zookeeper在hadoop和hbase中的作用
会话(Session)
Session是指客户端会话,在讲解客户端会话之前,我们先来了解下客户端连接。在ZooKeeper中,一个客户端连接是指客户端和ZooKeeper服务器之间的TCP长连接。ZooKeeper对外的服务端口默认是2181,客户端启动时,首先会与服务器建立一个TCP连接,从第一次连接建立开始,客户端会话的生命周期也开始了,通过这个连接,客户端能够通过心跳检测和服务器保持有效的会话,也能够向ZooKeeper服务器发送请求并接受响应,同时还能通过该连接接收来自服务器的Watch事件通知。Session的SessionTimeout值用来设置一个客户端会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在SessionTimeout规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
版本
ZooKeeper的每个ZNode上都会存储数据,对应于每个ZNode,ZooKeeper都会为其维护一个叫作Stat的数据结构,Stat中记录了这个ZNode的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和aversion(当前ZNode的ACL版本)。
状态信息
每个ZNode除了存储数据内容之外,还存储了ZNode本身的一些状态信息。用 get 命令可以同时获得某个ZNode的内容和状态信息。如下:
[zk: localhost:2181(CONNECTED) 23] get /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb
appcluster-yarnrm1
cZxid = 0x1b00133dc0 //Created ZXID,表示该ZNode被创建时的事务ID
ctime = Tue Jan 03 15:44:42 CST 2017 //Created Time,表示该ZNode被创建的时间
mZxid = 0x1d00000063 //Modified ZXID,表示该ZNode最后一次被更新时的事务ID
mtime = Fri Jan 06 08:44:25 CST 2017 //Modified Time,表示该节点最后一次被更新的时间
pZxid = 0x1b00133dc0 //表示该节点的子节点列表最后一次被修改时的事务ID。注意,只有子节点列表变更了才会变更pZxid,子节点内容变更不会影响pZxid。
cversion = 0 //子节点的版本号
dataVersion = 11 //数据节点的版本号
aclVersion = 0 //ACL版本号
ephemeralOwner = 0x0 //创建该节点的会话的seddionID。如果该节点是持久节点,那么这个属性值为0。
dataLength = 22 //数据内容的长度
numChildren = 0 //子节点的个数
[zk: localhost:2181(CONNECTED) 23] get /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb
appcluster-yarnrm1
cZxid = 0x1b00133dc0
ACL
ZooKeeper采用ACL(Access Control Lists)策略来进行权限控制。ZooKeeper定义了如下5种权限。
CREATE: 创建子节点的权限。
READ: 获取节点数据和子节点列表的权限。
WRITE:更新节点数据的权限。
DELETE: 删除子节点的权限。
ADMIN: 设置节点ACL的权限。
注意:CREATE 和 DELETE 都是针对子节点的权限控制。
ZooKeeper典型应用场景
ZooKeeper是一个高可用的分布式数据管理与协调框架。基于对ZAB算法的实现,该框架能够很好地保证分布式环境中数据的一致性。也是基于这样的特性,使得ZooKeeper成为了解决分布式一致性问题的利器。
数据发布与订阅(配置中心)
数据发布与订阅,即所谓的配置中心,顾名思义就是发布者将数据发布到ZooKeeper节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和动态更新。
在我们平常的应用系统开发中,经常会碰到这样的需求:系统中需要使用一些通用的配置信息,例如机器列表信息、数据库配置信息等。这些全局配置信息通常具备以下3个特性。
数据量通常比较小。
数据内容在运行时动态变化。
集群中各机器共享,配置一致。
对于这样的全局配置信息就可以发布到ZooKeeper上,让客户端(集群的机器)去订阅该消息。
发布/订阅系统一般有两种设计模式,分别是推(Push)和拉(Pull)模式。
推:服务端主动将数据更新发送给所有订阅的客户端。
