presto
presto是什么
是Facebook开源的,完全基于内存的并⾏计算,分布式SQL交互式查询引擎
是一种Massively parallel processing (MPP)架构,多个节点管道式执⾏
⽀持任意数据源(通过扩展式Connector组件),数据规模GB~PB级
使用的技术,如向量计算,动态编译执⾏计划,优化的ORC和Parquet Reader等
presto不太支持存储过程,支持部分标准sql
presto的查询速度比hive快5-10倍
上面讲述了presto是什么,查询速度,现在来看看presto适合干什么
适合:PB级海量数据复杂分析,交互式SQL查询,⽀持跨数据源查询
不适合:多个大表的join操作,因为presto是基于内存的,多张大表在内存里可能放不下
和hive的对比:
hive是一个数据仓库,是一个交互式比较弱一点的查询引擎,交互式没有presto那么强,而且只能访问hdfs的数据
presto是一个交互式查询引擎,可以在很短的时间内返回查询结果,秒级,分钟级,能访问很多数据源
hive在查询100Gb级别的数据时,消耗时间已经是分钟级了
但是presto是取代不了hive的,因为p全部的数据都是在内存中,限制了在内存中的数据集大小,比如多个大表的join,这些大表是不能完全放进内存的,实际应用中,对于在presto的查询是有一定规定条件的,比比如说一个查询在presto查询超过30分钟,那就kill掉吧,说明不适合在presto上使用,主要原因是,查询过大的话,会占用整个集群的资源,这会导致你后续的查询是没有资源进行查询的,这跟presto的设计理念是冲突的,就像是你进行一个查询,但是要等个5分钟才有资源继续查询,这是很不合理的,交互式就变得弱了很多
presto基本架构
在谈presto架构之前,先回顾下hive的架构
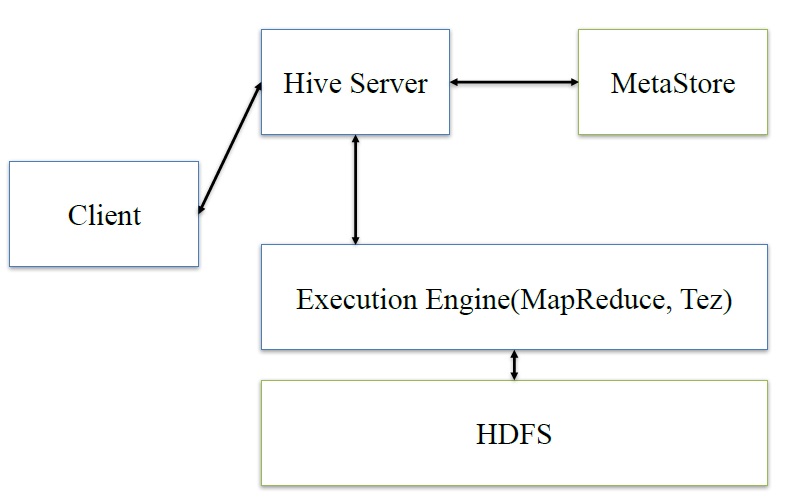
hive:client将查询请求发送到hive server,它会和metastor交互,获取表的元信息,如表的位置结构等,之后hive server会进行语法解析,解析成语法树,变成查询计划,进行优化后,将查询计划交给执行引擎,默认是MR,然后翻译成MR
presto:presto是在它内部做hive类似的逻辑
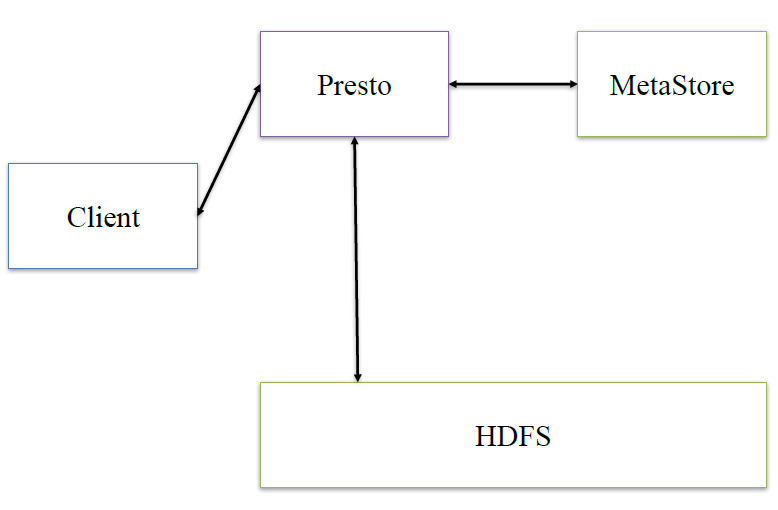
接下来,深入看下presto的内部架构
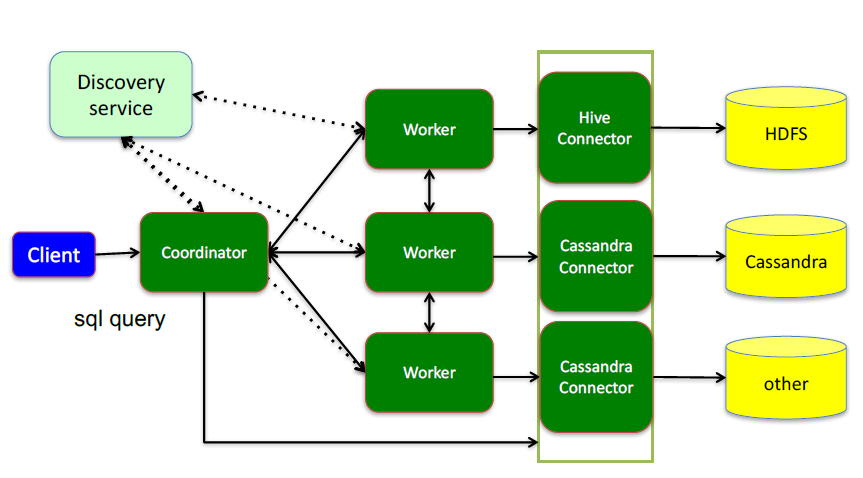
这里面三个服务:
Coordinator(考第内ter),是一个中心的查询角色,它主要的一个作用是接受查询请求,将他们转换成各种各样的任务,将任务拆解后分发到多个worker去执行各种任务的节点
1、解析SQL语句
2、⽣成执⾏计划
3、分发执⾏任务给Worker节点执⾏
Worker,是一个真正的计算的节点,执行任务的节点,它接收到task后,就会到对应的数据源里面,去把数据提取出来,提取方式是通过各种各样的connector:
1、负责实际执⾏查询任务
Discovery service,是将coordinator和woker结合到一起的服务:
1、Worker节点启动后向Discovery Server服务注册
2、Coordinator从Discovery Server获得Worker节点
