mysql 的排序
用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序
1.排序优化与索引使用
为了优化SQL语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。因为索引本身也是有序的,如果在需要排序的字段上面建立了合适的索引,那么就可以跳过排序的过程,提高SQL的查询速度。
不能利用索引避免排序的SQL
//排序字段在多个索引中,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1,key_part2, key2;
//排序键顺序与索引中列顺序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part2, key_part1;
//升降序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
//key_part1是范围查询,key_part2无法使用索引排序
SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
2.排序实现的算法
对于不能利用索引避免排序的SQL,数据库不得不自己实现排序功能以满足用户需求,此时SQL的执行计划中会出现“Using filesort”,这里需要注意的是filesort并不意味着就是文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size参数与结果集大小确定。MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。
a.常规排序
(1).从表t1中获取满足WHERE条件的记录
(2).对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
(3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法)
(4).若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的
(5).循环执行上述过程,直到所有满足条件的记录全部参与排序
(6).扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3)
(7).将获取的结果集返回给用户。
从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)对,这个buffer的大小由sort_buffer_size参数控制。此外一次排序需要两次IO,一次是捞(id,col2),第二次是捞(col1,col2,col3),由于返回的结果集是按col2排序,因此id是乱序的,通过乱序的id去捞(col1,col2,col3)时会产生大量的随机IO。对于第二次MySQL本身一个优化,即在捞之前首先将id排序,并放入缓冲区,这个缓存区大小由参数read_rnd_buffer_size控制,然后有序去捞记录,将随机IO转为顺序IO。
b.优化排序
常规排序方式除了排序本身,还需要额外两次IO。优化的排序方式相对于常规排序,减少了第二次IO。主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。当然MySQL提供了参数max_length_for_sort_data,只有当排序元组小于max_length_for_sort_data时,才能利用优化排序方式,否则只能用常规排序方式。
c.优先队列排序
为了得到最终的排序结果,无论怎样,我们都需要将所有满足条件的记录进行排序才能返回。那么相对于优化排序方式,是否还有优化空间呢?5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
合并排序的强大之处
你可以更改算法,以便于节省内存空间,方法是不创建新的序列而是直接修改输入序列。
注:这种算法叫『原地算法』(in-place algorithm)
你可以更改算法,以便于同时使用磁盘空间和少量内存而避免巨量磁盘 I/O。方法是只向内存中加载当前处理的部分。在仅仅100MB的内存缓冲区内排序一个几个GB的表时,这是个很重要的技巧。
注:这种算法叫『外部排序』(external sorting)。
你可以更改算法,以便于在 多处理器/多线程/多服务器 上运行。
比如,分布式合并排序是Hadoop(那个著名的大数据框架)的关键组件之一。
B+树索引
查找一个特定值这个树挺好用,但是当你需要查找两个值之间的多个元素时,就会有大麻烦了。你的成本将是 O(N),因为你必须查找树的每一个节点,以判断它是否处于那 2 个值之间(例如,对树使用中序遍历)。而且这个操作不是磁盘I/O有利的,因为你必须读取整个树。我们需要找到高效的范围查询方法。为了解决这个问题,现代数据库使用了一种修订版的树,叫做B+树。在一个B+树里:
只有最底层的节点(叶子节点)才保存信息(相关表的行位置)
其它节点只是在搜索中用来指引到正确节点的。
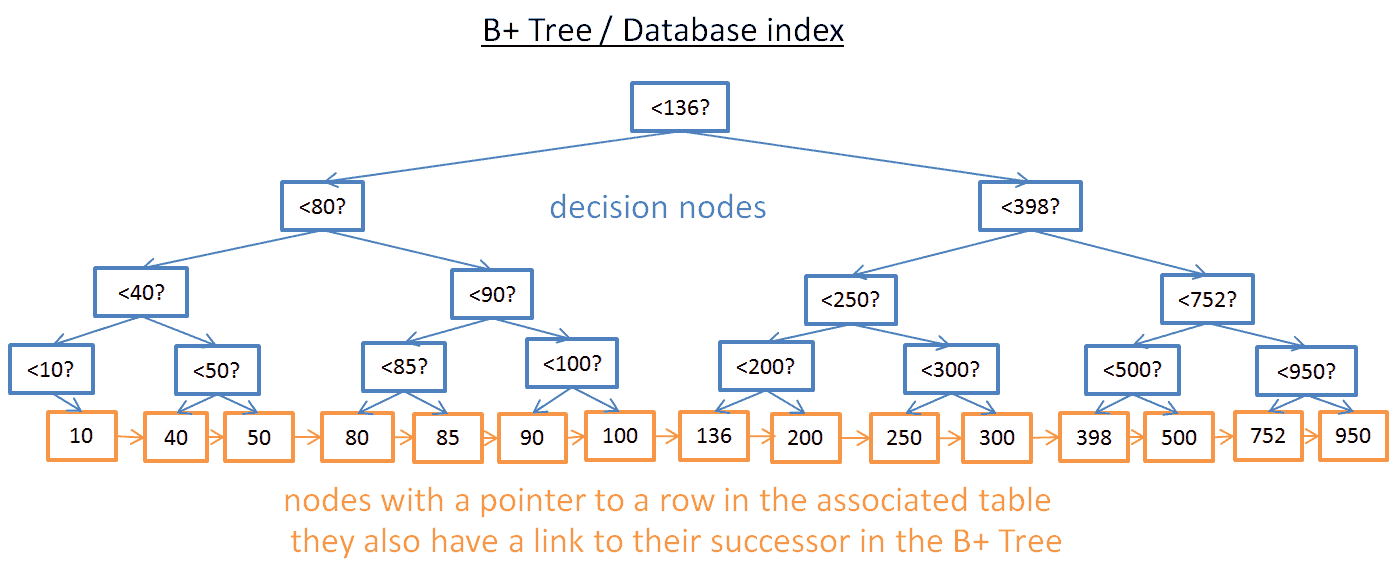