拉:客户端主动发起请求来获取最新数据,通常客户端都采用定时轮询拉取的方式。
ZooKeeper采用的是推拉相结合的方式。如下:
客户端想服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知后,需要主动到服务端获取最新的数据(推拉结合)。
命名服务(Naming Service)
命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架(如RPC、RMI)中的服务地址列表。通过在ZooKeepr里创建顺序节点,能够很容易创建一个全局唯一的路径,这个路径就可以作为一个名字。
ZooKeeper的命名服务即生成全局唯一的ID。
分布式协调/通知
ZooKeeper中特有Watcher注册与异步通知机制,能够很好的实现分布式环境下不同机器,甚至不同系统之间的通知与协调,从而实现对数据变更的实时处理。使用方法通常是不同的客户端都对ZK上同一个ZNode进行注册,监听ZNode的变化(包括ZNode本身内容及子节点的),如果ZNode发生了变化,那么所有订阅的客户端都能够接收到相应的Watcher通知,并做出相应的处理。
ZK的分布式协调/通知,是一种通用的分布式系统机器间的通信方式。
心跳检测
机器间的心跳检测机制是指在分布式环境中,不同机器(或进程)之间需要检测到彼此是否在正常运行,例如A机器需要知道B机器是否正常运行。在传统的开发中,我们通常是通过主机直接是否可以相互PING通来判断,更复杂一点的话,则会通过在机器之间建立长连接,通过TCP连接固有的心跳检测机制来实现上层机器的心跳检测,这些都是非常常见的心跳检测方法。
下面来看看如何使用ZK来实现分布式机器(进程)间的心跳检测。
基于ZK的临时节点的特性,可以让不同的进程都在ZK的一个指定节点下创建临时子节点,不同的进程直接可以根据这个临时子节点来判断对应的进程是否存活。通过这种方式,检测和被检测系统直接并不需要直接相关联,而是通过ZK上的某个节点进行关联,大大减少了系统耦合。
工作进度汇报
在一个常见的任务分发系统中,通常任务被分发到不同的机器上执行后,需要实时地将自己的任务执行进度汇报给分发系统。这个时候就可以通过ZK来实现。在ZK上选择一个节点,每个任务客户端都在这个节点下面创建临时子节点,这样便可以实现两个功能:
通过判断临时节点是否存在来确定任务机器是否存活。
各个任务机器会实时地将自己的任务执行进度写到这个临时节点上去,以便中心系统能够实时地获取到任务的执行进度。
Master选举
Master选举可以说是ZooKeeper最典型的应用场景了。比如HDFS中Active NameNode的选举、YARN中Active ResourceManager的选举和HBase中Active HMaster的选举等。
针对Master选举的需求,通常情况下,我们可以选择常见的关系型数据库中的主键特性来实现:希望成为Master的机器都向数据库中插入一条相同主键ID的记录,数据库会帮我们进行主键冲突检查,也就是说,只有一台机器能插入成功——那么,我们就认为向数据库中成功插入数据的客户端机器成为Master。
依靠关系型数据库的主键特性确实能够很好地保证在集群中选举出唯一的一个Master。但是,如果当前选举出的Master挂了,那么该如何处理?谁来告诉我Master挂了呢?显然,关系型数据库无法通知我们这个事件。但是,ZooKeeper可以做到!
利用ZooKeepr的强一致性,能够很好地保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,即ZooKeeper将会保证客户端无法创建一个已经存在的ZNode。也就是说,如果同时有多个客户端请求创建同一个临时节点,那么最终一定只有一个客户端请求能够创建成功。利用这个特性,就能很容易地在分布式环境中进行Master选举了。
成功创建该节点的客户端所在的机器就成为了Master。同时,其他没有成功创建该节点的客户端,都会在该节点上注册一个子节点变更的Watcher,用于监控当前Master机器是否存活,一旦发现当前的Master挂了,那么其他客户端将会重新进行Master选举。
这样就实现了Master的动态选举。
分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
分布式锁又分为排他锁和共享锁两种。
排他锁
排他锁(Exclusive Locks,简称X锁),又称为写锁或独占锁。
如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能在对这个数据对象进行任何类型的操作(不能再对该对象加锁),直到T1释放了排他锁。
可以看出,排他锁的核心是如何保证当前只有一个事务获得锁,并且锁被释放后,所有正在等待获取锁的事务都能够被通知到。
如何利用ZooKeeper实现排他锁?
