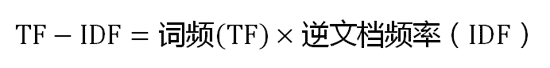SBT = (not so) Simple Build Tool,是scala的构建工具,与java的maven地位相同。其设计宗旨是让简单的项目可以简单的配置,而复杂的项目可以复杂的配置。。。
sbt项目的目录规约
和maven一样,sbt有约定了一个通用的目录结构,使用约定的结构会使后面的工作简单很多。
base/
build.sbt //构建配置文件
/project //也是构建配置的一部分
/build.scala //高级配置,可选
/src/
/main
/scala
/java
/resources
/test
/scala
/java
/resources
base代表项目的根目录
项目配置可以在build.sbt文件里定义,也可以在base/project/build.scala文件里定义,一般情况下build.sbt就已经足够,除非多工程项目或者需要很多特殊定义的项目
常用命令
在我读完sbt的getting started文档之前,我也经常有疑问:为什么scala不沿用maven,而要搞出sbt这么个(not so simple) Simple Build Tool ?
在读完文档,并实际操作后,我现在感觉确实是物有所值的。
checkout 我的sbtTemple项目后,进入命令行,进入到项目根目录,输入sbt回车进入sbt交互模式
sbt有哪些命令可用?输入help命令查询,即会列出一堆可用的命令,比如exit,reload等,不知道某个命令的作用?help 命令名,比如输入help exit显示exit命令的作用。
列出的命令里并没有compile,test等常用的命令?因为那些不是sbt的命令而是当前工程的task. 输入 tasks命令,就可以看见 compile,test,package等等任务的说明了。
想查看项目的配置?用show命令,输入show name,看当前项目的名字,输入show libraryDependencies看当前项目依赖的库,libraryDependencies太长记不住?输入lib后按tab键! 交互窗口是有tab提示的!输入help show,你可以看到show命令的作用是显示配置的值,如果show之后跟的是任务,则执行该任务并显示任务执行的结果。 你可以试试show compile看什么结果,如果你不想执行compile,而是想看命令的说明,请用inspect命令,inspect命令比较复杂,执行后输出的结果也比较复杂,具体这个命令的作用是什么请help inspect, 不过得等理解了build definition的含义后才能看懂help说的是什么。。。
常用的任务则有compile, test, run,package,doc等,请顾名思义或自行help之。另外这些任务常常还有些变种,比如package-doc,package-src等,用tasks命令查看任务的列表,必有一款适合您
有一个强大的任务不得不特别拎出来说一下:console
输入console回车,会在当前会话内启动一个REPL,不要告诉我你不知道REPL是scala解释器的意思。。。就是你在命令行下输入scala回车后进入的那个交互界面。
强大的是,sbt会加载你的项目依赖的全部jar包和你自己的代码! 你可以在这个解释器里实验你的半成品。 我的模板工程里有一个sample/Account.scala文件,十几行很简单的代码,你可以看一下,然后在console窗口里玩弄Account类和Account伴生对象. 不过别忘了先import sample._
因为依赖的jar包也都被加载了,所以对于那些你可能还不熟悉的第三方库,你有可以在console里玩个痛快!这功能很给力,谁用谁知道。
顺便在提一下,sbt命令有3种执行模式:
1、交互式,即上文所描述的
2、批处理式,即在命令行下输入sbt 命令名来执行,比如sbt compile就会编译代码,而不进入交互模式
3、连绵不绝式,在命令名前加上~号,即会进入连绵不绝模式,比如~compile,会编译当前代码,然后监听代码改变,每当你编辑了代码并保存后,sbt就会自动编译代码,~test也一样,当你修改代码后自动编译并运行单元测试。按回车键可退出此模式。
build definition释义
你前面应该试过show name和show libraryDependencies了吧?show出来的结果就是来自你的build.sbt文件,也就是build definition了。打开build.sbt就可以看到name := “sbt11template” 还有其他的一堆xxx := xxxx,很显然的,这就是个key-value pair, sbt就是读取配置文件并构建一个key-value的map. 但是在build.sbt里面并非key := value, 而是key := expression. 文件里的每一行其实是一句scala语句,不行你可以试试把
name := “sbt11template” 改成
name := {“sbt11template”.toUpperCase}
然后reload, 再show name,你会看到变成大写的SBT11TEMPLATE
