内存屏障
linux内核(4.0版本)的Documentation/memory-barriers.txt。
.1 内存访问的的抽象模型
2.2 什么是内存屏障
2.3 内核中的显式和隐式的内存屏障
2.4 cpu间的锁和屏障的关系
2.5 哪里需要使用屏障
2.6 内核中io屏障的作用
2.7 执行有序的最小假想模型
2.8 cpu cache对屏障的影响
2.9 alpha cpu
2.10 一个环形缓冲区的使用样例
只要能保证程序逻辑正确执行,cpu和complier(为了提升性能)怎么个乱序(优化)都行!
cpu1有2条指令,cpu2也有2条指令,共4条指令,总共有24种执行顺序(其实就是4的阶乘),够多了吧!(更可怕的是,这还是建立在一个重要假设之下的:假设cpu上执行顺序和其它cpu感知的是一样的!
*A = 5;
x = *D;
A是地址端口寄存器,D是数据端口寄存器。很明显,此时必须先放地址,再读数据,我们肯定认为只能这一种顺序,但是谁也保证不了!
至此,我们停顿下来,做个分析。貌似很乱了,软件根本搞不定,感觉是个硬件问题啊,那就让硬件做些限制(保证)吧!(cpu必须得做一些前提保证,否则软件世界大乱。。。)
前面说了,cpu会按照自己的(优化)顺序去执行指令,但一定不能违反一个大准则:程序本身的逻辑顺序。它会做如下保证:
1)有依赖的,保证保持现有顺序。
比如下面指针使用的例子:
ACCESS_ONCE(Q) = P; smp_read_barrier_depends(); D = ACCESS_ONCE(*Q);
smp_read_barrier_depends()一般为空,也就是说大部分的cpu是(不需要特殊处理)保证这种顺序的:因为得保持程序自身的依赖关系!
2)保证对重叠操作的处理保序
所谓重叠操作就是对同一内存地址的连续处理。
比如:
a = ACCESS_ONCE(X); ACCESS_ONCE(X) = b;
对地址X的处理顺序的两条指令就是重叠操作,cpu会保证现有顺序。
3)对毫无关系的指令,cpu保证你猜不出顺序!比如:
X = *A; Y = *B; *D = Z;
这样的指令序列,会有几种可能的顺序?6种(3的阶乘)顺序,哪种都可能!
4)cpu保证对重叠部分可能合并,可能覆盖!
比如:
X = *A; Y = *(A + 4);
此时可能有:
X = LOAD *A; Y = LOAD *(A + 4);
Y = LOAD *(A + 4); X = LOAD *A;
{X, Y} = LOAD {*A, *(A + 4) };
重叠时,cpu可能会合并(又可能导致覆盖)。
cpu能做出以上保证,算给软件稍微(一点点)减负了。
特别需要注意的是位域结构:一般地,位域操作不是线程安全的!就是说,对同一个结构体内的不同位域成员(即使连续定义的成员)的多线程访问是无法保证线程安全的:
Do not attempt to use bitfields to synchronize parallel algorithms.
我们来仔细分析这个问题,先看跟位域相关的一个memory location定义:
memory location
either an object of scalar type, or a maximal sequence
of adjacent bit-fields all having nonzero width
所谓memory location,指的是一个标量类型对象或一个最大的连续非0长度位域组。特别地,0长度位域会单独霸占一个memory location,从而隔离出memory location!
那memory location到底对线程安全有何影响?对同一memory location的访问(包括更新)不是线程安全的;对不同memory location的访问(包括更新)则是线程安全的。
更具体地讲,对于一个结构体(各个字段的类型,可能是位域,也可能不是)而言,我们总结如下几个要点:
位域类型和非位域类型之间的并发访问(包括更新),是线程安全(两个线程分别访问其中一个类型字段)的。
此结构体内部和该结构体的嵌套子结构体之间的位域字段,是线程安全的。
位域之间如果有0长度位域分割,则是线程安全的。
位域之间如果被一个非位域分割,则是线程安全的。
位域之间所有的位域都是非0位域,则是线程不安全的。
综上,要使访问位域线程安全化,可以采用锁,也可以在两个位域之间插入0长度位域(虽然有点浪费空间)。
内存屏障是硬件之上、操作系统或JVM之下,对并发作出的最后一层支持。再向下是是硬件提供的支持;向上是操作系统或JVM对内存屏障作出的各种封装。内存屏障是一种标准,各厂商可能采用不同的实现。
本文仅为了帮助理解JVM提供的并发机制。首先,从volatile的语义引出可见性与重排序问题;接下来,阐述问题的产生原理,了解为什么需要内存屏障;然后,浅谈内存屏障的标准、厂商对内存屏障的支持,并以volatile为例讨论内存屏障如何解决这些问题;最后,补充介绍JVM在内存屏障之上作出的几个封装。为了帮助理解,会简要讨论硬件架构层面的一些基本原理(特别是CPU架构),但不会深入实现机制。
内存屏障的实现涉及大量硬件架构层面的知识,又需要操作系统或JVM的配合才能发挥威力,单纯从任何一个层面都无法理解。本文整合了这三个层面的大量知识,篇幅较长,希望能在一篇文章内,把内存屏障的基本问题讲述清楚。
如有疏漏,还望指正!
volatile变量规则
一个用于引出内存屏障的好例子是volatile变量规则。
volatile关键字可参考猴子刚开博客时的文章volatile关键字的作用、原理。volatile变量规则描述了volatile变量的偏序语义;这里从volatile变量规则的角度来讲解,顺便做个复习。
定义
volatile变量规则:对volatile变量的写入操作必须在对该变量的读操作之前执行。
volatile变量规则只是一种标准,要求JVM实现保证volatile变量的偏序语义。结合程序顺序规则、传递性,该偏序语义通常表现为两个作用:
保持可见性
禁用重排序(读操作禁止重排序之后的操作,写操作禁止重排序之前的操作)
补充:
程序顺序规则:如果程序中操作A在操作B之前,那么在线程中操作A将在操作B之前执行。
传递性:如果操作A在操作B之前执行,并且操作B在操作C之前执行,那么操作A必须在操作C之前执行。
后文,如果仅涉及可见性,则指明“可见性”;如果二者均涉及,则以“偏序”代称。重排序一定会带来可见性问题,因此,不会出现单独讨论重排序的场景。
正确姿势
之前的文章多次涉及volatile变量规则的用法。
简单的仅利用volatile变量规则对volatile变量本身的可见性保证:
面试中单例模式有几种写法?:“饱汉 - 变种 3”在DCL的基础上,使用volatile修饰单例,以保证单例的可见性。
复杂的利用volatile变量规则(结合了程序顺序规则、传递性)保证变量本身及周围其他变量的偏序:
源码|并发一枝花之ReentrantLock与AQS(1):lock、unlock:exclusiveOwnerThread借助于volatile变量state保证其相对于state的偏序。
源码|并发一枝花之CopyOnWriteArrayList:CopyOnWriteArrayList借助于volatile变量array,对外提供偏序语义。
可见性与重排序
前文多次提到可见性与重排序的问题,内存屏障的存在就是为了解决这些问题。到底什么是可见性?什么是重排序?为什么会有这些问题?
可见性
定义
可见性的定义常见于各种并发场景中,以多线程为例:当一个线程修改了线程共享变量的值,其它线程能够立即得知这个修改。
从性能角度考虑,没有必要在修改后就立即同步修改的值——如果多次修改后才使用,那么只需要最后一次同步即可,在这之前的同步都是性能浪费。因此,实际的可见性定义要弱一些,只需要保证:当一个线程修改了线程共享变量的值,其它线程在使用前,能够得到最新的修改值。
可见性可以认为是最弱的“一致性”(弱一致),只保证用户见到的数据是一致的,但不保证任意时刻,存储的数据都是一致的(强一致)。下文会讨论“缓存可见性”问题,部分文章也会称为“缓存一致性”问题。
问题来源
一个最简单的可见性问题来自计算机内部的缓存架构:
计算机内部的缓存架构
缓存大大缩小了高速CPU与低速内存之间的差距。以三层缓存架构为例:
L1 Cache最接近CPU, 容量最小(如32K、64K等)、速度最高,每个核上都有一个L1 Cache。
L2 Cache容量更大(如256K)、速度更低, 一般情况下,每个核上都有一个独立的L2 Cache。
L3 Cache最接近内存,容量最大(如12MB),速度最低,在同一个CPU插槽之间的核共享一个L3 Cache。
准确地说,每个核上有两个L1 Cache, 一个存数据 L1d Cache, 一个存指令 L1i Cache。
单核时代的一切都是那么完美。然而,多核时代出现了可见性问题。一个badcase如下:
Core0与Core1命中了内存中的同一个地址,那么各自的L1 Cache会缓存同一份数据的副本。
最开始,Core0与Core1都在友善的读取这份数据。
突然,Core0要使坏了,它修改了这份数据,使得两份缓存中的数据不同了,更确切的说,Core1 L1 Cache中的数据失效了。
单核时代只有Core0,Core0修改Core0读,没什么问题;但是,现在Core0修改后,Core1并不知道数据已经失效,继续傻傻的使用,轻则数据计算错误,重则导致死循环、程序崩溃等。
实际的可见性问题还要扩展到两个方向:
除三级缓存外,各厂商实现的硬件架构中还存在多种多样的缓存,都存在类似的可见性问题。例如,寄存器就相当于CPU与L1 Cache之间的缓存。
各种高级语言(包括Java)的多线程内存模型中,在线程栈内自己维护一份缓存是常见的优化措施,但显然在CPU级别的缓存可见性问题面前,一切都失效了。
以上只是最简单的可见性问题,不涉及重排序等。
重排序也会导致可见性问题;同时,缓存上的可见性也会引起一些看似重排序导致的问题。
重排序
定义
重排序并没有严格的定义。整体上可以分为两种:
真·重排序:编译器、底层硬件(CPU等)出于“优化”的目的,按照某种规则将指令重新排序(尽管有时候看起来像乱序)。
伪·重排序:由于缓存同步顺序等问题,看起来指令被重排序了。
重排序也是单核时代非常优秀的优化手段,有足够多的措施保证其在单核下的正确性。在多核时代,如果工作线程之间不共享数据或仅共享不可变数据,重排序也是性能优化的利器。然而,如果工作线程之间共享了可变数据,由于两种重排序的结果都不是固定的,会导致工作线程似乎表现出了随机行为。
第一次接触重排序的概念一定很迷糊,耐心,耐心。
问题来源
重排序问题无时无刻不在发生,源自三种场景:
编译器编译时的优化
处理器执行时的乱序优化
缓存同步顺序(导致可见性问题)
场景1、2属于真·重排序;场景3属于伪·重排序。场景3也属于可见性问题,为保持连贯性,我们先讨论场景3。
可见性导致的伪·重排序
缓存同步顺序本质上是可见性问题。
假设程序顺序(program order)中先更新变量v1、再更新变量v2,不考虑真·重排序:
Core0先更新缓存中的v1,再更新缓存中的v2(位于两个缓存行,这样淘汰缓存行时不会一起写回内存)。
Core0读取v1(假设使用LRU协议淘汰缓存)。
Core0的缓存满,将最远使用的v2写回内存。
Core1的缓存中本来存有v1,现在将v2加载入缓存。
重排序是针对程序顺序而言的,如果指令执行顺序与程序顺序不同,就说明这段指令被重排序了。
此时,尽管“更新v1”的事件早于“更新v2”发生,但Core1只看到了v2的最新值,却看不到v1的最新值。这属于可见性导致的伪·重排序:虽然没有实际上没有重排序,但看起来发生了重排序。
可以看到,缓存可见性不仅仅导致可见性问题,还会导致伪·重排序。因此,只要解决了缓存上的可见性问题,也就解决了伪·重排序。
MESI协议
回到可见性问题中的例子和可见性的定义。要解决这个问题很简单,套用可见性的定义,只需要:在Core0修改了数据v后,让Core1在使用v前,能得到v最新的修改值。
这个要求很弱,既可以在每次修改v后,都同步修改值到其他缓存了v的Cache中;又可以只同步使用前的最后一次修改值。后者性能上更优,如何实现呢:
Core0修改v后,发送一个信号,将Core1缓存的v标记为失效,并将修改值写回内存。
Core0可能会多次修改v,每次修改都只发送一个信号(发信号时会锁住缓存间的总线),Core1缓存的v保持着失效标记。
Core1使用v前,发现缓存中的v已经失效了,得知v已经被修改了,于是重新从其他缓存或内存中加载v。
以上即是MESI(Modified Exclusive Shared Or Invalid,缓存的四种状态)协议的基本原理,不算严谨,但对于理解缓存可见性(更常见的称呼是“缓存一致性”)已经足够。
MESI协议解决了CPU缓存层面的可见性问题。
以下是MESI协议的缓存状态机,
状态:
M(修改, Modified): 本地处理器已经修改缓存行, 即是脏行, 它的内容与内存中的内容不一样. 并且此cache只有本地一个拷贝(专有)。
E(专有, Exclusive): 缓存行内容和内存中的一样, 而且其它处理器都没有这行数据。
S(共享, Shared): 缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝。
I(无效, Invalid): 缓存行失效, 不能使用。
剩余问题
既然有了MESI协议,是不是就不需要volatile的可见性语义了?当然不是,还有三个问题:
并不是所有的硬件架构都提供了相同的一致性保证,JVM需要volatile统一语义(就算是MESI,也只解决CPU缓存层面的问题,没有涉及其他层面)。
可见性问题不仅仅局限于CPU缓存内,JVM自己维护的内存模型中也有可见性问题。使用volatile做标记,可以解决JVM层面的可见性问题。
如果不考虑真·重排序,MESI确实解决了CPU缓存层面的可见性问题;然而,真·重排序也会导致可见性问题。
暂时第一个问题称为“内存可见性”问题,内存屏障解决了该问题。后文讨论。
编译器编译时的优化
JVM自己维护的内存模型中也有可见性问题,使用volatile做标记,取消volatile变量的缓存,就解决了JVM层面的可见性问题。编译器产生的重排序也采用了同样的思路。
编译器为什么要重排序(re-order)呢?和处理器乱序执行的目的是一样的:与其等待阻塞指令(如等待缓存刷入)完成,不如先去执行其他指令。与处理器乱序执行相比,编译器重排序能够完成更大范围、效果更好的乱序优化。
由于同处理器乱序执行的目的相同,原理相似,这里不讨论编译器重排序的实现原理。
幸运的是,既然是编译器层面的重排序,自然可以由编译器控制。使用volatile做标记,就可以禁用编译器层面的重排序。
处理器执行时的乱序优化
