MySQL高可用架构之MHA
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
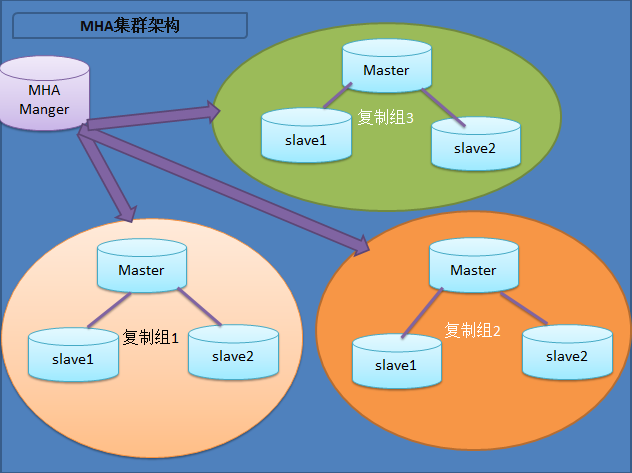
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
官方介绍:https://code.google.com/p/mysql-master-ha/
(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下。
Manager工具包主要包括以下几个工具:
复制代码
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
复制代码
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
注意:
为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL 5.5的半同步复制。
<!– 配置MHA
(1)创建MHA的工作目录,并且创建相关配置文件(在软件包解压后的目录里面有样例配置文件)。
[root@192.168.0.20 ~]# mkdir -p /etc/masterha
[root@192.168.0.20 ~]# cp mha4mysql-manager-0.53/samples/conf/app1.cnf /etc/masterha/
[root@192.168.0.20 ~]#
修改app1.cnf配置文件,修改后的文件内容如下(注意,配置文件中的注释需要去掉,我这里是为了解释清楚):
复制代码
[root@192.168.0.20 ~]# cat /etc/masterha/app1.cnf
[server default]
manager_workdir=/var/log/masterha/app1.log //设置manager的工作目录
manager_log=/var/log/masterha/app1/manager.log //设置manager的日志
master_binlog_dir=/data/mysql //设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
master_ip_failover_script= /usr/local/bin/master_ip_failover //设置自动failover时候的切换脚本
master_ip_online_change_script= /usr/local/bin/master_ip_online_change //设置手动切换时候的切换脚本
password=123456 //设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
user=root 设置监控用户root
ping_interval=1 //设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover
remote_workdir=/tmp //设置远端mysql在发生切换时binlog的保存位置
repl_password=123456 //设置复制用户的密码
repl_user=repl //设置复制环境中的复制用户名
report_script=/usr/local/send_report //设置发生切换后发送的报警的脚本
secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02
shutdown_script=”” //设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)
ssh_user=root //设置ssh的登录用户名
[server1]
hostname=192.168.0.50
port=3306
[server2]
hostname=192.168.0.60
port=3306
candidate_master=1 //设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
check_repl_delay=0 //默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server3]
hostname=192.168.0.70
port=3306
[root@192.168.0.20 ~]#
复制代码
(2)设置relay log的清除方式(在每个slave节点上):
[root@192.168.0.60 ~]# mysql -e ‘set global relay_log_purge=0’
[root@192.168.0.70 ~]# mysql -e ‘set global relay_log_purge=0’
注意:
MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。(在mysql数据库中,删除大表时,通常也采用建立硬链接的方式)
MHA节点中包含了pure_relay_logs命令工具,它可以为中继日志创建硬链接,执行SET GLOBAL relay_log_purge=1,等待几秒钟以便SQL线程切换到新的中继日志,再执行SET GLOBAL relay_log_purge=0。
pure_relay_logs脚本参数如下所示:
–user mysql 用户名
–password mysql 密码
–port 端口号
–workdir 指定创建relay log的硬链接的位置,默认是/var/tmp,由于系统不同分区创建硬链接文件会失败,故需要执行硬链接具体位置,成功执行脚本后,硬链接的中继日志文件被删除
–disable_relay_log_purge 默认情况下,如果relay_log_purge=1,脚本会什么都不清理,自动退出,通过设定这个参数,当relay_log_purge=1的情况下会将relay_log_purge设置为0。清理relay log之后,最后将参数设置为OFF。
(3)设置定期清理relay脚本(两台slave服务器)