:=是最常用的方法,其作用就是将key设置成expression的值,相同的key如果被多次赋值,则后面的值会覆盖掉前面的值。适用于简单类型的key,比如name,version等。
其他的常用方法有
+=,将值添加进现有值里,适用于集合类型的key,比如libraryDependencies
++=,将一个集合值加入当前集合里.~=将key的当前值传给你的函数,然后将函数结果作为新值,比如你可以在name := xxx后面再来一句
name ~= { _. toUpperCase },一样是把name变成大写
«= 将另一个key的值赋给当前key,比如auther «= name ,这个方法还有个高级用法,你可以组合多个其他key的值,赋给当前key,用文档里的例子
name «= (name, organization, version) { (n, o, v) => “project “ + n + “ from “ + o + “ version “ + v }
还有适用于集合类型的版本
<+= 和 <++=
这些语法的官方文档在此https://github.com/harrah/xsbt/wiki/Getting-Started-More-About-Settings
依赖管理
对于不打算通过官方repository管理的第三方库,在项目目录下建个lib目录,把jar包扔进去就行了。
希望sbt待为管理的则在build.sbt里用下面的语法加入
libraryDependencies += groupID % artifactID % revision % configuration
% configuration是可选的,表示某依赖库只在特定配置中需要,比如模板项目里的”org.specs2” %% “specs2” % “1.7.1” % “test” 是单元测试框架,只在测试时需要。
如果你视力好,会看到其中有个 %%,而不是一个%,这表示要求sbt寻找用当前你配置的scala版本编译出来的jar包,这是因为scala不同版本编译出来的结果会不兼容(悲剧),希望以后scala社区会解决这不兼容的问题。。。
对于依赖的java语言写的库的jar包,就没这问题了,比如libraryDependencies += “org.slf4j” % “slf4j-api” % “1.6.4” 就不需要%%了
配置好依赖后,运行sbt update,sbt会自动到maven库和scala官方库里去找这些jar包并下载到你的用户目录的.ivy2目录里面,如果你不同的项目用了相同的库,则sbt下载一次就够了。
如果你希望sbt从你自己配置的repository里下载,使用这个语法:
resolvers += name at location
比如
resolvers += “Scala-Tools Maven2 Snapshots Repository” at “http://scala-tools.org/repo-snapshots”
所有的一切都是通过key类配置的,key 的列表在http://harrah.github.com/xsbt/latest/sxr/Keys.scala.html 慢慢看吧。。。
sbt插件
现有的sbt插件的列表在https://github.com/harrah/xsbt/wiki/sbt-0.10-plugins-list 安装的方法各有不同,请自己查阅
我的项目模板里已经配置了sbteclipse插件,运行sbt eclipse或在交互模式下输入eclipse回车即会生成相应的eclipse项目文件,然后你就可以在eclipse里用import / existing projects into workspace来导入了。
添加依赖这个简单的解析器对于这点输入内容是可以正常工作的,但是我们还需要加入测试代码并且对它进行一些改造。首先要做的就是把specs测试库以及一个真正的JSON解析器加入到我们的工程里来。为了达到这个目标,我们需要在默认的工程结构上进行改造,然后创建项目。把下面的内容添加到project/build/SampleProject.scala里:import sbt._class SampleProject(info: ProjectInfo) extends DefaultProject(info) {
val jackson = “org.codehaus.jackson” % “jackson-core-asl” % “1.6.1”
val specs = “org.scala-tools.testing” % “specs_2.8.0” % “1.6.5” % “test”
}
常用命令actions – 显示对当前工程可用的命令
update – 下载依赖
compile – 编译代码
test – 运行测试代码
package – 创建一个可发布的jar包
publish-local – 把构建出来的jar包安装到本地的ivy缓存
publish – 把jar包发布到远程仓库(如果配置了的话)
更多命令test-failed – 运行失败的spec
test-quick – 运行所有失败的以及/或者是由依赖更新的spec
