TCMalloc
在tcmalloc内存管理的体系之中,一共有三个层次:ThreadCache、CentralCache、PageHeap
分配内存和释放内存的时候都是按从前到后的顺序,在各个层次中去进行尝试。基本思想是:前面的层次分配内存失败,则从下一层分配一批补充上来;前面的层次释放了过多的内存,则回收一批到下一层次。
这几个层次从前到后,主要有这么几方面的变化:
线程私有性:ThreadCache,顾名思义,是每个线程一份的。理想情况下,每个线程的内存需求都在自己的ThreadCache里面完成,线程之间不需要竞争,非常高效。而CentralCache和PageHeap则是全局的;
内存分配粒度:在tcmalloc里面,有两种粒度的内存,object和span。span是连续page的内存,而object则是由span切成的小块。object的尺寸被预设了一些规格(class),比如16字节、32字节、等等,同一个span切出来的object都是相同的规格。object不大于256K,超大的内存将直接分配span来使用。ThreadCache和CentralCache都是管理object,而PageHeap管理的是span。
ThreadCache
比较简单,最主要的逻辑是维护一组FreeList,针对每一种class的object;
CentralCache
里面有多个CentralFreeList,针对每一种class的object。
CentralFreeList并不像ThreadCache那样直接维护object的链表,而是维护span的链表,每个span下面再挂一个由这个span切分出来的object的链。这样做便于在span内的object是否都已经free的情况下,将span整体回收给PageHeap(span.refcount_记录了被分配出去的object个数)。但是这样一来,每个回收回来的object都需要寻找自己所属的span,然后才能挂进freelist,过程会比较耗时。
所以CentralFreeList里面还搞了一个cache(tc_slots_),回收回来的一批object先往cache里面塞,塞不下了再回收进span的objects链。分配object给ThreadCache时也是先尝试在cache里面拿,没了再去span里面分配。
多少个object算做是一批?这都是预定义好的(称作batch_size,比如32个),不同的class可能有不同的值。ThreadCache向CentralCache分配和回收object时,都尽量以batch_size为一个批次。而为了cache的简单高效,如果批次个数不等于batch_size,则会绕过cache。
另外,CentralFreeList里的span链表其实是有两个:nonempty_和empty_,根据span的objects链是否有空闲,放入对应链表。这样就避免了在分配时去判断span是否为空,只需要在由空变非空、或者由非空变空时移动一下span。
PageHeap
维护了两个很重要的东西
:page到span的映射关系,和空闲span的伙伴系统。
当应用free()一个地址的时候,怎么知道该把它对应的object放回哪里去呢?tcmalloc里面并没有针对object的控制结构,要解决这个问题,page到span的映射关系至关重要。地址值经过地址对齐,很容易知道它属于哪一个page。再通过page到span的映射关系就能知道object应该放到哪里。span.sizeclass记录了span被切分成的object属于哪一个class,那么属于这个span的object在free时就应该放到ThreadCache对应class的FreeList上面去;如果object需要放回CentralCache,直接把它挂到对应span的objects链表上即可。
page到span的映射关系通过radix tree来实现,逻辑上可以把它理解为一个大数组,以page的值作为偏移,就能访问到page所对应的节点。这个节点上面其实就是一个指针,指向这个page所对应的span(注意,可能有多个page指向同一个span,因为span的尺寸可能不止一个page)。
为减少查询radix tree的开销,PageHeap还维护了一个最近最常使用的若干个page到class(span.sizeclass)的对应关系cache。为了保持cache的效率,cache只提供64K个固定坑位,旧的对应关系会被新来的对应关系替换掉。
空闲span的伙伴系统为上层提供span的分配与回收。当需要的span没有空闲时,可以把更大尺寸的span拆小(如果大的span都没有了,则需要重新找kernel分配);当span回收时,又需要判断相邻的span是否空闲,以便将它们组合。判断相邻span还是要用到radix tree,radix tree就像一个大数组,很容易取到当前span前后相邻的span。
span的尺寸有从1个page到255个page的所有规格,所以span总是可以按任意尺寸进行拆分和组合(当然是page粒度的)。大于255个page的span单独归为一类,不作细分。
伙伴系统的freelist其实是有两个链,normal和returned,以区别活跃跟不活跃的内存。PageHeap并不会将内存释放给kernel,因为它们之间的交互都是针对一批连续page的,要想回收到整批的page,可能性很小。在PageHeap里面,多余的内存会放到returned里面去,跟normal做一下隔离。这样一来,normal的内存总是优先被使用,kernel倾向于一直保留它们。而returned的内存则不常被使用,kernel在内存不够的时候会优先将它们swap掉。
其实不用returned也能完成这样的事情,因为normal是个链表,每次分配回收总是作用在链表头上,那么链表内的span本身就按从热到冷的顺序排序了。链表尾部的span如果长期不被使用,不管是否移动到returned链,kernel都会倾向于将它们swap掉。不过,span进入returned时,tcmalloc还附加了一个操作,madvise(MADV_DONTNEED),试图告诉kernel这个内存已经不用了(kernel具体会怎么做,那就是另外一回事了)。
所以,在伙伴系统中分配span时,会有三个过程:优先在normal链中分配、尝试未果则在returned链中分配、还搞不定就向kernel去申请新的内存。
在PageHeap里面,还有一个PageHeapAllocator,专门用于分配各种控制结构的内存,比如span、ThreadCache、等。可见,在tcmalloc里面控制结构与object是分离的。而object自身并不需要额外的控制结构,当它被分配时,它的所有内存空间都服务于使用者;而当它空闲时,它的第一个8Byte空间被当作链表指针,链在各种freelist里面。
分配回收过程
再通过malloc和free两个过程把上述逻辑串起来看一看:
alloc
根据分配size,判断是小块内存还是大块内存(256K为界);
小块内存:
通过size得到对应的class;
先尝试在ThreadCache.list_[class]的FreeList里面分配,分配成功则直接返回;
尝试在CentralCache里面分配batch_size个object,其中一个用于返回,其他的都加进ThreadCache.list_[class];
拿到class对应的CentralFreeList;
尝试在CentralFreeList.tc_slots_[]里面分配(CentralFreeList.used_slots_是空闲slot游标);
尝试在CentralFreeList.nonempty_里面分配,尽量分配batch_size个object。但最后只要分配了多于一个object,即可返回;
如果CentralFreeList.nonempty_为空,则要向PageHeap去申请一个span。对应的class申请的span应该包含多少个连续page,这个也是预设好的。拿到span之后将其拆分成N个object,然后返回前面所需要的object;
