Lockless
https://docs.microsoft.com/zh-cn/windows/win32/dxtecharts/lockless-programming?redirectedfrom=MSDN
https://en.cppreference.com/w/cpp/atomic
在 2014 年的 C++ 大会上,Herb Sutter 做了 C++ 无锁(译注:lock-free,意为不使用锁来保持代码的同步)编程的演讲,在演讲中他解释了无锁编程的基本概念,并用三种算法展示了无锁技术。
Herb 首先指出了无锁代码的优势:
通过减少阻塞和等待,来改进并发性和可扩展性。
消除条件竞争(race condition)、死锁、可组合性不足带来的潜在问题。
但是无锁编程不是万能药,因为无锁算法实现起来更复杂,它也有潜在问题,比如竞争(contention),这会极大地影响性能。从这一点出发,Herb 引出了他的第一条强烈建议:
在使用无锁技术前,你必须先测试你的程序,确定它有性能或可扩展性问题。
实现无锁算法后,再次测试你的程序,确定结果得到了有效的改进。
人们经常将Lock-Free编程认为是没有互斥的编程,或者说没有锁的编程。这是对的,但是只是这个故事的一部分。在学术文献上通常被接收的概念是无锁是描述某些代码一个属性,但没有说太多关于这段代码是如何写成的。
基本上,如果你的部分代码满足以下的条件,就可以被认为是无锁的,相对的,如果你的代码不满足这些条件,那么这部部分就不是无锁的。
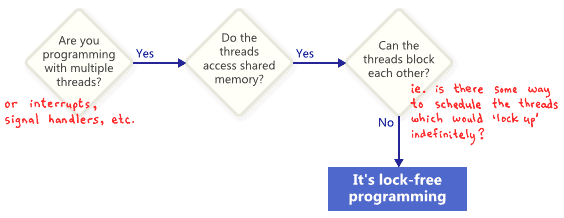
在这种情况下,“无锁”中的“锁”并不直接是互斥量,而是看起来有能力以某种方式阻塞住应用程序,不论是锁本身是死锁还是活锁。甚至是由与你为敌的线程调度问题(made by your worst enemy)。最后一点可能看起来比较搞笑,但是却很重要。共享的互斥量只是简单的具有排他性,因为一但被一个线程获得,线程调度有可能永远不能够再调度该线程。当然,实际情况不会允许这个情况发生,我们只不过是定义这个术语。
这里有一个简单的例子,这个操作不包含基本的互斥,但仍然不是Lock-Free的。初始值X=0。作为读者们的一个练习,思考一下两个线程执行这段代码,是否没有一个线程能退出这个循环。
while (X == 0)
{
X = 1 - X;
}
没有人期望一个大型的应用程序全都是无锁的。通常,我们在整个代码中确定一组特定的无锁操作。举个例子,一个Lock-Free queue,也只有少部分的无锁操作,比如push,pop,或者isEmpty。荷里希和(以)谢菲特,多处理器编程的艺术的作者,表述了在一个类方法中,提供了lock-free 如下简结的定义:
“一个方法总能在有限次调用内完成。换言之,完成调用的数量不断增加,无论它是什么。”
这些操作在系统中,在算法上是无法被阻塞的。
另外一个重要的概念就是如果你挂起了一个单独的线程,他不会阻止其他线程处理任务。总体来讲,每个线程有自己的Lock-Free操作。这就是暗示了Lock-Free编程的价值。当写一个中断处理和实时系统的时候,它可以确保在限定的时间内完成不管什么程序的其余部分处于什么状态。
最后一个说明:某些操作被设计为阻塞的并不意味是这就不是Lock-Free的。一个队列的的pop操作当队列为空的时估计被设置为阻塞,剩余的代码仍然被认为是lock-free的。
Lock-Free编程技巧
事实证明,当您试图在无锁编程中满足非阻塞条件时:原子操作,内存屏障,避免了ABA的问题,等等。这就是事情很快成为恶魔。(译者:Lock—free并非是无阻塞的,而是不使用互斥来达到“锁”的目的。)
所以我下面用了一个图来来描述了技术相关的关系,并且会在下面详细讲述。
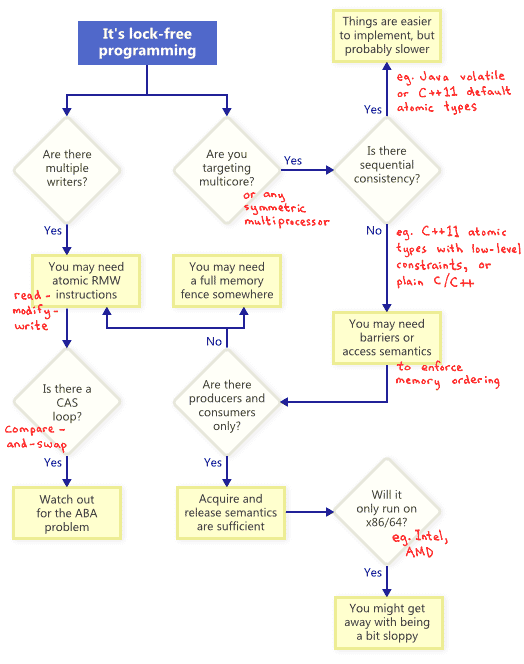
原子的读-改-写操作
原子操作(Atomic Operations)在操作内存时可以被看做是不可分割的(Indivisible),其他线程不会打断该操作,没有一个线程可以看到执行的中间状态。在现代的 CPU 处理器上,很多操作已经被设计为原子的,比如对齐读(Aligned Read)和对齐写(Aligned Write)等。
Read-Modify-Write更进一步。允许你使用更复杂的原子事务。这在支持多写者的情况下开发Lock-Free 算法尤其有用。因为当多线程试图读-改-写一个同样地址的时候,他们会有效地排成一列并且同时只有有一个操作。本文涉及到的读-改-写的操作,在轻量级互斥锁 递归锁和 轻量级日志系统中有体现。
;常见的RMW操作包括Win32的_InterlockedIncrement ,IOS的OSAtomicAdd32以及C++的 std::atomic
不同的cpu家族以不同的方式支持RMW。
比如POWERPC和ARM通过公开load-link/store-conditional指令集,允许你在低级别的有效实现你自己的原始RMW。尽管并不经常这样做。通常的RMW已经足够。
流程图说明了,原子的RWM操作在lock free编程中是非常必要的一部分,甚至是在单处理器中,一个线程在执行事务的过程中可能在半路被中断,有可能会导致状态的不一致。
Compare-And-Swap Loops
或许讨论最广泛的操作就是compare-and-swap (CAS)操作了,在 Win32 平台上,CAS 操作有一组原生的实现,例如 _InterlockedCompareExchange 等。对 RMW 操作最常见的讨论可能就是,使用 CAS Loops 来完成对事务的原子处理。
void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
} } Sequential Consistency(顺序一致性) 顺序一致性意味着所有的线程都同意在内存操作时都按照顺序发生。 并且这个顺序是鱼程序代码的顺序有关的。 在顺序一致性下,不会出现如我在讲到的内存重排序问题。 一个简单的(但明显不能用于实践)方式就是禁止编译器优化并且强制所有的线程在一个处理器下面运行。一个处理器绝不会看见自己的内存乱序,甚至是处理器在空闲的时间。一些编程语言提供了顺序一致性来阻止在多处理器器程序的代码优化。 在 C++11中,你可以声明所有的共享变量作为其原子类型,在java中间,你可以让所有的变量为volatile变量。下面是我先前博客一个例子:以C++11的的风格重写的:
std::atomic
int r1, r2;
void thread1()
{
X.store(1);
r1 = Y.load();
}
void thread2()
{
Y.store(1);
r2 = X.load();
}
因为C++11原子类型保证了顺序一致性。所以输出 r1=r2=0是不可能发生的。为了达到这种效果,编译器输出了额外的指令-典型的内存栅栏或者RWM操作。
这种额外的指令导致了没有直接内存排序的程序高效。
内存重排序
如流程图上面所示,你的无锁程序在多核或者多处理器(或者对称处理器)上任何时间都不能完全的保证顺序一致性。你必须思考如何阻止内存排序。
在如今的架构中,强制保证正确内存排序的工具主要有三个级别,来保证阻止编译器重排序和处理器重排序。
一些我在后续的文章中讲到的轻量级的同步或者栅栏指令
一个针对所有内存的栅栏指令,我之前发表过
提供请求和释放内存操作语义
请求内存的操作语义阻止了按照程序的编写顺序之后内存重排序,释放内存阻止了其操作之前的重排序。这些程序非常适合生产者/消费者关系。我会在后续的文章讲到这一点
不同的处理器有不同的内存模型
当我们谈到内存排序的时候,不同的处理器有不同的内存模型。每个CPU供应商都会明确地写明规则并且严格按照硬件来编排。比如,PowerPC 和 ARM的处理器通过自身的指令改变内存屏障的顺序,但英特尔和AMDx86/64指令集则不会。我们说,更早的处理器拥有更宽松的内存模型。
抽象出各个平台的细节是非常诱人的。尤其是C++11提供了我们标准的方式去方便地编写Lock-Free代码。但就目前来看,我认为大部分Lock-Free的程序员们还是需要了解一些不同平台的细节。记住,有一个关键区别,
X86/64指令级的每个从内存加载必须有有获取语义,每个从内存释放都必须有释放语义(否则内存重排序)——至少非SSE指令和非写联合内存是这样的,但是在 其他处理器又不一样。
基本概念
以下是考虑无锁算法的时候需要理解的一些基本概念:
一致性(Consistency):一段关键代码可以把系统从一个稳定的状态转换到另一个稳定的状态。
隔离(Isolation):两次转换永远不同时操作同一数据。
持续性(Durability):在一次转换的结果出来之前,不会被另一次转换所打断。
为达到这些目的所用到的基本技术有:
把计算结果保存在私有区域中;
借助“比较与交换(compare/exchange)”指令,使用单个原子写操作(atomic write)把计算结果公布出去。
在 C++ 11 中,你可以使用atomic
你可以把每个读操作和写操作看作是原子的,不再需要锁。
另外,读操作和写操作保证不会被重排序。
关于atomic的一些要点如下:
对于占空间小的数据类型,atomic通常是通过平台特定的操作来实现的。
atomic对象必须要初始化(否则会包含垃圾数据)。
两个原子操作可以保证各自是原子的,但是atomic对象的状态有可能来回发生变化。
例子:两次检查的加锁(double-checked locking)
Herb 给的第一个例子是如果保证一个全局对象只被构造了一次。
核心思想是:用一个锁来保护原子写操作,但是让原子读操作处于无锁状态。这样只有在各个线程竞争初始化这个单例(singleton)的时候才可能发生阻塞。算法取这个名字的原因是,实例的指针共检查了两次,加锁前和加锁后:
atomic Widget::pInstance{ nullptr };
Widget* Widget::Instance() {
if (pInstance == nullptr) {
lock_guard lock { mutW };
if (pInstance == nullptr) {
pInstance = new Widget();
}
}
}*>
例子:生产者——消费者
Herb 描述的第二个例子是经典的生产者——消费者算法。他先描述了传统的使用锁的解决方案:
生产者获取共享队列的锁,把一些对象放进去;针对每个对象,都会触发一个条件变量,这样生产者就得到了通知。
另一方面,生产者也尝试获取队列的锁,得到锁以后,它检查队列中是否有对象可以消费;如果有,取走对象,并释放锁。
使用无锁技术对这个算法做第一种改进,通过atomic变量来访问单向链表。这样可以使生产者一次性放完它的东西,然后通过原子性地修改队列的头指针来通知消费者。消费者的实现不变。
然后,我们考虑完全无锁的实现。在这种情况下,算法的思想是,生产者要去填满一定数量的“槽(slot)”。当生产者有一个新任务要处理,它会去检查是否有空闲的槽,并把要处理的任务放进去。在下面的代码中,slot 是一个atomic变量:
curr = 0;
// 第一阶段:生成任务
while (ThereAreMoreTasks()) {
task = AllocateAndBuildNewTask();
while (slot[curr] != null)
curr = (curr+1)%K;
slot[curr] = task;
sem[curr].signal();
}
// 第二阶段: 把邮箱置为 done 状态
numNotified = 0;
while (numNotified < K) {
while (slot[curr] != null)
curr = (curr+1)%K;
slot[curr] = done;
sem[curr].signal();
++numNotified;
}
对于消费者来说,代码更简单:
myTask = null;
while (myTask != done) {
while (myTask = slot[mySlot]) == null)
sem[mySlot].wait();
if (myTask != done) {
slot[mySlot] = null;
DoWork(myTask);
}
}
