用余弦相似度算法计算文本相似度
句子A:这只皮靴号码大了。那只号码合适。
句子B:这只皮靴号码不小,那只更合适。
1、分词:
使用结巴分词对上面两个句子分词后,分别得到两个列表:
listA=[‘这‘, ‘只‘, ‘皮靴‘, ‘号码‘, ‘大‘, ‘了‘, ‘那‘, ‘只‘, ‘号码‘, ‘合适‘]
listB=[‘这‘, ‘只‘, ‘皮靴‘, ‘号码‘, ‘不小‘, ‘那‘, ‘只‘, ‘更合‘, ‘合适‘]
2、列出所有词,将listA和listB放在一个set中,得到:
set={‘不小’, ‘了’, ‘合适’, ‘那’, ‘只’, ‘皮靴’, ‘更合’, ‘号码’, ‘这’, ‘大’}
将上述set转换为dict,key为set中的词,value为set中词出现的位置,即‘这’:1这样的形式。
dict1={‘不小’: 0, ‘了’: 1, ‘合适’: 2, ‘那’: 3, ‘只’: 4, ‘皮靴’: 5, ‘更合’: 6, ‘号码’: 7, ‘这’: 8, ‘大’: 9},可以看出“不小”这个词在set中排第1,下标为0。
3、将listA和listB进行编码,将每个字转换为出现在set中的位置,转换后为:
listAcode=[8, 4, 5, 7, 9, 1, 3, 4, 7, 2]
listBcode=[8, 4, 5, 7, 0, 3, 4, 6, 2]
我们来分析listAcode,结合dict1,可以看到8对应的字是“这”,4对应的字是“只”,9对应的字是“大”,就是句子A和句子B转换为用数字来表示。
4、对listAcode和listBcode进行oneHot编码,就是计算每个分词出现的次数。oneHot编号后得到的结果如下:
listAcodeOneHot = [0, 1, 1, 1, 2, 1, 0, 2, 1, 1]
listBcodeOneHot = [1, 0, 1, 1, 2, 1, 1, 1, 1, 0]
 使用方式:
(1)Maven 依赖:
使用方式:
(1)Maven 依赖: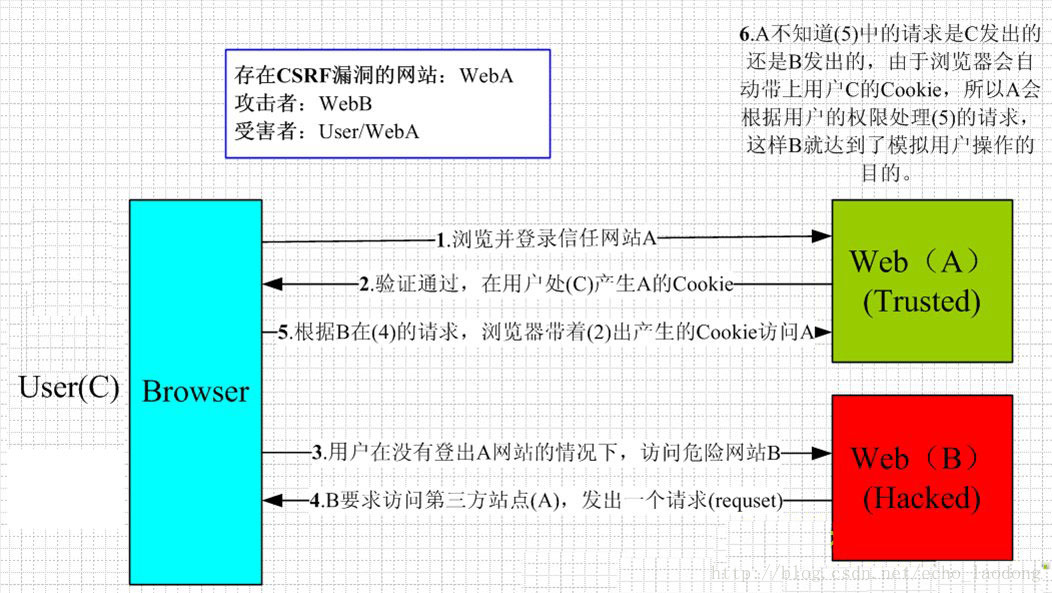 XSS攻击(服务端):跨站脚本攻击, XSS攻击是Web攻击中最常见的攻击方法之一,它是通过对网页注入可执行代码且成功地被浏览器执行,达到攻击的目的,形成了一次有效XSS攻击,一旦攻击成功,它可以获取用户的联系人列表,然后向联系人发送虚假诈骗信息,可以删除用户的日志等等,有时候还和其他攻击方式同时实施比如SQL注入攻击服务器和数据库、Click劫持、相对链接劫持等实施钓鱼,它带来的危害是巨大的,是web安全的头号大敌
