检测内存泄露
1、win下的内存泄露检测方法:_CrtDumpMemoryLeaks
通过包括 crtdbg.h,将 malloc 和 free 函数映射到它们的调试版本,即 _malloc_dbg 和 _free_dbg,这两个函数将跟踪内存分配和释放。 此映射只在调试版本(在其中定义了_DEBUG)中发生。 发布版本使用普通的 malloc 和 free 函数。
在程序退出前调用:_CrtDumpMemoryLeaks();
define _CRTDBG_MAP_ALLOC
#include
#include
#include
using namespace std;
void GetMemory(char p, int num)
{
p = (char)malloc(sizeof(char) * num);
}
int main(int argc,char** argv)
{
char *str = NULL;
GetMemory(str, 100);
cout«“Memory leak test!”«endl;
_CrtDumpMemoryLeaks();
return 0;
}
2、Linux下的内存泄露检测方法
mtrace/muntrace
valgrind
memwatch
mtrace
Linux下mtrace的使用
#include
#include
int main(void) {
mtrace(); /* Starts the recording of memory allocations and releases */
int* a = NULL;
a = malloc(sizeof(int)); /* allocate memory and assign it to the pointer */
if (a == NULL) {
return 1; /* error */
}
free(a); /* we free the memory we allocated so we don't have leaks */
muntrace();
return 0; /* exit */
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
valgrind工具
The Valgrind Quick Start Guide
Memwatch
Usage:
只要在你程序中加入memwatch.h,编译时加上-DMEMWATCH -DMW_STDIO及memwatch.c就能使用memwatch
memwatch 的输出文件名称为memwatch.log,而且在程序执行期间,所有错误提示都会显示在stdout上,如果memwatch未能写入以上文件,它会尝试写入memwatchNN.log,而NN介于01至99之间,若它仍未能写入memwatchNN.log,则会放弃写入文件。
gcc -DMEMWATCH -DMW_STDIO test.c memwatch.c -o test
#include
#include
#include "memwatch.h"
int main(int argc,char **argv)
{
int i = 0;
char *p;
mwInit(); //执行memwatch的初始化工作。虽然memwatch有在第一次使用时能够自动装载,但作者还是建议我们使用该函数。
p = malloc(100);
p = malloc(200);
free(p);
for(i=0;i<5;i++)
{
p = malloc(50);
if(p == NULL)
{
printf("can't malloc memory for test,num:%d\n",i);
continue;
}
if((i%2) == 0)
{
free(p);
p = NULL;
}
}
mwTerm(); //执行memwatch的清除工作。当我们使用了mwInit()时,就必须使用该函数来终止memwatch的工作。
return; } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 参考:这里写链接内容
gcc
gcc -E 产生预编译后的源代码,即源代码经过预编译后的结果,所有的预编译动作都已完成。如头文件的插入,宏定义的展开。
参考:GCC C Compiler
gdb调试宏、条件断点、命令行参数
例子:
#include
#include
#define MACRO1(x) (++(x))
#define MACRO2(x) (MACRO1(x)+100)
#define MACRO3(x) (MACRO2(x)+200)
int main(void)
{
int a = 0;
int b = 0;
b = MACRO3(a);
printf(“%d\n”, b);
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1、调试宏
在GCC编译程序的时候,加上-ggdb3/-g3参数,这样,你就可以调试宏了。
macro expand/exp 展开宏定义
info macro 查看宏展开,及被调用处
(gdb) macro exp MACRO3(3) //展开宏,并传入值
expands to: (((++(3))+100)+200)
(gdb) info macro MACRO3 //查看这个宏在哪些文件里被引用了,以及宏定义是什么样的
Defined at /mnt/hgfs/VMUB/codeTs/test/macro_gdb.c:6
#define MACRO3(x) (MACRO2(x)+200)
1
2
3
4
5
2、条件断点
break line-or-function if expr
(gdb) break main if b = 0
Breakpoint 1 at 0x8048426: file macro_gdb.c, line 10.
1
2
3、命令行参数
可以使用两种方法输入命令行参数
1)run 命令行参数
2)set args 命令行参数
如:我的程序中需要输入的时服务器端ip地址,可以通过以下两种方法输入
1)如果直接运行程序,run www.baidu.com
2)set args www.baidu.com,后面再继续进行调试
4、修改变量的值
p a = 100 #修改变量的文件中的值
参考:这里写链接内容
gdb调试多线程
1、命令
info thread 查看当前进程的线程。
thread 切换调试的线程为指定ID的线程。
break file.c:100 thread all 在file.c文件第100行处为所有经过这里的线程设置断点。
set scheduler-locking off|on|step
这个是问得最多的。在使用step或者continue命令调试当前被调试线程的时候,其他线程也是同时执行的,怎么只让被调试程序执行呢?通过这个命令就可以实现这个需求。
off 不锁定任何线程,也就是所有线程都执行,这是默认值。
on 只有当前被调试程序会执行。
step 在单步的时候,除了next过一个函数的情况(熟悉情况的人可能知道,这其实是一个设置断点然后continue的行为)以外,只有当前线程会执行。
thread apply ID1 ID2 command 让一个或者多个线程执行GDB命令command。