处理器层面的乱序优化节省了大量等待时间,提高了处理器的性能。
所谓“乱序”只是被叫做“乱序”,实际上也遵循着一定规则:只要两个指令之间不存在数据依赖,就可以对这两个指令乱序。不必关心数据依赖的精确定义,可以理解为:只要不影响程序单线程、顺序执行的结果,就可以对两个指令重排序。
不进行乱序优化时,处理器的指令执行过程如下:
指令获取。
如果输入的运算对象是可以获取的(比如已经存在于寄存器中),这条指令会被发送到合适的功能单元。如果一个或者更多的运算对象在当前的时钟周期中是不可获取的(通常需要从主内存获取),处理器会开始等待直到它们是可以获取的。
指令在合适的功能单元中被执行。
功能单元将运算结果写回寄存器。
乱序优化下的执行过程如下:
指令获取。
指令被发送到一个指令序列(也称执行缓冲区或者保留站)中。
指令将在序列中等待,直到它的数据运算对象是可以获取的。然后,指令被允许在先进入的、旧的指令之前离开序列缓冲区。(此处表现为乱序)
指令被分配给一个合适的功能单元并由之执行。
结果被放到一个序列中。
仅当所有在该指令之前的指令都将他们的结果写入寄存器后,这条指令的结果才会被写入寄存器中。(重整乱序结果)
当然,为了实现乱序优化,还需要很多技术的支持,如寄存器重命名、分枝预测等,但大致了解到这里就足够。后文的注释中会据此给出内存屏障的实现方案。
乱序优化在单核时代不影响正确性;但多核时代的多线程能够在不同的核上实现真正的并行,一旦线程间共享数据,就出现问题了。看一段很经典的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class OutofOrderExecution {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args)
throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
public void run() {
a = 1;
x = b;
}
});
Thread t2 = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(“(” + x + “,” + y + “)”);
} } 不考虑编译器重排序和缓存可见性问题,上面的代码可能会输出什么呢?
最容易想到的结果是(0,1)、(1,0)或(1,1)。因为可能先后执行线程t1、t2,也可能反之,还可能t1、t2交替执行。
然而,这段代码的执行结果也可能是(0,0),看起来违反常理。这是处理器乱序执行的结果:线程t1内部的两行代码之间不存在数据依赖,因此,可以将x = b乱序到a = 1前;同时,线程t2中的y = a早于线程t1中的a = 1执行。一个可能的执行序列如下:
t1: x = b
t2: b = 1
t2: y = a
t1: a = 1
这里将代码等同于指令,不严谨,但不妨碍理解。
看起来,似乎将上述重排序(或乱序)导致的问题称为“可见性”问题也未尝不可。然而,这种重排序的危害要远远大于单纯的可见性,因为并不是所有的指令都是简单的读或者写——面试中单例模式有几种写法?与volatile关键字的作用、原理中都提到了部分初始化的例子,这种不安全发布就是由于重排序导致的。因此,将重排序归为“可见性”问题并不合适,只能说重排序会导致可见性问题。
也就是说,单纯解决内存可见性问题是不够的,还需要专门解决处理器重排序的问题。
当然,某些处理器不会对指令乱序,或能够基于多核间的数据依赖乱序。这时,volatile仅用于统一重排序方面的语义。
内存屏障
内存屏障(Memory Barrier)与内存栅栏(Memory Fence)是同一个概念,不同的叫法。
通过volatile标记,可以解决编译器层面的可见性与重排序问题。而内存屏障则解决了硬件层面的可见性与重排序问题。
猴子暂时没有验证下述分析,仅从逻辑和系统设计考量上进行了判断、取舍。以后会补上实验。
标准
先简单了解两个指令:
Store:将处理器缓存的数据刷新到内存中。
Load:将内存存储的数据拷贝到处理器的缓存中。
屏障类型 指令示例 说明
LoadLoad Barriers Load1;LoadLoad;Load2 该屏障确保Load1数据的装载先于Load2及其后所有装载指令的的操作
StoreStore Barriers Store1;StoreStore;Store2 该屏障确保Store1立刻刷新数据到内存(使其对其他处理器可见)的操作先于Store2及其后所有存储指令的操作
LoadStore Barriers Load1;LoadStore;Store2 确保Load1的数据装载先于Store2及其后所有的存储指令刷新数据到内存的操作
StoreLoad Barriers Store1;StoreLoad;Load2 该屏障确保Store1立刻刷新数据到内存的操作先于Load2及其后所有装载装载指令的操作。它会使该屏障之前的所有内存访问指令(存储指令和访问指令)完成之后,才执行该屏障之后的内存访问指令
StoreLoad Barriers同时具备其他三个屏障的效果,因此也称之为全能屏障(mfence),是目前大多数处理器所支持的;但是相对其他屏障,该屏障的开销相对昂贵。
然而,除了mfence,不同的CPU架构对内存屏障的实现方式与实现程度非常不一样。相对来说,Intel CPU的强内存模型比DEC Alpha的弱复杂内存模型(缓存不仅分层了,还分区了)更简单。x86架构是在多线程编程中最常见的,下面讨论x86架构中内存屏障的实现。
查阅资料时,你会发现每篇讲内存屏障的文章讲的都不同。不过,重要的是理解基本原理,需要的时候再继续深究即可。
不过不管是那种方案,内存屏障的实现都要针对乱序执行的过程来设计。前文的注释中讲解了乱序执行的基本原理:核心是一个序列缓冲区,只要指令的数据运算对象是可以获取的,指令就被允许在先进入的、旧的指令之前离开序列缓冲区,开始执行。对于内存可见性的语义,内存屏障可以通过使用类似MESI协议的思路实现。对于重排序语义的实现机制,猴子没有继续研究,一种可行的思路是:
当CPU收到屏障指令时,不将屏障指令放入序列缓冲区,而将屏障指令及后续所有指令放入一个FIFO队列中(指令是按批发送的,不然没有乱序的必要)
允许乱序执行完序列缓冲区中的所有指令
从FIFO队列中取出屏障指令,执行(并刷新缓存等,实现内存可见性的语义)
将FIFO队列中的剩余指令放入序列缓冲区
恢复正常的乱序执行
对于x86架构中的sfence屏障指令而言,则保证sfence之前的store执行完,再执行sfence,最后执行sfence之后的store;除了禁用sfence前后store乱序带来的新的数据依赖外,不影响load命令的乱序。详细见后。
x86架构的内存屏障
x86架构并没有实现全部的内存屏障。
Store Barrier
sfence指令实现了Store Barrier,相当于StoreStore Barriers。
强制所有在sfence指令之前的store指令,都在该sfence指令执行之前被执行,发送缓存失效信号,并把store buffer中的数据刷出到CPU的L1 Cache中;所有在sfence指令之后的store指令,都在该sfence指令执行之后被执行。即,禁止对sfence指令前后store指令的重排序跨越sfence指令,使所有Store Barrier之前发生的内存更新都是可见的。
这里的“可见”,指修改值可见(内存可见性)且操作结果可见(禁用重排序)。下同。
内存屏障的标准中,讨论的是缓存与内存间的相干性,实际上,同样适用于寄存器与缓存、甚至寄存器与内存间等多级缓存之间。x86架构使用了MESI协议的一个变种,由协议保证三层缓存与内存间的相关性,则内存屏障只需要保证store buffer(可以认为是寄存器与L1 Cache间的一层缓存)与L1 Cache间的相干性。下同。
Load Barrier
lfence指令实现了Load Barrier,相当于LoadLoad Barriers。
强制所有在lfence指令之后的load指令,都在该lfence指令执行之后被执行,并且一直等到load buffer被该CPU读完才能执行之后的load指令(发现缓存失效后发起的刷入)。即,禁止对lfence指令前后load指令的重排序跨越lfence指令,配合Store Barrier,使所有Store Barrier之前发生的内存更新,对Load Barrier之后的load操作都是可见的。
Full Barrier
mfence指令实现了Full Barrier,相当于StoreLoad Barriers。
mfence指令综合了sfence指令与lfence指令的作用,强制所有在mfence指令之前的store/load指令,都在该mfence指令执行之前被执行;所有在mfence指令之后的store/load指令,都在该mfence指令执行之后被执行。即,禁止对mfence指令前后store/load指令的重排序跨越mfence指令,使所有Full Barrier之前发生的操作,对所有Full Barrier之后的操作都是可见的。
volatile如何解决内存可见性与处理器重排序问题
在编译器层面,仅将volatile作为标记使用,取消编译层面的缓存和重排序。
如果硬件架构本身已经保证了内存可见性(如单核处理器、一致性足够的内存模型等),那么volatile就是一个空标记,不会插入相关语义的内存屏障。
如果硬件架构本身不进行处理器重排序、有更强的重排序语义(能够分析多核间的数据依赖)、或在单核处理器上重排序,那么volatile就是一个空标记,不会插入相关语义的内存屏障。
如果不保证,仍以x86架构为例,JVM对volatile变量的处理如下:
在写volatile变量v之后,插入一个sfence。这样,sfence之前的所有store(包括写v)不会被重排序到sfence之后,sfence之后的所有store不会被重排序到sfence之前,禁用跨sfence的store重排序;且sfence之前修改的值都会被写回缓存,并标记其他CPU中的缓存失效。
在读volatile变量v之前,插入一个lfence。这样,lfence之后的load(包括读v)不会被重排序到lfence之前,lfence之前的load不会被重排序到lfence之后,禁用跨lfence的load重排序;且lfence之后,会首先刷新无效缓存,从而得到最新的修改值,与sfence配合保证内存可见性。
在另外一些平台上,JVM使用mfence代替sfence与lfence,实现更强的语义。
二者结合,共同实现了Happens-Before关系中的volatile变量规则。
JVM对内存屏障作出的其他封装
除volatile外,常见的JVM实现还基于内存屏障作了一些其他封装。借助于内存屏障,这些封装也得到了内存屏障在可见性与重排序上的语义。
借助:piggyback。
在JVM中,借助通常指:将Happens-Before的程序顺序规则与其他某个顺序规则(通常是监视器锁规则、volatile变量规则)结合起来,从而对某个未被锁保护的变量的访问操作进行排序。
本文将借助的语义扩展到更大的范围,可以借助任何现有机制,以获得现有机制的某些属性。当然,并不是所有属性都能被借助,比如原子性。但基于前文对内存屏障的分析可知,可见性与重排序是可以被借助的。
下面仍基于x86架构讨论。
final关键字
如果一个实例的字段被声明为final,则JVM会在初始化final变量后插入一个sfence。
类的final字段在
final字段的初始化在
再谈部分初始化
上述良好性质被称为“初始化安全性”。它保证,对于被正确构造的对象,所有线程都能看到构造函数给对象的各个final字段设置的正确值,而不管采用何种方式来发布对象。
这里将可见性从“final字段初始化之前(include)的内存更新”缩小到“final字段初始化”。猴子没找到确切的原因,手里暂时只有一个jdk也不方便验证。可能是因为,JVM没有要求虚拟机实现在生成
初始化安全性为解决部分初始化问题带来了新的思路:如果待发布对象的所有域都是final修饰的,那么可以防止对对象的初始引用被重排序到构造过程完成之前。于是,面试中单例模式有几种写法?中的饱汉变种三还可以扔掉volatile,改为借助final的sfence语义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 饱汉
// ThreadSafe
public class Singleton1_3 {
private static Singleton1_3 singleton = null;
public int f1 = 1; // 触发部分初始化问题
public int f2 = 2;
private Singleton1_3() {
}
public static Singleton1_3 getInstance() {
if (singleton == null) {
synchronized (Singleton1_3.class) {
// must be a complete instance
if (singleton == null) {
singleton = new Singleton1_3();
}
}
}
return singleton;
}
}
注意,初始化安全性仅针对安全发布中的部分初始化问题,与其他安全发布问题、发布后的可见性问题无关。
CAS
在x86架构上,CAS被翻译为”lock cmpxchg…“。cmpxchg是CAS的汇编指令。在CPU架构中依靠lock信号保证可见性并禁止重排序。
lock前缀是一个特殊的信号,执行过程如下:
对总线和缓存上锁。
强制所有lock信号之前的指令,都在此之前被执行,并同步相关缓存。
执行lock后的指令(如cmpxchg)。
释放对总线和缓存上的锁。
强制所有lock信号之后的指令,都在此之后被执行,并同步相关缓存。
因此,lock信号虽然不是内存屏障,但具有mfence的语义(当然,还有排他性的语义)。
与内存屏障相比,lock信号要额外对总线和缓存上锁,成本更高。
锁
JVM的内置锁通过操作系统的管程实现。且不论管程的实现原理,由于管程是一种互斥资源,修改互斥资源至少需要一个CAS操作。因此,锁必然也使用了lock信号,具有mfence的语义。
锁的mfence语义实现了Happens-Before关系中的监视器锁规则。
CAS具有同样的mfence语义,也必然具有与锁相同的偏序关系。尽管JVM没有对此作出显式的要求。
利用 Memory Barrier 实现的无锁环形缓冲区。
Memory Barrier 简介
程序在运行时内存实际的访问顺序和程序代码编写的访问顺序不一定一致,这就是内存乱序访问。内存乱序访问行为出现的理由是为了提升程序运行时的性能。内存乱序访问主要发生在两个阶段:
