livenessProbe
通用tcp探活原理
其实,探活原理特别简单,只要稍懂计算机网络就能够理解。
检测端 发起tcp三次握手,建立新连接,连接建立成功代表服务活着,建立失败代表服务死了,之后发送rst包主动断开连接。
被检测端 接受检测端发送的三次握手手建立连接,当接收到检测端的rst包后,被检测端断开连接,释放资源。
但是假如rst包丢失了,会发生什么样的情况呢?我们以thrift为例讲述一下之后所发生的事情,如下图所示。
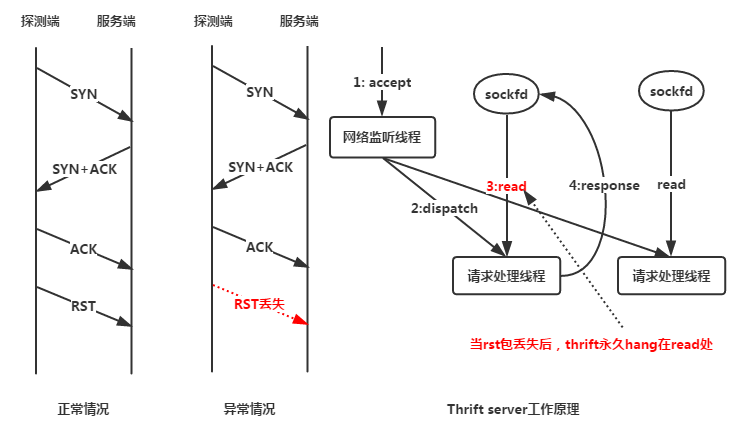
经过三次握手后,服务端已经建立一个新的数据连接,并把连接丢给工作线程。服务端的工作线程监听连接,并准备接收请求(毕竟,任何一个thrift服务都是先接收请求数据,之后进行计算,最后返回响应数据,所以当新连接建立后,thrift默认首先读取连接上的数据)。
检测端建立连接成功后,认为下游服务还活着,所以立刻发送rst包(检测端认为这个rst包一定会到达被检测服务),并且释放连接资源。
但是如果网络状态不好,rst包丢失,那么服务端(被检测端)的工作线程就会无限制的hang在读取连接数据上(因为检测端已经单方面认为连接断开,不会写任何数据,所以服务端也读不到任何数据)。如果多丢几个rst包,那可以预期无论你有多少thrift工作线程,都将会hang死。
此时真正调用服务的客户端的请求也无限制的hang住,因为这些请求得不到thrift工作线程的处理。
最最可怕的是:由于探活只是单纯的建立连接而并不发送或者接受额外数据,并且thrift服务有单独的线程进行accept,这导致了连接建立每次都成功,但实际上服务已经没有了计算能力。
最后的结局就是:整个系统流量突然降低,下游接收不到请求(以为是上游调用的锅),上游发出的请求得不到响应(认为是下游服务的锅),并且没有报警短信发出(以为是运维的锅),对排查问题造成很大的困扰。
出现这种问题时有一个非常明显的现象:即使在系统流量为0的情况下,服务端也会不断有新连接建立并处于Establish状态(这是因为周期性的探活导致的),并且服务端日志不滚动,客户端请求无响应。如果你的系统有这种情况,那么多半和探活有关。
我当时遇到的情况比较糟糕,因为之前一段时间rst丢包率特别低,平均几天丢一个rst包,所以服务hang死造成的影响并不大,只要抽空重新启动服务即可。可是突然某一天,单台服务的rst丢包数达到了秒级:隔几秒丢一个rst包,导致我的服务短时间内全部hang死。
HTTP探活原理
在实际工作中,对于HTTP服务的探活通常也采取TCP探活原理,毕竟HTTP建立在TCP服务之上,所以TCP探活同样适用于HTTP服务。很多HTTP服务实现原理和thrift大同小异,所以当TCP探活的rst包丢失后,HTTP服务同样会hang在读取连接数据。
为了避免rst包丢失,HTTP服务通常使用HTTP探活请求:探测端对被探测端发送特定的HTTP请求,并且验证被探测端的响应数据是否符合预期。如果rst包丢失,服务端连接最差的情况下会处于TIME_WAIT状态,经过2倍超时时间后服务端会主动关闭连接释放资源,这样服务端的工作线程不会长时间的被占用,相比于用TCP探活要好的多。HTTP探活原理如下图所示。
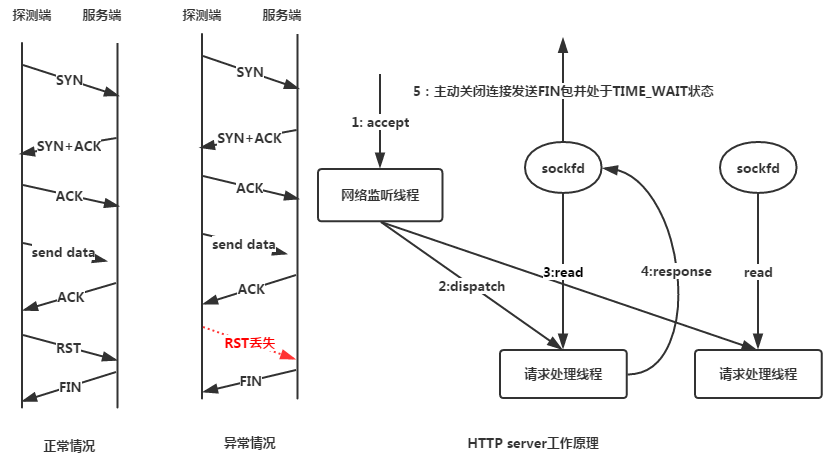
此时rst包虽然丢失,但是由于探测使用的HTTP请求,那么整个请求的交互就会完成(探测端会等待服务端的响应数据,所以能够确保服务端能够完成这个响应),服务端发送完响应数据后会主动关闭连接,发送FIN包(一般的HTTP服务框架默认都会这么做),服务端连接处于TIME_WAIT状态,经过一段时间后连接释放,不会长时间占用服务端资源。
对于HTTP服务,我们需要提供一个不耗费cpu和内存的调用接口,这个接口只是为了满足HTTP探活请求调用,如果探活接口死了,可以认为这个服务也死了。
如何确保不被探活搞死?
