只能解决一条SQL的问题,并且由于数据分布的变化或其他原因(如索引更名)等,会导致SQL再次出现性能问题。 3,Hint的弊端 Hint是比较”暴力”的一种解决方式,不是很优雅。需要开发人员手工修改代码。 Hint不会去适应新的变化。比如数据结构、数据规模发生了重大变化,但使用Hint的语句是感知变化并产生更优的执行计划。 Hint随着数据库版本的变化,可能会有一些差异、甚至废弃的情况。此时,语句本身是无感知的,必须人工测试并修正。 4Hint与注释关系 提示是Oracle为了不破坏和其他数据库引擎之间对SQL语句的兼容性而提供的一种扩展功能。Oracle决定把提示作为一种特殊的注释来添加。它的特殊性表现在提示必须紧跟着DELETE、INSERT、UPDATE或MERGE关键字。 换句话说,提示不能像普通注释那样在SQL语句中随处添加。且在注释分隔符之后的第一个字符必须是加号。在后面的用法部分,会详细说明。 5Hint功能 Hint提供的功能非常丰富,可以很灵活地调整语句的执行过程。通过Hint,我们可以调整: 优化器类型 优化器优化目标 数据读取方式(访问路径) 查询转换类型 表间关联的顺序 表间关联的类型 并行特性 其他特性 二、Hint用法 1语法 {delete|insert|select|update}/+hint[text][hint[text]]/ {delete|insert|select|update}–+hint[text][hint[text]]– 1)关键字说明 DELETE、INSERT、SELECT和UPDATE是标识一个语句块开始的关键字,包含提示的注释只能出现在这些关键字的后面,否则提示无效。 “+”号表示该注释是一个提示,该加号必须立即跟在”/*“的后面,中间不能有空格。 hint是下面介绍的具体提示之一,如果包含多个提示,则每个提示之间需要用一个或多个空格隔开。 text是其它说明hint的注释性文本 2)提示中的错误 提示中的语法错误不会报错,如果解析器不能解析它,就会把它看做一个普通注释处理。这也是容易造成困惑的一点,使用的Hint到底是否起效?可以采用一些手段,检查提示的有效性。需要注意的是,那些语法正确但引用对象错误的提示是不会被报告的。 explain plan + dbms_xplan 使用dbms_xplan输出中的note选项。 10132事件 在10g中,这个事件产生的输出文档的末尾有一部分内容专门讲提示。通过它可以检查两个方面:一是每个用到的提示都会被列出来。如果漏掉了哪个,就说明这个提示没有被识别;二是检查是否有一些信息指明了出现提示错误(如果出错,err值将大于0)。 3)提示中的对象
1.简介 RocksDB项目起源于Facebook的一个实验项目,该项目旨在开发一个与快速存储器(尤其是闪存)存储数据性能相当的数据库软件,以应对高负载服务。 这是一个c++库,可用于存储键和值,可以是任意大小的字节流。它支持原子读和写。 RocksDB具有高度灵活的配置功能,可以通过配置使其运行在各种各样的生产环境,包括纯内存,Flash,硬盘或HDFS。它支持各种压缩算法,并提供了便捷的生产环境维护和调试工具。 RocksDB借鉴了开源项目LevelDB的重要代码和Apache HBase项目的重要思想。最初的代码来源于开源项目leveldb 1.5分叉。它借鉴了了Facebook的代码和思想。
mysql、zookeeper、redis和elasticsearch主从同步机制。
redis是目前最流行的缓存系统,因其丰富的数据结构和良好的性能表现,被各大公司广泛使用。尽管redis性能极佳,但若不注意使用方法,极容易出现慢查询,慢查询多了或者一个20s的慢查询会导致操作队列(redis是单进程)堵塞,最终引起雪崩甚至整个服务不可用。对于慢查询语句,redis提供了相关的配置和命令。 配置有两个:slowlog-log-slower-than 和 slowlog-max-len。slowlog-log-slower-than是指当命令执行时间(不包括排队时间)超过该时间时会被记录下来,单位为微秒,比如通过下面的命令,就可以记录执行时长超过20ms的命令了。
和MySQL主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。 1 全量同步 Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下: 1)从服务器连接主服务器,发送SYNC命令; 2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令; 3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令; 4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照; 5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令; 6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令; 完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。 2 增量同步 Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
3 Redis主从同步策略 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
4 注意点 如果多个Slave断线了,需要重启的时候,因为只要Slave启动,就会发送sync请求和主机全量同步,当多个同时出现的时候,可能会导致Master IO剧增宕机。
一、redis replication概括 1、主从架构的核心原理 当启动一个slave node的时候,它会发送一个PSYNC命令给master node 如果这是slave node重新连接master node,那么master node仅仅会复制给slave部分缺少的数据; 如果是slave node第一次连接master node,那么会触发一次full resynchronization(全量复制) 开始full resynchronization的时候,master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。RDB文件生成完毕之后,master会将这个RDB发送给slave,slave会先写入本地磁盘,然后再从本地磁盘加载到内存中。然后master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。 slave node如果跟master node有网络故障,断开了连接,会自动重连。master如果发现有多个slave node都来重新连接,仅仅会启动一个rdb save操作,用一份数据服务所有slave node。
redis的介绍: Redis的主从复制功能非常强大,一个master可以拥有多个slave,而一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构。下面是关于redis主从复制的一些特点: 1.master可以有多个slave 2.除了多个slave连到相同的master外,slave也可以连接其他slave形成图状结构 3.主从复制不会阻塞master。也就是说当一个或多个slave与master进行初次同步数据时,master可以继续处理client发来的请求。相反slave在初次同步数据时则会阻塞不能处理client的请求。 4.主从复制可以用来提高系统的可伸缩性,我们可以用多个slave 专门用于client的读请求,比如sort操作可以使用slave来处理。也可以用来做简单的数据冗余 5.可以在master禁用数据持久化,只需要注释掉master 配置文件中的所有save配置,然后只在slave上配置数据持久化。
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度,现在已被LiveJournal、hatena、Facebook、Vox、LiveJournal等公司所使用。
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。 Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存多种数据结构,此外单个value的最大限制是1GB,不像 memcached只能保存1MB的数据,因此Redis可以用来实现很多有用的功能,比方说用他的List来做FIFO双向链表,实现一个轻量级的高性 能消息队列服务,用他的Set可以做高性能的tag系统等等。另外Redis也可以对存入的Key-Value设置expire时间,因此也可以被当作一 个功能加强版的memcached来用。 Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
MySQL中的日志包括:错误日志、二进制日志、通用查询日志、慢查询日志等等。这里主要介绍下比较常用的两个功能:通用查询日志和慢查询日志。
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案。实际上这意味着你可以使用Sentinel模式创建一个可以不用人为干预而应对各种故障的Redis部署。
十年前,谷歌发表了 “BigTable” 的论文,论文中很多很酷的方面之一就是它所使用的文件组织方式,这个方法更一般的名字叫 Log Structured-Merge Tree。
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。 在关系数据库系统里,索引[1] 是检索数据最有效率的方式,。但对于搜索引擎,它并不能满足其特殊要求: 1)海量数据:搜索引擎面对的是海量数据,像Google,百度这样大型的商业搜索引擎索引都是亿级甚至百亿级的网页数量 ,面对如此海量数据 ,使得数据库系统很难有效的管理。 2)数据操作简单:搜索引擎使用的数据操作简单 ,一般而言 ,只需要增、 删、 改、 查几个功能 ,而且数据都有特定的格式 ,可以针对这些应用设计出简单高效的应用程序。而一般的数据库系统则支持大而全的功能 ,同时损失了速度和空间。最后 ,搜索引擎面临大量的用户检索需求 ,这要求搜索引擎在检索程序的设计上要分秒必争 ,尽可能的将大运算量的工作在索引建立时完成 ,使检索运算尽量的少。一般的数据库系统很难承受如此大量的用户请求 ,而且在检索响应时间和检索并发度上都不及我们专门设计的索引系统。 倒排列表 倒排列表用来记录有哪些文档包含了某个单词。一般在文档集合里会有很多文档包含某个单词,每个文档会记录文档编号(DocID),单词在这个文档中出现的次数(TF)及单词在文档中哪些位置出现过等信息,这样与一个文档相关的信息被称做倒排索引项(Posting),包含这个单词的一系列倒排索引项形成了列表结构,这就是某个单词对应的倒排列表。右图是倒排列表的示意图,在文档集合中出现过的所有单词及其对应的倒排列表组成了倒排索引。 在实际的搜索引擎系统中,并不存储倒排索引项中的实际文档编号,而是代之以文档编号差值(D-Gap)。文档编号差值是倒排列表中相邻的两个倒排索引项文档编号的差值,一般在索引构建过程中,可以保证倒排列表中后面出现的文档编号大于之前出现的文档编号,所以文档编号差值总是大于0的整数。如图2所示的例子中,原始的 3个文档编号分别是187、196和199,通过编号差值计算,在实际存储的时候就转化成了:187、9、3。 之所以要对文档编号进行差值计算,主要原因是为了更好地对数据进行压缩,原始文档编号一般都是大数值,通过差值计算,就有效地将大数值转换为了小数值,而这有助于增加数据的压缩率。 倒排索引 倒排索引[2] (英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。 倒排索引 倒排索引 倒排索引[2] 有两种不同的反向索引形式: 一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。 一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。 后者的形式提供了更多的兼容性(比如短语搜索),但是需要更多的时间和空间来创建。 现代搜索引擎的索引[3] 都是基于倒排索引。相比“签名文件”、“后缀树”等索引结构,“倒排索引”是实现单词到文档映射关系的最佳实现方式和最有效的索引结构. 构建方法编辑 简单法 索引的构建[4] 相当于从正排表到倒排表的建立过程。当我们分析完网页时 ,得到的是以网页为主码的索引表。当索引建立完成后 ,应得到倒排表 ,具体流程如图所示: 流程描述如下: 1)将文档分析成单词term标记, 2)使用hash去重单词term 3)对单词生成倒排列表 倒排列表就是文档编号DocID,没有包含其他的信息(如词频,单词位置等),这就是简单的索引。 这个简单索引功能可以用于小数据,例如索引几千个文档。然而它有两点限制: 1)需要有足够的内存来存储倒排表,对于搜索引擎来说, 都是G级别数据,特别是当规模不断扩大时 ,我们根本不可能提供这么多的内存。 2)算法是顺序执行,不便于并行处理。 合并法 归并法[4] ,即每次将内存中数据写入磁盘时,包括词典在内的所有中间结果信息都被写入磁盘,这样内存所有内容都可以被清空,后续建立索引可以使用全部的定额内存。 归并索引 归并索引 如图 归并示意图: 合并流程: 1)页面分析,生成临时倒排数据索引A,B,当临时倒排数据索引A,B占满内存后,将内存索引A,B写入临时文件生成临时倒排文件, 2) 对生成的多个临时倒排文件 ,执行多路归并 ,输出得到最终的倒排文件 ( inverted file)。 合并流程 合并流程 索引创建过程中的页面分析 ,特别是中文分词为主要时间开销。算法的第二步相对很快。这样创建算法的优化集中在中文分词效率上。 更新策略编辑 更新策略有四种[2] :完全重建、再合并策略、原地更新策略以及混合策略。 完全重建策略:当新增文档到达一定数量,将新增文档和原先的老文档整合,然后利用静态索引创建方法对所有文档重建索引,新索引建立完成后老索引会被遗弃。此法代价高,但是主流商业搜索引擎一般是采用此方式来维护索引的更新(这句话是书中原话) 再合并策略:当新增文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排表列表末尾追加倒排表列表项;一旦临时索引将指定内存消耗光,即进行一次索引合并,这里需要倒排文件里的倒排列表存放顺序已经按照索引单词字典顺序由低到高排序,这样直接顺序扫描合并即可。其缺点是:因为要生成新的倒排索引文件,所以对老索引中的很多单词,尽管其在倒排列表并未发生任何变化,也需要将其从老索引中取出来并写入新索引中,这样对磁盘消耗是没必要的。 原地更新策略:试图改进再合并策略,在原地合并倒排表,这需要提前分配一定的空间给未来插入,如果提前分配的空间不够了需要迁移。实际显示,其索引更新的效率比再合并策略要低。 混合策略:出发点是能够结合不同索引更新策略的长处,将不同索引更新策略混合,以形成更高效的方法。
