spark的ML和MLLib两个包区别和联系
ML的API是面向Dataset的(Dataframe是Dataset的子集,也就是Dataset[Row]), mllib是面对RDD的。Dataset和RDD有啥不一样呢?Dataset的底端是RDD。Dataset对RDD进行了更深一层的优化,比如说有sql语言类似的黑魔法,Dataset支持静态类型分析所以在compile time就能报错,各种combinators(map,foreach等)性能会更好
spark.mllib中的算法接口是基于RDDs的;spark.ml中的算法接口是基于DataFrames的。实际使用中推荐ml,建立在DataFrames基础上的ml中一系列算法更适合创建包含从数据清洗到特征工程再到模型训练等一系列工作的ML pipeline;而且未来mllib也会被弃用。
Spark机器学习库现支持两种接口的API:RDD-based和DataFrame-based,Spark官方网站上说,RDD-based APIs在2.0后进入维护模式,主要的机器学习API是spark-ml包中的DataFrame-based API,并将在3.0后完全移除RDD-based API。
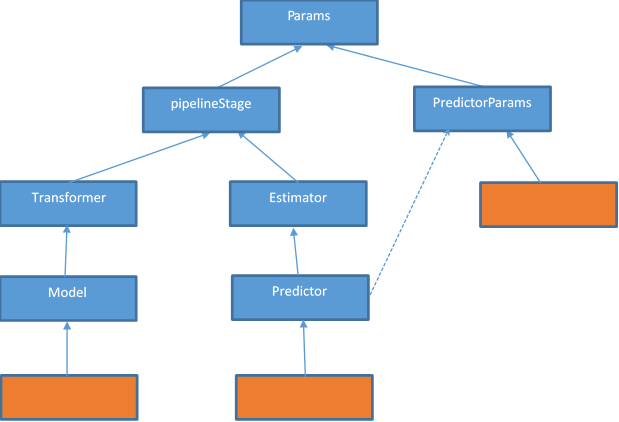
DataFrame-based API 包含在org.apache.spark.ml包中,其中主要的类结构如下