消费者等待信号量,直到槽里面有任务为止。任务来了,消费者把它拿出来,并清空槽,然后开始处理任务。这就是把任务处理放到关键区(critical section)之外的思想。但是如果消费者处理得比生产者慢,那么在任务处理完之后再释放锁比较合理,这样,当消费者忙的时候,生产者就不会再去填充同一个槽,而是去找另外一个空闲的槽。这表明了,你的设计决策会对业务吞吐量 / 可扩展性(throughput/scalability)和负载平衡(load balancing)之间的取舍产生微妙的影响。
例子:单向链表:
单向链表可能是最简单的数据结构之一了,在这个例子中只支持四种操作:构造(construct)、销毁(destroy)、查找(find)、前插入(push_front)。
Herb 提出的无锁实现使用了atomic<Node*> head{ nullptr };来访问链表头。唯一有可能导致并发问题的操作是push_front操作,它的单线程版本有可能是这样的:
template
void slist
auto p = new Node;
p->t = t;
p->next = head;
head = p;
}
这个代码有问题,因为它在设置新的head值的时候可能会引入竞争。使用 compare_exchange 来写 head,我们可以修复这个问题,代码如下:
template
void slist
auto p = new Node;
p->t = t;
p->next = head;
while (!head.compare_exchange_weak(p->next, p))
{}
}
这里,我们不停尝试交换head和p的值,直到成功为止。在无锁的代码中,使用compare_exchange_weak很常见。它通常用在循环内,在循环外则使用compare_exchange_strong。
而当我们要实现一个移除节点(pop)的操作时,更多的问题就来了。移除操作会删掉链表中的第一个节点,在这种情况下,导致复杂性的一个主要原因是,返回的对象指针有可能很快被另外一个线程释放掉。这个问题有个广为人知的名字叫 ABA 问题,Herb 随后深入细节,讲述了它在特定的环境下是如何发生的。
C++ 11 为这个问题给出了优雅的解决方案,不再使用原始的指针,而是用shared_ptr来取代。用伪代码表示的实现如下:
template
struct Node { T t; shared_ptr
atomic<shared_ptr
public:
slist() =default;
~slist() =default;
class reference {
shared_ptr p;
public:
reference(shared_ptr
T& operator*() { return p->t; }
T* operator->() { return &p->t; }
};
auto find(T t) const {
auto p = head.load();
while (p && p->t != t)
p = p->next;
return reference{move(p)};
void push_front(T t) {
auto p = make_shared
p->t = t;
p->next = head;
while (head.compare_exchange_weak(p->next, p))
{}
}
void pop_front() {
auto p = head.load();
while (p && !head.compare_exchange_weak(p, p->next))
{}
}
};
这里用到的技巧是,返回的指针被指定为一个shared_ptr,这样我们不需要再特别关注指针被意外删除的情况。
这种实现展示了一种很好的属性叫线性化,它可以使一组互相交错的操作看起来像是顺序执行的一样。
演讲的最后部分讨论了一个例子,这个例子展示了如何来衡量一个程序的行为,以及它可以从无锁的实现中获得什么样的好处。
https://www.infoq.com/news/2014/10/cpp-lock-free-programming/
有锁编程
对于保护多线程共享数据,最常用也是最基本的方法就是使用C++11线程标准库提供的互斥锁mutex保护临界区,保证同一时间只能有一个线程可以获取锁,持有锁的线程可以对共享变量进行修改,修改完毕后释放锁,而不持有锁的线程阻塞等待直到获取到锁,然后才能对共享变量进行修改,这种方法几乎是并发编程中的标准做法。
无锁编程
原子操作是无锁编程的基石,原子操作是不可分隔的操作,一般通过CAS(Compare and Swap)操作实现,CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。C++11的线程库为我们提供了一系列原子类型,同时提供了相对应的原子操作,我们通过使用这些原子类型即可摆脱每次对共享变量进行操作都进行的加锁解锁动作,节省了系统开销,同时避免了线程因阻塞而频繁的切换.
无锁编程最大的优势在于两点:
避免了死锁的产生。由于无锁编程避免了使用锁,所以也就不会出现并发编程中最让人头疼的死锁问题,对于提高程序健壮性有很大积极意义
代码更加清晰与简洁。对于一个多线程共享的变量,保证其安全性我们只需在声明时将其声明为原子类型即可,在代码中使用的时候和使用一个普通变量一样,而不用每次使用都要在前面写个加锁操作,在后面写一个解锁操作。我写的C++期货高频交易软件中,有一个全局变量fund,存储的是当前资金量,程序采用线程池运行交易策略,交易策略中频繁使用到fund变量,如果采用加锁的方式,使用起来极其繁琐,为了保护一个fund变量需要非常频繁的加锁解锁,后来将fund变量改为原子类型,后面使用就不用再考虑加锁问题,整个程序阅读起来清晰很多。
如果是为了提高性能将程序大幅改写成无锁编程,一般来说结果可能会让我们失望,而且无锁编程里面需要注意的地方也非常多,比如ABA问题,内存顺序问题,正确实现无锁编程比实现有锁编程要困难很多,除非有必要(确定了性能瓶颈)才去考虑使用无锁编程,否则还是使用互斥锁更好,毕竟程序的高性能是建立在程序正确性的基础上,如果程序不正确,一切性能提升都是徒劳无功。
同步可分为阻塞型同步(Blocking Synchronization)和非阻塞型同步( Non-blocking Synchronization)。
阻塞型同步是指当一个线程到达临界区时,因另外一个线程已经持有访问该共享数据的锁,从而不能获取锁资源而阻塞,直到另外一个线程释放锁。常见的同步原语有 mutex、semaphore 等。如果同步方案采用不当,就会造成死锁(deadlock),活锁(livelock)和优先级反转(priority inversion),以及效率低下等现象。
为了降低风险程度和提高程序运行效率,业界提出了不采用锁的同步方案,依照这种设计思路设计的算法称为非阻塞型算法,其本质特征就是停止一个线程的执行不会阻碍系统中其他执行实体的运行。
当今比较流行的 Non-blocking Synchronization 实现方案有三种:
Wait-free
Wait-free 是指任意线程的任何操作都可以在有限步之内结束,而不用关心其它线程的执行速度。 Wait-free 是基于 per-thread 的,可以认为是 starvation-free 的。非常遗憾的是实际情况并非如此,采用 Wait-free 的程序并不能保证 starvation-free,同时内存消耗也随线程数量而线性增长。目前只有极少数的非阻塞算法实现了这一点。
Lock-free
Lock-Free 是指能够确保执行它的所有线程中至少有一个能够继续往下执行。由于每个线程不是 starvation-free 的,即有些线程可能会被任意地延迟,然而在每一步都至少有一个线程能够往下执行,因此系统作为一个整体是在持续执行的,可以认为是 system-wide 的。所有 Wait-free 的算法都是 Lock-Free 的。
Obstruction-free
Obstruction-free 是指在任何时间点,一个孤立运行线程的每一个操作可以在有限步之内结束。只要没有竞争,线程就可以持续运行。一旦共享数据被修改,Obstruction-free 要求中止已经完成的部分操作,并进行回滚。 所有 Lock-Free 的算法都是 Obstruction-free 的。
综上所述,不难得出 Obstruction-free 是 Non-blocking synchronization 中性能最差的,而 Wait-free 性能是最好的,但实现难度也是最大的,因此 Lock-free 算法开始被重视,并广泛运用于当今正在运行的程序中,比如 linux 内核。
一般采用原子级的 read-modify-write 原语来实现 Lock-Free 算法,其中 LL 和 SC 是 Lock-Free 理论研究领域的理想原语,但实现这些原语需要 CPU 指令的支持,非常遗憾的是目前没有任何 CPU 直接实现了 SC 原语。根据此理论,业界在原子操作的基础上提出了著名的 CAS(Compare - And - Swap)操作来实现 Lock-Free 算法,Intel 实现了一条类似该操作的指令:cmpxchg8。
CAS 原语负责将某处内存地址的值(1 个字节)与一个期望值进行比较,如果相等,则将该内存地址处的值替换为新值,CAS 操作伪码描述如下:
清单 1. CAS 伪码
Bool CAS(T* addr, T expected, T newValue)
{
if( *addr == expected )
{
*addr = newValue;
return true;
}
else
return false;
}
在实际开发过程中,利用 CAS 进行同步,代码如下所示:
清单 2. CAS 实际操作
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 ))
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的 commit-retry 的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
加锁的层级
根据复杂程度、加锁粒度及运行速度,可以得出如下所示的锁层级:
wait-free
lock-free
Automic
lockless-based
lock-based
其中最后两方案为 Blocking synchronization
Lock-based 和 Lockless-based 两者之间的区别仅仅是加锁粒度的不同。
lock-based 方案就是大家经常使用的 mutex 和 semaphore 等方案,代码复杂度低,但运行效率也最低。
Linux 内核可能是当今最大最复杂的并行程序之一,它的并行主要来至于中断、内核抢占及 SMP 等。内核设计者们为了不断提高 Linux 内核的效率,从全局着眼,逐步废弃了大内核锁来降低锁的粒度;从细处下手,不断对局部代码进行优化,用无锁编程替代基于锁的方案,如 seqlock 及 RCU 等;不断减少锁冲突程度、降低等待时间,如 Double-checked locking 和原子锁等。
内核无锁第一层级 — 少锁
无论什么时候当临界区中的代码仅仅需要加锁一次,同时当其获取锁的时候必须是线程安全的,此时就可以利用 Double-checked Locking 模式来减少锁竞争和加锁载荷。目前 Double-checked Locking 已经广泛应用于单例 (Singleton) 模式中。内核设计者基于此思想,巧妙的将 Double-checked Locking 方法运用于内核代码中。
当一个进程已经僵死,即进程处于 TASK_ZOMBIE 状态,如果父进程调用 waitpid() 系统调用时,父进程需要为子进程做一些清理性的工作,代码如下所示:
static int wait_task_zombie(task_t p, int noreap,
struct siginfo __user *infop,
int __user *stat_addr, struct rusage __user *ru)
{
……
if (p->real_parent != p->parent) {
write_lock_irq(&tasklist_lock);
/ Double-check with lock held. */
if (p->real_parent != p->parent) {
__ptrace_unlink(p);
// TODO: is this safe?