AVL树:平衡二叉树,一般是用平衡因子差值决定并通过旋转来实现,左右子树树高差不超过1,那么和红黑树比较它是严格的平衡二叉树,平衡条件非常严格(树高差只有1),只要插入或删除不满足上面的条件就要通过旋转来保持平衡。由于旋转是非常耗费时间的。我们可以推出AVL树适合用于插入删除次数比较少,但查找多的情况。
如果想知道MySQL数据库中每个表占用的空间、表记录的行数的话,可以打开MySQL的 information_schema 数据库。在该库中有一个 TABLES 表,这个表主要字段分别是:
redis命令发送格式: *<参数数量> CRLF $<参数 1 的字节数量> CRLF <参数 1 的数据> CRLF ... $<参数 N="" 的字节数量=""> CRLF
<参数 N="" 的数据=""> CRLF 其中CRLF表示 rn客户端管理器
 客户端管理器是处理客户端通信的。客户端可以是一个(网站)服务器或者一个最终用户或最终应用。客户端管理器通过一系列知名的API(JDBC, ODBC, OLE-DB …)提供不同的方式来访问数据库。客户端管理器也提供专有的数据库访问API。
当你连接到数据库时:
管理器首先检查你的验证信息(用户名和密码),然后检查你是否有访问数据库的授权。这些权限由DBA分配。
然后,管理器检查是否有空闲进程(或线程)来处理你对查询。
管理器还会检查数据库是否负载很重。
管理器可能会等待一会儿来获取需要的资源。如果等待时间达到超时时间,它会关闭连接并给出一个可读的错误信息。
然后管理器会把你的查询送给查询管理器来处理。
因为查询处理进程不是『不全则无』的,一旦它从查询管理器得到数据,它会把部分结果保存到一个缓冲区并且开始给你发送。
如果遇到问题,管理器关闭连接,向你发送可读的解释信息,然后释放资源。
查询管理器
这部分是数据库的威力所在,在这部分里,一个写得糟糕的查询可以转换成一个快速执行的代码,代码执行的结果被送到客户端管理器。这个多步骤操作过程如下:查询首先被解析并判断是否合法
然后被重写,去除了无用的操作并且加入预优化部分
接着被优化以便提升性能,并被转换为可执行代码和数据访问计划。
然后计划被编译
最后,被执行
查询解析器每一条SQL语句都要送到解析器来检查语法,如果你的查询有错,解析器将拒绝该查询。比如,如果你写成”SLECT …” 而不是 “SELECT …”,那就没有下文了。但这还不算完,解析器还会检查关键字是否使用正确的顺序,比如 WHERE 写在 SELECT 之前会被拒绝。然后,解析器要分析查询中的表和字段,使用数据库元数据来检查:表是否存在
表的字段是否存在
对某类型字段的 运算 是否 可能(比如,你不能将整数和字符串进行比较,你不能对一个整数使用 substring() 函数)
接着,解析器检查在查询中你是否有权限来读取(或写入)表。再强调一次:这些权限由DBA分配。在解析过程中,SQL 查询被转换为内部表示(通常是一个树)。如果一切正常,内部表示被送到查询重写器。查询重写器在这一步,我们已经有了查询的内部表示,重写器的目标是:预优化查询
避免不必要的运算
帮助优化器找到合理的最佳解决方案
重写器按照一系列已知的规则对查询执行检测。如果查询匹配一种模式的规则,查询就会按照这条规则来重写。下面是(可选)规则的非详尽的列表:视图合并:如果你在查询中使用视图,视图就会转换为它的 SQL 代码。
子查询扁平化:子查询是很难优化的,因此重写器会尝试移除子查询去除不必要的运算符:比如,如果你用了 DISTINCT,而其实你有 UNIQUE 约束(这本身就防止了数据出现重复),那么 DISTINCT 关键字就被去掉了。
排除冗余的联接:如果相同的 JOIN 条件出现两次,比如隐藏在视图中的 JOIN 条件,或者由于传递性产生的无用 JOIN,都会被消除。
常数计算赋值:如果你的查询需要计算,那么在重写过程中计算会执行一次。比如 WHERE AGE > 10+2 会转换为 WHERE AGE > 12 , TODATE(“日期字符串”) 会转换为 datetime 格式的日期值。
(高级)分区裁剪(Partition Pruning):如果你用了分区表,重写器能够找到需要使用的分区。
(高级)物化视图重写(Materialized view rewrite):如果你有个物化视图匹配查询谓词的一个子集,重写器将检查视图是否最新并修改查询,令查询使用物化视图而不是原始表。
(高级)自定义规则:如果你有自定义规则来修改查询(就像 Oracle policy),重写器就会执行这些规则。
(高级)OLAP转换:分析/加窗 函数,星形联接,ROLLUP 函数……都会发生转换(但我不确定这是由重写器还是优化器来完成,因为两个进程联系很紧,必须看是什么数据库)。当你要求数据库收集统计信息,数据库会计算下列值:表中行和页的数量
表中每个列中的:
唯一值
数据长度(最小,最大,平均)
数据范围(最小,最大,平均)
表的索引信息
这些统计信息会帮助优化器估计查询所需的磁盘 I/O、CPU、和内存使用对每个列的统计非常重要。
比如,如果一个表 PERSON 需要联接 2 个列: LAST_NAME, FIRST_NAME。
根据统计信息,数据库知道FIRST_NAME只有 1,000 个不同的值,LAST_NAME 有 1,000,000 个不同的值。
因此,数据库就会按照 LAST_NAME, FIRST_NAME 联接。
因为 LAST_NAME 不大可能重复,多数情况下比较 LAST_NAME 的头 2 、 3 个字符就够了,这将大大减少比较的次数。所有的现代数据库都在用基于成本的优化(即CBO)来优化查询。道理是针对每个运算设置一个成本,通过应用成本最低廉的一系列运算,来找到最佳的降低查询成本的方法。为了理解成本优化器的原理,我觉得最好用个例子来『感受』一下这个任务背后的复杂性。这里我将给出联接 2 个表的 3 个方法,我们很快就能看到即便一个简单的联接查询对于优化器来说都是个噩梦。之后,我们会了解真正的优化器是怎么做的。对于这些联接操作,我会专注于它们的时间复杂度,但是,数据库优化器计算的是它们的 CPU 成本、磁盘 I/O 成本、和内存需求。时间复杂度和 CPU 成本的区别是,时间成本是个近似值(给我这样的懒家伙准备的)。而 CPU 成本,我这里包括了所有的运算,比如:加法、条件判断、乘法、迭代……还有呢:每一个高级代码运算都要特定数量的低级 CPU 运算。
对于 Intel Core i7、Intel Pentium 4、AMD Opteron…等,(就 CPU 周期而言)CPU 的运算成本是不同的,也就是说它取决于 CPU 的架构。
使用时间复杂度就容易多了(至少对我来说),用它我也能了解到 CBO 的概念。由于磁盘 I/O 是个重要的概念,我偶尔也会提到它。请牢记,大多数时候瓶颈在于磁盘 I/O 而不是 CPU 使用。索引在研究 B+树的时候我们谈到了索引,要记住一点,索引都是已经排了序的。仅供参考:还有其他类型的索引,比如位图索引,在 CPU、磁盘I/O、和内存方面与B+树索引的成本并不相同。另外,很多现代数据库为了改善执行计划的成本,可以仅为当前查询动态地生成临时索引。存取路径在应用联接运算符(join operators)之前,你首先需要获得数据。以下就是获得数据的方法。
全扫描如果你读过执行计划,一定看到过『全扫描』(或只是『扫描』)一词。简单的说全扫描就是数据库完整的读一个表或索引。就磁盘 I/O 而言,很明显全表扫描的成本比索引全扫描要高昂。范围扫描其他类型的扫描有索引范围扫描,比如当你使用谓词 ” WHERE AGE > 20 AND AGE < 40 ” 的时候它就会发生。当然,你需要在 AGE 字段上有索引才能用到索引范围扫描。在第一部分我们已经知道,范围查询的时间成本大约是 log(N)+M,这里 N 是索引的数据量,M 是范围内估测的行数。多亏有了统计我们才能知道 N 和 M 的值(注: M 是谓词 “ AGE > 20 AND AGE < 40 ” 的选择率)。另外范围扫描时,你不需要读取整个索引,因此在磁盘 I/O 方面没有全扫描那么昂贵。唯一扫描如果你只需要从索引中取一个值你可以用唯一扫描。根据 ROW ID 存取多数情况下,如果数据库使用索引,它就必须查找与索引相关的行,这样就会用到根据 ROW ID 存取的方式。
其它路径我没有列举所有的存取路径,如果你感兴趣可以读一读 Oracle文档。其它数据库里也许叫法不同但背后的概念是一样的。联接运算符那么,我们知道如何获取数据了,那现在就把它们联接起来!我要展现的是3个个常用联接运算符:合并联接(Merge join),哈希联接(Hash Join)和嵌套循环联接(Nested Loop Join)。但是在此之前,我需要引入新词汇了:内关系和外关系( inner relation and outer relation) 【译者注: “内关系和外关系” 这个说法来源不明,跟查询的”内联接(INNER JOIN) 、外联接(OUTER JOIN) ” 不是一个概念 。只查到百度百科词条:关系数据库 里提到”每个表格(有时被称为一个关系)……” 。 其他参考链接 “Merge Join” “Hash Join” “Nested Loop Join” 】 。 一个关系可以是:一个表
一个索引
上一个运算的中间结果(比如上一个联接运算的结果)
当你联接两个关系时,联接算法对两个关系的处理是不同的。在本文剩余部分,我将假定:外关系是左侧数据集
内关系是右侧数据集
比如, A JOIN B 是 A 和 B 的联接,这里 A 是外关系,B 是内关系。多数情况下, A JOIN B 的成本跟 B JOIN A 的成本是不同的。在这一部分,我还将假定外关系有 N 个元素,内关系有 M 个元素。要记住,真实的优化器通过统计知道 N 和 M 的值。注:N 和 M 是关系的基数。【译者注: 基数 】嵌套循环联接嵌套循环联接是最简单的哈希联接哈希联接更复杂,不过在很多场合比嵌套循环联接成本低哈希联接的道理是:1) 读取内关系的所有元素
2) 在内存里建一个哈希表
3) 逐条读取外关系的所有元素
4) (用哈希表的哈希函数)计算每个元素的哈希值,来查找内关系里相关的哈希桶内
5) 是否与外关系的元素匹配。
在时间复杂度方面我需要做些假设来简化问题:内关系被划分成 X 个哈希桶
哈希函数几乎均匀地分布每个关系内数据的哈希值,就是说哈希桶大小一致。
外关系的元素与哈希桶内的所有元素的匹配,成本是哈希桶内元素的数量。
时间复杂度是 (M/X) * N + 创建哈希表的成本(M) + 哈希函数的成本 * N 。
如果哈希函数创建了足够小规模的哈希桶,那么复杂度就是 O(M+N)。还有个哈希联接的版本,对内存有利但是对磁盘 I/O 不够有利。 这回是这样的:1) 计算内关系和外关系双方的哈希表
2) 保存哈希表到磁盘
3) 然后逐个哈希桶比较(其中一个读入内存,另一个逐行读取)。
合并联接合并联接是唯一产生排序的联接算法。注:这个简化的合并联接不区分内表或外表;两个表扮演同样的角色。但是真实的实现方式是不同的,比如当处理重复值时。1.(可选)排序联接运算:两个输入源都按照联接关键字排序。2.合并联接运算:排序后的输入源合并到一起。排序我们已经谈到过合并排序,在这里合并排序是个很好的算法(但是并非最好的,如果内存足够用的话,还是哈希联接更好)。然而有时数据集已经排序了,比如:如果表内部就是有序的,比如联接条件里一个索引组织表 【译者注: index-organized table 】
如果关系是联接条件里的一个索引
如果联接应用在一个查询中已经排序的中间结果
空闲内存:没有足够的内存的话就跟强大的哈希联接拜拜吧(至少是完全内存中哈希联接)。
两个数据集的大小。比如,如果一个大表联接一个很小的表,那么嵌套循环联接就比哈希联接快,因为后者有创建哈希的高昂成本;如果两个表都非常大,那么嵌套循环联接CPU成本就很高昂。
是否有索引:有两个 B+树索引的话,聪明的选择似乎是合并联接。
结果是否需要排序:即使你用到的是未排序的数据集,你也可能想用成本较高的合并联接(带排序的),因为最终得到排序的结果后,你可以把它和另一个合并联接串起来(或者也许因为查询用 ORDER BY/GROUP BY/DISTINCT 等操作符隐式或显式地要求一个排序结果)。