PageHeap先从伙伴系统对应npages的span链表里面查找空闲的span(优先查normal链、然后returned链),有则直接返回;
在更大npages的span里面查找空闲的span(优先查normal链、然后returned链),有则将其拆小,并返回所需要的span;
向kernel申请若干个page的内存(可能大于npage),返回所需要的span,其他的span放回伙伴系统;
大块内存:
直接向PageHeap去申请一个刚好大于等于请求size的span。申请过程与小块内存走到这一步时的过程一致;
free
通过释放的ptr,在PageHeap维护的映射关系中,找到对应span的class(先尝试在cache里面找,没有再查radix tree,然后插入cache。cache里面自动淘汰老的项)。class为0代表ptr指向的是大块内存;
小块内存:
将ptr指向的内存释放到ThreadCache.list_[class]里面;
如果ThreadCache.list_[class]长度超过阈值(FreeList.length_>=FreeList.max_length_),或者ThreadCache的容量超过阈值(ThreadCache.size_>=ThreadCache.max_size_),则触发回收过程。两种情况分别针对class对应的FreeList,和ThreadCache下面的所有FreeList进行回收(具体的策略后续再讨论);
object被回收到CentralCache里面class对应的CentralFreeList上。先尝试batch_size个object的整块回收,CentralFreeList会试图将其释放到自己的cache里面去(tc_slots_);
如果cache装满,或者凑不满batch_size个整数的object,则单个回收,回收进其对应的span.objects。这个回收过程不必拿着object在CentralFreeList的span链表中逐个去寻找自己对应的span,而是通过PageHeap中的对应关系直接找到span;
如果span下面的object都已经回收了(refcount_减为0),则进一步将其释放回PageHeap;
在radix tree中找到span之前和这后的span,如果它们空闲且也在normal链上,则进行合并;
PageHeap将多余的span回收到其对应的returned链上,然后继续考虑span之间的合并(要求span都在returned链上)(具体策略后续再讨论);
大块内存:
ptr对应的直接就是一个span,直接将其释放回PageHeap即可;
回收策略
tcmalloc的主要数据结构基本上就是这些了。上面讨论的时候,有一个细节一直没深入:每一个层次在空闲量达到一定阈值的时候,会向下做一次释放。那么这个阈值该怎么定呢?
CentralCache => PageHeap
span从CentralCache回收到PageHeap的过程比较简单,只要一个span里面的object都空闲了,就将它回收到PageHeap;
normal => returned
在PageHeap中,span从normal链表回收到returned链表的过程则略复杂一些:
考虑到这个过程是很偏避的一个逻辑,span是否移到returned链表对整体性能而言差别并不会太大,所以尽量lazy。基本思路是,每当PageHeap回收到N个page的span时(这个过程中可能伴随着相当数目的span分配),触发一次normal到returned的回收,只回收一个span。
这个N值初始化为1G内存的page数,每次回收span到returned链之后,可能还会增加N值,但是最大不超过4G。
触发回收的过程也比较简单,每次进来轮询伙伴系统中的一个normal链表,将链尾的span回收即可。
这里面没有判断normal链是否应该被回收,如果回收了不该回收的span,后续的分配过程会把span从returned链里面捞回来。否则span将长期呆在returned链里面。
ThreadCache => CentralCache
ThreadCache是tcmalloc的核心,它里面的FreeList长度控制还是比较复杂的。
前面提到过,FreeList长度超过限额和ThreadCache容量超过限额,这两种情况下会触发object回收。考虑到应用程序的多样性,这两个限额不能是定死的,必需得自适应:有些线程对内存的需求可能远多于其他一些线程、有些线程可能总是在分配内存而另一些线程则总是释放内存(生产者消费者)、等等。
先来看ThreadCache的容量限额,其思想是:为每一个ThreadCache初始化一个比较小的限额,然后每当ThreadCache由于cache超限而触发object到CentralCache的回收时,就增大该ThreadCache的限额。有限额增大,就应该有限额回收。tcmalloc预设了一个所有ThreadCache的总容量,当ThreadCache需要增大容量时,如果总容量尚有余额,则使用这些余额。否则需要增大的容量就从其他线程的ThreadCache里面去收刮(具体从收刮哪个线程的容量,简单采用了轮询的方式)。这样一来,只需要在ThreadCache内存回收时做一些简单的处理,就能实现ThreadCache的容量的自适应:内存需求大的线程总是收刮别人的容量,而内存需求低的线程则总是被收刮。当然,收刮与被收刮并不是无节制的,会有一个最大值最小值的限制,比如128字节~4M。
到达ThreadCache的容量限额时,会对它下面的每一个FreeList进行回收,回收的数目是该Freelist.lowator_的一半。什么是lowator_呢?就是该Freelist在ThreadCache超限的两次回收周期之间内,FreeList的最小长度。也就是说,在上一个周期中,FreeList里面有lowator_个object是从未被用到的。通过这一历史信息,可以预估在下一次回收到来时,可能也有lowator_个object可能不会被用到。不过保守一点,只回收lowator_的一半。
回收过程其实只是对每一个FreeList的保守回收,回收完成之后ThreadCache的容量可能还会继续高于限额,不过随着这次回收,ThreadCache的容量限额也会被抬高。
下一个问题是单个FreeList的限额,tcmalloc采用慢启动策略,每个FreeList初始时长度限额为1。在限额为1~batch_size之间时,为慢启动状态。此时,不管是alloc遇到空FreeList、还是free遇到长度超限,都给限额加1。这样做可以给不常用或者使用很规律的object确定一个合适的限额,而如果object的使用抖动较大的话,应该给它一个更大的buffer。
如果限额增加达到batch_size,则慢启动状态结束。此时,如果alloc遇到空FreeList,限额会按batch_size的整数倍进行扩展。而如果free超限,则限额将按照batch_size的整数倍进行缩减。
alloc遇到空FreeList(说明FreeList的限额达不到线程的分配需求),应该不断增加限额,这个好理解。那么free超限的情况下,为什么慢启动状态下要增加限额,非慢启动状态则要减少限额呢?如果free总是超限,说明线程对object的free要多于alloc,线程之间对该object的分配回收很可能是不对称的。那么作为专职回收的那个线程,没必要给他留大的限额,因为它的分配需求很少。而慢启动状态下超限还给限额做加1递增,一方面可以应对抖动,另一方面递增限额的目的是使之能够达到batch_size(如果free确实远多于alloc话),从而在回收object时可以按batch_size批量回收。
FreeList限额超限的处理比较简单,直接回收batch_size个object即可(不足batch_size个,则有多少回收多少)。可见,处于慢启动状态下的FreeList限额超限,将导致FreeList被清空。
| TCMalloc 的全局分配器,处于 TCMalloc 的最底层,负责向操作系统申请和释放内存,接口有两个,定义在 src/system-alloc.h | .cc: |