clean-cache – 清除所有的sbt缓存。类似于sbt的clean命令
clean-lib – 删除lib_managed下的所有内容sbt结构说明基础目录 在 sbt 的术语里,“基础目录”是包含项目的目录。所以,如果你创建了一个和 Hello, World 一样的项目hello ,包含 hello/build.sbt 和 hello/hw.scala, hello 就是基础目录。源代码 源代码可以像 hello/hw.scala 一样的放在项目的基础目录中。然而,大多数人不会在真实的项目中这样做,因为太杂乱了。 sbt 和 Maven 的默认的源文件的目录结构是一样的(所有的路径都是相对于基础目录的):src/
main/
resources/
scala/
java/
test/
resources
scala/
java/
src/ 中其他的目录将被忽略。而且,所有的隐藏目录也会被忽略。构建产品 构建出来的文件(编译的 classes,打包的 jars,托管文件,caches 和文档)默认写在 target 目录中。交互模式 在你的项目目录下运行 sbt 不跟任何参数:$ sbt
执行 sbt 不跟任何命令行参数将会进入交互模式。交互模式有一个命令行(含有 tab 自动补全功能和历史记录)。例如,在 sbt 命令行里输入 compile:> compile
再次 compile,只需要按向上的方向键,然后回车。 输入 run 来启动程序。 输入 exit 或者 Ctrl+D (Unix)或者 Ctrl+Z (Windows)可以退出交互模式。批处理模式 你也可以用批处理模式来运行 sbt,可以以空格为分隔符指定参数。对于接受参数的 sbt 命令,将命令和参数用引号引起来一起传给 sbt。例如:$ sbt clean compile "testOnly TestA TestB"
在这个例子中,testOnly 有两个参数 TestA 和 TestB。这个命令会按顺序执行(clean, compile, 然后 testOnly)。常用命令 下面是一些非常常用的的 sbt 命令。更加详细的列表请参见 命令行参考。clean 删除所有生成的文件 (在 target 目录下)。
compile 编译源文件(在 src/main/scala 和 src/main/java 目录下)。
test 编译和运行所有测试。
console 进入到一个包含所有编译的文件和所有依赖的 classpath 的 Scala 解析器。输入 :quit, Ctrl+D (Unix),或者 Ctrl+Z (Windows) 返回到 sbt。
run <参数>* 在和 sbt 所处的同一个虚拟机上执行项目的 main class。
package 将 src/main/resources 下的文件和 src/main/scala 以及 src/main/java 中编译出来的 class 文件打包成一个 jar 文件。
help <命令> 显示指定的命令的详细帮助信息。如果没有指定命令,会显示所有命令的简介。
reload 重新加载构建定义(build.sbt, project/*.scala, project/*.sbt 这些文件中定义的内容)。在修改了构建定义文件之后需要重新加载。
添加依赖库 有两种方式添加第三方的依赖。一种是将 jar 文件 放入 lib/(非托管的依赖)中,另一种是在build.sbt 中添加托管的依赖,像这样:val derby = "org.apache.derby" % "derby" % "10.4.1.3"lazy val commonSettings = Seq(
organization := "com.example",
version := "0.1.0",
scalaVersion := "2.11.4"
)lazy val root = (project in file(".")).
settings(commonSettings: _*).
settings(
name := "hello",
libraryDependencies += derby
)
 3.安装完成后,可在Help->Installation Details中查看
4.添加远程的原型或模板目录
3.安装完成后,可在Help->Installation Details中查看
4.添加远程的原型或模板目录
 Catalog file:http://repo1.maven.org/maven2/archetype-catalog.xml
Description:Remote Catalog Scala
5、出现过mvn连不上公共库的问题;
解决方法:vi eclipse.ini
add : -vmargs -Djava.net.preferIPv4Stack=true
Catalog file:http://repo1.maven.org/maven2/archetype-catalog.xml
Description:Remote Catalog Scala
5、出现过mvn连不上公共库的问题;
解决方法:vi eclipse.ini
add : -vmargs -Djava.net.preferIPv4Stack=true