log
近日,有幸拜读《日志管理与分析权威指南》一书,本书由三位业界资深安全专家编著,从日志的基本概念开始,由浅入深讲述了整个日志生命周期的详细过程,从日志的概念、数据概念、人工分析日志、以及日志与合规的依从性、自动化分析日志引申到SIEM日志管理。而其一作者Anton A.Chuvakin博士是日志管理、SIEM和PCI DSS依从性领域公认的安全专家,他的博客www.securitywarrior.org是该领域中最受欢迎的博客之一
日志数据
简单地说,日志消息就是计算机系统、设备、软件等在某种触发下反应生成的东西。确切的触发在很大程度上取决于日志消息的来源。例如,UNix操作系统会记录用户登录和注销的消息,防火墙将记录ACL通过和拒绝的消息,磁盘存储系统在故障发生或者在某些系统认为将会发生故障的情况下会生成日志消息。
日志数据就是一条日志消息里用来告诉你为什么生成消息的信息,例如,web服务器一般会在有人访问web页面请求资源(图片、文件等等)的时候记录日志。如果用户访问的页面需要通过认证,日志消息将会包含用户名。天天好彩
日志消息可以分成下面的几种通用类型:
信息:这种类型的消息被设计成告诉用户和管理员一些没有风险的事情发生了。例如,Cisco IOS将在系统重启的时候生成消息。不过,需要注意的是,如果重启发生在非正常维护时间或是业务时间,就有发出报警的理由。
调试:软件系统在应用程序代码运行时发生调试信息,是为了给软件开发人员提供故障检测和定位问题的帮助。
警告:警告消息是在系统需要或者丢失东西,而又不影响操作系统的情况下发生的。
错误:错误日志消息是用来传达在计算机系统中出现的各种级别的错误。例如,操作系统在无法同步缓冲区到磁盘的时候会生成错误信息。
警报:警报表明发生了一些有趣的事,一般情况下,警报是属于安全设备和安全相关系统的,但并不是硬性规定。在计算机网络中可能会运行一个入侵防御系统IPS,检查所有入站的流量。它将根据数据包的内容判断是否允许其进行网络连接。如果IPS检测到一个恶意连接,可能会采取任何预先配置的处置。IPS会记录下检测结果以及所采取的行动。
02
日志数据的传输与收集
计算机或者其他设备都实现了日志记录子系统,能够在确定有必要的时候生成日志消息,具体的确定方式取决于设备。另外,必须有一个用来接收和收集日志消息的地方,这个地方一般被称为日志主机。日志主机是一个计算机系统,一般来说可能是linux和windows服务器系统,它是集中收集日志消息的地方。使用集中日志收集器的优点如下:
可以集中存储从多个地方得到的日志消息。
可以在上面备份你的日志。
可以在上面进行日志数据的分析。
那么,日志消息如何传输?最常见的方法是通过syslog协议。syslog协议是日志消息交换的一种标准。常见于Linux系统中,也使用在windows平台上。syslog基本上都实现了客户端和服务端组件,两者之间通过用户数据报协议(UDP)通信,但是为了可靠传输,很多开源和商业syslog实现同样也支持传输控制协议(TCP)。
syslog并不是传输和收集日志数据的唯一机制。例如,微软为windows开发了自己的日志记录系统,称为windows事件日志。用户登录注销,应用程序消息等都以专有的格式存储。有开源和商业的应用程序用来将windows事件日志转换成syslog的格式,以发送给syslog服务器。
简单网络管理协议(SNMP)是一种用来管理网络设备的基于标准的协议。
数据库已经变成了应用程序存储日志消息的简便途径。应用程序可以将它的日志消息写进数据库模式,而不是生成一条syslog消息。在某些情况下,syslog服务器本身也可以直接写入关系型数据库,特别是在结构化存储、分析和报告日志消息的情况下有着极大的优势。
最后,也有一些专有的日志记录格式。第三方设备和应用程序实现了用于生成和检索日志消息的专有机制。在这个领域,供应商可能以C或者java类库的形式给你提供应用编程接口(API),或者由你自行实现协议。可将windows事件日志看作一种专有格式,但时常人们将其看作非官方日志记录标准,类似syslog,因此这种方式很流行。
syslog:基于UDP的客户端/服务器协议。这是最常见和普遍的日志记录机制。
SNMP:SNMP最初是为了管理网络中的设备而创造的,然而多年来许多非网络系统已采用SNMP作为发出日志消息和其他状态类型数据的方式。
windows事件日志:微软的专有日志记录格式。
数据库:以结构化的方式来存储和检索日志消息。
常用的专有协议:
LEA:日志提取API是Checkpoint用于从它的防火墙和安全产品线收集日志的API。
SDEE:安全设备事件交换是思科用于从它的IPS设备产品线收集日志消息的基于可扩展标记语言的协议。
E-Streamer:E-Streamer是Sourcefire公司为其IPS开发的专有协议。
选用以syslog方式采集日志数据非常方便,且具有下述原因:
第一,Syslog协议广泛应用在编程上,许多日志函数都已采纳syslog协议,syslog用于许多保护措施中。可以通过它记录任何事件。通过系统调用记录用户自行开发的应用程序的运行状况。研究和开发一些系统程序是日志系统的重点之一,例如网络设备日志功能将网络应用程序的重要行为向 syslog接口呼叫并记录为日志,大部分内部系统工具(如邮件和打印系统)都是如此生成信息的,许多新增的程序(如tcpwrappers和SSH)也是如此工作的。通过syslogd(负责大部分系统事件的守护进程),将系统事件可以写到一个文件或设备中,或给用户发送一个信息。它能记录本地事件或通过网络记录到远端设备上的事件。
第二,当今网络设备普遍支持syslog协议。几乎所有的网络设备都可以通过syslog协议,将日志信息以用户数据报协议(UDP)方式传送到远端服务器,远端接收日志服务器必须通过syslogd监听UDP 端口514,并根据syslog.conf配置文件中的配置处理本机,接收访问系统的日志信息,把指定的事件写入特定文件中,供后台数据库管理和响应之用。意味着可以让任何事件都登录到一台或多台服务器上,以备后台数据库用off-line(离线) 方法分析远端设备的事件。
第三,Syslog协议和进程的最基本原则就是简单,在协议的发送者和接收者之间不要求严格的相互协调。事实上,syslog信息的传递可以在接收器没有被配置甚至没有接收器的情况下开始。反之,在没有清晰配置或定义的情况下,接收器也可以接收到信息。
03
日志来源
日志来源主要分为两类:
基于“推”
基于“拉”
对于基于“推”的日志来源,设备或者应用程序向本地磁盘或者通过网络发出消息。如果通过网络,你必须配备一个日志收集器来接收消息。3种主要的基于“推”来源是syslog、SNMP和windows事件日志。日志消息通过这些协议传输。从技术上说,windows事件日志包含协议、传输机制、存储和读取。
对于基于“拉”的日志来源,应用程序从来源拉取日志消息。这种方法几乎总是依赖客户-服务器模型。以这种方式运行的系统通常以专有格式保存日志数据。例如,Checkpoint提供OPSEC C程序库,开发人员可以用它编写应用程序,拉取Checkpoint防火墙日志。其他产品使用MSSQL、Qracle、Mysql等数据库存储数据。从数据库拉取日志稍微容易一些,可以用脚本或程序完成。
上面提到的三种最常见的日志来源协议,首先是syslog。
syslog最初是用于收集调试信息的,因此,它对于安全日志分析有一些限制,不是最优的,尽管如此,syslog已经成为了基于Linux的系统中记录应用程序事件的最常用方法。
SNMP设计用于满足网络管理员不断增长的需求。SNMP几乎集成到所有你能想到的网络中,包括许多网络安全设备。SNMP是查询和配置设备的一种协议。虽然SNMP协议整体来说不是一个日志记录系统,但是可以看作日志消息的类型。虽然许多网络设备能够通过syslog发送事件消息,但是有些设备不能,特别是旧设备,因此SNMP是从设备获得其他途径不能收集的事件信息的一种方式。
Microsoft在很久以前就决定要创造自己的日志生成和收集系统。这一系统被称作事件日志。现在的事件日志有一些高级特性。事件日志主要用于收集和查看两类日志:
Windows日志
应用程序日志
Windows日志至少包括应用程序、安全和系统。最重要的是安全日志,登录、注销、资源访问记录的地方。
一、系统日志:
记录系统中硬件、软件和系统问题的信息,同时还可以监视系统中发生的事件。系统日志包括系统日志、应用程序日志和安全日志。
二、网站日志:
1.记录web服务器接收处理请求以及运行时错误等各种原始信息以.log结尾的文件。我们通过对日志进行统计、分析、综合,就能有效地掌握网站运行状况,发现和排除错误原因,了解客户访问分布等,更好的加强系统的维护和管理。
2.日志也是了解搜索引擎工作原理和搜索引擎对网页抓取频率的最佳途径。通过这个文件,可以了解搜索引擎什么时间、抓取了哪些页面,以及可以知道是主搜索蜘蛛还是从搜索蜘蛛抓取了您的网站等的信息。
3.通过不同的log日志级别来记录以往的操作行为,可以很轻易地分析得到:
4.通过分析网站日志Log文件我们可以看到用户、搜索引擎蜘蛛访问网站和管理人员操作的行为数据,这些数据能让我们分析出用户和蜘蛛对网站的偏好以及网站安全操作及健康情况。因此在网站日志分析中,我们主要需要分析的是蜘蛛行为和操作行为。
5.在分析日志时,对于单日日志文件我们需要分析的内容有:访问次数、停留时间、抓取量、目录抓取统计、页面抓取统计、蜘蛛访问IP、HTTP状态码、蜘蛛活跃时段、蜘蛛爬取路径等;对于多日日志文件我们需要分析的内容有:蜘蛛访问次数趋势、停留时间趋势、整体抓取趋势、各目录抓取趋势、抓取时间段、蜘蛛活跃周期等。
网站日志数据分析解读:
1、访问次数、停留时间、抓取量
从这三项数据中我们可以得知:平均每次抓取页面数、单页抓取停留时间和平均每次停留时间。
平均每次抓取页面数=总抓取量/访问次数
单页抓取停留=每次停留/每次抓取
平均每次停留时间=总停留时间/访问次数
从这些数据我们可以看出蜘蛛的活跃程度、亲和程度、抓取深度等,总访问次数、停留时间、抓取量越高、平均抓取页面、平均停留时间,表明网站页面越受搜索引擎喜欢。而单页抓取停留时间表明网站页面访问速度,时间越长,表明网站访问速度越慢,对搜索引擎抓取收录较不利,我们应尽量提高网页加载速度,减少单而立停留时间,让爬虫资源更多的去抓取收录。
2、目录抓取统计
通过日志分析我们可以看到网站哪些目录受蜘蛛喜欢、抓取目录深度、重要页面目录抓取状况、无效页面目录抓取状况等。对于重要目录,我们需要通过内外调整增加权重及爬取;对于无效页面,在robots.txt中进行屏蔽。
3、访问状态码
蜘蛛经常出现的状态码如301、404等,出现这些状态码要及时处理,以避免对网站造成坏的影响。