关系是否已经排序:这时候合并联接是最好的候选项。
联接的类型:是等值联接(比如 tableA.col1 = tableB.col2 )? 还是内联接?外联接?笛卡尔乘积?或者自联接?有些联接在特定环境下是无法工作的。
数据的分布:如果联接条件的数据是倾斜的(比如根据姓氏来联接人,但是很多人同姓),用哈希联接将是个灾难,原因是哈希函数将产生分布极不均匀的哈希桶。
如果你希望联接操作使用多线程或多进程。
动态规划,贪婪算法和启发式算法关系型数据库会尝试我刚刚提到的多种方法,优化器真正的工作是在有限时间里找到一个好的解决方案。多数时候,优化器找到的不是最佳的方案,而是一个『不错』的对于小规模的查询,采取粗暴的方式是有可能的。但是为了让中等规模的查询也能采取粗暴的方式,我们有办法避免不必要的计算,这就是动态规划。动态规划这几个字背后的理念是,很多执行计划是非常相似的。
贪婪算法但是,优化器面对一个非常大的查询,或者为了尽快找到答案(然而查询速度就快不起来了),会应用另一种算法,叫贪婪算法。原理是按照一个规则(或启发)以渐进的方式制定查询计划。在这个规则下,贪婪算法逐步寻找最佳算法,先处理一条JOIN,接着每一步按照同样规则加一条新的JOIN。我们来看个简单的例子。比如一个针对5张表(A,B,C,D,E)4次JOIN 的查询,为了简化我们把嵌套JOIN作为可能的联接方式,按照『使用最低成本的联接』规则。直接从 5 个表里选一个开始(比如 A)
计算每一个与 A 的联接(A 作为内关系或外关系)
发现 “A JOIN B” 成本最低
计算每一个与 “A JOIN B” 的结果联接的成本(”A JOIN B” 作为内关系或外关系)
发现 “(A JOIN B) JOIN C” 成本最低
计算每一个与 “(A JOIN B) JOIN C” 的结果联接的成本 ……
最后确定执行计划 “( ( (A JOIN B) JOIN C) JOIN D ) JOIN E )”
因为我们是武断地从表 A 开始,我们可以把同样的算法用在 B,然后 C,然后 D, 然后 E。最后保留成本最低的执行计划。顺便说一句,这个算法有个名字,叫『最近邻居算法』。抛开细节不谈,只需一个良好的模型和一个 Nlog(N) 复杂度的排序,问题就轻松解决了。这个算法的复杂度是 O(Nlog(N)) ,对比一下完全动态规划的 O(3^N)。如果你有个20个联接的大型查询,这意味着 26 vs 3,486,784,401 ,天壤之别!这个算法的问题是,我们做的假设是:找到 2 个表的最佳联接方法,保留这个联接结果,再联接下一个表,就能得到最低的成本。但是:即使在 A, B, C 之间,A JOIN B 可得最低成本
(A JOIN C) JOIN B 也许比 (A JOIN B) JOIN C 更好。
为了改善这一状况,你可以多次使用基于不同规则的贪婪算法,并保留最佳的执行计划。其他算法[ 如果你已经受够了算法话题,就直接跳到下一部分。这部分对文章余下的内容不重要。] 【译者注:我也很想把这段跳过去 -_- 】很多计算机科学研究者热衷于寻找最佳的执行计划,他们经常为特定问题或模式探寻更好的解决方案,比如:如果查询是星型联接(一种多联接查询),某些数据库使用一种特定的算法。
如果查询是并行的,某些数据库使用一种特定的算法。 ……
其他算法也在研究之中,就是为了替换在大型查询中的动态规划算法。贪婪算法属于一个叫做启发式算法的大家族,它根据一条规则(或启发),保存上一步找到的方法,『附加』到当前步骤来进一步搜寻解决方法。有些算法根据特定规则,一步步的应用规则但不总是保留上一步找到的最佳方法。它们统称启发式算法。比如,基因算法就是一种:一个方法代表一种可能的完整查询计划
每一步保留了 P 个方法(即计划),而不是一个。
0) P 个计划随机创建
1) 成本最低的计划才会保留
2) 这些最佳计划混合在一起产生 P 个新的计划
3) 一些新的计划被随机改写
4) 1,2,3步重复 T 次
5) 然后在最后一次循环,从 P 个计划里得到最佳计划。
循环次数越多,计划就越好。我们来看看 SQLite 优化器 是怎么工作的。这是个轻量化数据库,它使用一种简单优化器,基于带有附加规则的贪婪算法,来限制可能性的数量。SQLite 在有 CROSS JOIN 操作符时从不给表重新排序
使用嵌套联接
外联接始终按顺序评估
……
3.8.0之前的版本使用『最近邻居』贪婪算法来搜寻最佳查询计划
等等……我们见过这个算法!真是巧哈!
从3.8.0版本(发布于2015年)开始,SQLite使用『N最近邻居』贪婪算法来搜寻最佳查询计划
我们再看看另一个优化器是怎么工作的。IBM DB2 跟所有企业级数据库都类似,我讨论它是因为在切换到大数据之前,它是我最后真正使用的数据库。看过官方文档后,我们了解到 DB2 优化器可以让你使用 7 种级别的优化:对联接使用贪婪算法
0 – 最小优化,使用索引扫描和嵌套循环联接,避免一些查询重写
1 – 低级优化
2 – 完全优化
对联接使用动态规划算法
3 – 中等优化和粗略的近似法
5 – 完全优化,使用带有启发式的所有技术
7 – 完全优化,类似级别5,但不用启发式
9 – 最大优化,完全不顾开销,考虑所有可能的联接顺序,包括笛卡尔乘积
可以看到 DB2 使用贪婪算法和动态规划算法。当然,他们不会把自己的启发算法分享出来的,因为查询优化器是数据库的看家本领。DB2 的默认级别是 5,优化器使用下列特性: 【译者注:以下出现的一些概念我没有做考证,因为[ 这段不重要,可以跳过 ]】使用所有可用的统计,包括线段树(frequent-value)和分位数统计(quantile statistics)。
使用所有查询重写规则(含物化查询表路由,materialized query table routing),除了在极少情况下适用的计算密集型规则。
使用动态规划模拟联接
有限使用组合内关系(composite inner relation)
对于涉及查找表的星型模式,有限使用笛卡尔乘积
考虑宽泛的访问方式,含列表预取(list prefetch,注:我们将讨论什么是列表预取),index ANDing(注:一种对索引的特殊操作),和物化查询表路由。
默认的,DB2 对联接排列使用受启发式限制的动态规划算法。其它情况 (GROUP BY, DISTINCT…) 由简单规则处理。
查询计划缓存由于创建查询计划是耗时的,大多数据库把计划保存在查询计划缓存,来避免重复计算。这个话题比较大,因为数据库需要知道什么时候更新过时的计划。办法是设置一个上限,如果一个表的统计变化超过了上限,关于该表的查询计划就从缓存中清除。查询执行器在这个阶段,我们有了一个优化的执行计划,再编译为可执行代码。然后,如果有足够资源(内存,CPU),查询执行器就会执行它。计划中的操作符 (JOIN, SORT BY …) 可以顺序或并行执行,这取决于执行器。为了获得和写入数据,查询执行器与数据管理器交互,本文下一部分来讨论数据管理器在这一步,查询管理器执行了查询,需要从表和索引获取数据,于是向数据管理器提出请求。但是有 2 个问题:关系型数据库使用事务模型,所以,当其他人在同一时刻使用或修改数据时,你无法得到这部分数据。
数据提取是数据库中速度最慢的操作,所以数据管理器需要足够聪明地获得数据并保存在内存缓冲区内。
在这一部分,我没看看关系型数据库是如何处理这两个问题的。我不会讲数据管理器是怎么获得数据的,因为这不是最重要的(而且本文已经够长的了!)。
缓存管理器我已经说过,数据库的主要瓶颈是磁盘 I/O。为了提高性能,现代数据库使用缓存管理器。查询执行器不会直接从文件系统拿数据,而是向缓存管理器要。缓存管理器有一个内存缓存区,叫做缓冲池,从内存读取数据显著地提升数据库性能。对此很难给出一个数量级,因为这取决于你需要的是哪种操作:顺序访问(比如:全扫描) vs 随机访问(比如:按照row id访问)
读还是写
以及数据库使用的磁盘类型:7.2k/10k/15k rpm的硬盘
SSD
RAID 1/5/…
要我说,内存比磁盘要快100到10万倍。然而,这导致了另一个问题(数据库总是这样…),缓存管理器需要在查询执行器使用数据之前得到数据,否则查询管理器不得不等待数据从缓慢的磁盘中读出来。预读这个问题叫预读。查询执行器知道它将需要什么数据,因为它了解整个查询流,而且通过统计也了解磁盘上的数据。道理是这样的:当查询执行器处理它的第一批数据时
会告诉缓存管理器预先装载第二批数据
当开始处理第二批数据时
告诉缓存管理器预先装载第三批数据,并且告诉缓存管理器第一批可以从缓存里清掉了。
……
缓存管理器在缓冲池里保存所有的这些数据。为了确定一条数据是否有用,缓存管理器给缓存的数据添加了额外的信息(叫闩锁)。有时查询执行器不知道它需要什么数据,有的数据库也不提供这个功能。相反,它们使用一种推测预读法(比如:如果查询执行器想要数据1、3、5,它不久后很可能会要 7、9、11),或者顺序预读法(这时候缓存管理器只是读取一批数据后简单地从磁盘加载下一批连续数据)。为了监控预读的工作状况,现代数据库引入了一个度量叫缓冲/缓存命中率,用来显示请求的数据在缓存中找到而不是从磁盘读取的频率。注:糟糕的缓存命中率不总是意味着缓存工作状态不佳。更多信息请阅读Oracle文档。缓冲只是容量有限的内存空间,因此,为了加载新的数据,它需要移除一些数据。加载和清除缓存需要一些磁盘和网络I/O的成本。如果你有个经常执行的查询,那么每次都把查询结果加载然后清除,效率就太低了。现代数据库用缓冲区置换策略来解决这个问题。
缓冲区置换策略多数现代数据库(至少 SQL Server, MySQL, Oracle 和 DB2)使用 LRU 算法。LRULRU代表最近最少使用(Least Recently Used)算法,背后的原理是:在缓存里保留的数据是最近使用的,所以更有可能再次使用。
图解:
为了更好的理解,我假设缓冲区里的数据没有被闩锁锁住(就是说是可以被移除的)。在这个简单的例子里,缓冲区可以保存 3 个元素:1:缓存管理器(简称CM)使用数据1,把它放入空的缓冲区
2:CM使用数据4,把它放入半载的缓冲区
3:CM使用数据3,把它放入半载的缓冲区
4:CM使用数据9,缓冲区满了,所以数据1被清除,因为它是最后一个最近使用的,数据9加入到缓冲区
5:CM使用数据4,数据4已经在缓冲区了,所以它再次成为第一个最近使用的。
6:CM使用数据1,缓冲区满了,所以数据9被清除,因为它是最后一个最近使用的,数据1加入到缓冲区
……
这个算法效果很好,但是有些限制。如果对一个大表执行全表扫描怎么办?换句话说,当表/索引的大小超出缓冲区会发生什么?使用这个算法会清除之前缓存内所有的数据,而且全扫描的数据很可能只使用一次。改进为了防止这个现象,有些数据库增加了特殊的规则,比如Oracle文档中的描述:『对非常大的表来说,数据库通常使用直接路径来读取,即直接加载区块[……],来避免填满缓冲区。对于中等大小的表,数据库可以使用直接读取或缓存读取。如果选择缓存读取,数据库把区块置于LRU的尾部,防止清空当前缓冲区。』
还有一些可能,比如使用高级版本的LRU,叫做 LRU-K。例如,SQL Server 使用 LRU-2。这个算法的原理是把更多的历史记录考虑进来。简单LRU(也就是 LRU-1),只考虑最后一次使用的数据。LRU-K呢:考虑数据最后第K次使用的情况
数据使用的次数加进了权重
一批新数据加载进入缓存,旧的但是经常使用的数据不会被清除(因为权重更高)
但是这个算法不会保留缓存中不再使用的数据
所以数据如果不再使用,权重值随着时间推移而降低
计算权重是需要成本的,所以SQL Server只是使用 K=2,这个值性能不错而且额外开销可以接受。其他算法当然还有其他管理缓存的算法,比如:2Q(类LRU-K算法)
CLOCK(类LRU-K算法)
MRU(最新使用的算法,用LRU同样的逻辑但不同的规则)
LRFU(Least Recently and Frequently Used,最近最少使用最近最不常用)
……
写缓冲区我只探讨了读缓存 —— 在使用之前预先加载数据。用来保存数据、成批刷入磁盘,而不是逐条写入数据从而造成很多单次磁盘访问。要记住,缓冲区保存的是页(最小的数据单位)而不是行(逻辑上/人类习惯的观察数据的方式)。缓冲池内的页如果被修改了但还没有写入磁盘,就是脏页。有很多算法来决定写入脏页的最佳时机,但这个问题与事务的概念高度关联,下面我们就谈谈事务。
事务管理器最后但同样重要的,是事务管理器,我们将看到这个进程是如何保证每个查询在自己的事务内执行的。但开始之前,我们需要理解ACID事务的概念。现代数据库不会使用纯粹的隔离作为默认模式,因为它会带来巨大的性能消耗。SQL一般定义4个隔离级别:串行化(Serializable,SQLite默认模式):最高级别的隔离。两个同时发生的事务100%隔离,每个事务有自己的『世界』。
可重复读(Repeatable read,MySQL默认模式):每个事务有自己的『世界』,除了一种情况。如果一个事务成功执行并且添加了新数据,这些数据对其他正在执行的事务是可见的。但是如果事务成功修改了一条数据,修改结果对正在运行的事务不可见。所以,事务之间只是在新数据方面突破了隔离,对已存在的数据仍旧隔离。
举个例子,如果事务A运行”SELECT count(1) from TABLE_X” ,然后事务B在 TABLE_X 加入一条新数据并提交,当事务A再运行一次 count(1)结果不会是一样的。
这叫幻读(phantom read)。
读取已提交(Read committed,Oracle、PostgreSQL、SQL Server默认模式):可重复读+新的隔离突破。如果事务A读取了数据D,然后数据D被事务B修改(或删除)并提交,事务A再次读取数据D时数据的变化(或删除)是可见的。