extern void* TCMalloc_SystemAlloc(size_t bytes, size_t actual_bytes,
size_t alignment = 0);
extern bool TCMalloc_SystemRelease(void start, size_t length);
TCMalloc_SystemAlloc 的参数,除了要申请的大小 bytes,还有 actual_bytes 和 alignment,因为对齐的需求,该接口可能分配大于 bytes 的内存,实际大小保存在 actual_bytes。TCMalloc_SystemRelease 负责『释放』内存,至于释放为什么加引号,下面会提到。接下来,介绍下这两个接口的实现。
malloc-extension.h 里面,定义了接口类 SysAllocator,该类只有一个接口:
class SysAllocator {
public:
SysAllocator() {}
virtual ~SysAllocator();
virtual void* Alloc(size_t size, size_t *actual_size, size_t alignment) = 0;
};
system-alloc.cc 里面,对 SysAllocator 有三个实现:SbrkSysAllocator, MmapSysAllocator, DefaultSysAllocator。SbrkSysAllocator 和 MmapSysAllocator 分别使用 sbrk 和 mmap 向系统分配内存,这两个类没有任何数据成员。DefaultSysAllocator 是 前两种 Allocator 的委托:
class SbrkSysAllocator : public SysAllocator {
public:
SbrkSysAllocator() : SysAllocator() {
}
void* Alloc(size_t size, size_t *actual_size, size_t alignment);
};
class MmapSysAllocator : public SysAllocator {
public:
MmapSysAllocator() : SysAllocator() {
}
void* Alloc(size_t size, size_t *actual_size, size_t alignment);
};
class DefaultSysAllocator : public SysAllocator {
public:
DefaultSysAllocator() : SysAllocator() {
for (int i = 0; i < kMaxAllocators; i++) {
failed_[i] = true;
allocs_[i] = NULL;
names_[i] = NULL;
}
}
void SetChildAllocator(SysAllocator* alloc, unsigned int index,
const char* name) {
if (index < kMaxAllocators && alloc != NULL) {
allocs_[index] = alloc;
failed_[index] = false;
names_[index] = name;
}
}
void* Alloc(size_t size, size_t actual_size, size_t alignment);
private:
static const int kMaxAllocators = 2;
bool failed_[kMaxAllocators];
SysAllocator allocs_[kMaxAllocators];
const char* names_[kMaxAllocators];
};
static char sbrk_space[sizeof(SbrkSysAllocator)];
static char mmap_space[sizeof(MmapSysAllocator)];
static char default_space[sizeof(DefaultSysAllocator)];
在 libtcmalloc 初始化的时候,使用 new 操作符的 placeholder 形式,分别在 sbrk_space, mmap_space, default_space 上面初始化这三个 Allocator。然后调用 DefaultSysAllocator 的 SetChildAllocator 接口,将 SbrkSysAllocator 和 MmapSysAllocator 设置成待用分配器:
void InitSystemAllocators(void) {
MmapSysAllocator mmap = new (mmap_space) MmapSysAllocator();
SbrkSysAllocator *sbrk = new (sbrk_space) SbrkSysAllocator();
DefaultSysAllocator *sdef = new (default_space) DefaultSysAllocator();
if (kDebugMode && sizeof(void) > 4) {
sdef->SetChildAllocator(mmap, 0, mmap_name);
sdef->SetChildAllocator(sbrk, 1, sbrk_name);
} else {
sdef->SetChildAllocator(sbrk, 0, sbrk_name);
sdef->SetChildAllocator(mmap, 1, mmap_name);
}
sys_alloc = tc_get_sysalloc_override(sdef);
}
DefaultSysAllocator 的 Alloc 接口是这样实现的:
void* DefaultSysAllocator::Alloc(size_t size, size_t actual_size,
size_t alignment) {
for (int i = 0; i < kMaxAllocators; i++) {
if (!failed_[i] && allocs_[i] != NULL) {
void result = allocs_[i]->Alloc(size, actual_size, alignment);
if (result != NULL) {
return result;
}
failed_[i] = true;
}
}
// After both failed, reset “failed_” to false so that a single failed
// allocation won’t make the allocator never work again.
for (int i = 0; i < kMaxAllocators; i++) {
failed_[i] = false;
}
return NULL;
}
先后尝试使用 SbrkSysAllocator 和 MmapSysAllocator 分配内存,如果某个分配器分配失败,则标记相应的 failed_ 域,下次便不从这个分配器分配内存。如果全部失败,则返回 NULL,同时清除 failed_ 域,以免无法恢复。TCMalloc_SystemAlloc 函数分配内存时候,调用全局的 sys_alloc->Alloc() 即可。
关于全局内存的分配要介绍的就这么多,至于 SbrkSysAllocator 和 MmapSysAllocator 的 Alloc 实现细节,但凡对 sbrk 和 mmap 了解的人一猜就知道了。
下面介绍下内存的释放。可以注意到,前面的 Allocator 只有 Alloc 接口,并没有一个 Release 或者 Free 接口,那么内存是怎么释放的呢?事实上,TCMalloc 从来不释放内存!