[root@192.168.0.60 ~]# cat purge_relay_log.sh
#!/bin/bash
user=root
passwd=123456
port=3306
log_dir=’/data/masterha/log’
work_dir=’/data’
purge=’/usr/local/bin/purge_relay_logs’
if [ ! -d $log_dir ]
then
mkdir $log_dir -p
fi
$purge –user=$user –password=$passwd –disable_relay_log_purge –port=$port –workdir=$work_dir » $log_dir/purge_relay_logs.log 2>&1
[root@192.168.0.60 ~]#
添加到crontab定期执行
[root@192.168.0.60 ~]# crontab -l
0 4 * * * /bin/bash /root/purge_relay_log.sh
[root@192.168.0.60 ~]#
purge_relay_logs脚本删除中继日志不会阻塞SQL线程。下面我们手动执行看看什么情况。
复制代码
[root@192.168.0.60 ~]# purge_relay_logs –user=root –password=123456 –port=3306 -disable_relay_log_purge –workdir=/data/
2014-04-20 15:47:24: purge_relay_logs script started.
Found relay_log.info: /data/mysql/relay-log.info
Removing hard linked relay log files server03-relay-bin* under /data/.. done.
Current relay log file: /data/mysql/server03-relay-bin.000002
Archiving unused relay log files (up to /data/mysql/server03-relay-bin.000001) …
Creating hard link for /data/mysql/server03-relay-bin.000001 under /data//server03-relay-bin.000001 .. ok.
Creating hard links for unused relay log files completed.
Executing SET GLOBAL relay_log_purge=1; FLUSH LOGS; sleeping a few seconds so that SQL thread can delete older relay log files (if it keeps up); SET GLOBAL relay_log_purge=0; .. ok.
Removing hard linked relay log files server03-relay-bin* under /data/.. done.
2014-04-20 15:47:27: All relay log purging operations succeeded.
[root@192.168.0.60 ~]#
6.检查SSH配置
检查MHA Manger到所有MHA Node的SSH连接状态:
复制代码
[root@192.168.0.20 ~]# masterha_check_ssh –conf=/etc/masterha/app1.cnf
Sun Apr 20 17:17:39 2014 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sun Apr 20 17:17:39 2014 - [info] Reading application default configurations from /etc/masterha/app1.cnf..
Sun Apr 20 17:17:39 2014 - [info] Reading server configurations from /etc/masterha/app1.cnf..
Sun Apr 20 17:17:39 2014 - [info] Starting SSH connection tests..
Sun Apr 20 17:17:40 2014 - [debug]
Sun Apr 20 17:17:39 2014 - [debug] Connecting via SSH from root@192.168.0.50(192.168.0.50:22) to root@192.168.0.60(192.168.0.60:22)..
Sun Apr 20 17:17:39 2014 - [debug] ok.
Sun Apr 20 17:17:39 2014 - [debug] Connecting via SSH from root@192.168.0.50(192.168.0.50:22) to root@192.168.0.70(192.168.0.70:22)..
Sun Apr 20 17:17:39 2014 - [debug] ok.
Sun Apr 20 17:17:40 2014 - [debug]
Sun Apr 20 17:17:40 2014 - [debug] Connecting via SSH from root@192.168.0.60(192.168.0.60:22) to root@192.168.0.50(192.168.0.50:22)..
Sun Apr 20 17:17:40 2014 - [debug] ok.
Sun Apr 20 17:17:40 2014 - [debug] Connecting via SSH from root@192.168.0.60(192.168.0.60:22) to root@192.168.0.70(192.168.0.70:22)..
Sun Apr 20 17:17:40 2014 - [debug] ok.
