文件锁
1.文件锁可以对将要修改文件的某个部分进行加锁,精确控制到字节
通过fcntl()函数来进行设置文件锁
fcntl(int fd,int cmd,………);
参数:fd:文件描述符
cmd:F_GETLK:测试能否加锁(不过能加也不一定能加上,非原子操作。一般不用)
F_SETLK:对文件加锁,则立即出错返回
F_SETLKW:对文件加锁,不能加则阻塞
第三个参数为 strcuct flock 类型的结构体 如struct folct lock;
复制代码
1 lock.l_type = F_WRLCK; //加一把写锁 //F_RDLCK 读锁,F_UNLCK 释放锁
2 lock.l_whence=SEEK_SET; //相对头偏移 //SEEK_END SEEK_CUR
3 lock.l_start =0; //相对头偏移量为0
4 //lock.l_start=-5; //指针向左移5个字节开始
5
6 lock.l_len =5; //加锁的字节数
7 //lock.l_len =0; //从start之后所有内容都加锁,包括新写的。(通篇加锁)
复制代码
fctnl(fd,F_SETLKW,&lock);
2.解锁
lock.l_type=F_UNLCK;
fcntl(fd,F_SETLKW,&lock);
关闭文件会释放该进程在该文件上加的所有锁。
注意隐含释放,如:
newfd=dup (fd);
close(newfd) //依然会将该进程加的所有锁释放
原因:记录锁是以进程pid标示,并非以文件描述符,一旦检测到有关闭函数,则会检查有五该进程对应的文件锁并关闭。
lock 实现细节
能够实现进程的互斥,主要是依靠了内核里统一的资源入口控制
在flock 的 man page 中有关于 flock 细节的一些描述。其中说明了flock 是与打开文件的文件
表项相关联的。根据《Unix 环境高级编程》对打开文件的介绍,打开的文件在进程表和操作系统
中的对应的结构如下图所示:
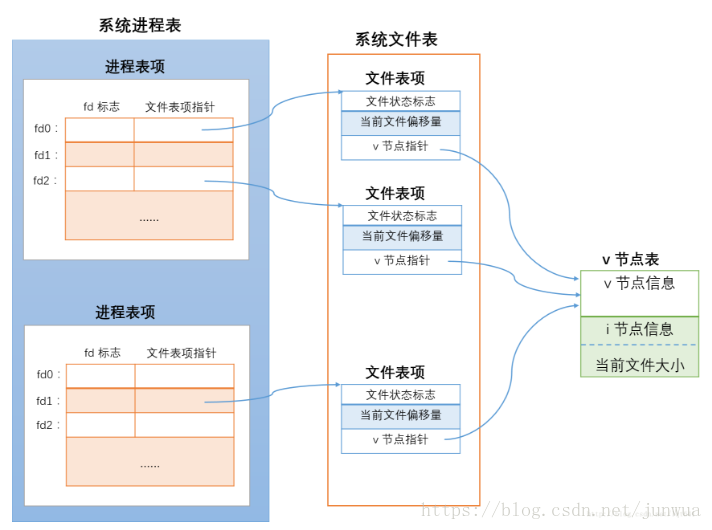
每个进程在进程表中都一个对应的项目,叫做进程表项,上图是最左边展示了进程表中两进程表项,
分别对应两个独立的进程。在进程表项中,有一个文件描述符表,其中存储了所有本进程打开的文件描述符
信息及指向对应文件表项的指针。而操作系统中,还另外有一张表,叫做文件表,其中存储的是系统中所有进
程打开的文件的相关信息,其中的项目叫做文件表项(上图中间蓝色部分)。
在进程表项的文件描述符表中每个描述符都对应一个文件表项指针,指向文件表中的一项。v 节点表中的项
目称为 v 节点表项,可以认为其中存储了真正的文件内容。
从图中可以看出,进程1对同一个文件打开了两次,分别对应本进程中的文件描述符 fd0 和 fd2。而下面的
进程对这个文件又打开了一次,对应此进程中的 fd1描述符。要注意的是,不论是同一进程还是不同的进
程,对同一文件打开时,都建立了与各fd 对应的独立的文件表项。
- 在flock 的man page 中关于文件表项有如下描述:
Locks created by flock() are associated with anopen file table entry
这说明进程使用 flock 对已打开文件加文件锁时,是加在了上图中间蓝色部分的文件表项上。假如图中位于下
方的进程对fd1 加上了排他锁,实际就是加在了fd1 指向的文件表项上,这时上方的进程对 fd0 或 fd2 再加任
何类型的文件锁都会失败。这是因为操作系统会检测到上方的两个文件表项和下方的文件表项都指向了相
同的 v 节点,并且下方的文件表项已经加了排他锁,这时如果其他指向相同v 节点的文件表项再想尝试加
上与原有锁类型不相容的文件锁时,操作系统会将此文件表项对应的进程阻塞。
3. 调用dup 、 fork、execve 时的文件锁
如果要了解用 dup 复制文件描述符时和使用 fork 产生子进程时的文件锁表现,就要了解在调用这两个函数时
,描述符对应的数据结构发生了哪些变化。
使用 dup 复制文件描述符
用 dup 复制文件描述符时,新的文件描述符和旧的文件描述符共享同一个文件表表项,示意图如下
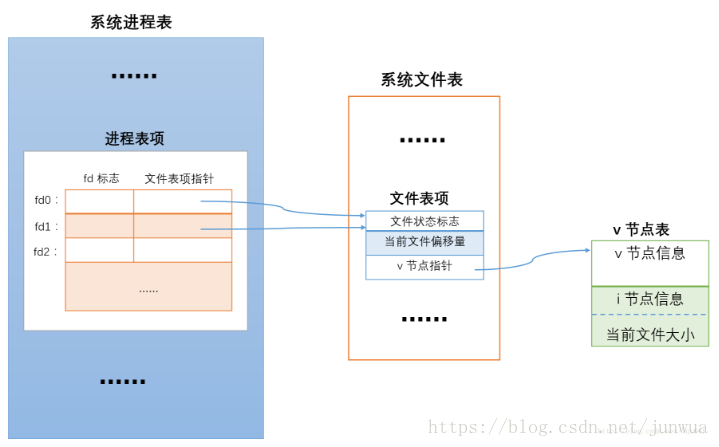