定义锁
ZooKeeper上的一个ZNode可以表示一个锁。例如/exclusive_lock/lock节点就可以被定义为一个锁。
获得锁
如上所说,把ZooKeeper上的一个ZNode看作是一个锁,获得锁就通过创建ZNode的方式来实现。所有客户端都去/exclusive_lock节点下创建临时子节点/exclusive_lock/lock。ZooKeeper会保证在所有客户端中,最终只有一个客户端能够创建成功,那么就可以认为该客户端获得了锁。同时,所有没有获取到锁的客户端就需要到/exclusive_lock节点上注册一个子节点变更的Watcher监听,以便实时监听到lock节点的变更情况。
释放锁
因为/exclusive_lock/lock是一个临时节点,因此在以下两种情况下,都有可能释放锁。
当前获得锁的客户端机器发生宕机或重启,那么该临时节点就会被删除,释放锁。
正常执行完业务逻辑后,客户端就会主动将自己创建的临时节点删除,释放锁。
无论在什么情况下移除了lock节点,ZooKeeper都会通知所有在/exclusive_lock节点上注册了节点变更Watcher监听的客户端。这些客户端在接收到通知后,再次重新发起分布式锁获取,即重复『获取锁』过程。
共享锁
共享锁(Shared Locks,简称S锁),又称为读锁。如果事务T1对数据对象O1加上了共享锁,那么T1只能对O1进行读操作,其他事务也能同时对O1加共享锁(不能是排他锁),直到O1上的所有共享锁都释放后O1才能被加排他锁。
总结:可以多个事务同时获得一个对象的共享锁(同时读),有共享锁就不能再加排他锁(因为排他锁是写锁)
#ZooKeeper在Hadoop中的应用
在Hadoop中,ZooKeeper主要用于实现HA(Hive Availability),包括HDFS的NamaNode和YARN的ResourceManager的HA。同时,在YARN中,ZooKeepr还用来存储应用的运行状态。HDFS的NamaNode和YARN的ResourceManager利用ZooKeepr实现HA的原理是一样的,所以本节以YARN为例来介绍。
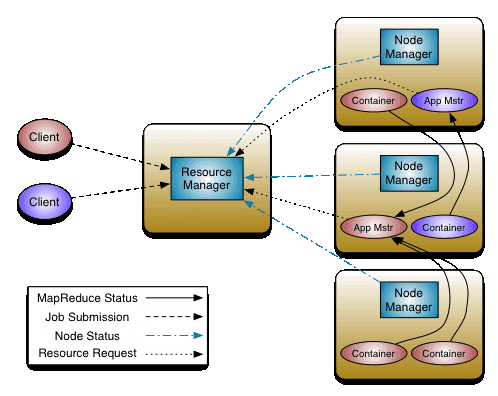
从上图可以看出,YARN主要由ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)和Container四部分组成。其中最核心的就是ResourceManager。
ResourceManager负责集群中所有资源的统一管理和分配,同时接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(Application Manager),其内部维护了各个应用程序的ApplicationMaster信息、NodeManager信息以及资源使用信息等。
为了实现HA,必须有多个ResourceManager并存(一般就两个),并且只有一个ResourceManager处于Active状态,其他的则处于Standby状态,当Active节点无法正常工作(如机器宕机或重启)时,处于Standby的就会通过竞争选举产生新的Active节点。
主备切换
下面我们就来看看YARN是如何实现多个ResourceManager之间的主备切换的。
创建锁节点
在ZooKeeper上会有一个/yarn-leader-election/appcluster-yarn的锁节点,所有的ResourceManager在启动的时候,都会去竞争写一个Lock子节点:/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb,该节点是临时节点。ZooKeepr能够为我们保证最终只有一个ResourceManager能够创建成功。创建成功的那个ResourceManager就切换为Active状态,没有成功的那些ResourceManager则切换为Standby状态。
get /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb
appcluster-yarnrm2
cZxid = 0x1b00133dc0
ctime = Tue Jan 03 15:44:42 CST 2017
可以看到此时集群中ResourceManager2为Active。
注册Watcher监听
所有Standby状态的ResourceManager都会向/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb节点注册一个节点变更的Watcher监听,利用临时节点的特性,能够快速感知到Active状态的ResourceManager的运行情况。
主备切换
当Active状态的ResourceManager出现诸如宕机或重启的异常情况时,其在ZooKeeper上连接的客户端会话就会失效,因此/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb节点就会被删除。此时其余各个Standby状态的ResourceManager就都会接收到来自ZooKeeper服务端的Watcher事件通知,然后会重复进行步骤1的操作。