4、蜘蛛爬取路径
在网站日志中我们可以跟踪到特定IP的访问路径,则能发现对于本网站结构下蜘蛛的爬取路径偏好。由此,我们可以适当的引导蜘蛛的爬取路径,让蜘蛛更多的爬取重要、有价值、新更新页面。其中爬取路径中我们可以分析页面物理结构路径偏好以及url逻辑结构爬取偏好。
04
日志存储技术
日志的存储和快速检索分析是企业中的一个关键问题。中小企业保存的日志记录会很快地增长到TB或PB级。这些数据在企业中会以各种不同的格式存储。
开发自己的日志保存策略时,应该审视以下各项:
1)评估适用的依从性需求:
在当今的许多行业中,诞生了一大批健全的依从性需求。这方面的例子包括支付卡行业数据安全标准(PCI DSS)。它规定了非常具体的日志保存周期–1年。PCI DSS涉及到日志需求的内容我在《日志管理与分析(二)》中会涉及到。
2)评估企业的风险态势:
内部和外部的风险驱动网络不同部分的保存周期。对企业来说,每个风险领域的时间长度以及日志的重要性可能有很大的不同。如果你的日志主要用于内部威胁调查,则需要较长的保存周期。因为事故常常是多年都未曾发现的。
3)关注各种日志来源和生成日志的大小:
防火墙、服务器、数据库、web代理服务,不仅基于需要,也基于典型日志体积及每个日志记录的大小和类型。各种设备或应用程序生成的日志体积有很大的不同,例如,主防火墙会生成大量的日志内容,因此为了满足此数据的长期保存需求,通常只存储30天的日志。然而,应该仔细评估某些企业的依从性需求以及主防火墙的关键程度,决定是否采用更长的保存周期。
4)评估可用的存储选项:
日志存储选项包括硬盘、DVD、WORM、磁带、RDBMS、日志特定存储,以及基于云的存储。这方面的决策主要取决于价格、容量、访问速度,最重要的是以合理的周期得到正确日志记录的能力。
企业中的日志保存的时间和空间需求是压倒一切的第一需求。
4.1日志存储格式
我们的网络设备、应用程序以及操作系统产生多种不同的日志格式,在许多情况下,日志会被存储为基于文本、二进制或者压缩的格式。
4.1.1 基于文本的日志文件
基于文本的日志记录是目前最丰富的日志类型,这归功于生成这类日志时较低的系统成本,以及现有的许多计算机语言中包含了可以很轻松地生成基于文本日志的框架。许多流行的系统采用了基于文本的日志文件格式,因为这种格式有着许多的优点:
应用程序写入基于文本的日志文件,从CPU以及I/O资源来说代价很低。
文本格式是典型可读格式,可用常规文本工具(如grep和awk,都是各种lunix操作系统变种的固有工具)处理和查阅。
许多常见的基于文本的日志格式已经存在,例如syslog。使得运营和安全团队易于使用一种通用方法来集中化以及解析日志,创造一个更完善的日志管理系统。
1)扁平文本文件
扁平文本文件在许多方面上是一个扁平的无模式文件,可能遵循某种常见模式或自由格式。系统通常会创建一个新日志文件,并持续向其追加写入,直到磁盘空间不足或某个系统进程指示系统开始一个新日志文件并将当前文件存档。这种格式倾向于以时间先后排序,最早发生的事件位于文件开始处,最近发生的事件位于文件末尾。
许多系统采用的较常用格式之一是syslog格式。我们知道,许多服务器配置为使用syslog的514端口,通过用户数据报协议UDP或传输控制协议TCP发送自己的日志数据。通过syslog发送的日志在发送之前保存在磁盘上,具有非常简单的特殊格式。
使用扁平文本文件长期存储日志数据的显著优势之一是,可以使用大量工具来阅读和审核这种格式的数据。每个平台都有许多工具可以轻松访问和读取此类格式的文件。如果你在未来5、7或10年需要去阅读或审核数据,需要能够处理和关联事件记录的工具,这一点就变得非常重要。
2)索引扁平文本文件
企业在扁平文本文件上很快就会遇到的一个局限性是从扁平文本文件中快速查询、排序、检索关键元素。随着日志文件迅速增至GB、TB甚至PB级别,再使用传统的grep、awk和基于文本的搜索工具会让人失去耐心,变成一个极其耗时的过程。
索引文本文件是一种从日志文件中企业数据的方式,它使日志的关键元素能被快速查询。许多企业可能再企业成长和开始集中日志信息时,很快发现需要结构来生成报表,以及在超出保存周期时销毁日志数据,从而开始采用索引文本日志文件。索引文本文件具备扁平文本文件的许多优点,具备快速数据插入能力,并保持人类可读的数据格式。
索引文本日志文件的一个例子-OSSEC
/var/ossec/logs/alerts/2011
/var/ossec/logs/alerts/2011/jan
/var/ossec/logs/alerts/2011/feb
/var/ossec/logs/alerts/2011/mar
…
4.1.2 二进制文件
顾名思义,二进制日志文件是应用程序生成的极其可读日志文件,需要专有的工具或程序去阅读或处理他们,在各种环境中较常见的二进制日志文件的例子包括Micromoft Internet信息服务(IIS)日志以及windows事件日志。在使用大型主机或定制应用程序的许多环境下,日志文件也可能被编码为二进制或机器特定格式,如广义二进制编码的十进制交换码,在Intel和PC硬件平台需要工具去解码和阅读他们。
二进制日志文件的长期存储会给企业带来许多挑战,在存储和保存二进制日志文件的原生格式之前需要考虑的问题如下:
未来5、7甚至10年后阅读这些日志的工具的可用性。从现在开始的10年内,保留一台windows NT服务器来阅读遗留的iis6.0web服务器日志,并进行确证分析,几乎是不可能的。
二进制日志文件在磁盘空间利用上很高效,然而,无法进行很大的压缩。压缩的二进制文件的大小可能是原生文件的90%。相比之下,基于文本的文件压缩后可能仅占原文件的10%左右。与文本文件日志记录相比,二进制文件所需的存储空间会比较大。
示例:二进制日志的内容如下图所示:
二进制日志中的字段如下:
Event_Type:用来设置数据的操作类型。如Query、Update。
Server_id:服务器的id
Log_name:用来表明该事件保存的二进制日志文件名称
Pos:事件的开始位置
End_log_pos:事件的结束位置
info:事件信息的可读文本
关于更多二进制文件的了解,可以参考:
https://www.cnblogs.com/youzhongmin/p/9575167.html
4.1.3 压缩文件
大部分生成日志的系统一般会在日志增长到指定大小时,或者在每天、每周、每月配置的时间周期以及其他条件下开始一个新的日志文件。之前的日志文件通常会重命名,并以未压缩格式存档于系统硬盘中,以便使其易于访问和查询,随着日志文件的老化,某个日志文件与日常报告和日志审核任务的相关性越来越弱,但它对于符合依从性保存周期和执行取证仍然是关键。在许多情况下啊,我们依然期望日志文件能够快速访问,但是在磁盘上占用较小空间。在系统中压缩日志文件就是解决这种需求并节省宝贵磁盘空间的一种机制。
LINUX系统的许多标准工具都有等价的压缩工具集,zgrep和zcat工具可以从压缩文件中读取和检索数据,就像grep和cat在未压缩文件上所做的一样。在选择一个压缩格式时,为了避免陈旧过时,最好选择一种已经被使用很多年并在多个平台可用的格式,在linux中,tar和zip格式已经使用很长时间,而PKZip格式的压缩文件是windows中常见的压缩格式。就像二进制文件一样,我们应该避免未来用于解压和访问日志数据的工具集过时。
4.2日志文件的数据库存储
上面提到了几种存储技术需要直接访问系统和特定的日志审核工具集,这样做是很快速和高效的,但是在许多情况下,我们创建摘要报告、过滤器,以及在多台主机间关联日志数据的能力常常受到严重的限制。许多企业发现将日志信息写入数据库中,这样某种格式的日志信息可以快速搜索和查询,并且便于日志审核过程中前段工具的安装和使用。
优点:
使用数据库来实现日志保存主要的优点之一是易用性,你可以使用标准的SQL查询快速搜索和检索日志记录。数据库系统具有健全的用户访问和权限系统,而且可能已经是企业备份和恢复计划的一部分,现在有许多标准工具可以查询数据库,这些工具允许使用一个通用的工具集来查询日志数据,而不是使用需要专门知识和权限的平台特定工具。
缺点:
将日志数据存入数据库系统并不能避免本身的一些问题和风险,向数据库中写日志消息会有显著的开销。向数据库中写数据明显比写入本地磁盘文本文件慢,主要是因为网络延迟、SQL解析、索引更新以及向磁盘提交信息。使用数据库存储日志对磁盘的空间需求也较高,主要是因为实现快速搜索和检索需要大量索引文件,压缩数据的选项也较为有限。数据库系统在一个企业中往往有多种用途,因此需要面临数据库故障、维护以及为支持日志记录或其他内部系统而升级时的数据丢失风险。当根据保存策略不再需要日志条目时、数据的销毁也会成为问题。若没有合适的规划或分区,删除日志数据可能花费相当长的时间。日志数据一般非常巨大,因此数据的销毁可能需要数据库系统删除数百万甚至数十亿行,并更新所有被删除数据的索引。
4.3 Hadoop日志存储
传统数据库作为日志数据系统面临各种挑战,包括对日志数据增长的可伸缩性和高峰活动时需要的存储和系统容量。与传统数据库系统相比,Hadoop是一个较新的替代方案。传统的数据库系统,利用具备快速SAN存储的高端硬件,支持大量的并发用户和请求,并满足数据存储需求。相比之下,Hadoop系统通常由运行着Linux的商业PC Intel硬件构成,集群的每个节点只有几个TB本地存储空间,且没有使用RAID。一个Hadoop集群由一系列从节点和最少一个主节点组成。这样的系统在需要增加空间和容量时,可以简单地向集群中添加新的节点。
优点:
Hadoop有传统数据库系统的很多优点,Hadoop不用在各个系统上使用平台特定的查询工具,就能对日志数据进行快速检索和搜索。Hadoop通过将搜索请求分布到集群各个节点,快速寻找、处理和检索结果,从而在数据尺寸增长时很好地实现了可伸缩性。Hadoop主要用java构建,可以开发工具、实现日志数据的实时查看和分析。Hadoop同样具备容错性,通过在集群节点间制作多个备份数据,当一个节点出现故障时,数据扔可以从其他节点检索。
缺点:
Hadoop是一个强大的日志存储系统,但是同样存在许多可能影响企业的缺点。现有的许多日志记录工具对Hadoop的直接支持有限,Rsyslog已经添加了向Hadoop集群写入syslog消息的功能,但是对大部分其他日志源来说,依旧需要开发一个向Hadoop写入日志的工具。可以直接在Hadoop中查询和报告数据的工具集依旧非常有限。企业需要开发和维护定制的前端系统,以便进行实时分析和审核。
05
隐蔽日志