我们不能保证网络时时刻刻正常rst包不丢失,所以我们只能改造服务使得其更健壮。
正确解决方案如下:
服务端加入读超时时间。当rst包丢失导致服务端线程hang在读取上,超过一定时间后服务端线程会主动断开连接,释放资源,从而确保服务端线程能够服务于其它请求。
客户端请求服务端加入超时限制并进行重试。当一个服务hang死,导致连接其上的客户端也hang住后,超过一段时间后,客户端主动断开连接并且尝试请求其它可用服务。
- TCP保活的必要性
1) 很多防火墙等对于空闲socket自动关闭
2) 对于非正常断开, 服务器并不能检测到. 为了回收资源, 必须提供一种检测机制.
- 导致TCP断连的因素
如果网络正常, socket也通过close操作来进行优雅的关闭, 那么一切完美. 可是有很多情况, 比如网线故障, 客户端一侧突然断电或者崩溃等等, 这些情况server并不能正常检测到连接的断开.
- 保活的两种方式:
1) 应用层面的心跳机制
自定义心跳消息头. 一般客户端主动发送, 服务器接收后进行回应(也可以不回应). 这里不进行详述.
PS: 有人从软件的功能角度列出第三种方式, 就是通过第三方软件来进行探测, 确定连接的有效性. 这种方式局限性很大, 而且不属于软件内部的功能实现. 不进行讨论.
2) TCP协议自带的保活功能
打开keep-alive功能即可. 具体属性也可以通过API设定.
- 两种方式的优劣性
TCP协议自带的保活功能, 使用起来简单, 减少了应用层代码的复杂度. 推测也会更节省流量, 因为一般来说应用层的数据传输到协议层时都会被加上额外的包头包尾. 由TCP协议提供的检活, 其发的探测包, 理论上实现的会更精妙(用更少的字节完成更多的目标), 耗费更少的流量.
由应用自己实现的应用层的心跳, 为心跳消息额外定义一个消息类型就可以了. 就是应用正常的消息包, 只是这个包特殊点, 专门用来检活而已, 通常比较小, 可能只有消息头就可以了, 除非需要额外的信息.
应用层心跳的好处我个人的理解有两点:
一是比较灵活, 因为协议层的心跳只能提供最纯粹的检活功能, 但是应用层自己可以随意控制, 包括协议可能提供的是秒级的, 但是你想做成毫秒级的都任意(虽然实际几乎不会有这种时间级别的心跳), 包里还甚至可以携带额外的信息, 这些都是灵活之处.
二是通用, 应用层的心跳不依赖协议. 如果有一天不用TCP要改为UDP了, 协议层不提供心跳机制了, 但是你应用层的心跳依旧是通用的, 可能只需要做少许改动就可以继续使用.
应用层心跳的不好的地方也很显而易见, 增加开发工作量, 由于应用特定的网络框架, 还可能很增加代码结构的复杂度. 再就是根据上面的推测, 应用层心跳的流量消耗还是更大的, 毕竟这本质上还是个普通的数据包.
- 到底选用那种心跳方式?
优劣点第4节已经进行了阐述, 因此如果能确定你们更换协议的可能性非常小, 同时只是需要检活的功能, 那么用协议自带的就绝对OK了, 使用简单而且高效. 有些自负的人总喜欢用自己搞的, 来代替成熟协议自带的东西, 代替系统内核提供的东西, 其实往往你应用层实现的东西, 都是更拙劣的. 网上看了一些关于协议的Keep-alive不靠谱的说法, 也都比较空想和想当然, 都没有拿出任何事实论据或实验数据.
- 类Unix平台如何使用Keep-alive
keepalive默认是关闭的, 因为虽然流量极小, 毕竟是开销. 因此需要用户手动开启. 有两种方式开启.
1) 在代码里针对每个socket进行单独设定, 使用起来灵活.