以上就是利用ZooKeeper来实现ResourceManager的主备切换的过程,实现了ResourceManager的HA。
HDFS中NameNode的HA的实现原理跟YARN中ResourceManager的HA的实现原理相同。其锁节点为/hadoop-ha/mycluster/ActiveBreadCrumb。
ResourceManager状态存储
在 ResourceManager 中,RMStateStore 能够存储一些 RM 的内部状态信息,包括 Application 以及它们的 Attempts 信息、Delegation Token 及 Version Information 等。需要注意的是,RMStateStore 中的绝大多数状态信息都是不需要持久化存储的,因为很容易从上下文信息中将其重构出来,如资源的使用情况。在存储的设计方案中,提供了三种可能的实现,分别如下。
基于内存实现,一般是用于日常开发测试。
基于文件系统的实现,如HDFS。
基于ZooKeeper实现。
由于这些状态信息的数据量都不是很大,因此Hadoop官方建议基于ZooKeeper来实现状态信息的存储。在ZooKeepr上,ResourceManager 的状态信息都被存储在/rmstore这个根节点下面。
ls /rmstore/ZKRMStateRoot
[RMAppRoot, AMRMTokenSecretManagerRoot, EpochNode, RMDTSecretManagerRoot, RMVersionNode]
RMAppRoot 节点下存储的是与各个 Application 相关的信息,RMDTSecretManagerRoot 存储的是与安全相关的 Token 等信息。每个 Active 状态的 ResourceManager 在初始化阶段都会从 ZooKeeper 上读取到这些状态信息,并根据这些状态信息继续进行相应的处理。
小结:
ZooKeepr在Hadoop中的应用主要有:
HDFS中NameNode的HA和YARN中ResourceManager的HA。
存储RMStateStore状态信息
ZooKeeper在HBase中的应用
HBase主要用ZooKeeper来实现HMaster选举与主备切换、系统容错、RootRegion管理、Region状态管理和分布式SplitWAL任务管理等。
HMaster选举与主备切换
HMaster选举与主备切换的原理和HDFS中NameNode及YARN中ResourceManager的HA原理相同。
系统容错
当HBase启动时,每个RegionServer都会到ZooKeeper的/hbase/rs节点下创建一个信息节点(下文中,我们称该节点为”rs状态节点”),例如/hbase/rs/[Hostname],同时,HMaster会对这个节点注册监听。当某个 RegionServer 挂掉的时候,ZooKeeper会因为在一段时间内无法接受其心跳(即 Session 失效),而删除掉该 RegionServer 服务器对应的 rs 状态节点。与此同时,HMaster 则会接收到 ZooKeeper 的 NodeDelete 通知,从而感知到某个节点断开,并立即开始容错工作。
HBase为什么不直接让HMaster来负责RegionServer的监控呢?如果HMaster直接通过心跳机制等来管理RegionServer的状态,随着集群越来越大,HMaster的管理负担会越来越重,另外它自身也有挂掉的可能,因此数据还需要持久化。在这种情况下,ZooKeeper就成了理想的选择。
RootRegion管理
对应HBase集群来说,数据存储的位置信息是记录在元数据region,也就是RootRegion上的。每次客户端发起新的请求,需要知道数据的位置,就会去查询RootRegion,而RootRegion自身位置则是记录在ZooKeeper上的(默认情况下,是记录在ZooKeeper的/hbase/meta-region-server节点中)。当RootRegion发生变化,比如Region的手工移动、重新负载均衡或RootRegion所在服务器发生了故障等是,就能够通过ZooKeeper来感知到这一变化并做出一系列相应的容灾措施,从而保证客户端总是能够拿到正确的RootRegion信息。
Region管理
HBase里的Region会经常发生变更,这些变更的原因来自于系统故障、负载均衡、配置修改、Region分裂与合并等。一旦Region发生移动,它就会经历下线(offline)和重新上线(online)的过程。
在下线期间数据是不能被访问的,并且Region的这个状态变化必须让全局知晓,否则可能会出现事务性的异常。对于大的HBase集群来说,Region的数量可能会多达十万级别,甚至更多,这样规模的Region状态管理交给ZooKeeper来做也是一个很好的选择。
分布式SplitWAL任务管理
当某台RegionServer服务器挂掉时,由于总有一部分新写入的数据还没有持久化到HFile中,因此在迁移该RegionServer的服务时,一个重要的工作就是从WAL中恢复这部分还在内存中的数据,而这部分工作最关键的一步就是SplitWAL,即HMaster需要遍历该RegionServer服务器的WAL,并按Region切分成小块移动到新的地址下,并进行日志的回放(replay)。