这叫不可重复读(non-repeatable read)。
读取未提交(Read uncommitted):最低级别的隔离,是读取已提交+新的隔离突破。如果事务A读取了数据D,然后数据D被事务B修改(但并未提交,事务B仍在运行中),事务A再次读取数据D时,数据修改是可见的。如果事务B回滚,那么事务A第二次读取的数据D是无意义的,因为那是事务B所做的从未发生的修改(已经回滚了嘛)。
这叫脏读(dirty read)。
多数数据库添加了自定义的隔离级别(比如 PostgreSQL、Oracle、SQL Server的快照隔离),而且并没有实现SQL规范里的所有级别(尤其是读取未提交级别)。默认的隔离级别可以由用户/开发者在建立连接时覆盖(只需要增加很简单的一行代码)。
并发控制确保隔离性、一致性和原子性的真正问题是对相同数据的写操作(增、更、删):如果所有事务只是读取数据,它们可以同时工作,不会更改另一个事务的行为。
如果(至少)有一个事务在修改其他事务读取的数据,数据库需要找个办法对其它事务隐藏这种修改。而且,它还需要确保这个修改操作不会被另一个看不到这些数据修改的事务擦除。
这个问题叫并发控制。最简单的解决办法是依次执行每个事务(即顺序执行),但这样就完全没有伸缩性了,在一个多处理器/多核服务器上只有一个核心在工作,效率很低。理想的办法是,每次一个事务创建或取消时:监控所有事务的所有操作
检查是否2个(或更多)事务的部分操作因为读取/修改相同的数据而存在冲突
重新编排冲突事务中的操作来减少冲突的部分
按照一定的顺序执行冲突的部分(同时非冲突事务仍然在并发运行)
考虑事务有可能被取消
用更正规的说法,这是对冲突的调度问题。更具体点儿说,这是个非常困难而且CPU开销很大的优化问题。企业级数据库无法承担等待几个小时,来寻找每个新事务活动最好的调度,因此就使用不那么理想的方式以避免更多的时间浪费在解决冲突上。
锁管理器为了解决这个问题,多数数据库使用锁和/或数据版本控制。这是个很大的话题,我会集中探讨锁,和一点点数据版本控制。悲观锁原理是:如果一个事务需要一条数据
它就把数据锁住
如果另一个事务也需要这条数据
它就必须要等第一个事务释放这条数据
这个锁叫排他锁。
但是对一个仅仅读取数据的事务使用排他锁非常昂贵,因为这会迫使其它只需要读取相同数据的事务等待。因此就有了另一种锁,共享锁。共享锁是这样的:如果一个事务只需要读取数据A
它会给数据A加上『共享锁』并读取
如果第二个事务也需要仅仅读取数据A
它会给数据A加上『共享锁』并读取
如果第三个事务需要修改数据A
它会给数据A加上『排他锁』,但是必须等待另外两个事务释放它们的共享锁。
同样的,如果一块数据被加上排他锁,一个只需要读取该数据的事务必须等待排他锁释放才能给该数据加上共享锁。锁管理器是添加和释放锁的进程,在内部用一个哈希表保存锁信息(关键字是被锁的数据),并且了解每一块数据是:被哪个事务加的锁
哪个事务在等待数据解锁
死锁但是使用锁会导致一种情况,2个事务永远在等待一块数据:
在本图中:
事务A 给 数据1 加上排他锁并且等待获取数据2
事务B 给 数据2 加上排他锁并且等待获取数据1
这叫死锁。在死锁发生时,锁管理器要选择取消(回滚)一个事务,以便消除死锁。这可是个艰难的决定:杀死数据修改量最少的事务(这样能减少回滚的成本)?
杀死持续时间最短的事务,因为其它事务的用户等的时间更长?
杀死能用更少时间结束的事务(避免可能的资源饥荒)?
一旦发生回滚,有多少事务会受到回滚的影响?
在作出选择之前,锁管理器需要检查是否有死锁存在。哈希表可以看作是个图表(见上文图),图中出现循环就说明有死锁。由于检查循环是昂贵的(所有锁组成的图表是很庞大的),经常会通过简单的途径解决:使用超时设定。如果一个锁在超时时间内没有加上,那事务就进入死锁状态。锁管理器也可以在加锁之前检查该锁会不会变成死锁,但是想要完美的做到这一点还是很昂贵的。因此这些预检经常设置一些基本规则。两段锁实现纯粹的隔离最简单的方法是:事务开始时获取锁,结束时释放锁。就是说,事务开始前必须等待确保自己能加上所有的锁,当事务结束时释放自己持有的锁。这是行得通的,但是为了等待所有的锁,大量的时间被浪费了。更快的方法是两段锁协议(Two-Phase Locking Protocol,由 DB2 和 SQL Server使用),在这里,事务分为两个阶段:成长阶段:事务可以获得锁,但不能释放锁。
收缩阶段:事务可以释放锁(对于已经处理完而且不会再次处理的数据),但不能获得新锁。
这两条简单规则背后的原理是:释放不再使用的锁,来降低其它事务的等待时间
防止发生这类情况:事务最初获得的数据,在事务开始后被修改,当事务重新读取该数据时发生不一致。
这个规则可以很好地工作,但有个例外:如果修改了一条数据、释放了关联的锁后,事务被取消(回滚),而另一个事务读到了修改后的值,但最后这个值却被回滚。为了避免这个问题,所有独占锁必须在事务结束时释放。多说几句当然了,真实的数据库使用更复杂的系统,涉及到更多类型的锁(比如意向锁,intention locks)和更多的粒度(行级锁、页级锁、分区锁、表锁、表空间锁),但是道理是相同的。我只探讨纯粹基于锁的方法,数据版本控制是解决这个问题的另一个方法。版本控制是这样的:每个事务可以在相同时刻修改相同的数据
每个事务有自己的数据拷贝(或者叫版本)
如果2个事务修改相同的数据,只接受一个修改,另一个将被拒绝,相关的事务回滚(或重新运行)
这将提高性能,因为:读事务不会阻塞写事务
写事务不会阻塞读
没有『臃肿缓慢』的锁管理器带来的额外开销
除了两个事务写相同数据的时候,数据版本控制各个方面都比锁表现得更好。只不过,你很快就会发现磁盘空间消耗巨大。数据版本控制和锁机制是两种不同的见解:乐观锁和悲观锁。两者各有利弊,完全取决于使用场景(读多还是写多)。关于数据版本控制,我推荐这篇非常优秀的文章,讲的是PostgreSQL如何实现多版本并发控制的。一些数据库,比如DB2(直到版本 9.7)和 SQL Server(不含快照隔离)仅使用锁机制。其他的像PostgreSQL, MySQL 和 Oracle 使用锁和鼠标版本控制混合机制。我不知道是否有仅用版本控制的数据库(如果你知道请告诉我)。[2015-08-20更新]一名读者告诉我:Firebird 和 Interbase 用不带锁的版本控制。版本控制对索引的影响挺有趣的:有时唯一索引会出现重复,索引的条目会多于表行数,等等。
如果你读过不同级别的隔离那部分内容,你会知道,提高隔离级别就会增加锁的数量和事务等待加锁的时间。这就是为什么多数数据库默认不会使用最高级别的隔离(即串行化)。当然,你总是可以自己去主流数据库(像MySQL, PostgreSQL 或 Oracle)的文档里查一下。
日志管理器我们已经知道,为了提升性能,数据库把数据保存在内存缓冲区内。但如果当事务提交时服务器崩溃,崩溃时还在内存里的数据会丢失,这破坏了事务的持久性。你可以把所有数据都写在磁盘上,但是如果服务器崩溃,最终数据可能只有部分写入磁盘,这破坏了事务的原子性。事务作出的任何修改必须是或者撤销,或者完成。有 2 个办法解决这个问题:影子副本/页(Shadow copies/pages):每个事务创建自己的数据库副本(或部分数据库的副本),并基于这个副本来工作。一旦出错,这个副本就被移除;一旦成功,数据库立即使用文件系统的一个把戏,把副本替换到数据中,然后删掉『旧』数据。
事务日志(Transaction log):事务日志是一个存储空间,在每次写盘之前,数据库在事务日志中写入一些信息,这样当事务崩溃或回滚,数据库知道如何移除或完成尚未完成的事务。
WAL(预写式日志)影子副本/页在运行较多事务的大型数据库时制造了大量磁盘开销,所以现代数据库使用事务日志。事务日志必须保存在稳定的存储上,我不会深挖存储技术,但至少RAID磁盘是必须的,以防磁盘故障。多数数据库(至少是Oracle, SQL Server, DB2, PostgreSQL, MySQL 和 SQLite) 使用预写日志协议(Write-Ahead Logging protocol ,WAL)来处理事务日志。WAL协议有 3 个规则:1) 每个对数据库的修改都产生一条日志记录,在数据写入磁盘之前日志记录必须写入事务日志。
2) 日志记录必须按顺序写入;记录 A 发生在记录 B 之前,则 A 必须写在 B 之前。
3) 当一个事务提交时,在事务成功之前,提交顺序必须写入到事务日志。
这个工作由日志管理器完成。简单的理解就是,日志管理器处于缓存管理器(cache manager)和数据访问管理器(data access manager,负责把数据写入磁盘)之间,每个 update / delete / create / commit / rollback 操作在写入磁盘之前先写入事务日志。简单,对吧?回答错误! 我们研究了这么多内容,现在你应该知道与数据库相关的每一件事都带着『数据库效应』的诅咒。好吧,我们说正经的,问题在于,如何找到写日志的同时保持良好的性能的方法。如果事务日志写得太慢,整体都会慢下来。
1992年,IBM 研究人员『发明』了WAL的增强版,叫 ARIES。ARIES 或多或少地在现代数据库中使用,逻辑未必相同,但AIRES背后的概念无处不在。我给发明加了引号是因为,按照MIT这门课的说法,IBM 的研究人员『仅仅是写了事务恢复的最佳实践方法』。AIRES 论文发表的时候我才 5 岁,我不关心那些酸溜溜的科研人员老掉牙的闲言碎语。事实上,我提及这个典故,是在开始探讨最后一个技术点前让你轻松一下。我阅读过这篇 ARIES 论文 的大量篇幅,发现它很有趣。在这一部分我只是简要的谈一下 ARIES,不过我强烈建议,如果你想了解真正的知识,就去读那篇论文。ARIES 代表『数据库恢复原型算法』(Algorithms for Recovery and Isolation Exploiting Semantics)。这个技术要达到一个双重目标:1) 写日志的同时保持良好性能
2) 快速和可靠的数据恢复
有多个原因让数据库不得不回滚事务:因为用户取消
因为服务器或网络故障
因为事务破坏了数据库完整性(比如一个列有唯一性约束而事务添加了重复值)
因为死锁
有时候(比如网络出现故障),数据库可以恢复事务。这怎么可能呢?为了回答这个问题,我们需要了解日志里保存的信息。
日志
事务的每一个操作(增/删/改)产生一条日志,由如下内容组成:LSN:一个唯一的日志序列号(Log Sequence Number)。LSN是按时间顺序分配的 * ,这意味着如果操作 A 先于操作 B,log A 的 LSN 要比 log B 的 LSN 小。
TransID:产生操作的事务ID。
PageID:被修改的数据在磁盘上的位置。磁盘数据的最小单位是页,所以数据的位置就是它所处页的位置。
PrevLSN:同一个事务产生的上一条日志记录的链接。
UNDO:取消本次操作的方法。
比如,如果操作是一次更新,UNDO将或者保存元素更新前的值/状态(物理UNDO),或者回到原来状态的反向操作(逻辑UNDO) 。
REDO:重复本次操作的方法。 同样的,有 2 种方法:或者保存操作后的元素值/状态,或者保存操作本身以便重复。
…:(供您参考,一个 ARIES 日志还有 2 个字段:UndoNxtLSN 和 Type)。
进一步说,磁盘上每个页(保存数据的,不是保存日志的)都记录着最后一个修改该数据操作的LSN。*LSN的分配其实更复杂,因为它关系到日志存储的方式。但道理是相同的。 ARIES 只使用逻辑UNDO,因为处理物理UNDO太过混乱了。注:据我所知,只有 PostgreSQL 没有使用UNDO,而是用一个垃圾回收服务来删除旧版本的数据。这个跟 PostgreSQL 对数据版本控制的实现有关。为了更好的说明这一点,这有一个简单的日志记录演示图,是由查询 “UPDATE FROM PERSON SET AGE = 18;” 产生的,我们假设这个查询是事务18执行的。【译者注: SQL 语句原文如此,应该是作者笔误 】每条日志都有一个唯一的LSN,链接在一起的日志属于同一个事务。日志按照时间顺序链接(链接列表的最后一条日志是最后一个操作产生的)。日志缓冲区为了防止写日志成为主要的瓶颈,数据库使用了日志缓冲区。
当查询执行器要求做一次修改:
1) 缓存管理器将修改存入自己的缓冲区;
2) 日志管理器将相关的日志存入自己的缓冲区;
3) 到了这一步,查询执行器认为操作完成了(因此可以请求做另一次修改);
4) 接着(不久以后)日志管理器把日志写入事务日志,什么时候写日志由某算法来决定。
5) 接着(不久以后)缓存管理器把修改写入磁盘,什么时候写盘由某算法来决定。
当事务提交,意味着事务每一个操作的 1 2 3 4 5 步骤都完成了。写事务日志是很快的,因为它只是『在事务日志某处增加一条日志』;而数据写盘就更复杂了,因为要用『能够快速读取的方式写入数据』。STEAL 和 FORCE 策略出于性能方面的原因,第 5 步有可能在提交之后完成,因为一旦发生崩溃,还有可能用REDO日志恢复事务。这叫做 NO-FORCE策略。数据库可以选择FORCE策略(比如第 5 步在提交之前必须完成)来降低恢复时的负载。另一个问题是,要选择数据是一步步的写入(STEAL策略),还是缓冲管理器需要等待提交命令来一次性全部写入(NO-STEAL策略)。选择STEAL还是NO-STEAL取决于你想要什么:快速写入但是从 UNDO 日志恢复缓慢,还是快速恢复。总结一下这些策略对恢复的影响:STEAL/NO-FORCE 需要 UNDO 和 REDO: 性能高,但是日志和恢复过程更复杂 (比如 ARIES)。多数数据库选择这个策略。 注:这是我从多个学术论文和教程里看到的,但并没有看到官方文档里显式说明这一点。
STEAL/ FORCE 只需要 UNDO.