编译时,编译器优化导致内存乱序访问(指令重排)
运行时,多 CPU 间交互引起内存乱序访问
Memory Barrier 能够让 CPU 或编译器在内存访问上有序。一个 Memory Barrier 之前的内存访问操作必定先于其之后的完成。Memory Barrier 包括两类:
编译器Memory Barrier
CPU Memory Barrier
很多时候,编译器和 CPU 引起内存乱序访问不会带来什么问题,但一些特殊情况下,程序逻辑的正确性依赖于内存访问顺序,这时候内存乱序访问会带来逻辑上的错误,例如:
// thread 1
while (!ok);
do(x);
// thread 2
x = 42;
ok = 1;
此段代码中,ok 初始化为 0,线程 1 等待 ok 被设置为 1 后执行 do 函数。假如说,线程 2 对内存的写操作乱序执行,也就是 x 赋值后于 ok 赋值完成,那么 do 函数接受的实参就很可能出乎程序员的意料,不为 42。
编译时内存乱序访问
在编译时,编译器对代码做出优化时可能改变实际执行指令的顺序(例如 gcc 下 O2 或 O3 都会改变实际执行指令的顺序):
// test.cpp
int x, y, r;
void f()
{
x = r;
y = 1;
}
编译器优化的结果可能导致 y = 1 在 x = r 之前执行完成。首先直接编译此源文件:
g++ -S test.cpp
得到相关的汇编代码如下:
movl r(%rip), %eax
movl %eax, x(%rip)
movl $1, y(%rip)
这里我们看到,x = r 和 y = 1 并没有乱序。现使用优化选项 O2(或 O3)编译上面的代码(g++ -O2 -S test.cpp),生成汇编代码如下:
movl r(%rip), %eax
movl $1, y(%rip)
movl %eax, x(%rip)
我们可以清楚的看到经过编译器优化之后 movl $1, y(%rip) 先于 movl %eax, x(%rip) 执行。避免编译时内存乱序访问的办法就是使用编译器 barrier(又叫优化 barrier)。Linux 内核提供函数 barrier() 用于让编译器保证其之前的内存访问先于其之后的完成。内核实现 barrier() 如下(X86-64 架构):
#define barrier() asm volatile(“” ::: “memory”)
现在把此编译器 barrier 加入代码中:
int x, y, r;
void f()
{
x = r;
asm volatile(“” ::: “memory”);
y = 1;
}
这样就避免了编译器优化带来的内存乱序访问的问题了(如果有兴趣可以再看看编译之后的汇编代码)。本例中,我们还可以使用 volatile 这个关键字来避免编译时内存乱序访问(而无法避免后面要说的运行时内存乱序访问)。volatile 关键字能够让相关的变量之间在内存访问上避免乱序,这里可以修改 x 和 y 的定义来解决问题:
volatile int x, y;
int r;
void f()
{
x = r;
y = 1;
}
现加上了 volatile 关键字,这使得 x 相对于 y、y 相对于 x 在内存访问上有序。在 Linux 内核中,提供了一个宏 ACCESS_ONCE 来避免编译器对于连续的 ACCESS_ONCE 实例进行指令重排。其实 ACCESS_ONCE 实现源码如下:
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
此代码只是将变量 x 转换为 volatile 的而已。现在我们就有了第三个修改方案:
int x, y, r;
void f()
{
ACCESS_ONCE(x) = r;
ACCESS_ONCE(y) = 1;
}
到此基本上就阐述完了我们的编译时内存乱序访问的问题。下面开始介绍运行时内存乱序访问。
运行时内存乱序访问
在运行时,CPU 虽然会乱序执行指令,但是在单个 CPU 的上,硬件能够保证程序执行时所有的内存访问操作看起来像是按程序代码编写的顺序执行的,这时候 Memory Barrier 没有必要使用(不考虑编译器优化的情况下)。这里我们了解一下 CPU 乱序执行的行为。在乱序执行时,一个处理器真正执行指令的顺序由可用的输入数据决定,而非程序员编写的顺序。
早期的处理器为有序处理器(In-order processors),有序处理器处理指令通常有以下几步:
指令获取
如果指令的输入操作对象(input operands)可用(例如已经在寄存器中了),则将此指令分发到适当的功能单元中。如果一个或者多个操作对象不可用(通常是由于需要从内存中获取),则处理器会等待直到它们可用
指令被适当的功能单元执行
功能单元将结果写回寄存器堆(Register file,一个 CPU 中的一组寄存器)
相比之下,乱序处理器(Out-of-order processors)处理指令通常有以下几步:
指令获取
指令被分发到指令队列
指令在指令队列中等待,直到输入操作对象可用(一旦输入操作对象可用,指令就可以离开队列,即便更早的指令未被执行)
指令被分配到适当的功能单元并执行
执行结果被放入队列(而不立即写入寄存器堆)
只有所有更早请求执行的指令的执行结果被写入寄存器堆后,指令执行的结果才被写入寄存器堆(执行结果重排序,让执行看起来是有序的)
从上面的执行过程可以看出,乱序执行相比有序执行能够避免等待不可用的操作对象(有序执行的第二步)从而提高了效率。现代的机器上,处理器运行的速度比内存快很多,有序处理器花在等待可用数据的时间里已经可以处理大量指令了。
现在思考一下乱序处理器处理指令的过程,我们能得到几个结论:
对于单个 CPU 指令获取是有序的(通过队列实现)
对于单个 CPU 指令执行结果也是有序返回寄存器堆的(通过队列实现)
由此可知,在单 CPU 上,不考虑编译器优化导致乱序的前提下,多线程执行不存在内存乱序访问的问题。我们从内核源码也可以得到类似的结论(代码不完全的摘录):
#ifdef CONFIG_SMP
#define smp_mb() mb()
#else
#define smp_mb() barrier()
#endif
这里可以看到,如果是 SMP 则使用 mb,mb 被定义为 CPU Memory barrier(后面会讲到),而非 SMP 时,直接使用编译器 barrier。
在多 CPU 的机器上,问题又不一样了。每个 CPU 都存在 cache(cache 主要是为了弥补 CPU 和内存之间较慢的访问速度),当一个特定数据第一次被特定一个 CPU 获取时,此数据显然不在 CPU 的 cache 中(这就是 cache miss)。此 cache miss 意味着 CPU 需要从内存中获取数据(这个过程需要 CPU 等待数百个周期),此数据将被加载到 CPU 的 cache 中,这样后续就能直接从 cache 上快速访问。当某个 CPU 进行写操作时,它必须确保其他的 CPU 已经将此数据从它们的 cache 中移除(以便保证一致性),只有在移除操作完成后此 CPU 才能安全的修改数据。显然,存在多个 cache 时,我们必须通过一个 cache 一致性协议来避免数据不一致的问题,而这个通讯的过程就可能导致乱序访问的出现,也就是这里说的运行时内存乱序访问。这里不再深入讨论整个细节,这是一个比较复杂的问题,有兴趣可以研究http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdf 一文,其详细的分析了整个过程。
现在通过一个例子来说明多 CPU 下内存乱序访问:
// test2.cpp
#include
#include
// ——————-
int cpu_thread1 = 0;
int cpu_thread2 = 1;
volatile int x, y, r1, r2;
void start()
{
x = y = r1 = r2 = 0;
}
void end()
{
assert(!(r1 == 0 && r2 == 0));
}
void run1()
{
x = 1;
r1 = y;
}
void run2()
{
y = 1;
r2 = x;
}
// ——————-
static pthread_barrier_t barrier_start;
static pthread_barrier_t barrier_end;
static void* thread1(void*)
{
while (1) {
pthread_barrier_wait(&barrier_start);
run1();
pthread_barrier_wait(&barrier_end);
}
return NULL;
}
static void* thread2(void*)
{
while (1) {
pthread_barrier_wait(&barrier_start);
run2();
pthread_barrier_wait(&barrier_end);
}
return NULL;
}
int main()
{
assert(pthread_barrier_init(&barrier_start, NULL, 3) == 0);
assert(pthread_barrier_init(&barrier_end, NULL, 3) == 0);
pthread_t t1;
pthread_t t2;
assert(pthread_create(&t1, NULL, thread1, NULL) == 0);
assert(pthread_create(&t2, NULL, thread2, NULL) == 0);
cpu_set_t cs;
CPU_ZERO(&cs);
CPU_SET(cpu_thread1, &cs);
assert(pthread_setaffinity_np(t1, sizeof(cs), &cs) == 0);
CPU_ZERO(&cs);
CPU_SET(cpu_thread2, &cs);
assert(pthread_setaffinity_np(t2, sizeof(cs), &cs) == 0);
while (1) {
start();
pthread_barrier_wait(&barrier_start);
pthread_barrier_wait(&barrier_end);
end();
}
return 0;
}
这里创建了两个线程来运行测试代码(需要测试的代码将放置在 run 函数中)。我使用了 pthread barrier(区别于本文讨论的 Memory Barrier)主要为了让两个子线程能够同时运行它们的 run 函数。此段代码不停的尝试同时运行两个线程的 run 函数,以便得出我们期望的结果。在每次运行 run 函数前会调用一次 start 函数(进行数据初始化),run 运行后会调用一次 end 函数(进行结果检查)。run1 和 run2 两个函数运行在哪个 CPU 上则通过 cpu_thread1 和 cpu_thread2 两个变量控制。
先编译此程序:g++ -lpthread -o test2 test2.cpp(这里未优化,目的是为了避免编译器优化的干扰)。需要注意的是,两个线程运行在两个不同的 CPU 上(CPU 0 和 CPU 1)。只要内存不出现乱序访问,那么 r1 和 r2 不可能同时为 0,因此断言失败表示存在内存乱序访问。编译之后运行此程序,会发现存在一定概率导致断言失败。为了进一步说明问题,我们把 cpu_thread2 的值改为 0,换而言之就是让两个线程跑在同一个 CPU 下,再运行程序发现断言不再失败。
最后,我们使用 CPU Memory Barrier 来解决内存乱序访问的问题(X86-64 架构下):
int cpu_thread1 = 0;
int cpu_thread2 = 1;
void run1()
{
x = 1;
asm volatile(“mfence” ::: “memory”);
r1 = y;
}
void run2()
{
y = 1;
asm volatile(“mfence” ::: “memory”);
r2 = x;
}
准备使用 Memory Barrier
Memory Barrier 常用场合包括:
实现同步原语(synchronization primitives)
实现无锁数据结构(lock-free data structures)
驱动程序
实际的应用程序开发中,开发者可能完全不知道 Memory Barrier 就可以开发正确的多线程程序,这主要是因为各种同步机制中已经隐含了 Memory Barrier(但和实际的 Memory Barrier 有细微差别),这就使得不直接使用 Memory Barrier 不会存在任何问题。但是如果你希望编写诸如无锁数据结构,那么 Memory Barrier 还是很有用的。
通常来说,在单个 CPU 上,存在依赖的内存访问有序:
Q = P;
D = *Q;
这里内存操作有序。然而在 Alpha CPU 上,存在依赖的内存读取操作不一定有序,需要使用数据依赖 barrier(由于 Alpha 不常见,这里就不详细解释了)。
在 Linux 内核中,除了前面说到的编译器 barrier — barrier() 和 ACCESS_ONCE(),还有 CPU Memory Barrier:
通用 barrier,保证读写操作有序的,mb() 和 smp_mb()
写操作 barrier,仅保证写操作有序的,wmb() 和 smp_wmb()
读操作 barrier,仅保证读操作有序的,rmb() 和 smp_rmb()
注意,所有的 CPU Memory Barrier(除了数据依赖 barrier 之外)都隐含了编译器 barrier。这里的 smp 开头的 Memory Barrier 会根据配置在单处理器上直接使用编译器 barrier,而在 SMP 上才使用 CPU Memory Barrier(也就是 mb()、wmb()、rmb(),回忆上面相关内核代码)。
最后需要注意一点的是,CPU Memory Barrier 中某些类型的 Memory Barrier 需要成对使用,否则会出错,详细来说就是:一个写操作 barrier 需要和读操作(或数据依赖)barrier 一起使用(当然,通用 barrier 也是可以的),反之依然。
Memory Barrier 的范例
读内核代码进一步学习 Memory Barrier 的使用。
Linux 内核实现的无锁(只有一个读线程和一个写线程时)环形缓冲区 kfifo 就使用到了 Memory Barrier,实现源码如下:
/*
- A simple kernel FIFO implementation.