除了keepAlive 开关, 还有keepIdle, keepInterval, keepCount 3个属性, 使用简单, 如下:
int keepAlive = 1; // 开启keepalive属性. 缺省值: 0(关闭)
int keepIdle = 60; // 如果在60秒内没有任何数据交互,则进行探测. 缺省值:7200(s)
int keepInterval = 5; // 探测时发探测包的时间间隔为5秒. 缺省值:75(s)
int keepCount = 2; // 探测重试的次数. 全部超时则认定连接失效..缺省值:9(次)
setsockopt(s, SOL_SOCKET, SO_KEEPALIVE, (void)&keepAlive, sizeof(keepAlive));
setsockopt(s, SOL_TCP, TCP_KEEPIDLE, (void)&keepIdle, sizeof(keepIdle));
setsockopt(s, SOL_TCP, TCP_KEEPINTVL, (void)&keepInterval, sizeof(keepInterval));
setsockopt(s, SOL_TCP, TCP_KEEPCNT, (void)&keepCount, sizeof(keepCount));
使用时需要#include <netinet/tcp.h>, 否则SOL_TCP和TCP_KEEPIDLE等3个宏找不到.
2) 修改配置文件, 对整个系统所有的socket有效.
我们可以用cat命令查看到系统中这几个默认的值.
#cat /proc/sys/net/ipv4/tcp_keepalive_time 7200
#cat /proc/sys/net/ipv4/tcp_keepalive_intvl 75
#cat /proc/sys/net/ipv4/tcp_keepalive_probes 9
修改它们:
#echo 60 > /proc/sys/net/ipv4/tcp_keepalive_time
#echo 5 > /proc/sys/net/ipv4/tcp_keepalive_intvl
#echo 3 > /proc/sys/net/ipv4/tcp_keepalive_probes
TCP协议中有长连接和短连接之分。短连接在数据包发送完成后就会自己断开,长连接在发包完毕后,会在一定的时间内保持连接,即我们通常所说的Keepalive(存活定时器)功能。 www.2cto.com
默认的Keepalive超时需要7,200,000 milliseconds,即2小时,探测次数为5次。它的功效和用户自己实现的心跳机制是一样的。开启Keepalive功能需要消耗额外的宽带和流量,尽管这微不足道,但在按流量计费的环境下增加了费用,另一方面,Keepalive设置不合理时可能会因为短暂的网络波动而断开健康的TCP连接。
keepalive并不是TCP规范的一部分。在Host Requirements RFC罗列有不使用它的三个理由:(1)在短暂的故障期间,它们可能引起一个良好连接(good connection)被释放(dropped),(2)它们消费了不必要的宽带,(3)在以数据包计费的互联网上它们(额外)花费金钱。然而,在许多的实现中提供了存活定时器。
一些服务器应用程序可能代表客户端占用资源,它们需要知道客户端主机是否崩溃。存活定时器可以为这些应用程序提供探测服务。Telnet服务器和Rlogin服务器的许多版本都默认提供存活选项。
个人计算机用户使用TCP/IP协议通过Telnet登录一台主机,这是能够说明需要使用存活定时器的一个常用例子。如果某个用户在使用结束时只是关掉了电源,而没有注销(log off),那么他就留下了一个半打开(half-open)的连接。如果客户端消失,留给了服务器端半打开的连接,并且服务器又在等待客户端的数据,那么等待将永远持续下去。存活特征的目的就是在服务器端检测这种半打开连接。
也可以在客户端设置存活器选项,且没有不允许这样做的理由,但通常设置在服务器。如果连接两端都需要探测对方是否消失,那么就可以在两端同时设置(比如NFS)。
keepalive工作原理:
若在一个给定连接上,两小时之内无任何活动,服务器便向客户端发送一个探测段。(我们将在下面的例子中看到探测段的样子。)客户端主机必须是下列四种状态之一:
1) 客户端主机依旧活跃(up)运行,并且从服务器可到达。从客户端TCP的正常响应,服务器知道对方仍然活跃。服务器的TCP为接下来的两小时复位存活定时器,如果在这两个小时到期之前,连接上发生应用程序的通信,则定时器重新为往下的两小时复位,并且接着交换数据。
2) 客户端已经崩溃,或者已经关闭(down),或者正在重启过程中。在这两种情况下,它的TCP都不会响应。服务器没有收到对其发出探测的响应,并且在75秒之后超时。服务器将总共发送10个这样的探测,每个探测75秒。如果没有收到一个响应,它就认为客户端主机已经关闭并终止连接。
3) 客户端曾经崩溃,但已经重启。这种情况下,服务器将会收到对其存活探测的响应,但该响应是一个复位,从而引起服务器对连接的终止。
4) 客户端主机活跃运行,但从服务器不可到达。这与状态2类似,因为TCP无法区别它们两个。它所能表明的仅是未收到对其探测的回复。
服务器不必担心客户端主机被关闭然后重启的情况(这里指的是操作员执行的正常关闭,而不是主机的崩溃)。当系统被操作员关闭时,所有的应用程序进程(也就是客户端进程)都将被终止,客户端TCP会在连接上发送一个FIN。收到这个FIN后,服务器TCP向服务器进程报告一个文件结束,以允许服务器检测这种状态。
在第一种状态下,服务器应用程序不知道存活探测是否发生。凡事都是由TCP层处理的,存活探测对应用程序透明,直到后面2,3,4三种状态发生。在这三种状态下,通过服务器的TCP,返回给服务器应用程序错误信息。(通常服务器向网络发出一个读请求,等待客户端的数据。如果存活特征返回一个错误信息,则将该信息作为读操作的返回值返回给服务器。)在状态2,错误信息类似于“连接超时”。状态3则为“连接被对方复位”。第四种状态看起来像连接超时,或者根据是否收到与该连接相关的ICMP错误信息,而可能返回其它的错误信息。
linux内核包含对keepalive的支持。其中使用了三个参数:tcp_keepalive_time(开启keepalive的闲置时 长)tcp_keepalive_intvl(keepalive探测包的发送间隔)和tcp_keepalive_probes (如果对方不予应答,探测包的发送次数);在liunx中,keepalive是一个开关选项,可以通过函数来使能。具体地说,可以使用以下代码:
setsockopt(rs, SOL_SOCKET, SO_KEEPALIVE, (void *)&keepAlive, sizeof(keepAlive));