攻击者一般通过script标签对网站注入一些可执行的代码,这样就可以很轻松的获取到用户的一些信息。预防措施:strip_tags() 函数,过滤掉输入、输出里面的恶意标签和使用htmlentities()函数把标签字符串转换成html实体。
XSS攻击(服务端):跨站脚本攻击, XSS攻击是Web攻击中最常见的攻击方法之一,它是通过对网页注入可执行代码且成功地被浏览器执行,达到攻击的目的,形成了一次有效XSS攻击,一旦攻击成功,它可以获取用户的联系人列表,然后向联系人发送虚假诈骗信息,可以删除用户的日志等等,有时候还和其他攻击方式同时实施比如SQL注入攻击服务器和数据库、Click劫持、相对链接劫持等实施钓鱼,它带来的危害是巨大的,是web安全的头号大敌
攻击者一般通过script标签对网站注入一些可执行的代码,这样就可以很轻松的获取到用户的一些信息。预防措施:strip_tags() 函数,过滤掉输入、输出里面的恶意标签和使用htmlentities()函数把标签字符串转换成html实体。
 跨网站指令码(英语:Cross-site scripting,通常简称为:XSS)是一种网站应用程式的安全漏洞攻击,是代码注入的一种。它允许恶意使用者将程式码注入到网页上,其他使用者在观看网页时就会受到影响。这类攻击通常包含了HTML以及使用者端脚本语言。
跨网站指令码(英语:Cross-site scripting,通常简称为:XSS)是一种网站应用程式的安全漏洞攻击,是代码注入的一种。它允许恶意使用者将程式码注入到网页上,其他使用者在观看网页时就会受到影响。这类攻击通常包含了HTML以及使用者端脚本语言。 当用户还没进行用户登录的时候
用户去访问系统1的保护资源 ,系统1检测到用户还没登录,跳转至SSO认证中心,SSO认证中心也发现用户没有登录,就跳转到用户至认证中心的登录页面
用户在登录页面提交用户相应信息后,认证中心会校验用户信息,如果用户信息正确的话认证中心就会创建与该用户的全局会话(全局会话过期的时候,用户就需要重新登录了。全局会话中存的信息可能有令牌,用户信息,及该在各个系统的一些情况),同时创建授权令牌,然后进行下一步,否则认证中心给出提示(用户信息有误),待用户再次点击登录的时候,再一次进行校验用户信息
认证中心带着令牌跳转到用户最初请求的地址(系统1),系统1拿到令牌后去SSO认证中心校验令牌是否有效,SSO认证中心校验令牌,若该令牌有效则进行下一步
注册系统1,然后系统1使用该令牌创建和用户的局部会话(若局部会话过期,跳转至SSO认证中心,SSO认证中心发现用户已经登录,然后执行第3步),返回受保护资源
用户已经通过认证中心的认证后