调用 dup 后,两个描述符指向了相同的文件表项,而flock 的文件锁是加在了文件表项上,因而如果对
fd0 加锁那么 fd1 就会自动持有同一把锁,释放锁时,可以使用这两个描述符中的任意一个。
4. execve函数族中的文件锁
在fork 产生子进程后,一般会调用 execve 函数族在子进程中执行新的程序。如果在调用 execve 之前,
子进程中某些打开的文件描述符已经持有了文件锁,那么在执行execve 时,如果没有设置 close-on-exec
标志,那么在新的程序中,原本打开的文件描述符依然会保持打开,原本持有的文件锁还会继续持有。
文件锁的解除
用 LOCK_UN 解锁
文件锁的解除可以通过将 flock 的 operation 参数设置为 LOCK_UN常量来实现。这时如果有多个fd 指向
同一文件表项,例如给 fd0 加文件锁后,用 dup 复制了fd0 的情况下,用 LOCK_UN对fd0 解锁后,所有
和 fd0 指向同一文件表项的 fd 都不再持有文件锁。fork 子进程复制父进程文件描述符的情形也是如此。
关闭文件时自动解解锁
对描述符fd加了文件锁后,如果没有显式使用LOCK_UN 解锁,在关闭 fd 时,会自动解除其持有的文件锁。
但是在为 fd 加锁后如果调用了dup 复制了文件描述符,这时关闭fd 时的表现和调用 LOCK_UN 是不一样的。
如果未显式使用 LOCK_UN解锁,在关闭文件描述符后,如果还有其他的fd 指向同一文件表项,比如之前调用
了dup 的情形,这时加在文件表项上的文件锁并不会解除,其他指向此文件表项的文件描述符依然持有锁,并且
锁的类型也不会发生变化。
使用fork 产生子进程时同样如此。父进程和子进程的描述符指向同一文件表项且已经加了文件锁时,如果用
LOCK_UN将其中一个fd 解锁,那么指向同一表项的所有其他fd 都会自动解锁。但是如果未使用 LOCK_UN
解锁,只是通过 close(fd)关闭了某个文件描述符,那么指向同一文件表项的其他描述符,依然会持有原有的锁。
出于方便考虑,在没有出现多个fd 指向现一文件表项的情况下,可以直接使用close(fd) 的默认解锁功能,
而不用显式的使用LOCK_UN。在有多个 fd 指向同一文件表项的情形下,如果要完全解锁,一定要使用
LOCK_UN 解锁,不能再使用 close(fd) 的默认解锁功能
在多数unix系统中,当多个进程/线程同时编辑一个文件时,该文件的最后状态取决于最后一个写该文件的进程。
对于有些应用程序,如数据库,各个进程需要保证它正在单独地写一个文件。这时就要用到文件锁。
文件锁(也叫记录锁)的作用是,当一个进程读写文件的某部分时,其他进程就无法修改同一文件区域。
能够实现文件锁的函数主要有2个:flock和fcntl。
早期的伯克利版本只支持flock,该函数只能对整个文件加锁,不能对文件的一部分加锁。
lockf是在fcntl基础上构造的函数,它提供了一个简化的接口。它们允许对文件中任意字节区域加锁,短至一个字节,长至整个文件。
fcntl函数
#include
int fcntl(int fd, int cmd, …/struct flock *flockptr/);
#返回值:若成功,返回值依赖于cmd,失败返回-1
1
2
3
4
cmd是F_GETLK, F_SETLK, F_SETLKW中的一个。第三个参数是指向flock结构的指针,flock结构如下:
struct flock {
short l_type;/* one of F_RDLCK, F_WRLCK, F_UNLCK /
short l_whence;/ SEEK_SET, SEEK_CUR, SEEK_END /
off_t l_start;/ offset in bytes, relative to l_whence /
off_t l_end;/ length, in bytes, 0 means lock to EOF /
off_t l_pid;/ returned with F_GETLK */
};
1
2
3
4
5
6
7
其中,
锁类型:共享读锁F_RDLCK,独占性写锁F_WRLCK,解锁F_UNLCK
加锁或解锁区域的起始字节偏移量(l_start, l_whence)