thread apply all command 让所有被调试线程执行GDB命令command。
gdb对于多线程程序的调试有如下的支持:
线程产生通知:在产生新的线程时, gdb会给出提示信息
(gdb) r
Starting program: /root/thread
[New Thread 1073951360 (LWP 12900)]
[New Thread 1082342592 (LWP 12907)]—以下三个为新产生的线程
[New Thread 1090731072 (LWP 12908)]
[New Thread 1099119552 (LWP 12909)]
查看线程:使用info threads可以查看运行的线程。
(gdb) info threads
4 Thread 1099119552 (LWP 12940) 0xffffe002 in ?? ()
3 Thread 1090731072 (LWP 12939) 0xffffe002 in ?? ()
2 Thread 1082342592 (LWP 12938) 0xffffe002 in ?? ()
- 1 Thread 1073951360 (LWP 12931) main (argc=1, argv=0xbfffda04) at thread.c:21
(gdb)
注意,行首的蓝色文字为gdb分配的线程号,对线程进行切换时,使用该该号码,而不是上文标出的绿色数字。
另外,行首的红色星号标识了当前活动的线程
切换线程:使用 thread THREADNUMBER 进行切换,THREADNUMBER 为上文提到的线程号。下例显示将活动线程从 1 切换至 4。
(gdb) info threads
4 Thread 1099119552 (LWP 12940) 0xffffe002 in ?? ()
3 Thread 1090731072 (LWP 12939) 0xffffe002 in ?? ()
2 Thread 1082342592 (LWP 12938) 0xffffe002 in ?? ()
- 1 Thread 1073951360 (LWP 12931) main (argc=1, argv=0xbfffda04) at thread.c:21
(gdb) thread 4
[Switching to thread 4 (Thread 1099119552 (LWP 12940))]#0 0xffffe002 in ?? ()
(gdb) info threads - 4 Thread 1099119552 (LWP 12940) 0xffffe002 in ?? ()
3 Thread 1090731072 (LWP 12939) 0xffffe002 in ?? ()
2 Thread 1082342592 (LWP 12938) 0xffffe002 in ?? ()
1 Thread 1073951360 (LWP 12931) main (argc=1, argv=0xbfffda04) at thread.c:21
(gdb)
后面就是直接在你的线程函数里面设置断点,然后continue到那个断点,一般情况下多线程的时候,由于是同时运行的,最好设置 set scheduler-locking on这样的话,只调试当前线程
gdb调试多进程
1、follow-fork-mode GDB 6.4
set follow-fork-mode [parent|child]
parent: fork之后继续调试父进程,子进程不受影响。
child: fork之后调试子进程,父进程不受影响。
因此如果需要调试子进程,在启动gdb后:
(gdb) set follow-fork-mode child
2、detach-on-fork GDB 6.6
set detach-on-fork [on|off]
on: 断开调试follow-fork-mode指定的进程。
off: gdb将控制父进程和子进程。follow-fork-mode指定的进程将被调试,另一个进程置于暂停(suspended)状态。
3、Attach子进程
attach
4、GDB wrapper
小结:
follow-fork-mode方法:方便易用,对系统内核和GDB版本有限制,适合于较为简单的多进程系统
attach子进程方法:灵活强大,但需要添加额外代码,适合于各种复杂情况,特别是守护进程
GDB wrapper方法:专用于fork+exec模式,不用添加额外代码,但需要X环境支持(xterm/VNC)。
参考:gdb调试子进程
core
linux 下调试core 的命令,察看堆栈状态命令
【实例】
#include
static void sub(void)
{
int *p = NULL;
printf("%d", *p); }
int main(void)
{
sub();
return 0; }
ulimit -c 查看core文件的生成开关。若结果为0,则表示关闭了此功能,不会生成core文件。
ulimit -c filesize(大小为KB)
ulimit -c unlimited
ulimit -a 显示所有的用户定制,其中选项-a代表“all”。
先运行,a.out -> 产生core dump文件
默认生成的文件就叫core,不带PID,如果要带PID需要设置,通过echo “1” > /proc/sys/kernel/core_uses_pid能够设置pid
$ gdb –core=core
Core was generated by `./a.out’.
Program terminated with signal 11, Segmentation fault.
#0 0x08048373 in ?? ()
(gdb) bt
#0 0x08048373 in ?? ()
#1 0xbfffd8f8 in ?? ()
#2 0x0804839e in ?? ()
#3 0xb74cc6b3 in ?? ()
#4 0x00000000 in ?? ()
此时用bt看不到backtrace,也就是调用堆栈,原来GDB还不知道符号信息在哪里。我们告诉它一下:
(gdb) file ./a.out
Reading symbols from ./a.out…done.
Using host libthread_db library “/lib/tls/libthread_db.so.1”.
(gdb) bt
#0 0x08048373 in sub () at foo.c:17
#1 0x08048359 in main () at foo.c:8
此时backtrace出来了。
调试core
内核态用户态的通信
四种方法:
内存映射、procfs、syscall、ioctl、netlink
1、内存映射的方式,将内核地址映射到用户态。这种方式最直接,可以适用大量的数据传输机制。
这种方式的缺点是很难进行“业务控制”,没有一种可靠的机制保障内核和用户态的调动同步,比如信号量等都不能跨内核、用户层使用。因此内存映射机制一般需要配合一种“消息机制”来控制数据的读取,比如采用“消息”类型的短数据通道来完成一个可靠的数据读取功能。
2、ioctl机制,ioctl机制可以在驱动中扩展特定的ioctl消息,用于将一些状态从内核反应到用户态。