常识和各项法规制度迫使我们将工作的重点放在保护日志免于各种攻击上,其实还可以使用一种保护方法就是将日志文件和日志记录基础设施隐藏起来,使试图破坏的攻击者无法看到。加密、基于安全代理的日志收集以及完整性检查是有效的,在攻击者面前隐藏自己的日志记录和日志收集架构有一种独特的吸引力。多年实施“蜜罐”甚至整个蜜罐网络的经验告诉我们,大部分攻击者都没那么幸运,这种掩护下的基础设施是安全技术的一个罕见特例–防御者可能获得优势。
业务攻击者闯入linux或unix系统后,会首先结束syslog守护进程,阻止本地添加新增日志记录和向远程日志服务器传送日志。通过类似“killall syslogd”的命令执行。所以,在这个小公司网络中,系统管理员将编译了syslog守护进程的另一个拷贝,命名为”cachefd”并且用管理员主目录下的配置文件运行。该文件配置为将日志累计到一些非标准的目录下(例如/usr/src/kernel)。这样,能够有效地防止业余攻击者终止日志记录。这种方案取决于公司确实关注日志文件,并且有周期性的日志审核,或者具备准时的日志监控能力。
高级的安全专家可能会嘲笑这种“安全日志记录”,但是在“蜜罐”中观察到的业余攻击者的方法都没有超出结束syslog守护进程,并且从没有寻找其他日志记录机制。因此,以上的措施实际上100%有效。
5.1隐藏日志生成
隐藏日志生成提出了一个挑战,因为生成日志的程序非常可能存在于一个被入侵的信息资产上。通过包捕获采集的日志几乎都是隐藏的,但是生成日志这一环节很难隐蔽起来。
一般来说,有以下两个选择:
完全地隐藏日志记录行为;
隐藏日志记录,并伪造一个日志记录守护进程,满足攻击者的心理。
1. 隐藏日志记录
使用内核能力或linux专用可加载内核模块(LKM)来隐藏守护进程是众所周知的。本质上,当我们谈论日志记录的rootkit技术时,通常有两个额外的选择:
可以隐藏其他运行进程(例如我们的日志记录进程)的单独隐藏模块或者通用隐藏程序。大多数的rootkit都基于这一原理。
专用隐藏登录模块,Honeynet Project的Sebek工具基于此方法。这种方法也就可以隐藏其他程序。
最后要注意一点,如果攻击者采用类似原理的rootkit,他仍然可能干扰我们对日志记录的隐藏。
- 利用误导隐藏日志记录
如果我们运用上述技术,并留下默认的日志记录基础设施,让攻击者去杀死他,大部分攻击者都很可能不在进一步攻击,并认为没有其他的日志机制。
这只需要创建一个单独的syslog实例,并连接到基础设施,保留默认的实例,启用一些功能,使他不会干扰真正的日志记录。
06
简单分析技术
人工阅读日志应该保留,用作地狱中的惩罚。在缺乏好的自动化工具时,人们总是不得不进行人工审核。
为什么需要进行日志分析:
依从性和监管的要求
了解网络条件
基础设施ROI
安全度量
事故响应
6.1简单日志查看器
6.1.1 实时审核
在大部分unix和linux变种上,有多种工具能够辅助日志分析。有些在实时日志查看上有所帮助,而其他则有助于审核历史日志。
从经典工具开始:
tail -f/var/log/messages
上述命令将显示标准linux消息文件的最后几行,以及命令启动之后出现的新行。这是目前最简单的实时日志查看器,但是在大部分情况下没什么用处。如果你所需要的只是在系统日志记录出现时看到他们,这个命令就相当方便。
上述命令可以与grep结合使用:
tail -f/var/log/messages | grep sshd
为了进一步改进上述的实时日志查看,可以加入一个tee命令,它将帮助我们查看数据,并发送到一个文件:
tail -f/var/log/messages | grep sshd | tee file-of-latest-sshd-logs.txt
上述命令显示日志行,并将其记录到”file-of-latest-sshd-logs.txt”文件。
Less可以使用这个命令的等待模式,完成同样的功能:
less/var/log/messages
然后,按下F使less进入”tail”模式,显示最近和最新的数据。
在windows模式下,捆绑的事件查看器可以监控三种日志中新到的记录。
6.1.2历史日志审核
你所选择的平台上的任何文本编辑器都可以用于查看普通文本日志,但是有一点需要注意,有些日志文件非常大,不是所有文本编辑器都能够高效地处理它们。所以需要一个轻量级的工具,另外它还需要具备搜索和其他有用的功能。
在linux上,more和less工具通常符合上述要求。它们能够处理大文件(GB数量级),也有搜索功能。有时候,更多详细的帮助可以用info命令得到,如:
info less
在windows上,唯一的捆绑工具是事件查看器,它能够阅读三种标准的windows日志(应用程序、系统和安全),等待新事件并显示,也可以进行过滤和排序。
Windows 7 事件查看器较为有趣的功能包括:
将单独的事件当做XML处理。
用事件订阅功能,在远程主机上订阅事件。
保存过滤器为自定义视图。
在应用程序日志中记录你的自定义事件。
运行一个任务,对事件作出相应。
6.1.3简单日志操纵
在Linux上用tail和less实时查看日志,并用许多文件查看器(cat、more或者less)查看存储的文件。
使用简单工具的目标:
1)日志过滤:我们只想看到特定的内容。
2)日志重新格式化:修改我们查看的方式。
3)日志总结:查看紧凑的视图。
如上所述,tail和grep结合可以进行简单的过滤,grep还有助于在大的日志文件上进行更为高级的过滤:
grep -ev ‘ssh|telnet’ /var/log/messages
查看除了包含ssh和telnet之外的所有信息。
grep -f patterns /var/log/messages
查看匹配文件’patterns ’中模式的所有消息。
改进grep的其他命令还有tail和head。他们用于查看日志的开头部分和结束部分。
Log Parser和Log ParserLizard:筛查windows日志的最好手段
在windows上,事件查看器可以过滤、排序日志和将日志提取到文件中。在典型的windows系统上,过滤限于:
事件类型
事件分类
事件ID
源计算机
源应用程序或者系统组件名称
用户名称
日期和事件范围
为了进行windows日志的更高级分析,我们可以使用LogParser和Log Parser Lizard。Log Parser是一个MicrosoftWindows插件程序,为你提供一个类似Sql的Windows事件日志接口。LogParser本身就是一个命令行工具,在分析工作中难以使用,这就是Log Parser的用武之地。
6.1.4人工日志审核的局限性
到现在已经很明显,人工和使用简单的工具和命令进行的日志审核无疑在日志分析中占据一席之地。但是不应该依赖它作为日志分析的主要机制。
人工日志审核有明显的局限性:
人工日志审核无法随着日志文件尺寸的增大而伸缩:我们查看了8行日志,但是现实的任务是查看800万行日志。在大规模的企业环境中,日志常常以每秒20000条记录的速度产生。在比这低得多的日志记录速度上,人工日志分析就已经无法继续且变得越来越低效。
人工日志审核只能用于简单的日志:告诉你具体的故障部位时,可以人工解读它,但是在日志来源较为模糊且没有文档时,这种方法必然失败。解读每一行的工作量将从一秒钟的快速思考变成几个小时的在线和其他来源研究。
简单的工具和人工审核可能无法获得计算环境中所发生情况的全貌,而更高级的工具能够从日志数据中还原这些情况。
除了令人困惑和模糊的格式之外,在许多情况下分析需要关联来自多个源的日志。这种活动确实可以人工进行,但是需要的时间将大大增加(与只查看一个日志文件相比)。这种关联最好留给自动工具完成。
最后,这种活动通常极其乏味。而且通常效率很低
每个系统都有日志,当系统出现问题时,需要通过日志解决问题
当系统机器比较少时,登陆到服务器上查看即可满足
当系统机器规模巨大,登陆到机器上查看几乎不现实
当然即使是机器规模不大,一个系统通常也会涉及到多种语言的开发,拿我们公司来说,底层是通过c++开发的,而也业务应用层是通过Python开发的,并且即使是C++也分了很多级别应用,python这边同样也是有多个应用,那么问题来了,每次系统出问题了,如何能够迅速查问题? 好一点的情况可能是python应用层查日志发现是系统底层处理异常了,于是又叫C++同事来查,如果C++这边能够迅速定位出错误告知python层这边还好,如果错误好排查,可能就是各个开发层的都在一起查到底是哪里引起的。当然可能这样说比较笼统,但是却引发了一个问题:
当系统出现问题后,如何根据日志迅速的定位问题出在一个应用层?
在平常的工作中如何根据日志分析出一个请求到系统主要在那个应用层耗时较大?
在平常的工作中如何获取一个请求到达系统后在各个层测日志汇总?
针对以上问题,我们想要实现的一个解决方案是:
把机器上的日志实时收集,统一的存储到中心系统
然后再对这些日志建立索引,通过搜索即可以找到对应日志
通过提供界面友好的web界面,通过web即可以完成日志搜索
关于实现这个系统时可能会面临的问题:
实时日志量非常大,每天几十亿条(虽然现在我们公司的系统还没达到这个级别)
日志准实时收集,延迟控制在分钟级别
能够水平可扩展
关于日志收集系统,业界的解决方案是ELK
ELK的解决方案是通用的一套解决方案,所以不免就会产生以下的几个问题:
运维成本高,每增加一个日志收集,都需要手动修改配置
监控缺失,无法准确获取logstash的状态
无法做定制化开发以及维护
针对这种情况,其实我们想要的系统是agent可以动态的获取某个服务器我们需要监控哪些日志
以及那些日志我们需要收集,并且当我们需要收集日志的服务器下线了,我们可以动态的停止收集
当然这些实现的效果最终也是通过web界面呈现。
日志收集系统设计
主要的架构图为
关于各个组件的说明:
Log Agent,日志收集客户端,用来收集服务器上的日志
Kafka,高吞吐量的分布式队列,linkin开发,apache顶级开源项目
ES,elasticsearch,开源的搜索引擎,提供基于http restful的web接口
Hadoop,分布式计算框架,能够对大量数据进行分布式处理的平台
关于Kakfa的介绍
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
注:这里关于Kafka并不会介绍太多,只是对基本的内容和应用场景的说明,毕竟展开来说,这里的知识也是费非常多的
Kafka中有几个基本的消息术语需要了解:
Kafka将消息以topic为单位进行归纳。
将向Kafka topic发布消息的程序成为producers.
将预订topics并消费消息的程序成为consumer.
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
Kafka的优点:
可靠性 - Kafka是分布式,分区,复制和容错的。