用户访问系统2的保护资源,系统2发现用户未登录,跳转至SSO认证中心,SSO认证中心发现用户已经登录,就会带着令牌跳转回系统2,系统2拿到令牌后去SSO认证中心校验令牌是否有效,SSO认证中心返回有效,注册系统2,系统2使用该令牌创建与用户的局部会话,返回受保护资源。
当用户还没进行用户登录的时候
用户去访问系统1的保护资源 ,系统1检测到用户还没登录,跳转至SSO认证中心,SSO认证中心也发现用户没有登录,就跳转到用户至认证中心的登录页面
用户在登录页面提交用户相应信息后,认证中心会校验用户信息,如果用户信息正确的话认证中心就会创建与该用户的全局会话(全局会话过期的时候,用户就需要重新登录了。全局会话中存的信息可能有令牌,用户信息,及该在各个系统的一些情况),同时创建授权令牌,然后进行下一步,否则认证中心给出提示(用户信息有误),待用户再次点击登录的时候,再一次进行校验用户信息
认证中心带着令牌跳转到用户最初请求的地址(系统1),系统1拿到令牌后去SSO认证中心校验令牌是否有效,SSO认证中心校验令牌,若该令牌有效则进行下一步
注册系统1,然后系统1使用该令牌创建和用户的局部会话(若局部会话过期,跳转至SSO认证中心,SSO认证中心发现用户已经登录,然后执行第3步),返回受保护资源
用户已经通过认证中心的认证后
用户访问系统2的保护资源,系统2发现用户未登录,跳转至SSO认证中心,SSO认证中心发现用户已经登录,就会带着令牌跳转回系统2,系统2拿到令牌后去SSO认证中心校验令牌是否有效,SSO认证中心返回有效,注册系统2,系统2使用该令牌创建与用户的局部会话,返回受保护资源。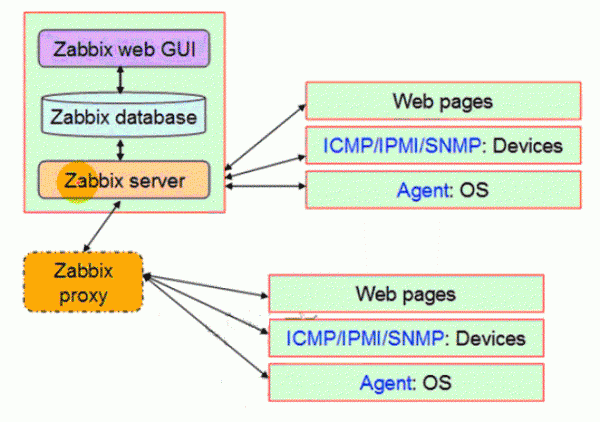 每个模块工作职责:
每个模块工作职责:
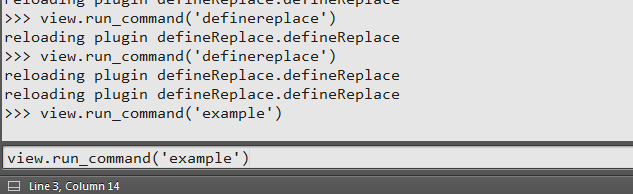 执行结果如下,第一行插入了Hello,World!:
4、ExampleCommand类名字改为你想要的插件名字,如: definereplaceCommand(将Command之前的名称先全部小写,当然还有其他方式),然后就可以开发该插件对应的功能了,当然这时候输入的命令也变成了view.run_command(‘definereplace’),这样执行才有效。
执行结果如下,第一行插入了Hello,World!:
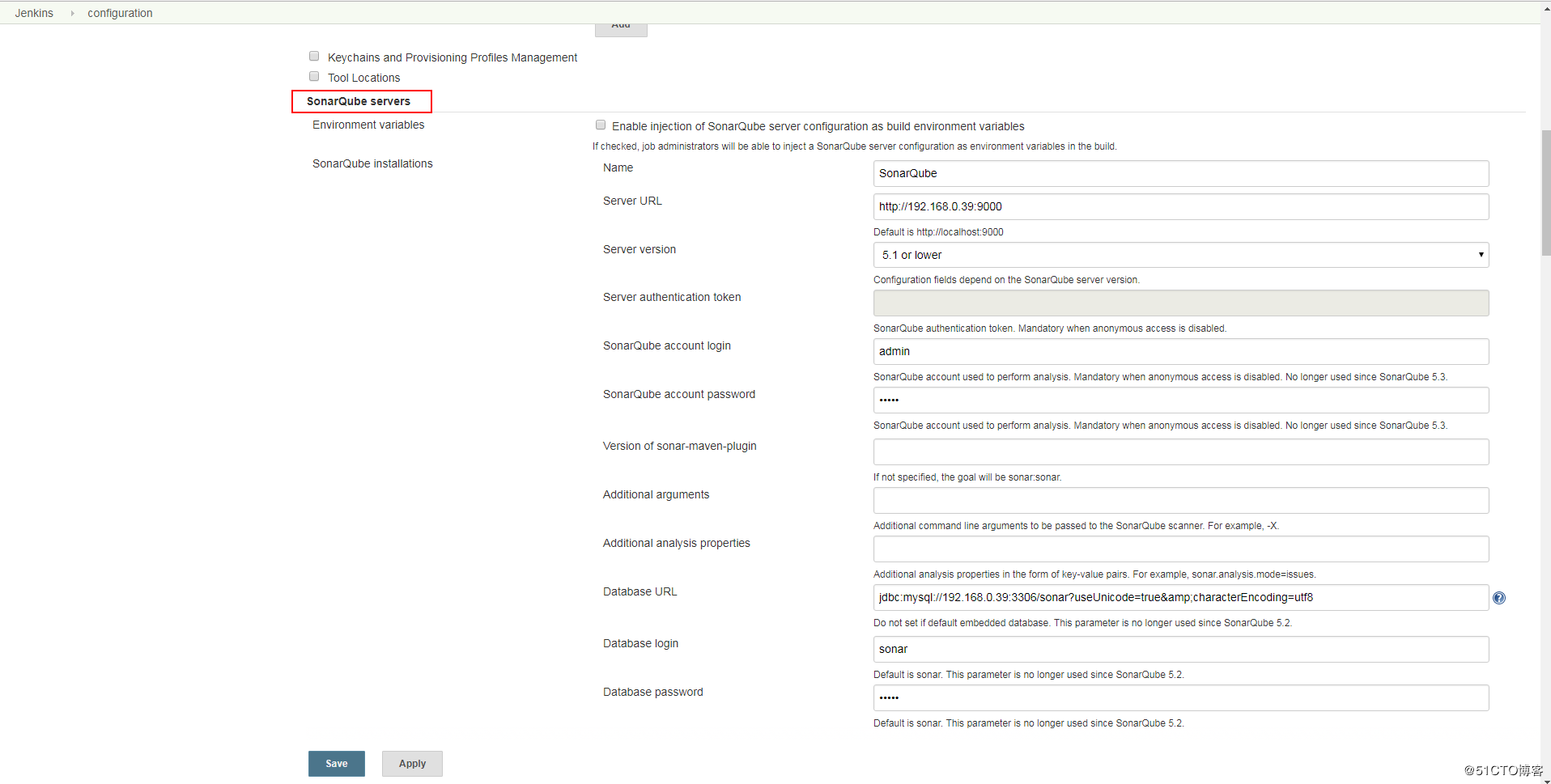