p->exit_state = EXIT_ZOMBIE;
……
}
write_unlock_irq(&tasklist_lock);
}
……
}
内核无锁第二层级 — 原子锁
原子操作可以保证指令以原子的方式执行——执行过程不被打断。内核提供了两组原子操作接口:一组针对于整数进行操作,另外一组针对于单独的位进行操作。内核中的原子操作通常是内联函数,一般是通过内嵌汇编指令来完成。对于一些简单的需求,例如全局统计、引用计数等等,可以归结为是对整数的原子计算。
内核无锁第三层级 — Lock-free
- Lock-free 应用场景一 —— Spin Lock
Spin Lock 是一种轻量级的同步方法,一种非阻塞锁。当 lock 操作被阻塞时,并不是把自己挂到一个等待队列,而是死循环 CPU 空转等待其他线程释放锁。 Spin lock 锁实现代码如下:
static inline void __preempt_spin_lock(spinlock_t *lock)
{
……
do {
preempt_enable();
while (spin_is_locked(lock))
cpu_relax();
preempt_disable();
} while (!_raw_spin_trylock(lock));
}
static inline int _raw_spin_trylock(spinlock_t *lock)
{
char oldval;
asm volatile(
“xchgb %b0,%1”
:”=q” (oldval), “=m” (lock->lock)
:”0” (0) : “memory”);
return oldval > 0;
}
汇编语言指令 xchgb 原子性的交换 8 位 oldval( 存 0) 和 lock->lock 的值,如果 oldval 为 1(lock 初始值为 1),则获取锁成功,反之,则继续循环,接着 relax 休息一会儿,然后继续周而复始,直到成功。
对于应用程序来说,希望任何时候都能获取到锁,也就是期望 lock->lock 为 1,那么用 CAS 原语来描述 _raw_spin_trylock(lock) 就是 CAS(lock->lock,1,0);
如果同步操作总是能在数条指令内完成,那么使用 Spin Lock 会比传统的 mutex lock 快一个数量级。Spin Lock 多用于多核系统中,适合于锁持有时间小于将一个线程阻塞和唤醒所需时间的场合。
pthread 库已经提供了对 spin lock 的支持,所以用户态程序也能很方便的使用 spin lock 了,需要包含 pthread.h 。在某些场景下,pthread_spin_lock 效率是 pthread_mutex_lock 效率的一倍多。美中不足的是,内核实现了读写 spin lock 锁,但 pthread 未能实现。
- Lock -free 应用场景二 —— Seqlock
手表最主要最常用的功能是读时间,而不是校正时间,一旦后者成了最常用的功能,消费者肯定不会买账。计算机的时钟也是这个功能,修改时间是小概率事件,而读时间是经常发生的行为。
Linux 2.6 内核中引入一种新型锁——顺序锁 (seqlock),它与 spin lock 读写锁非常相似,只是它为写者赋予了较高的优先级。也就是说,即使读者正在读的时候也允许写者继续运行。当存在多个读者和少数写者共享一把锁时,seqlock 便有了用武之地,因为 seqlock 对写者更有利,只要没有其他写者,写锁总能获取成功。根据 lock-free 和时钟功能的思想,内核开发者在 2.6 内核中,将上述读写锁修改成了顺序锁 seqlock,代码如下:
static inline unsigned read_seqbegin(const seqlock_t *sl)
{
unsigned ret = sl->sequence;
smp_rmb();
return ret;
}
static inline int read_seqretry(const seqlock_t *sl, unsigned iv)
{
smp_rmb();
return (iv & 1) | (sl->sequence ^ iv);
}
static inline void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock);
++sl->sequence;
smp_wmb();
}
void do_gettimeofday(struct timeval *tv)
{
unsigned long seq;
unsigned long usec, sec;
unsigned long max_ntp_tick;
……
do {
unsigned long lost;
seq = read_seqbegin(&xtime_lock);
……
sec = xtime.tv_sec;
usec += (xtime.tv_nsec / 1000);
} while (read_seqretry(&xtime_lock, seq));
……
tv->tv_sec = sec;
tv->tv_usec = usec;
}
int do_settimeofday(struct timespec *tv)
{
……
write_seqlock_irq(&xtime_lock);
……
write_sequnlock_irq(&xtime_lock);
clock_was_set();
return 0;
}
Seqlock 实现原理是依赖一个序列计数器,当写者写入数据时,会得到一把锁,并且将序列值加 1。当读者读取数据之前和之后,该序列号都会被读取,如果读取的序列号值都相同,则表明写没有发生。反之,表明发生过写事件,则放弃已进行的操作,重新循环一次,直至成功。不难看出,do_gettimeofday 函数里面的 while 循环和接下来的两行赋值操作就是 CAS 操作。
采用顺序锁 seqlock 好处就是写者永远不会等待,缺点就是有些时候读者不得不反复多次读相同的数据直到它获得有效的副本。当要保护的临界区很小,很简单,频繁读取而写入很少发生(WRRM— Write Rarely Read Mostly)且必须快速时,就可以使用 seqlock。但 seqlock 不能保护包含有指针的数据结构,因为当写者修改数据结构时,读者可能会访问一个无效的指针。
- Lock -free 应用场景三 —— RCU
在 2.6 内核中,开发者还引入了一种新的无锁机制 -RCU(Read-Copy-Update),允许多个读者和写者并发执行。RCU 技术的核心是写操作分为写和更新两步,允许读操作在任何时候无阻碍的运行,换句话说,就是通过延迟写来提高同步性能。RCU 主要应用于 WRRM 场景,但它对可保护的数据结构做了一些限定:RCU 只保护被动态分配并通过指针引用的数据结构,同时读写控制路径不能有睡眠
内核无锁第四层级 — 免锁
环形缓冲区是生产者和消费者模型中常用的数据结构。生产者将数据放入数组的尾端,而消费者从数组的另一端移走数据,当达到数组的尾部时,生产者绕回到数组的头部。
如果只有一个生产者和一个消费者,那么就可以做到免锁访问环形缓冲区(Ring Buffer)。写入索引只允许生产者访问并修改,只要写入者在更新索引之前将新的值保存到缓冲区中,则读者将始终看到一致的数据结构。同理,读取索引也只允许消费者访问并修改。
当读者和写者指针相等时,表明缓冲区是空的,而只要写入指针在读取指针后面时,表明缓冲区已满。
无锁(lock-free)技术在Linux内核2.6版本中就已经有了应用。
无锁,英文一般翻译为lock-free,是利用处理器的一些特殊的原子指令来避免传统并行设计中对锁的使用。
如果一个共享数据结构的操作不需要互斥,那么它是无锁的。如果一个进程或线程在操作中间被中断,其他进程或线程的操作不受影响。[Herlihy 1991]
笔者对于无锁的实践都是在一个进程下关于多线程并发的,所以后面我们只讨论多线程。
为什么要无锁?
首先是性能考虑。
通信项目一般对性能有极致的追求,这是我们使用无锁的重要原因。当然,无锁算法如果实现的不好,性能可能还不如使用锁,所以我们选择比较擅长的数据结构和算法进行lock-free实现,比如Queue,对于比较复杂的数据结构和算法我们通过lock来控制,比如Map(虽然我们实现了无锁Hash,但是大小是限定的,而Map是大小不限定的)。
对于性能数据,后续文章会给出无锁和有锁的对比。
其次是避免锁的使用引起的错误和问题。
死锁(dead lock):两个以上线程互相等待
锁护送(lock convoy):多个同优先级的线程反复竞争同一个锁,抢占锁失败后强制上下文切换,引起性能下降
优先级反转(priority inversion):低优先级线程拥有锁时被中优先级的线程抢占,而高优先级的线程因为申请不到锁被阻塞
如何无锁?
