mysql
https://hejtao.com/2019/09/20/2019-9-20/#qi-dong-xuan-xiang-he-xi-tong-bian-liang
InnoDB是一个将表中的数据存储到磁盘上的存储引擎。磁盘读写的速度比内存的读写速度差了几个数量级,因此设计InnoDB时将数据划分为若干个页并以页作为磁盘和内存之间交互的基本单位,页的大小一般为 16 KB。
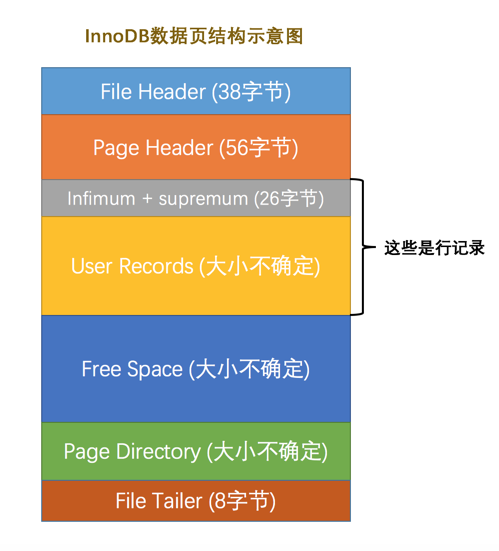
记录在页中的存储
记录头信息
delete_mask
标记当前记录是否被删除,值为0的时候代表记录没有被删除,1则被删除了; 所有被删的记录会组成一个垃圾链表,新记录插入到表时可以覆盖这些被删除的记录占用的存储空间。
n_owned
heap_no
表示当前记录在本页中的位置
record_type
记录类型,共4种:
0:普通记录
1:B+树非叶节点记录 (或目录项记录,见目录项)
2:最小记录
3:最大记录
min_rec_mask
代表B+树的每层非叶节点中的最小记录 (或者主键值最小的目录项记录的min_rec_mask值为1)
next_record
表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。例如第一条记录的next_record值为32,意味着从第一条记录的真实数据的地址处向后找32个字节便是下一条记录的真实数据。记录按照主键从小到大的顺序形成了一个单链表
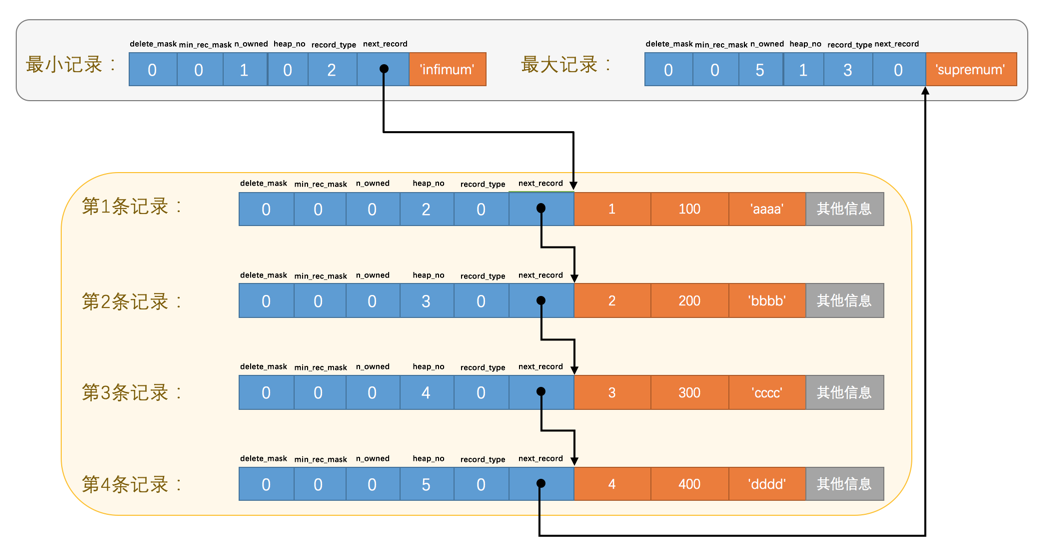
删除第2条记录前后的主要变化:
第2条记录的delete_mask值设置为1;
第2条记录的next_record值变为了0,意味着该记录没有下一条记录了;
第1条记录的next_record指向了第3条记录;
最大记录的n_owned值从5变成了4。
Page Directory#
设计页目录是为了方便快速查找记录,就像书的目录那样,创建 page directory 的步骤:
将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组;
每个组内最大的那条记录的头信息的 n_owned 表示组内记录的数量;
将每个组的最大的那条记录的地址偏移量(也称槽,slot)集中起来存放,构成 Page Directory;