Ioctl有很好的数据同步保护机制,不要担心内核和用户层的数据访问冲突,但是ioctl不适合传输大量的数据,通过和内存映射结合可以很好的完成大量数据交换过程。但是,ioctl的发起方一定是在用户态,因此如果需要内核态主动发起一个通知消息给用户层,则非常的麻烦。可能需要用户态程序采用轮询机制不停的ioctl。
3、系统调用必须通过用户态发起
4、proc方式不太可靠和实时,用于调试信息的输出还是非常合适的。
参考:Linux内核态与用户态通信的常用方法
Netlink 相对于系统调用,ioctl 以及 /proc 文件系统而言具有以下优点:
1,为了使用 netlink,用户仅需要在 include/linux/netlink.h 中增加一个新类型的 netlink 协议定义即可, 如 #define NETLINK_MYTEST 17 然后,内核和用户态应用就可以立即通过 socket API 使用该 netlink 协议类型进行数据交换。但系统调用需要增加新的系统调用,ioctl 则需要增加设备或文件, 那需要不少代码,proc 文件系统则需要在 /proc 下添加新的文件或目录,那将使本来就混乱的 /proc 更加混乱。
- netlink是一种异步通信机制,在内核与用户态应用之间传递的消息保存在socket缓存队列中,发送消息只是把消息保存在接收者的socket的接 收队列,而不需要等待接收者收到消息,但系统调用与 ioctl 则是同步通信机制,如果传递的数据太长,将影响调度粒度。
3.使用 netlink 的内核部分可以采用模块的方式实现,使用 netlink 的应用部分和内核部分没有编译时依赖,但系统调用就有依赖,而且新的系统调用的实现必须静态地连接到内核中,它无法在模块中实现,使用新系统调用的应用在编译时需要依赖内核。
4.netlink 支持多播,内核模块或应用可以把消息多播给一个netlink组,属于该neilink 组的任何内核模块或应用都能接收到该消息,内核事件向用户态的通知机制就使用了这一特性,任何对内核事件感兴趣的应用都能收到该子系统发送的内核事件,在 后面的文章中将介绍这一机制的使用。
5.内核可以使用 netlink 首先发起会话,但系统调用和 ioctl 只能由用户应用发起调用。
6.netlink 使用标准的 socket API,因此很容易使用,但系统调用和 ioctl则需要专门的培训才能使用。
Linux内核态与用户态进程通信方法-用户上下文
Linux 内核提供 copy_from_user()/copy_to_user() 函数来实现内核态与用户态数据的拷贝
参考:Linux内核态与用户态进程通信方法-用户上下文
Linux netlink套接字机制
netlink套接字是用以实现用户进程与内核进程通信的一种特殊的进程间通信(IPC) ,也是网络应用程序与内核通信的最常用的接口。
netlink套接字可以使用标准的套接字APIs来创建。socket(), bind(), sendmsg(), recvmsg() 和 close()很容易地应用到 netlink socket。
netlink包含于头文件linux/netlink.h中,
1、用户态使用 netlink
创建套接字:
socket(AF_NETLINK, SOCK_RAW, netlink_type)
绑定套接字:
//用于把【打开的netlink socket】与【源netlink socket】地址绑定在一起。
bind(fd, (struct sockaddr*)&nladdr, sizeof(struct sockaddr_nl));
对消息进行封装,加上消息头,即可发送。
sendmsg(fd, &msg, 0);
接收消息
//应用接收消息时需要首先分配一个足够大的缓存来保存消息头以及消息的数据部分,然后填充消息头,
//添完后就可以调用函数 recvmsg() 来接收。
recvmsg(fd, &msg, 0);
2、netlink内核API
创建一个内核的netlink套接字
struct sock *
netlink_kernel_create(int unit, void (*input)(struct sock *sk, int len));
发送消息:
//netlink_unicast 来发送单播消息:
int netlink_unicast(struct sock *sk, struct sk_buff *skb, u32 pid,
int nonblock);
//netlink_broadcast来发送广播消息:
void netlink_broadcast(struct sock *sk, struct sk_buff *skb, u32 pid,
u32 group, int allocation);
释放套接字
void sock_release(struct socket * sock);
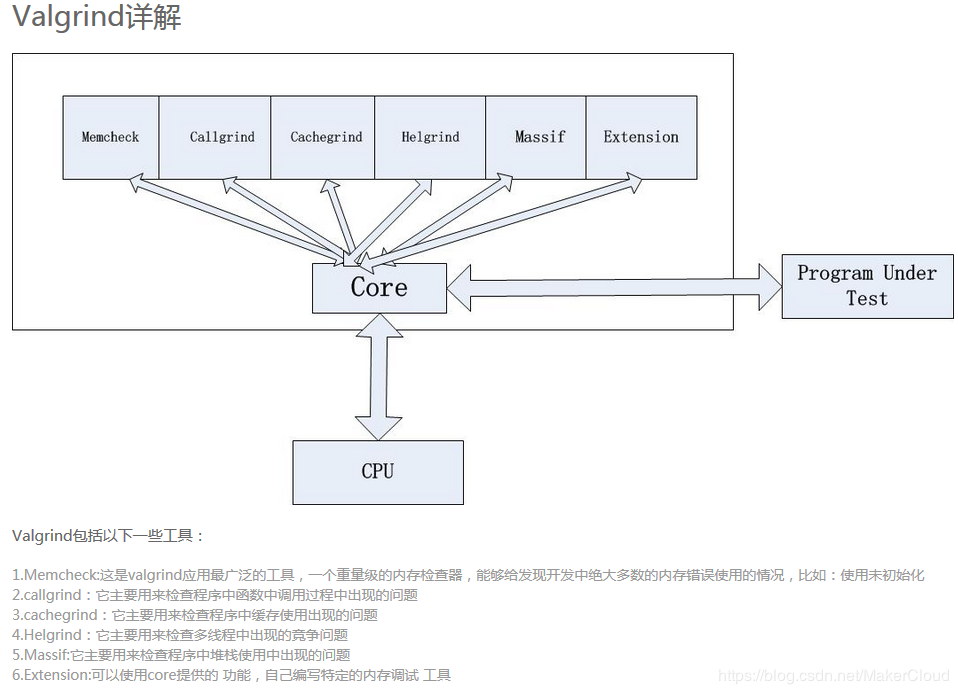
Valgrind检测内存泄漏
概述
任何长期运行的应用程序都必须正确地管理内存,否则它最终会耗尽所有可用内存并崩溃,如果你使用的是自动为你管理内存的语言,那么祝贺你,如果你用C/C++则需要你负责内存管理,这里有一个valgrind的简短教程,这个工具将对你的程序的任何内存泄漏出具报告。
Valgrind是用于构建动态分析工具的仪器框架。有Valgrind工具可以自动检测许多内存管理和线程错误,并详细描述程序。您也可以使用Valgrind构建新工具。
Valgrind发行版当前包括六个生产质量工具:一个内存错误检测器,两个线程错误检测器,一个缓存和分支预测探查器,一个生成调用图的缓存和分支预测探查器以及一个堆探查器。它还包括三个实验工具:堆栈/全局数组溢出检测器,第二个堆分析器(用于检查堆块的使用方式)以及SimPoint基本块向量生成器。它可在以下平台上运行:X86 / Linux,AMD64 / Linux,ARM / Linux,ARM64 / Linux,PPC32 / Linux,PPC64 / Linux,PPC64LE / Linux,S390X / Linux,MIPS32 / Linux,MIPS64 / Linux,X86 / Solaris ,AMD64 / Solaris,ARM / Android(2.3.x和更高版本),ARM64 / Android,X86 / Android(4.0和更高版本),MIPS32 / Android,X86 / Darwin和AMD64 / Darwin(Mac OS X 10.12)。
官网:
http://valgrind.org
当前最新版本valgrind-3.15.0
安装
要在Ubuntu或者debian操作系统上安装valgrind,可以输入
sudo apt-get update
sudo apt-get install valgrind
1
2
Valgrind 命令介绍:
用法: valgrind options prog-and-args
options: 常用选项,适用于所有Valgrind工具
–tool= 最常用的选项。运行 valgrind中名为toolname的工具。默认memcheck。
memcheck ——> 这是valgrind应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等。