coordinator和woker之间的关系是怎么维护的呢?是通过Discovery Server,所有的worker都把自己注册到Discovery Server上,Discovery Server是一个发现服务的service,Discovery Server发现服务之后,coordinator便知道在我的集群中有多少个worker能够给我工作,然后我分配工作到worker时便有了根据
最后,presto是通过connector plugin获取数据和元信息的,它不是⼀个数据存储引擎,不需要有数据,presto为其他数据存储系统提供了SQL能⼒,客户端协议是HTTP+JSON
Presto支持的数据源和存储格式
Hadoop/Hive connector与存储格式:
HDFS,ORC,RCFILE,Parquet,SequenceFile,Text
开源数据存储系统:
MySQL & PostgreSQL,Cassandra,Kafka,Redis
其他:
MongoDB,ElasticSearch,HBase
Presto中SQL运行过程:整体流程
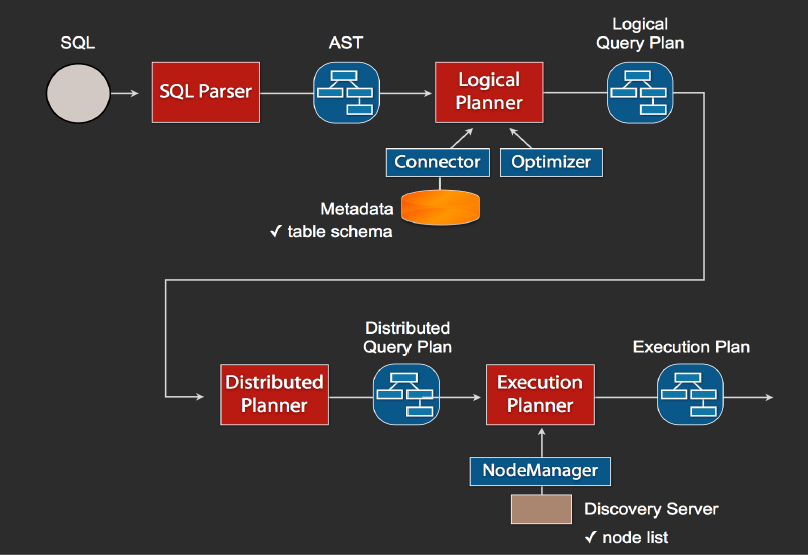
1、当我们执行一条sql查询,coordinator接收到这条sql语句以后,它会有一个sql的语法解析器去把sql语法解析变成一个抽象的语法树AST,这抽象的语法书它里面只是进行一些语法解析,如果你的sql语句里面,比如说关键字你用的是int而不是Integer,就会在语法解析这里给暴露出来
2、如果语法是符合sql语法规范,之后会经过一个逻辑查询计划器的组件,他的主要作用是,比如说你sql里面出现的表,他会通过connector的方式去meta里面把表的schema,列名,列的类型等,全部给找出来,将这些信息,跟语法树给对应起来,之后会生成一个物理的语法树节点,这个语法树节点里面,不仅拥有了它的查询关系,还拥有类型的关系,如果在这一步,数据库表里某一列的类型,跟你sql的类型不一致,就会在这里报错
3、如果通过,就会得到一个逻辑的查询计划,然后这个逻辑查询计划,会被送到一个分布式的逻辑查询计划器里面,进行一个分布式的解析,分布式解析里面,他就会去把对应的每一个查询计划转化为task
4、在每一个task里面,他会把对应的位置信息全部给提取出来,交给执行的plan,由plan把对应的task发给对应的worker去执行,这就是整个的一个过程
这是一个通用的sql解析流程,像hive也是遵循类似这样的流程,不一样的地方是distribution planner和executor pan,这里是各个引擎不一样的地方,前面基本上都一致的
Presto中SQL运行过程:MapReduce vs Presto
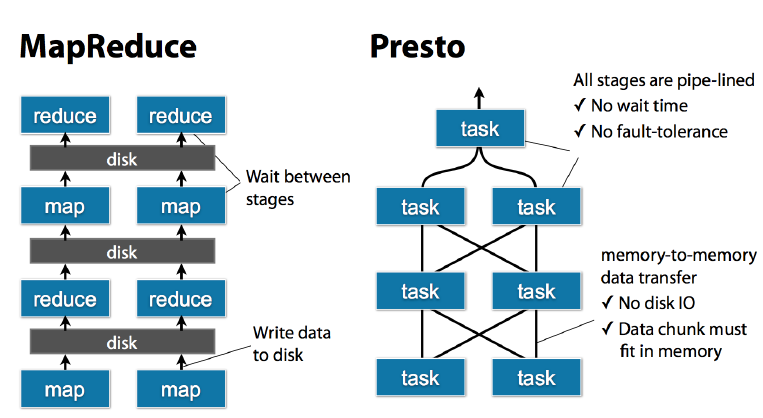
task是放在每个worker上该执行的,每个task执行完之后,数据是存放在内存里了,而不像mr要写磁盘,然后当多个task之间要进行数据交换,比如shuffle的时候,直接从内存里处理
Presto监控和配置:监控
Web UI
Query基本状态的查询
JMX HTTP API
GET /v1/jmx/mbean[/{objectName}]
