DelayQueue 延迟队列实现原理
使用场景
关闭空闲连接。服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之。
清理过期数据业务上。比如缓存中的对象,超过了空闲时间,需要从缓存中移出。
任务超时处理。在网络协议滑动窗口请求应答式交互时,处理超时未响应的请求。
下单之后如果三十分钟之内没有付款就自动取消订单。
订餐通知:下单成功后60s之后给用户发送短信通知。
当订单一直处于未支付状态时,如何及时的关闭订单,并退还库存?
如何定期检查处于退款状态的订单是否已经退款成功?
新创建店铺,N天内没有上传商品,系统如何知道该信息,并发送激活短信?
定时任务调度:使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行。
2 延时任务-实现方式
定期轮询(数据库等)
DelayQueue
Timer
ScheduledExecutorService
时间轮(kafka)
RabbitMQ
Quartz
Redis Zset
Koala
JCronTab
SchedulerX(阿里)
有赞延迟队列
2.1 轮询
特点:定期轮训数据库,设置状态。
优点:实现简单
缺点:数据量过大时会消耗太多的IO资源,效率太低
复制代码2.2 DelayQueue
特点:
无界、延迟、阻塞队列
a、BlockingQueue+PriorityQueue(堆排序)+Delayed
b、DelayQueue中存放的对象需要实现compareTo()方法和getDelay()方法。
c、getDelay方法返回该元素距离失效还剩余的时间,当<=0时元素就失效了,
就可以从队列中获取到。
1,添加元素(带有延时时间)
2,按延时时间排序
3,出队:最先要过期的元素
这里为什么要用leader/follower模式?
如果不是队首节点,根本不需要唤醒操作!
假设取值时,延时时间还没有到,那么需要等待,但这个时候,队列中新加入了一个延时更短的,并放在了队首,那么
此时,for循环由开始了,取得是新加入的元素,那之前的等待就白等了,明显可以早点退出等待!
还有就是如果好多线程都在此等待,如果时间到了,同时好多线程会充等待队列进入锁池中,去竞争锁资源,但结果只能是一个成功,
多了写无畏的竞争!(多次的等待和唤醒
2.3 Timer与TimerTask
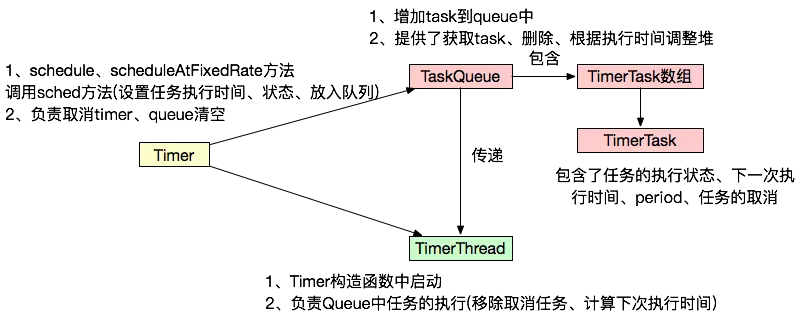
TaskQueue中的排序是对TimerTask中的下一次执行时间进行堆排序,每次去取数组第一个。
而delayQueue是对queue中的元素的getDelay()结果进行排序
Timer是一种定时器工具,用来在一个后台线程计划执行指定任务。它可以计划执行一个任务一次或反复多次。
主要方法:
2.4 时间轮(kafka)
时间轮名词解释:
时间格:环形结构中用于存放延迟任务的区块;
指针(CurrentTime):指向当前操作的时间格,代表当前时间
格数(ticksPerWheel):为时间轮中时间格的个数
间隔(tickDuration):每个时间格之间的间隔
总间隔(interval):当前时间轮总间隔,也就是等于ticksPerWheel*tickDuration
根据每个TimerTaskEntry的过期时间和当前时间轮的时间,选择一个合适的bucket(实际上就是TimerTaskList),把这个TimerTaskEntry对象放进去,同时如果bucket的过期时间有更新,就将这个bucket推进DelayQueue,重新排序
例子:假设编号为0的时间格或者桶保存着到期时间为t,每一个tick的持续时间(tickDuration)为20ms,在这个格子里只能保存着到期时间为[t~t+20]ms的任务,假设时间轮的时间格有n个,每一个间隔1ms,到期时间为m(ms),那么计算公式m%n = 所在的时间格或者桶,比如n=10,m=34ms,那么他所在桶或者时间格是4
2.5 RabbitMQ-延时任务
RabbitMQ本身没有直接支持延迟队列功能,但是可以通过以下特性模拟出延迟队列的功能。
RabbitMQ可以针对Queue和Message设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为dead letter
RabbitMQ针对队列中的消息过期时间有两种方法可以设置。
A: 通过队列属性设置,队列中所有消息都有相同的过期时间。
B: 对消息进行单独设置,每条消息TTL可以不同。
2.6 Quartz
为什么不用Timer?
Timers没有持久化机制.