那么,TCMalloc_SystemRelease 做些什么呢?我们知道,无论是 brk,还是 mmap,申请的都是虚拟内存,物理内存是由内核在缺页中断时按需分配的。TCMalloc_SystemRelease 并没有调用 sbrk 和 munmap 将虚拟内存『归还』给操作系统,而是调用 madvise 系统调用。
#if !defined(MADV_FREE) && defined(MADV_DONTNEED)
define MADV_FREE MADV_DONTNEED
#endif
bool TCMalloc_SystemRelease(void* start, size_t length) {
#ifdef MADV_FREE
const size_t pagemask = pagesize - 1;
size_t new_start = reinterpret_cast
size_t end = new_start + length;
size_t new_end = end;
// Round up the starting address and round down the ending address
// to be page aligned:
new_start = (new_start + pagesize - 1) & ~pagemask;
new_end = new_end & ~pagemask;
if (new_end > new_start) {
int result;
do {
result = madvise(reinterpret_cast<char*>(new_start),
new_end - new_start, MADV_FREE);
} while (result == -1 && errno == EAGAIN);
return result != -1; } #endif return false; } 因为 Linux 不支持 MADV_FREE,所以使用了 MADV_DONTNEED。使用 MADV_DONTNEED 调用 madvise,告诉内核这段内存今后『很可能』用不到了,其映射的物理内存尽管拿去好了! 因此,TCMalloc_SystemRelease 只是告诉内核,物理内存可以回收以做它用,但虚拟空间还留着。 那么,是不是 TCMalloc 永远不会归还虚拟空间呢?一般来说,是的。但当虚拟空间耗尽,或者虚拟空间有碎片,无法满足内存需要时,TCMalloc 会试图合并,然后把所有空闲的虚拟空间归还,然后从新分配。 所谓内存碎片,就是有一部分内存不能够分配给程序使用,因为它们以碎片的方式存在。内存碎片可以分两种,内部碎片和外部碎片,内部碎片是分配器分配的内存大于程序申请的内存,外部碎片是内存块太小,无法分配给程序使用。 首先是 free-list,通过链表,把内存中空闲块连接起来。分配的时候,找到大小合适的 Block,把它切分成两块,一块是待分配的大小,另一块放回 free-list;释放的时候,插入到链表中,并且合并一下前后的内存块方便下次分配。
分配的时候,选择哪块内存进行分裂?第一个满足大小的?还是大小最合适的?通常有 First-Fit、Next-Fit、Best-Fit这几种策略。
放回的时候,也有多种策略,可以直接放回链表头部(Last In First Out),最省事;或者按照地址顺序放回(Address-Ordered),使得链表中的空闲块都按照地址顺序排列。
free-list的内部碎片来自于固定大小的头部和尾部,用来记录内存块的大小以及这块内存的空闲与否,否则无从得知一个内存块的大小,以及前一个内存块的地址,后一个内存块的地址,也就无从进行内存合并了。
free-list的外部碎片则取决于分配和释放策略。通常来说,First-Fit策略会使得链表前面的大块内存被频繁分裂,从而造成较多的内存碎片;Best-Fit的内存碎片较少;放回时,采用Address-Ordered顺序能够增加内存合并的机会,相比于 LIFO 的碎片会更少。
这里有一个很有意思的策略是Address-Ordered。先看一下LIFO的情况:
首先这些内存块都是按地址排序的,3和5是空闲的,4是已分配的,3指向5。现在分别申请了3和5的内存,然后又释放了3和5,得到第二幅图的情况,指针变成了5指向3,因为直接把 3 和 5 插入到链表头部,LIFO策略。接下来再申请 3字节内存,按照 First-Fit策略,就会把 5的内存进行分裂。
如果采用Address-Ordered策略,放回3和5时,指针顺序还是从3指向5。那么再次申请3字节内存时,直接分配原有的3,而不需要分裂5的内存。
一些研究表明,采用Address-Ordered策略能够显著降低内存碎片,不过其实现较为复杂,释放内存的复杂度较高。
内存碎片-Segregated-Freelist
上面的 Freelist 都可以申请和释放任意大小的内存块,而将大的内存块和小的内存块放在一起很容易带来内存碎片,因此就有了 Segregated-Freelist,每个 Freelist 存储不同大小的内存块。
在Seglist中,就无需 Boundary-Tag 去存储内存块的大小信息了,只需要实现从地址到Seglist的映射即可,例如TCMalloc中使用的PageMap就是一种方式。
看起来可以减少内部碎片,但是问题随之而来,每个Freelist都存储固定大小的内存块,如果申请9字节数据,可能就要分配16字节,带来的内存碎片反而更多了!因此,虽然按照2的幂级数去分配是一种很简单的策略,但是它并不高效。解决方案也有不少,例如分配 2^N 和 3*2^N 的内存块。
至于外部碎片的问题,Seglist也同样存在,不过不是那么明显。因为在分配Freelist的时候,通常按照内存 Page为单位,如果块大小不是 Page 的约数,就会有外部碎片了。
Segregated-Freelist 还有一个变种,称之为 Segregated-Fit。每个Freelist 不再是存储固定大小的内存块,而是存储一定范围的内存块。大名鼎鼎的 Doug Lea内存分配其(dlmalloc)就使用了这种策略。