Sun Apr 20 17:17:41 2014 - [debug]
Sun Apr 20 17:17:40 2014 - [debug] Connecting via SSH from root@192.168.0.70(192.168.0.70:22) to root@192.168.0.50(192.168.0.50:22)..
Sun Apr 20 17:17:40 2014 - [debug] ok.
Sun Apr 20 17:17:40 2014 - [debug] Connecting via SSH from root@192.168.0.70(192.168.0.70:22) to root@192.168.0.60(192.168.0.60:22)..
Sun Apr 20 17:17:41 2014 - [debug] ok.
Sun Apr 20 17:17:41 2014 - [info] All SSH connection tests passed successfully.
可以看见各个节点ssh验证都是ok的。
7.检查整个复制环境状况。
通过masterha_check_repl脚本查看整个集群的状态
[root@192.168.0.20 ~]# masterha_check_repl –conf=/etc/masterha/app1.cnf
Sun Apr 20 18:36:55 2014 - [info] Checking replication health on 192.168.0.60..
Sun Apr 20 18:36:55 2014 - [info] ok.
Sun Apr 20 18:36:55 2014 - [info] Checking replication health on 192.168.0.70..
Sun Apr 20 18:36:55 2014 - [info] ok.
Sun Apr 20 18:36:55 2014 - [info] Checking master_ip_failover_script status:
Sun Apr 20 18:36:55 2014 - [info] /usr/local/bin/master_ip_failover –command=status –ssh_user=root –orig_master_host=192.168.0.50 –orig_master_ip=192.168.0.50 –orig_master_port=3306
Bareword “FIXME_xxx” not allowed while “strict subs” in use at /usr/local/bin/master_ip_failover line 88.
Execution of /usr/local/bin/master_ip_failover aborted due to compilation errors.
Sun Apr 20 18:36:55 2014 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln214] Failed to get master_ip_failover_script status with return code 255:0.
Sun Apr 20 18:36:55 2014 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln383] Error happend on checking configurations. at /usr/local/bin/masterha_check_repl line 48
Sun Apr 20 18:36:55 2014 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln478] Error happened on monitoring servers.
Sun Apr 20 18:36:55 2014 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK!more –>
上面两台服务器的keepalived都设置为了BACKUP模式,在keepalived中2种模式,分别是master->backup模式和backup->backup模式。这两种模式有很大区别。在master->backup模式下,一旦主库宕机,虚拟ip会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟ip抢占过来,即使设置了非抢占模式(nopreempt)抢占ip的动作也会发生。在backup->backup模式下,当主库宕机后虚拟ip会自动漂移到从库上,当原主库恢复和keepalived服务启动后,并不会抢占新主的虚拟ip,即使是优先级高于从库的优先级别,也不会发生抢占。为了减少ip漂移次数,通常是把修复好的主库当做新的备库。
(5)MHA引入keepalived(MySQL服务进程挂掉时通过MHA 停止keepalived):
要想把keepalived服务引入MHA,我们只需要修改切换是触发的脚本文件master_ip_failover即可,在该脚本中添加在master发生宕机时对keepalived的处理。
在许多情况下, 需要将现有的主服务器迁移到另外一台服务器上。 比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降, 导致停机时间至少无法写入数据。 另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA 提供快速切换和优雅的阻塞写入,这个切换过程只需要 0.5-2s 的时间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。