你可以看到,节点更多了(多了两倍)。确实,你有了额外的节点,它们就是帮助你找到正确节点的『决策节点』(正确节点保存着相关表中行的位置)。但是搜索复杂度还是在 O(log(N))(只多了一层)。一个重要的不同点是,最底层的节点是跟后续节点相连接的。
用这个 B+树,假设你要找40到100间的值:
你只需要找 40(若40不存在则找40之后最贴近的值),就像你在上一个树中所做的那样。
然后用那些连接来收集40的后续节点,直到找到100。
比方说你找到了 M 个后续节点,树总共有 N 个节点。对指定节点的搜索成本是 log(N),跟上一个树相同。但是当你找到这个节点,你得通过后续节点的连接得到 M 个后续节点,这需要 M 次运算。那么这次搜索只消耗了 M+log(N) 次运算,区别于上一个树所用的 N 次运算。此外,你不需要读取整个树(仅需要读 M+log(N) 个节点),这意味着更少的磁盘访问。如果 M 很小(比如 200 行)并且 N 很大(1,000,000),那结果就是天壤之别了。
然而还有新的问题(又来了!)。如果你在数据库中增加或删除一行(从而在相关的 B+树索引里):
你必须在B+树中的节点之间保持顺序,否则节点会变得一团糟,你无法从中找到想要的节点。
你必须尽可能降低B+树的层数,否则 O(log(N)) 复杂度会变成 O(N)。
换句话说,B+树需要自我整理和自我平衡。谢天谢地,我们有智能删除和插入。但是这样也带来了成本:在B+树中,插入和删除操作是 O(log(N)) 复杂度。所以有些人听到过使用太多索引不是个好主意这类说法。没错,你减慢了快速插入/更新/删除表中的一个行的操作,因为数据库需要以代价高昂的每索引 O(log(N)) 运算来更新表的索引。再者,增加索引意味着给事务管理器带来更多的工作负荷(在本文结尾我们会探讨这个管理器)。
https://blog.jcole.us/2013/01/07/the-physical-structure-of-innodb-index-pages/
https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
哈希表
我们最后一个重要的数据结构是哈希表。当你想快速查找值时,哈希表是非常有用的。而且,理解哈希表会帮助我们接下来理解一个数据库常见的联接操作,叫做『哈希联接』。这个数据结构也被数据库用来保存一些内部的东西(比如锁表或者缓冲池,我们在下文会研究这两个概念)。
哈希表这种数据结构可以用关键字来快速找到一个元素。为了构建一个哈希表,你需要定义:
元素的关键字
关键字的哈希函数。关键字计算出来的哈希值给出了元素的位置(叫做哈希桶)。
关键字比较函数。一旦你找到正确的哈希桶,你必须用比较函数在桶内找到你要的元素。
阵列 vs 哈希表
为什么不用阵列呢?
一个哈希表可以只装载一半到内存,剩下的哈希桶可以留在硬盘上。
用阵列的话,你需要一个连续内存空间。如果你加载一个大表,很难分配足够的连续内存空间。
用哈希表的话,你可以选择你要的关键字(比如,一个人的国家和姓氏)。
数据库是由多种互相交互的组件构成的。
核心组件:
进程管理器(process manager):很多数据库具备一个需要妥善管理的进程/线程池。再者,为了实现纳秒级操作,一些现代数据库使用自己的线程而不是操作系统线程。
网络管理器(network manager):网路I/O是个大问题,尤其是对于分布式数据库。所以一些数据库具备自己的网络管理器。
文件系统管理器(File system manager):磁盘I/O是数据库的首要瓶颈。具备一个文件系统管理器来完美地处理OS文件系统甚至取代OS文件系统,是非常重要的。
内存管理器(memory manager):为了避免磁盘I/O带来的性能损失,需要大量的内存。但是如果你要处理大容量内存你需要高效的内存管理器,尤其是你有很多查询同时使用内存的时候。
安全管理器(Security Manager):用于对用户的验证和授权。
客户端管理器(Client manager):用于管理客户端连接。
……
工具:
备份管理器(Backup manager):用于保存和恢复数据。
复原管理器(Recovery manager):用于崩溃后重启数据库到一个一致状态。
监控管理器(Monitor manager):用于记录数据库活动信息和提供监控数据库的工具。
Administration管理器(Administration manager):用于保存元数据(比如表的名称和结构),提供管理数据库、模式、表空间的工具。【译者注:好吧,我真的不知道Administration manager该翻译成什么,有知道的麻烦告知,不胜感激……】
……
查询管理器:
查询解析器(Query parser):用于检查查询是否合法
查询重写器(Query rewriter):用于预优化查询
查询优化器(Query optimizer):用于优化查询
查询执行器(Query executor):用于编译和执行查询
数据管理器:
事务管理器(Transaction manager):用于处理事务
缓存管理器(Cache manager):数据被使用之前置于内存,或者数据写入磁盘之前置于内存
数据访问管理器(Data access manager):访问磁盘中的数据