可扩展性 - Kafka消息传递系统轻松缩放,无需停机。
耐用性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。
性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。
Kafka非常快,并保证零停机和零数据丢失。
Kafka的应用场景:
异步处理, 把非关键流程异步化,提高系统的响应时间和健壮性
应用解耦,通过消息队列
流量削峰
关于ZooKeeper介绍
ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
Apache ZooKeeper是由集群(节点组)使用的一种服务,用于在自身之间协调,并通过稳健的同步技术维护共享数据。ZooKeeper本身是一个分布式应用程序,为写入分布式应用程序提供服务。
ZooKeeper主要包含几下几个组件:
Client(客户端):我们的分布式应用集群中的一个节点,从服务器访问信息。对于特定的时间间隔,每个客户端向服务器发送消息以使服务器知道客户端是活跃的。类似地,当客户端连接时,服务器发送确认码。如果连接的服务器没有响应,客户端会自动将消息重定向到另一个服务器。
Server(服务器):服务器,我们的ZooKeeper总体中的一个节点,为客户端提供所有的服务。向客户端发送确认码以告知服务器是活跃的。
Ensemble:ZooKeeper服务器组。形成ensemble所需的最小节点数为3。
Leader: 服务器节点,如果任何连接的节点失败,则执行自动恢复。Leader在服务启动时被选举。
Follower:跟随leader指令的服务器节点。
ZooKeeper的应用场景:
服务注册&服务发现
配置中心
分布式锁
Zookeeper是强一致的多个客户端同时在Zookeeper上创建相同znode,只有一个创建成功
关于Log Agent
这个就是我们后面要通过代码实现的一步分内容,主要实现的功能是:
类似于我们在linux下通过tail的方法读日志文件,讲读取的内容发给Kafka
这里需要知道的是,我们这里的tailf是可以动态变化的,当配置文件发生变化是,可以通知我们程序自动增加需要增加的tailf去获取相应的日志并发给kafka producer
主要由一下几部目录组成:
Kafka
tailf
configlog
小结
以上是对整个要开发的系统的一个总的概括,以及架构的一个构建,并且各个组件的实现,接下来会一个一个实现每个部分的功能,下一篇文章会实现上述组件中log Agent的开发
关于zookeeper+kafka
我们需要先把两者启动,先启动zookeeper,再启动kafka
启动ZooKeeper:./bin/zkServer.sh start
启动kafka:./bin/kafka-server-start.sh ./config/server.properties
操作kafka需要安装一个包:go get github.com/Shopify/sarama
写一个简单的代码,通过go调用往kafka里扔数据:
复制代码
package main
import (
“github.com/Shopify/sarama”
“fmt”
)
func main() {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
msg := &sarama.ProducerMessage{}
msg.Topic = “nginx_log”
msg.Value = sarama.StringEncoder(“this is a good test,my message is zhaofan”)
client,err := sarama.NewSyncProducer([]string{“192.168.0.118:9092”},config)
if err != nil{
fmt.Println(“producer close err:”,err)
return
}
defer client.Close()
pid,offset,err := client.SendMessage(msg)
if err != nil{
fmt.Println("send message failed,",err)
return
}
fmt.Printf("pid:%v offset:%v\n",pid,offset) } 复制代码 config.Producer.RequiredAcks = sarama.WaitForAll 这里表示是在给kafka扔数据的时候是否需要确认收到kafka的ack消息
msg.Topic = “nginx_log” 因为kafka是一个分布式系统,假如我们要读的是nginx日志,apache日志,我们可以根据topic做区分,同时也是我们也可以有不同的分区
我们将上述代码执行一下,就会往kafka中扔一条消息,可以通过kakfa中自带的消费者命令查看:
./bin/kafka-console-consumer.sh –zookeeper localhost:2181 –topic nginx_log –from-beginning
我们可以将最后的代码稍微更改一下,更改为循环发送:
复制代码
for{
pid,offset,err := client.SendMessage(msg)
if err != nil{
fmt.Println(“send message failed,”,err)
return
}
fmt.Printf(“pid:%v offset:%v\n”,pid,offset)
time.Sleep(2*time.Second)
}
复制代码
这样当我们再次执行的程序的时候,我们可以看到客户端在不停的消费到数据:
这样我们就实现一个kakfa的生产者的简单的demo
接下来我们还需要知道一个工具的使用tailf
tailf
我们的agent需要读日志目录下的日志文件,而日志文件是不停的增加并且切换文件的,所以我们就需要借助于tailf这个包来读文件,当然这里的tailf和linux里的tail -f命令虽然不同,但是效果是差不多的,都是为了获取日志文件新增加的内容。
而我们的客户端非常重要的一个地方就是要读日志文件并且将读到的日志文件推送到kafka
这里需要我们下载一个包:go get github.com/hpcloud/tail
我们通过下面一个例子对这个包进行一个基本的使用,更详细的api说明看:https://godoc.org/github.com/hpcloud/tail
复制代码
package main
import (
“github.com/hpcloud/tail”
“fmt”
“time”
)
func main() {
filename := “/Users/zhaofan/go_project/src/go_dev/13/tailf/my.log”
tails,err := tail.TailFile(filename,tail.Config{
ReOpen:true,
Follow:true,
Location:&tail.SeekInfo{Offset:0,Whence:2},
MustExist:false,
Poll:true,
})
if err !=nil{
fmt.Println("tail file err:",err)
return
}
var msg *tail.Line
var ok bool
for true{
msg,ok = <-tails.Lines
if !ok{
fmt.Printf("tail file close reopen,filenam:%s\n",tails,filename)
time.Sleep(100*time.Millisecond)
continue
}
fmt.Println("msg:",msg.Text)
} } 复制代码 最终实现的效果是当你文件里面添加内容后,就可以不断的读取文件中的内容
日志库的使用
这里是通过beego的日志库实现的,beego的日志库是可以单独拿出来用的,还是非常方便的,使用例子如下:
复制代码
package main
import (
“github.com/astaxie/beego/logs”
“encoding/json”
“fmt”
)
func main() {
config := make(map[string]interface{})
config[“filename”] = “/Users/zhaofan/go_project/src/go_dev/13/log/logcollect.log”
config[“level”] = logs.LevelTrace
configStr,err := json.Marshal(config)
if err != nil{
fmt.Println(“marshal failed,err:”,err)
return
}
logs.SetLogger(logs.AdapterFile,string(configStr))
logs.Debug(“this is a debug,my name is %s”,”stu01”)
logs.Info(“this is a info,my name is %s”,”stu02”)
logs.Trace(“this is trace my name is %s”,”stu03”)
logs.Warn(“this is a warn my name is %s”,”stu04”)
}
复制代码
简单版本logagent的实现
这里主要是先实现核心的功能,后续再做优化和改进,主要实现能够根据配置文件中配置的日志路径去读取日志并将读取的实时推送到kafka消息队列中
关于logagent的主要结构如下:
程序目录结构为:
复制代码
├── conf
│ └── app.conf
├── config.go
├── kafka.go
├── logs
│ └── logcollect.log
├── main.go
└── server.go
复制代码
app.conf :配置文件
config.go:用于初始化读取配置文件中的内容,这里的配置文件加载是通过之前自己实现的配置文件热加载包处理的,博客地址:http://www.cnblogs.com/zhaof/p/8593204.html
logcollect.log:日志文件
kafka.go:对kafka的操作,包括初始化kafka连接,以及给kafka发送消息
server.go:主要是tail 的相关操作,用于去读日志文件并将内容放到channel中