callgrind ——> 它主要用来检查程序中函数调用过程中出现的问题,检测程序代码的运行时间和调用过程,以及分析程序性能。
cachegrind ——> 它主要用来检查程序中缓存使用出现的问题,分析CPU的cache命中率、丢失率,用于进行代码优化。
helgrind ——> 它主要用来检查多线程程序中出现的竞争问题,用于检查多线程程序的竞态条件。
massif ——> 它主要用来检查程序中堆栈使用中出现的问题。堆栈分析器,指示程序中使用了多少堆内存等信息。
extension ——> 可以利用core提供的功能,自己编写特定的内存调试工具
-h –help 显示帮助信息。
-version 显示valgrind内核的版本,每个工具都有各自的版本。
-q –quiet 安静地运行,只打印错误信息。
-v –verbose 更详细的信息, 增加错误数统计。
-trace-children=no|yes 跟踪子线程? [no]
-track-fds=no|yes 跟踪打开的文件描述?[no]
-time-stamp=no|yes 增加时间戳到LOG信息? [no]
-log-fd= 输出LOG到描述符文件 [2=stderr]
-log-file= 将输出的信息写入到filename.PID的文件里,PID是运行程序的进行ID
-log-file-exactly= 输出LOG信息到 file
-log-file-qualifier= 取得环境变量的值来做为输出信息的文件名。 [none]
-log-socket=ipaddr:port 输出LOG到socket ,ipaddr:port
LOG信息输出
-xml=yes 将信息以xml格式输出,只有memcheck可用
-num-callers= show callers in stack traces [12]
-error-limit=no|yes 如果太多错误,则停止显示新错误? [yes]
-error-exitcode= 如果发现错误则返回错误代码 [0=disable]
-db-attach=no|yes 当出现错误,valgrind会自动启动调试器gdb。[no]
-db-command= 启动调试器的命令行选项[gdb -nw %f %p]
适用于Memcheck工具的相关选项:
-leak-check=no|summary|full 要求对leak给出详细信息? [summary]
-leak-resolution=low|med|high how much bt merging in leak check [low]
-show-reachable=no|yes show reachable blocks in leak check? [no]
最常用的命令格式:
valgrind –tool=memcheck –leak-check=full ./test
1
测试用例:
testValgrind.cpp
#include
#include
int main()
{
char* p = new char(10);
//delete p;
return 0; }
g++ -g -o test testValgrind.cpp
valgrind –tool=memcheck –leak-check=full ./test
==1179== Memcheck, a memory error detector
==1179== Copyright (C) 2002-2017, and GNU GPL’d, by Julian Seward et al.
==1179== Using Valgrind-3.13.0 and LibVEX; rerun with -h for copyright info
==1179== Command: ./test
==1179==
==1179== error calling PR_SET_PTRACER, vgdb might block
==1179==
==1179== HEAP SUMMARY:
==1179== in use at exit: 1 bytes in 1 blocks
==1179== total heap usage: 2 allocs, 1 frees, 72,705 bytes allocated
==1179==
==1179== 1 bytes in 1 blocks are definitely lost in loss record 1 of 1
==1179== at 0x4C3017F: operator new(unsigned long) (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==1179== by 0x10868B: main (testValgrind.cpp:8)
==1179==
==1179== LEAK SUMMARY:
==1179== definitely lost: 1 bytes in 1 blocks
==1179== indirectly lost: 0 bytes in 0 blocks
==1179== possibly lost: 0 bytes in 0 blocks
==1179== still reachable: 0 bytes in 0 blocks
==1179== suppressed: 0 bytes in 0 blocks
==1179==
==1179== For counts of detected and suppressed errors, rerun with: -v
==1179== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 0 from 0)
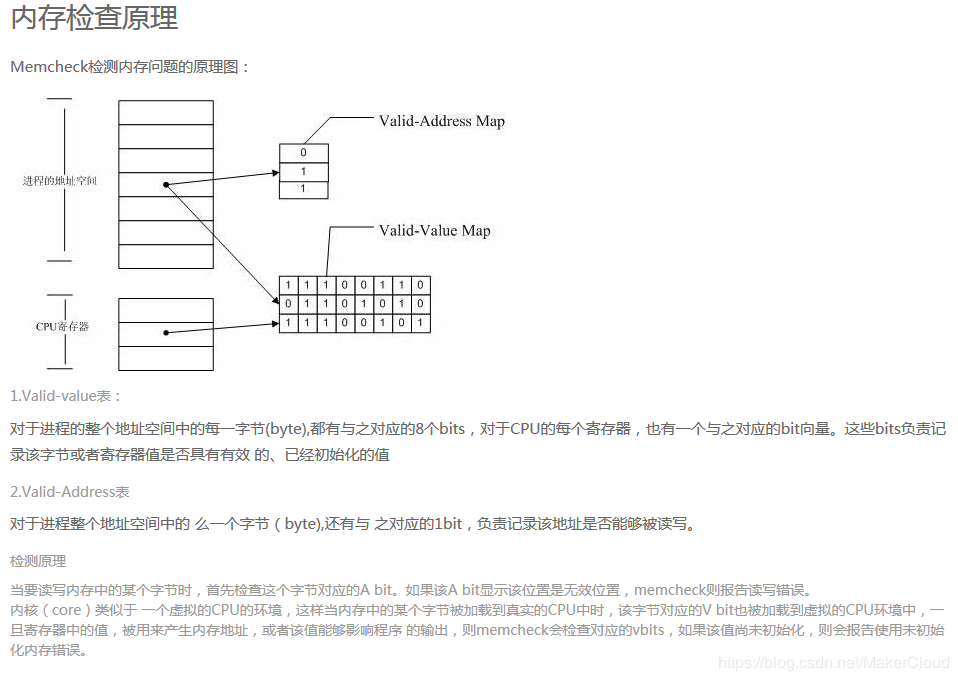
原理:
Memcheck将内存泄露分为两种,一种是可能的内存泄露(Possibly lost),另外一种是确定的内存泄露(Definitely lost)。Possibly lost 是指仍然存在某个指针能够访问某块内存,但该指针指向的已经不是该内存首地址。Definitely lost 是指已经不能够访问这块内存。而Definitely lost又分为两种:直接的(direct)和间接的(indirect)。直接和间接的区别就是,直接是没有任何指针指向该内存,间接是指指向该内存的指针都位于内存泄露处。在上述的例子中,根节点是directly lost,而其他节点是indirectly lost。
Bigpipe是Baidu公司内部的分布式传输系统,其服务器模块Broker采用异步编程框架来实现,并大量使用了引用计数来管理对象资源的生命周期和释放时机。在对Broker模块进行压力测试过程中,发现Broker长时间运行后,内存占用逐步变大,出现了内存泄漏问题。
二、初步分析
针对近期Broker的升级改造点,确定Broker中可能出现内存泄漏的对象。Broker新增了监控功能,其中一项是对服务器各个参数的监控统计,这必然对参数对象有读取操作,每次操作都将引用计数“加一”,并在完成操作后“减一”。当前,参数对象有数个,需要确定是哪个参数对象泄漏了。
三、代码&业务分析