* - Copyright (C) 2004 Stelian Pop stelian@popies.net
* - This program is free software; you can redistribute it and/or modify
- it under the terms of the GNU General Public License as published by
- the Free Software Foundation; either version 2 of the License, or
- (at your option) any later version.
* - This program is distributed in the hope that it will be useful,
- but WITHOUT ANY WARRANTY; without even the implied warranty of
- MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
- GNU General Public License for more details.
* - You should have received a copy of the GNU General Public License
- along with this program; if not, write to the Free Software
- Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
*
*/
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/err.h>
#include <linux/kfifo.h>
#include <linux/log2.h>
/**
- kfifo_init - allocates a new FIFO using a preallocated buffer
- @buffer: the preallocated buffer to be used.
- @size: the size of the internal buffer, this have to be a power of 2.
- @gfp_mask: get_free_pages mask, passed to kmalloc()
- @lock: the lock to be used to protect the fifo buffer
* - Do NOT pass the kfifo to kfifo_free() after use! Simply free the
- &struct kfifo with kfree().
*/
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
gfp_t gfp_mask, spinlock_t *lock)
{
struct kfifo *fifo;
/* size must be a power of 2 */
BUG_ON(!is_power_of_2(size));
fifo = kmalloc(sizeof(struct kfifo), gfp_mask);
if (!fifo)
return ERR_PTR(-ENOMEM);
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = 0;
fifo->lock = lock;
return fifo;
}
EXPORT_SYMBOL(kfifo_init);
/**
- kfifo_alloc - allocates a new FIFO and its internal buffer
- @size: the size of the internal buffer to be allocated.
- @gfp_mask: get_free_pages mask, passed to kmalloc()
- @lock: the lock to be used to protect the fifo buffer
* - The size will be rounded-up to a power of 2.
*/
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
/*
- round up to the next power of 2, since our ‘let the indices
- wrap’ technique works only in this case.
*/
if (!is_power_of_2(size)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}
EXPORT_SYMBOL(kfifo_alloc);
/**
- kfifo_free - frees the FIFO
- @fifo: the fifo to be freed.
*/
void kfifo_free(struct kfifo *fifo)
{
kfree(fifo->buffer);
kfree(fifo);
}
EXPORT_SYMBOL(kfifo_free);
/**
- __kfifo_put - puts some data into the FIFO, no locking version
- @fifo: the fifo to be used.
- @buffer: the data to be added.
- @len: the length of the data to be added.
* - This function copies at most @len bytes from the @buffer into
- the FIFO depending on the free space, and returns the number of
- bytes copied.
* - Note that with only one concurrent reader and one concurrent
- writer, you don’t need extra locking to use these functions.
*/
unsigned int __kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/*
- Ensure that we sample the fifo->out index -before- we
- start putting bytes into the kfifo.
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
/*
- Ensure that we add the bytes to the kfifo -before-
- we update the fifo->in index.
*/
smp_wmb();
fifo->in += len;
return len;
}
EXPORT_SYMBOL(__kfifo_put);
/**
- __kfifo_get - gets some data from the FIFO, no locking version
- @fifo: the fifo to be used.
- @buffer: where the data must be copied.
- @len: the size of the destination buffer.
* - This function copies at most @len bytes from the FIFO into the
- @buffer and returns the number of copied bytes.
* - Note that with only one concurrent reader and one concurrent
- writer, you don’t need extra locking to use these functions.
*/
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/*
- Ensure that we sample the fifo->in index -before- we
- start removing bytes from the kfifo.
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
- Ensure that we remove the bytes from the kfifo -before-
- we update the fifo->out index.
*/
smp_mb();
fifo->out += len;
return len;
}
EXPORT_SYMBOL(__kfifo_get);
为了更好的理解上面的源码,这里顺带说一下此实现使用到的一些和本文主题无关的技巧:
使用与操作来求取环形缓冲区的下标,相比取余操作来求取下标的做法效率要高不少。使用与操作求取下标的前提是环形缓冲区的大小必须是 2 的 N 次方,换而言之就是说环形缓冲区的大小为一个仅有一个 1 的二进制数,那么 index & (size – 1) 则为求取的下标(这不难理解)
使用了 in 和 out 两个索引且 in 和 out 是一直递增的(此做法比较巧妙),这样能够避免一些复杂的条件判断(某些实现下,in == out 时还无法区分缓冲区是空还是满)
这里,索引 in 和 out 被两个线程访问。in 和 out 指明了缓冲区中实际数据的边界,也就是 in 和 out 同缓冲区数据存在访问上的顺序关系,由于未使用同步机制,那么保证顺序关系就需要使用到 Memory barrier 了。索引 in 和 out 都分别只被一个线程修改,而被两个线程读取。__kfifo_put 先通过 in 和 out 来确定可以向缓冲区中写入数据量的多少,这时,out 索引应该先被读取后才能真正的将用户 buffer 中的数据写入缓冲区,因此这里使用到了 smp_mb(),对应的,__kfifo_get 也使用 smp_mb() 来确保修改 out 索引之前缓冲区中数据已经被成功读取并写入用户 buffer 中了。对于 in 索引,在 __kfifo_put 中,通过 smp_wmb() 保证先向缓冲区写入数据后才修改 in 索引,由于这里只需要保证写入操作有序,故选用写操作 barrier,在 __kfifo_get 中,通过 smp_rmb() 保证先读取了 in 索引(这时候 in 索引用于确定缓冲区中实际存在多少可读数据)才开始读取缓冲区中数据(并写入用户 buffer 中),由于这里只需要保证读取操作有序,故选用读操作 barrier。
由于缓存的原因导致的线程间内存操作相互不可见的原理,并介绍了四种内存屏障模型#LoadLoad,#StoreStore,#LoadStore和#StoreLoad
如果你使用过版本控制系统,那么你也许能够更容易理解内存顺序,进而理解无锁代码的诸多特性。
理解内存顺序需要两步,第一步在我之前的文章编译期间的内存顺序 已经成功介绍了,而第二步,则是这篇文章我想讲的,来自于处理器本身的运行时的内存操作重排。和编译器的重排相似,处理器的重排也是对单线程程序不可见的,只有在无锁程序中,共享内存被多个不互斥的线程同时访问时才能够出现。不过,与编译重排不同的是,处理器重排只在多核/多处理器系统可见。
你可以通过强制一些指令表现为内存屏障来保证正确的内存顺序,从某种意义上来说,你只需要这些技巧就够了,因为这样,编译器顺序就已经自动维护了。这些指令包括但不限于:
某些特定的汇编指令,例如PowerPC的 asm volatile(“lwsync” ::: “memory”)
任何Win32的原子操作(Interlock operation),Xbox360除外
大部分C++11原子类型的方法
与POSIX锁相关的操作,如 pthread_mutex_lock
既然有很多的指令都能表现的如同一个内存屏障,那么内存屏障的种类就有很多种了。实际上,上述的这些指令所代表的内存屏障都并不相同。leading to another possible area of confusion when writing lock-free code。为了让读者能够更加清楚,我准备通过类比的方式介绍大部分内存屏障的种类。
首先,考虑经典的多核系统:双核,每个核有32KB的私有L1缓存,1MB的公有L2缓存,和512MB的公有主存。
一个多核系统有点像一组程序员合作完成一个工程,他们用了一个很奇怪的源码维护方式。比如一个双核系统意味着两个程序员,我们不妨称他们为Larry和Sergey
在我们的右边,我们有一个公有的,核心代码仓库,这一部分表示了主存和L2缓存。Larry与Sergey分别将将他们的相关代码拷贝到自己的私有电脑上,这个私有电脑代表了每一个核拥有的L1缓存,由于每一个机器都有一个暂存区域,默默地耿总寄存器以及局部变量。我们的两个程序员坐在电脑前,不停地改动他们自己暂存区中的代码拷贝,这里的改动指的是基于自己在内存中(自己的私有拷贝)看到的数据,进行一系列决策,并且更新内存中的数据,和线程的执行过程完全相同。
现在,我们再来看看代码控制的策略吧,在这个类比情形中,源码控制的策略非常奇怪。当Larry和Sergey修改了自己的私有代码仓库,他们的修改逐步的渗透到中心代码仓库,而且这种渗透是随机的。一旦Larry修改了本地代码X,修改一定会在通过渗透与中心代码仓库同步,但是我们无法保证渗透的时间。也许同步在修改后立即发生,也许在修改后很久很久才成功同步。甚至当Larry后续修改了代码Y和Z,后面的修改比前面的修改更早渗透也是有可能的。在这样的情形下,内存的写从主存的角度来看,是完全乱序的。
同样的,在Sergey的机器上,修改从公共代码仓库反向同步到私有代码仓库的时间也是不固定的,内存读的顺序因此也被打乱了。
现在,倘若一个程序员在这个代码仓库中工作,他既不会知道中心代码的渗透同步何时在发生,他甚至不能知道是否有其他程序员在和他一起工作!这样,程序员就可以和我们的线程联系到一起了。顺便一提,之前曾提到过的基本规则——单线程无法分辨内存的乱序仍然是满足的。
上述类比在程序员们开始处理代码仓库的同一个文件时,变得很有意思。首先,我们复习一下之前文章中提到的一个问题:X和Y都是初始值为0的全局变量:
考虑X和Y是存在于Larry的私有仓库的两个文件,同时X和Y也存在于公共代码仓库和Sergey的私有仓库。Larry在自己的私有仓库的X中写下了一个1,同时Sergey也在同时向自己的私有仓库Y写下了一个1。现在,由于他们写的太快了,双方都在自己修改还没有渗透到公共仓库的情况下查询另一个文件的值。他们会发现同时满足r1=0和r2=0。这个结果在原来是根本无法理解的,但是通过代码仓库的类比,我们发现这中情况的发生是显然的。
内存屏障的种类
幸运的是,对于这种无法预测的渗透同步操作,Larry和Sergey并没有束手无策。他们拥有一个特殊的指令,称之为“屏障(fence)”。屏障(fence)的表现和内存屏障(memory barrier)相似,且在我们的类比中,我们可以定义出四种不同的内存屏障(memory barrier),每一种屏障通过一种“屏障指令(fence instruction)”实现,且代表了一种为了避免的内存重排。举一个例子#StoreLoad是用来防止一个内存写后面一个内存读这样的指令的重排的。
正如Doug Lea指出的,这四个类别非常清楚地对应了真实CPU上的指令,但是也不近绝对。在大多数情况下,CPU的指令可能表现的向上述一些屏障类型的组合,甚至外加一些其他额外的效果。不过,只要通过类比你理解这四种屏障的含义,你就可以很轻松拓展到真实CPU上的情况了。
#LoadLoad
一个#LoadLoad屏障用于防止屏障前的Load操作和屏障后的Load操作的重排。
在我们的类比中,一个#LoadLoad屏障等价于从中心仓库pull一次。考虑 git pull , hg pull , p4 sync , svn update 或者 cvs update ,都是作用于整个代码仓库的,如果其中有任何合并冲突,那么就只有随机舍弃一边的修改了。
这里有一点需要注意的,#LoadLoad操作并没有保证pull的一定是最近的修改,他甚至可能pull到一个较早的修改,不过可以保证的是,屏障后的Load操作至少会比之前的Load操作更新。也就是说至少不会比最近渗透同步到私有仓库的那个文件早。
听起来,这是一个非常弱的保证,不过仍然能够有效防止读取到过时的信息。考虑一个经典操作,Sergey通过比较公共的标记(flag)来判断是否有一些数据被Larry更新了,如果flag是真,那么他就可以在读取数据之前使用#LoadLoad屏障来保证数据已经成功更新的值。
if (IsPublished) // Load and check shared flag
{
LOADLOAD_FENCE(); // Prevent reordering of loads
return Value; // Load published value
}
1
2
3
4
5
if (IsPublished) // Load and check shared flag
{
LOADLOAD_FENCE(); // Prevent reordering of loads
return Value; // Load published value
}
诚然,这个例子要求 IsPublished 标记自己渗透到Sergey的私有仓库,而这并没有确切发生时间,不过只要标记成功渗透过去,那么Sergey久一定可以通过#LoadLoad屏障防止读到的 Value 比标记老。
#StoreStore
一个#StoreStore屏障用于防止屏障前的Store操作和屏障后的Store操作的重排。
在我们的类比中,一个#StoreStore屏障等价于向中心仓库push一次。考虑 git push , hg push , p4 submit , svn commit 或者 cvs commit ,都是作用于整个代码仓库的。
同理,我们#StoreStore操作可能不会立即进行,而是存在一些延迟,类似于异步操作。因此,即使Larry执行了#StoreStore,我们并不能得出什么时候他的所有的Store操作在中心仓库可见。
相似的,虽然看起来#StoreStore屏障非常的弱,但仍然足够用来防止Sergey看到过时的数据。还是原来的例子,Larry只需要先讲数据放在储存下来,然后使用#StoreStore屏障,保证之后对flag的储存一定晚于数据就好了。
Value = x; // Publish some data
STORESTORE_FENCE();
IsPublished = 1; // Set shared flag to indicate availability of data
1
2
3
Value = x; // Publish some data
STORESTORE_FENCE();
IsPublished = 1; // Set shared flag to indicate availability of data
我们假设 IsPublished 自发渗透到了Larry的私有仓库,一旦Sergey发现了flag的变化,那么他可以肯定此时读到的Value是足够新的。有趣的是,这样的工作甚至不需要Value是一个原子数据类型,甚至一个复杂的大结构体也可以使用这种方式传递。
#LoadStore
不同于#LoadLoad和#StoreStore,我们不太好用版本系统的方式理解。最好的理解方式很简单,就是用从指令重排的角度理解。
考虑Larry有一系列操作,其中一部分让他从自己的私有仓库读取一些数据到寄存器,另一部分将寄存器的信息写回到私有仓库。在一些特殊的情况下,Larry有能力去打乱这些指令的顺序。一旦他遇到了load操作,他看看之后的所有store操作,如果这些store操作完全和当前的load无关,那么他允许这些store提前执行,并在之后执行load。在这种情况下,基本规则——单线程无法分辨出内存乱序是满足的。
在真实CPU上,如果在load操作时发生了cache miss,而在store操作时发生了cache hit,处理器可能会尝试上述的内存操作重排。不过,硬件的实现细节并不会有助于我们理解内存屏障。现在Larry有一个很无聊的工作,不过有些时候他被允许自行调整工作的顺序,这样的调整是不可预料的。幸运的是,存在这样的一个时间花销并不昂贵的指令,强制Larry不在这个地方随意调整读写的执行顺序。
在我们的类比中,即使存在了#LoadLoad屏障和#StoreStore屏障,Larry仍然可以在Load和Store中间进行重排。不过在真实CPU中,如果一个指令表现为#LoadStore屏障,那么这个指令一定可以以理解为#LoadLoad和#StoreStore的其中之一。
#StoreLoad
一个#StoreLoad屏障保证屏障前所有的Store在其他处理器可见后,屏障后的Load操作的结果一定比Store操作的结果更新。换句话说,这个屏障保证了屏障前的所有store操作不会发生在之后所有load操作之后。符合顺序一致性。
#StoreLoad非常特别,因为他是唯一一种可以防止前文例子中结果为r1=r2=0的情况的发生。看到这里,你一定会非常疑惑,为什么#StoreLoad操作就是如此的特别呢?毕竟#StoreStore等价于代码管理的push,#LoadLoad等价于代码管理的pull,而这两种内存屏障都是不够的。因为push操作可能被延迟若干时间,而这时pull并没有能力去获得最新的版本。这结识了为什么PowerPC的 lwsync 操作同时支持了#LoadLoad,#LoadStore和#StoreStore,但是仍然无法防止r1=r2=0的出现。
在类比中,#StoreLoad屏障push了所有的局部修改,等这些修改push完成后,再pull最近的远程库的HEAD。在大多数处理器中#StoreLoad屏障的时间花销远大于其他三种内存屏障。
如果我们使用了#LoadStore,我们就能够得到一个万能的内存屏障,同时支持了本文介绍的四种内存屏障。正如Doug Lea所说,所有支持#StoreLoad屏障的指令都是一个完整的内存屏障。
版本控制的类比告诉我们
之前曾说过,每一个处理器在处理内存重排的策略不尽相同。在x86/64系列中,内存模型是抢的,内存重排被降低到了最小。而在PowerPC和ARM中,内存模型是弱的,Alpha则自成一派。辛运的是,我们的类比是依赖于弱内存模型的,只要我们在类比中成功理解了屏障操作,那么我们就可以随心所欲解决主流CPU的无锁编程任务了。
这个类比在C++11下也非常实用,因此,如果我们这个类比来理解无锁代码,那么也可以在很多平台上正确编程。
在这个类比中,我曾假设所有程序员在不同的核上执行程序,而在实际的操作系统中,线程有时会在不同的核上交替运行,不过我们的假设依然成立。同时,我们的类比是以C++为载体,不过也可拓展到其他语言上。
一. 内存屏障 Memory Barrior
1.1 重排序
同步的目的是保证不同执行流对共享数据并发操作的一致性。在单核时代,使用原子变量就很容易达成这一目的。甚至因为CPU的一些访存特性,对某些内存对齐数据的读或写也具有原子的特性。但在多核架构下即使操作是原子的,仍然会因为其他原因导致同步失效。
首先是现代编译器的代码优化和编译器指令重排可能会影响到代码的执行顺序。
其次还有指令执行级别的乱序优化,流水线、乱序执行、分支预测都可能导致处理器次序(Process Ordering,机器指令在CPU实际执行时的顺序)和程序次序(Program Ordering,程序代码的逻辑执行顺序)不一致。可惜不影响语义依旧只能是保证单核指令序列间,单核时代CPU的Self-Consistent特性在多核时代已不存在(Self-Consistent即重排原则:有数据依赖不会进行重排,单核最终结果肯定一致)。
除此还有硬件级别Cache一致性(Cache Coherence)带来的问题:CPU架构中传统的MESI协议中有两个行为的执行成本比较大。一个是将某个Cache Line标记为Invalid状态,另一个是当某Cache Line当前状态为Invalid时写入新的数据。所以CPU通过Store Buffer和Invalidate Queue组件来降低这类操作的延时。如图:
当一个核心在Invalid状态进行写入时,首先会给其它CPU核发送Invalid消息,然后把当前写入的数据写入到Store Buffer中。然后异步在某个时刻真正的写入到Cache Line中。当前CPU核如果要读Cache Line中的数据,需要先扫描Store Buffer之后再读取Cache Line(Store-Buffer Forwarding)。但是此时其它CPU核是看不到当前核的Store Buffer中的数据的,要等到Store Buffer中的数据被刷到了Cache Line之后才会触发失效操作。
而当一个CPU核收到Invalid消息时,会把消息写入自身的Invalidate Queue中,随后异步将其设为Invalid状态。和Store Buffer不同的是,当前CPU核心使用Cache时并不扫描Invalidate Queue部分,所以可能会有极短时间的脏读问题。这里的Store Buffer和Invalidate Queue的说法是针对一般的SMP架构来说的,不涉及具体架构。
内存对于缓存更新策略,要区分Write-Through和Write-Back两种策略。前者更新内容直接写内存并不同时更新Cache,但要置Cache失效,后者先更新Cache,随后异步更新内存。通常X86 CPU更新内存都使用Write-Back策略。
1.2 编译器屏障 Compiler Barrior
/* The “volatile” is due to gcc bugs */
#define barrier() asm volatile(“”: : :”memory”)
阻止编译器重排,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
1.3 CPU屏障 CPU Barrior
CPU级别内存屏障其作用有两个:
防止指令之间的重排序
保证数据的可见性
指令重排中Load和Store两种操作会有Load-Store、Store-Load、Load-Load、Store-Store这四种可能的乱序结果。
Intel为此提供三种内存屏障指令:
sfence ,实现Store Barrior 会将store buffer中缓存的修改刷入L1 cache中,使得其他cpu核可以观察到这些修改,而且之后的写操作不会被调度到之前,即sfence之前的写操作一定在sfence完成且全局可见;
lfence ,实现Load Barrior 会将invalidate queue失效,强制读取入L1 cache中,而且lfence之后的读操作不会被调度到之前,即lfence之前的读操作一定在lfence完成(并未规定全局可见性);
mfence ,实现Full Barrior 同时刷新store buffer和invalidate queue,保证了mfence前后的读写操作的顺序,同时要求mfence之后写操作结果全局可见之前,mfence之前写操作结果全局可见;
lock 用来修饰当前指令操作的内存只能由当前CPU使用,若指令不操作内存仍然由用,因为这个修饰会让指令操作本身原子化,而且自带Full Barrior效果;还有指令比如IO操作的指令、exch等原子交换的指令,任何带有lock前缀的指令以及CPUID等指令都有内存屏障的作用。
X86-64下仅支持一种指令重排:Store-Load ,即读操作可能会重排到写操作前面,同时不同线程的写操作并没有保证全局可见,例子见《Intel® 64 and IA-32 Architectures Software Developer’s Manual》手册8.6.1、8.2.3.7节。要注意的是这个问题只能用mfence解决,不能靠组合sfence和lfence解决。(用sfence+lfence组合仅可以解决重排问题,但不能解决全局可见性问题,简单理解不如视为sfence和lfence本身也能乱序重拍)
X86-64一般情况根本不会需要使用lfence与sfence这两个指令,除非操作Write-Through内存或使用 non-temporal 指令(NT指令,属于SSE指令集),比如movntdq, movnti, maskmovq,这些指令也使用Write-Through内存策略,通常使用在图形学或视频处理,Linux编程里就需要使用GNC提供的专门的函数(例子见参考资料13:Memory part 5: What programmers can do)。
下面是GNU中的三种内存屏障定义方法,结合了编译器屏障和三种CPU屏障指令
#define lfence() asm volatile(“lfence”: : :”memory”)
#define sfence() asm volatile(“sfence”: : :”memory”)
#define mfence() asm volatile(“mfence”: : :”memory”)