内存碎片-Buddy-System
伙伴系统也是一种很经典的分配算法。
按照一分为二,二分为四的原则,直到分裂出一个满足大小的内存块;合并的时候看看它的 Buddy 是否也为空闲,如果是就可以合并,可以一直向上合并。
伙伴系统的优势在于地址计算很快,对于一个内存块的地址,可以通过位运算直接算出它的 Buddy,Buddy 的 Buddy,因此速度很不错。
不过考虑内存碎片,它并没有什么优势,像图中的这种经典的 Binary Buddy,全部都是2的幂级数,内部碎片还是会达到 50%。当然也有一些其他的优化,块大小可以是3的倍数之类的。
内存分配算法的比较
对于以上的几种算法,实际会产生的内存碎片会有多少呢,有人专门做过测试比较:
Frag#3和Frag#4分别是两种不同的度量方法,一个是分配器申请内存最大时,程序分配的内存和分配器申请的内存,另一个是程序最大申请的内存和分配器最大申请的内存。测试时使用了实际的程序进行模拟,例如GCC之类内存开销较大的程序。
这里有几个比较夸张的值,例如simple seg的1468%,这是因为碎片率的度量仅仅考虑分配器申请的内存和程序分配的内存,存在一定误差。不过对于 best fit AO来说,其内存碎片显然是相当少的,而一些在我们看来比较朴素的算法,first fit,其内存碎片率其实也相当低,反而是 buddy system 和 segregated list 比较尴尬。
不过这篇文章说明的核心观点是,只要选择了合适的策略,其内存碎片就完全不用担心,只要关心实现的性能就可以了,程序员也不用再手写内存分配器什么的了。
TCMalloc的内存碎片
TCMalloc采用了 Segregated-Freelist 的算法,提前分配好多种 size-class,在64位系统中,通常就是 88 种,那么问题来了,这个怎么计算?
首先看一下结果:8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176……
TCMalloc 的目标是最多 12.5% 的内存碎片,按照上面的 size-class算一下,例如 [112, 128),碎片率最大是 (128-112-1)/128 = 11.7%,(1152-1024-1)/1151 = 11.02%。当然结果是满足 12.5% 这一目标的。
要生成一批满足碎片率的 size-class 其实也有多种方法,比如,[x, y)区间内,只要满足 (y-x-1)/y <= 0.125即可,即 y <= 8/7*(x+1),从前往后递推一下就可以得到这些结果了,另外再考虑一下字节对齐什么的,就可以得到不错的结果。
不过 TCMalloc 从另一个角度来考虑这个问题的:从 size 到 size-class,需要进行一次向上对齐(round-up),例如 17 对齐到32;其实也是进行了一次字节对齐(Alignment),把 17 以 16 字节进行对齐,(17 + 15) / 16 * 16 = 32。
那么,内存碎片率其实就是 (Alignment-1) / SizeClass。那么我们只需要保证每个SizeClass它的 Alignment 满足 (Alignment-1)/SizeClass <= 0.125 就能满足需求了。
例如,对于 size-class 1024,下一个size-class 就是 1024 + 1024 / 8 = 1152,其中 Alignment 是1024/8=128;那么1152,我们是按照 1152/8=144,还是按照128计算 Alignment 呢,我们选一个比较好看的数字 128 计算出下一个 size-class。好吧,为什么是128呢,因为是把 1152 向下对齐到了2的幂级数1024,(这里的原因我就不是那么清楚了)。得到的代码如下:
func InitSizeClass() []int {
alignment := 8
classToSize := make([]int, 0, 88)
for size := alignment; size <= 256*1024; size += alignment {
alignment = align(size)
classToSize = append(classToSize, size)
}
return classToSize
}
代码非常简单,不过省略了 align 这个函数的实现:
func align(size int) int {
aligment := 8
if size > 256*1024 {
aligment = PageSize
} else if size >= 128 {
aligment = (1 « uint32(lgfloor(size))) / 8
} else if size >= 16 {
aligment = 16
}
if aligment > PageSize {
aligment = PageSize
}
return aligment
}
计算 Alignment 的时候,大于 256 × 1024就按照Page进行对齐;最小对齐是8;在128到256×1024之间的,按照 1«lgfloor(size) / 8进行对齐。等等,说好的向下取整到 2的幂级数然后除以8呢?
其实 lgfloor 就是用二分查找,向下对齐到2的幂级数的:
func lgfloor(size int) int {
n := 0
for i := 4; i >= 0; i– {
shift := uint32(1 « uint32(i))
if (size » shift) != 0 {
size »= shift
n += int(shift)
}
}
return n
}
先看左边16位,有数字的话就搜左边,否则搜右边。。。
到这里,基本上完成了 size-class的计算(TCMalloc 还有一个优化)。
TCMalloc的外部碎片
上面的 size-class 保证了内部碎片基本在 12.5%以下,但是外部碎片呢?