所以这里我们主要的代码逻辑或者重要的代码逻辑就是kafka.go 以及server.go
kafka.go代码内容为:
复制代码
// 这里主要是kafak的相关操作,包括了kafka的初始化,以及发送消息的操作
package main
import (
“github.com/Shopify/sarama”
“github.com/astaxie/beego/logs”
)
var (
client sarama.SyncProducer
kafkaSender *KafkaSender
)
type KafkaSender struct {
client sarama.SyncProducer
lineChan chan string
}
// 初始化kafka
func NewKafkaSender(kafkaAddr string)(kafka *KafkaSender,err error){
kafka = &KafkaSender{
lineChan:make(chan string,100000),
}
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
client,err := sarama.NewSyncProducer([]string{kafkaAddr},config)
if err != nil{
logs.Error("init kafka client failed,err:%v\n",err)
return
}
kafka.client = client
for i:=0;i<appConfig.KafkaThreadNum;i++{
// 根据配置文件循环开启线程去发消息到kafka
go kafka.sendToKafka()
}
return }
func initKafka()(err error){
kafkaSender,err = NewKafkaSender(appConfig.kafkaAddr)
return
}
func (k *KafkaSender) sendToKafka(){
//从channel中读取日志内容放到kafka消息队列中
for v := range k.lineChan{
msg := &sarama.ProducerMessage{}
msg.Topic = “nginx_log”
msg.Value = sarama.StringEncoder(v)
,,err := k.client.SendMessage(msg)
if err != nil{
logs.Error(“send message to kafka failed,err:%v”,err)
}
}
}
func (k *KafkaSender) addMessage(line string)(err error){
//我们通过tailf读取的日志文件内容先放到channel里面
k.lineChan <- line
return
}
复制代码
server.go的代码为:
复制代码
package main
import (
“github.com/hpcloud/tail”
“fmt”
“sync”
“github.com/astaxie/beego/logs”
“strings”
)
type TailMgr struct {
//因为我们的agent可能是读取多个日志文件,这里通过存储为一个map
tailObjMap map[string]*TailObj
lock sync.Mutex
}
type TailObj struct {
//这里是每个读取日志文件的对象
tail *tail.Tail
offset int64 //记录当前位置
filename string
}
var tailMgr *TailMgr
var waitGroup sync.WaitGroup
func NewTailMgr()(TailMgr){
tailMgr = &TailMgr{
tailObjMap:make(map[string]TailObj,16),
}
return tailMgr
}
func (t *TailMgr) AddLogFile(filename string)(err error){
t.lock.Lock()
defer t.lock.Unlock()
_,ok := t.tailObjMap[filename]
if ok{
err = fmt.Errorf(“duplicate filename:%s\n”,filename)
return
}
tail,err := tail.TailFile(filename,tail.Config{
ReOpen:true,
Follow:true,
Location:&tail.SeekInfo{Offset:0,Whence:2},
MustExist:false,
Poll:true,
})
tailobj := &TailObj{
filename:filename,
offset:0,
tail:tail,
}
t.tailObjMap[filename] = tailobj
return }
func (t *TailMgr) Process(){
//开启线程去读日志文件
for _, tailObj := range t.tailObjMap{
waitGroup.Add(1)
go tailObj.readLog()
}
}
func (t *TailObj) readLog(){
//读取每行日志内容
for line := range t.tail.Lines{
if line.Err != nil {
logs.Error(“read line failed,err:%v”,line.Err)
continue
}
str := strings.TrimSpace(line.Text)
if len(str)==0 || str[0] == ‘\n’{
continue
}
kafkaSender.addMessage(line.Text)
}
waitGroup.Done() }
func RunServer(){
tailMgr = NewTailMgr()
// 这一部分是要调用tailf读日志文件推送到kafka中
for _, filename := range appConfig.LogFiles{
err := tailMgr.AddLogFile(filename)
if err != nil{
logs.Error(“add log file failed,err:%v”,err)
continue
}
}
tailMgr.Process()
waitGroup.Wait() } 复制代码 可以整体演示一下代码实现的效果,当我们运行程序之后我配置文件配置的目录为: log_files=/app/log/a.log,/Users/zhaofan/a.log 我通过一个简单的代码对对a.log循环追加内容,你可以从kafka的客户端消费力看到内容了:
完成的代码地址:https://github.com/pythonsite/logagent
小结
这次只是实现logagent的核心功能,实现了从日志文件中通过多个线程获取要读的日志内容,这里借助了tailf,并将获取的内容放到channel中,kafka.go会从channel中取出日志内容并放到kafka的消息队列中
这里并没有做很多细致的处理,下一篇文章会在这个代码的基础上进行改进。同时现在的配置文件的方式也不是最佳的,每次改动配置文件都需要重新启动程序,后面将通过etcd的方式。
再次整理了一下这个日志收集系统的框,如下图
这次要实现的代码的整体逻辑为:
完整代码地址为: https://github.com/pythonsite/logagent
etcd介绍
高可用的分布式key-value存储,可以用于配置共享和服务发现
类似的项目:zookeeper和consul
开发语言:go
接口:提供restful的接口,使用简单
实现算法:基于raft算法的强一致性,高可用的服务存储目录
etcd的应用场景:
服务发现和服务注册
配置中心(我们实现的日志收集客户端需要用到)
分布式锁
master选举
官网对etcd的有一个非常简明的介绍:
etcd搭建:
下载地址:https://github.com/coreos/etcd/releases/
根据自己的环境下载对应的版本然后启动起来就可以了
启动之后可以通过如下命令验证一下:
复制代码
[root@localhost etcd-v3.2.18-linux-amd64]# ./etcdctl set name zhaofan
zhaofan
[root@localhost etcd-v3.2.18-linux-amd64]# ./etcdctl get name
zhaofan
[root@localhost etcd-v3.2.18-linux-amd64]#
复制代码
context 介绍和使用
其实这个东西翻译过来就是上下文管理,那么context的作用是做什么,主要有如下两个作用:
控制goroutine的超时
保存上下文数据
通过下面一个简单的例子进行理解:
复制代码
package main
import (
“fmt”
“time”
“net/http”
“context”
“io/ioutil”
)
type Result struct{
r *http.Response
err error
}
func process(){
ctx,cancel := context.WithTimeout(context.Background(),2*time.Second)
defer cancel()
tr := &http.Transport{}
client := &http.Client{Transport:tr}
c := make(chan Result,1)
req,err := http.NewRequest(“GET”,”http://www.google.com”,nil)
if err != nil{
fmt.Println(“http request failed,err:”,err)
return
}
// 如果请求成功了会将数据存入到管道中
go func(){
resp,err := client.Do(req)
pack := Result{resp,err}
c <- pack
}()
select{
case <- ctx.Done():
tr.CancelRequest(req)
fmt.Println("timeout!")