Timers不灵活 (只可以设置开始时间和重复间隔,不是基于时间、日期、天等(秒、分、时)的)
Timers 不能利用线程池,一个timer一个线程
Timers没有真正的管理计划
核心概念:调度器、任务和触发器。
三者关系:调度器负责调度各个任务,到了某个时刻或者过了一定时间,触发器触动了,特定任务便启动执行。
scheduler是一个计划调度器容器(总部),容器里面可以盛放众多的JobDetail和trigger,当容器启动后,里面的每个JobDetail都会根据trigger按部就班自动去执行。
JobDetail是一个可执行的工作,它本身是有状态的。
Trigger代表什么时候去调。
当JobDetail和Trigger在scheduler容器上注册后,形成了装配好的作业(JobDetail和Trigger所组成的一对儿),就可以伴随容器启动而调度执行了。
scheduler是个容器,容器中有一个线程池,用来并行调度执行每个作业,这样可以提高容器效率。
TimingWheel并非简单的环形时间轮,而是多层级时间轮,每个时间轮由多个时间格组成,每个时间格为一个时间间隔,底层的时间格跨度较小,然后随着延迟任务延迟时间的长短逐层变大。
默认情况下,各个层级的时间轮的时间格个数为20,第一层时间轮每一个时间格跨度为1ms,整个时间轮跨度为20ms,跨度不够。第二层时间轮每一个时间格跨度为20ms,整个时间轮跨度为400ms,跨度依然不够,第三层时间轮每一个时间格跨度为400ms,整个时间轮跨度为8000ms,现在跨度够了,此任务就放在第三层时间轮的第一个时间格对应的TimerTaskList,等待被执行,此TimerTaskList到期时间是400ms,随着时间的流逝,当此TimerTaskList到期时,距离该任务到期时间还有45ms,不能执行该任务,我们将重新提交到时间轮,此时第一层时间轮跨度依然不够,不能执行任务,第二层时间轮时间格跨度为20,整个世间轮跨度为400,跨度足够,放在第三个时间格等待执行,如此往复几次,高层时间轮最终会慢慢移动到低层时间轮上,最终任务到期执行。那么时间轮和DelayQueue有什么区别呢?Øjava.util.Timer与java.util.concurrent.DelayQueue的插入和删除时间复杂度都为对数阶O(log
ØKafka实现了基于时间轮的定时任务组件,该时间轮定时任务实现的插入与删除(开始定时器与暂停定时器)的时间复杂度都为常数阶O(1)共同缺点:自己要处理分布式横向扩展的问题,因为数据是放在内存里,需要自己写持久化的备案以达到高可用。Koala(美团)整体架构为在RocketMQ的基础上,增加了一个基于LevelDB的延时消息处理引擎,从而实现延时消息的处理。Ø生产者:生产消息Ø消费者:消费消息ØBroker: 存储和转发消息ØCommitLog:使用了RocketMQ,持久化存储消息ØNameServer:管理broker,producer和consumer从它那获取broker信息ØDelayEngine:延时消息处理引擎(使用LevelDB进行消息存储)延迟消息的特点:延迟消息可能会堆积—-需要持久化需要排序的支持支持性能高的随机写入和顺序读取LevelDB的特点:KV系统且数据保存在磁盘存储数据按key有序存储LevelDb性能非常突出,官方网站报道其随机写性能达到40万条记录每秒,而随机读性能达到6万条记录每秒。总体来说,LevelDb的写操作要大大快于读操作,而顺序读写操作则大大快于随机读写操作。爱奇艺任务调度服务JCrontabJCronTab 借鉴了
crontab 的语法,其区别在于
command 不再是 unix/linux 的命令,而是一个
Java 类。如果该类带参数,例如“com.ibm.scheduler.JCronTask2#run”,则定期执行
run 方法;如果该类不带参数,则默认执行
main 方法。此外,还可以传参数给
main 方法或者构造函数。例如“com.ibm.scheduler.JCronTask2#run
Hello World“表示传两个参数 Hello
和
World 给构造函数。Jcrontab VS Quartz阿里分布式任务调度服务SchedulerX需求:将一个耗时很长的定时任务进行拆解由于每次迁移的数据量巨大,如果单台机器去迁移的话是没办法在一天之内完成迁移任务的,所以必须将这样一个迁移任务拆分成多个子任务分片,然后用多台机器去执行不同的子任务分片。特点分布式:多台客户端机器中任何一台宕机,服务端自动选择正常运行的客户端继续执行支持Quartz
时间表达式用户不需要关心调度逻辑,只需要实现业务逻辑应用场景固定时间点触发的任务周期性触发的任务通过控制台手动触发的任务有赞延迟队列设计Job:需要异步处理的任务,与具体的Topic关联在一起。Topic:一组相同类型Job的集合(队列)供消费者来订阅。TTR(time-to-run):Job执行超时时间。单位:秒。整个延迟队列由4个部分组成:Job
Pool 存放jobDelay
Bucket
时间维度有序队列(存放JobId)Timer
扫描Bucket,delay时间结束,可以执行了,放入ready
queueReady
Queue
供消费程序消费(存放JobId,无需有序)
有赞延迟队列-缺点1、多实例部署时,Timer程序并发执行,如何保证放入ready queue的job是唯一的?2、
timer是通过独立线程的无限循环来实现,在没有ready job的时候会对CPU造成一定的浪费,如何解决