外部碎片是因为 CentralCache 在向 PageHeap 申请内存的时候,以 Page 为单位进行申请。举个例子,对于 size-class 1024,以一个Page(8192)申请,完全没有外部碎片;但是对于 size-class 1152,就有 8192 % 1152 = 128 的碎片。为了保证外部碎片也小于 12.5%,可以一次多申请几个Page,但是又不能太多造成浪费。
func numMoveSize(size int) int {
if size == 0 {
return 0
}
num := 64 * 1024 / size
return minInt(32768, maxInt(2, num))
}
func InitPages(classToSize []int) []int {
classToPage := make([]int, 0, NumClass)
for _, size := range classToSize {
blocksToMove := numMoveSize(size) / 4
psize := 0
for {
psize += PageSize
for (psize % size) > (psize » 3) {
psize += PageSize
}
if (psize / size) >= blocksToMove {
break
}
}
classToPage = append(classToPage, psize»PageShift)
}
return classToPage
}
这里计算出来的结果,就是每个 size-class 每次申请的 Page 数量,保证12.5%以下的外部碎片。
到这里基本能够保证内部碎片和外部碎片都在 12.5% 以下了,但 TCMalloc 还没有就此止步。。
size-class的合并
在我们上面计算出来的size-class中存在一些冗余,比如 1664,1792。它们都是一次申请2个Page,1664 可以分配出 8 * 1024 * 2 / 1664 = 9 个对象,1792也是可以分配出 8 * 1024 * 2 / 1792 = 9 个对象,那么,区分这两个 size-class有意义吗?1664浪费的内存是 810242%1664=1408, 1792浪费的内存是 810242%1792=256,1792浪费的内存反而更少一点。因此都保留并不能让这2 个Page 发挥更大的价值,所以,我们干脆把这两个合并了,仅仅保留 1792,结果并不会更差。
不过还有一个问题,如果我们计算一下[1536, 1792)的碎片,会发现 (1792-1536+1) / 1792 = 14.28% ,怎么大于 12.5 % 了?略尴尬。这也意味着,申请 1537字节,它的实际碎片率是 (81922 - (81922/1792*1537)) / (8192 * 2) = 15.57%,还是大于了 12.5% 的承诺。。
这里会发现,虽然内部碎片小于 12.5%,外部碎片也小于 12.5%,但是它们加在一起就大于12.5%了,很悲伤的故事。。不知道 Sanjay是有意为之,还是无心之过。
size到size-class
还有一个小的问题,如何从size 计算出 size-class。最简单的最大是二分查找,用std::upper_bound 就可以搞定,不过对于88个size-class,O(LogN)需要7次查找,还是有些多,随之带来的 cache miss 可能又会加剧问题。
另一个方法是打表,因为所有size-class都是至少8字节对齐的,我们把 256×1024 所有 8 字节对齐的数都打表,就能用O(1)的复杂度查找到 size-class,不过这种方法略废内存,cache locality可能也不会太好;观察一下发现,大于1024的 size-class 其实都以128对齐,那么这个表就可以分两段,小于1024和大于1024,省了很多内存。具体的计算就不再赘述。
首先是 free-list,通过链表,把内存中空闲块连接起来。分配的时候,找到大小合适的 Block,把它切分成两块,一块是待分配的大小,另一块放回 free-list;释放的时候,插入到链表中,并且合并一下前后的内存块方便下次分配。
分配的时候,选择哪块内存进行分裂?第一个满足大小的?还是大小最合适的?通常有 First-Fit、Next-Fit、Best-Fit这几种策略。
放回的时候,也有多种策略,可以直接放回链表头部(Last In First Out),最省事;或者按照地址顺序放回(Address-Ordered),使得链表中的空闲块都按照地址顺序排列。
free-list的内部碎片来自于固定大小的头部和尾部,用来记录内存块的大小以及这块内存的空闲与否,否则无从得知一个内存块的大小,以及前一个内存块的地址,后一个内存块的地址,也就无从进行内存合并了。
free-list的外部碎片则取决于分配和释放策略。通常来说,First-Fit策略会使得链表前面的大块内存被频繁分裂,从而造成较多的内存碎片;Best-Fit的内存碎片较少;放回时,采用Address-Ordered顺序能够增加内存合并的机会,相比于 LIFO 的碎片会更少。
这里有一个很有意思的策略是Address-Ordered。先看一下LIFO的情况:
首先这些内存块都是按地址排序的,3和5是空闲的,4是已分配的,3指向5。现在分别申请了3和5的内存,然后又释放了3和5,得到第二幅图的情况,指针变成了5指向3,因为直接把 3 和 5 插入到链表头部,LIFO策略。接下来再申请 3字节内存,按照 First-Fit策略,就会把 5的内存进行分裂。
如果采用Address-Ordered策略,放回3和5时,指针顺序还是从3指向5。那么再次申请3字节内存时,直接分配原有的3,而不需要分裂5的内存。
一些研究表明,采用Address-Ordered策略能够显著降低内存碎片,不过其实现较为复杂,释放内存的复杂度较高。
内存碎片-Segregated-Freelist
上面的 Freelist 都可以申请和释放任意大小的内存块,而将大的内存块和小的内存块放在一起很容易带来内存碎片,因此就有了 Segregated-Freelist,每个 Freelist 存储不同大小的内存块。
在Seglist中,就无需 Boundary-Tag 去存储内存块的大小信息了,只需要实现从地址到Seglist的映射即可,例如TCMalloc中使用的PageMap就是一种方式。
看起来可以减少内部碎片,但是问题随之而来,每个Freelist都存储固定大小的内存块,如果申请9字节数据,可能就要分配16字节,带来的内存碎片反而更多了!因此,虽然按照2的幂级数去分配是一种很简单的策略,但是它并不高效。解决方案也有不少,例如分配 2^N 和 3*2^N 的内存块。
至于外部碎片的问题,Seglist也同样存在,不过不是那么明显。因为在分配Freelist的时候,通常按照内存 Page为单位,如果块大小不是 Page 的约数,就会有外部碎片了。
Segregated-Freelist 还有一个变种,称之为 Segregated-Fit。每个Freelist 不再是存储固定大小的内存块,而是存储一定范围的内存块。大名鼎鼎的 Doug Lea内存分配其(dlmalloc)就使用了这种策略。
内存碎片-Buddy-System
伙伴系统也是一种很经典的分配算法。
按照一分为二,二分为四的原则,直到分裂出一个满足大小的内存块;合并的时候看看它的 Buddy 是否也为空闲,如果是就可以合并,可以一直向上合并。
伙伴系统的优势在于地址计算很快,对于一个内存块的地址,可以通过位运算直接算出它的 Buddy,Buddy 的 Buddy,因此速度很不错。
不过考虑内存碎片,它并没有什么优势,像图中的这种经典的 Binary Buddy,全部都是2的幂级数,内部碎片还是会达到 50%。当然也有一些其他的优化,块大小可以是3的倍数之类的。
内存分配算法的比较
对于以上的几种算法,实际会产生的内存碎片会有多少呢,有人专门做过测试比较:
Frag#3和Frag#4分别是两种不同的度量方法,一个是分配器申请内存最大时,程序分配的内存和分配器申请的内存,另一个是程序最大申请的内存和分配器最大申请的内存。测试时使用了实际的程序进行模拟,例如GCC之类内存开销较大的程序。
这里有几个比较夸张的值,例如simple seg的1468%,这是因为碎片率的度量仅仅考虑分配器申请的内存和程序分配的内存,存在一定误差。不过对于 best fit AO来说,其内存碎片显然是相当少的,而一些在我们看来比较朴素的算法,first fit,其内存碎片率其实也相当低,反而是 buddy system 和 segregated list 比较尴尬。
不过这篇文章说明的核心观点是,只要选择了合适的策略,其内存碎片就完全不用担心,只要关心实现的性能就可以了,程序员也不用再手写内存分配器什么的了。
TCMalloc的内存碎片
TCMalloc采用了 Segregated-Freelist 的算法,提前分配好多种 size-class,在64位系统中,通常就是 88 种,那么问题来了,这个怎么计算?