在现代的 CPU 处理器上,很多操作已经被设计为原子的,比如对齐读(Aligned Read)和对齐写(Aligned Write)等。Read-Modify-Write(RMW)操作的设计让执行更复杂的事务操作变成了原子操作,当有多个写入者想对相同的内存进行修改时,保证一次只执行一个操作。
RMW 操作在不同的 CPU 家族中是通过不同的方式来支持的:
x86/64 和 Itanium 架构通过 Compare-And-Swap (CAS) 方式来实现
PowerPC、MIPS 和 ARM 架构通过 Load-Link/Store-Conditional (LL/SC) 方式来实现
笔者都是在x64下进行实践的,用的是CAS操作,CAS操作是lock-free技术的基础,我们可以用下面的代码来描述:
template
bool CAS(T* addr, T expected, T value)
{
if (*addr == expected)
{
*addr = value;
return true;
}
return false;
}
在GCC中,CAS操作如下所示:
bool __sync_bool_compare_and_swap (type ptr, type oldval type newval, …)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, …)
这两个函数提供原子的比较和交换,如果ptr == oldval,就将newval写入*ptr,第一个函数在相等并写入的情况下返回true,第二个函数的内置行为和第一个函数相同,只是它返回操作之前的值。
后面的可扩展参数(…)用来指出哪些变量需要memory barrier,因为目前gcc实现的是full barrier,所以可以略掉这个参数。
除过CAS操作,GCC还提供了其他一些原子操作,可以在无锁算法中灵活使用:
type __sync_fetch_and_add (type *ptr, type value, …)
type __sync_fetch_and_sub (type *ptr, type value, …)
type __sync_fetch_and_or (type *ptr, type value, …)
type __sync_fetch_and_and (type *ptr, type value, …)
type __sync_fetch_and_xor (type *ptr, type value, …)
type __sync_fetch_and_nand (type *ptr, type value, …)
type __sync_add_and_fetch (type *ptr, type value, …)
type __sync_sub_and_fetch (type *ptr, type value, …)
type __sync_or_and_fetch (type *ptr, type value, …)
type __sync_and_and_fetch (type *ptr, type value, …)
type __sync_xor_and_fetch (type *ptr, type value, …)
type __sync_nand_and_fetch (type *ptr, type value, …)
_sync*系列的built-in函数,用于提供加减和逻辑运算的原子操作。这两组函数的区别在于第一组返回更新前的值,第二组返回更新后的值。
笔者开发无锁算法感触最深的是复杂度的分解,比如多线程对于一个双向链表的插入或删除操作,如何能一步一步分解成一个一个串联的原子操作,并能保证事务内存的一致性。
ABA问题
ABA问题可以俗称为“调包问题”,
我们再看一个CAS化的例子:
若线程对同一内存地址进行了两次读操作,而两次读操作得到了相同的值,通过 “值相同” 来判定 “值没变”是不可靠的。因为在这两次读操作的时间间隔之内,另外的线程可能已经多次修改了该值,这样就相当于欺骗了前面的线程,使其认为 “值没变”,实际上值已经被篡改过了。
下面是 ABA 问题发生的过程:
T1 线程从共享的内存地址读取值 A;
T1 线程被抢占,线程 T2 开始运行;
T2 线程将共享的内存地址中的值由 A 改成 B,然后又改成 A;
T1 线程继续执行,读取共享的内存地址中的值 A,认为没有改变,然后继续执行
由于 T1 并不知道两次读取的值 A 已经被 “隐性” 的修改过,所以可能产生无法预期的结果。
当 CAS操作循环执行时,存在多个线程交错地对共享的内存地址进行处理,如果实现的不正确,将有可能遇到 ABA 问题。
https://en.cppreference.com/w/cpp/atomic
https://github.com/forhappy/Cplusplus-Concurrency-In-Practice
原子操作
我们写的代码最终都会被翻译为CPU指令,一条最简单加减法语句都有可能会被翻译成几条指令执行;为了避免语句在CPU这一层级上的指令交叉带来的行为不可知,在多线程程序设计时我们必须通过一些方式来进行规范;这里面最常见的做法就是引入互斥锁,其大概的模型就是篮球模式:几个人一起抢球,谁抢到了谁玩,玩完了再把球丢出来重新抢;但互斥锁是操作系统这一层级的,最终映射到CPU上也是一堆指令,是指令就必然会带来额外的开销;
既然CPU指令是多线程不可再分的最小单元,那我们如果有办法将代码语句和指令对应起来,不就不需要引入互斥锁从而提高性能了吗? 而这个对应关系就是所谓的原子操作;在C++11的atomic中有两种做法:
模拟, 比如说对于一个atomic
有相应的CPU层级的对应,这就是一个标准的lock-free类型;
可以通过is_lock_free函数,判断一个atomic是否是lock-free类型
自旋锁
使用原子操作模拟互斥锁的行为就是自旋锁,互斥锁状态是由操作系统控制的,自旋锁的状态是程序员自己控制的;要搞清楚自旋锁我们首先要搞清楚自旋锁模型,常用的自旋锁模型有:
TAS, Test-and-set,有且只有atomic_flag类型与之对应
CAS, Compare-and-swap,对应atomic的compare_exchange_strong 和 compare_exchange_weak,这两个版本的区别是:Weak版本如果数据符合条件被修改,其也可能返回false,就好像不符合修改状态一致;而Strong版本不会有这个问题,但在某些平台上Strong版本比Weak版本慢 [注:在x86平台我没发现他们之间有任何性能差距];绝大多数情况下,我们应该优先选择使用Strong版本;
我针对这两种模型分别实现了两个版本的自旋锁,最终代码可以在性能测试章节中找到,这里我们要注意以下问题:
LOCK时自旋锁是自己轮询状态,如果不引入中断机制,会有大量计算资源浪费到轮询本身上;常用的做法是使用yield切换到其他线程执行,或直接使用sleep暂停当前线程.
无锁编程
如果看了CAS实现的自旋锁代码会发现其有些别扭:每次都需要去重置exp的状态为false;CAS虽然也能实现自旋锁,但通常被我们用来进行无锁编程; 什么是无锁编程呢,让我们以一个例子开始:
template
struct LockFreeStackT
{
struct Node
{
_Ty val;
Node* next;
};
LockFreeStackT() : head_(nullptr) {}
void push(const _Ty& val)
{
Node* node = new Node{ val, head_.load() };
while (!head_.compare_exchange_strong(node->next, node)) {
}
}
void pop()
{
Node* node = head_.load();
while (node && !head_.compare_exchange_strong(node, node->next) {
}
if (node) delete node;
}
std::atomic<Node*> head_;
};
整个逻辑很简单,pop只是push的逆过程,这里我们仅仅只分析一下push:每次push时去获得栈顶元素,生成一个指向栈顶的新元素,然后使用CAS操作去更新栈顶,这里可能有两种情况:
如果新元素的next和栈顶一样,证明在你之前没人操作它,使用新元素替换栈顶退出即可;
如果不一样,证明在你之前已经有人操作它,栈顶已发生改变,该函数会自动更新新元素的next值为改变后的栈顶;然后继续循环检测直到状态1成立退出;
不难看出,其实所谓无锁编程只是将多条指令合并成了一条指令形成一个逻辑完备的最小单元,通过兼容CPU指令执行逻辑形成的一种多线程编程模型;结束了吗,再等等,使用上面的代码,有很大的几率出delete不存在的内存,或内存被多次delete的错误,让我们进入下一节.
ABA问题
维基百科: ABA problem,如果有两个线程[1&2]操作上面的堆栈,初始状态有2个元素: top->A->B,线程1执行pop操作,在CAS前进行线程切换:
注意pop函数中的head_.compare_exchange_strong(node, node->next)语句,如果对C/C++不够熟悉,很容易发生误解;我们不考虑函数包装等复杂情况,只考虑最简单的情况下在调用CAS原子操作前至少还有参数压栈操作,也就是说node->next不是调用时确定的,而是在参数压栈时确定的;前面说的CAS操作前进行线程切换,切换时{node, node->next}对应的是{A, B}.
然后线程2执行pop操作,将A,B都删掉,然后创建了一个新元素push进去,因为操作系统的内存分配机制会重复使用之前释放的内存,恰好push进去的内存地址和A一样,我们记为A’,这时候切换到线程1,CAS操作检查到A没变化成功将B设为栈顶,但B是一个已经被释放的内存块…
解决ABA问题的办法无非就是通过打标签标识A和A’为不同的指针,这下总结束了吧,事实上还没有,再次进入下一节.
内存回收
还是先看上面的代码,在Pop时先获得了头指针Node* node = head_.load();,如果这时候发生线程切换并且这个节点被另一个线程删除,当线程切回时候node无效造成node->next访问异常…,对于这个问题,现在流行的处理方式主要有:
Lock-Free Reference Counting: 引用计数方式,严格的说应该是全局计数方式;每次POP时首先增加计数,然后处理完后做检测,计数如果大于1证明其他线程也在操作,把节点存起来;只要检测到计数等于1,证明目前只有自己操作,可以删除当前节点和之前缓存的节点,删除之前节点时必须进行二次判断来解决交换后,其他线程Acquire的问题;具体可以参见Paper: Lock-Free Reference Counting, Efficient and Reliable Lock-Free Memory Reclamation Based on Reference Counting
Hazard pointer: 使用POP的线程,都有一个自己可以写的thread_local变量,每次得到的旧指针都存入其中,当交换完成后将该变量置为0;对于其他线程来说每次删除前对整个Hazard pointer表遍历一遍,如果发现其他线程也在访问,就把要删除的节点放入将删列表中,否则可以直接删除;定时对将删列表中的节点按照之前的规则和整个Hazard pointer表做比较,只要Hazard pointer表不持有这个节点就可删除;可参考维基百科: Hazard pointer
Epoch Based Reclamation
Quiescent State Based Reclamation
循环CAS操作对时会大量占用cpu,对系统时间的开销也是很大。这也是基于循环CAS实现的各种自旋锁不适合做操作和等待时间太长的并发操作的原因。
一、基于锁的编程的缺点
在传统的多线程编程中,多线程之间一般用各种锁的机制来保证正确的对共享资源进行访问和操作。只要需要共享某些数据,就应当将对它的访问串行化。比如像++count(count是整型变量)这样的简单操作也得加锁,因为即便是增量操作这样的操作,实际上也是分三步进行的:读、改、写(回)。
在使用锁机制的过程中,即便在锁的粒度、负载、竞争、死锁等需要重点控制的方面解决的很好,也无法彻底避免这种机制的如下一些缺点:
- 锁机制会引起线程的阻塞,对于没有能占用到锁的线程或者进程,将一直等待到锁的占有者释放锁资源后才能继续执行,而等待时间理论上是不可设置和预估的。
- 申请和释放锁的操作,增加了很多访问共享资源的消耗,尤其是在锁竞争很严重的时候。
- 现有实现的各种锁机制,都不能很好的避免编程开发者设计实现的程序出现死锁或者活锁的可能。
- 难以调试。
二、无锁编程的定义
无锁编程按字面最直观的理解是不使用锁的情况下实现多线程之间对变量同步和访问的一种程序设计实现方案。一个锁无关的程序能够确保它所有线程中至少有一个能够继续往下执行,而有些线程可能会被的延迟。然而在整体上,在某个时刻至少有一个线程能够执行下去。作为整体进程总是在前进的,尽管有些线程的进度可能没有其它线程进行的快。
三、无锁编程的原理
无锁编程具体使用技术方法包括:原子操作(atomic operations), 内存栅栏(memory barriers), 内存顺序冲突(memory order), 指令序列一致性(sequential consistency)和顺ABA现象等等。其中最重要的是原子操作,其中最常用的原子操作又是CAS(COMPARE AND SWAP)算法。
CAS算法的过程是这样:它包含3个参数CAS(V,E,N)。V表示要更新的变量,E表示预期值,N表示新值。仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。最后,CAS返回当前V的真实值。CAS操作是抱着乐观的态度进行的,它总是认为自己可以成功完成操作。当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。
在java语言中在java.util.concurrent包中大量实现都是建立在基于CAS实现Lock-Free算法上。java.util.concurrent.atomic提供了基于CAS实现的若干类:
- AtomicBoolean – 原子布尔
- AtomicInteger – 原子整型
- AtomicIntegerArray – 原子整型数组
- AtomicLong – 原子长整型
- AtomicLongArray – 原子长整型数组
- AtomicReference – 原子引用
- AtomicReferenceArray – 原子引用数组
- AtomicMarkableReference – 原子标记引用
- AtomicStampedReference – 原子时间戳记引用(解决ABA现象)
- AtomicIntegerFieldUpdater – 用来包裹对整形 volatile 域的原子操作
- AtomicLongFieldUpdater – 用来包裹对长整型 volatile 域的原子操作
- AtomicReferenceFieldUpdater – 用来包裹对对象 volatile 域的原子操作
引入这些类的主要目的就是为了实现Lock-Free算法和相关数据结构
在无锁编程中,并不是说所有操作都是原子的,只有一个很有限的操作集是原子的,这就意味着无锁编程十分困难。那么这个有限的操作集是否存在,存在的话包含哪些原子操作呢? 2003 年 Maurice Herlihy 的一篇论文 ”Wait-Free Synchronization”[3] 解决了这个问题。这里给出文章的结论,文章指出像 test-and-set,swap,fetch-and-add 甚至是原子队列对于多线程而言都无法做到 lock-free 。而最朴素最简单的原语 CAS(compare-and-swap) 操作即可以完成所有的无锁功能,其他的如 LL/SC (load linked/store conditional) 。 CAS 的伪码如下:
template
bool CAS(T* addr, T expected, T value)
{
if (*addr == expected)
{
*addr = value;
return true;
}
return false;
}
CAS 将 expected 与一个内存地址进行比较,如果比较成功,就将内存内容替换为 new 。当前大多数机器都在硬件级实现了这个操作,在 Inter 处理器上这个操作是 CMPXCHG ,因而 CAS 是一个最基础的原子操作。
wait-free / lock-free 与 有锁对比
wait-free 的过程可以通过有限步骤完成,而不管其他线程的速度。
lock-free 的过程保证至少一个线程在执行,其他线程可能会被延迟,但系统整体仍在前进。
有锁的情况下,如果某个线程占有锁,则其他线程就无法执行。更普通的,有锁需要避免死锁和活锁的情况。
2 无锁编程的相关研究与进展
本节内容对文献 [2] 进行概述,介绍当前已经实现的无锁算法与数据结构。
近二十年来研究者们对 lock-free 和 wait-free 的算法和数据结构进行了大量的研究。实现了一些 wait-free 和 lock-free 的算法,比如 FIFO 的队列和 LIFO 的栈,而更复杂的优化级队列、 hash 表及红黑树的 lock-free 算法也渐渐为人所知。
无锁算法的实现都依赖内存屏障,因而具有平台相关性。下面将列举目前已经较为成熟的原子操作和算法数据结构的实现。
MidiShare Source Code is available under the GPL license. MidiShare includes implementations of lock-free FIFO queues and LIFO stacks.