由于单个RegionServer的日志量相对庞大(可能有上千个Region,上GB的日志),而用户又往往希望系统能够快速完成日志的恢复工作。因此一个可行的方案是将这个处理WAL的任务分给多台RegionServer服务器来共同处理,而这就又需要一个持久化组件来辅助HMaster完成任务的分配。当前的做法是,HMaster会在ZooKeeper上创建一个SplitWAL节点(默认情况下,是/hbase/SplitWAL节点),将“哪个RegionServer处理哪个Region”这样的信息以列表的形式存放到该节点上,然后由各个RegionServer服务器自行到该节点上去领取任务并在任务执行成功或失败后再更新该节点的信息,以通知HMaster继续进行后面的步骤。ZooKeeper在这里担负起了分布式集群中相互通知和信息持久化的角色。
小结:
以上就是一些HBase中依赖ZooKeeper完成分布式协调功能的典型场景。但事实上,HBase对ZooKeepr的依赖还不止这些,比如HMaster还依赖ZooKeeper来完成Table的enable/disable状态记录,以及HBase中几乎所有的元数据存储都是放在ZooKeeper上的。
由于ZooKeeper出色的分布式协调能力及良好的通知机制,HBase在各版本的演进过程中越来越多地增加了ZooKeeper的应用场景,从趋势上来看两者的交集越来越多。HBase中所有对ZooKeeper的操作都封装在了org.apache.hadoop.hbase.zookeeper这个包中
Hadoop 1.x does not use Zookeeper. HBase does use zookeeper even in Hadoop 1.x installations.
Hadoop adopted Zookeeper as well starting with version 2.0.
The purpose of Zookeeper is cluster management. This fits with the general philosophy of *nix of using smaller specialized components - so components of Hadoop that want clustering capabilities rely on Zookeeper for that rather than develop their own.
Zookeeper is a distributed storage that provides the following guarantees (copied from Zookeeper overview page):
Sequential Consistency - Updates from a client will be applied in the order that they were sent.
Atomicity - Updates either succeed or fail. No partial results.
Single System Image - A client will see the same view of the service regardless of the server that it connects to.
Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update.
Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound.
You can use these to implement different “recipes” that are required for cluster management like locks, leader election etc.
If you’re going to use ZooKeeper yourself, I recommend you take a look at Curator from Netflix which makes it easier to use (e.g. they implement a few recipes out of the box)
zookeeper在Hadoop及hbase中具体作用
1,Hadoop有NameNode,HBase有HMaster,为什么还需要zookeeper,下面给大家通过例子给大家介绍。
一个Zookeeper的集群中,3个Zookeeper节点.一个leader,两个follower的情况下,停掉leader,然后两个follower选举出一个leader.获取的数据不变.我想Zookeeper能够帮助Hadoop做到:
Hadoop,使用Zookeeper的事件处理确保整个集群只有一个NameNode,存储配置信息等.
HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
2,hbase regionserver 向zookeeper注册,提供hbase regionserver状态信息(是否在线)
3,hmaster启动时候会将hbase 系统表-ROOT- 加载到 zookeeper cluster,通过zookeeper cluster可以获取当前系统表.META.的存储所对应的regionserver信息。
HMaster主要作用在于,通过HMaster维护系统表-ROOT-,.META.,记录regionserver所对应region变化信息。此外还负责监控处理当前hbase cluster中regionserver状态变化信息。
hbase regionserver则用于多个/单个维护region。
region则对应为hbase数据表的表分区数据维护。
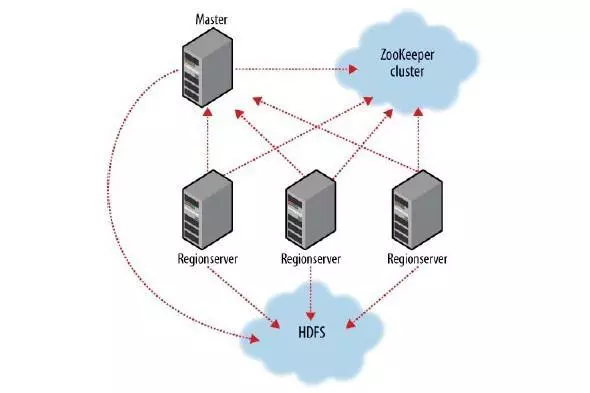
Zookeeper作用在于:
1、hbase regionserver向zookeeper注册,提供hbase regionserver状态信息(是否在线)。
2、hmaster启动时候会将hbase系统表-ROOT-加载到zookeeper cluster,通过zookeeper cluster可以获取当前系统表.META.的存储所对应的regionserver信息。
zookeeper是hbase集群的”协调器”。由于zookeeper的轻量级特性,因此我们可以将多个hbase集群共用一个zookeeper集群,以节约大量的服务器。多个hbase集群共用zookeeper集群的方法是使用同一组ip,修改不同hbase集群的”zookeeper.znode.parent”属性,让它们使用不同的根目录。比如cluster1使用/hbase-c1,cluster2使用/hbase-c2,等等。
HMaster主要作用在于,通过HMaster维护系统表-ROOT-,.META.,记录regionserver所对应region变化信息。此外还负责监控处理当前hbase cluster中regionserver状态变化信息。
hbase regionserver则用于多个/单个维护region。
region则对应为hbase数据表的表分区数据维护。
hbase.zookeeper.zookeeperwatcher.java类
ZooKeeper Watcher.One instance of this is instantiated for each Master, RegionServer, and client process.每一个Master、RS和客户端进程都会创建一个zookeeperwatcher的实例。
1、初始化ZooKeeper连接和watcher
①设置节点名称
②ZKUtil.connet
③如果连接成功,则新建一些节点,如ZKUtil.createAndFailSilent(this, baseZNode);如果节点存在,则不再创建。不加watch。此处创建的是持久性节点,并具有open access性。
HBase中的znode
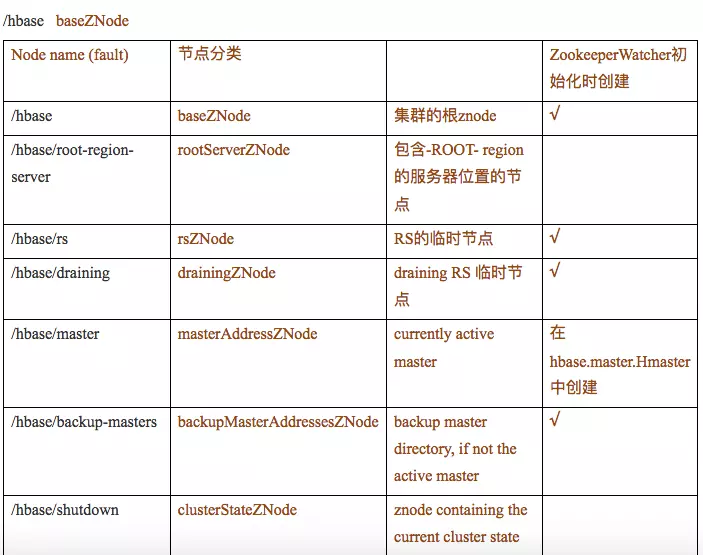
ZooKeeperWatcher的构造函数的作用就是初始化一个ZooKeeper连接并设置watcher。因此在ZookeeperWatcher初始化时创建的节点,表示只要HBase在连接ZooKeeper时就会创建这些节点。
1、/hbase的子节点:
2、HBase中的list命令和/hbase/table下的子节点对比:前者不包括-ROOT-和.META.表:
3、启动HBase时,/hbase/unassigned节点的变化:
ZooKeeperListener.java
packageorg.apache.hadoop.hbase.zookeeper;
抽象类,实现HBase内部ZooKeeper事件的监听。ZooKeeperWatcher会执行适当的方法来实现该类。为了从watcher接收到事件,每个监听者必须要通过ZooKeeperWatcher注册。子类需要重写需要的方法。值得注意的是监听者的watcher在执行这些方法时会引起阻塞,因此不能长期运行这些方法。
