SO_REUSEPORT 多个server进程同时监听一个unix socket文件
nginx配置大致如下:
upstream webserver {
server unix:/var/3w/9101.sock
server unix:/var/3w/9102.sock
server unix:/var/3w/9103.sock
server unix:/var/3w/9104.sock
}
- 多个server 进程,共同对应一个unix socket file,前面走nginx代理
启动配置大致如下:
python webserver –app_sockfile=/var/3w/webserver.sock
python webserver –app_sockfile=/var/3w/webserver.sock
python webserver –app_sockfile=/var/3w/webserver.sock
python webserver –app_sockfile=/var/3w/webserver.sock
nginx配置大致如下:
upstream webserver {
server unix:/var/3w/webserver.sock
}
reuseaddr是用来去掉2MSL的,MSL请看tcp协议,简单来讲,当某个绑定了套接字127.0.0.1:8080的进程stop后,假如没有使用reuseaddr,该进程不能立刻重新运行,反之,则可以立刻running。 reuseport,也是setsockopt来设置套接字属性的
至于多个进程能不能绑定同一个套接字,实践告诉我,是可以的,listen完再fork,所有进程都会占有那个listen的套接字,2.6内核以前,当新的链接握手完成后,所有fork出来的父子进程都会唤醒,但是,只有第一个被schedule的进程才会真正去处理链接,其他的进程睁开眼一看没自己什么事,又接着去睡觉了,俗称惊群。2.6以后内核稍稍优化下,每次只会取待调度队列的第一个进程来唤醒。
在linux 3.9以后kernel引入了SO_REUSEPORT,可以允许多个进程绑定同一个端口,nginx 1.9.1 引入这个feature,可大幅提升性能SO_REUSEPORT vs SO_REUSEADDRhttp://stackoverflow.com/questions/14388706/socket-options-so-reuseaddr-and-so-reuseport-how-do-they-differ-do-they-mean-tSocket Sharding in NGINXhttps://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
先listen后,server会创建一个socket描述符,fork之后,子进程的描述符和父进程的一致,所以子进程accept会和父进程取相同的队列中的connet任务。
服务端监听一个端口会经历:
1、根据套接字类型(Ipv4,Ipv6等)创建套接字socket
2、将套接字bind绑定到具体的网络地址和端口号
3、调用listen开始在这个套接字上进行监听。
Unix提供了一个接口setsockopt()可以在bind之前设置套接字选项,其中就包括REUSEADDR这个选项,表明可以多个进程复用bind函数中指定的地址和端口号。
由此可知多个应用(进程),包括同一个应用多次,都是可以绑定到同一个端口进行监听的。
在默认情况下,IPV4和IPV6的同一个协议的套接口也不能再同一个端口侦听,而套接口编程的五元组就是<IP,port,peerip,peerport,inet proto>,其中没有进程区分,所以一个系统的套接口对于同一个网络地址来说是唯一的。但是有时候为了实现负载平衡,可能希望有多个进程来侦听同一个套接口,从而并发执行某个任务,此时就希望多个相同的进程(相同的可执行文件)来对同一个套接口进行侦听,从而完成负载分流和平衡。
当然,多线程也是一种实现方法,但是缺点就是需要实现用户态编码,不对可执行程序透明,用户态的代码需要自己调用pthread_create来创建多个线程,这样属于一种硬编码的方式,有其资源共享的优点,但是会增加维护的复杂度。而一个程序同时执行多份的话,由于代码段共享的原因,系统同样不会有太大的内存开销,并且可以方便的由用户态决定启动多少个任务而不依赖代码实现。
二、fastcgi starter实现
如果让同一个进程依次派生执行,那么这个多进程侦听同一个套接口是一定无法实现的,因为在bind系统调用会返回端口被占用错误,所以此时就需要由一个父进程来完成这个同一个的bind+listen动作,这时候把一个套接口已经培养到可以执行accept系统调用来获得连接请求的时候,这个fd相当于已经被培育成熟,所以此时根据需要个数派生服务进程,这样子进程就可以在照约定的文件描述符上进行accept接收外部连接请求。或者任务fastcgi派生的都是“官二代”,当这些子进程启动起来之后,它就可以直接从一个文件描述符上进行accept来接见各种连接请求,并且每个子进程都有这种接收机会。
这个流程无论从实现和原理上来讲都不是很复杂,但是比较有创意。大家经常说“文件是unix的精髓”,但是能够把它用到这种地步还真是不容易,同样的套接口,同样的文件描述符,就是可以做到多进程侦听同一个端口的实现。这一点和busybox的可执行文件“多路复用”一样,是一种化腐朽为神奇,或者至少是“化平凡为神奇”的实现方法。而两者也的确是依靠这两个比较有创意的思路,实现了两种非常有用的机制,busybox在嵌入式中几乎是根文件系统的基础,而fastcgi则是网络服务器中的快速响应流行模型。
1、等待队列头创建
最原始的等待队列在sock_alloc—»>