当tcp检测到对端socket不再可用时(不能发出探测包,或探测包没有收到ACK的响应包),select会返回socket可读,并且在recv时返回-1,同时置上errno为ETIMEDOUT。此时TCP的状态是断开的。
keepalive参数设置代码如下:
// 开启KeepAlive
BOOL bKeepAlive = TRUE;
int nRet = ::setsockopt(socket_handle, SOL_SOCKET, SO_KEEPALIVE, (char*)&bKeepAlive, sizeof(bKeepAlive));
if (nRet == SOCKET_ERROR)
{
return FALSE;
}
// 设置KeepAlive参数
tcp_keepalive alive_in = {0};
tcp_keepalive alive_out = {0};
alive_in.keepalivetime = 5000; // 开始首次KeepAlive探测前的TCP空闭时间
alive_in.keepaliveinterval = 1000; // 两次KeepAlive探测间的时间间隔
alive_in.onoff = TRUE;
unsigned long ulBytesReturn = 0;
nRet = WSAIoctl(socket_handle, SIO_KEEPALIVE_VALS, &alive_in, sizeof(alive_in),
&alive_out, sizeof(alive_out), &ulBytesReturn, NULL, NULL);
if (nRet == SOCKET_ERROR)
{
return FALSE;
}
开启Keepalive选项之后,对于使用IOCP模型的服务器端程序来说,一旦检测到连接断开,GetQueuedCompletionStatus函数将立即返回FALSE,使得服务器端能及时清除该连接、释放该连接相关的资源。对于使用select模型的客户端来说,连接断开被探测到时,以recv目的阻塞在socket上的select方法将立即返回SOCKET_ERROR,从而得知连接已失效,客户端程序便有机会及时执行清除工作、提醒用户或重新连接。
TCP连接非正常断开的检测(KeepAlive探测)
此处的”非正常断开”指TCP连接不是以优雅的方式断开,如网线故障等物理链路的原因,还有突然主机断电等原因
有两种方法可以检测:1.TCP连接双方定时发握手消息 2.利用TCP协议栈中的KeepAlive探测
第二种方法简单可靠,只需对TCP连接两个Socket设定KeepAlive探测。
TCP保活可能带来的问题
1, 中间设备因大量保活连接,导致其连接表满
网关设备由于保活问题,导致其连接表满,无法新建连接(XX局网闸故障案例)或性能下降严重 2, 正常连接被释放
当连接一端在发送保活探测报文时,中间网络正好由于各种异常(如链路中断、中间设备重启等)而无法将该保活探测报文正确转发至对端时,可能会导致探测的一方释放本来正常的连接,但是这种可能情况发生的概率较小,另外,一般也可以增加保活探测报文发生的次数来减小这种情况发生的概率和影响。
TCP保活的设置
一般而言,保活探测主要在服务器端实现,如果应用层有相应的保活机制时,传输层的TCP保活就可以不用。
在windows系统中,我们可以通过修改注册表等来达到开启、调整保活相关 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters KeepAliveInterval 项:Tcpip\Parameters 数值类型:REG_DWORD - 时间(以毫秒为单位) 有效范围:1 - 0xFFFFFFFF 默认值:1000(1 秒) 说明:此参数确定在收到响应之前,保活重传之间的时间间隔。一旦收到一个响应,将由 KeepAliveTime 值重新控制在下一次保活传输之前的延迟。如果经过 TcpMaxDataRetransmissions 指定的重新传输次数后仍无响应,将放弃连接。 KeepAliveTime 项:Tcpip\Parameters 数值类型:REG_DWORD - 时间(以毫秒为单位) 有效范围:1 - 0xFFFFFFFF 默认值:7,200,000(两个小时) 说明:此参数控制 TCP 试图通过发送保活数据包来验证空闲连接是否仍然保持的次数。如果远程系统仍然可以连接并且正在运行,它就会响应保活传输。默认情况下不发送保活数据包。应用程序可以在连接上启用此功能。
Probe 是由Kubelet执行的,对 Container 的定期检测机制,用于确定 Container 是否存活,或者是否可以提供服务(接收访问流量)。
Probe被 Kubelet 使用时根据其作用分为两类:
livenessProbe: 表示 Container 是否为正常运行(running)状态
如果探测结果为Failure,Kubelet 会杀掉对应的容器,并且根据其 restart policy 来决定是否重启;
如果 Container 没有提供自定义的 liveness probe,默认视为返回Success。
需要定义initial delay来决定什么时候开始探测,避免初始化时间太短导致一直循环重启容器;
readinessProbe: 表示 Container 是否可以正常提供服务
如果探测结果为Failure,endpoints controller 会将对应的 Pod IP 从所有匹配上的 Service 的 Endpoint 列表中移除;
默认在initial delay时间结束之前,readiness probe 返回Failure;
如果 Container 没有提供自定义的 readiness probe,默认
视为返回Success。
Probe 实际上是通过调用由Container 实现的 Handler 来实现的,可以实现的 Handler 包括:
ExecAction: 在容器里执行一个制定命令,如果命令退出时返回0,则认为检测成功(Success),否则认为检测失败(Failure);
TCPSocketAction: 针对 容器IP:端口 的组合进行 TCP 连接检查,如果对应IP:端口处于开放状态,则认为成功,否则认为失败;
HTTPGetAction: 针对 容器IP:端口:API路径 的组合进行 HTTP GET 请求,如果 HTTP Response的 Status Code 在200~400之间,则认为检测成功,否则认为失败;
所以根据对应 Handler 的调用结果,每个 Probe 的探测结果可以有以下三种类型:
Success: 对应 Handler 返回成功;
Failure: 对应 Handler 返回失败;
Unknown: 对应 Handler 无法正常执行;
什么时候应该使用 liveness 或者 readiness probes?