在构造函数中就初始化了一个ZooKeeperWatcher。
监听的事件包括nodeCreated(String path)、nodeDeleted(String path)、nodeDataChanged(String path)、nodeChildrenChanged(String path)。
ActiveMasterManager.java
作用:处理所有master方面的master选举的事务。监听并回应master znode的zookeeper通知,包括nodeCreated(节点创建)和nodeDeleted(节点删除)。
包含阻断方法,备master等待主master失败。?
在HMaster构造函数的blockUntilBecomingActiveMaster方法中实例化该类。
实现了抽象类ZooKeeperListener中的nodeCreated(节点创建)和nodeDeleted(节点删除)方法。
HA 方式安装部署才是最常见的生产环境上的安装部署方式。Hadoop HA 是 Hadoop 2.x 中新添加的特性,包括 NameNode HA 和 ResourceManager HA。
因为 DataNode 和 NodeManager 本身就是被设计为高可用的,所以不用对他们进行特殊的高可用处理。
ookeeper 保证高可用的原理。
Zookeeper 集群能够保证 NamaNode 服务高可用的原理是:Hadoop 集群中有两个 NameNode 服务,两个NaameNode都定时地给 Zookeeper 发送心跳,告诉 Zookeeper 我还活着,可以提供服务,单某一个时间只有一个是 Action 状态,另外一个是 Standby 状态,一旦 Zookeeper 检测不到 Action NameNode 发送来的心跳后,就切换到 Standby 状态的 NameNode 上,将它设置为 Action 状态,所以集群中总有一个可用的 NameNode,达到了 NameNode 的高可用目的。
Zookeeper 的选举机制。
Zookeeper 集群也能保证自身的高可用,保证自身高可用的原理是,Zookeeper 集群中的各个机器分为 Leader 和 Follower 两个角色,写入数据时,要先写入Leader,Leader 同意写入后,再通知 Follower 写入。客户端读取数时,因为数据都是一样的,可以从任意一台机器上读取数据。
这里 Leader 角色就存在单点故障的隐患,高可用就是解决单点故障隐患的。
Zookeeper 从机制上解决了 Leader 的单点故障问题,Leader 是哪一台机器是不固定的,Leader 是选举出来的。
选举流程是,集群中任何一台机器发现集群中没有 Leader 时,就推荐自己为 Leader,其他机器来同意,当超过一半数的机器同意它为 Leader 时,选举结束,所以 Zookeeper 集群中的机器数据必须是奇数。
这样就算当 Leader 机器宕机后,会很快选举出新的 Leader,保证了 Zookeeper 集群本身的高可用。
写入高可用。
集群中的写入操作都是先通知 Leader,Leader 再通知 Follower 写入,实际上当超过一半的机器写入成功后,就认为写入成功了,所以就算有些机器宕机,写入也是成功的。
读取高可用。
zookeeperk 客户端读取数据时,可以读取集群中的任何一个机器。所以部分机器的宕机并不影响读取。
zookeeper 服务器必须是奇数台,因为 zookeeper 有选举制度,角色有:领导者、跟随者、观察者,选举的目的是保证集群中数据的一致性。
HDFS HA原理
单 NameNode 的缺陷存在单点故障的问题,如果 NameNode 不可用,则会导致整个 HDFS 文件系统不可用。
所以需要设计高可用的 HDFS(Hadoop HA)来解决 NameNode 单点故障的问题。解决的方法是在 HDFS 集群中设置多个 NameNode 节点。
但是一旦引入多个 NameNode,就有一些问题需要解决。
HDFS HA 需要保证的四个问题:
保证 NameNode 内存中元数据数据一致,并保证编辑日志文件的安全性。
多个 NameNode 如何协作
客户端如何能正确地访问到可用的那个 NameNode。
怎么保证任意时刻只能有一个 NameNode 处于对外服务状态。