区域字节长度(L_len)
进程的id持有的锁能阻塞当前进程,仅由F_GETLK返回
锁可以在文件尾处开始或者越过尾端开始,但是不能在文件起始位置之前开始
若l_len=0, 表示锁的范围可以扩大到最大可能偏移量,这意味着不管向文件中追加多少数据,它们都可以处于锁的范围内,而且起始位置可以任意
设置l_start和l_whence指向文件的起始位置,并且指定l_len=0,以实现对整个文件加锁(一般l_start=0, l_whence=SEEK_SET)
锁的使用
使用锁的基本规则:
任意多个进程在一个给定的字节上可以有一把共享的读锁(F_RDLCK),但是在一个给定的字节上只能有一个进程有一把独占性写锁(F_WRLCK)
如果在一个给定字节上已经有一把或多把读锁,则不能在该字节上再加写锁,如果在一个字节上已经有一把独占性写锁,则不能再对它加任何读锁
对于单个进程而言,如果进程对某个文件区域已经有了一把锁,然后又试图在相同区域再加一把锁,则新锁会替换旧锁
加读锁时,该描述符必须是读打开,加写锁时,该描述符必须是写打开
fcntl三种cmd的使用:
F_GETLK:判断由flockptr所描述的锁是否会被另一把锁所排斥(阻塞),如果存在一把锁阻止创建由flockptr所描述的锁,由该现有锁的信息将重写flockptr指向的信息。如果不存在这种情况,则除了将l_type设置为F_UNLCK之处,flockptr所指向结构中的其他信息保持不变
F_SETLK:设置由flockptr所描述的锁,如果程序试图获得一把锁,而系统阻止程序获得该锁,则fcntl会立即返回错误,errno设置为EACCES或EAGAIN。当l_type=F_UNLCK时,此命令用来清除指定的锁
F_SETLKW:F_SETLK的阻塞版本(wait)。如果程序尝试获得的锁无法被授予,调用进程会进入休眠直到进程获得锁或者信号中断
注意:用F_GETLK 测试能否创建一把锁,然后用F_SETLK尝试建立锁之间并非原子操作,也就是说两次调用之间有可能另一进程插入并创建了相同的锁。如果不希望在等待锁变为可用时产生阻塞,就必须处理由F_SETLK返回的可能出错值
下面是测试一把锁的例子:
#include
#include
#include
#include
pid_t lock_test(int fd, int type, off_t offset, int whence, off_t len)
{
struct flock lock;
lock.l_type = type;
lock.l_start = offset;
lock.l_whence = whence;
l ock.l_len = len;
if (fcntl(fd, F_GETLK, &lock) < 0) {
printf("fcntl error: %s\n", strerror(errno));
return 1;
}
if (lock.l_type == F_UNLCK) {
return 0;
}
return lock.l_pid; } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 锁的继承与释放 锁的继承和释放有以下三条原则:
锁与进程和文件两者相关联。即当一个进程终止时,它所建立的所有锁均释放,对于描述符而言,无论它何时关闭,进程通过它引用的文件上的任何一把锁也都会释放
由fork产生的子进程不继承父进程所设置的锁
执行exec后,新程序可以继承原程序的锁。注意,如果对一个文件描述符设置了执行时关闭标志,那么当作为exec的一部分关闭该文件描述符时,将释放相应文件的所有锁
避免死锁
如果两个进程互相等待对方持有并且不释放的资源时,这两个进程就会进入死锁状态。
如果一个进程已经控制了文件中的一个加锁区域,然后它又试图对另一个进程控制的区域加锁,那么它就会进入睡眠,并有可能发生死锁。
检测到死锁时,内核必须选择一个进程接收错误返回。
总结
在多进程或多线程环境中,当多个应用需要读写同一个文件时,需要考虑对文件加锁,以保证对文件修改的一致性。
在使用文件锁时,应明确应用模式,防止死锁。
更多关于文件锁的使用细节,请参考《UNIX环境高级编程》。
如何避免多进程/多客户端并发写同一日志文件可能出现的异常?