1. 为证明之前的初步分析的结果,可能的方法有是:使用Valgrind运行Broker并启动压力程序复现可能的内存泄漏。但是,使用这种方法:
1) 由于内存泄漏的触发条件并不简单,可能导致复现周期很长,甚至无法复现同样的内存泄漏;
2) 内存泄漏的对象放置在容器中,valgrind正常退出后不报告相关的内存泄漏;
经过另外的测试集群短时间的运行尝试进行复现,果然Valgrind报告未出现异常。
2. 分析现有拥有的条件:幸好,出现“内存泄漏”问题的Broker进程仍然在运行中,真相就在这个进程内部。应该充分利用已有的现场,完成问题的定位。初步希望使用GDB调试。
3. 挑战:使用GDB attach pid的方法将会导致进程挂起,按Broker的设计,一当配对另一个主/从Broker不互相发送心跳, Broker也将自动退出程序,退出后现场就无法保存,这意味着使用GDB的机会只有一次。
4. 方案:利用gdb打印内存信息并从信息中观察可能的内存泄漏点。
5. 步骤一:pmap -x {PID}查看内存信息(如:pmap -x 24671);得到类似如下信息,注意标记为anon的位置:
6. 步骤二:启动gdb ./bin/broker并使用 attach {PID}命令加载现有进程;例如上述进程号为24671,则使用:attach 24671;
7. 步骤三:使用setheight 0和 setlogging on开启gdb日志,日志将存储于gdb.txt文件中;
8. 步骤四:使用x/{内存字节数}a {内存地址} 打印出一段内存信息,例如上述的anon为堆头地址,占用了144508kb内存,则使用:x/18497024a0x000000000109d000;若命令行较多,可以在外围编辑好命令行直接张贴至gdb命令行提示符中运行,或者将命令行写到一个文本文件中,例如command.txt中,然后再gdb命令行提示符中使用 sourcecommand.txt来执行文件中的命令集合,下面是command.txt文件的内容;
9. 步骤五:分析gdb.txt文件中的信息,gdb.txt中的内容如下:
Gdb.txt中内容的说明和分析:第一列为当前内存地址,如0x22c2f00;第二、三、四列分别为当前内存地址对应所存储的值(使用十六进制表示),以及gdb的debug的符号信息,例如:0x10200d0<_ZTVN7bigpipe15BigpipeDIEngineE+16> 0x4600000001,分别表示:“前16字节”、“符号信息(注意有+16的偏移)”、“后16字节”,但不是所有地址都会打印gdb的debug符号信息,有时符号信息显示在第三列,有时显示在第二列。上述这行内存地址0x22c2f00 存储了bigpipe::BigpipeDiEngine 类的生成的其中一个对象的虚析构函数的函数指针,即虚函数表指针(vptr),其中地址0x10200d0附近内存存储的应该是BigpipeDiEngine类的虚函数表(vtbl),如下所示:
地址0x10200d0中的值是指向BigpipeDiEngine类的析构函数的地址,即真正的析构函数代码段头地址0x53e2c6。可以从上述执行结果看到,地址0x53e2c6的“符号信息”是析构函数名<bigpipe::BigpipeDIEngine::~BigpipeDIEngine()>,其汇编命令为push。因此,可以知道最初看到的0x22c2f00地址是对象的一个虚析构函数指针,并且有“符号信息”BigpipeDIEngine显示出来,可以根据这种信息确定出这个类(带虚析构函数的类)生成了多少个实例,然后根据排出来的实例个数做进一步判断。
| 因此,对gdb.txt排序并做适当处理获得符号(类名/函数名称)出现的次数的列表。例如将上述内容过滤出带尖括号的“符号信息”部分并按出现次数排序,可以使用类似如下命令,catgdb.txt | grep “<” | awk -F ‘<’ ‘{print $2}’ | awk -F ‘>’‘{print $1}’ | sort | uniq -c | sort -rn > result.txt,过滤出项目相关的变量前缀(如bmq、Bigpipe、bmeta等)cat result.txt | grep -P”bmq | Bigpipe | bigpipe | bmeta” | grep “_ZTV” > result2.txt,获得类似如下的列表: |
10. 然后找出和本工程项目相关的且出现次数最多的为CConnect对象;判断出可能泄漏的对象后,还需要定位在异步框架下,哪个引用计数出现了问题导致CConnect对象无法正常减一并得到释放。
11. 经过追查新增的“监控”功能与CConnect相关的代码,如下。
四、真相大白
查看atomic_add函数的实现(如下),可以得知,返回值是自增(减)之前的值,而由于函数名称atomic_add并未特别的表现出这样的含义,导致调用者误用了这个函数,认为是自增之后的值,最终引用计数误认为不为0,导致未执行_free操作,进而导致内存泄漏。通常,和__sync_fetch_and_add对应的函数还有__sync_add _and_fetch,这两者的区别在于“先获得值再加”还是“先加值在获取”。
五、解决方案
因此,程序的改进如下:
六、总结
1. 由于异步框架实现的程序对问题定位跟踪难度较高,需要综合:日志,gdb,pmap等手段完成问题复现和定位;
2. Valgrind检测内存泄漏并不是唯一的方法,且具有一定的局限性;
3. 函数名称定义尽量直观表明函数功能,能够避免调用方的一部分错误;
4. 应当仔细阅读库函数的说明文档,了解使用方法;
5. 本方法运用的场景和局限:1)使用gdb打印内存信息中,必须符合实例数和内存信息符号有一对一关系的情形,上述实践中CConnect类有虚析构函数,因此在内存信息中能查看到虚函数表指针,且和出现的符号有一一对应的关系,由此能作为内存泄漏存在于此类的推测条件;若泄漏的内存在内存信息中没有留下“痕迹”则无法获得内存泄漏的有效信息;2)在线下尝试内存泄漏复现失败后,但有内存泄漏的进程(现场)在线上仍然存在,可以尝试使用上述方法,从已有的进程(现场)中更多获取内存泄漏信息;3)此方法可以利用现有的已经产生内存泄漏的进程(现场)进行分析,充分利用了已有的问题进程;4)上述方法作为其他内存泄漏调试方法的一种补充,一种值得尝试的方法,可以作为参考。
以 test 程序为例,test.c 代码:
#include
#include
void main()
{
void* p = malloc(100);
if(NULL == p)
printf(“malloc failed.\n”);
printf(“—————- test end ————–\n”);
return;
}
编译生成test执行文件:
[root@localhost test]# gcc -o test test.c
用 valgrind 检查test是否有内存泄漏:
[root@localhost test]# valgrind –tool=memcheck –leak-check=full ./test
==9407== Memcheck, a memory error detector
==9407== Copyright (C) 2002-2010, and GNU GPL’d, by Julian Seward et al.