NO-STEAL/NO-FORCE 只需要 REDO.
NO-STEAL/FORCE 什么也不需要: 性能最差,而且需要巨大的内存。
关于恢复Ok,有了不错的日志,我们来用用它们!假设新来的实习生让数据库崩溃了(首要规矩:永远是实习生的错。),你重启了数据库,恢复过程开始了。ARIES从崩溃中恢复有三个阶段:1) 分析阶段:恢复进程读取全部事务日志,来重建崩溃过程中所发生事情的时间线,决定哪个事务要回滚(所有未提交的事务都要回滚)、崩溃时哪些数据需要写盘。
2) Redo阶段:这一关从分析中选中的一条日志记录开始,使用 REDO 来将数据库恢复到崩溃之前的状态。
在REDO阶段,REDO日志按照时间顺序处理(使用LSN)。对每一条日志,恢复进程需要读取包含数据的磁盘页LSN。如果LSN(磁盘页)>= LSN(日志记录),说明数据已经在崩溃前写到磁盘(但是值已经被日志之后、崩溃之前的某个操作覆盖),所以不需要做什么。如果LSN(磁盘页)< LSN(日志记录),那么磁盘上的页将被更新。即使将被回滚的事务,REDO也是要做的,因为这样简化了恢复过程(但是我相信现代数据库不会这么做的)。3) Undo阶段:这一阶段回滚所有崩溃时未完成的事务。回滚从每个事务的最后一条日志开始,并且按照时间倒序处理UNDO日志(使用日志记录的PrevLSN)。
恢复过程中,事务日志必须留意恢复过程的操作,以便写入磁盘的数据与事务日志相一致。一个解决办法是移除被取消的事务产生的日志记录,但是这个太困难了。相反,ARIES在事务日志中记录补偿日志,来逻辑上删除被取消的事务的日志记录。当事务被『手工』取消,或者被锁管理器取消(为了消除死锁),或仅仅因为网络故障而取消,那么分析阶段就不需要了。对于哪些需要 REDO 哪些需要 UNDO 的信息在 2 个内存表中:事务表(保存当前所有事务的状态)
脏页表(保存哪些数据需要写入磁盘)
当新的事务产生时,这两个表由缓存管理器和事务管理器更新。因为是在内存中,当数据库崩溃时它们也被破坏掉了。分析阶段的任务就是在崩溃之后,用事务日志中的信息重建上述的两个表。为了加快分析阶段,ARIES提出了一个概念:检查点(check point),就是不时地把事务表和脏页表的内容,还有此时最后一条LSN写入磁盘。那么在分析阶段当中,只需要分析这个LSN之后的日志即可。
客户端管理器是处理客户端通信的。客户端可以是一个(网站)服务器或者一个最终用户或最终应用。客户端管理器通过一系列知名的API(JDBC, ODBC, OLE-DB …)提供不同的方式来访问数据库。客户端管理器也提供专有的数据库访问API。
当你连接到数据库时:
管理器首先检查你的验证信息(用户名和密码),然后检查你是否有访问数据库的授权。这些权限由DBA分配。
然后,管理器检查是否有空闲进程(或线程)来处理你对查询。
管理器还会检查数据库是否负载很重。
管理器可能会等待一会儿来获取需要的资源。如果等待时间达到超时时间,它会关闭连接并给出一个可读的错误信息。
然后管理器会把你的查询送给查询管理器来处理。
因为查询处理进程不是『不全则无』的,一旦它从查询管理器得到数据,它会把部分结果保存到一个缓冲区并且开始给你发送。
如果遇到问题,管理器关闭连接,向你发送可读的解释信息,然后释放资源。
查询管理器
这部分是数据库的威力所在,在这部分里,一个写得糟糕的查询可以转换成一个快速执行的代码,代码执行的结果被送到客户端管理器。这个多步骤操作过程如下:查询首先被解析并判断是否合法
然后被重写,去除了无用的操作并且加入预优化部分
接着被优化以便提升性能,并被转换为可执行代码和数据访问计划。
然后计划被编译
最后,被执行
查询解析器每一条SQL语句都要送到解析器来检查语法,如果你的查询有错,解析器将拒绝该查询。比如,如果你写成”SLECT …” 而不是 “SELECT …”,那就没有下文了。但这还不算完,解析器还会检查关键字是否使用正确的顺序,比如 WHERE 写在 SELECT 之前会被拒绝。然后,解析器要分析查询中的表和字段,使用数据库元数据来检查:表是否存在
表的字段是否存在
对某类型字段的 运算 是否 可能(比如,你不能将整数和字符串进行比较,你不能对一个整数使用 substring() 函数)
接着,解析器检查在查询中你是否有权限来读取(或写入)表。再强调一次:这些权限由DBA分配。在解析过程中,SQL 查询被转换为内部表示(通常是一个树)。如果一切正常,内部表示被送到查询重写器。查询重写器在这一步,我们已经有了查询的内部表示,重写器的目标是:预优化查询
避免不必要的运算
帮助优化器找到合理的最佳解决方案
重写器按照一系列已知的规则对查询执行检测。如果查询匹配一种模式的规则,查询就会按照这条规则来重写。下面是(可选)规则的非详尽的列表:视图合并:如果你在查询中使用视图,视图就会转换为它的 SQL 代码。
子查询扁平化:子查询是很难优化的,因此重写器会尝试移除子查询去除不必要的运算符:比如,如果你用了 DISTINCT,而其实你有 UNIQUE 约束(这本身就防止了数据出现重复),那么 DISTINCT 关键字就被去掉了。
排除冗余的联接:如果相同的 JOIN 条件出现两次,比如隐藏在视图中的 JOIN 条件,或者由于传递性产生的无用 JOIN,都会被消除。
常数计算赋值:如果你的查询需要计算,那么在重写过程中计算会执行一次。比如 WHERE AGE > 10+2 会转换为 WHERE AGE > 12 , TODATE(“日期字符串”) 会转换为 datetime 格式的日期值。
(高级)分区裁剪(Partition Pruning):如果你用了分区表,重写器能够找到需要使用的分区。
(高级)物化视图重写(Materialized view rewrite):如果你有个物化视图匹配查询谓词的一个子集,重写器将检查视图是否最新并修改查询,令查询使用物化视图而不是原始表。
(高级)自定义规则:如果你有自定义规则来修改查询(就像 Oracle policy),重写器就会执行这些规则。
(高级)OLAP转换:分析/加窗 函数,星形联接,ROLLUP 函数……都会发生转换(但我不确定这是由重写器还是优化器来完成,因为两个进程联系很紧,必须看是什么数据库)。当你要求数据库收集统计信息,数据库会计算下列值:表中行和页的数量
表中每个列中的:
唯一值
数据长度(最小,最大,平均)
数据范围(最小,最大,平均)
表的索引信息
这些统计信息会帮助优化器估计查询所需的磁盘 I/O、CPU、和内存使用对每个列的统计非常重要。
比如,如果一个表 PERSON 需要联接 2 个列: LAST_NAME, FIRST_NAME。
根据统计信息,数据库知道FIRST_NAME只有 1,000 个不同的值,LAST_NAME 有 1,000,000 个不同的值。
因此,数据库就会按照 LAST_NAME, FIRST_NAME 联接。
因为 LAST_NAME 不大可能重复,多数情况下比较 LAST_NAME 的头 2 、 3 个字符就够了,这将大大减少比较的次数。所有的现代数据库都在用基于成本的优化(即CBO)来优化查询。道理是针对每个运算设置一个成本,通过应用成本最低廉的一系列运算,来找到最佳的降低查询成本的方法。为了理解成本优化器的原理,我觉得最好用个例子来『感受』一下这个任务背后的复杂性。这里我将给出联接 2 个表的 3 个方法,我们很快就能看到即便一个简单的联接查询对于优化器来说都是个噩梦。之后,我们会了解真正的优化器是怎么做的。对于这些联接操作,我会专注于它们的时间复杂度,但是,数据库优化器计算的是它们的 CPU 成本、磁盘 I/O 成本、和内存需求。时间复杂度和 CPU 成本的区别是,时间成本是个近似值(给我这样的懒家伙准备的)。而 CPU 成本,我这里包括了所有的运算,比如:加法、条件判断、乘法、迭代……还有呢:每一个高级代码运算都要特定数量的低级 CPU 运算。
对于 Intel Core i7、Intel Pentium 4、AMD Opteron…等,(就 CPU 周期而言)CPU 的运算成本是不同的,也就是说它取决于 CPU 的架构。
使用时间复杂度就容易多了(至少对我来说),用它我也能了解到 CBO 的概念。由于磁盘 I/O 是个重要的概念,我偶尔也会提到它。请牢记,大多数时候瓶颈在于磁盘 I/O 而不是 CPU 使用。索引在研究 B+树的时候我们谈到了索引,要记住一点,索引都是已经排了序的。仅供参考:还有其他类型的索引,比如位图索引,在 CPU、磁盘I/O、和内存方面与B+树索引的成本并不相同。另外,很多现代数据库为了改善执行计划的成本,可以仅为当前查询动态地生成临时索引。存取路径在应用联接运算符(join operators)之前,你首先需要获得数据。以下就是获得数据的方法。