• com.facebook.presto.execution:name=TaskManager
• com.facebook.presto.execution:name=QueryManager
• com.facebook.presto.execution:name=NodeScheduler
事件通知
Event Listener
• query start, query complete
Presto监控和配置:配置
执行计划计划(Coordinator)
node-scheduler.include-coordinator
• 是否让coordinator运行task
query.initial-hash-partitions
• 每个GROUP BY操作使⽤的hash bucket(=tasks)最大数目(default: 8)
node-scheduler.min-candidates
• 每个stage并发运行过程中可使用的最大worker数目(default:10)
query.schedule-split-batch-size
• 每个split数据量
任务执行(Worker)
query.max-memory (default: 20 GB)
• 一个查询可以使用的最大集群内存
• 控制集群资源使用,防止一个大查询占住集群所有资源
• 使用resource_overcommit可以突破限制
query.max-memory-per-node (default: 1 GB)
• 一个查询在一个节点上可以使用的最大内存
举例
• Presto集群配置: 120G * 40
• query.max-memory=1 TB
• query.max-memory-per-node=20 GB
query.max-run-time (default: 100 d)
• 一个查询可以运行的最大时间
• 防止用户提交一个长时间查询阻塞其他查询
task.max-worker-threads (default: Node CPUs * 4)
• 每个worker同时运行的split个数
• 调大可以增加吞吐率,但是会增加内存的消耗
队列(Queue)
任务提交或者资源使用的一些配置,是通过队列的配置来实现的
资源隔离,查询可以提交到相应队列中
• 资源隔离,查询可以提交到相应队列中
• 每个队列可以配置ACL(权限)
• 每个队列可以配置Quota
可以并发运行查询的数量
排队的最大数量
大数据OLAP引擎对比
Presto:内存计算,mpp架构
Druid:时序,数据放内存,索引,预计算
Spark SQL:基于Spark Core,mpp架构
Kylin:Cube预计算
最后,一些零散的知识点
presto适合pb级的海量数据查询分析,不是说把pb的数据放进内存,比如一张pb表,查询count,vag这种有个特点,虽然数据很多,但是最终的查询结果很小,这种就不会把数据都放到内存里面,只是在运算的过程中,拿出一些数据放内存,然后计算,在抛出,在拿,这种的内存占用量是很小的,但是join这种,在运算的中间过程会产生大量的数据,或者说那种查询的数据不大,但是生成的数据量很大,这种也是不合适用presto的,但不是说不能做,只是会占用大量内存,消耗很长的时间,这种hive合适点
presto算是hive的一个补充,需要尽快得出结果的用presto,否则用hive
