时间轮算法
内核自身的正常运行也依赖于时钟系统。Linux 是一个典型的分时系统,CPU 时间被分成多个时间片,这是多任务实现的基础。Linux 内核依赖 tick,即时钟中断来进行分时。
为了满足应用和内核自己的需求,内核时间系统必须提供以下三个基本功能:
提供系统 tick 中断(驱动调度器,实现分时)
维护系统时间
维护软件定时器
目前的 Linux 内核版本为 3.8,其时间系统比较复杂,复杂的原因来自几个方面:
首先 Linux 要支持不同的硬件体系结构和时钟电路,Linux 是一个通用操作系统,支持平台的多样性导致时间系统必须包含各种各样的硬件处理和驱动代码。
其次,早期 Linux 的时钟实现采用低精度时钟框架(ms 级别),随着硬件的发展和软件需求的发展,越来越多的呼声是提高时钟精度(ns 级别);经过若干年的努力,人们发现无法在早期低精度时钟体系结构上优雅地扩展高精度时钟。最终,内核采用了两套独立的代码实现,分别对应于高精度和低精度时钟。这使得代码复杂度增加。
最后,来自电源管理的需求进一步增加了时间系统的复杂性。Linux 越来越多地被应用到嵌入式设备,对节电的要求增加了。当系统 idle 时,CPU 进入节电模式,此时一成不变的时钟中断将频繁地打断 CPU 的睡眠状态,新的时间系统必须改变以应对这种需求,在系统没有任务执行时,停止时钟中断,直到有任务需要执行时再恢复时钟。
以上几点,造成了内核时间系统的复杂性。不过 Linux 内核并不是从一开始就如此复杂,所以还是让我们从头说起吧。
早期的 Linux 时间系统
在 Linux 2.6.16 之前,内核只支持低精度时钟。内核围绕着 tick 时钟来实现所有的时间相关功能。Tick 是一个定期触发的中断,一般由 PIT (Programmable Interrupt Timer) 提供,大概 10ms 触发一次 (100HZ),精度很低。在这个简单体系结构下,内核如何实现三个基本功能?
第一大功能:提供 tick 中断。
以 x86 为例,系统初始化时选择一个能够提供定时中断的设备 (比如 Programmable Interrupt Timer, PIT),配置相应的中断处理 IRQ 和相应的处理例程。当硬件设备初始化完成后,便开始定期地产生中断,这便是 tick 了。非常简单明了,需要强调的是 tick 中断是由硬件直接产生的真实中断,这一点在当前的内核实现中会改变,我们在第四部分介绍。
第二大功能:维护系统时间。
RTC (Real Time Clock) 有独立的电池供电,始终保存着系统时间。Linux 系统初始化时,读取 RTC,得到当前时间值。
读取 RTC 是一个体系结构相关的操作,对于 x86 机器,定义在 arch\x86\kernel\time.c 中。可以看到最终的实现函数为 mach_get_cmos_time,它直接读取 RTC 的 CMOS 芯片获得当前时间。如前所述,RTC 芯片一般都可以直接通过 IO 操作来读取年月日等时间信息。得到存储在 RTC 中的时间值之后,内核调用 mktime () 将 RTC 值转换为一个距离 Epoch(既 1970 年元旦)的时间值。此后直到下次重新启动,Linux 不会再读取硬件 RTC 了。
虽然内核也可以在每次需要的得到当前时间的时候读取 RTC,但这是一个 IO 调用,性能低下。实际上,在得到了当前时间后,Linux 系统会立即启动 tick 中断。此后,在每次的时钟中断处理函数内,Linux 更新当前的时间值,并保存在全局变量 xtime 内。比如时钟中断的周期为 10ms,那么每次中断产生,就将 xtime 加上 10ms。
当应用程序通过 time 系统调用需要获取当前时间时,内核只需要从内存中读取 xtime 并返回即可。就这样,Linux 内核提供了第二大功能,维护系统时间。
第三大功能:软件定时器
能够提供可编程定时中断的硬件电路都有一个缺点,即同时可以配置的定时器个数有限。但现代 Linux 系统中需要大量的定时器:内核自己需要使用 timer,比如内核驱动的某些操作需要等待一段给定的时间,或者 TCP 网络协议栈代码会需要大量 timer;内核还需要提供系统调用来支持 setitimer 和 POSIX timer。这意味着软件定时器的需求数量将大于硬件能够提供的 timer 个数,内核必须依靠软件 timer。
简单的软件 timer 可以通过 timer 链表来实现。需要添加新 timer 时,只需在一个全局的链表中添加一个新的 Timer 元素。每次 tick 中断来临时,遍历该链表,并触发所有到期的 Timer 即可。但这种做法缺乏可扩展性:当 Timer 的数量增加时,遍历链表的花销将线形增加。如果将链表排序,则 tick 中断中无须遍历列表,只需要查看链表头即可,时间为 O(1),但这又导致创建新的 Timer 的时间复杂度变为 O(n),因为将一个元素插入排序列表的时间复杂度为 O(N)。这些都是可行但扩展性有限的算法。在 Linux 尚未大量被应用到服务器时,系统中的 timer 个数不多,因此这种基于链表的实现还是可行的。