4、ExampleCommand类名字改为你想要的插件名字,如: definereplaceCommand(将Command之前的名称先全部小写,当然还有其他方式),然后就可以开发该插件对应的功能了,当然这时候输入的命令也变成了view.run_command(‘definereplace’),这样执行才有效。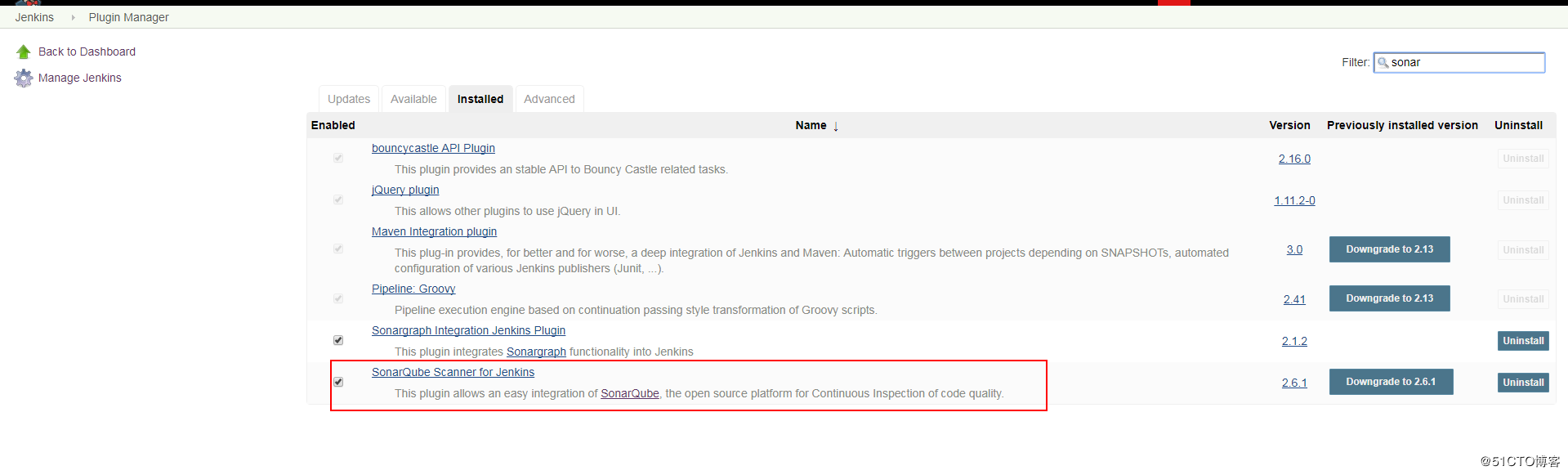 点击”Manage Jenkins”,选择“Configure System”将SonarQube server的信息填入,点击保存。如图:
点击”Manage Jenkins”,选择“Configure System”将SonarQube server的信息填入,点击保存。如图:
 在jenkinse服务器上下载sonar-scanner,下载地址:https://sonarsource.bintray.com/Distribution/sonar-scanner-cli/sonar-scanner-cli-3.0.3.778-linux.zip
在jenkinse服务器上下载sonar-scanner,下载地址:https://sonarsource.bintray.com/Distribution/sonar-scanner-cli/sonar-scanner-cli-3.0.3.778-linux.zip 可以从七个维度检测代码质量:
(1)复杂度分布(complexity):代码复杂度过高将难以理解
(2) 重复代码(duplications):程序中包含大量复制、粘贴的代码而导致代码臃肿,sonar可以展示源码中重复严重的地方
(3) 单元测试统计(unit tests):统计并展示单元测试覆盖率,开发或测试可以清楚测试代码的覆盖情况
(4) 代码规则检查(coding rules):通过Findbugs,PMD,CheckStyle等检查代码是否符合规范
(5) 注释率(comments):若代码注释过少,特别是人员变动后,其他人接手比较难接手;若过多,又不利于阅读
(6) 潜在的Bug(potential bugs):通过Findbugs,PMD,CheckStyle等检测潜在的bug
(7) 结构与设计(architecture & design):找出循环,展示包与包、类与类之间的依赖、检查程序之间耦合度
SonarQube安装
搭建分两大步:服务端跟客户端
服务端
◆进入条件:
1、准备Java环境,这里略去配置
2、需要安装MySQL (支持数据库种类见sonar.properties),这里略去配置
3、sonar https://docs.sonarqube.org
◆数据库配置:
1、创建sonar数据库