flock + seek 使用方法
问题现象
文件存储 NAS 为多客户端提供了统一名字空间的文件共享读写能力,但在多进程/多客户端并发写同一个文件的场景中(典型的例如并发写同一个日志文件),各进程分别维护了独立的文件描述符及写入位置等上下文信息,而 NFS 协议本身并没有提供Atomic Append语义的支持,因此可能会出现写覆盖、交叉、串行等异常现象,推荐的解决方案有两种:
(推荐)不同进程/客户端写入同一文件系统的不同文件中,后续分析处理时再进行归并,这个方案能够很好地解决并发写入导致的问题,同时无需使用文件锁,不会对性能造成影响。
对于并发追加写同一个文件(如日志)的场景,可以使用文件锁 + seek 机制来保证写入的原子性和一致性。但是文件锁 + seek 是一个比较耗时的操作,可能会对性能产生显著的影响。下面将对这种方式进行一个简单的介绍,以供参考。
flock + seek 使用方法
由于 NFS 协议本身没有提供对 Atomic Append 语义的支持,因此当并发写入同一文件末尾(如日志)时,很可能会出现相互覆盖的情况。在 Linux 中,通过使用 flock + seek 的方式,可以在 NFS 文件系统上做到模拟 Atomic Append,对并发追加写入同一文件提供保护和支持。
使用方式如下:
调用 fd = open(filename, O_WRONLY | O_APPEND | O_DIRECT) 以追加写的方式打开文件,并且指定 O_DIRECT(直写,不通过 Page Cache),获得文件描述符 fd。
调用 flock(fd, LOCK_EX|LOCK_NB) 尝试获取文件锁,如果获取失败(如锁已被占用)则会返回错误,此时可以继续重试或进行错误处理。
文件锁获取成功后,调用 lseek(fd, 0, SEEK_END) 将 fd 当前的写入偏移定位到文件末尾。
执行正常的 write 操作,此时写入位置应该是文件的末尾,并且由于有文件锁的保护,不会出现并发写入相互覆盖的问题。
写操作执行完成后,调用 flock(fd, LOCK_UN) 释放文件锁。
下面是一个简单的 C 语言示例程序,仅供参考:
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#include<sys/file.h>
#include
const char *OUTPUT_FILE = “/mnt/blog”;
int WRITE_COUNT = 50000;
int do_lock(int fd)
{
int ret = -1;
while (1)
{
ret = flock(fd, LOCK_EX | LOCK_NB);
if (ret == 0)
{
break;
}
usleep((rand() % 10) * 1000);
}
return ret;
}
int do_unlock(int fd)
{
return flock(fd, LOCK_UN);
}
int main()
{
int fd = open(OUTPUT_FILE, O_WRONLY | O_APPEND | O_DIRECT);
if (fd < 0)
{
printf(“Error Open\n”);
exit(-1);
}
for (int i = 0; i < WRITE_COUNT; ++i)
{
char *buf = “one line\n”;
/* Lock file */
int ret = do_lock(fd);
if (ret != 0)
{
printf("Lock Error\n");
exit(-1);
}
/* Seek to the end */
ret = lseek(fd, 0, SEEK_END);
if (ret < 0)
{
printf("Seek Error\n");
exit(-1);
}
/* Write to file */
int n = write(fd, buf, strlen(buf));
if (n <= 0)
{
printf("Write Error\n");
exit(-1);
}
/* Unlock file */
ret = do_unlock(fd);
if (ret != 0)
{
printf("UnLock Error\n");
exit(-1);
}
}
return 0; } 更详细的 flock()
一、问题还原
在多进程的环境下,父子进程同时去写一个文件,例如父进程每次写入aaaaa,子进程每次写入bbbbb,问题是会不会出现写操作被打断的现象,比如出现aabbbaaabb这样交替的情况?