全扫描如果你读过执行计划,一定看到过『全扫描』(或只是『扫描』)一词。简单的说全扫描就是数据库完整的读一个表或索引。就磁盘 I/O 而言,很明显全表扫描的成本比索引全扫描要高昂。范围扫描其他类型的扫描有索引范围扫描,比如当你使用谓词 ” WHERE AGE > 20 AND AGE < 40 ” 的时候它就会发生。当然,你需要在 AGE 字段上有索引才能用到索引范围扫描。在第一部分我们已经知道,范围查询的时间成本大约是 log(N)+M,这里 N 是索引的数据量,M 是范围内估测的行数。多亏有了统计我们才能知道 N 和 M 的值(注: M 是谓词 “ AGE > 20 AND AGE < 40 ” 的选择率)。另外范围扫描时,你不需要读取整个索引,因此在磁盘 I/O 方面没有全扫描那么昂贵。唯一扫描如果你只需要从索引中取一个值你可以用唯一扫描。根据 ROW ID 存取多数情况下,如果数据库使用索引,它就必须查找与索引相关的行,这样就会用到根据 ROW ID 存取的方式。
其它路径我没有列举所有的存取路径,如果你感兴趣可以读一读 Oracle文档。其它数据库里也许叫法不同但背后的概念是一样的。联接运算符那么,我们知道如何获取数据了,那现在就把它们联接起来!我要展现的是3个个常用联接运算符:合并联接(Merge join),哈希联接(Hash Join)和嵌套循环联接(Nested Loop Join)。但是在此之前,我需要引入新词汇了:内关系和外关系( inner relation and outer relation) 【译者注: “内关系和外关系” 这个说法来源不明,跟查询的”内联接(INNER JOIN) 、外联接(OUTER JOIN) ” 不是一个概念 。只查到百度百科词条:关系数据库 里提到”每个表格(有时被称为一个关系)……” 。 其他参考链接 “Merge Join” “Hash Join” “Nested Loop Join” 】 。 一个关系可以是:一个表
一个索引
上一个运算的中间结果(比如上一个联接运算的结果)
当你联接两个关系时,联接算法对两个关系的处理是不同的。在本文剩余部分,我将假定:外关系是左侧数据集
内关系是右侧数据集
比如, A JOIN B 是 A 和 B 的联接,这里 A 是外关系,B 是内关系。多数情况下, A JOIN B 的成本跟 B JOIN A 的成本是不同的。在这一部分,我还将假定外关系有 N 个元素,内关系有 M 个元素。要记住,真实的优化器通过统计知道 N 和 M 的值。注:N 和 M 是关系的基数。【译者注: 基数 】嵌套循环联接嵌套循环联接是最简单的哈希联接哈希联接更复杂,不过在很多场合比嵌套循环联接成本低哈希联接的道理是:1) 读取内关系的所有元素
2) 在内存里建一个哈希表
3) 逐条读取外关系的所有元素
4) (用哈希表的哈希函数)计算每个元素的哈希值,来查找内关系里相关的哈希桶内
5) 是否与外关系的元素匹配。
在时间复杂度方面我需要做些假设来简化问题:内关系被划分成 X 个哈希桶
哈希函数几乎均匀地分布每个关系内数据的哈希值,就是说哈希桶大小一致。
外关系的元素与哈希桶内的所有元素的匹配,成本是哈希桶内元素的数量。
时间复杂度是 (M/X) * N + 创建哈希表的成本(M) + 哈希函数的成本 * N 。
如果哈希函数创建了足够小规模的哈希桶,那么复杂度就是 O(M+N)。还有个哈希联接的版本,对内存有利但是对磁盘 I/O 不够有利。 这回是这样的:1) 计算内关系和外关系双方的哈希表
2) 保存哈希表到磁盘
3) 然后逐个哈希桶比较(其中一个读入内存,另一个逐行读取)。
合并联接合并联接是唯一产生排序的联接算法。注:这个简化的合并联接不区分内表或外表;两个表扮演同样的角色。但是真实的实现方式是不同的,比如当处理重复值时。1.(可选)排序联接运算:两个输入源都按照联接关键字排序。2.合并联接运算:排序后的输入源合并到一起。排序我们已经谈到过合并排序,在这里合并排序是个很好的算法(但是并非最好的,如果内存足够用的话,还是哈希联接更好)。然而有时数据集已经排序了,比如:如果表内部就是有序的,比如联接条件里一个索引组织表 【译者注: index-organized table 】
如果关系是联接条件里的一个索引
如果联接应用在一个查询中已经排序的中间结果
空闲内存:没有足够的内存的话就跟强大的哈希联接拜拜吧(至少是完全内存中哈希联接)。
两个数据集的大小。比如,如果一个大表联接一个很小的表,那么嵌套循环联接就比哈希联接快,因为后者有创建哈希的高昂成本;如果两个表都非常大,那么嵌套循环联接CPU成本就很高昂。
是否有索引:有两个 B+树索引的话,聪明的选择似乎是合并联接。
结果是否需要排序:即使你用到的是未排序的数据集,你也可能想用成本较高的合并联接(带排序的),因为最终得到排序的结果后,你可以把它和另一个合并联接串起来(或者也许因为查询用 ORDER BY/GROUP BY/DISTINCT 等操作符隐式或显式地要求一个排序结果)。
关系是否已经排序:这时候合并联接是最好的候选项。
联接的类型:是等值联接(比如 tableA.col1 = tableB.col2 )? 还是内联接?外联接?笛卡尔乘积?或者自联接?有些联接在特定环境下是无法工作的。
数据的分布:如果联接条件的数据是倾斜的(比如根据姓氏来联接人,但是很多人同姓),用哈希联接将是个灾难,原因是哈希函数将产生分布极不均匀的哈希桶。
如果你希望联接操作使用多线程或多进程。
动态规划,贪婪算法和启发式算法关系型数据库会尝试我刚刚提到的多种方法,优化器真正的工作是在有限时间里找到一个好的解决方案。多数时候,优化器找到的不是最佳的方案,而是一个『不错』的对于小规模的查询,采取粗暴的方式是有可能的。但是为了让中等规模的查询也能采取粗暴的方式,我们有办法避免不必要的计算,这就是动态规划。动态规划这几个字背后的理念是,很多执行计划是非常相似的。
贪婪算法但是,优化器面对一个非常大的查询,或者为了尽快找到答案(然而查询速度就快不起来了),会应用另一种算法,叫贪婪算法。原理是按照一个规则(或启发)以渐进的方式制定查询计划。在这个规则下,贪婪算法逐步寻找最佳算法,先处理一条JOIN,接着每一步按照同样规则加一条新的JOIN。我们来看个简单的例子。比如一个针对5张表(A,B,C,D,E)4次JOIN 的查询,为了简化我们把嵌套JOIN作为可能的联接方式,按照『使用最低成本的联接』规则。直接从 5 个表里选一个开始(比如 A)
计算每一个与 A 的联接(A 作为内关系或外关系)
发现 “A JOIN B” 成本最低
计算每一个与 “A JOIN B” 的结果联接的成本(”A JOIN B” 作为内关系或外关系)
发现 “(A JOIN B) JOIN C” 成本最低
计算每一个与 “(A JOIN B) JOIN C” 的结果联接的成本 ……
最后确定执行计划 “( ( (A JOIN B) JOIN C) JOIN D ) JOIN E )”
因为我们是武断地从表 A 开始,我们可以把同样的算法用在 B,然后 C,然后 D, 然后 E。最后保留成本最低的执行计划。顺便说一句,这个算法有个名字,叫『最近邻居算法』。抛开细节不谈,只需一个良好的模型和一个 Nlog(N) 复杂度的排序,问题就轻松解决了。这个算法的复杂度是 O(Nlog(N)) ,对比一下完全动态规划的 O(3^N)。如果你有个20个联接的大型查询,这意味着 26 vs 3,486,784,401 ,天壤之别!这个算法的问题是,我们做的假设是:找到 2 个表的最佳联接方法,保留这个联接结果,再联接下一个表,就能得到最低的成本。但是:即使在 A, B, C 之间,A JOIN B 可得最低成本
(A JOIN C) JOIN B 也许比 (A JOIN B) JOIN C 更好。
为了改善这一状况,你可以多次使用基于不同规则的贪婪算法,并保留最佳的执行计划。其他算法[ 如果你已经受够了算法话题,就直接跳到下一部分。这部分对文章余下的内容不重要。] 【译者注:我也很想把这段跳过去 -_- 】很多计算机科学研究者热衷于寻找最佳的执行计划,他们经常为特定问题或模式探寻更好的解决方案,比如:如果查询是星型联接(一种多联接查询),某些数据库使用一种特定的算法。
如果查询是并行的,某些数据库使用一种特定的算法。 ……
其他算法也在研究之中,就是为了替换在大型查询中的动态规划算法。贪婪算法属于一个叫做启发式算法的大家族,它根据一条规则(或启发),保存上一步找到的方法,『附加』到当前步骤来进一步搜寻解决方法。有些算法根据特定规则,一步步的应用规则但不总是保留上一步找到的最佳方法。它们统称启发式算法。比如,基因算法就是一种:一个方法代表一种可能的完整查询计划
每一步保留了 P 个方法(即计划),而不是一个。
0) P 个计划随机创建
1) 成本最低的计划才会保留
2) 这些最佳计划混合在一起产生 P 个新的计划
3) 一些新的计划被随机改写
4) 1,2,3步重复 T 次
5) 然后在最后一次循环,从 P 个计划里得到最佳计划。
循环次数越多,计划就越好。我们来看看 SQLite 优化器 是怎么工作的。这是个轻量化数据库,它使用一种简单优化器,基于带有附加规则的贪婪算法,来限制可能性的数量。SQLite 在有 CROSS JOIN 操作符时从不给表重新排序
使用嵌套联接
外联接始终按顺序评估
……
3.8.0之前的版本使用『最近邻居』贪婪算法来搜寻最佳查询计划
等等……我们见过这个算法!真是巧哈!