2、选择conf/sonar.properties文件,配置数据库设置,默认已经提供了各类数据库的支持,这里选择MySQL数据库,默认已经准备了支持各种数据库,只需将MySQL注释部分去掉,顺便改了sonarQube的端口sonar.web.port=1011
sonar.jdbc.url=jdbc:mysql://localhost:1010/sonar?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&useConfigs=maxPerformance
sonar.jdbc.driver=com.mysql.jdbc.Driver
sonar.jdbc.username=root
sonar.jdbc.password=root
◆sonar
将下载的soar安装包后,解压,随意放置一个地方
注:JDK的环境和系统环境,要对应,我是windows系统,JDK位64位,选windows-x86-64
进入bin目录后,点击SonarStart.bat,页面输入http://localhost:1011/,进入页面,配置成功
客户端
前面已经说了客户端可以通过IDE插件、Sonar-Scanner插件、Ant插件和Maven插件方式进行扫描分析,这一节先记录Sonar-Scanner扫描
◆下载sonar-scanner解压,将bin文件加入环境变量path中如我的路径E:\sonar\sonar-scanner\bin将此路径加入path中
◆修改sonar scanner配置文件, conf/sonar-scanner.properties。根据数据库使用情况进行取消相关的注释即可,同时需要添加数据库用户名和密码信息,即配置要访问的sonar服务和mysql服务器地址
◆创建sonar-project.properties文件,以java工程为例在工程根目录下新建立一个sonar-project.properties配置文件
可以从七个维度检测代码质量:
(1)复杂度分布(complexity):代码复杂度过高将难以理解
(2) 重复代码(duplications):程序中包含大量复制、粘贴的代码而导致代码臃肿,sonar可以展示源码中重复严重的地方
(3) 单元测试统计(unit tests):统计并展示单元测试覆盖率,开发或测试可以清楚测试代码的覆盖情况
(4) 代码规则检查(coding rules):通过Findbugs,PMD,CheckStyle等检查代码是否符合规范
(5) 注释率(comments):若代码注释过少,特别是人员变动后,其他人接手比较难接手;若过多,又不利于阅读