看了上面关于两种 probe 的介绍后,就会有一个问题,是不是容器是否存活一定要定义 liveness probe 来探测,容器是否可服务一定要定义 readiness 来探测?
答案是否定的。
关于容器的存活情况:
容器本身的生命周期管理能够解决的问题,不需要通过 liveness 来进行探测,比如容器的 PID1 进程在发生错误的时候退出的场景,Kubelet 会根据容器的状况和 Pod 的 restartPolicy 来进行调谐;
当你希望不止基于容器本身的存活状态,而是通过某种自定义方式来决定 Kubelet 是否视容器为存活时,需要使用 liveness probe,举个例子,如果容器的 PID1 进程是一个常驻的 init 进程,而我们希望通过这个 init 启动的 flask 进程来判断容器是否为存活,如果 flask 进程启动不成功,就杀掉容器,并根据restartPolicy进行调谐,这个时候可以使用自定义 liveness probe。
关于容器的可服务情况:
当你希望有某一种机制,解决容器启动成功,和容器可以提供服务之间的区分,你需要使用 readiness probe,比如应用启动成功,但需要比较长的的初始化时间后(比如拉取大量初始化数据)才能正常提供服务,这个时候仅仅以容器是否存活来决定服务状态是不够的,等到 readiness 探测成功,容器才会被加入到 endpoint 里去对外提供服务;
当你希望容器在存活状态下,根据某种条件来让 Kubelet 认为它处于维护状态,自动把它从 endpoint 中去掉,停止对外提供服务,你需要使用和 liveness probe 不同的 readiness probe(容器已经启动,当对应服务正在维护中…);
容器本身生命周期能够解决的服务问题,也不需要通过 readiness probe 来探测是否可服务,比如当一个 Pod 被删除的时候,Pod 会被置为 unready 状态,不管 readiness probe 是否存在,也不管其结果如何。
probes 的实践
exec-liveness.yaml:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
观测 Pod 状态:
root@kmaster135:/home/chenjiaxi01/yaml/pods/probe# kubectl describe pod liveness-exec
Name: liveness-exec
…
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
—- —— —- —- ——-
Normal Scheduled 4m19s default-scheduler Successfully assigned default/liveness-exec to dnode136
Normal Killing 2m2s kubelet, dnode136 Killing container with id docker://liveness:Container failed liveness probe.. Container will be killed and recreated.
Warning Failed 107s kubelet, dnode136 Failed to pull image “k8s.gcr.io/busybox”: rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/busybox/manifests/latest: dial tcp [2404:6800:4008:c06::52]:443: connect: network is unreachable
Warning Failed 107s kubelet, dnode136 Error: ErrImagePull
Normal BackOff 106s kubelet, dnode136 Back-off pulling image “k8s.gcr.io/busybox”
Warning Failed 106s kubelet, dnode136 Error: ImagePullBackOff
Normal Pulling 93s (x3 over 4m8s) kubelet, dnode136 pulling image “k8s.gcr.io/busybox”
Normal Pulled 72s (x2 over 3m18s) kubelet, dnode136 Successfully pulled image “k8s.gcr.io/busybox”
Normal Created 72s (x2 over 3m17s) kubelet, dnode136 Created container
Normal Started 72s (x2 over 3m17s) kubelet, dnode136 Started container
Warning Unhealthy 27s (x6 over 2m42s) kubelet, dnode136 Liveness probe failed: cat: can’t open ‘/tmp/healthy’: No such file or directory
可以看到在 30s 过后,liveness 探测失败,kubelet 会删掉容器,并根据默认restartPolicy=Always重启容器;
发现有个问题, Node 上有镜像,但还是会去尝试远程拉取镜像,原因是imagePullPolicy: Always,如果想要在本地有对应镜像的时候不拉取,应该设置为imagePullPolcy: IfNotPresent 。
代码实现
代码版本: release-1.12
Kubelet 中的数据结构
pkg/kubelet/kubelet.go
// Kubelet is the main kubelet implementation.
type Kubelet struct {
kubeletConfiguration componentconfig.KubeletConfiguration
…
// Handles container probing.
probeManager prober.Manager
// Manages container health check results.
livenessManager proberesults.Manager
... } 初始化 pkg/kubelet/kubelet.go
// NewMainKubelet instantiates a new Kubelet object along with all the required internal modules.