static struct inode sock_alloc_inode(struct super_block *sb)
{
init_waitqueue_head(&ei->socket.wait);
}
中实现,这里其实没有什么初始化,就是初始化了一个自旋锁,并且初始化为可获取状态,它并没有初始化方法成员。
然后在__sock_create—»inet_create—»>sock_init_data
sk->sk_sleep = &sock->wait;
这里将sk结构中的等待队列头指向socket中的wait成员,而这个sk_sleep将会是accept的等待队列头地址。
2、accept阻塞
sys_accept—-»>inet_accept—»inet_csk_accept—-»>inet_csk_wait_for_connect—»prepare_to_wait_exclusive(sk->sk_sleep, &wait,TASK_INTERRUPTIBLE)
wait->flags |= WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
if (list_empty(&wait->task_list))
__add_wait_queue_tail(q, wait);
/
在加入等待队列之后,通过timeo = schedule_timeout(timeo);让出调度权。
这里比较特殊的是这里的唤醒是互斥的,也就是那个 WQ_FLAG_EXCLUSIVE标志,这个标志会在唤醒函数中使用,当遇到这个标志并且唤醒互斥进程个数为1(默认情况)时只唤醒一个进程,其中的prepare_to_wait_exclusiv的wait是通过下面宏创建的
DEFINE_WAIT(wait);
3、连接到来时唤醒
tcp_v4_do_rcv—»>tcp_child_process
/* Wakeup parent, send SIGIO */
if (state == TCP_SYN_RECV && child->sk_state != state)
parent->sk_data_ready(parent, 0);
inet_create—»>sock_init_data
sk->sk_state_change = sock_def_wakeup;
sk->sk_data_ready = sock_def_readable;
sk->sk_write_space = sock_def_write_space;
sk->sk_error_report = sock_def_error_report;
sk->sk_destruct = sock_def_destruct; 也就是执行的sk_data_ready即为sock_def_readable函数,在该函数中,其执行操作为 static void sock_def_readable(struct sock *sk, int len) {
read_lock(&sk->sk_callback_lock);
if (sk->sk_sleep && waitqueue_active(sk->sk_sleep))
wake_up_interruptible(sk->sk_sleep);
sk_wake_async(sk,1,POLL_IN);
read_unlock(&sk->sk_callback_lock); } #define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL) 可以看到,通过sk->sk_sleep唤醒了正在accept的接收套接口,并且其中__wake_up的唤醒互斥任务个数为1,所以只会唤醒一个进程,这次连接的到来对其它任务透明。
这应该是多个进程同时复用一个socket
不过在现代linux中,多个socket同时监听同一个端口也是可能的,在Nginx 1.9.1以上版本也支持这一行为
linux 3.9以上内核支持SO_REUSEPORT选项,即允许多个socket bind/listen在同一个端口上。这样,多个进程就可以各自申请socket监听同一个端口,当数据来时,内核做负载均衡,唤醒监听的其中一个进程处理,用法类似于setsockopt(listener, SOL_SOCKET, SO_REUSEPORT, &option, sizeof(option))
采用SO_REUSEPORT选项可以有效地解决epoll惊群问题
inux下网络编程“惊群”现象,给出Nginx处理惊群的方法,使用互斥锁。为例发挥多核的优势,目前常见的网络编程模型就是多进程或多线程,根据accpet的位置,分为如下场景:
(1)单进程或线程创建socket,并进行listen和accept,接收到连接后创建进程和线程处理连接
(2)单进程或线程创建socket,并进行listen,预先创建好多个工作进程或线程accept()在同一个服务器套接字、
这两种模型解充分发挥了多核CPU的优势,虽然可以做到线程和CPU核绑定,但都会存在:
单一listener工作进程胡线程在高速的连接接入处理时会成为瓶颈
多个线程之间竞争获取服务套接字
缓存行跳跃
很难做到CPU之间的负载均衡
随着核数的扩展,性能并没有随着提升
Linux kernel 3.9带来了SO_REUSEPORT特性,可以解决以上大部分问题。
2、SO_REUSEPORT解决了什么问题
SO_REUSEPORT支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,解决的问题:
允许多个套接字 bind()/listen() 同一个TCP/UDP端口
每一个线程拥有自己的服务器套接字
在服务器套接字上没有了锁的竞争
内核层面实现负载均衡
安全层面,监听同一个端口的套接字只能位于同一个用户下面