MHA在线切换的大概过程:
1.检测复制设置和确定当前主服务器
2.确定新的主服务器
3.阻塞写入到当前主服务器
4.等待所有从服务器赶上复制
5.授予写入到新的主服务器
6.重新设置从服务器
注意,在线切换的时候应用架构需要考虑以下两个问题:
1.自动识别master和slave的问题(master的机器可能会切换),如果采用了vip的方式,基本可以解决这个问题。
2.负载均衡的问题(可以定义大概的读写比例,每台机器可承担的负载比例,当有机器离开集群时,需要考虑这个问题)
为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1.所有slave的IO线程都在运行
2.所有slave的SQL线程都在运行
3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4.在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
在线切换步骤如下:
首先,停掉MHA监控:
[root@192.168.0.20 ~]# masterha_stop –conf=/etc/masterha/app1.cnf
其次,进行在线切换操作(模拟在线切换主库操作,原主库192.168.0.50变为slave,192.168.0.60提升为新的主库)
[root@192.168.0.20 ~]# masterha_master_switch –conf=/etc/masterha/app1.cnf –master_state=alive –new_master_host=192.168.0.60 –new_master_port=3306 –orig_master_is_new_slave –running_updates_limit=10000
最后查看日志,了解切换过程,输出信息如下:
View Code
其中参数的意思:
–orig_master_is_new_slave 切换时加上此参数是将原 master 变为 slave 节点,如果不加此参数,原来的 master 将不启动
–running_updates_limit=10000,故障切换时,候选master 如果有延迟的话, mha 切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由recover 时relay 日志的大小决定
注意:由于在线进行切换需要调用到master_ip_online_change这个脚本,但是由于该脚本不完整,需要自己进行相应的修改,我google到后发现还是有问题,脚本中new_master_password这个变量获取不到,导致在线切换失败,所以进行了相关的硬编码,直接把mysql的root用户密码赋值给变量new_master_password,如果有哪位大牛知道原因,请指点指点。这个脚本还可以管理vip。
四.修复宕机的Master
通常情况下自动切换以后,原master可能已经废弃掉,待原master主机修复后,如果数据完整的情况下,可能想把原来master重新作为新主库的slave,这时我们可以借助当时自动切换时刻的MHA日志来完成对原master的修复。下面是提取相关日志的命令:
[root@192.168.0.20 app1]# grep -i “All other slaves should start” manager.log
Mon Apr 21 22:28:33 2014 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=’192.168.0.60’, MASTER_PORT=3306, MASTER_LOG_FILE=’mysql-bin.000022’, MASTER_LOG_POS=506716, MASTER_USER=’repl’, MASTER_PASSWORD=’xxx’;
[root@192.168.0.20 app1]#
获取上述信息以后,就可以直接在修复后的master上执行change master to相关操作,重新作为从库了。
MHA工作原理
当master出现故障时,通过对比slave之间I/O线程读取master binlog的位置,选取最接近的slave做为latest slave。其它slave通过与latest slave对比生成差异中继日志。
在latest slave上应用从master保存的binlog,同时将latest slave提升为master。最后在其它slave上应用相应的差异中继日志并开始从新的master开始复制。

在MHA实现Master故障切换过程中,MHA Node会试图访问故障的master(通过SSH),如果可以访问(不是硬件故障,比如InnoDB数据文件损坏等),会保存二进制文件,以最大程度
保证数据不丢失。MHA和半同步复制一起使用会大大降低数据丢失的危险。
MHA软件的架构:由两部分组成,Manager工具包和Node工具包,具体的说明如下。
Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs(保存二进制日志) 保存和复制master的二进制日志
apply_diff_relay_logs(应用差异中继日志) 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs(清理中继日志) 清除中继日志(不会阻塞SQL线程)
………………………………………………………………………………………..