(6) 潜在的Bug(potential bugs):通过Findbugs,PMD,CheckStyle等检测潜在的bug
(7) 结构与设计(architecture & design):找出循环,展示包与包、类与类之间的依赖、检查程序之间耦合度
SonarQube安装
搭建分两大步:服务端跟客户端
服务端
◆进入条件:
1、准备Java环境,这里略去配置
2、需要安装MySQL (支持数据库种类见sonar.properties),这里略去配置
3、sonar https://docs.sonarqube.org
◆数据库配置:
1、创建sonar数据库
2、选择conf/sonar.properties文件,配置数据库设置,默认已经提供了各类数据库的支持,这里选择MySQL数据库,默认已经准备了支持各种数据库,只需将MySQL注释部分去掉,顺便改了sonarQube的端口sonar.web.port=1011
sonar.jdbc.url=jdbc:mysql://localhost:1010/sonar?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&useConfigs=maxPerformance
sonar.jdbc.driver=com.mysql.jdbc.Driver
sonar.jdbc.username=root
sonar.jdbc.password=root
◆sonar
将下载的soar安装包后,解压,随意放置一个地方
注:JDK的环境和系统环境,要对应,我是windows系统,JDK位64位,选windows-x86-64
进入bin目录后,点击SonarStart.bat,页面输入http://localhost:1011/,进入页面,配置成功
客户端
前面已经说了客户端可以通过IDE插件、Sonar-Scanner插件、Ant插件和Maven插件方式进行扫描分析,这一节先记录Sonar-Scanner扫描
◆下载sonar-scanner解压,将bin文件加入环境变量path中如我的路径E:\sonar\sonar-scanner\bin将此路径加入path中
◆修改sonar scanner配置文件, conf/sonar-scanner.properties。根据数据库使用情况进行取消相关的注释即可,同时需要添加数据库用户名和密码信息,即配置要访问的sonar服务和mysql服务器地址
◆创建sonar-project.properties文件,以java工程为例在工程根目录下新建立一个sonar-project.properties配置文件