==9407== Using Valgrind-3.6.0 and LibVEX; rerun with -h for copyright info
==9407== Command: ./test
==9407==
—————- test end ————–
==9407==
==9407== HEAP SUMMARY:
==9407== in use at exit: 100 bytes in 1 blocks
==9407== total heap usage: 1 allocs, 0 frees, 100 bytes allocated
==9407==
==9407== 100 bytes in 1 blocks are definitely lost in loss record 1 of 1
==9407== at 0x4A05FDE: malloc (vg_replace_malloc.c:236)
==9407== by 0x400515: main (in /data/test/test)
==9407==
==9407== LEAK SUMMARY:
==9407== definitely lost: 100 bytes in 1 blocks
==9407== indirectly lost: 0 bytes in 0 blocks
==9407== possibly lost: 0 bytes in 0 blocks
==9407== still reachable: 0 bytes in 0 blocks
==9407== suppressed: 0 bytes in 0 blocks
==9407==
==9407== For counts of detected and suppressed errors, rerun with: -v
==9407== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 6 from 6)
[root@localhost test]#
检查到有100个字节的空间没释放:
==9407== definitely lost: 100 bytes in 1 blocks
如果是全局指针所指的内存没有释放,“still reachable” 提示,但 “definitely lost” 不提示,如下:
test.c 文件
#include
#include
void* p;
int main()
{
p = malloc(100);
//free(p);
return 0;
}
[root@localhost test]$ valgrind –tool=memcheck –leak-check=full ./test
==4696== Memcheck, a memory error detector
==4696== Copyright (C) 2002-2010, and GNU GPL’d, by Julian Seward et al.
==4696== Using Valgrind-3.6.0 and LibVEX; rerun with -h for copyright info
==4696== Command: ./test
==4696==
==4696==
==4696== HEAP SUMMARY:
==4696== in use at exit: 100 bytes in 1 blocks
==4696== total heap usage: 1 allocs, 0 frees, 100 bytes allocated
==4696==
==4696== LEAK SUMMARY:
==4696== definitely lost: 0 bytes in 0 blocks
==4696== indirectly lost: 0 bytes in 0 blocks
==4696== possibly lost: 0 bytes in 0 blocks
==4696== still reachable: 100 bytes in 1 blocks
==4696== suppressed: 0 bytes in 0 blocks
==4696== Reachable blocks (those to which a pointer was found) are not shown.
==4696== To see them, rerun with: –leak-check=full –show-reachable=yes
==4696==
==4696== For counts of detected and suppressed errors, rerun with: -v
==4696== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 6 from 6)
一,用valgrind定位程序问题
在排查程序问题时候,我们会经常用到gdb。gdb确实是定位程序问题的很有用的工具。但是很多时候我们用gdb来定位问题,会发现不好定位,花了很多时候把发生core的地方找到了,可是还是不知道为何会发生该错误—–因为常常产生core的地方是由于在core之前的错误导致的。
这时候别忘了另一个工具,那就是valgrind,根据我定位程序问题的经验,valgrind经常能给我惊喜。所以我觉得很有必要重视该工具,因为它确实能带给我们很多便利。
我这里不具体说valgrind的原理和使用,网上有一大堆相关文档,大家感兴趣的话可以在网上找相关资料。我这里只是具体针对我们QQ秀的情况做介绍:
1:使用valgrind定位cgi、fastcgi:
1)使用valgrind来定位cgi问题:
有两个前提条件:
A)cgi必须是可执行程序,这意味着定位fastcgi(动态库)时,需要把它编译成cgi(可执行文件)形式;
B)运行cgi时,需要配置环境变量(cgi的获取客户端请求是通过环境变量来读取请求包信息的),在qzthhp里面,对于cgi的环境变量,由qzhhtp来设置,现在我们需要单独跑cgi时,就需要我们自己配置环境变量了:
设置方法:
Ø 首先我们通过httpwatch获取请求包:
Ø 根据请求包配置环境变量:
export REQUEST_METHOD=POST
export QUERY_STRING=”parm1=1&parm2=2&…”
exportHTTP_COOKIE=”vid=1011255824;flv=9.0;pt2gguin=o0249694429;airkey=c14101efd87eb……”
export CONTENT_TYPE=””
export CONTENT_LENGTH=””
Ø 把cgi编译成可执行文件,运行:(譬如:qqshow_user_info)
valgrind –log-file-exactly=allen.log –tool=memcheck –leak-check=yes ./qqshow_user_info
PS: 如果是post方式,那run后会等待输入,直接把参数拷贝过来输入就ok了,如“parm1=1&parm2=2&…”, 输入完按Ctrl+D或回车键表示输入完成,程序继续run
Ø 分析allen.log,定位程序问题。
2)利用封装的valgrind工具leakscan来定位cgi、fastcgi
大家每天都会收到一封邮件《CGI内存泄漏扫描(QQShow)》,里面大概是报告下cgi/fasctgi的内存使用情况,尽管标题是“内存泄漏”,但是不单单报告内存泄漏情况;其实该邮件用到的检测工具就是valgrind,只是封装过的,它就是运维同学开发的工具leakscan。