代码中仍然使用lfence()与sfence()这两个内存屏障应该也是一种长远的考虑。按照Interface写代码是最保险的,万一Intel以后出一个采用弱一致模型的CPU,遗留代码出问题就不好了。目前在X86下面视为编译器屏障即可。
GCC 4以后的版本也提供了Built-in的屏障函数__sync_synchronize(),这个屏障函数既是编译屏障又是内存屏障,代码插入这个函数的地方会被安插一条mfence指令。
C++11为内存屏障提供了专门的函数std::atomic_thread_fence,方便移植统一行为而且可以配合内存模型进行设置,比如实现Acquire-release语义:
#include
std::atomic_thread_fence(std::memory_order_acquire);
std::atomic_thread_fence(std::memory_order_release);
二、内存模型
2.1 Acquire与Release语义
对于Acquire来说,保证Acquire后的读写操作不会发生在Acquire动作之前
对于Release来说,保证Release前的读写操作不会发生在Release动作之后
Acquire & Release 语义保证内存操作仅在acquire和release屏障之间发生
X86-64中Load读操作本身满足Acquire语义,Store写操作本身也是满足Release语义。但Store-Load操作间等于没有保护,因此仍需要靠mfence或lock等指令才可以满足到Synchronizes-with规则。
2.2 happens-before规则
相对于Synchronizes-with规则更宽松,happens-before规则定义指令执行顺序与变量的可见性,类似偏序关系,具有可传递性,因此可以运用于并行逻辑分析。
2.3 内存一致性模型 Memory Model
内存一致性模型从程序员视角,由内存序Memory Ordering和写操作原子性Store Atomicity来定义,针对不同线程中原子操作的全局顺序:
Strong Consistency / Sequential consistency 顺序一致性
Release Consistency / release-acquire / release-consume
Relaxed Consistency
C++11相应定义了6种内存模型:
std::memory_order_seq_cst 所有读写操作不能跨过,写顺序全线程可见
std::memory_order_acq_rel 所有读写操作不能跨过,写顺序仅同步线程间可见、std::memory_order_release 所有读写操作不能往后乱序、std::memory_order_acquire 所有读写操作不能向前乱序、std::memory_order_consume 依赖该读操作的后续读写操作不能向前乱序
std::memory_order_relaxed 无特殊要求
三. volatile 关键字
voldatile关键字首先具有“易变性”,声明为volatile变量编译器会强制要求读内存,相关语句不会直接使用上一条语句对应的的寄存器内容,而是重新从内存中读取。
其次具有”不可优化”性,volatile告诉编译器,不要对这个变量进行各种激进的优化,甚至将变量直接消除,保证代码中的指令一定会被执行。
最后具有“顺序性”,能够保证Volatile变量间的顺序性,编译器不会进行乱序优化。不过要注意与非volatile变量之间的操作,还是可能被编译器重排序的。
需要注意的是其含义跟原子操作无关,比如:volatile int a; a++; 其中a++操作实际对应三条汇编指令实现”读-改-写“操作(RMW),并非原子的。
思考:bool类型是不是适合使用,不会出问题。
不同编程语言中voldatile含义与实现并不完全相同,Java语言中voldatile变量可以被看作是一种轻量级的同步,因其还附带了acuire和release语义。实际上也是从JDK5以后才通过这个措施进行完善,其volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。Java语言中有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个lock指令,就是增加一个完全的内存屏障指令,这点与C++实现并不一样。volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
Java实践中仅满足下面这些条件才应该使用volatile关键字:
变量写入操作不依赖变量当前值,或确保只有一个线程更新变量的值(Java可以,C++仍然不能)
该变量不会与其他变量一起纳入
变量并未被锁保护
C++中voldatile等于插入编译器级别屏障,因此并不能阻止CPU硬件级别导致的重排。C++11 中volatile语义没有任何变化,不过提供了std::atomic工具可以真正实现原子操作,而且默认加入了内存屏障(可以通过在store与load操作时设置内存模型参数进行调整,默认为std::memory_order_seq_cst)。
C++实践中推荐涉及并发问题都使用std::atomic,只有涉及特殊内存操作的时候才使用volatile关键字。这些情况通常IO相关,防止相关操作被编译器优化,也是volatile关键字发明的本意。
四、使用经验
内存屏障相关并行逻辑使用的分析顺序:线程安全、操作原子性、存储器操作顺序
C++ 使用对齐变量与mfence
C++11 使用std::atomic与std::atomic_thread_fence,先使用默认std::memory_order_seq_cst模型再进行相关优化
Java 使用volatile或atomic
一个经典的例子就是DCL双重检查加锁实现单例模式,本意是想要实现延迟初始化
@NotThreadSafe
public class DoubleCheckedLock {
private static Resource resoure;
public static Resource getInstance() {
if (resource == null) {
synchronized (DoubleCheckedLock.class) {
if (resource == null)
resource = new Resource();
}
}
return resource;
} } 问题在于未同步状态下读共享变量,可能获取的是中间值,比如这里获取的resource对象可能还未完全构造好。尽管JDK5以后声明为volatile可以避免这个问题,但DCL已经没有必要,因为Java可以利用JVM内部静态类装载的特点实现“延迟初始化占位类模式”来达到同样的效果。C++下面可以使用pthread_once实现。
内存屏障是一种底层原语,在不同计算机架构下有不同的实现细节。本文主要在x86_64处理器下,通过Linux及其内核代码来分析和使用内存屏障
对大多数应用层开发者来说,“内存屏障”(memory barrier)是一种陌生,甚至有些诡异的技术。实际上,他常被用在操作系统内核中,用于实现同步机制、驱动程序等。利用它,能实现高效的无锁数据结构,提高多线程程序的性能表现。本文首先探讨了内存屏障的必要性,之后介绍如何使用内存屏障实现一个无锁唤醒缓冲区(队列),用于在多个线程间进行高效的数据交换。
理解内存屏障
不少开发者并不理解一个事实 – 程序实际运行时很可能并不完全按照开发者编写的顺序访问内存。例如:
1
2
x = r;
y = 1;
这里,y = 1很可能先于x = r执行。这就是内存乱序访问。内存乱序访问行为出现的理由是为了提升程序运行时的性能。编译器和CPU都可能引起内存乱序访问:
编译时,编译器优化进行指令重排而导致内存乱序访问;
运行时,多CPU间交互引入内存乱序访问。
编译器和CPU引入内存乱序访问通常不会带来什么问题,但在一些特殊情况下(主要是多线程程序中),逻辑的正确性依赖于内存访问顺序,这时,内存乱序访问会带来逻辑上的错误,例如:
1
2
3
4
5
6
7
// thread 1
while(!ok);
do(x);
// thread 2
x = 42;
ok = 1;
ok初始化为0, 线程1等待ok被设置为1后执行do函数。假如,线程2对内存的写操作乱序执行,也就是x赋值晚于ok赋值完成,那么do函数接受的实参很有可能出乎开发者的意料,不为42。
我们可以引入内存屏障来避免上述问题的出现。内存屏障能让CPU或者编译器在内存访问上有序。一个内存屏障之前的内存访问操作必定先于其之后的完成。内存屏障包括两类:编译器屏障和CPU内存屏障。
编译时内存乱序访问
编译器对代码做出优化时,可能改变实际执行指令的顺序(例如g++下O2或者O3都会改变实际执行指令的顺序),看一个例子:
1
2
3
4
5
6
int x, y, r;
void f()
{
x = r;
y = 1;
}
首先直接编译次源文件:g++ -S test.cpp。我们得到相关的汇编代码如下:
1
2
3
movl r(%rip), %eax
movl %eax, x(%rip)
movl $1, y(%rip)
这里我们可以看到,x = r和y = 1并没有乱序执行。现使用优化选项O2(或O3)编译上面的代码(g++ -O2 –S test.cpp),生成汇编代码如下:
1
2
3
movl r(%rip), %eax
movl $1, y(%rip)
movl %eax, x(%rip)
我们可以清楚地看到经过编译器优化之后,movl $1, y(%rip)先于movl %eax, x(%rip)执行,这意味着,编译器优化导致了内存乱序访问。避免次行为的办法就是使用编译器屏障(又叫优化屏障)。Linux内核提供了函数barrier(),用于让编译器保证其之前的内存访问先于其之后的内存访问完成。(这个强制保证顺序的需求在哪里?换句话说乱序会带来什么问题内? – 一个线程执行了 y =1 , 但实际上x=r还没有执行完成,此时被另一个线程抢占,另一个线程执行,发现y=1,以为此时x必定=r,执行相应逻辑,造成错误)内核实现barrier()如下:
1
#define barrier() asm volatile(“”: : :”memory”)
现在把此编译器barrier加入代码中:
1
2
3
4
5
6
7
int x, y, r;
void f()
{
x = r;
asm volatile(“”: : :”memory”)
y = 1;
}
再编译,就会发现内存乱序访问已经不存在了。除了barrier()函数外,本例还可以使用volatile这个关键字来避免编译时内存乱序访问(且仅能避免编译时的乱序访问,为什么呢,可以参考前面部分的说明,编译器对于volatile声明究竟做了什么 – volatile关键字对于编译器而言,是开发者告诉编译器,这个变量内存的修改,可能不再你可视范围内,不要对这个变量相关的代码进行优化)。volatile关键字能让volatile变量之间的内存访问上有序,这里可以修改x和y的定义来解决问题:
1
volatile int x, y, r;
通过volatile关键字,使得x相对y、y相对x在内存访问上是有序的。实际上,Linux内核中,宏ACCESS_ONCE能避免编译器对于连续的ACCESS_ONCE实例进行指令重排,其就是通过volatile实现的:
1
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
此代码只是将变量x转换为volatile的而已。现在我们就有了第三个修改方案:
1
2
3
4
5
6
int x, y, r;
void f()
{
ACCESS_ONCE(x) = r;
ACCESS_ONCE(y) = 1;
}
到此,基本上就阐述完成了编译时内存乱序访问的问题。下面看看CPU会有怎样的行为。
运行时内存乱序访问
运行时,CPU本身是会乱序执行指令的。早期的处理器为有序处理器(in-order processors),总是按开发者编写的顺序执行指令,如果指令的输入操作对象(input operands)不可用(通常由于需要从内存中获取),那么处理器不会转而执行那些输入操作对象可用的指令,而是等待当前输入操作对象可用。相比之下,乱序处理器(out-of-order processors)会先处理那些有可用输入操作对象的指令(而非顺序执行)从而避免了等待,提高了效率。现代计算机上,处理器运行的速度比内存快很多,有序处理器花在等待可用数据的时间里已可处理大量指令了。即便现代处理器会乱序执行,但在单个CPU上,指令能通过指令队列顺序获取并执行,结果利用队列顺序返回寄存器堆(详情可参考http://en.wikipedia.org/wiki/Out-of-order_execution),这使得程序执行时所有的内存访问操作看起来像是按程序代码编写的顺序执行的,因此内存屏障是没有必要使用的(前提是不考虑编译器优化的情况下)。
SMP架构需要内存屏障的进一步解释:从体系结构上来看,首先在SMP架构下,每个CPU与内存之间,都配有自己的高速缓存(Cache),以减少访问内存时的冲突
采用高速缓存的写操作有两种模式:(1). 穿透(Write through)模式,每次写时,都直接将数据写回内存中,效率相对较低;(2). 回写(Write back)模式,写的时候先写回告诉缓存,然后由高速缓存的硬件再周转复用缓冲线(Cache Line)时自动将数据写回内存,或者由软件主动地“冲刷”有关的缓冲线(Cache Line)。出于性能的考虑,系统往往采用的是模式2来完成数据写入。正是由于存在高速缓存这一层,正是由于采用了Write back模式的数据写入,才导致在SMP架构下,对高速缓存的运用可能改变对内存操作的顺序。已上面的一个简短代码为例:
1
2
3
4
5
6
7
// thread 0 – 在CPU0上运行
x = 42;
ok = 1;
// thread 1 – 在CPU1上运行
while(!ok);
print(x);
这里CPU1执行时, x一定是打印出42吗?让我们来看看以下图为例的说明:
假设,正好CPU0的高速缓存中有x,此时CPU0仅仅是将x=42写入到了高速缓存中,另外一个ok也在高速缓存中,但由于周转复用高速缓冲线(Cache Line)而导致将ok=1刷会到了内存中,此时CPU1首先执行对ok内存的读取操作,他读到了ok为1的结果,进而跳出循环,读取x的内容,而此时,由于实际写入的x(42)还只在CPU0的高速缓存中,导致CPU1读到的数据为x(17)。程序中编排好的内存访问顺序(指令序: program ordering)是先写入x,再写入y。而实际上出现在该CPU外部,即系统总线上的次序(处理器序: processor ordering),却是先写入y,再写入x(这个例子中x还未写入)。在SMP架构中,每个CPU都只知道自己何时会改变内存的内容,但是都不知道别的CPU会在什么时候改变内存的内容,也不知道自己本地的高速缓存中的内容是否与内存中的内容不一致。反过来,每个CPU都可能因为改变了内存内容,而使得其他CPU的高速缓存变的不一致了。在SMP架构下,由于高速缓存的存在而导致的内存访问次序(读或写都有可能书序被改变)的改变很有可能影响到CPU间的同步与互斥。因此需要有一种手段,使得在某些操作之前,把这种“欠下”的内存操作(本例中的x=42的内存写入)全都最终地、物理地完成,就好像把欠下的债都结清,然后再开始新的(通常是比较重要的)活动一样。这种手段就是内存屏障,其本质原理就是对系统总线加锁。
回过头来,我们再来看看为什么非SMP架构(UP架构)下,运行时内存乱序访问不存在。在单处理器架构下,各个进程在宏观上是并行的,但是在微观上却是串行的,因为在同一时间点上,只有一个进程真正在运行(系统中只有一个处理器)。在这种情况下,我们再来看看上面提到的例子:
线程0和线程1的指令都将在CPU0上按照指令序执行。thread0通过CPU0完成x=42的高速缓存写入后,再将ok=1写入内存,此后串行的将thread0换出,thread1换入,及时此时x=42并未写入内存,但由于thread1的执行仍然是在CPU0上执行,他仍然访问的是CPU0的高速缓存,因此,及时x=42还未写回到内存中,thread1势必还是先从高速缓存中读到x=42,再从内存中读到ok=1
综上所述,在单CPU上,多线程执行不存在运行时内存乱序访问,我们从内核源码也可得到类似结论(代码不完全摘录)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#define barrier() asm volatile(“”: : :”memory”)
#define mb() alternative(“lock; addl $0,0(%%esp)”, “mfence”, X86_FEATURE_XMM2)
#define rmb() alternative(“lock; addl $0,0(%%esp)”, “lfence”, X86_FEATURE_XMM2)
#ifdef CONFIG_SMP
#define smp_mb() mb()
#define smp_rmb() rmb()
#define smp_wmb() wmb()
#define smp_read_barrier_depends() read_barrier_depends()
#define set_mb(var, value) do { (void) xchg(&var, value); } while (0)
#else
#define smp_mb() barrier()
#define smp_rmb() barrier()
#define smp_wmb() barrier()
#define smp_read_barrier_depends() do { } while(0)
#define set_mb(var, value) do { var = value; barrier(); } while (0)
#endif
这里可看到对内存屏障的定义,如果是SMP架构,smp_mb定义为mb(),mb()为CPU内存屏障(接下来要谈的),而非SMP架构时(也就是UP架构),直接使用编译器屏障,运行时内存乱序访问并不存在。
为什么多CPU情况下会存在内存乱序访问?我们知道每个CPU都存在Cache,当一个特定数据第一次被其他CPU获取时,此数据显然不在对应CPU的Cache中(这就是Cache Miss)。这意味着CPU要从内存中获取数据(这个过程需要CPU等待数百个周期),此数据将被加载到CPU的Cache中,这样后续就能直接从Cache上快速访问。当某个CPU进行写操作时,他必须确保其他CPU已将此数据从他们的Cache中移除(以便保证一致性),只有在移除操作完成后,此CPU才能安全地修改数据。显然,存在多个Cache时,必须通过一个Cache一致性协议来避免数据不一致的问题,而这个通信的过程就可能导致乱序访问的出现,也就是运行时内存乱序访问。受篇幅所限,这里不再深入讨论整个细节,有兴趣的读者可以研究《Memory Barriers: a Hardware View for Software Hackers》这边文章,它详细地分析了整个过程。
现在通过一个例子来直观地说明多CPU下内存乱序访问的问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
volatile int x, y, r1, r2;
//thread 1
void run1()
{
x = 1;
r1 = y;
}
//thread 2
void run2
{
y = 1;
r2 = x;
}
变量x、y、r1、r2均被初始化为0,run1和run2运行在不同的线程中。如果run1和run2在同一个cpu下执行完成,那么就如我们所料,r1和r2的值不会同时为0,而假如run1和run2在不同的CPU下执行完成后,由于存在内存乱序访问的可能,这时r1和r2可能同时为0。我们可以使用CPU内存屏障来避免运行时内存乱序访问(x86_64):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void run1()
{
x = 1;
//CPU内存屏障,保证x=1在r1=y之前执行
asm volatile(“mfence”:::”memory”);
r1 = y;
}
//thread 2
void run2
{
y = 1;
//CPU内存屏障,保证y = 1在r2 = x之前执行
asm volatile(“mfence”:::”memory”);
r2 = x;
}
这里mfence的含义是什么?
x86/64系统架构提供了三中内存屏障指令:(1) sfence; (2) lfence; (3) mfence。(参考介绍:http://peeterjoot.wordpress.com/2009/12/04/intel-memory-ordering-fence-instructions-and-atomic-operations/ 以及Intel文档:http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-3a-part-1-manual.pdf 和http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html)
sfence
Performs a serializing operation on all store-to-memory instructions that were issued prior the SFENCE instruction. This serializing operation guarantees that every store instruction that precedes in program order the SFENCE instruction is globally visible before any store instruction that follows the SFENCE instruction is globally visible. The SFENCE instruction is ordered with respect store instructions, other SFENCE instructions, any MFENCE instructions, and any serializing instructions (such as the CPUID instruction). It is not ordered with respect to load instructions or the LFENCE instruction.
也就是说sfence确保:sfence指令前后的写入(store/release)指令,按照在sfence前后的指令序进行执行。写内存屏障提供这样的保证: 所有出现在屏障之前的STORE操作都将先于所有出现在屏障之后的STORE操作被系统中的其他组件所感知.
[!] 注意, 写屏障一般需要与读屏障或数据依赖屏障配对使用; 参阅”SMP内存屏障配对”章节. (译注: 因为写屏障只保证自己提交的顺序, 而无法干预其他代码读内存的顺序. 所以配对使用很重要. 其他类型的屏障亦是同理.)
lfence
Performs a serializing operation on all load-from-memory instructions that were issued prior the LFENCE instruction. This serializing operation guarantees that every load instruction that precedes in program order the LFENCE instruction is globally visible before any load instruction that follows the LFENCE instruction is globally visible. The LFENCE instruction is ordered with respect to load instructions, other LFENCE instructions, any MFENCE instructions, and any serializing instructions (such as the CPUID instruction). It is not ordered with respect to store instructions or the SFENCE instruction.
也就是说lfence确保:lfence指令前后的读取(load/acquire)指令,按照在mfence前后的指令序进行执行。读屏障包含数据依赖屏障的功能, 并且保证所有出现在屏障之前的LOAD操作都将先于所有出现在屏障之后的LOAD操作被系统中的其他组件所感知.
[!] 注意, 读屏障一般要跟写屏障配对使用; 参阅”SMP内存屏障的配对使用”章节.
mfence
Performs a serializing operation on all load-from-memory and store-to-memory instructions that were issued prior the MFENCE instruction. This serializing operation guarantees that every load and store instruction that precedes in program order the MFENCE instruction is globally visible before any load or store instruction that follows the MFENCE instruction is globally visible. The MFENCE instruction is ordered with respect to all load and store instructions, other MFENCE instructions, any SFENCE and LFENCE instructions, and any serializing instructions (such as the CPUID instruction).
也就是说mfence指令:确保所有mfence指令之前的写入(store/release)指令,都在该mfence指令之后的写入(store/release)指令之前(指令序,Program Order)执行;同时,他还确保所有mfence指令之后的读取(load/acquire)指令,都在该mfence指令之前的读取(load/acquire)指令之后执行。即:既确保写者能够按照指令序完成数据写入,也确保读者能够按照指令序完成数据读取。通用内存屏障保证所有出现在屏障之前的LOAD和STORE操作都将先于所有出现在屏障之后的LOAD和STORE操作被系统中的其他组件所感知.
sfence我认为其动作,可以看做是一定将数据写回内存,而不是写到高速缓存中。lfence的动作,可以看做是一定将数据从高速缓存中抹掉,从内存中读出来,而不是直接从高速缓存中读出来。mfence则正好结合了两项操作。sfence只确保写者在将数据(A->B)写入内存的顺序,并不确保其他人读(A,B)数据时,一定是按照先读A更新后的数据,再读B更新后的数据这样的顺序,很有可能读者读到的顺序是A旧数据,B更新后的数据,A更新后的数据(只是这个更新后的数据出现在读者的后面,他并没有“实际”去读);同理,lfence也就只能确保读者在读入顺序时,按照先读A最新的在内存中的数据,再读B最新的在内存中的数据的顺序,但如果没有写者sfence的配合,显然,即使顺序一致,内容还是有可能乱序。
为什么仅通过保证了写者的写入顺序(sfence), 还是有可能有问题?还是之前的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void run1()
{
x = 1;
//CPU内存屏障,保证x=1在r1=y之前执行
asm volatile(“sfence”:::”memory”);
r1 = y;
}
//thread 2
void run2
{
y = 1;
//CPU内存屏障,保证y = 1在r2 = x之前执行
asm volatile(“sfence”:::”memory”);
r2 = x;
}
如果仅仅是对“写入”操作进行顺序化,实际上,还是有可能使的上面的代码出现r1,r2同时为0(初始值)的场景:
当CPU0上的thread0执行时,x被先行写回到内存中,但如果此时y在CPU0的高速缓存中,这时y从缓存中读出,并被赋予r1写回内存,此时r1为0。同理,CPU1上的thread1执行时,y被先行写回到内存中,如果此时x在CPU1的高速缓存中存在,则此时r2被赋予了x的(过时)值0,同样存在了r1, r2同时为0。这个现象实际上就是所谓的r1=y的读顺序与x=1的写顺序存在逻辑上的乱序所致(或者是r2 = x与y=1存在乱序) – 读操作与写操作之间存在乱序。而mfence就是将这类乱序也屏蔽掉
如果是通过mfence,是怎样解决该问题的呢?