Appcore is an SMP and HyperThread friendly library which uses Lock-free techniques to implement stacks, queues, linked lists and other useful data structures. Appcore appears currently to be for x86 computers running Windows. The licensing terms of Appcore are extremely unclear.
Noble – a library of non-blocking synchronisation protocols. Implements lock-free stack, queue, singly linked list, snapshots and registers. Noble is distributed under a license which only permits non-commercial academic use.
lock-free-lib published under the GPL license. Includes implementations of software transactional memory, multi-workd CAS primitives, skip lists, binary search trees, and red-black trees. For Alpha, Mips, ia64, x86, PPC, and Sparc.
Nonblocking multiprocessor/multithread algorithms in C++ (for MSVC/x86) posted by Joshua Scholar to musicdsp.org , and are presumably in the public domain. Included are queue, stack, reference-counted garbage collection, memory allocation, templates for atomic algorithms and types. This code is largely untested. A local mirror is here .
Qprof includes the Atomic_ops library of atomic operations and data structures under an MIT-style license. Only available for Linux at the moment, but there are plans to support other platforms. download available here
Amino Concurrent Building Blocks provides lock free datastructures and STM for C++ and Java under an Apache Software (2.0) licence.
其中 Noble 已经进行了商业化, License 相当不便宜。
3 性能分析
本节对 PTHREAD 中的 mutex , windows 中的原子增,及 CAS 原子操作进行对比,并对 MidiShare 中实现的无锁 FIFO 队列与基于 STL 的 list 实现的有锁队列进行的性能对比和分析,并对优化方式进行了总结。
3.1 原子增的性能测试
测试机 CPU 为 Intel E5300 2.60GHZ
首先是对简单的递增操作进行了测试,分别对无任何同步机制的 ++ 操作、 pthread_mutex 保护的 ++ 操作,以及 CAS 的语义实现的 atomic_add1() 以及 windows 下的 interlockedIncrease() 进行了单个线程情况下的定量测试。
i++
3.2 亿
lock(p_mutex);i++;unlock(p_mutex);
2 千万
CAS_atomic_add1(i)
4 千万
interlockedIncrease(&i)
4 千万
首先在无任何同步情况下, CPU 可以每秒执行 ++ 操作 3.2 亿次,接近于 CPU 的主频速率。而每次 ++ 时执行 thread_mutex_lock() 及 unlock() 操作情况下, CPU 每秒只能执行 2 千万次,这就是说 CPU 每秒钟可以执行加锁及解锁操作共 4 千万次,加解锁的开销是执行加法指令的的 15 倍左右。而 CAS 的情况稍好,为每秒 4 千万次。这个速度与 windows 下的 interlockedIncrease() 的执行速度十分近似。
从上面的测试结果来看, windows 下的原子增操作与 CAS 实现的增操作代价基本是相同的,估计 windows 底层也是借助汇编指令 CMPXCHG 的 CAS 来实现原子增操作的。当然 pthread_mutex 作为一种互斥锁,也是拥有相当高的效率的,在没有锁突然的情况下,加锁开销与一次 CAS 的开销相当。
但如果对比无同步的 ++ 操作,硬件级的同步也造成了至少 8 倍的性能下降。
接着,对 pthread_mutex 的程序进行了逻辑优化,分别测试了 ++ 执行 8 次、 20,100 次进行一次加解锁的情况。
lock();for(k=0;k<8;i++,k++);unlock()
1.2 亿
lock();for(k=0;k<20;i++,k++);unlock()
2 亿
lock();for(k=0;k<100;i++,k++);unlock()
3.4 亿
结果 CPU 每秒钟可以执行 ++ 的次数为 1.2 亿 /2 亿 /3.4 亿,这种情况与预期是一致的,因为每秒钟调用加解锁的次数分别是原来的 1/8 、 1/20 和 1/100 ,当执行 100 次 ++ 进行一次加解锁后,性能已经达到了无任何同步时的性能。当然原子的 interlockedIncrease() 和 CAS 实现的 atomic_add1() 都不具备这种批量处理的改进优势,无论如果,它们最好的执行情况已经固定了。
对于在单线程与多线程的情况下的 windows 下的原子操作的性能测试情况,可以参考文献 [4] ,这里只列出其中的结论。其所列的测试机 CPU 为 Intel2.66GHZ 双核处理器。
单个线程执行 2 百万次原子增操作
interlockedIncrease
78ms
Windows CriticalSection
172ms
OpenMP 的 lock 操作
250ms
两个线程对共享变量执行 2 百万次原子增操作
interlockedIncrease
156ms
Windows CriticalSection
3156ms
OpenMP 的 lock 操作
1063ms
3.2 无锁队列与有锁队列的性能测试
这里测试的无锁列队由 MidiShare 实现的,而有锁队列是通过 pthread_mutex 与 c++ 的 STL list 共同实现。这里只列出测试结果。
对于存储相同的数据的情况下,从主线程 enque 并从子线程 deque ,计算每秒钟 enque/deque 的次数,当然二者基本上是相同的。
无锁队列的性能在 150w -200w 次入队操作,这个性能已经无法再有任何提高,因为每次入队出队操作都是硬件级的互斥。而对于有锁队列,根据每次加解锁之间处理入队的次数的不同,有以下的结果:
lock();for(k=0;k<x;i++,k++);unlock()
结果(次/s)
x=1
40 万
x=10
190 万
x=128
350 万
x=1000
400 万
x=10000
396 万
这说明通过对锁之间的数据进行批处理,可以极大的提高系统的性能,而使用原子操作,则无法实现批处理上的改进。
4 结论
通过上面的无锁和有锁的性能测试,可以得出这样的结论,对于 CAS 实现的硬件级的互斥,其单次操作性能比相同条件下的应用层的较为高效,但当多个线程并发时,硬件级的互斥引入的代价与应用层的锁争用同样令人惋惜。因此如果纯粹希望通过使用 CAS 无锁算法及相关数据结构而带来程序性能的大量提升是不可能的,硬件级原子操作使应用层操作变慢,而且无法再度优化。相反通过对有锁多线程程序的良好设计,可以使程序性能没有任何下降,可以实现高度的并发性。
但是我们也要看到应用层无锁的好处,比如不需要程序员再去考虑死锁、优先级反转等棘手的问题,因此在对应用程序不太复杂,而对性能要求稍高时,可以采用有锁多线程。而程序较为复杂,性能要求满足使用的情况下,可以使用应用级无锁算法。
至于如何对多线程的工作模式进行更好的调度,可以参考文献 [5] ,文献介绍了一种较好的线程间合作的工作模式,当然前提是机器的处理器个数较多,足以支持多组线程并行的工作。如果处理器个数较,较多的线程之间在各个核心上来回调度增加了系统上下文切换的开销,会导致系统整体性能下降。
参考文献
[1] Lock-Free Data Structures http://www.drdobbs.com/184401865
[2] Some notes on lock-free wait-free algorithms http://www.rossbencina.com/code/lockfree
[3] Wait-Free Synchronization http://www.podc.org/dijkstra/2003.html
[4] OpenMP 创建线程中的锁及原子操作性能比较 http://blog.163.com/kangtao-520/blog/static/772561452009510751068/
[5] 多核编程中的线程分组竞争模式 http://kangtao-520.blog.163.com/blog/static/77256145200951074121305/
传统的共享数据访问方式是采用同步原语(临界区、锁、条件变量等)来达到共享数据的安全访问,然而,同步恰恰和并行编程是对立的,很容易成为并行程序中的瓶颈。一方面,有些同步原语是操作系统的内核对象,调用该原语会带来昂贵的上下文切换(用户态切换到内核态)代价,同时,内核对象是一个比较有限的资源。另一方面,同步杜绝了并行操作,一个线程在访问共享数据的时候,其他的多个线程必须在排队空闲等待,同时,同步可扩展性很弱,随着并行线程的增加,很容易成为程序的一个瓶颈,甚至出现,服务性能吞吐量并没随CPU核数增加或并发线程的增加呈现线性增长,相反出现下降的情况。
于是,人们开始研究对共享数据进行并发访问的数据结构和算法,通常有以下几方面:
1. Transactional memory --- 事务性内存
2. Fine-grained algorithms --- 细粒度(锁)算法
3. Lock-free data structures --- 无锁数据结构
(1) 事务内存(Transactional memory)TM是一个软件技术,简化了并发程序的编写。 TM借鉴了在数据库社区中首先建立和发展起来的概念, 基本的想法是要申明一个代码区域作为一个事务。一个事务(transaction ) 执行并原子地提交所有结果到内存(如果事务成功),或中止并取消所有的结果(如果事务失败)。 TM的关键是提供原子性(Atomicity),一致性(Consistency )和隔离性(Isolation )这些要素。 事务可以安全地并行执行,以取代现有的痛苦和容易犯错误(下面几点)的技术,如锁和信号量。 还有一个潜在的性能优势。 我们知道锁是悲观的(pessimistic ),并假设上锁的线程将写入数据,因此,其他线程的进展被阻塞。 然而访问锁定值的两个事务可以并行地进行,且回滚只发生在当事务之一写入数据的时候。但是,目前还没有嵌入式的事务内存,比较难和传统代码集成,需要软件做出比较大的变化,同时,软件TM性能开销极大,2-10倍的速度下降是常见的,这也限制了软件TM的广泛使用
1. 因为忘记使用锁而导致条件竞争(race condition)