case res := <-c:
defer res.r.Body.Close()
out,_:= ioutil.ReadAll(res.r.Body)
fmt.Printf("server response:%s",out)
}
return
}
func main() {
process()
}
复制代码
写一个通过context保存上下文,代码例子如:
复制代码
package main
import (
“github.com/Go-zh/net/context”
“fmt”
)
func add(ctx context.Context,a,b int) int {
traceId := ctx.Value(“trace_id”).(string)
fmt.Printf(“trace_id:%v\n”,traceId)
return a+b
}
func calc(ctx context.Context,a, b int) int{
traceId := ctx.Value(“trace_id”).(string)
fmt.Printf(“trace_id:%v\n”,traceId)
//再将ctx传入到add中
return add(ctx,a,b)
}
func main() {
//将ctx传递到calc中
ctx := context.WithValue(context.Background(),”trace_id”,”123456”)
calc(ctx,20,30)
}
复制代码
结合etcd和context使用
关于通过go连接etcd的简单例子:(这里有个小问题需要注意就是etcd的启动方式,默认启动可能会连接不上,尤其你是在虚拟你安装,所以需要通过如下命令启动:
./etcd –listen-client-urls http://0.0.0.0:2371 –advertise-client-urls http://0.0.0.0:2371 –listen-peer-urls http://0.0.0.0:2381
)
复制代码
package main
import (
etcd_client “github.com/coreos/etcd/clientv3”
“time”
“fmt”
)
func main() {
cli, err := etcd_client.New(etcd_client.Config{
Endpoints:[]string{“192.168.0.118:2371”},
DialTimeout:5*time.Second,
})
if err != nil{
fmt.Println(“connect failed,err:”,err)
return
}
fmt.Println("connect success")
defer cli.Close() } 复制代码 下面一个例子是通过连接etcd,存值并取值
复制代码
package main
import (
“github.com/coreos/etcd/clientv3”
“time”
“fmt”
“context”
)
func main() {
cli,err := clientv3.New(clientv3.Config{
Endpoints:[]string{“192.168.0.118:2371”},
DialTimeout:5*time.Second,
})
if err != nil{
fmt.Println(“connect failed,err:”,err)
return
}
fmt.Println(“connect succ”)
defer cli.Close()
ctx,cancel := context.WithTimeout(context.Background(),time.Second)
_,err = cli.Put(ctx,”logagent/conf/”,”sample_value”)
cancel()
if err != nil{
fmt.Println(“put failed,err”,err)
return
}
ctx, cancel = context.WithTimeout(context.Background(),time.Second)
resp,err := cli.Get(ctx,”logagent/conf/”)
cancel()
if err != nil{
fmt.Println(“get failed,err:”,err)
return
}
for _,ev := range resp.Kvs{
fmt.Printf(“%s:%s\n”,ev.Key,ev.Value)
}
}
复制代码
关于context官网也有一个例子非常有用,用于控制开启的goroutine的退出,代码如下:
复制代码
package main
import (
“context”
“fmt”
)
func main() {
// gen generates integers in a separate goroutine and
// sends them to the returned channel.
// The callers of gen need to cancel the context once
// they are done consuming generated integers not to leak
// the internal goroutine started by gen.
gen := func(ctx context.Context) <-chan int {
dst := make(chan int)
n := 1
go func() {
for {
select {
case <-ctx.Done():
return // returning not to leak the goroutine
case dst <- n:
n++
}
}
}()
return dst
}
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // cancel when we are finished consuming integers
for n := range gen(ctx) {
fmt.Println(n)
if n == 5 {
break
}
} } 复制代码 关于官网文档中的WithDeadline演示的代码例子:
复制代码
package main
import (
“context”
“fmt”
“time”
)
func main() {
d := time.Now().Add(50 * time.Millisecond)
ctx, cancel := context.WithDeadline(context.Background(), d)
// Even though ctx will be expired, it is good practice to call its
// cancelation function in any case. Failure to do so may keep the
// context and its parent alive longer than necessary.
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err())
}
}
复制代码
通过上面的代码有了一个基本的使用,那么如果我们通过etcd来做配置管理,如果配置更改之后,我们如何通知对应的服务器配置更改,通过下面例子演示:
复制代码
package main
import (
“github.com/coreos/etcd/clientv3”
“time”
“fmt”
“context”
)
func main() {
cli,err := clientv3.New(clientv3.Config{
Endpoints:[]string{“192.168.0.118:2371”},
DialTimeout:5*time.Second,
})
if err != nil {
fmt.Println(“connect failed,err:”,err)
return
}
defer cli.Close()
// 这里会阻塞
rch := cli.Watch(context.Background(),”logagent/conf/”)
for wresp := range rch{
for _,ev := range wresp.Events{
fmt.Printf(“%s %q : %q\n”, ev.Type, ev.Kv.Key, ev.Kv.Value)
}
}
}
复制代码
实现一个kafka的消费者代码的简单例子:
复制代码
package main
import (
“github.com/Shopify/sarama”
“strings”
“fmt”
“time”
)
func main() {
consumer,err := sarama.NewConsumer(strings.Split(“192.168.0.118:9092”,”,”),nil)
if err != nil{
fmt.Println(“failed to start consumer:”,err)
return
}
partitionList,err := consumer.Partitions(“nginx_log”)
if err != nil {
fmt.Println(“Failed to get the list of partitions:”,err)
return
}
fmt.Println(partitionList)
for partition := range partitionList{
pc,err := consumer.ConsumePartition(“nginx_log”,int32(partition),sarama.OffsetNewest)
if err != nil {
fmt.Printf(“failed to start consumer for partition %d:%s\n”,partition,err)
return
}
defer pc.AsyncClose()
go func(partitionConsumer sarama.PartitionConsumer){
for msg := range pc.Messages(){
fmt.Printf(“partition:%d Offset:%d Key:%s Value:%s”,msg.Partition,msg.Offset,string(msg.Key),string(msg.Value))
}
}(pc)
}
time.Sleep(time.Hour)
consumer.Close()
}
复制代码
但是上面的代码并不是最佳代码,因为我们最后是通过time.sleep等待goroutine的执行,我们可以更改为通过sync.WaitGroup方式实现
复制代码
package main
import (
“github.com/Shopify/sarama”
“strings”
“fmt”
“sync”
)
var (
wg sync.WaitGroup
)
func main() {
consumer,err := sarama.NewConsumer(strings.Split(“192.168.0.118:9092”,”,”),nil)
if err != nil{
fmt.Println(“failed to start consumer:”,err)
return
}
partitionList,err := consumer.Partitions(“nginx_log”)