其核心的实现主要有三点:
扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport。
修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择。
有了SO_RESUEPORT后,每个进程可以自己创建socket、bind、listen、accept相同的地址和端口,各自是独立平等的。让多进程监听同一个端口,各个进程中accept socket fd不一样,有新连接建立时,内核只会唤醒一个进程来accept,并且保证唤醒的均衡性。
include
#include
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include
#include <sys/wait.h>
#include
#include
#include
#include
#define IP “127.0.0.1”
#define PORT 8888
#define WORKER 4
#define MAXLINE 4096
int worker(int i)
{
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
inet_pton( AF_INET, IP, &address.sin_addr);
address.sin_port = htons(PORT);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
assert(listenfd >= 0);
int val =1;
/*set SO_REUSEPORT*/
if (setsockopt(listenfd, SOL_SOCKET, SO_REUSEPORT, &val, sizeof(val))<0) {
perror("setsockopt()");
}
int ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
while (1) {
printf("I am worker %d, begin to accept connection.\n", i);
struct sockaddr_in client_addr;
socklen_t client_addrlen = sizeof( client_addr );
int connfd = accept( listenfd, ( struct sockaddr* )&client_addr, &client_addrlen );
if (connfd != -1) {
printf("worker %d accept a connection success. ip:%s, prot:%d\n", i, inet_ntoa(client_addr.sin_addr), client_addr.sin_port);
} else {
printf("worker %d accept a connection failed,error:%s", i, strerror(errno));
}
char buffer[MAXLINE];
int nbytes = read(connfd, buffer, MAXLINE);
printf("read from client is:%s\n", buffer);
write(connfd, buffer, nbytes);
close(connfd);
}
return 0; }
int main()
{
int i = 0;
for (i = 0; i < WORKER; i++) {
printf(“Create worker %d\n”, i);
pid_t pid = fork();
/child process */
if (pid == 0) {
worker(i);
}
if (pid < 0) {
printf(“fork error”);
}
}
/wait child process*/
while (wait(NULL) != 0)
;
if (errno == ECHILD) {
fprintf(stderr, “wait error:%s\n”, strerror(errno));
}
return 0;
}
php在socket编程中常用的扩展,pcntl和libevent:
pcntl
php本身并不支持多进程,但通过扩展pcntl便可以实现fork功能,fork编程的大概原理是,每次调用fork函数,操作系统就会产生一个子进程,儿子进程所有的堆栈信息都是原封不动复制父进程的,而在fork之后,父进程与子进程实际上是相互独立的,父子进程不会相互影响。也就是说,fork调用位置之前的所有变量,父进程和子进程是一样的,但fork之后则取决于各自的动作,且数据也是独立的;因为数据已经完整的复制给了子进程。而唯一能够区分父子进程的方法就是判断fork的返回值。如果为0,表示是子进程,如果为正数,表示为父进程,且该正数为子进程的PID(进程号),而如果是-1,表示子进程创建失败。
libevent
linux网络编程中有三大事件处理,IO(socket)、信号和定时器,理解并处理好这三者,linux网络编程就理解了一半,而libevent则是对这三者处理提供了一个很好的封装,大大简化了socket编程中事件处理的难度
一、多个进程监听同个端口
listen 后fork
二、单个进程监听多个端口
<?php
/** * */
class Server {
protected $socks = array();
protected $event_base = null;
protected $events = array();