解决方法
对于保证 NameNode 元数据的一致性和编辑日志的安全性,采用 Zookeeper 来存储编辑日志文件。
两个 NameNode 一个是 Active 状态的,一个是 Standby 状态的,一个时间点只能有一个 Active 状态的NameNode 提供服务,两个 NameNode 上存储的元数据是实时同步的,当 Active 的 NameNode 出现问题时,通过 Zookeeper 实时切换到 Standby 的 NameNode 上,并将 Standby 改为 Active 状态。
客户端通过连接一个 Zookeeper 的代理来确定当时哪个 NameNode 处于服务状态。
HDFS HA 架构中有两台 NameNode 节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
元数据文件有两个文件:fsimage 和 edits,备份元数据就是备份这两个文件。JournalNode 用来实时从 Active NameNode 上拷贝 edits 文件,JournalNode 有三台也是为了实现高可用。
Standby NameNode 不对外提供元数据的访问,它从 Active NameNode 上拷贝 fsimage 文件,从 JournalNode 上拷贝 edits 文件,然后负责合并 fsimage 和 edits 文件,相当于 SecondaryNameNode 的作用。
最终目的是保证 Standby NameNode 上的元数据信息和 Active NameNode 上的元数据信息一致,以实现热备份。
Zookeeper 来保证在 Active NameNode 失效时及时将 Standby NameNode 修改为 Active 状态。
ZKFC(失效检测控制)是 Hadoop 里的一个 Zookeeper 客户端,在每一个 NameNode 节点上都启动一个 ZKFC 进程,来监控 NameNode 的状态,并把 NameNode 的状态信息汇报给 Zookeeper 集群,其实就是在 Zookeeper 上创建了一个 Znode 节点,节点里保存了 NameNode 状态信息。
当 NameNode 失效后,ZKFC 检测到报告给 Zookeeper,Zookeeper把对应的 Znode 删除掉,Standby ZKFC 发现没有 Active 状态的 NameNode 时,就会用 shell 命令将自己监控的 NameNode 改为 Active 状态,并修改 Znode 上的数据。Znode 是个临时的节点,临时节点特征是客户端的连接断了后就会把 znode 删除,所以当 ZKFC 失效时,也会导致切换 NameNode。
DataNode 会将心跳信息和 Block 汇报信息同时发给两台 NameNode, DataNode 只接受 Active NameNode 发来的文件读写操作指令。
Hadoop2.4 版本之前,ResourceManager 也存在单点故障的问题,也需要实现HA来保证 ResourceManger 的高可也用性。
ResouceManager 从记录着当前集群的资源分配情况和 JOB 的运行状态,YRAN HA 利用 Zookeeper 等共享存储介质来存储这些信息来达到高可用。另外利用 Zookeeper 来实现 ResourceManager 自动故障转移。
MasterHADaemon:控制RM的 Master的启动和停止,和RM运行在一个进程中,可以接收外部RPC命令。
共享存储:Active Master将信息写入共享存储,Standby Master读取共享存储信息以保持和Active Master同步。
ZKFailoverController:基于 Zookeeper 实现的切换控制器,由 ActiveStandbyElector 和 HealthMonitor 组成,ActiveStandbyElector 负责与 Zookeeper 交互,判断所管理的 Master 是进入 Active 还是 Standby;HealthMonitor负责监控Master的活动健康情况,是个监视器。
Zookeeper:核心功能是维护一把全局锁控制整个集群上只有一个 Active的ResourceManager。