前面讲到,我们自己手动配置运行cgi比较麻烦:1)fastcgi得重编成cgi;2)要配置一大堆环境变量;
而使用leakscan就不需要这些。该工具我已经安装在开发QQshow开发环境了,运行文件是:
/usr/local/services/leakscan/leakscan
运行该程序前,需要做的一件事就是把httpwatch的请求包另存为一个文件,譬如
qqshow_user_info.txt,通过crt上传到开发机,譬如在/home/user_00/下面,然后
cd /usr/local/services/leakscan/
./leakscan /usr/local/qqshow/cgi/cgi-bin/qqshow_user_info /home/user_00/qqshow_user_info.txt
2:使用valgrind定位server问题:
QQShow 的server,一般都是用servrbeach++(简称S++)平台组件来搭建,我们根据业务编写相应的插件。
通过修改S++配置文件能做到嵌入valgrind来分析server的问题;
以qqmail中转server为例子:
qqmail开发环境(172.23.2.199)server目录:/usr/local/services/qqmailserver/
配置文件:/usr/local/services/qqmailserver/etc/
qqmail_ctrl.xml
qqmail_proxy.xml
qqmail_worker.xml
如果我们要定位业务代码的问题,通过修改qqmail_ctrl.xml就可以做到,如图所示:
修改点:
1)加入valgrind:
exe=”./_valgrind –log-file=allen.log –tool=memcheck –leak-check=yes ./qqmail_worker”
PS:因为配置文件上basepath是bin目录,所以如果直接用valgrind会提示找不到该命令,我简单的在bin下面做个符号链接:
2)修改worker的个数:
因为我们只是定位问题,把worker的数目配置为1,便于我们定位问题,通过修改成 maxprocnum=”2” minprocnum=”1”就可以。
3)启动server,就能通过分析log-file来定位程序问题
PS:
1)运行valgrind会影响server的性能,并且输出valgrind分析日志,所以最好不要在外网这么做;
2)通过修改qqshow_ctrl.xml的方式嵌入valgrind时,可能在停止server时,该valgrind没法停止,这时候需要手动kill掉。
3)分析完毕后,记得把配置文件还原
二,外网cgi core文件分析:发生段错误导致堆栈破坏的core文件分析
外网的cgi一般都是非debug编译,而且经常由于段错误导致core,这时候用gdb来分析,会发现尽管有core文件,但是貌似给不了信息给我们,因为gdb分析没法知道core发生在哪。很多人做法是编译一个debug版本,然后通过打印日志来定位,这种方法相对来说有点消极。因为就算是破坏了堆栈的core文件,通过一些方式还是很有可能定位到core的地方的。下面介绍下分析的方法:
PS:该方法是km上的同学贡献的,我这里把他的文章汇总在这里:(robertyu发表于 2008-12-19 21:08)
如果有调试信息,gdb program core是很容易定位到位置的,除非把stack写乱。
但目前我们的cgi一般都没有调试信息(即编译时优化过,或者strip过),或者有时堆栈被写坏了,此时,上面的gdb program core不太容易定义到具体位置。
这里介绍一下通过异常点地址定义的方法:
1,gdb找到core的地址;
2,通过存活的同批/proc/PID/maps(linux2.6以后每次启动,地址有一点点随机,所以必须是同批次,除非禁止了此特性),或者info file找到cgi所在so的加载地址。如果不是cgi.so的问题,从这里也可以看的到。
注意,第一个是可执行段,属性为r-xp.第二个rw的为数据段。如果是其它段的异常,可以通过查看异常地址位于哪一个段里确定所属模块。
3,上述1-2得到异常的偏移;
0xb79c844f - 0xb7985000 = 0x4344f
4,objdump -D cgi-so >cgi.s反汇编。
5,用3的偏移(16进制)查找,即可找到异常的位置。
从上面可以看出,问题处在CFrameTTCClient::Get函数里。在gdb prog core里的最后一层,可以通过info reg命令看到当时的 esi=0,这是core的直接原因。根本原因这个bug上溯一层就查到了。
6,函数很小的化,很容易定位到问题。如果很大的话,看阅读asm的水平。所以建议多写小函数。
上述函数比较小,所以很快就定位到了问题。如果函数实在比较大,可以从asm里比较有特征的代码找到具体C/C++错误位置。如函数,比较,赋值等涉及的常数,字符串,典型C/C++代码编译为asm的特征等。
7,一般core的位置都不是错误的源头,但找到错误的位置及其特征之后,有助于定位问题的根源。
另外,由于优化过的代码(包括strip过),没有符号信息,尤其没有局部变量的信息,此时可以通过当时的reg及asm确定局部变量等的地址从而查看出变量的内容。这些内容有时非常有用。
Valgrind 使用
用法:valgrind options prog-and-args
-tool=
h -help 显示帮助信息。
-version 显示valgrind内核的版本,每个工具都有各自的版本。
q -quiet 安静地运行,只打印错误信息。
v -verbose 更详细的信息,增加错误数统计。
-trace-children=no|yes 跟踪子线程?[no]
-track-fds=no|yes 跟踪打开的文件描述?[no]
-time-stamp=no|yes 增加时间戳到LOG信息?[no]
-log-fd=
-log-file=
-log-file-exactly=
-log-file-qualifier= 取得环境变量的值来做为输出信息的文件名。[none]
-log-socket=ipaddr:port 输出LOG到socket,ipaddr:port
LOG信息输出
-xml=yes 将信息以xml格式输出,只有memcheck可用
-num-callers=
-error-limit=no|yes 如果太多错误,则停止显示新错误?[yes]
-error-exitcode=
-db-attach=no|yes 当出现错误,valgrind会自动启动调试器gdb。[no]
-db-command=
适用于Memcheck工具的相关选项:
| -leak-check=no | summary | full要求对leak给出详细信息? [summary] |
| -leak-resolution=low | med | high how much bt merging in leak check [low] |
| -show-reachable=no | yes show reachable blocks in leak check? [no] |
常用命令
Valgrind –tool=memcheck –leak-check=yes ./mx
Valgrind –leak-check=full ./mx
valgrind–tool=memcheck –leak-check=yes ./mx
弱网络环境的构造 traffic control