首先看一下结果:8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176……
TCMalloc 的目标是最多 12.5% 的内存碎片,按照上面的 size-class算一下,例如 [112, 128),碎片率最大是 (128-112-1)/128 = 11.7%,(1152-1024-1)/1151 = 11.02%。当然结果是满足 12.5% 这一目标的。
要生成一批满足碎片率的 size-class 其实也有多种方法,比如,[x, y)区间内,只要满足 (y-x-1)/y <= 0.125即可,即 y <= 8/7*(x+1),从前往后递推一下就可以得到这些结果了,另外再考虑一下字节对齐什么的,就可以得到不错的结果。
不过 TCMalloc 从另一个角度来考虑这个问题的:从 size 到 size-class,需要进行一次向上对齐(round-up),例如 17 对齐到32;其实也是进行了一次字节对齐(Alignment),把 17 以 16 字节进行对齐,(17 + 15) / 16 * 16 = 32。
那么,内存碎片率其实就是 (Alignment-1) / SizeClass。那么我们只需要保证每个SizeClass它的 Alignment 满足 (Alignment-1)/SizeClass <= 0.125 就能满足需求了。
例如,对于 size-class 1024,下一个size-class 就是 1024 + 1024 / 8 = 1152,其中 Alignment 是1024/8=128;那么1152,我们是按照 1152/8=144,还是按照128计算 Alignment 呢,我们选一个比较好看的数字 128 计算出下一个 size-class。好吧,为什么是128呢,因为是把 1152 向下对齐到了2的幂级数1024,(这里的原因我就不是那么清楚了)。得到的代码如下:
func InitSizeClass() []int {
alignment := 8
classToSize := make([]int, 0, 88)
for size := alignment; size <= 256*1024; size += alignment {
alignment = align(size)
classToSize = append(classToSize, size)
}
return classToSize
}
代码非常简单,不过省略了 align 这个函数的实现:
func align(size int) int {
aligment := 8
if size > 256*1024 {
aligment = PageSize
} else if size >= 128 {
aligment = (1 « uint32(lgfloor(size))) / 8
} else if size >= 16 {
aligment = 16
}
if aligment > PageSize {
aligment = PageSize
}
return aligment
}
计算 Alignment 的时候,大于 256 × 1024就按照Page进行对齐;最小对齐是8;在128到256×1024之间的,按照 1«lgfloor(size) / 8进行对齐。等等,说好的向下取整到 2的幂级数然后除以8呢?
其实 lgfloor 就是用二分查找,向下对齐到2的幂级数的:
func lgfloor(size int) int {
n := 0
for i := 4; i >= 0; i– {
shift := uint32(1 « uint32(i))
if (size » shift) != 0 {
size »= shift
n += int(shift)
}
}
return n
}
先看左边16位,有数字的话就搜左边,否则搜右边。。。
到这里,基本上完成了 size-class的计算(TCMalloc 还有一个优化)。
TCMalloc的外部碎片
上面的 size-class 保证了内部碎片基本在 12.5%以下,但是外部碎片呢?