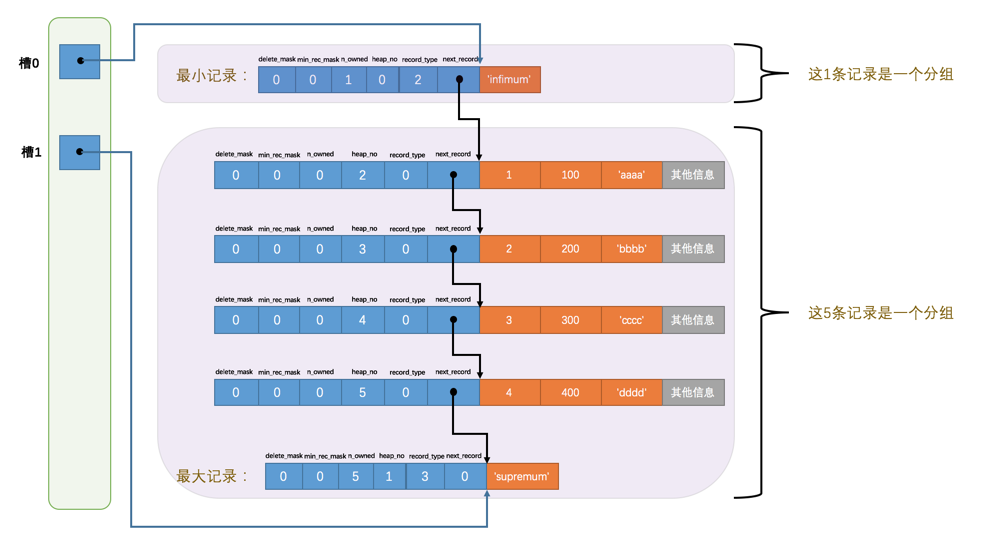
InnoDB规定最小记录所在的分组只能有 1 条记录,最大记录所在的分组的记录条数在 1~8 条之间,其它分组中记录的条数则在是 4~8 条之间。
利用页目录查找指定主键的记录的过程分为两步:
通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录;
通过记录的 next_record 属性遍历组中的各个记录。
Page Header#
存储数据的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等。
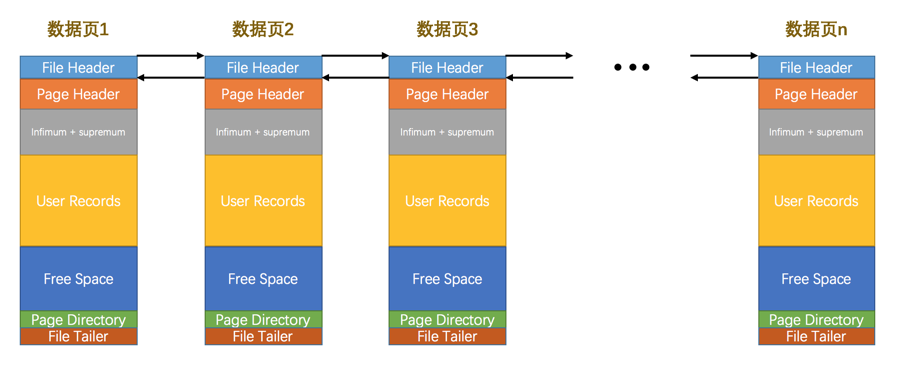
File Header#
不同类型的页都会以File Header作为第一个组成部分,它记录了针对各种页都通用的一些信息。 索引页(数据页)通过 file header 构成双向链表
无索引查找#
在页内查找#
以主键查找 依据页目录(槽)采用二分查找定位分组,再遍历分组
以主键以外的列查找 遍历页内的记录链表
在多页中查找#
定位记录所在的页
页内查找
索引#
建立索引是为了快速定位记录所在的数据页。
对数据页进行排序。即让下一个数据页的记录的主键值大于上一个页的记录的主键值,因此在插入新的记录时涉及数据页间的记录的调整
对每个页设置目录项
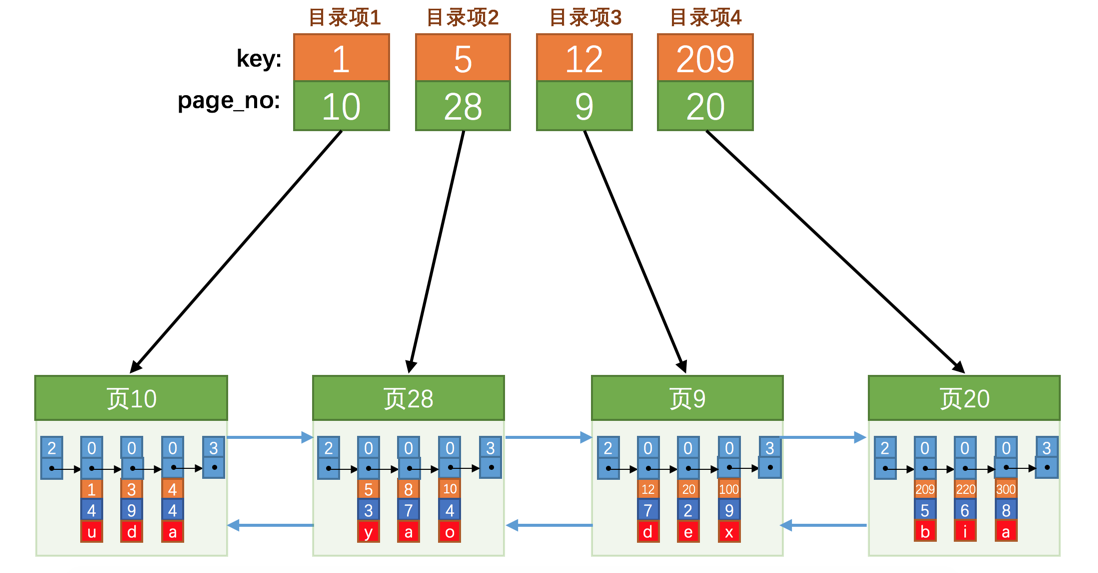
目录项#
目录项包括
数据页中的记录的最小主键值,用key来表示;
页号,用page_no表示。
<img src="https://xiazemin.github.io/MyBlog/img/innodb_record_type.png"/>
用户记录都存放在B+树的叶节点上,而目录项都存放在非页节点上。
聚簇索引#
特性包括:
依据记录的主键值排序
页内的记录是按照主键的大小顺序排成一个单向链表
数据页根据主键大小顺序排成一个双向链表
存放目录项记录的页根据主键大小分为不同的层次
B+树的叶节点存储的是完整的记录,即记录的所有列的值(包括隐藏列)
二级索引#
依据记录的其它列(比如c1)的值排序形成的B+树。将聚簇索引的主键值换为c1的值,此外,叶节点存储的不是完整的记录而只有主键和c1。
通过二级索引来查找完整记录:通过二级索引找到主键值之后再通过聚簇索引查找完整记录。
二级索引 + 回表 or 全表扫码#