MHA如何保持数据的一致性呢?主要通过MHA node的以下几个工具实现,但是这些工具由mha manager触发:
save_binary_logs 如果master的二进制日志可以存取的话,保存复制master的二进制日志,最大程度保证数据不丢失
apply_diff_relay_logs 相对于最新的slave,生成差异的中继日志并将所有差异事件应用到其他所有的slave
注意:
对比的是relay log,relay log越新就越接近于master,才能保证数据是最新的。
purge_relay_logs删除中继日志而不阻塞sql线程
MHA的优势
1)故障切换快
在主从复制集群中,只要从库在复制上没有延迟,MHA通常可以在数秒内实现故障切换。9-10秒内检查到master故障,可以选择在7-10秒关闭master以避免出现裂脑,几秒钟内,
将差异中继日志(relay log)应用到新的master上,因此总的宕机时间通常为10-30秒。恢复新的master后,MHA并行的恢复其余的slave。即使在有数万台slave,也不会
影响master的恢复时间。
DeNA在超过150个MySQL(主要5.0/5.1版本)主从环境下使用了MHA。当mater故障后,MHA在4秒内就完成了故障切换。在传统的主动/被动集群解决方案中,4秒内完成故障切换是不可能的。
2)master故障不会导致数据不一致
当目前的master出现故障时,MHA自动识别slave之间中继日志(relay log)的不同,并应用到所有的slave中。这样所有的salve能够保持同步,只要所有的slave处于存活
状态。和Semi-Synchronous Replication一起使用,(几乎)可以保证没有数据丢失。
3)无需修改当前的MySQL设置
MHA的设计的重要原则之一就是尽可能地简单易用。MHA工作在传统的MySQL版本5.0和之后版本的主从复制环境中。和其它高可用解决方法比,MHA并不需要改变MySQL的部署环境。
MHA适用于异步和半同步的主从复制。
启动/停止/升级/降级/安装/卸载MHA不需要改变(包扩启动/停止)MySQL复制。当需要升级MHA到新的版本,不需要停止MySQL,仅仅替换到新版本的MHA,然后重启MHA Manager
就好了。
MHA运行在MySQL 5.0开始的原生版本上。一些其它的MySQL高可用解决方案需要特定的版本(比如MySQL集群、带全局事务ID的MySQL等等),但并不仅仅为了master的高可用才迁移应用的。在大多数情况下,已经部署了比较旧MySQL应用,并且不想仅仅为了实现Master的高可用,花太多的时间迁移到不同的存储引擎或更新的前沿发行版。MHA工作的包括5.0/5.1/5.5的原生版本的MySQL上,所以并不需要迁移。
4)无需增加大量的服务器
MHA由MHA Manager和MHA Node组成。MHA Node运行在需要故障切换/恢复的MySQL服务器上,因此并不需要额外增加服务器。MHA Manager运行在特定的服务器上,因此需要
增加一台(实现高可用需要2台),但是MHA Manager可以监控大量(甚至上百台)单独的master,因此,并不需要增加大量的服务器。即使在一台slave上运行MHA Manager也是
可以的。综上,实现MHA并没用额外增加大量的服务。
5)无性能下降
MHA适用与异步或半同步的MySQL复制。监控master时,MHA仅仅是每隔几秒(默认是3秒)发送一个ping包,并不发送重查询。可以得到像原生MySQL复制一样快的性能。
6)适用于任何存储引擎
MHA可以运行在只要MySQL复制运行的存储引擎上,并不仅限制于InnoDB,即使在不易迁移的传统的MyISAM引擎环境,一样可以使用MHA。
在许多情况下, 需要将现有的主服务器迁移到另外一台服务器上,比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降,
导致停机时间至少无法写入数据。 另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA提供快速切换和优雅的阻塞写入,这个切换过程只需要 0.5-2s 的时
间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。
MHA在线切换的大概过程:
1)检测复制设置和确定当前主服务器
2)确定新的主服务器
3)阻塞写入到当前主服务器
4)等待所有从服务器赶上复制
5)授予写入到新的主服务器
6)重新设置从服务器
注意,在线切换的时候应用架构需要考虑以下两个问题:
1)自动识别master和slave的问题(master的机器可能会切换),如果采用了vip的方式,基本可以解决这个问题。
2)负载均衡的问题(可以定义大概的读写比例,每台机器可承担的负载比例,当有机器离开集群时,需要考虑这个问题)
为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1)所有slave的IO线程都在运行
2)所有slave的SQL线程都在运行
3)所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么
默认情况下running_updates_limit为1秒。
4)在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
在线切换步骤如下:
首先,manager节点上停掉MHA监控:
[root@Manager_Slave ~]# masterha_stop –conf=/etc/masterha/app1.cnf
其次,进行在线切换操作(模拟在线切换主库操作,原主库182.48.115.236变为slave,182.48.115.237提升为新的主库)