public function __construct() {
$this->event_base = event_base_new();
}
protected function acceptConnect($sock) {
echo "acceptConnect pid:".getmypid()."\n";
//sleep(5);
if(($msgsock = socket_accept($sock)) < 0) {
echo "socket_accept() failed: reason: " . socket_strerror($msgsock) . " ,pid: ".getmypid()."\n";
//break;
}else{
$msg ="测试成功,sock:$sock ! \n";
echo $msg."pid: ".getmypid()."\n";
socket_write($msgsock, $msg, strlen($msg));
socket_close($msgsock);
}
}
protected function addEvent($sock,$callback) {
$event = event_new();
if (!event_set($event, $sock, EV_READ|EV_PERSIST, $callback, null)) {
echo "event_set faild,pid:".getmypid()."\n";
return ;
}
if (!event_base_set($event,$this->event_base)) {
echo "event_base_set faild,pid:".getmypid()."\n";
return ;
}
if (!event_add($event)) {
echo "event_add faild,pid:".getmypid()."\n";
return ;
}
$this->event[] = $event;
}
public function listen($ip = '127.0.0.1',$port = '5000') {
if(($sock = socket_create(AF_INET,SOCK_STREAM,SOL_TCP)) < 0) {
echo "socket_create() 失败的原因是:".socket_strerror($sock)."\n";
return ;
}
if(($ret = socket_bind($sock,$ip,$port)) < 0) {
echo "socket_bind() 失败的原因是:".socket_strerror($ret)."\n";
return ;
}
if(($ret = socket_listen($sock,4)) < 0) {
echo "socket_listen() 失败的原因是:".socket_strerror($ret)."\n";
return ;
}
$this->socks[] = $sock;
}
public function main() {
if($this->event_base == null)
{
echo "event base null";
return ;
}
echo "event base:".$this->event_base."\n";
foreach ($this->socks as $sock) {
echo "sock:$sock\n";
$this->addEvent($sock,array($this,'acceptConnect'));
}
echo "libevent success,pid:".getmypid()."\n";
$result = event_base_loop($this->event_base);
echo "event loop result:$result";
}
}
$server = new Server();
$server->listen(‘127.0.0.1’,’5000’);
$server->listen(‘127.0.0.1’,’5001’);
$server->main();
运行在Linux系统上网络应用程序,为了利用多核的优势,一般使用以下比较典型的多进程/多线程服务器模型:
单线程listen/accept,多个工作线程接收任务分发,虽CPU的工作负载不再是问题,但会存在:
单线程listener,在处理高速率海量连接时,一样会成为瓶颈
CPU缓存行丢失套接字结构(socket structure)现象严重
所有工作线程都accept()在同一个服务器套接字上呢,一样存在问题:
多线程访问server socket锁竞争严重
高负载下,线程之间处理不均衡,有时高达3:1不均衡比例
导致CPU缓存行跳跃(cache line bouncing)
在繁忙CPU上存在较大延迟
上面模型虽然可以做到线程和CPU核绑定,但都会存在:
单一listener工作线程在高速的连接接入处理时会成为瓶颈
缓存行跳跃
很难做到CPU之间的负载均衡
随着核数的扩展,性能并没有随着提升
Linux kernel 3.9带来了SO_REUSEPORT特性,可以解决以上大部分问题。
SO_REUSEPORT解决了什么问题
linux man文档中一段文字描述其作用:
The new socket option allows multiple sockets on the same host to bind to the same port, and is intended to improve the performance of multithreaded network server applications running on top of multicore systems.