从3.8.0版本(发布于2015年)开始,SQLite使用『N最近邻居』贪婪算法来搜寻最佳查询计划
我们再看看另一个优化器是怎么工作的。IBM DB2 跟所有企业级数据库都类似,我讨论它是因为在切换到大数据之前,它是我最后真正使用的数据库。看过官方文档后,我们了解到 DB2 优化器可以让你使用 7 种级别的优化:对联接使用贪婪算法
0 – 最小优化,使用索引扫描和嵌套循环联接,避免一些查询重写
1 – 低级优化
2 – 完全优化
对联接使用动态规划算法
3 – 中等优化和粗略的近似法
5 – 完全优化,使用带有启发式的所有技术
7 – 完全优化,类似级别5,但不用启发式
9 – 最大优化,完全不顾开销,考虑所有可能的联接顺序,包括笛卡尔乘积
可以看到 DB2 使用贪婪算法和动态规划算法。当然,他们不会把自己的启发算法分享出来的,因为查询优化器是数据库的看家本领。DB2 的默认级别是 5,优化器使用下列特性: 【译者注:以下出现的一些概念我没有做考证,因为[ 这段不重要,可以跳过 ]】使用所有可用的统计,包括线段树(frequent-value)和分位数统计(quantile statistics)。
使用所有查询重写规则(含物化查询表路由,materialized query table routing),除了在极少情况下适用的计算密集型规则。
使用动态规划模拟联接
有限使用组合内关系(composite inner relation)
对于涉及查找表的星型模式,有限使用笛卡尔乘积
考虑宽泛的访问方式,含列表预取(list prefetch,注:我们将讨论什么是列表预取),index ANDing(注:一种对索引的特殊操作),和物化查询表路由。
默认的,DB2 对联接排列使用受启发式限制的动态规划算法。其它情况 (GROUP BY, DISTINCT…) 由简单规则处理。
查询计划缓存由于创建查询计划是耗时的,大多数据库把计划保存在查询计划缓存,来避免重复计算。这个话题比较大,因为数据库需要知道什么时候更新过时的计划。办法是设置一个上限,如果一个表的统计变化超过了上限,关于该表的查询计划就从缓存中清除。查询执行器在这个阶段,我们有了一个优化的执行计划,再编译为可执行代码。然后,如果有足够资源(内存,CPU),查询执行器就会执行它。计划中的操作符 (JOIN, SORT BY …) 可以顺序或并行执行,这取决于执行器。为了获得和写入数据,查询执行器与数据管理器交互,本文下一部分来讨论数据管理器在这一步,查询管理器执行了查询,需要从表和索引获取数据,于是向数据管理器提出请求。但是有 2 个问题:关系型数据库使用事务模型,所以,当其他人在同一时刻使用或修改数据时,你无法得到这部分数据。
数据提取是数据库中速度最慢的操作,所以数据管理器需要足够聪明地获得数据并保存在内存缓冲区内。
在这一部分,我没看看关系型数据库是如何处理这两个问题的。我不会讲数据管理器是怎么获得数据的,因为这不是最重要的(而且本文已经够长的了!)。
缓存管理器我已经说过,数据库的主要瓶颈是磁盘 I/O。为了提高性能,现代数据库使用缓存管理器。查询执行器不会直接从文件系统拿数据,而是向缓存管理器要。缓存管理器有一个内存缓存区,叫做缓冲池,从内存读取数据显著地提升数据库性能。对此很难给出一个数量级,因为这取决于你需要的是哪种操作:顺序访问(比如:全扫描) vs 随机访问(比如:按照row id访问)
读还是写
以及数据库使用的磁盘类型:7.2k/10k/15k rpm的硬盘
SSD
RAID 1/5/…
要我说,内存比磁盘要快100到10万倍。然而,这导致了另一个问题(数据库总是这样…),缓存管理器需要在查询执行器使用数据之前得到数据,否则查询管理器不得不等待数据从缓慢的磁盘中读出来。预读这个问题叫预读。查询执行器知道它将需要什么数据,因为它了解整个查询流,而且通过统计也了解磁盘上的数据。道理是这样的:当查询执行器处理它的第一批数据时
会告诉缓存管理器预先装载第二批数据
当开始处理第二批数据时
告诉缓存管理器预先装载第三批数据,并且告诉缓存管理器第一批可以从缓存里清掉了。
……
缓存管理器在缓冲池里保存所有的这些数据。为了确定一条数据是否有用,缓存管理器给缓存的数据添加了额外的信息(叫闩锁)。有时查询执行器不知道它需要什么数据,有的数据库也不提供这个功能。相反,它们使用一种推测预读法(比如:如果查询执行器想要数据1、3、5,它不久后很可能会要 7、9、11),或者顺序预读法(这时候缓存管理器只是读取一批数据后简单地从磁盘加载下一批连续数据)。为了监控预读的工作状况,现代数据库引入了一个度量叫缓冲/缓存命中率,用来显示请求的数据在缓存中找到而不是从磁盘读取的频率。注:糟糕的缓存命中率不总是意味着缓存工作状态不佳。更多信息请阅读Oracle文档。缓冲只是容量有限的内存空间,因此,为了加载新的数据,它需要移除一些数据。加载和清除缓存需要一些磁盘和网络I/O的成本。如果你有个经常执行的查询,那么每次都把查询结果加载然后清除,效率就太低了。现代数据库用缓冲区置换策略来解决这个问题。
缓冲区置换策略多数现代数据库(至少 SQL Server, MySQL, Oracle 和 DB2)使用 LRU 算法。LRULRU代表最近最少使用(Least Recently Used)算法,背后的原理是:在缓存里保留的数据是最近使用的,所以更有可能再次使用。
图解:
为了更好的理解,我假设缓冲区里的数据没有被闩锁锁住(就是说是可以被移除的)。在这个简单的例子里,缓冲区可以保存 3 个元素:1:缓存管理器(简称CM)使用数据1,把它放入空的缓冲区
2:CM使用数据4,把它放入半载的缓冲区
3:CM使用数据3,把它放入半载的缓冲区
4:CM使用数据9,缓冲区满了,所以数据1被清除,因为它是最后一个最近使用的,数据9加入到缓冲区
5:CM使用数据4,数据4已经在缓冲区了,所以它再次成为第一个最近使用的。
6:CM使用数据1,缓冲区满了,所以数据9被清除,因为它是最后一个最近使用的,数据1加入到缓冲区
……
这个算法效果很好,但是有些限制。如果对一个大表执行全表扫描怎么办?换句话说,当表/索引的大小超出缓冲区会发生什么?使用这个算法会清除之前缓存内所有的数据,而且全扫描的数据很可能只使用一次。改进为了防止这个现象,有些数据库增加了特殊的规则,比如Oracle文档中的描述:『对非常大的表来说,数据库通常使用直接路径来读取,即直接加载区块[……],来避免填满缓冲区。对于中等大小的表,数据库可以使用直接读取或缓存读取。如果选择缓存读取,数据库把区块置于LRU的尾部,防止清空当前缓冲区。』
还有一些可能,比如使用高级版本的LRU,叫做 LRU-K。例如,SQL Server 使用 LRU-2。这个算法的原理是把更多的历史记录考虑进来。简单LRU(也就是 LRU-1),只考虑最后一次使用的数据。LRU-K呢:考虑数据最后第K次使用的情况
数据使用的次数加进了权重
一批新数据加载进入缓存,旧的但是经常使用的数据不会被清除(因为权重更高)
但是这个算法不会保留缓存中不再使用的数据
所以数据如果不再使用,权重值随着时间推移而降低
计算权重是需要成本的,所以SQL Server只是使用 K=2,这个值性能不错而且额外开销可以接受。其他算法当然还有其他管理缓存的算法,比如:2Q(类LRU-K算法)
CLOCK(类LRU-K算法)
MRU(最新使用的算法,用LRU同样的逻辑但不同的规则)
LRFU(Least Recently and Frequently Used,最近最少使用最近最不常用)
……
写缓冲区我只探讨了读缓存 —— 在使用之前预先加载数据。用来保存数据、成批刷入磁盘,而不是逐条写入数据从而造成很多单次磁盘访问。要记住,缓冲区保存的是页(最小的数据单位)而不是行(逻辑上/人类习惯的观察数据的方式)。缓冲池内的页如果被修改了但还没有写入磁盘,就是脏页。有很多算法来决定写入脏页的最佳时机,但这个问题与事务的概念高度关联,下面我们就谈谈事务。
事务管理器最后但同样重要的,是事务管理器,我们将看到这个进程是如何保证每个查询在自己的事务内执行的。但开始之前,我们需要理解ACID事务的概念。现代数据库不会使用纯粹的隔离作为默认模式,因为它会带来巨大的性能消耗。SQL一般定义4个隔离级别:串行化(Serializable,SQLite默认模式):最高级别的隔离。两个同时发生的事务100%隔离,每个事务有自己的『世界』。
可重复读(Repeatable read,MySQL默认模式):每个事务有自己的『世界』,除了一种情况。如果一个事务成功执行并且添加了新数据,这些数据对其他正在执行的事务是可见的。但是如果事务成功修改了一条数据,修改结果对正在运行的事务不可见。所以,事务之间只是在新数据方面突破了隔离,对已存在的数据仍旧隔离。
举个例子,如果事务A运行”SELECT count(1) from TABLE_X” ,然后事务B在 TABLE_X 加入一条新数据并提交,当事务A再运行一次 count(1)结果不会是一样的。
这叫幻读(phantom read)。
读取已提交(Read committed,Oracle、PostgreSQL、SQL Server默认模式):可重复读+新的隔离突破。如果事务A读取了数据D,然后数据D被事务B修改(或删除)并提交,事务A再次读取数据D时数据的变化(或删除)是可见的。
这叫不可重复读(non-repeatable read)。
读取未提交(Read uncommitted):最低级别的隔离,是读取已提交+新的隔离突破。如果事务A读取了数据D,然后数据D被事务B修改(但并未提交,事务B仍在运行中),事务A再次读取数据D时,数据修改是可见的。如果事务B回滚,那么事务A第二次读取的数据D是无意义的,因为那是事务B所做的从未发生的修改(已经回滚了嘛)。
这叫脏读(dirty read)。
多数数据库添加了自定义的隔离级别(比如 PostgreSQL、Oracle、SQL Server的快照隔离),而且并没有实现SQL规范里的所有级别(尤其是读取未提交级别)。默认的隔离级别可以由用户/开发者在建立连接时覆盖(只需要增加很简单的一行代码)。
并发控制确保隔离性、一致性和原子性的真正问题是对相同数据的写操作(增、更、删):如果所有事务只是读取数据,它们可以同时工作,不会更改另一个事务的行为。
如果(至少)有一个事务在修改其他事务读取的数据,数据库需要找个办法对其它事务隐藏这种修改。而且,它还需要确保这个修改操作不会被另一个看不到这些数据修改的事务擦除。
这个问题叫并发控制。最简单的解决办法是依次执行每个事务(即顺序执行),但这样就完全没有伸缩性了,在一个多处理器/多核服务器上只有一个核心在工作,效率很低。理想的办法是,每次一个事务创建或取消时:监控所有事务的所有操作
检查是否2个(或更多)事务的部分操作因为读取/修改相同的数据而存在冲突
重新编排冲突事务中的操作来减少冲突的部分
按照一定的顺序执行冲突的部分(同时非冲突事务仍然在并发运行)
考虑事务有可能被取消
用更正规的说法,这是对冲突的调度问题。更具体点儿说,这是个非常困难而且CPU开销很大的优化问题。企业级数据库无法承担等待几个小时,来寻找每个新事务活动最好的调度,因此就使用不那么理想的方式以避免更多的时间浪费在解决冲突上。
锁管理器为了解决这个问题,多数数据库使用锁和/或数据版本控制。这是个很大的话题,我会集中探讨锁,和一点点数据版本控制。悲观锁原理是:如果一个事务需要一条数据
它就把数据锁住
如果另一个事务也需要这条数据
它就必须要等第一个事务释放这条数据
这个锁叫排他锁。
但是对一个仅仅读取数据的事务使用排他锁非常昂贵,因为这会迫使其它只需要读取相同数据的事务等待。因此就有了另一种锁,共享锁。共享锁是这样的:如果一个事务只需要读取数据A
它会给数据A加上『共享锁』并读取
如果第二个事务也需要仅仅读取数据A
它会给数据A加上『共享锁』并读取
如果第三个事务需要修改数据A
它会给数据A加上『排他锁』,但是必须等待另外两个事务释放它们的共享锁。
同样的,如果一块数据被加上排他锁,一个只需要读取该数据的事务必须等待排他锁释放才能给该数据加上共享锁。锁管理器是添加和释放锁的进程,在内部用一个哈希表保存锁信息(关键字是被锁的数据),并且了解每一块数据是:被哪个事务加的锁
哪个事务在等待数据解锁
死锁但是使用锁会导致一种情况,2个事务永远在等待一块数据:
在本图中:
事务A 给 数据1 加上排他锁并且等待获取数据2
事务B 给 数据2 加上排他锁并且等待获取数据1
这叫死锁。在死锁发生时,锁管理器要选择取消(回滚)一个事务,以便消除死锁。这可是个艰难的决定:杀死数据修改量最少的事务(这样能减少回滚的成本)?
杀死持续时间最短的事务,因为其它事务的用户等的时间更长?
杀死能用更少时间结束的事务(避免可能的资源饥荒)?
一旦发生回滚,有多少事务会受到回滚的影响?