// No initialization of Kubelet and its modules should happen here.
func NewMainKubelet(kubeCfg componentconfig.KubeletConfiguration, kubeDeps *KubeletDeps, crOptions *options.ContainerRuntimeOptions, standaloneMode bool, hostnameOverride, nodeIP, providerID string) (Kubelet, error) {
…
klet := &Kubelet{
hostname: hostname,
nodeName: nodeName,
kubeClient: kubeDeps.KubeClient,
…
}
…
klet.probeManager = prober.NewManager(
klet.statusManager,
klet.livenessManager,
klet.runner,
containerRefManager,
kubeDeps.Recorder)
…
}
启动
pkg/kubelet/kubelet.go
// Run starts the kubelet reacting to config updates
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
…
// Start component sync loops.
kl.statusManager.Start()
kl.probeManager.Start()
…
}
使用:
Pod 被创建时: pkg/kubelet/kubelet.go
// HandlePodAdditions is the callback in SyncHandler for pods being added from
// a config source.
func (kl Kubelet) HandlePodAdditions(pods []v1.Pod) {
start := kl.clock.Now()
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
…
kl.probeManager.AddPod(pod)
}
}
Pod 被删除时: pkg/kubelet/kubelet.go
// HandlePodRemoves is the callback in the SyncHandler interface for pods
// being removed from a config source.
func (kl Kubelet) HandlePodRemoves(pods []v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
kl.podManager.DeletePod(pod)
…
kl.probeManager.RemovePod(pod)
}
prober.Manager 接口
pkg/kubelet/prober/prober_manager.go
// Manager manages pod probing. It creates a probe “worker” for every container that specifies a
// probe (AddPod). The worker periodically probes its assigned container and caches the results. The
// manager use the cached probe results to set the appropriate Ready state in the PodStatus when
// requested (UpdatePodStatus). Updating probe parameters is not currently supported.
// TODO: Move liveness probing out of the runtime, to here.
type Manager interface {
// AddPod creates new probe workers for every container probe. This should be called for every
// pod created.
AddPod(pod *v1.Pod)
// RemovePod handles cleaning up the removed pod state, including terminating probe workers and
// deleting cached results.
RemovePod(pod *v1.Pod)
// CleanupPods handles cleaning up pods which should no longer be running.
// It takes a list of "active pods" which should not be cleaned up.
CleanupPods(activePods []*v1.Pod)
// UpdatePodStatus modifies the given PodStatus with the appropriate Ready state for each
// container based on container running status, cached probe results and worker states.
UpdatePodStatus(types.UID, *v1.PodStatus)
// Start starts the Manager sync loops.
Start() } prober.Manager 负责 Pod 探测的管理,提供了五个方法:
AddPod(pod v1.Pod): 在 Pod 创建时被知道用,为每个容器 probe 创建新的 probe worker;
RemovePod(pod *v1.Pod): 清理被删除的 Pod 的 Probe 状态,包括停止 probe wokers 以及清理掉缓存的结果;
CleanupPods(activePods []v1.Pod): 清理不需要运行的 Pods(??和 RemovePod 的区别和联系??);
UpdatePodStatus(type.UID, *v1.PodStatus): 基于容器的运行状态、缓存的探测结果,worker 的状态来更新 PodStatus;
Start(): 启动 Manager 同步循环;
基于上述的五个方法,Manager 会通过AddPod在 Pod 创建时为每个 container创建一个probe worker指定对应的探针,worker 定期执行探测并缓存结果。基于缓存的结果,Manager会在被请求的时候通过UpdatePodStatus更新PodStatus中的Ready状态。当容器被删除的时候,通过RemovePod回收worker。
// TODO: Move liveness probing out of the runtime, to here. 如何理解
接口的实现: prober.manager
type manager struct {
// Map of active workers for probes
workers map[probeKey]*worker
// Lock for accessing & mutating workers
workerLock sync.RWMutex
// The statusManager cache provides pod IP and container IDs for probing.
statusManager status.Manager
// readinessManager manages the results of readiness probes
readinessManager results.Manager
// livenessManager manages the results of liveness probes
livenessManager results.Manager
// prober executes the probe actions.
prober *prober } prober.manager包括如下数据结构:
workers: 维护 probe 和 worker 之间的映射;
workerLock: 访问 worker 时需要加锁;
statusManager: 提供 Pod 和 Container 信息;
readinessManager: 保存 readiness probes 结果;
livenessManager: 保存 liveness probes 结果;
prober: 具体执行 probe 动作;
worker: probe 探测的主要逻辑
worker 对象封装了对一个 probe 探测的主要任务;
其数据结构如下:
pkg/kubelet/prober/worker.go:37
// worker handles the periodic probing of its assigned container. Each worker has a go-routine
// associated with it which runs the probe loop until the container permanently terminates, or the
// stop channel is closed. The worker uses the probe Manager’s statusManager to get up-to-date
// container IDs.