外部碎片是因为 CentralCache 在向 PageHeap 申请内存的时候,以 Page 为单位进行申请。举个例子,对于 size-class 1024,以一个Page(8192)申请,完全没有外部碎片;但是对于 size-class 1152,就有 8192 % 1152 = 128 的碎片。为了保证外部碎片也小于 12.5%,可以一次多申请几个Page,但是又不能太多造成浪费。
func numMoveSize(size int) int {
if size == 0 {
return 0
}
num := 64 * 1024 / size
return minInt(32768, maxInt(2, num))
}
func InitPages(classToSize []int) []int {
classToPage := make([]int, 0, NumClass)
for _, size := range classToSize {
blocksToMove := numMoveSize(size) / 4
psize := 0
for {
psize += PageSize
for (psize % size) > (psize » 3) {
psize += PageSize
}
if (psize / size) >= blocksToMove {
break
}
}
classToPage = append(classToPage, psize»PageShift)
}
return classToPage
}
这里计算出来的结果,就是每个 size-class 每次申请的 Page 数量,保证12.5%以下的外部碎片。
到这里基本能够保证内部碎片和外部碎片都在 12.5% 以下了,但 TCMalloc 还没有就此止步。。
size-class的合并
在我们上面计算出来的size-class中存在一些冗余,比如 1664,1792。它们都是一次申请2个Page,1664 可以分配出 8 * 1024 * 2 / 1664 = 9 个对象,1792也是可以分配出 8 * 1024 * 2 / 1792 = 9 个对象,那么,区分这两个 size-class有意义吗?1664浪费的内存是 810242%1664=1408, 1792浪费的内存是 810242%1792=256,1792浪费的内存反而更少一点。因此都保留并不能让这2 个Page 发挥更大的价值,所以,我们干脆把这两个合并了,仅仅保留 1792,结果并不会更差。
不过还有一个问题,如果我们计算一下[1536, 1792)的碎片,会发现 (1792-1536+1) / 1792 = 14.28% ,怎么大于 12.5 % 了?略尴尬。这也意味着,申请 1537字节,它的实际碎片率是 (81922 - (81922/1792*1537)) / (8192 * 2) = 15.57%,还是大于了 12.5% 的承诺。。
这里会发现,虽然内部碎片小于 12.5%,外部碎片也小于 12.5%,但是它们加在一起就大于12.5%了,很悲伤的故事。。不知道 Sanjay是有意为之,还是无心之过。
size到size-class
还有一个小的问题,如何从size 计算出 size-class。最简单的最大是二分查找,用std::upper_bound 就可以搞定,不过对于88个size-class,O(LogN)需要7次查找,还是有些多,随之带来的 cache miss 可能又会加剧问题。
另一个方法是打表,因为所有size-class都是至少8字节对齐的,我们把 256×1024 所有 8 字节对齐的数都打表,就能用O(1)的复杂度查找到 size-class,不过这种方法略废内存,cache locality可能也不会太好;观察一下发现,大于1024的 size-class 其实都以128对齐,那么这个表就可以分两段,小于1024和大于1024,省了很多内存。具体的计算就不再赘述。
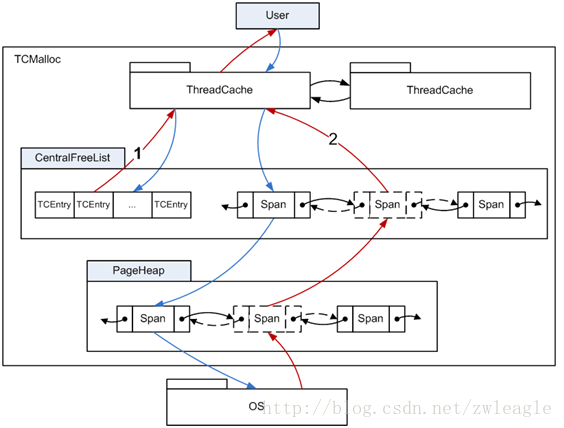
TCMalloc是专门对多线并发的内存管理而设计的,TCMalloc主要是在线程级实现了缓存,使得用户在申请内存时大多情况下是无锁内存分配。整个 TCMalloc对小内存(小于等于256k)的管理实现了三级缓存,分别是ThreadCache(线程级缓存),Central Cache(中央缓存:CentralFreeeList),PageHeap(页缓存)。小内存的分配和释放流程如下图所示,红线表示内存的申请,蓝线表示内存的释放过程。下面将分别介绍各级缓存模块的实现。
一. SizeMap
在介绍三个缓存模块之前,先需要介绍一下sizeMap。
TCMalloc为了提高内存分配效率和减少内存的浪费,对小内存进行了细化分类,在默认的情况下:
size在(0, 16)之间时,以8字节对齐分配内存,size在[16,128)之间,按16字节对齐来分配内存,size在[128,256*1024),按(2^(n+1)-2^n)/8字节对齐来分配内存(n的值为log2(size)取整,见函数AlignmentForSize())。
TCMalloc对这些细化分类构建了两个映射表,即class_array_[kClassArraySize]和class_to_size_[kNumClasses]。class_array_[kClassArraySize]表示了size到class的映射关系(size需要先经过函数ClassIndex(size)转换),class_to_size_[kNumClasses]表示了class到size的映射关系。要申请一个size的内存时,先从class_array_[ClassIndex(size)]查到size对应的sizeclass,然后从映射表class_to_size_[kNumClasses]获取实际获取的内存大小。
同时TCMalloc另外维护了两种映射表:class_to_pages_[kNumClasses]和num_objects_to_move_[kNumClasses]。class_to_pages_[kNumClasses]表示了Central Cache每次从PageHeap获取内存时,对应的sizeclass每次需要从PageHeap获取几页内存;num_objects_to_move_[kNumClasses]表示了ThreadCache每次从Central Cache获取内存时,对应的sizeclass每次需要从Central Cache获取的buffer(Object)个数。
二. 线程缓存ThreadCache
ThreadCache是线程缓存的对象,每个线程都有一个ThreadCache对象作为本线程的内存缓存池,当线程需要申请内存时,就从自己的ThreadCache中获取。所有线程的ThreadCache通过双向链表(next_,prev_)连接起来,链表头是静态变量ThreadCache::thread_heaps_ 。
线程对本线程的ThreadCache的访问采用线程私有数据的接口进行访问,线程的私有数据有两种实现方式:
1. 静态局部缓存线程私有数据,通过关键字static __thread定义一个静态变量,这个在TCMalloc由编译宏HAVE_TLS来控制;
2. 动态线程私有数据,通过POSIX接口pthread_key_create,pthread_setspecific,pthread_getspecific来实现。
静态局部缓存的优点是设置和读取的速度非常快,比动态方式快很多,但是也有它的缺点。
主要有如下两个缺点:
1. 静态缓存在线程结束时没有办法清除;而动态线程私有数据在创建key时,就可以注册释放线程数据的接口(TCMalloc注册的接口DestroyThreadCache),当线程退出时会调用这个接口对线程的私有数据进行清理,即可以释放掉线程申请的资源。
2. 不是所有的操作系统都支持。
tcmalloc采用的是动态局部缓存,但同时检测系统是否支持静态方式,如果支持那么同时保存一份拷贝,方便快速读取。