work是部署的时候就事先部署好的,work启动100个,使用的work不一定100个,而是根据coordinator来决定拆分成多少个task,然后分发到多少个work去
一个coordinator可能同时又多个用户在请求query,然后共享work的去执行,这是一个共享的集群
coordinator和discovery server可以启动在一个节点一个进程,也可以放在不同的node上,但是现在公司大部分都是放在一个节点上,一个launcher start会同时把上述两个启动起来
对于presto的容错,如果某个worker挂掉了,discovery server会发现并通知coordinator
但是对于一个query,是没有容错的,一旦一个work挂了,那么整个qurey就是败了
因为对于presto,他的查询时间是很短的,与其查询这里做容错能力,不如重新执行来的快来的简单
对于coordinator和discovery server节点的单点故障,presto还没有开始处理这个问题貌似
1,Presto基本认识
1.1 定义
Presto是一个分布式的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto是一个OLAP的工具,擅长对海量数据进行复杂的分析;但是对于OLTP场景,并不是Presto所擅长,所以不要把Presto当做数据库来使用。
和大家熟悉的Mysql相比:首先Mysql是一个数据库,具有存储和计算分析能力,而Presto只有计算分析能力;其次数据量方面,Mysql作为传统单点关系型数据库不能满足当前大数据量的需求,于是有各种大数据的存储和分析工具产生,Presto就是这样一个可以满足大数据量分析计算需求的一个工具。
1.2 数据源
Presto需要从其他数据源获取数据来进行运算分析,它可以连接多种数据源,包括Hive、RDBMS(Mysql、Oracle、Tidb等)、Kafka、MongoDB、Redis等
一条Presto查询可以将多个数据源的数据进行合并分析。
比如:select * from a join b where a.id=b.id;,其中表a可以来自Hive,表b可以来自Mysql。
1.3 优势
Presto是一个低延迟高并发的内存计算引擎,相比Hive,执行效率要高很多。
举例:
SELECT id,
name,
source_type,
created_at
FROM dw_dwb.dwb_user_day
WHERE dt=’2018-06-03’
AND created_at>’2018-05-20’;
上述SQL在Presto运行时间不到1秒钟,在Hive里要几十秒钟。
1.4数据模型
Presto使用Catalog、Schema和Table这3层结构来管理数据。
—- Catalog:就是数据源。Hive是数据源,Mysql也是数据源,Hive 和Mysql都是数据源类型,可以连接多个Hive和多个Mysql,每个连接都有一个名字。一个Catalog可以包含多个Schema,大家可以通过show catalogs 命令看到Presto连接的所有数据源。
—- Schema:相当于一个数据库实例,一个Schema包含多张数据表。show schemas from ‘catalog_name’可列出catalog_name下的所有schema。