type worker struct {
// Channel for stopping the probe.
stopCh chan struct{}
// The pod containing this probe (read-only)
pod *v1.Pod
// The container to probe (read-only)
container v1.Container
// Describes the probe configuration (read-only)
spec *v1.Probe
// The type of the worker.
probeType probeType
// The probe value during the initial delay.
initialValue results.Result
// Where to store this workers results.
resultsManager results.Manager
probeManager *manager
// The last known container ID for this worker.
containerID kubecontainer.ContainerID
// The last probe result for this worker.
lastResult results.Result
// How many times in a row the probe has returned the same result.
resultRun int
// If set, skip probing.
onHold bool
// proberResultsMetricLabels holds the labels attached to this worker
// for the ProberResults metric.
proberResultsMetricLabels prometheus.Labels
}
其方法包括:
newWorker: 根据用户传入的 proberType等参数,初始化一个对应到 container-liveness/readiness 探测任务的worker;
run: 按照用户指定的Probe.PeriodSeconds,周期性执行 worker 的doProbe操作,直到收到退出信号;
stop: 发出终止信号,停止 woker;
doProbe: 真正执行探测动作,返回探测结果true/false;
主要看doProbe的具体实现:
// doProbe probes the container once and records the result.
// Returns whether the worker should continue.
func (w *worker) doProbe() (keepGoing bool) {
defer func() { recover() }() // Actually eat panics (HandleCrash takes care of logging)
defer runtime.HandleCrash(func(_ interface{}) { keepGoing = true })
... // 防御式编程,去掉不需要 probe 的情况,比如 Pod 不存在,Container 不存在等
// TODO: in order for exec probes to correctly handle downward API env, we must be able to reconstruct
// the full container environment here, OR we must make a call to the CRI in order to get those environment
// values from the running container.
result, err := w.probeManager.prober.probe(w.probeType, w.pod, status, w.container, w.containerID)
if err != nil {
// Prober error, throw away the result.
return true
}
... // 根据 Probe 的结果和对应配置(比如重试次数等),决定是否返回成功 doProbe 对容器的不同情况进行分类,决定是否要进行 probe,并且处理 probe 的结果,决定是否返回成功(true);
下面继续看w.probeManager.prober.probe,分别支持exec,tcp,httpGet三种 Probe 类型,代码实现:
pkg/kubelet/prober/prober.go:81:
// probe probes the container.
func (pb *prober) probe(probeType probeType, pod *v1.Pod, status v1.PodStatus, container v1.Container, containerID kubecontainer.ContainerID) (results.Result, error) {
var probeSpec *v1.Probe
switch probeType {
case readiness:
probeSpec = container.ReadinessProbe
case liveness:
probeSpec = container.LivenessProbe
default:
return results.Failure, fmt.Errorf(“Unknown probe type: %q”, probeType)
}
…
result, output, err := pb.runProbeWithRetries(probeType, probeSpec, pod, status, container, containerID, maxProbeRetries)
…
}
runProbeWithRetries 封装了重试逻辑,最终调用到runProbe,按照不同的 Probe 类型实现不同的 Probe 具体探测流程,基于我们的问题背景,我们目前主要关心的是 HTTPGet 的具体实现,问题是:
用户是否可以指定 HTTPGet 的 Host?
如果用户没有指定,默认的 Host 是(猜测是 ClusterIP)?
pkg/kubelet/prober/prober.go:147
func (pb *prober) runProbe(probeType probeType, p *v1.Probe, pod *v1.Pod, status v1.PodStatus, container v1.Container, containerID kubecontainer.ContainerID) (probe.Result, string, error) {
timeout := time.Duration(p.TimeoutSeconds) * time.Second
if p.Exec != nil {
glog.V(4).Infof(“Exec-Probe Pod: %v, Container: %v, Command: %v”, pod, container, p.Exec.Command)
command := kubecontainer.ExpandContainerCommandOnlyStatic(p.Exec.Command, container.Env)
return pb.exec.Probe(pb.newExecInContainer(container, containerID, command, timeout))
}
if p.HTTPGet != nil {
scheme := strings.ToLower(string(p.HTTPGet.Scheme))
// 1. 用户可以指定 HTTPGet 的 Host;
// 2. 如果用户没有指定,默认的 Host 就是 PodIP。
host := p.HTTPGet.Host
if host == “” {
host = status.PodIP
}
port, err := extractPort(p.HTTPGet.Port, container)
if err != nil {
return probe.Unknown, “”, err
}
path := p.HTTPGet.Path
glog.V(4).Infof(“HTTP-Probe Host: %v://%v, Port: %v, Path: %v”, scheme, host, port, path)
url := formatURL(scheme, host, port, path)
headers := buildHeader(p.HTTPGet.HTTPHeaders)
glog.V(4).Infof(“HTTP-Probe Headers: %v”, headers)
if probeType == liveness {
return pb.livenessHttp.Probe(url, headers, timeout)
} else { // readiness
return pb.readinessHttp.Probe(url, headers, timeout)
}
}
if p.TCPSocket != nil {
port, err := extractPort(p.TCPSocket.Port, container)
if err != nil {
return probe.Unknown, “”, err
}
host := p.TCPSocket.Host
if host == “” {
host = status.PodIP
}
glog.V(4).Infof(“TCP-Probe Host: %v, Port: %v, Timeout: %v”, host, port, timeout)
return pb.tcp.Probe(host, port, timeout)
}
glog.Warningf(“Failed to find probe builder for container: %v”, container)
return probe.Unknown, “”, fmt.Errorf(“Missing probe handler for %s:%s”, format.Pod(pod), container.Name)
}
继续追查下去会追查到DoHTTPProbe: pkg/probe/http/http.go:66
// DoHTTPProbe checks if a GET request to the url succeeds.