traffic control是一个很好的构造弱网络环境的工具,能够控制网络速率、丢包率、延时等网络环境,作为iproute工具集中的一个工具,由linux系统自带。但TC的配置规则很复杂,facebook在tc的基础上封装成了一个开源工具apc,有兴趣的可以试试。
WRK压力测试工具
WRK是一款非常优秀的开源HTTP压力测试工具,采用多线程 + 异步事件驱动的框架,其中事件机制使用了redis的ae事件框架,协议解析使用了nginx的相关代码。相比ab(apache bench)等传统压力测试工具的优点就是性能好,基本上单台机器发送几百万pqs,打满网卡都没有问题。 wrk的缺点就是只支持HTTP类协议,不支持其他协议类测试,比如protobuf,另外数据显示也不是很方便。
nginx的测试用法: wrk -t500 -c2000 -d30s https://127.0.0.1:8443/index.html
内存泄漏
valgrind的缺点
出现内存泄漏或者内存问题,大家第一时间都会想到valgrind.valgrind是一款非常优秀的软件,不需要重新编译程序就能够直接测试。能够检测常见的内存错误包括内存初始化、越界访问、内存溢出、free错误等都能够检测出来。推荐大家使用。
valgrind 运行的基本原理是:
待测程序运行在valgrind提供的模拟CPU上,valgrind会纪录内存访问及计算值,最后进行比较和错误输出
简单分享下valgrind测试nginx的经验:
nginx通常都是使用master fork子进程的方式运行,使用–trace-children=yes来追踪子进程的信息
测试nginx + openssl时,在使用rand函数的地方会提示很多内存错误。比如Conditional jump or move depends on uninitialised value,Uninitialised value was created by a heap allocation等。这是由于rand数据需要一些熵,未初始化是正常的。如果需要去掉valgrind提示错误,编译时需要加一个选项:-DPURIFY
如果nginx进程较多,比如超过4个时,会导致valgrind的错误日志打印混乱,尽量减小nginx工作进程,保持为1个。因为一般的内存错误其实和进程数目都是没有关系的。
但是valgrind也有一个非常大的缺点,就是它会显著降低程序的性能,官方文档说使用memcheck工具时,降低10-50倍。也就是说,如果nginx完全握手性能是20000 qps,那么使用valgrind测试,性能就只有400 qps左右。对于一般的内存问题,降低性能没啥影响,但是有些项目的内存泄漏是在大压力测试时才可能遇到的,如果性能降低这么明显,内存泄漏的错误有可能检测不出来。
AddressSanitizer的优点
address sanitizer(简称asan)是一个用来检测c/c++程序的快速内存检测工具。相比valgrind的优点就是速度快,官方文档介绍对程序性能的降低只有2倍。 对Asan原理有兴趣的同学可以参考asan的算法这篇文章,它的实现原理就是在程序代码中插入一些自定义代码,如下:
编译前:
*address = …; // or: … = *address;
编译后:
if (IsPoisoned(address)){
ReportError(address, kAccessSize, kIsWrite);
}
*address = …; // or: … = *address;`
和valgrind明显不同的是,asan需要添加编译开关重新编译程序,好在不需要自己修改代码。而valgrind不需要编程程序就能直接运行。
address sanitizer集成在了clang编译器中,GCC 4.8版本以上才支持。我们线上程序默认都是使用gcc4.3编译,于是我测试时直接使用clang重新编译nginx:
–with-cc=”clang” \ –with-cc-opt=”-g -fPIC -fsanitize=address -fno-omit-frame-pointer” 其中with-cc是指定编译器,with-cc-opt指定编译选项, -fsanitize=address就是开启AddressSanitizer功能。
由于AddressSanitizer对nginx的影响较小,所以大压力测试时也能达到上万的并发,内存泄漏的问题很容易就定位了。
性能热点分析
到此,经过改造的nginx程序没有core dump和内存泄漏方面的风险了。但这显然不是我们最关心的结果(因为代码本该如此),我们最关心的问题是:
- 代码优化前,程序的瓶颈在哪里?能够优化到什么程度?
- 代码优化后,优化是否彻底?会出现哪些新的性能热点和瓶颈?
这个时候我们就需要一些工具来检测程序的性能热点。
perf,gprof,systemtap
linux世界有许多非常好用的性能分析工具,我挑选几款最常用的简单介绍下:
- perf应该是最全面最方便的一个性能检测工具。由linux内核携带并且同步更新,基本能满足日常使用。推荐大家使用。
- gprof主要是针对应用层程序的性能分析工具,缺点是需要重新编译程序,而且对程序性能有一些影响。不支持内核层面的一些统计,优点就是应用层的函数性能统计比较精细,接近我们对日常性能的理解,比如各个函数时间的运行时间,,函数的调用次数等,很人性易读。
- systemtap 其实是一个运行时程序或者系统信息采集框架,主要用于动态追踪,当然也能用做性能分析,功能最强大,同时使用也相对复杂。不是一个简单的工具,可以说是一门动态追踪语言。如果程序出现非常麻烦的性能问题时,推荐使用 systemtap。
这里再多介绍一下perf命令,tlinux系统上默认都有安装,比如通过perf top就能列举出当前系统或者进程的热点事件,函数的排序。
perf record能够纪录和保存系统或者进程的性能事件,用于后面的分析,比如接下去要介绍的火焰图。
火焰图 flame graph
perf有一个缺点就是不直观。火焰图就是为了解决这个问题。它能够以矢量图形化的方式显示事件热点及函数调用关系。
比如我通过如下几条命令就能绘制出原生nginx在ecdhe_rsa cipher suite下的性能热点:
perf record -F 99 -p PID -g – sleep 10
| perf script | ./stackcollapse-perf.pl > out.perf-folded |
./flamegraph.pl out.perf-folded>ou.svg
直接通过火焰图就能看到各个函数占用的百分比,比如上图就能清楚地知道rsaz_1024_mul_avx2和rsaz_1024_sqr_avx2函数占用了75%的采样比例。那我们要优化的对象也就非常清楚了,能不能避免这两个函数的计算?或者使用非本地CPU方案实现它们的计算? 当然是可以的,我们的异步代理计算方案正是为了解决这个问题,
从上图可以看出,热点事件里已经没有RSA相关的计算了。至于是如何做到的,后面有时间再写专门的文章来分享。
OS X下热点函数分析工具
但是,我真的找不到OS X下能用的热点函数分析工具了。
所谓热点函数,就是运行时占用CPU较高的函数。
在Windows或Linux上,有VTune、有perf等等;但我所知道的这些都没有OS X的版本。
我要找的工具应该满足一下特性:
支持OS X
支持分析C/C++程序
具有一定的信息可视化功能,比如动态的数据图(如果能导出运行监控的报表就更好了)
最好是GUI程序,命令行也可以
可以是Xcode插件