2. 因为不正确的加锁顺序而导致死锁(deadlock)
3. 因为未被捕捉的异常而造成程序崩溃(corruption)
4. 因为错误地忽略了通知,造成线程无法正常唤醒(lost wakeup)
(2) 细粒度(锁)算法是一种基于另类的同步方法的算法,它通常基于“轻量级的”原子性原语(比如自旋锁),而不是基于系统提供的昂贵消耗的同步原语。细粒度(锁)算法适用于任何锁持有时间少于将一个线程阻塞和唤醒所需要的时间的场合,由于锁粒度极小,在此类原语之上构建的数据结构,可以并行读取,甚至并发写入。Linux 4.4以前的内核就是采用_spin_lock自旋锁这种细粒度锁算法来安全访问共享的listen socket,在并发连接相对轻量的情况下,其性能和无锁性能相媲美。然而,在高并发连接的场景下,细粒度(锁)算法就会成为并发程序的瓶颈所在。
(3) 无锁数据结构,为解决在高并发场景下,细粒度锁无法避免的性能瓶颈,将共享数据放入无锁的数据结构中,采用原子修改的方式来访问共享数据。
目前,常见的无锁数据结构主要有:无锁队列(lock free queue)、无锁容器(b+tree、list、hashmap等)。
- C++11 标准的原子性操作: load、store、compare_exchange_weak、compare_exchange_strong
- 一个无限循环: while ( true ) { … }
- 局部变量的安全性(guards):t = guard.protect( m_pTail, node_to_value() );
- 补偿策略(functor bkoff):这不是必须的,但可以在连接很多的情况下缓解处理器的压力,尤其是多个线程逐个地调用队列时。
helping方法:本例中,dequeue中帮助enqueue将m_pTail设置正确。
// It is needed to help enqueue
m_pTail.compare_exchange_strong( t, pNext, memory_model::memory_order_release,
memory_model::memory_order_relaxed );
标准原子操作中使用的内存模型(memory model),也就是内存栅栏(屏障):memory_order_release、memory_order_acquire等
```
下面分别讲一下上面提到无锁队列实现中的6个特征。
- 原子性、原子性原语
我们知道无论是何种情况,只要有共享的地方,就离不开同步,也就是concurrency。对共享资源的安全访问,在不使用锁、同步原语的情况下,只能依赖于硬件支持的原子性操作,离开原子操作的保证,无锁编程(lock-free programming)将变得不可能。
留意本例的无锁队列的实现例子,我们发现原子性操作可以简单划分为两部分:
``` - 原子性读写(atomic read and write):本例中的原子load(读)、原子store(写)
- 原子性交换(Atomic Read-Modify-Write – RMW):本例中的compare_exchange_weak、compare_exchange_strong
原子操作可认为是一个不可分的操作;要么发生,要么没发生,我们看不到任何执行的中间过程,不存在部分结果(partial effects)。可以想象的到,原子操作要保证要么全部发生,要么全部没发生,这样原子操作绝对不是一个廉价的消耗低的指令,相反,原子操作是一个较为昂贵的指令。那么在无锁编程中,我们要避免滥用原子操作,那么什么情况下,我们需要对共享变量的操作采用原子操作呢?对变量的普通的读取赋值操作是原子的吗?
通常情况下,我们有一个对共享变量必须使用原子操作的规则:
任何时刻,只要存在两个或多个线程并发地对同一个共享变量进行操作,并且这些操作中的其中一个是执行了写操作,那么所有的线程都必须使用原子操作。
```
如果违反上面的规则,即存在某个线程使用了非原子操作,那么你将会陷入一个在C++11标准中称之为数据竞争(data race)(这里的数据竞争和Java中的data race概念,以及更通用的race condition是不一样的)的情形。如果你引发了数据竞争,那么就会得到一个”未定义行为(undefined behavior)”的结果,它们会导致torn reads(撕裂读)和torn writes(撕裂写),也就是一个非完整的读写。
什么样的内存操作是原子的呢?通常情况下,如果一个内存操作使用了多条CPU指令,那么这个内存操作是非原子的。那么只使用一条CPU指令的内存操作是不是就一定是原子的呢?答案是不一定,某些仅仅使用一条CPU的内存操作,在绝大多数CPU架构上是原子,但是,在个别CPU架构上是非原子的。如果,我们想写出可移植的代码,就不能做出使用一条CPU指令的内存操作一定是原子的假设。
在C/C++中,所有的内存操作都被假定为非原子性的,即使是普通的32位整形赋值,除非编译器或硬件厂商有特殊说明这个赋值操作是原子的。在所有的现代x86,x64,Itanium,SPARC,ARM和PowerPC处理器中,普通的32位整形,只要内存地址是对齐的,那么赋值操作就是原子操作,这个保证是特定平台下编译器和处理器做出的保证。由于C/C++语言标准并没对整型赋值是原子操作做出保证,于是,要想写出真正可移植的C和C++代码时,我们只能使用C++11提供的原子库( C++11 atomic library)来保证对变量的load(读)和store(写)是原子的。
2.1 不能不说的关键字:volatile
通过上面我们知道,在现代处理器中,对于一个对齐的整形类型(整形或指针),其读写操作是原子的,而对于现代编译器,用volatile修饰的基本类型正确对齐的保障,并且限制了编译器对其优化。这样通过对int变量加上volatile修饰,我们就能对该变量进行原子性读写。
volatile int i=10;//用volatile修饰变量i
......//something happened
int b = i;//atomic read
由于volatile 在某种程度上限制了编译器的优化,而很多时候,对于同一个变量,我们在某些地方有原子性读写的需求,在某些地方我们又不需要原子性读写,这个时候希望编译器该优化的时候就优化。然而,不加volatile修饰,那么就做不到前面一点。加了volatile,后面这一方面就无从谈起,怎么办?其实,这里有个小技巧可以达到这个目的:
int i = 2; //变量i还是不用加volatile修饰
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
#define READ_ONCE(x) ACCESS_ONCE(x)
#define WRITE_ONCE(x, val) ({ ACCESS_ONCE(x) = (val); })
a = READ_ONCE(i);
WRITE_ONCE(i, 2);
通过上面我们知道,用volatile修饰的int在现代处理器中,能够做到原子性的读写,并且限制编译器的优化,每次都是从内存中读取最新的值,很多同学就误以为volatile能够保证原子性并且具有Memery Barrier的作用。其实vloatile既不能保证原子性,也不会有任何的Memery Barrier(内存栅栏)的保证。上面例子中,volatile仅仅是保证int的地址对齐,而对齐后的整形在现代处理器中,是能够做到原子性读写的。在C++中volatile具有以下特性:
1. 易变性:所谓的易变性,在汇编层面反映出来,就是两条语句,下一条语句不会直接使用上一条语句对应的volatile变量的寄存器内容,而是重新从内存中读取。
2. "不可优化"性:volatile告诉编译器,不要对我这个变量进行各种激进的优化,甚至将变量直接消除,保证程序员写在代码中的指令,一定会被执行。
3. "顺序性":能够保证Volatile变量间的顺序性,编译器不会进行乱序优化。Volatile变量与非Volatile变量的顺序,编译器不保证顺序,可能会进行乱序优化。
2.2 Compare-And-Swap(CAS)
对于CAS相信大家都不陌生,在学术圈,compare-and-swap (CAS)被认为是最基础的一种原子性RMW操作,其伪代码如下:
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
else
return false ;
}
上面的CAS返回bool告知原子性交换是否成功,然而在有些应用场景中,我们希望CAS 失败后,能够返回内存单元中的当前值,于是就有一个称为 valued CAS的变种,伪代码如下:
int CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return nExpected ;
}
else
return *pAddr;
}
CAS作为最基础的RMW操作,其他所有RMW操作都可以通过CAS来实现,例如 fetch-and-add(FAA),伪代码如下:
int FAA( int * pAddr, int nIncr )
{
int ncur = *pAddr;
do {} while ( !compare_exchange( pAddr, ncur, ncur + nIncr ) ;//compare_exchange失败会返回当前值于ncur
return ncur ;
}
在C++11的原子lib中,主要有以下RMW操作:
std::atomic<>::fetch_add()
std::atomic<>::fetch_sub()
std::atomic<>::fetch_and()
std::atomic<>::fetch_or()
std::atomic<>::fetch_xor()
std::atomic<>::exchange()
std::atomic<>::compare_exchange_strong()
std::atomic<>::compare_exchange_weak()
其中compare_exchange_weak()就是最基础的CAS,使用compare_exchange_weak()我们可以实现其他所有的RMW操作,C++11 atomic library中的原子RMW操作有点少,不能满足我们实际需求,我们可以自己动手实现自己需要的原子RMW操作。
例如:我们需要一个原子对内存中值执行乘法,也就是 atomic fetch_multiply,实现伪代码如下:
uint32_t fetch_multiply(std::atomic<uint32_t>& shared, uint32_t multiplier)
{
uint32_t oldValue = shared.load();
while (!shared.compare_exchange_weak(oldValue, oldValue * multiplier))
{
}
return oldValue;
}
以上的原子RMW操作都是只能对一个integer变量进行原子修改操作,如果我们想同时对两个integer变量进行原子操作,怎么实现呢?我们知道C++11的原子库std::atomic<>是一个模版,这样我们可以用一个结构体来包含两个integer变量,来对结构体进行原子修改,实现如下:
struct Terms
{
uint32_t x;
uint32_t y;
};
std::atomic<Terms> terms;
void atomicFibonacciStep()
{
Terms oldTerms = terms.load();
Terms newTerms;
do
{
newTerms.x = oldTerms.y;
newTerms.y = oldTerms.x + oldTerms.y;
}
while (!terms.compare_exchange_weak(oldTerms, newTerms));
}
到这里,可能大家会有疑问了,是不是terms.compare_exchange_weak(oldTerms, newTerms)在内部加了锁,要不怎么能够原子修改呢?