// If the HTTP response code is successful (i.e. 400 > code >= 200), it returns Success.
// If the HTTP response code is unsuccessful or HTTP communication fails, it returns Failure.
// This is exported because some other packages may want to do direct HTTP probes.
func DoHTTPProbe(url *url.URL, headers http.Header, client HTTPGetInterface) (probe.Result, string, error) {
req, err := http.NewRequest(“GET”, url.String(), nil)
…
if headers.Get(“Host”) != “” {
req.Host = headers.Get(“Host”)
}
res, err := client.Do(req)
if err != nil {
// Convert errors into failures to catch timeouts.
return probe.Failure, err.Error(), nil
}
defer res.Body.Close()
…
if res.StatusCode >= http.StatusOK && res.StatusCode < http.StatusBadRequest {
glog.V(4).Infof(“Probe succeeded for %s, Response: %v”, url.String(), *res)
return probe.Success, body, nil
}
glog.V(4).Infof(“Probe failed for %s with request headers %v, response body: %v”, url.String(), headers, body)
return probe.Failure, fmt.Sprintf(“HTTP probe failed with statuscode: %d”, res.StatusCode), nil
}
发送 HTTP 请求进行探测,至此 HTTPGet Probe 的流程梳理完毕。
其他知识
select 作为并发控制的理解
// run periodically probes the container.
func (w *worker) run() {
probeTickerPeriod := time.Duration(w.spec.PeriodSeconds) * time.Second
// If kubelet restarted the probes could be started in rapid succession.
// Let the worker wait for a random portion of tickerPeriod before probing.
time.Sleep(time.Duration(rand.Float64() * float64(probeTickerPeriod)))
probeTicker := time.NewTicker(probeTickerPeriod)
defer func() {
// Clean up.
probeTicker.Stop()
if !w.containerID.IsEmpty() {
w.resultsManager.Remove(w.containerID)
}
w.probeManager.removeWorker(w.pod.UID, w.container.Name, w.probeType)
ProberResults.Delete(w.proberResultsMetricLabels)
}()
probeLoop:
for w.doProbe() {
// Wait for next probe tick.
select {
case <-w.stopCh:
break probeLoop
case <-probeTicker.C:
// continue
}
}
}
这个probeLoop的用法不是很理解,直接写个 sample 来看看:
func main() {
stopCh := make(chan int)
ticker := time.NewTicker(1 * time.Second)
go func() {
time.Sleep(3 * time.Second)
stopCh <- 0
fmt.Println("Send to stopCh")
}()
testLoop:
for {
select {
case <-stopCh:
fmt.Println(“Receive from stopCh, break”)
break testLoop
case <-ticker.C:
fmt.Println(“Running…”)
// continue
}
}
fmt.Println("Done") } 定义一个循环的名字而已,如果去掉的话,无法直接 break 整个循环,而只是 break 一次循环; time.Ticker的使用方式值得学习,用于配置定时任务,直到收到某个终止信号; for{}便是一个一直运行的循环,等同于Python中的while(true); worker.stop 的写法 pkg/kubelet/prober/worker.go:147
// stop stops the probe worker. The worker handles cleanup and removes itself from its manager.
// It is safe to call stop multiple times.
func (w *worker) stop() {
select {
case w.stopCh <- struct{}{}:
default: // Non-blocking.
}
}
这样写和以下这么写有什么区别:
func (w *worker) stop() {
w.stopCh <- struct{}{}
}
Non-blocking 的写法,如果 channel 已经写满,不会阻塞住 stop 所在的 Goroutine,上层就算重复执行,也不会引发错误,相当于 stop 操作是幂等的,健壮性提高;
Sample 如下:
var stopCh = make(chan struct{}, 1)
func nonblockingStop() {
select {
case stopCh <- struct{}{}:
fmt.Println(“Write to stopCh… Break”)
default:
fmt.Println(“Cannot write to stopCh… Running”)
// non-blocking
}
}
func stop() {
stopCh <- struct{}{}
}
func looping() {
testLoop:
for {
select {
case <-stopCh:
fmt.Println(“Receive End Signal…Done”)
break testLoop
default:
fmt.Println(“Cannot Receive End Signal…Done”)
time.Sleep(500 * time.Millisecond)
}
}
}
func main() {
// make stop blocked
go looping()
time.Sleep(time.Second)
for i := 0; i <= 2; i++ {
//stop()
nonblockingStop()
}
time.Sleep(3 * time.Second)
}
执行三次stop()会死锁,但是 nonblockingStop 不会;