SO_REUSEPORT支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,解决的问题:
允许多个套接字 bind()/listen() 同一个TCP/UDP端口
每一个线程拥有自己的服务器套接字
在服务器套接字上没有了锁的竞争
内核层面实现负载均衡
安全层面,监听同一个端口的套接字只能位于同一个用户下面
其核心的实现主要有三点:
扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport。
修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择。
CPU之间平衡处理,水平扩展
以前通过fork形式创建多个子进程,现在有了SO_REUSEPORT,可以不用通过fork的形式,让多进程监听同一个端口,各个进程中accept socket fd不一样,有新连接建立时,内核只会唤醒一个进程来accept,并且保证唤醒的均衡性。
模型简单,维护方便了,进程的管理和应用逻辑解耦,进程的管理水平扩展权限下放给程序员/管理员,可以根据实际进行控制进程启动/关闭,增加了灵活性。
这带来了一个较为微观的水平扩展思路,线程多少是否合适,状态是否存在共享,降低单个进程的资源依赖,针对无状态的服务器架构最为适合了。
有一个hubtime开源工具,原理为SIGHUP信号处理器+SO_REUSEPORT+LD_RELOAD,可以帮助我们轻松做到服务器无缝重启/切换
https://github.com/amscanne/huptime
SO_REUSEPORT已知问题
SO_REUSEPORT根据数据包的四元组{src ip, src port, dst ip, dst port}和当前绑定同一个端口的服务器套接字数量进行数据包分发。若服务器套接字数量产生变化,内核会把本该上一个服务器套接字所处理的客户端连接所发送的数据包(比如三次握手期间的半连接,以及已经完成握手但在队列中排队的连接)分发到其它的服务器套接字上面,可能会导致客户端请求失败,一般可以使用:
使用固定的服务器套接字数量,不要在负载繁忙期间轻易变化
允许多个服务器套接字共享TCP请求表(Tcp request table)
不使用四元组作为Hash值进行选择本地套接字处理,挑选隶属于同一个CPU的套接字
与RFS/RPS/XPS-mq协作,可以获得进一步的性能:
服务器线程绑定到CPUs
RPS分发TCP SYN包到对应CPU核上
TCP连接被已绑定到CPU上的线程accept()
XPS-mq(Transmit Packet Steering for multiqueue),传输队列和CPU绑定,发送数据
RFS/RPS保证同一个连接后续数据包都会被分发到同一个CPU上
网卡接收队列已经绑定到CPU,则RFS/RPS则无须设置
需要注意硬件支持与否
目的嘛,数据包的软硬中断、接收、处理等在一个CPU核上,并行化处理,尽可能做到资源利用最大化。
SO_REUSEPORT不是一贴万能膏药
虽然SO_REUSEPORT解决了多个进程共同绑定/监听同一端口的问题,但根据新浪林晓峰同学测试结果来看,在多核扩展层面也未能够做到理想的线性扩展
可以参考Fastsocket在其基础之上的改进
支持SO_REUSEPORT的Tengine
淘宝的Tengine已经支持了SO_REUSEPORT特性,在其测试报告中,有一个简单测试,可以看出来相对比SO_REUSEPORT所带来的性能提升:
使用SO_REUSEPORT以后,最明显的效果是在压力下不容易出现丢请求的情况,CPU均衡性平稳。
JDK 1.6语言层面不支持,至于以后的版本,由于暂时没有使用到,不多说。
Netty 3/4版本默认都不支持SO_REUSEPORT特性,但Netty 4.0.19以及之后版本才真正提供了JNI方式单独包装的epoll native transport版本(在Linux系统下运行),可以配置类似于SO_REUSEPORT等(JAVA NIIO没有提供)选项,这部分是在io.netty.channel.epoll.EpollChannelOption中定义(在线代码部分)。
在linux环境下使用epoll native transport,可以获得内核层面网络堆栈增强的红利,如何使用可参考Native transports文档。
使用epoll native transport倒也简单,类名稍作替换:
NioEventLoopGroup → EpollEventLoopGroup
NioEventLoop → EpollEventLoop
NioServerSocketChannel → EpollServerSocketChannel
NioSocketChannel → EpollSocketChannel
但在海量的数据请求下,Linux内核在TCP/IP网络处理方面,已经成为瓶颈。比如新浪在某台HAProxy服务器上取样,90%的CPU时间被内核占用,应用程序只能够分配到较少的CPU时钟周期的资源。
经过Haproxy系统详尽分析后,发现大部分CPU资源消耗在kernel里,并且在多核平台下,kernel在网络协议栈处理过程中存在着大量同步开销。
同时在多核上进行测试,HTTP CPS(Connection Per Second)吞吐量并没有随着CPU核数增加呈现线性增长:
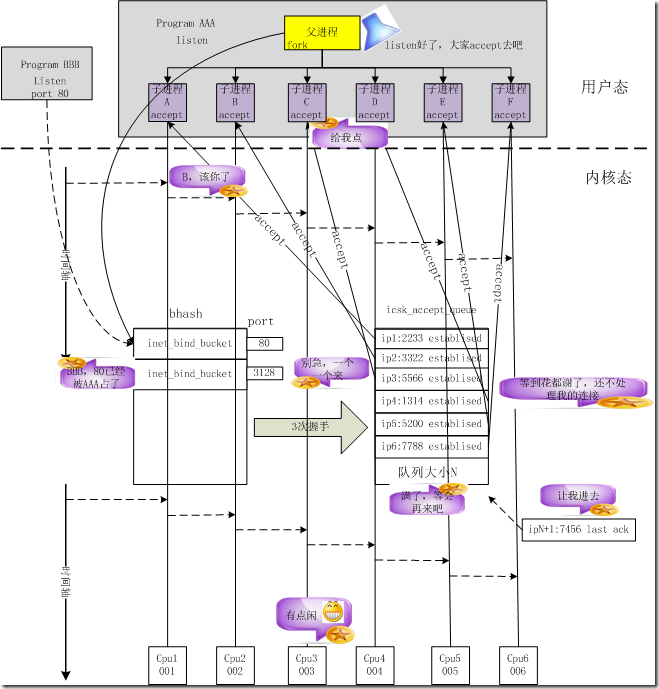
kernel 3.9之前的tcp socket实现
bind系统调用会将socket和port进行绑定,并加入全局tcp_hashinfo的bhash链表中
所有bind调用都会查询这个bhash链表,如果port被占用,内核会导致bind失败
listen则是根据用户设置的队列大小预先为tcp连接分配内存空间
一个应用在同一个port上只能listen一次,那么也就只有一个队列来保存已经建立的连接
nginx在listen之后会fork处多个worker,每个worker会继承listen的socket,每个worker会创建一个epoll fd,并将listen fd和accept的新连接的fd加入epoll fd
但是一旦新的连接到来,多个nginx worker只能排队accept连接进行处理
对于大量的短连接,accept显然成为了一个瓶颈
Linux网络堆栈所存在问题
TCP处理&多核
一个完整的TCP连接,中断发生在一个CPU核上,但应用数据处理可能会在另外一个核上
不同CPU核心处理,带来了锁竞争和CPU Cache Miss(波动不平衡)
多个进程监听一个TCP套接字,共享一个listen queue队列
用于连接管理全局哈希表格,存在资源竞争
epoll IO模型多进程对accept等待,惊群现象
Linux VFS的同步损耗严重
Socket被VFS管理
VFS对文件节点Inode和目录Dentry有同步需求
SOCKET只需要在内存中存在即可,非严格意义上文件系统,不需要Inode和Dentry