需要回表的记录越多,使用二级索引的性能就越低,甚至不如使用聚簇索引全表扫码;
使用LIMIT限制回表次数,使优化器倾向于使用二级索引 + 回表的方式执行查询。
覆盖索引#
如果需要查询的列包含在二级索引中,就可以避免回表查询,这种只需要用到索引的查询方式称为索引覆盖
合理地建立索引#
只给搜索、排序、分组的列创建索引
即只给出现在 WHERE、ORDER BY、GROUP BY 子句中的列创建索引;
列的方差越大越适合建立索引
列的数据越分散,越适合索引查询。举个极端的例子,数据都相同的列,对这样的列建立索引毫无意义;
列的数据类型越小越适合建立索引
比较数据大小更快,占用的存储空间更小;
索引字符串的前缀
MySQL的数据目录#
数据库和文件系统的关系#
InnoDB、MyISAM等存储引擎都是把表存储在磁盘上。操作系统通过文件系统管理磁盘。
InnoDB、MyISAM等存储引擎 ⇔ 文件系统 ⇔ 磁盘
数据目录#
数据目录和安装目录的区别#
数据目录是用来存储MySQL在运行过程中产生的数据,要与MySQL的安装目录区别开来。
查找数据目录#
数据目录的结构#
数据库在文件系统中的表示#
每新建一个数据库,MySQL执行了:
在数据目录下创建一个和数据库名同名的子目录;
并在该子目录下创建一个db.opt文件,这个文件中包含了该数据库的各种属性,比方说该数据库的字符集和比较规则等。
除了information_schema这个系统数据库外,其他的数据库在数据目录下都有对应的子目录。
表在文件系统中的表示#
每个表包含两部分信息:
表结构的定义
用表名.frm文件来描述表结构
表中的数据
InnoDB: 数据存在独立表空间(file-per-table tablespace)中,即 test.ibd 文件
MyISAM: 表名.MYD表示表的数据文件、表名.MYI表示表的索引文件
文件系统对数据库的影响#
数据库名和表名不得超过文件系统所允许的最大长度
特殊字符
MySQL会把数据库名和表名中除数字和拉丁字母外的所有字符在文件名里都映射成 @+编码值的形式,如test?.frm → test@003f.frm
文件大小受文件系统限制
MySQL系统数据库简介#
mysql
存储了MySQL的账户和权限信息,一些存储过程、事件的定义信息,一些运行过程中产生的日志信息、以及时区信息等
information_schema
这个数据库保存着MySQL服务器维护的所有其他数据库的信息,比如表、视图、触发器、列、索引等