if err != nil {
fmt.Println(“Failed to get the list of partitions:”,err)
return
}
fmt.Println(partitionList)
for partition := range partitionList{
pc,err := consumer.ConsumePartition(“nginx_log”,int32(partition),sarama.OffsetNewest)
if err != nil {
fmt.Printf(“failed to start consumer for partition %d:%s\n”,partition,err)
return
}
defer pc.AsyncClose()
go func(partitionConsumer sarama.PartitionConsumer){
wg.Add(1)
for msg := range partitionConsumer.Messages(){
fmt.Printf(“partition:%d Offset:%d Key:%s Value:%s”,msg.Partition,msg.Offset,string(msg.Key),string(msg.Value))
}
wg.Done()
}(pc)
}
//time.Sleep(time.Hour)
wg.Wait()
consumer.Close()
}
复制代码
将客户端需要收集的日志信息放到etcd中
关于etcd处理的代码为:
复制代码
package main
import (
“github.com/coreos/etcd/clientv3”
“time”
“github.com/astaxie/beego/logs”
“context”
“fmt”
)
var Client *clientv3.Client
var logConfChan chan string
// 初始化etcd
func initEtcd(addr []string,keyfmt string,timeout time.Duration)(err error){
var keys []string
for _,ip := range ipArrays{
//keyfmt = /logagent/%s/log_config
keys = append(keys,fmt.Sprintf(keyfmt,ip))
}
logConfChan = make(chan string,10)
logs.Debug("etcd watch key:%v timeout:%v", keys, timeout)
Client,err = clientv3.New(clientv3.Config{
Endpoints:addr,
DialTimeout: timeout,
})
if err != nil{
logs.Error("connect failed,err:%v",err)
return
}
logs.Debug("init etcd success")
waitGroup.Add(1)
for _, key := range keys{
ctx,cancel := context.WithTimeout(context.Background(),2*time.Second)
// 从etcd中获取要收集日志的信息
resp,err := Client.Get(ctx,key)
cancel()
if err != nil {
logs.Warn("get key %s failed,err:%v",key,err)
continue
}
for _, ev := range resp.Kvs{
logs.Debug("%q : %q\n", ev.Key, ev.Value)
logConfChan <- string(ev.Value)
}
}
go WatchEtcd(keys)
return }
func WatchEtcd(keys []string){
// 这里用于检测当需要收集的日志信息更改时及时更新
var watchChans []clientv3.WatchChan
for _,key := range keys{
rch := Client.Watch(context.Background(),key)
watchChans = append(watchChans,rch)
}
for {
for _,watchC := range watchChans{
select{
case wresp := <-watchC:
for _,ev:= range wresp.Events{
logs.Debug("%s %q : %q\n", ev.Type, ev.Kv.Key, ev.Kv.Value)
logConfChan <- string(ev.Kv.Value)
}
default:
}
}
time.Sleep(time.Second)
}
waitGroup.Done() }
func GetLogConf()chan string{
return logConfChan
}
复制代码
同样的这里增加对了限速的处理,毕竟日志收集程序不能影响了当前业务的性能,所以增加了limit.go用于限制速度:
复制代码
package main
import (
“time”
“sync/atomic”
“github.com/astaxie/beego/logs”
)
type SecondLimit struct {
unixSecond int64
curCount int32
limit int32
}
func NewSecondLimit(limit int32) *SecondLimit {
secLimit := &SecondLimit{
unixSecond:time.Now().Unix(),
curCount:0,
limit:limit,
}
return secLimit
}
func (s *SecondLimit) Add(count int) {
sec := time.Now().Unix()
if sec == s.unixSecond {
atomic.AddInt32(&s.curCount,int32(count))
return
}
atomic.StoreInt64(&s.unixSecond,sec)
atomic.StoreInt32(&s.curCount, int32(count))
}
func (s *SecondLimit) Wait()bool {
for {
sec := time.Now().Unix()
if (sec == atomic.LoadInt64(&s.unixSecond)) && s.curCount == s.limit {
time.Sleep(time.Microsecond)
logs.Debug(“limit is running,limit:%d s.curCount:%d”,s.limit,s.curCount)
continue
}
if sec != atomic.LoadInt64(&s.unixSecond) {
atomic.StoreInt64(&s.unixSecond,sec)
atomic.StoreInt32(&s.curCount,0)
}
logs.Debug("limit is exited")
return false
} } 复制代码 小结 这次基本实现了日志收集的前半段的处理,后面将把日志扔到es中,并最终在页面上呈现
Filebeat是一个开源的文件收集器,也是一款轻量级的日志传输工具。采用go语言开发,重构logstash采集器源码,安装在服务器上作为代理来监视日志目录或特定的日志文件,并把它们发送到logstash或elasticsearch,然后在Kibana上实现可视化。
其他介绍可参考官方文档:
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-configuration-details.html#configuration-output
一、Filebeat安装
下载地址:
源码安装:
wget
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.4.1-linux-x86_64.tar.gz
rpm下载安装:
curl -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.4.1-x86_64.rpm
rpm -ivh filebeat-6.4.1-x86_64.rpm
下面我们以rpm安装
image.png
二、Filebeat应用
因为我的是以rpm安装的,所以我们可以在/etc/filebeat/下面发现有filebeat.yml
image.png
我们可以发现在filebeat.yml配置文件里面,主要配置的模块有两个
· Filebeat input
· Output
Filebeat: 在这个模块里面,我们可以配置监控的日志,通过这个模块,我们可以指定日志的绝对路径,日志的类型,感知更新时间等等的·一些配置。
Output:在这个模块里面,主要的作用的是,filesbetas收集的日志输出到哪里,在这里,我们可以配置elasticsearch和logstash,两者二选一就可以了。
配置收集日志目录:
/etc/filebeat/filebeat.yml
下面以获取nginx的日志为例
安装Elasticsearch GeoIP和用户代理插件
在es的服务器上:
#su - www
#cd /usr/local/elasticsearch
#bin /elasticsearch-plugin install ingest-geoip
#bin /elasticsearch-plugin install ingest-user-agent
三、Filebeat采集数据,写入到elasticsearch
修改Filebeat配置
#vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log #定义日志格式
enabled: true
paths: - /data/wwwlogs/*.log #定义日志的路径
output.elasticsearch:
hosts: [“172.25.0.30:9200”] #定义的es的url
username: “elastic” 定义es的账号,已做安全连接
password: “changeme”
setup.kibana:
host: “172.25.0.30:5601” #定义kibana的url
启动filebeat
#cd /etc/filebeat
#filebeat modules enable nginx
修改/etc/filebeat/modules.d/nginx.yml文件中的设置
#vim /etc/filebeat/modules.d/nginx.yml
cat modules.d/nginx.yml
- module: nginx
Access logs
access:
enabled: true
var.paths: [“/data/wwwlogs/*.log”]
Error logs
error:
enabled: true
var.paths: [“/data/wwwlogs/error.log”]
#filebeat setup
service filebeat start
Starting filebeat (via systemctl): [ OK ]
进去kibana添加filebeat
image.png
image.png