当thread1在CPU0上对x=1进行写入时,x=1被刷新到内存中,由于是mfence,他要求r1的读取操作从内存读取数据,而不是从缓存中读取数据,因此,此时如果y更新为1,则r1 = 1; 如果y没有更新为1,则r1 = 0, 同时此时由于x更新为1, r2必须从内存中读取数据,则此时r2 = 1。总而言之是r1, r2, 一个=0, 一个=1。
关于内存屏障的一些补充
在实际的应用程序开发中,开发者可能完全不知道内存屏障就写出了正确的多线程程序,这主要是因为各种同步机制中已隐含了内存屏障(但和实际的内存屏障有细微差别),使得不直接使用内存屏障也不会存在任何问题。但如果你希望编写诸如无锁数据结构,那么内存屏障意义重大。
在Linux内核中,除了前面说到的编译器屏障—barrier()和ACESS_ONCE(),还有CPU内存屏障:
通用屏障,保证读写操作有序,包括mb()和smp_mb();
写操作屏障,仅保证写操作有序,包括wmb()和smp_wmb();
读操作屏障,仅保证读操作有序,包括rmb()和smp_rmb();
注意,所有的CPU内存屏障(除了数据依赖屏障外)都隐含了编译器屏障(也就是使用CPU内存屏障后就无需再额外添加编译器屏障了)。这里的smp开通的内存屏障会根据配置在单处理器上直接使用编译器屏障,而在SMP上才使用CPU内存屏障(即mb()、wmb()、rmb())。
还需要注意一点是,CPU内存屏障中某些类型的屏障需要成对使用,否则会出错,详细来说就是:一个写操作屏障需要和读操作(或者数据依赖)屏障一起使用(当然,通用屏障也是可以的),反之亦然。
通常,我们是希望在写屏障之前出现的STORE操作总是匹配度屏障或者数据依赖屏障之后出现的LOAD操作。以之前的代码示例为例:
1
2
3
4
5
6
7
8
9
// thread 1
x = 42;
smb_wmb();
ok = 1;
// thread 2
while(!ok);
smb_rmb();
do(x);
我们这么做,是希望在thread2执行到do(x)时(在ok验证的确=1时),x = 42的确是有效的(写屏障之前出现的STORE操作),此时do(x),的确是在执行do(42)(读屏障之后出现的LOAD操作)
利用内存屏障实现无锁环形缓冲区
最后,以一个使用内存屏障实现的无锁环形缓冲区(只有一个读线程和一个写线程时)来结束本文。本代码源于内核FIFO的一个实现,内容如下(略去了非关键代码):
代码来源:linux-2.6.32.63\kernel\kfifo.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
unsigned int __kfifo_put(struct kfifo fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
* 通过内存屏障确保先读取fifo->out后,才将buffer中数据拷贝到
* 当前fifo中
/
smp_mb();
/ first put the data starting from fifo->in to buffer end /
/ 将数据拷贝至fifo->in到fifo结尾的一段内存中 /
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/ then put the rest (if any) at the beginning of the buffer /
/ 如果存在剩余未拷贝完的数据(此时len – l > 0)则拷贝至
* fifo的开始部分
/
memcpy(fifo->buffer, buffer + l, len - l);
/
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
/*
* 通过写操作屏障确保数据拷贝完成后才更新fifo->in
*/
smp_wmb();
fifo->in += len;
return len; } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len) {
unsigned int l;
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
/*
* 通过读操作屏障确保先读取fifo->in后,才执行另一个读操作:
* 将fifo中数据拷贝到buffer中去
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
/* 从fifo->out开始拷贝数据到buffer中 */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
/* 如果需要数据长度大于fifo->out到fifo结尾长度,
* 则从fifo开始部分拷贝(此时len – l > 0)
*/
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
/* 通过内存屏障确保数据拷贝完后,才更新fifo->out */
smp_mb();
fifo->out += len;
return len; } 这里__kfifo_put被一个线程用于向fifo中写入数据,另外一个线程可以安全地调用__kfifo_get,从此fifo中读取数据。代码中in和out的索引用于指定环形缓冲区实际的头和尾。具体的in和out所指向的缓冲区的位置通过与操作来求取(例如:fifo->in & (fifo->size -1)),这样相比取余操作来求取下表的做法效率要高不少。使用与操作求取下表的前提是环形缓冲区的大小必须是2的N次方,换而言之,就是说环形缓冲区的大小为一个仅有一个1的二进制数,那么index & (size – 1)则为求取的下标(这不难理解)。
索引in和out被两个线程访问。in和out指明了缓冲区中实际数据的边界,也就是in和out同缓冲区数据存在访问上的顺序关系,由于不适用同步机制,那么保证顺序关系就需要使用到内存屏障了。索引in和out都分别只被一个线程修改,而被两个线程读取。__kfifo_put先通过in和out来确定可以向缓冲区中写入数据量的多少,这时,out索引应该先被读取,才能真正将用户buffer中的数据写入缓冲区,因此这里使用到了smp_mb(),对应的,__kfifo_get也使用smp_mb()来确保修改out索引之前缓冲区中数据已被成功读取并写入用户buffer中了。(我认为在__kfifo_put中添加的这个smp_mb()是没有必要的。理由如下,kfifo仅支持一写一读,这是前提。在这个前提下,in和out两个变量是有着依赖关系的,这的确没错,并且我们可以看到在put中,in一定会是最新的,因为put修改的是in的值,而在get中,out一定会是最新的,因为get修改out的值。这里的smp_mb()显然是希望在运行时,遵循out先load新值,in再load新值。的确,这样做是没错,但这是否有必要呢?out一定要是最新值吗?out如果不是最新值会有什么问题?如果out不是最新值,实际上并不会有什么问题,仅仅是在put时,fifo的实际可写入空间要大于put计算出来的空间(因为out是旧值,导致len在计算时偏小),这并不影响程序执行的正确性。从最新linux-3.16-rc3 kernel的代码:lib\kfifo.c的实现:__kfifo_in中也可以看出memcpy(fifo->data + off, src, l); memcpy(fifo->data, src + l, len - l);之前的那次smb_mb()已经被省去了,当然更新in之前的smb_wmb()还是在kfifo_copy_in中被保留了。之所以省去这次smb_mb()的调用,我想除了省去调用不影响程序正确性外,是否还有对于性能影响的考虑,尽量减少不必要的mb调用)对于in索引,在__kfifo_put中,通过smp_wmb()保证先向缓冲区写入数据后才修改in索引,由于这里只需要保证写入操作有序,所以选用写操作屏障,在__kfifo_get中,通过smp_rmb()保证先读取了in索引(这时in索引用于确定缓冲区中实际存在多少可读数据)才开始读取缓冲区中数据(并写入用户buffer中),由于这里指需要保证读取操作有序,故选用读操作屏障。
什么时候需要注意考虑内存屏障(补充)
从上面的介绍我们已经可以看出,在SMP环境下,内存屏障是如此的重要,在多线程并发执行的程序中,一个数据读取与写入的乱序访问,就有可能导致逻辑上错误,而显然这不是我们希望看到的。作为系统程序的实现者,我们涉及到内存屏障的场景主要集中在无锁编程时的原子操作。执行这些操作的地方,就是我们需要考虑内存屏障的地方。
从我自己的经验来看,使用原子操作,一般有如下三种方式:(1). 直接对int32、int64进行赋值;(2). 使用gcc内建的原子操作内存访问接口;(3). 调用第三方atomic库:libatomic实现内存原子操作。
对于第一类原子操作方式,显然内存屏障是需要我们考虑的,例如kernel中kfifo的实现,就必须要显示的考虑在数据写入和读取时插入必要的内存屏障,以保证程序执行的顺序与我们设定的顺序一致。
对于使用gcc内建的原子操作访问接口,基本上大多数gcc内建的原子操作都自带内存屏障,他可以确保在执行原子内存访问相关的操作时,执行顺序不被打断。“In most cases, these builtins are considered a full barrier. That is, no memory operand will be moved across the operation, either forward or backward. Further, instructions will be issued as necessary to prevent the processor from speculating loads across the operation and from queuing stores after the operation.”(http://gcc.gnu.org/onlinedocs/gcc-4.4.5/gcc/Atomic-Builtins.html)。当然,其中也有几个并未实现full barrier,具体情况可以参考gcc文档对对应接口的说明。同时,gcc还提供了对内存屏障的封装接口:__sync_synchronize (…),这可以作为应用程序使用内存屏障的接口(不用写汇编语句)。
对于使用libatomic库进行原子操作,原子访问的程序。Libatomic在接口上对于内存屏障的设置粒度更新,他几乎是对每一个原子操作的接口针对不同平台都有对应的不同内存屏障的绑定。“Provides implementations for atomic memory update operations on a number of architectures. This allows direct use of these in reasonably portable code. Unlike earlier similar packages, this one explicitly considers memory barrier semantics, and allows the construction of code that involves minimum overhead across a variety of architectures.”接口实现上分别添加了_release/_acquire/_full等各个后缀,分别代表的该接口的内存屏障类型,具体说明可参见libatomic的README说明。如果是调用最顶层的接口,已AO_compare_and_swap为例,最终会根据平台的特性以及宏定义情况调用到:AO_compare_and_swap_full或者AO_compare_and_swap_release或者AO_compare_and_swap_release等。我们可以重点关注libatomic在x86_64上的实现,libatomic中,在x86_64架构下,也提供了应用层的内存屏障接口:AO_nop_full
综合上述三点,总结下来便是:如果你在程序中是裸着写内存,读内存,则需要显式的使用内存屏障确保你程序的正确性,gcc内建不提供简单的封装了内存屏障的内存读写,因此,如果只是使用gcc内建函数,你仍然存在裸读,裸写,此时你还是必须显式使用内存屏障。如果你通过libatomic进行内存访问,在x86_64架构下,使用AO_load/AO_store,你可以不再显式的使用内存屏障(但从实际使用的情况来看,libatomic这类接口的效率不是很高)
https://preshing.com/20120710/memory-barriers-are-like-source-control-operations/
1 速度不对等
Cpu的速度比cpu之间的互联性能及cpu试图要访问的内存性能,都要快上几个数量级
上面展示的图显示现代处理器基本都是多核,并且每个cpu都有自己独立的cache,不同cpu共享主内存,然后不同cpu通过总线互联,cpu -> cache -> memory 访问速度成大数量级递减,cpu最快,cache慢一点,memory更慢。
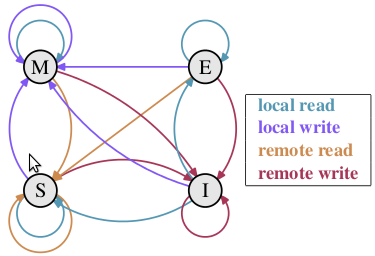
2 MESI协议
cpu从内存中加载数据到自己的cache,当不同的cpu都加载了同样的内存数据的时候,并且对数据进行操作的时候,需要维护数据在不同的cache 中的一致性视图就需要MESI协议,cache里面的缓存行有四种状态分别是Modified,Exclusive,Shared,Invalid。协议在每一个缓存行中维护 一个两位的状态“tag”, 这个“tag”附着在缓存行的物理地址或者数据后 ,标识着缓存行的状态
•Modified 修改的
•Exclusive 独占的
•Shared 共享的
•Invalid 无效的
Modified: 处于“modified”状态的缓存行是由于相应的 CPU 最近进行了内存存储。并 且相应的内存确保没有在其他 CPU 的缓存中出现。因此,“modified”状态的缓 存行可以被认为被 CPU 所“owned”。由于缓存保存了最新的数据,因此缓存最 终有责任将数据写回到内存,并且也应当为其他缓存提供数据,必须在当前缓存 缓存其他数据之前完成这些事情。
Exclusive: 状态非常类似于“modified”状态,唯一的例外是缓存行还没 有被相应的 CPU 修改,这表示缓存行中的数据及内存中的数据都是最新的。但 是,由于 CPU 能够在任何时刻将数据保存到该行,而不考虑其他 CPU,处于 exclusive 状态也可以认为被相应的 CPU 所“owned”。也就是说,由于内存 中的值是最新的,该行可以直接丢弃而不用回写到内存,也可以为其他缓存提供 数据。
Shared: 处于“shared”状态的缓存行可能被复制到至少一个其他 CPU 缓存中,这样 在没有得到其他 CPU 的许可时,不能向缓存行存储数据。由于“exclusive”状 态下,内存中的值是最新的,因此可以不用向内存回写值而直接丢弃缓存中的值, 或者向其他 CPU 提供值。
Invalid: 处于“invalid”状态的行是空的,换句话说,它没有保存任何有效数据。当 新数据进入缓存时,它替换一个处于“invalid”状态的缓存行。这个方法是比较 好的,因为替换其他状态的缓存行将引起大量的 cache miss。
如果上面的文字你都认真看完了,可能有点绕,不过没关系,我们只需要了解这四种状态仅仅是标识出当前在cache里面的缓存行的数据是处于一个什么样的状态,并且下面会简单的介绍通过发送MESI消息来改变这种缓存行的状态
缓存一致性消息:
由于所有 CPUs 必须维护缓存行中的数据一致性视图,因此缓存一致性协议 提供消息以调整系统缓存行的运行。
MESI 协议消息 :
Read:“read”消息包含缓存行需要读的物理地址。
Read Response:“read response”消息包含较早前的“read”消息的数据。 这个“read response”消息可能由内存或者其他缓存提供。例如,如果 一个缓存请求一个处于“modified”状态的数据,则缓存必须提供“read response”消息。
Invalidate“invalidate”消息包含要使无效的缓存行的物理地址。其他的 缓存必须从它们的缓存中移除相应的数据并且响应此消息。
Invalidate Acknowledge:一个接收到“invalidate”消息的 CPU 必须在移 除指定数据后响应一个“invalidate acknowledge”消息。
Read Invalidate:“read invalidate”消息包含要缓存行读取的物理地址。 同时指示其他缓存移除数据。因此,它包含一个“read”和一个 “invalidate”。“read invalidate”也需要“read response”以及“invalidate acknowledge”消息集。
Writeback:“writeback”消息包含要回写到内存的地址和数据。(并且也 许会“snooped”其他 CPUs 的缓存)。这个消息允许缓存在必要时换出 “modified”状态的数据以腾出空间。