代码层面略过不必须的常规锁,但又保持了足够的兼容性
Fastsocket所作改进
TCP单个连接完整处理做到了CPU本地化,避免了资源竞争
保持完整BSD socket API
CPU之间不共享数据,并行化各自独立处理TCP连接,也是其高效的主要原因。其架构图可以看出其改进:
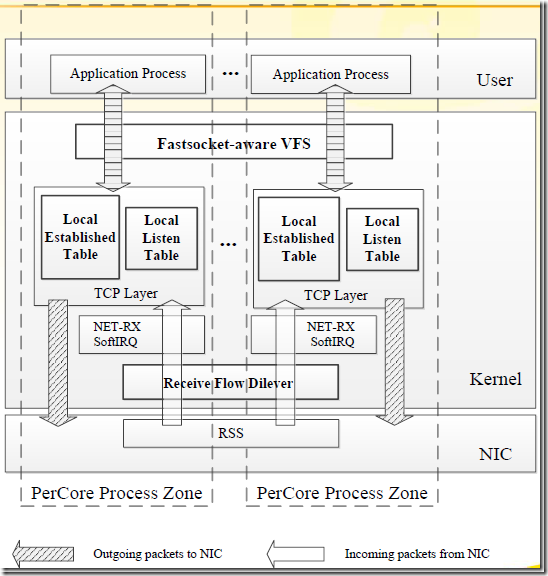
Fastsocket架构图可以很清晰说明其大致结构,内核态和用户态通过ioctl函数传输。记得netmap在重写网卡驱动里面通过ioctl函数直接透传到用户态中,其更为高效,但没有完整的TCP/IP网络堆栈支持嘛。
Fastsocket的TCP调用图
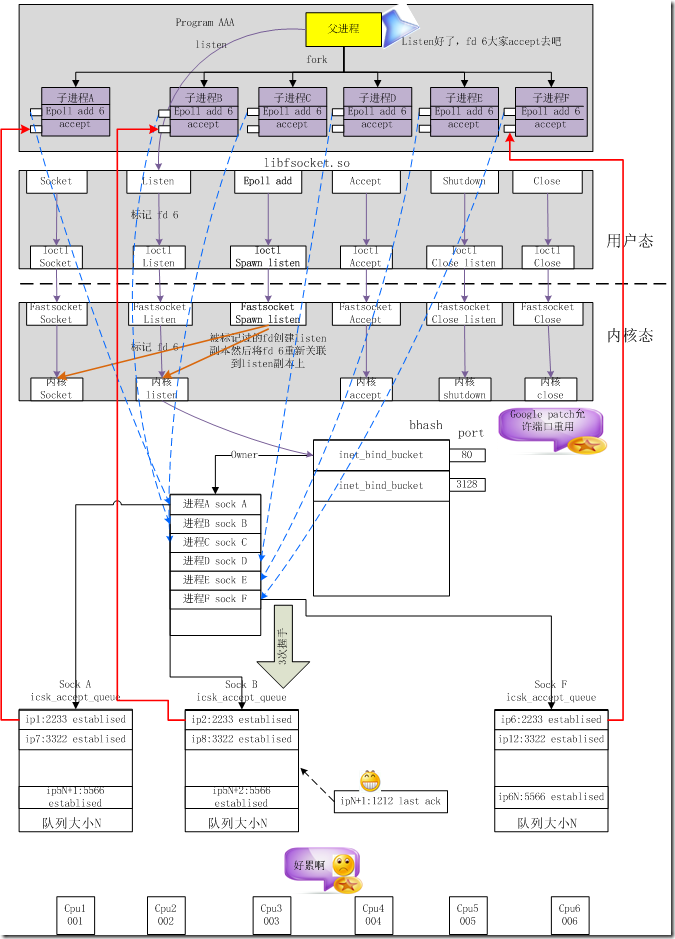
多个进程可以同时listen在同一个port上
动态链接库libfsocket.so拦截socket、bind、listen等系统调用并进入这个链接库进行处理
对于listen系统调用,fastsocket会记录下这个fd,当应用通过epoll将这个fd加入到epoll fdset中时,libfsocket.so会通过ioctl为该进程clone listen fd关联的socket、sock、file的系统资源
内核模块将clone的socket再次调用bind和listen
bind系统调用检测到另外一个进程绑定到已经被绑定的port时,会进行相关检查
通过检查sock将会被记录到port相关联的一个链表中,通过该链表可以知道所有bind同一个port的sock
而sock是关联到fd的,进程则持有fd,那么所有的资源就已经关联到一起
新的进程再次调用listen系统调用的时候,fastsocket内核会再次为其关联的sock分配accept队列
结果是多个进程也就拥有了多个accept队列,可避免cpu cache miss
fastsocket提供将每个listen和accept的进程绑定到用户指定的CPU核
如果用户未指定,fastsocket将会为该进程默认绑定一个空闲的CPU核
Fastsocket短连接性能
在新浪测试中,在24核的安装有Centos 6.5的服务器上,借助于Fastsocket,Nginx和HAProxy每秒处理连接数指标(connection/second)性能很惊人,分别增加290%和620%。这也证明了,Fastsocket带来了TCP连接快速处理的能力。 除此之外,借助于硬件特性:
借助于Intel超级线程,可以获得另外20%的性能增长
HAProxy代理服务器借助于网卡Flow-Director特性支持,吞吐量可增加15%
Fastsocket V1.0正式版从2014年3月份开始已经在新浪生产环境中使用,用作代理服务器,因此大家可以考虑是否可以采用。针对1.0版本,以下环境较为收益:
服务器至少不少于8个CPU核心
短连接被大量使用
CPU周期大部分消耗在网络软中断和套接字系统调用上
应用程序使用基于epoll的非阻塞IO
应用程序使用多个进程单独接受连接
多线程嘛,就得需要参考示范应用所提供实践建议了。
Nginx测试服务器配置
nginx工作进程数量设置成CPU核数个
http keep-alive特性被禁用
测试端http_load从nginx获取64字节静态文件,并发量为500*CPU核数
启用内存缓存静态文件访问,用于排除磁盘影响