下一步就可以创建完毕了
image.png
创建完毕后
我们直接跳到Discover,查看我们获取的数据
image.png
可以发现我们是已经获取到nginx的完整的数据了
继续查看我们的nginx的仪表板。
image.png
我们可以发现,我已经可以通过filebeat采集到nginx的日志的数据了,并生成的数据图像,到这里我们的获取数据就完成了,elasticsearch通过filebeat获取数据就完成了。
四、Filebeat采集数据,写入到logstash
1、修改Filebeat配置
#vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log #定义日志格式
enabled: true
paths: - /data/wwwlogs/*.log #定义日志的路径
output.logstash:
The Logstash hosts
hosts: [“172.25.0.30:5044”]
2、配置logstash
logstash服务器:
因为需要配置logstah来获取数据,所以我们需要配置logstash
#vim /etc/logstash/conf.d/filebeat.conf
input {
beats {
port => “5044” #定义输入端口
}
}
filter {
grok {
match => { “message” => “%{COMBINEDAPACHELOG}” }
}
date {
match => [ “timestamp”, “dd/MMM/yyyy:HH:mm:ss Z” ]
target => [“datetime”]
}
geoip {
source => “clientip”
}
}
output {
elasticsearch {
hosts => “172.25.0.30:9200” #定义输出的es的url。
index => “nginx_log” #定义标题索引
}
stdout { codec => rubydebug }
}
更改权限
#chown www:www /etc/logstash/conf.d/filebeat.conf
3、启动logstash,测试
#
./usr/local/src/logstash-6.3.0/bin/logstash
-f /etc/logstash/conf.d/filebeat.conf
启动之后,可以发现logstash已经从filebeat收集到数据了
image.png
查看logstash的启动状态,发现5044已经起来了。
image.png
4、添加索引,出数据
image.png
查看是否已经获取到数据
image.png
我们发现已经是可以获取到目标主机的nginx日志了。到这里我们使用logstash获取日志就完成了。
五、总结
Filebeat不仅仅可以收集nginx,还可以收集mysql、apache、redis和系统日志。从我们的搭建过程来看,可以发现filebeat配置并不是很难,不过更好的应用还是需要进一步熟悉才行。。
背景:
1、有上百个soa微服务
2、每个微服务的日志路径格式为 /mypath/soa1/log/yyyymm/dd/xxx.log
3、每个微服务的日志目录(/mypath/soa1/log/) 都会按照当天日期生成一个二级子目录,该子目录下存放交易日志,每一笔交易即生成一个日志文件,每天的交易都是实时的,高峰期每天会产生上百万个日志文件
我们尝试收集的过程:
1、我们做过很多收集日志尝试,但都遇到了瓶颈,logstash、flume、filebeat虽然都可以配置监听一个目录来收集日志文件,但是被监听的目录下日志文件个数上万以后,都特别慢,更别提上百万以后,而且这还只是一天的其中一个服务的日志目录
2、而且这些收集日志的组件都是按照日志文件的行来收集日志的,即每个日志文件都是一行一行的收集,这样查看起来非常麻烦,尤其是并发收集很多微服务日志的时候,顺序都是乱的,我们想要的效果是一次性传输一个日志文件的所有内容,这样查看起来很方便,也很好管理
需求:
1、目录感觉filebeat可能会好一些,请教大神指点一下filebeat如何收集单个子目录超过百万个日志文件的快速收集方法
2、最好是每个日志文件的所有内容当做一条信息收集走,而不是按照一行一行来收集
3、如果做不到第2点,请教大神,如果按照一行一行的收集日志后,当大量日志同时传输到logstash或者es时,每条日志信息的@timestmap都很相近,这样一个完整的日志文件的顺序就全乱了,请问如何让kibana展示的时候按照正常的日志顺序显示
作者:IT米粉
链接:https://www.zhihu.com/question/21427267/answer/227789798
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
收集日志日志管理的第一件事,就是日志的收集。日志收集是开发者必备的技巧,不管是哪个开发语言,哪个开发平台,日志收集的插件都是有很多选择的。例如:.net 平台大家钟爱的log4net,支持多种存储方式(文件、数据库),多种格式,多种日志拆分方式。java 平台主流的log4j、slf4j、logback,多种选择。日志收集的组件这里就不一一说明了,使用都是很简单的,这里重点说明一下,日志我们收集应该注意的地方:1. 日志等级一定要规范等级说明debug调试信息info用来收集关注的信息warn警告信息error错误信息好多开发工程师记录日志总是喜欢用info级别来记录日志,一般的组件默认级别都是info,所有info默认都是会被记录的,而debug信息发布后,是不会被记录的。这是一种偷懒的做法,但这也是很普遍的做法。正确的方式应该根据日志本身的特性去设置日志的级别,其实规范的日志级别是非常重要的:正确的级别便于运维。便于统一调整系统日志级别,如特殊情况可以只记录error错误没有正确的级别,对后期日志分析和处理是留下很大的隐患。error是需要去关注,并且处理掉的问题。info是普通日志的记录,大部分时候是无需关注的。2. error日志内容一定要详实 ,info日志要简洁易懂运营过大型系统的人都知道,除了数据库存储外,日志、图片、附件是存储的三大债主,他们是会占用非常非常大的空间,所有记录info的日志,要简洁易懂,避免空间浪费。 而对于error级别的错误,记录一定要详实,因为error的所有问题,是后期都要去解决的。请求的地址请求的参数请求的ip请求的用户error具体信息输出的内容……为了能很好的反馈当时error产生场景,以上的这些内容都应该被记录,而且越详细越好。3. error日志一定是全局统一收集的前文说过,error的日志,不仅是我们需要关注的,还是我需要解决掉的问题,所有error日志非常重要。错误日志的收集,必须是全局统一收集的,AOP是你最好的伙伴,如果你发现你的errorr日志收集是在每个类中,到处是try
{
……
}
catch()
{
log.error(“……”)
}
这个一定要避免,不管你用那种语言,错误的处理,都是可以通过全局进行统一的处理,错误日志也要通过全局统一收集。管理日志每个开发人员对日志的收集,都是非常熟悉的,基本都是将日志按照日期的方式进行保存,日常使用日志的时候,也是有一些要求:1. 单个文件的大小要控制因为大家都是通过日期方式保存的,但是因为有的人不重视日志,经常会看到有的系统单个日志文件上百M,有的甚至是几G,而实际大家处理问题关注的都是最近的日志,所以控制单个日志文件的大小,对日志的性能以及后期的运维都是非常便利的。2. 日志要便于浏览日志文件小才便于浏览,日志最好能通过网址直接访问到,而不需要一波三折登录服务器,花10分钟下载下来,再来分析。3. 日志的安全性要得到保障日志内容有时会包含敏感信息,特别是error日志,直接把系统的具体错误抛出来,所以日志除了查看方便,还需要确保日志文件的安全。如果是日志文件是html或者txt,请一定记得把你的日志文件权限修改下,特定用户才能访问,不要随便开放,所有人都能访问。4. 日志要定期清理日志是非常占用存储的空间,日志太大对存储的性能也有一定的影响,所有日志要定期进行清理。空间充足可以保留半年空间不足最少也要保留3个月当然,这个也不是一定的,根据每个系统的情况去制定清理计划就可以了。如果大家是小型网站,一个系统一台服务器,日志管理就简单了。如果系统是做了高可用,后端用了均衡负载,那么,日志存在当前服务器是不太明智的做法,日志一定要统一存储,因为均衡负载随时都可能会切换服务器,当出现故障,你需要去找日志究竟存在哪个服务器,也是件很浪费时间的事情。日志文件也可以通过:共享虚拟目录来存储定时进行文件同步来存储日志存储也是对性能有一定影响的,文件同步虽然看起来麻烦一定,但是比共享虚拟目录的方式来说,性能会好,推荐使用这种方式。说到日志的同步,就不得不提Logstash这个日志组件。Logstash是现在应用最广的日志收集组件,基于java平台。其实很多java平台的组件,是不用去了解java开发的,只要简单的配置就能使用。Logstash支持文件同步,也可以结合rsyslog进行文件同步,当然,也支持通过tcp协议,与第三方对接,好伙伴当然是Elasticsearch。Elasticsearch下文也会做简单的介绍。Logstash中文手册:点击这里分析日志日志的分析也是一个很大的概念,可能对于运维和安全人员关注的是系统的所有日志,包括访问日志、系统监测的日志等,但是开发人员对于日志更多的是:监控系统运行错误,并获取错误时的相关数据包记录重要的信息,某些时候便于后期检查所以,开发人员对日志的需求相对而言简单一点,但是处理不当也会面临挑战。如果要根据某些关键字找日志,没有一个靠谱的系统处理,那么大家只能一直在ctrl+f 或者 find 命令中来回查找自己需要的信息,使用过的人都知道,这绝对不是一个很好的体验。那么是否有很好的工具来处理呢?有,这里就介绍另外的两个工具:Elasticsearch——一个基于lucene的搜索引擎工具,解决日志的搜索问题。当然,也能解决系统的搜索问题,而且是分布式的哦。Kibana——一个可视化的日志操作引擎,结合Elasticsearch可以达到更好的效果。Kibana 界面预览 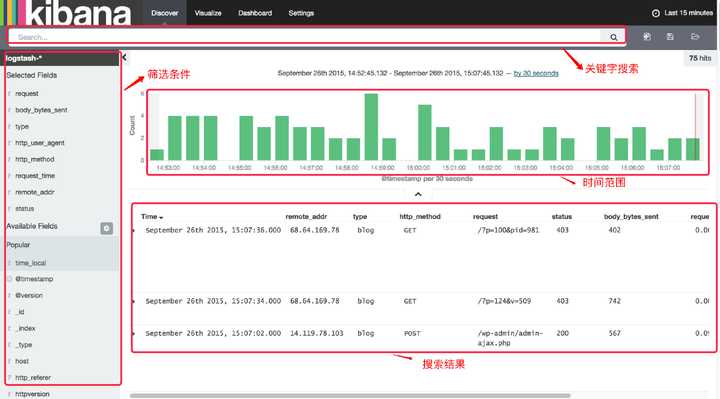 Elasticsearch+Logstash+Kibana 就是传说中的ELK了,应该是现在最流行的日志处理平台。Elasticsearch中文文档:点击这里 ELK中文文档:点击这里尾声这里简单说明一下,自己心目中的日志管理系统。 整体流程如图:
Elasticsearch+Logstash+Kibana 就是传说中的ELK了,应该是现在最流行的日志处理平台。Elasticsearch中文文档:点击这里 ELK中文文档:点击这里尾声这里简单说明一下,自己心目中的日志管理系统。 整体流程如图: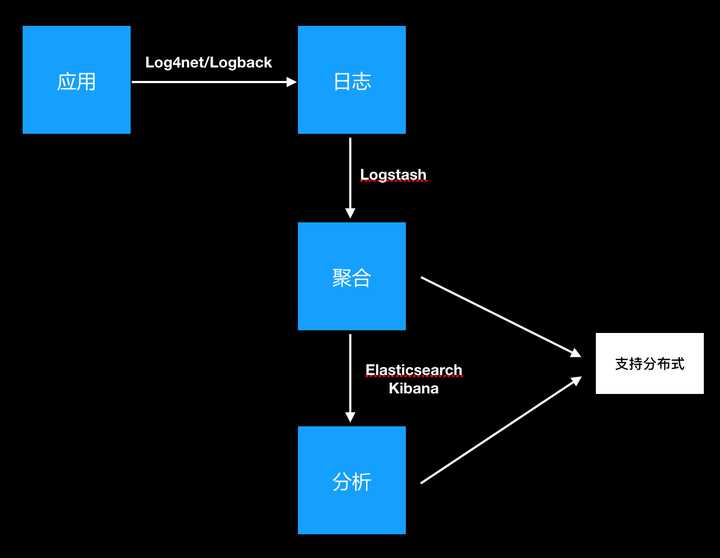 推荐的几个工具虽然是java平台的工具,但是日志处理的思路不管是哪个平台都是一样的。ELK如果只是作为日志管理的工具,也可以应用到.net平台,无需再进行二次开发就可以很好的使用。ELK的使用是有一定的学习成本的,如有时间可以另起一文探讨,但是,这个学习成本是可以忽略语言之间的差异。当然,如果大家愿意使用脚本同步或者rsyn文件同步进行日志处理也是可以的。
推荐的几个工具虽然是java平台的工具,但是日志处理的思路不管是哪个平台都是一样的。ELK如果只是作为日志管理的工具,也可以应用到.net平台,无需再进行二次开发就可以很好的使用。ELK的使用是有一定的学习成本的,如有时间可以另起一文探讨,但是,这个学习成本是可以忽略语言之间的差异。当然,如果大家愿意使用脚本同步或者rsyn文件同步进行日志处理也是可以的。