二、结论
1:使用write系统调用的情况下,不会出现内容交叉的情况。
2:使用fwriteANSIC标准C语言函数,会出现内容交叉的情况。
1:为什么write不会出现问题但是fwrite却出现了问题?
答:write是Linux操作系统的系统调用,fwrite是ANSIC标准的C语言库函数,fwrite在用户态是有缓冲区的。因此需要锁机制来保证并发环境下的安全访问。
http://www.cnblogs.com/ldp-web/archive/2011/10/21/2220180.html
2:如果两个进程同时write一个socket会怎样?
答:就像队列一样,一个进程写完另一个进程才能写,数据上不会有问题。
http://stackoverflow.com/questions/1981372/are-parallel-calls-to-send-recv-on-the-same-socket-valid
多进程写同一个日志并发问题分析
在优化日志组件项目中有如下场景:两个进程,A、B进程往同一个文件写日志的时候,使用C语言的库函数写,fopen文件追加方式打开, fwrite等。如果每一次写的时候都强制fflush操作,则写的时序是正常的。如果不是每次fflush操作的时候,则会出现写入日志的时候的时序问题,即是A进程的一条日志没打完,B进程的日志中间插进来了。
问题分析
原子性
系统调用
先从最基本的系统调用说起,磁盘IO效率的简单分析,该篇的问题2中提到,如果是系统调用,多进程需要保证写磁盘有序,则需要open的时候使用O_APPEND选项,其本质是open的时候,写磁盘的时候会锁住文件的inode节点,全局唯一,所以进程间可以实现互斥。
库函数IO
对于C语言的库函数而言,它在系统调用的上层,做了一层缓冲。之所以自己做一层缓冲,是为了提升IO效率,在用户空间就对数据进行缓冲,最终使用合并写操作,以提升IO的效率。而多进程同时写文件的时候,由于flush的时机,由库函数自动决定,因此,多进程状态下,存在刷新操作的非原子性问题。
追问
库函数的追加写不是通过O_APPEND方式打开的吗?为什么这里刷新操作为什么不是原子的, 底层不是通过锁定innode方式实现的吗?
Write原子性
系统调用原子性
O_APPEND进行open的文件而言,系统调用,它能够保证原子性,在系统调用的过程之中,不会有其他系统调用打断它
写数据的原子性
这里有个非常重要的概念,write函数原型如下:ssize_t write(int fd, const void *buf, size_t count);它有个返回值,它表示此次调用成功写入了多少个字节。在这些成功写入的字节中,它是原子的。并不是你写1G缓冲,write就给你保证这1G数据就原子性写入磁盘,不要太天真!
flush的非原子性
通过上面的分析,我们知道,flush操作的时候,缓冲区中的数据,它是调用write系统调用来写磁盘,写入的数据能保证原子性。但是,但是,这里的缓冲区数据,它未必能够保证一次性全部写完。即是A、B进程都有1K字节缓冲区,调用write一次写1K字节,可能返回500字节,那此时,B进程可以调用write写入500字节,A再写完剩下的500字节,再写剩下的B进程的500字节。这种情况下,那么,flush操作则会导致日志的乱序,原因找到。
如何优化
对于日志组件而言,在多进程并发写的情况下,一个优化方式无非就是合并写,但这里利用库函数做合并,flush的时候存在并发问题。如何解决?
解决方案
手动加锁刷新
通过手动刷新代替库函数的自动刷新,在缓冲区满之前,手动加上进程锁进行刷新操作。例如:满100条日志的时候,就手动刷新一次。但这里会存在一个问题,当流量特别小的时候,日志会特别久才出来一次,何解?且看方案二
定时线程刷新
每一个进程创建一个分离线程,进行定时刷新,例如:每一秒钟刷新一次。这样就能解决小流量调试的时候,日志的查看及时度问题