在作出选择之前,锁管理器需要检查是否有死锁存在。哈希表可以看作是个图表(见上文图),图中出现循环就说明有死锁。由于检查循环是昂贵的(所有锁组成的图表是很庞大的),经常会通过简单的途径解决:使用超时设定。如果一个锁在超时时间内没有加上,那事务就进入死锁状态。锁管理器也可以在加锁之前检查该锁会不会变成死锁,但是想要完美的做到这一点还是很昂贵的。因此这些预检经常设置一些基本规则。两段锁实现纯粹的隔离最简单的方法是:事务开始时获取锁,结束时释放锁。就是说,事务开始前必须等待确保自己能加上所有的锁,当事务结束时释放自己持有的锁。这是行得通的,但是为了等待所有的锁,大量的时间被浪费了。更快的方法是两段锁协议(Two-Phase Locking Protocol,由 DB2 和 SQL Server使用),在这里,事务分为两个阶段:成长阶段:事务可以获得锁,但不能释放锁。
收缩阶段:事务可以释放锁(对于已经处理完而且不会再次处理的数据),但不能获得新锁。
这两条简单规则背后的原理是:释放不再使用的锁,来降低其它事务的等待时间
防止发生这类情况:事务最初获得的数据,在事务开始后被修改,当事务重新读取该数据时发生不一致。
这个规则可以很好地工作,但有个例外:如果修改了一条数据、释放了关联的锁后,事务被取消(回滚),而另一个事务读到了修改后的值,但最后这个值却被回滚。为了避免这个问题,所有独占锁必须在事务结束时释放。多说几句当然了,真实的数据库使用更复杂的系统,涉及到更多类型的锁(比如意向锁,intention locks)和更多的粒度(行级锁、页级锁、分区锁、表锁、表空间锁),但是道理是相同的。我只探讨纯粹基于锁的方法,数据版本控制是解决这个问题的另一个方法。版本控制是这样的:每个事务可以在相同时刻修改相同的数据
每个事务有自己的数据拷贝(或者叫版本)
如果2个事务修改相同的数据,只接受一个修改,另一个将被拒绝,相关的事务回滚(或重新运行)
这将提高性能,因为:读事务不会阻塞写事务
写事务不会阻塞读
没有『臃肿缓慢』的锁管理器带来的额外开销
除了两个事务写相同数据的时候,数据版本控制各个方面都比锁表现得更好。只不过,你很快就会发现磁盘空间消耗巨大。数据版本控制和锁机制是两种不同的见解:乐观锁和悲观锁。两者各有利弊,完全取决于使用场景(读多还是写多)。关于数据版本控制,我推荐这篇非常优秀的文章,讲的是PostgreSQL如何实现多版本并发控制的。一些数据库,比如DB2(直到版本 9.7)和 SQL Server(不含快照隔离)仅使用锁机制。其他的像PostgreSQL, MySQL 和 Oracle 使用锁和鼠标版本控制混合机制。我不知道是否有仅用版本控制的数据库(如果你知道请告诉我)。[2015-08-20更新]一名读者告诉我:Firebird 和 Interbase 用不带锁的版本控制。版本控制对索引的影响挺有趣的:有时唯一索引会出现重复,索引的条目会多于表行数,等等。
如果你读过不同级别的隔离那部分内容,你会知道,提高隔离级别就会增加锁的数量和事务等待加锁的时间。这就是为什么多数数据库默认不会使用最高级别的隔离(即串行化)。当然,你总是可以自己去主流数据库(像MySQL, PostgreSQL 或 Oracle)的文档里查一下。
日志管理器我们已经知道,为了提升性能,数据库把数据保存在内存缓冲区内。但如果当事务提交时服务器崩溃,崩溃时还在内存里的数据会丢失,这破坏了事务的持久性。你可以把所有数据都写在磁盘上,但是如果服务器崩溃,最终数据可能只有部分写入磁盘,这破坏了事务的原子性。事务作出的任何修改必须是或者撤销,或者完成。有 2 个办法解决这个问题:影子副本/页(Shadow copies/pages):每个事务创建自己的数据库副本(或部分数据库的副本),并基于这个副本来工作。一旦出错,这个副本就被移除;一旦成功,数据库立即使用文件系统的一个把戏,把副本替换到数据中,然后删掉『旧』数据。
事务日志(Transaction log):事务日志是一个存储空间,在每次写盘之前,数据库在事务日志中写入一些信息,这样当事务崩溃或回滚,数据库知道如何移除或完成尚未完成的事务。
WAL(预写式日志)影子副本/页在运行较多事务的大型数据库时制造了大量磁盘开销,所以现代数据库使用事务日志。事务日志必须保存在稳定的存储上,我不会深挖存储技术,但至少RAID磁盘是必须的,以防磁盘故障。多数数据库(至少是Oracle, SQL Server, DB2, PostgreSQL, MySQL 和 SQLite) 使用预写日志协议(Write-Ahead Logging protocol ,WAL)来处理事务日志。WAL协议有 3 个规则:1) 每个对数据库的修改都产生一条日志记录,在数据写入磁盘之前日志记录必须写入事务日志。
2) 日志记录必须按顺序写入;记录 A 发生在记录 B 之前,则 A 必须写在 B 之前。
3) 当一个事务提交时,在事务成功之前,提交顺序必须写入到事务日志。
这个工作由日志管理器完成。简单的理解就是,日志管理器处于缓存管理器(cache manager)和数据访问管理器(data access manager,负责把数据写入磁盘)之间,每个 update / delete / create / commit / rollback 操作在写入磁盘之前先写入事务日志。简单,对吧?回答错误! 我们研究了这么多内容,现在你应该知道与数据库相关的每一件事都带着『数据库效应』的诅咒。好吧,我们说正经的,问题在于,如何找到写日志的同时保持良好的性能的方法。如果事务日志写得太慢,整体都会慢下来。
1992年,IBM 研究人员『发明』了WAL的增强版,叫 ARIES。ARIES 或多或少地在现代数据库中使用,逻辑未必相同,但AIRES背后的概念无处不在。我给发明加了引号是因为,按照MIT这门课的说法,IBM 的研究人员『仅仅是写了事务恢复的最佳实践方法』。AIRES 论文发表的时候我才 5 岁,我不关心那些酸溜溜的科研人员老掉牙的闲言碎语。事实上,我提及这个典故,是在开始探讨最后一个技术点前让你轻松一下。我阅读过这篇 ARIES 论文 的大量篇幅,发现它很有趣。在这一部分我只是简要的谈一下 ARIES,不过我强烈建议,如果你想了解真正的知识,就去读那篇论文。ARIES 代表『数据库恢复原型算法』(Algorithms for Recovery and Isolation Exploiting Semantics)。这个技术要达到一个双重目标:1) 写日志的同时保持良好性能
2) 快速和可靠的数据恢复
有多个原因让数据库不得不回滚事务:因为用户取消
因为服务器或网络故障
因为事务破坏了数据库完整性(比如一个列有唯一性约束而事务添加了重复值)
因为死锁
有时候(比如网络出现故障),数据库可以恢复事务。这怎么可能呢?为了回答这个问题,我们需要了解日志里保存的信息。
日志
事务的每一个操作(增/删/改)产生一条日志,由如下内容组成:LSN:一个唯一的日志序列号(Log Sequence Number)。LSN是按时间顺序分配的 * ,这意味着如果操作 A 先于操作 B,log A 的 LSN 要比 log B 的 LSN 小。
TransID:产生操作的事务ID。
PageID:被修改的数据在磁盘上的位置。磁盘数据的最小单位是页,所以数据的位置就是它所处页的位置。
PrevLSN:同一个事务产生的上一条日志记录的链接。
UNDO:取消本次操作的方法。
比如,如果操作是一次更新,UNDO将或者保存元素更新前的值/状态(物理UNDO),或者回到原来状态的反向操作(逻辑UNDO) 。
REDO:重复本次操作的方法。 同样的,有 2 种方法:或者保存操作后的元素值/状态,或者保存操作本身以便重复。
…:(供您参考,一个 ARIES 日志还有 2 个字段:UndoNxtLSN 和 Type)。
进一步说,磁盘上每个页(保存数据的,不是保存日志的)都记录着最后一个修改该数据操作的LSN。*LSN的分配其实更复杂,因为它关系到日志存储的方式。但道理是相同的。 ARIES 只使用逻辑UNDO,因为处理物理UNDO太过混乱了。注:据我所知,只有 PostgreSQL 没有使用UNDO,而是用一个垃圾回收服务来删除旧版本的数据。这个跟 PostgreSQL 对数据版本控制的实现有关。为了更好的说明这一点,这有一个简单的日志记录演示图,是由查询 “UPDATE FROM PERSON SET AGE = 18;” 产生的,我们假设这个查询是事务18执行的。【译者注: SQL 语句原文如此,应该是作者笔误 】每条日志都有一个唯一的LSN,链接在一起的日志属于同一个事务。日志按照时间顺序链接(链接列表的最后一条日志是最后一个操作产生的)。日志缓冲区为了防止写日志成为主要的瓶颈,数据库使用了日志缓冲区。
当查询执行器要求做一次修改:
1) 缓存管理器将修改存入自己的缓冲区;
2) 日志管理器将相关的日志存入自己的缓冲区;
3) 到了这一步,查询执行器认为操作完成了(因此可以请求做另一次修改);
4) 接着(不久以后)日志管理器把日志写入事务日志,什么时候写日志由某算法来决定。
5) 接着(不久以后)缓存管理器把修改写入磁盘,什么时候写盘由某算法来决定。
当事务提交,意味着事务每一个操作的 1 2 3 4 5 步骤都完成了。写事务日志是很快的,因为它只是『在事务日志某处增加一条日志』;而数据写盘就更复杂了,因为要用『能够快速读取的方式写入数据』。STEAL 和 FORCE 策略出于性能方面的原因,第 5 步有可能在提交之后完成,因为一旦发生崩溃,还有可能用REDO日志恢复事务。这叫做 NO-FORCE策略。数据库可以选择FORCE策略(比如第 5 步在提交之前必须完成)来降低恢复时的负载。另一个问题是,要选择数据是一步步的写入(STEAL策略),还是缓冲管理器需要等待提交命令来一次性全部写入(NO-STEAL策略)。选择STEAL还是NO-STEAL取决于你想要什么:快速写入但是从 UNDO 日志恢复缓慢,还是快速恢复。总结一下这些策略对恢复的影响:STEAL/NO-FORCE 需要 UNDO 和 REDO: 性能高,但是日志和恢复过程更复杂 (比如 ARIES)。多数数据库选择这个策略。 注:这是我从多个学术论文和教程里看到的,但并没有看到官方文档里显式说明这一点。
STEAL/ FORCE 只需要 UNDO.
NO-STEAL/NO-FORCE 只需要 REDO.
NO-STEAL/FORCE 什么也不需要: 性能最差,而且需要巨大的内存。
关于恢复Ok,有了不错的日志,我们来用用它们!假设新来的实习生让数据库崩溃了(首要规矩:永远是实习生的错。),你重启了数据库,恢复过程开始了。ARIES从崩溃中恢复有三个阶段:1) 分析阶段:恢复进程读取全部事务日志,来重建崩溃过程中所发生事情的时间线,决定哪个事务要回滚(所有未提交的事务都要回滚)、崩溃时哪些数据需要写盘。
2) Redo阶段:这一关从分析中选中的一条日志记录开始,使用 REDO 来将数据库恢复到崩溃之前的状态。
在REDO阶段,REDO日志按照时间顺序处理(使用LSN)。对每一条日志,恢复进程需要读取包含数据的磁盘页LSN。如果LSN(磁盘页)>= LSN(日志记录),说明数据已经在崩溃前写到磁盘(但是值已经被日志之后、崩溃之前的某个操作覆盖),所以不需要做什么。如果LSN(磁盘页)< LSN(日志记录),那么磁盘上的页将被更新。即使将被回滚的事务,REDO也是要做的,因为这样简化了恢复过程(但是我相信现代数据库不会这么做的)。3) Undo阶段:这一阶段回滚所有崩溃时未完成的事务。回滚从每个事务的最后一条日志开始,并且按照时间倒序处理UNDO日志(使用日志记录的PrevLSN)。
恢复过程中,事务日志必须留意恢复过程的操作,以便写入磁盘的数据与事务日志相一致。一个解决办法是移除被取消的事务产生的日志记录,但是这个太困难了。相反,ARIES在事务日志中记录补偿日志,来逻辑上删除被取消的事务的日志记录。当事务被『手工』取消,或者被锁管理器取消(为了消除死锁),或仅仅因为网络故障而取消,那么分析阶段就不需要了。对于哪些需要 REDO 哪些需要 UNDO 的信息在 2 个内存表中:事务表(保存当前所有事务的状态)
脏页表(保存哪些数据需要写入磁盘)
当新的事务产生时,这两个表由缓存管理器和事务管理器更新。因为是在内存中,当数据库崩溃时它们也被破坏掉了。分析阶段的任务就是在崩溃之后,用事务日志中的信息重建上述的两个表。为了加快分析阶段,ARIES提出了一个概念:检查点(check point),就是不时地把事务表和脏页表的内容,还有此时最后一条LSN写入磁盘。那么在分析阶段当中,只需要分析这个LSN之后的日志即可。
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
查看数据库支持的存储引擎: \G或者分号表示命令结束 MySQL>show engines \G or show variables like ‘have%’; mysql -h localhost -u root -p123 show databases; use database; show tables;
基础架构
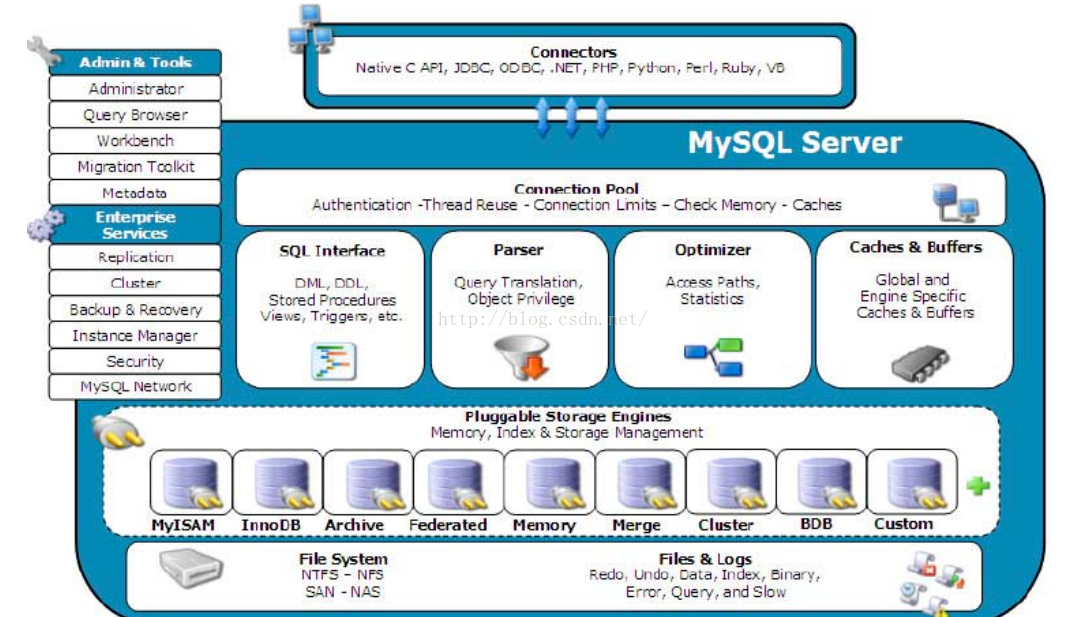
 GHOST工作原理:
GHOST工作原理: