Calcite
Apache Calcite是面向Hadoop新的查询引擎,它提供了标准的SQL语言、多种查询优化和连接各种数据源的能力,除此之外,Calcite还提供了OLAP和流处理的查询引擎。正是有了这些诸多特性,Calcite项目在Hadoop中越来越引入注目,并被众多项目集成。
Calcite之前的名称叫做optiq,optiq起初在Hive项目中,为Hive提供基于成本模型的优化,即CBO(Cost Based Optimizatio)。2014年5月optiq独立出来,成为Apache社区的孵化项目,2014年9月正式更名为Calcite。Calcite项目的创建者是Julian Hyde,他在数据平台上有非常多的工作经历,曾经是Oracle、 Broadbase公司SQL引擎的主要开发者、SQLStream公司的创始人和主架构师、Pentaho BI套件中OLAP部分的架构师和主要开发者。现在他在Hortonworks公司负责Calcite项目,其工作经历对Calcite项目有很大的帮助。除了Hortonworks,该项目的代码提交者还有MapR、Salesforce等公司,并且还在不断壮大。
Calcite的目标是“one size fits all(一种方案适应所有需求场景)”,希望能为不同计算平台和数据源提供统一的查询引擎,并以类似传统数据库的访问方式(SQL和高级查询优化)来访问Hadoop上的数据。
2、功能:
支持标准SQL语言;
独立于编程语言和数据源,可以支持不同的前端和后端;
支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎;
支持物化视图(materialized view)的管理(创建、丢弃、持久化和自动识别);
基于物化视图的Lattice和Tile机制,以应用于OLAP分析;
支持对流数据的查询。
动态的数据管理系统
Calcite的设计目标是成为动态的数据管理系统,所以在具有很多特性的同时,它也舍弃了一些功能,比如数据存储、处理数据的算法和元数据仓库。由于舍弃了这些功能,Calcite可以在应用和数据存储、数据处理引擎之间很好地扮演中介的角色。用Calcite创建数据库非常灵活,你只需要动态地添加数据即可。
同时,前面提到过,Calcite使用了基于关系代数的查询引擎,聚焦在关系代数的语法分析和查询逻辑的规划制定上。它不受上层编程语言的限制,前端可以使用SQL、Pig、Cascading或者Scalding,只要通过Calcite提供的API将它们转化成关系代数的抽象语法树即可。
同时,Calcite也不涉及物理规划层,它通过扩展适配器来连接多种后端的数据源和处理引擎,如Spark、Splunk、HBase、Cassandra或者MangoDB。简单的说,这种架构就是“一种查询引擎,连接多种前端和后端”。
支持对流数据的查询
在DDL中明确定义schema是流Or表,TODO:官网没有示例,待补充
比如有三张schema:
Orders (rowtime, productId, orderId, units) - 既是表,又是流
Products (rowtime, productId, name) - 表
Shipments (rowtime, orderId) - 流 查询中如果包含Stream关键字,就是流式查询,如果不包含,就是表查询。表查询可以马上返回结果并结束,流式查询只会输出结果但并不结束。
比如下面一个流查询示例:
SELECT STREAM *
FROM Orders;
rowtime | productId | orderId | units
———-+———–+———+——-
10:17:00 | 30 | 5 | 4
10:17:05 | 10 | 6 | 1
10:18:05 | 20 | 7 | 2
10:18:07 | 30 | 8 | 20
11:02:00 | 10 | 9 | 6
11:04:00 | 10 | 10 | 1
11:09:30 | 40 | 11 | 12
11:24:11 | 10 | 12 | 4
表查询示例:
SELECT *
FROM Orders;
rowtime | productId | orderId | units
———-+———–+———+——-
08:30:00 | 10 | 1 | 3
08:45:10 | 20 | 2 | 1
09:12:21 | 10 | 3 | 10
09:27:44 | 30 | 4 | 2
4 records returned.
流和表的查询不能混用,否则会报错
SELECT * FROM Shipments;
ERROR: Cannot convert stream ‘SHIPMENTS’ to a table
SELECT STREAM * FROM Products;
ERROR: Cannot convert table ‘PRODUCTS’ to a stream
其他过滤,排序,having等操作和标准sql一致,不再举例。 子查询只需要在外层语句写Stream关键字即可,内层写了无效。
如:
SELECT STREAM rowtime, productId
FROM (
SELECT TUMBLE_END(rowtime, INTERVAL ‘1’ HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS su
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ HOUR), productId)
WHERE c > 2 OR su > 10;
rowtime | productId
———-+———–
10:00:00 | 30
11:00:00 | 10
11:00:00 | 40
3、总结:
Calcite是一种动态数据管理系统,它具有标准SQL、连接不同前端和后端、可定制的逻辑规划器、物化视图、多维数据分析和流查询等诸多能力,使其成为大数据领域中非常有吸引力的查询引擎,目前它已经或被规划集成到Hadoop的诸多项目中,比如Lingual (Cascading项目的SQL接口)、Apache Drill、Apache Hive、Apache Kylin、Apache Phoenix、Apache Samza和Apache Flink
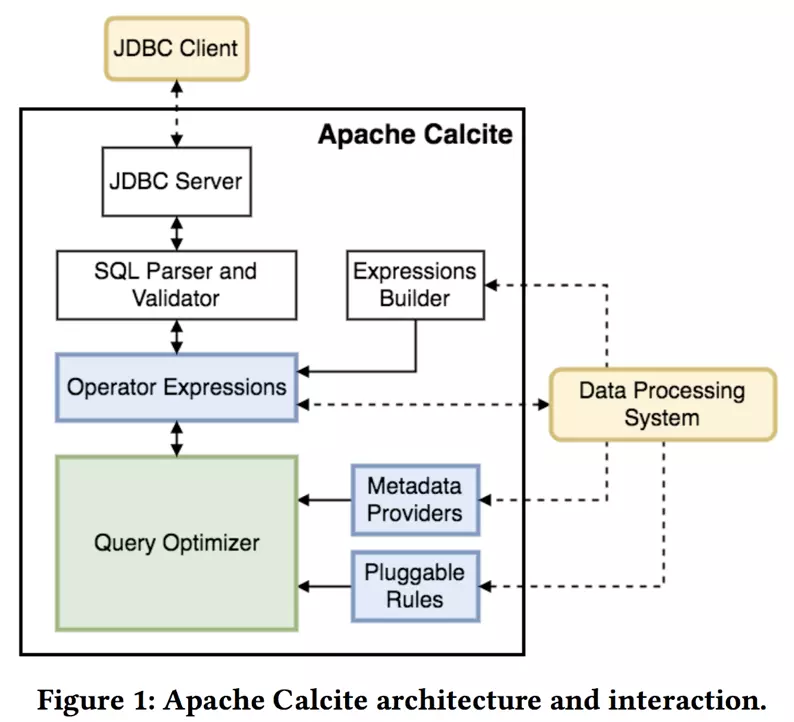
Calcite架构
Calcite架构图如下,其中Operator Expressions 是查询树在calcite中的表示,可以直接通过calcite的SQL Parser解析得到,也可以通过Expressions Builder由Data Processing System中的查询树(本文对应hive中的AST)转换得到。Query Optimizer 根据Pluggable Rules对Operator Expressions进行优化,其中会用到Metadata Providers提供的信息进行代价计算等操作。