C++11的原子库std::atomic<> template可以是任何类型(int、bool等buil-in type,或user-defined type),但并不是所有的类型的原子操作是lock-free的。C++11 标准库 std::atomic 提供了针对整形(integral)和指针类型的特化实现,其中 integal 代表了如下类型char, signed char, unsigned char, short, unsigned short, int, unsigned int, long, unsigned long, long long, unsigned long long, char16_t, char32_t, wchar_t,这些特化实现,都包含了一个is_lock_free()成员来用于判断该原子类型是原子操作是否是lock-free的。
上面的例子中,在X64平台下,用GCC4.9.2编译出来的代码terms.compare_exchange_weak(oldTerms, newTerms)是lock-free的,在其他平台下就不能保证了。在实际应用中,通常情况下,同时满足以下条件的原子类的原子操作才能做出是lock-free的保证:
1. The compiler is a recent version MSVC, GCC or Clang.
2. The target processor is x86, x64 or ARMv7 (and possibly others).
3. The atomic type is std::atomic<uint32_t>, std::atomic<uint64_t> or std::atomic<T*> for some type T.
2.3 Weak and Strong CAS
相信大家看到C++11的CAS操作有两个compare_exchange_weak和compare_exchange_strong,CAS怎么还有强弱之分呢?现代处理器架构对CAS的实现分成两大阵营:(1)实现了原子性CAS原语 – X86、Intel Itanium、Sparc等处理器架构,最早实现于IBM System 370。(2)实现LL/SC对(load-linked/store-conditional) – PowerPC, MIPS, Alpha, ARM 等处理器架构,最早实现于DEC,通过LL/SC对可以实现原子性CAS,但在一些情况下它并不具有原子性。为什么会存在LL/SC对的使用,而不直接实现CAS原语呢?要说明LL/SC对存在的原因,不得不说一下无锁编程中的一个棘手问题:ABA问题。
int compare_and_swap (int* reg, int oldval, int newval)
{
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
return old_reg_val;
}
这个操作可以变种为返回bool值的形式(返回 bool值的好处在于,可以调用者知道有没有更新成功):
1
2
3
4
5
6
7
8
bool compare_and_swap (int *accum, int *dest, int newval)
{
if ( *accum == *dest ) {
*dest = newval;
return true;
}
return false;
}
与CAS相似的还有下面的原子操作:(这些东西大家自己看Wikipedia吧)
Fetch And Add,一般用来对变量做 +1 的原子操作
Test-and-set,写值到某个内存位置并传回其旧值。汇编指令BST
Test and Test-and-set,用来低低Test-and-Set的资源争夺情况
注:在实际的C/C++程序中,CAS的各种实现版本如下:
1)GCC的CAS
GCC4.1+版本中支持CAS的原子操作(完整的原子操作可参看 GCC Atomic Builtins)
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, …)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, …)
2)Windows的CAS
在Windows下,你可以使用下面的Windows API来完成CAS:(完整的Windows原子操作可参看MSDN的InterLocked Functions)
InterlockedCompareExchange ( __inout LONG volatile *Target,
__in LONG Exchange,
__in LONG Comperand);
3) C++11中的CAS
C++11中的STL中的atomic类的函数可以让你跨平台。(完整的C++11的原子操作可参看 Atomic Operation Library)
template< class T >
bool atomic_compare_exchange_weak( std::atomic* obj,
T* expected, T desired );
template< class T >
bool atomic_compare_exchange_weak( volatile std::atomic* obj,
T* expected, T desired );
SLA,Service Level Agreement,SLA 99.99代表10K的请求最多一次失败或者超时)和延时。而离线架构在意的是吞吐,SLA的不会那么严苛,比如99.9。离线架构一般要有流控,以控制用户发送请求的速度。以免多于服务端处理能力的请求造成大量的数据在buffer或者队列里堆积,造成大量的超时。在线架构不可能有流控了,你不能限制用户的请求。因此在线架构对于弹性扩容有很高的要求,在大量请求到来时自动扩展后台的服务能力。比如当前的请求已经占用了集群的70%的资源时,系统需要自动的扩容;相反,当前的请求仅仅占用了集群20%的资源时,有必要回收一部分资源了。要知道,公司机房的电费还是很贵的。
几个原则吧:
不要使用全局锁。使用全局锁代表在需要请求锁时,其他为得到锁的线程都会等待,这将导致服务能力急剧下降。
一定要注意锁的作用范围,一定要保证锁作用于足够小的范围。一定不要在锁定区域有等待操作,比如IO调用。
尽量的考虑修改架构,避免加锁。
试想一个场景,为了服务质量,我们可能发送多个请求到后台,以达到:
高可用行,后台的某个节点挂了,有其他的backup request会被请求。如果节点的SLA是99%(很低了),那么发送2个请求到后台,SLA可以达到99.99%;如果单个节点的SLA是99.9%的话,SLA可以达到99.9999了,即百万次请求至多一次失败。
低延时,第一个回来的请求会响应,这样的话能够保证某些慢的节点不会影响系统整体的延时。
那么如何判断第一个请求是第一个达到的呢?
先想一个比较粗暴的办法:使用一个set记录未返回的request 的id,然后在接到响应时,查看这个set有没有这个id,如果有,删除它,并且响应client;第二个以后的响应达到时,由于在set已经没有这个id了,因此这些请求将被丢弃。
这个里边涉及到对set的读和写操作,这个需要加锁;如果这个set是进程内可见的,那么这个锁就是进程级别的(或者说该进程或者说是线程的子线程都是可见的),加锁时很多线程都会等待该锁。这样的话对性能会有很大损耗。
这个方法对于每秒几百次请求是没有问题的。但是如果达到千这个级别,那么锁的使用会达到数千次(比如1000个请求,发送3个请求到后台,那么每次写set加一次锁,3个请求回来都会加一次锁,因此相当于一个真实的请求会加锁4次,1000个请求就是4000次,想想都恐怖,1s要加锁4000次,锁的代价再小也很恐怖吧,别说set的插入和查询,删除也有不可忽略的性能损耗)。
那么可不可以加线程级别的锁?线程级别的锁会减少对其他线程的影响。但是,set如果也是线程级别的,那么得保证异步回调的借口也得是在同一个线程才可以。否则这个线程发出的请求,被其他的线程得到,那么上述的逻辑是不通的,因为set是线程级别的,对于其他线程来说是不可见的。这样的话如果架构能够保证一个异步请求的返回,也是在同一个线程处理就好了。那么,如果架构可以这么保证,那么你根本不需要锁,为什么呢?因为一个线程都是顺序执行的,不会有资源的竞争,因此读写set都是安全的,因此不需要加锁。
那么问题来了,架构如何支持这个异步回调也是走到相同的线程里?
一个实现就是实现一个线程池,对于特定的request id,基于一定的规则将他调度给一个工作线程;等到异步返回时,再通过这个request id调度给相同的线程处理。
那么如何实现一个线程池?boost 里有; 如果调度,boost 支持调度给哪个线程。
一般采用原子级的read-modify-write原语来实现Lock-Free算法,其中LL和SC是Lock-Free理论研究领域的理想原语,但实现这些原语需要CPU指令的支持,非常遗憾的是目前没有任何CPU直接实现了SC原语。根据此理论,业界在原子操作的基础上提出了著名的CAS(Compare-And-Swap)操作来实现Lock-Free算法,Intel实现了一条类似该操作的指令:cmpxchg8。
CAS原语负责将某处内存地址的值(1个字节)与一个期望值进行比较,如果相等,则将该内存地址处的值替换为新值,CAS 操作伪码描述如下:
Bool CAS(T* addr, T expected, T newValue)
{
if(*addr == expected )
{
*addr= newValue;
returntrue;
}
else
returnfalse;
}
CAS实际操作
do
{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS(内存地址,备份的旧数据,新数据))
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出CAS操作是基于共享数据不会被修改的假设,采用了类似于数据库的commit-retry的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
CAS的Linux解法
cmpxchg先比较内存地址的值是否与传入的值相等,如果相等则执行xchg逻辑。
inline int CAS(unsigned long* mem, unsignedlong newval, unsigned long oldval)
{
__typeof(mem) ret;
//这里测试的使用64位系统,如果是32位,这里使用cmpschgl
__asm__volatile (“lock; cmpxchgq %2,%1”
:”=a”(ret), “=m”(mem)
:”r”(newval), “m”(*mem), “0”(oldval));
returnret==oldval;
}
分布式系统中,多线程中,为了保持一致性,锁通常是一种很好用的方式,但是锁是涉及到操作系统层面的切换,是低效的一种方式,要尽量使用无锁的编程思想。
锁是一种悲观的策略,每次临界区操作都会产生冲突。无锁是一种乐观的策略,假设对资源的访问没有冲突。其有两大优点:
1.高并发情况下,比锁拥有更好的性能
2.死锁免疫
(一:基础类)
1.与众不同的并发策略:比较交换(CAS)
与锁相比,使用比较交换(下文简称CAS)会使程序看起来更加复杂一些。但由于其非阻塞性,它对死锁问题天生免疫,并且,线程间的相互影响也远远比基于锁的方式要小。更为重要的是,使用无锁的方式完全没有锁竞争带来的系统开销,也没有线程间频繁调度带来的开销,因此,它要比基于锁的方式拥有更优越的性能。
CAS算法的过程是这样:它包含三个参数CAS(V,E,N)。V表示要更新的变量,E表示预期值,N表示新值。仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。最后,CAS返回当前V的真实值。CAS操作是抱着乐观的态度进行的,它总是认为自己可以成功完成操作。当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。基于这样的原理,CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
简单地说,CAS需要你额外给出一个期望值,也就是你认为这个变量现在应该是什么样子的。如果变量不是你想象的那样,那说明它已经被别人修改过了。你就重新读取,再次尝试修改就好了。
在硬件层面,大部分的现代处理器都已经支持原子化的CAS指令。在JDK 5.0以后,虚拟机便可以使用这个指令来实现并发操作和并发数据结构,并且,这种操作在虚拟机中可以说是无处不在。
2.无锁的线程安全整数:AtomicInteger LongAddr系列
为了让Java程序员能够受益于CAS等CPU指令,JDK并发包中有一个atomic包,里面实现了一些直接使用CAS操作的线程安全的类型。其中,最常用的一个类,应该就是AtomicIn-teger。你可以把它看做是一个整数。但是与Inte-ger不同,它是可变的,并且是线程安全的。对其进行修改等任何操作,都是用CAS指令进行的。这里简单列举一下AtomicInteger的一些主要方法,对于其他原子类,操作也是非常类似的。