—- Table:数据表,与一般意义上的数据库表相同。show tables from ‘catalog_name.schema_name’可查看’catalog_name.schema_name’下的所有表。
在Presto中定位一张表,一般是catalog为根,例如:一张表的全称为 hive.test_data.test,标识 hive(catalog)下的 test_data(schema)中test表。
可以简理解为:数据源的大类.数据库.数据表。
2,Presto与Hive
Hive是一个基于HDFS(分布式文件系统)的一个数据库,具有存储和分析计算能力, 支持大数据量的存储和查询。Hive 作为数据源,结合Presto分布式查询引擎,这样大数据量的查询计算速度就会快很多。
Presto支持标准SQL,这里需要提醒大家的是,在使用Hive数据源的时候,如果表是分区表,一定要添加分区过滤,不加分区扫描全表是一个很暴力的操作,执行效率低下并且占用大量集群资源,大家尽量避免这种写法。
这里提到Hive分区,我简单介绍一下概念。Hive分区就是分目录,把一个大的数据集根据业务需要分割成更细的数据集。
举例:假如一个表的数据都放在/user/xiaoming/table/目录下,如果想把数据按照每天的数据细分,则就变成/user/xiaoming/table/2018-06-01/,/user/xiaoming/table/2018-06-02/,……如果查询某一天的数据,就可以直接取某一天目录下的数据,不需要扫描其他天的数据,节省了时间和资源。
使用Presto:
3,Presto接入方式
Presto的接入方式有多种:presto-cli,pyhive,jdbc,http,golang,SQLAlchemy,PHP等,其中presto-cli是Presto官方提供的,下面以presto-cli为例展开说明(自行下载)。
以连接hive数据源为例,在电脑终端输入:./presto-cli.jar –server presto.xxx-apps.com:9200 –catalog hive –user xxxx –source ‘pf=adhoc;client=cli’就可以进入presto终端界面。
先解释下各参数的含义:
–server 是presto服务地址;
–catalog 是默认使用哪个数据源,后面也可以切换,如果想连接mysql数据源,使用mysql数据源名称即可;
–user 是用户名;
–source 是代表查询来源,source设置格式为key=value形式(英文分号分割); 例如个人从command line查询应设置为pf=adhoc;client=cli。
进入终端后:
查看数据源: show catalogs;
查看数据库实例:show schemas;
Presto使用手册:https://prestodb.io/docs/current/
问答:
1.使用场景?
-mysql跨数据库查询;-数仓的表数据查询(数据分析) …
2.为什么presto查询速度比Hive快?
presto是常驻任务,接受请求立即执行,全内存并行计算;hive需要用yarn做资源调度,接受查询需要先申请资源,启动进程,并且中间结果会经过磁盘。