performance_schema
这个数据库里主要保存MySQL服务器运行过程中的一些状态信息,包括统计最近执行的语句,执行时间,内存使用情况等
sys
这个数据库主要是通过视图的形式把information_schema和performance_schema结合起来
InnoDB表空间#
表空间对应着文件系统中一个或多个实际文件(独立表空间对应一个表名.ibd文件)。可以把表空间想象成一本书,当想为某个表插入一条记录的时候,就在书中对应的页来把数据写进去。
数据页#
页类型#
File Header : 记录数据页的一些通用信息
File Trailer:校验数据页,保证从内存到磁盘的数据的一致性
独立表空间结构#
区(extent)的概念#
数据页16KB
物理上连续的64个页就是一个区1MB
每256个区被划分成一组,每个组的最开始的几个页面类型是固定的
系统表空间或独立表空间由若干个区组成
为什么引入区的设计?
区是连续的存储空间,这样可以减少随机I/O, 增加顺序I/O
段(segment)的概念#
所以设计InnoDB的大叔们对B+树的叶子节点和非叶子节点进行了区别对待,也就是说叶子节点有自己独有的区,非叶子节点也有自己独有的区。存放叶子节点的区的集合就算是一个段(segment),存放非叶子节点的区的集合也算是一个段。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。
https://juejin.cn/book/6844733769996304392/section/6844733770042441735
https://hejtao.com/2019/09/20/2019-9-20/#dan-biao-fang-wen-fang-fa
https://github.com/hejtao?tab=repositories
https://juejin.cn/book/6844733769996304392/section/6844733769945972749
https://blog.jcole.us/innodb/
https://blog.csdn.net/fly2nn
https://github.com/jeremycole/innodb_ruby
https://github.com/jeremycole/innodb_ruby/wiki