务必禁用accept_mutex(多核访问accept产生锁竞争,另fastsocket内核模块为其去除了锁竞争)
Fastsocket在24核服务器达到了475K Connection/Second,获得了21倍的提升
Centos 6.5在CPU核数增长到12核时并没有呈现线性增长势头,反而在24核时下降到159k CPS
Linux kernel 3.13在24核时获得了近乎两倍于Centos 6.5的吞吐量,283K CPS,但在12核后呈现出扩展性瓶颈
HAProxy重要配置
工作进程数量等同于CPU核数个
需要启用RFD(Receive Flow Deliver)
http keep-alive需要禁用
测试端http_load并发量为500*CPU核数
后端服务器响应外围64个字节的消息
测试结果中:
fastsocket呈现出了惊人的扩展性能
24核,Linux kernel 3.13成绩为139K CPS
24核,Centos 6.5借助Fastsocket,获得了370K CPS的吞吐量
当连接到来时,子进程、父进程都可以 accept, 这就是著名的“惊群”问题(thundering herd problem)。
计算机三次握手创建连接是不需要服务进程参数的,而服务进程仅仅要做的事调用accept将已建立的连接构建对应的连接套接字connfd
多个服务进程同时阻塞在accept等待监听套接字已建立连接的信息,那么当内核在该监听套接字上建立一个连接,那么将同时唤起这些处于accept阻塞的服务进程,从而导致“惊群现象”的产生,唤起多余的进程间影响服务器的性能(仅有一个服务进程accept成功,其他进程被唤起后没抢到“连接”而再次进入休眠)
如果多次启动一个进程会报错:“Address already in use!”。这是由于bind函数导致的,由于该端口号已经被监听了。
其实我们只要在绑定端口号(bind函数)之后,监听端口号之前(listen函数),用fork()函数生成子进程,这样子进程就可以克隆父进程,达到监听同一个端口的目的。
启用多个相同服务进程必然需要考虑共用一个socket。对于php-cgi程序来说,是通过stdin文件描述符来传递这个socket。
Parent Proecess:
import os, socket, sys
s = socket.socket()
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind((“”, 8000))
s.listen(10)
for i in xrange(3):
pid = os.fork()
if pid == 0:
os.dup2(s.fileno(), sys.stdin.fileno())
os.execv(“/usr/bin/python”, (“python”, “child.py”))
else:
print “fork”, i, “process id =”, pid
print “Parent exited”
sys.exit()
Child Process:
import socket, os, sys
print “Child”, os.getpid(), “started”
s = socket.fromfd(sys.stdin.fileno(), socket.AF_INET, socket.SOCK_STREAM)
fd, address = s.accept()
print “Accept from”, address
sys.exit()