3.Java中的指针:Unsafe类
在AtomicInteger中compareAndSet()方法:
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
有一个特殊的变量unsafe,它是sun.misc.Unsafe类型。这个类封装了一些不安全的操作,类似C语言中指针的操作。
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
方法是一个navtive方法,它的参数含义是:
var1为给定的对象
var2为对象内的偏移量(其实就是一个字段到对象头部的偏移量,通过这个偏移量可以快速定位字段)
var4表示期望值
xvar5要设置的值。如果指定的字段的值等于var4,那么就会把它设置为var5。
不难看出,compareAndSwapInt()方法的内部,必然是使用CAS原子指令来完成的。
注意:根据Java类加载器的工作原理,应用程序的类由App Loader加载。而系统核心类,如rt.jar中的类由Bootstrap类加载器加载。Bootstrap加载器没有Java对象的对象,因此试图获得这个类加载器会返回null。所以,当一个类的类加载器为null时,说明它是由Bootstrap加载的,而这个类也极有可能是rt.jar中的类。就是由rt.jar加载
netty中的无锁队列底层MPSC队列(JCTools)无锁就是利用这个实现
4.无锁的对象引用:AtomicReference
AtomicReference和AtomicInteger非常类似,不同之处就在于AtomicInteger是对整数的封装,而AtomicReference则对应普通的对象引用。也就是它可以保证你在修改对象引用时的线程安全性。在介绍AtomicReference的同时,我希望同时提出一个有关原子操作的逻辑上的不足。
之前我们说过,线程判断被修改对象是否可以正确写入的条件是对象的当前值和期望值是否一致。这个逻辑从一般意义上来说是正确的。但有可能出现一个小小的例外,就是当你获得对象当前数据后,在准备修改为新值前,对象的值被其他线程连续修改了两次,而经过这两次修改后,对象的值又恢复为旧值。这样,当前线程就无法正确判断这个对象究竟是否被修改过。
5.带有时间戳的对象引用:AtomicStampedReference
AtomicReference无法解决上述问题的根本因为是对象在修改过程中,丢失了状态信息。
AtomicStampedReference,它内部不仅维护了对象值,还维护了一个时间戳(我这里把它称为时间戳,实际上它可以使任何一个整数来表示状态值)。当AtomicStampedReference对应的数值被修改时,除了更新数据本身外,还必须要更新时间戳。可以解决ABA问题
当AtomicStampedReference设置对象值时,对象值以及时间戳都必须满足期望值,写入才会成功。因此,即使对象值被反复读写,写回原值,只要时间戳发生变化,就能防止不恰当的写入。
6.数组也能无锁:AtomicIntegerArray
除了提供基本数据类型外,JDK还为我们准备了数组等复合结构。当前可用的原子数组有:AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray,分别表示整数数组、long型数组和普通的对象数组。
7.让普通变量也享受原子操作:AtomicIntegerFieldUpdater
将普通变量也变成线性安全的。
在原子包里还有一个实用的工具类AtomicIn-tegerFieldUpdater。它可以让你在不改动(或者极少改动)原有代码的基础上,让普通的变量也享受CAS操作带来的线程安全性,这样你可以修改极少的代码,来获得线程安全的保证。
根据数据类型不同,这个Updater有三种,分别是AtomicIntegerFieldUpdater、AtomicLong-FieldUpdater和AtomicReferenceFieldUpdater。顾名思义,它们分别可以对int、long和普通对象进行CAS修改。
虽然AtomicIntegerFieldUpdater很好用,但是还是有几个注意事项:
第一,Updater只能修改它可见范围内的变量。因为Updater使用反射得到这个变量。如果变量不可见,就会出错。比如如果score申明为private,就是不可行的。
第二,为了确保变量被正确的读取,它必须是volatile类型的。如果我们原有代码中未申明这个类型,那么简单地申明一下就行,这不会引起什么问题。
第三,由于CAS操作会通过对象实例中的偏移量直接进行赋值,因此,它不支持static字段(Unsafe. objectFieldOffset()不支持静态变量)。
8.SynchronousQueue的实现
在对线程池的介绍中,提到了一个非常特殊的等待队列SynchronousQueue。Syn-chronousQueue的容量为0,任何一个对Syn-chronousQueue的写需要等待一个对Syn-chronousQueue的读,因此,Syn-chronousQueue与其说是一个队列,不如说是一个数据交换通道。
对SynchronousQueue来说,它将put()和take()两个功能截然不同的操作抽象为一个共通的方法Transferer.transfer()。
Object transfer(Object e, boolean timed, long nanos)
当参数e为非空时,表示当前操作传递给一个消费者,如果为空,则表示当前操作需要请求一个数据。timed参数决定是否存在timeout时间,nanos决定了timeout的时长。如果返回值非空,则表示数据已经接受或者正常提供,如果为空,则表示失败(超时或者中断)。
SynchronousQueue内部会维护一个线程等待队列。等待队列中会保存等待线程以及相关数据的信息。比如,生产者将数据放入Syn-chronousQueue时,如果没有消费者接收,那么数据本身和线程对象都会打包在队列中等待(因为SynchronousQueue容积为0,没有数据可以正常放入)。
如果等待队列为空,或者队列中节点的类型和本次操作是一致的,那么将当前操作压入队列等待。比如,等待队列中是读线程等待,本次操作也是读,因此这两个读都需要等待。进入等待队列的线程可能会被挂起,它们会等待一个“匹配”操作。
如果等待队列中的元素和本次操作是互补的(比如等待操作是读,而本次操作是写),那么就插入一个“完成”状态的节点,并且让他“匹配”到一个等待节点上。接着弹出这两个节点,并且使得对应的两个线程继续执行。
如果线程发现等待队列的节点就是“完成”节点,那么帮助这个节点完成任务。其流程和步骤2是一致的。
(二:无锁数据结构)
1.RingBuffer
一个环状的数据结构,一个生产者,一个消费者,在linux任务调度里应用很多
2.disruptor数据结构
是一个生产者、消费者的设计模式,也是一个ringbuffer,但是适合多个生产者、消费者。底层优化到操作系统二级缓存,还有其他的一些优化,这里不作具体介绍;
3.JCTools工具包
原本jdk里面缺少了对无锁队列的支持,这是提供了各种无锁队列,比如单生产者单消费者、单生产者多消费者、多生产者单消费者、多生产者多消费者等。netty的新版中,也用MPSC代替了原本的LinkedBlockingQueue,经过测试,性能大大提升。
1 锁引发的问题
使用锁时要特别防止出现死锁或活锁。死锁的情况很简单,就是申请者在申请过程中由于顺序原因(多个锁没有按固定顺序申请)进入堵塞状态了,指定顺序即可规避。我们只看一个活锁的例子:
两个线程都在尽量避免死锁,但是却有可能(尴尬地)进入了活锁场景:两个线程都不会如期进入do_something_x(),也都不会退出while(),而是处于反复尝试过程里!可见,活锁的含义就是申请者都活着(没有堵塞住)但还是锁住了。
上面活锁的例子,其实和下面这个(不使用任何锁的)例子是一个意思:
不考虑cpu/compiler优化的情况下,如果两个线程都在运行这个while(),则有可能两个线程都退不出这个while()。因为两个线程都在修改X,有可能造成while(X==0)的X一直为0!
2 无锁实例
无锁编程的本质就是处理最关键的点(一般针对最精简的数据结构里面的某个字段),所谓“好钢用在刀刃上”:使用CAS原子操作方式将有锁操作压缩到最小范围(可见无锁的本质还是有锁的,原子操作也是锁性质的),CAS原子操作会封装成下面的形式:(以32bit机为例)
bool cas32( int * pVal, int oldVal, int newVal );
pVal表示要要考察值的地址,oldVal表示期望的旧值,newVal表示可以替换时的新值。此函数相当于:
int compare_and_swap (int* reg, int oldval, int newval)
{
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
return old_reg_val;
}
这样,无锁相当于把锁因素转化为原子CAS操作而压缩到了最精简的数据结构,以至于看上去貌似无锁!我们看一个queue的无锁化:(本实例来自1994年的《Implementing Lock-Free Queues》,代码中“^.”相当于“->”)
搞清这个无锁queue,需要理解几个要点:
Queue始终含有一个dummy冗余节点,包括初始时。在后续的删除过程中,这个dummy节点会随时切换(指向旧节点)。
对于EnQueue(),第一个CAS确保第一个取到tail的操作者顺利加入队列;第二个CAS让没有顺利加入时(会反复尝试)能够快速推进tail指针的更新;第三个CAS很显然,第一个顺利完成入队列操作自然需要完成tail指针的更新,虽然有可能已经被第二个CAS提前更新过了。
对于Dequeue(),唯一的CAS是确保第一个取到head值的操作者顺利删除队列第一个节点。
总之,在EnQueue和DeQueue已有支持多线程特性基础(入队列和出队列在队列中至少一个节点的情况下,是不需要加锁保护的)上,通过CAS的使用,EnQueue()和DeQueue()各自都分别能支持多线程了。这样,看上去很美:无锁!
另外,需要注意异常情况,比如上面的EnQueue()如果在执行过程中某个线程挂掉,是否影响其它线程?如果删掉里面第二个CAS操作,那么EnQueue()就会有问题:thread1成功完成第一个CAS,开始第三个CAS(因为删除了第二个CAS,其实此时应该是第二个了)时挂掉了,那么其它thread都会死循环:死等next字段为NUL的tail,但其实这个tail的next永远停留在thread1刚入队列的那个节点了。
以上可见,EnQueue()里第二个CAS很重要,但防止上述某个线程中途崩溃的方法还有其它途径,比如这个EnQueue()版本:
处理原则都一样,就是:即使CAS没能顺利成功也需要推进tail指针!
3 gcc中的无锁支持
bool __sync_bool_compare_and_swap(type *ptr, type oldval type newval, …)
type __sync_val_compare_and_swap(type *ptr, type oldval type newval, …)
These builtins perform an atomic compare and swap. That is, ifthe current value of *ptr is oldval, thenwrite newval into *ptr.
The “bool” version returns true if the comparison is successfuland newval was written. The “val” version returns the contentsof *ptr before the operation.
我们仔细看下__sync_bool_compare_and_swap():
我们聚焦cmpxchg:
cmpxchg %ecx, %ebx;如果EAX与EBX相等则ECX送EBX且ZF置1;否则EBX送EAX且ZF清0
%eax是旧值,%ecx就是新值,%ebx就是待考察的值。原来,这条指令就是无锁根源!几乎所有CPU都支持CAS原子操作,x86下对应的原子操作就是cmpxchg指令。
4 CAS的ABA问题
ABA问题是指由于进程切换导致状态变化的遗漏。比如进程看到的变量是“A”,但其实可能已经经过多次状态变化了:“A->B->A”。
解决办法一般是增加一个引用计数字段。这样,CAS同时检查引用计数和目标内容两个值是否都没有发生变化。但麻烦的是引用计数字段也有一个溢出问题。
5 内核中的无锁
查看内核kfifo机制可看到,内核采用另一种无锁方式:内存屏障。关于内存屏障话题,具体请参考我们之前的《理解内存屏障》五部曲。
gcc中也对内存屏障有封装:
__sync_synchronize (…)
This builtin issues a full memory barrier.