但随着 Linux 开始作为一种服务器操作系统,用来支持网络应用时,需要的 timer 个数剧增。一些 TCP 实现对于每个连接都需要 2 个 Timer,此外多媒体应用也需要 Timer,总之 timer 的个数达到了需要考虑扩展性的程度。
timer 的三个操作:添加 (add_timer)、删除 (del_timer) 以及到期处理(tick 中断)都对 timer 的精度和延迟有巨大影响,timer 的精度和延迟又对应用有巨大影响。例如,add_timer 的延迟太大,那么高速 TCP 网络协议就无法实现。为此,从 Linux2.4 开始,内核通过一种被称为时间轮的算法来保证 add_timer()、del_timer() 以及 expire 处理操作的时间复杂度都为 O(1)。
时间轮算法简述
时间轮算法是一种实现软件 timer 的算法,由计算机科学家 George Varghese 等提出,在 NetBSD(一种操作系统) 上实现并替代了早期内核中的 callout 定时器实现。
最原始的时间轮如下图所示。
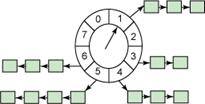
图 1. 原始的时间轮
原始的时间轮
上图中的轮子有 8 个 bucket,每个 bucket 代表未来的一个时间点。我们可以定义每个 bucket 代表一秒,那么 bucket [1] 代表的时间点就是“1 秒钟以后”,bucket [8] 代表的时间点为“8 秒之后”。Bucket 存放着一个 timer 链表,链表中的所有 Timer 将在该 bucket 所代表的时间点触发。中间的指针被称为 cursor。这样的一个时间轮工作如下:
加入Timer:如果新 Timer 在时间点 6 到期,它就被加入 bucket[6] 的 timer 链表。定位 bucket[6] 是一个数组访问的过程,因此这个操作是 O(1) 的。
删除Timer:类似的,删除 Timer 也是 O(1) 的。比如删除一个 6 秒钟后到期的 timer,直接定位到 bucket[6], 然后在链表中删除一个元素是 O(1) 的。
处理Timer的逻辑在时钟中断程序中,每次时钟中断产生时,cursor 增加一格,然后中断处理代码检查 cursor 所指向的 bucket,假如该 bucket 非空,则触发该 bucket 指向的 Timer 链表中的所有 Timer。这个操作也是 O(1) 的。
全都是 O(1) 操作?那这个算法岂不是完美的?可惜不是,我们的这个时间轮有一个限制:新 Timer 的到期时间必须在 8 秒之内。这显然不能满足实际需要,在 Linux 系统中,我们可以设置精度为 1 个 jiffy 的定时器,最大的到期时间范围可以达到 (2^32-1/2 ) 个 jiffies(一个很大的值)。如果采用上面这样的时间轮,我们需要很多个 bucket,需要巨大的内存消耗。这显然是不合理的。
为了减少 bucket 的数量,时间轮算法提供了一个扩展算法,即 Hierarchy 时间轮。图 1 里面的轮实际上也可以画成一个数组,
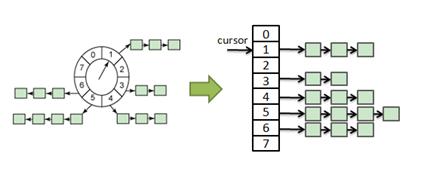
图 2. 时间轮的另一种表示
时间轮的另一种表示
Hierarchy 时间轮将单一的 bucket 数组分成了几个不同的数组,每个数组表示不同的时间精度,下图是其基本思路:
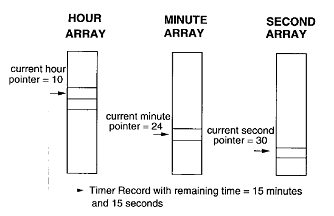
图 3. Hierarchy 时间轮
Hierarchy 时间轮
这样的一个分层时间轮有三级,分别表示小时,分钟和秒。在 Hour 数组中,每个 bucket 代表一个小时。采用原始的时间轮,如果我们要表示一天,且 bucket 精度为 1 秒时,我们需要 246060=86,400 个 bucket;而采用分层时间轮,我们只需要 24+60+60=144 个 bucket。
让我们简单分析下采用这样的数据结构,Timer 的添加/删除/处理操作的复杂度。
添加Timer
根据其到期值,Timer 被放到不同的 bucket 数组中。比如当前时间为 (hour:11, minute:0, second:0),我们打算添加一个 15 分钟后到期的 Timer,就应添加到 MINUTE ARRAY 的第 15 个 bucket 中。这样的一个操作是 O(m) 的,m 在这里等于 3,即 Hierarchy 的层数。
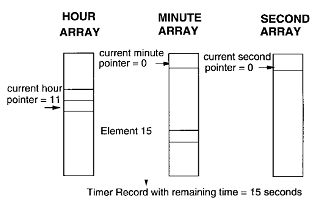
图 4. 添加 15 分钟到期 Timer
添加 15 分钟到期 Timer
删除Timer:
Timer 本身有指向 bucket 的指针,因此删除 Timer 是 O(1) 的操作,比如删除我们之前添加的 15 分钟后到期的 Timer,只需要从该 Timer 的 bucket 指针读取到 MINUTE ARRAY Element 15 的指针,然后从该 List 中删除自己即可。
定时器处理:
每个时钟中断产生时(时钟间隔为 1 秒),将 SECOND ARRAY 的 cursor 加一,假如 SECOND ARRAY 当前 cursor 指向的 bucket 非空,则触发其中的所有 Timer。这个操作是 O(1) 的。
可以看到,添加,删除定时器处理的操作复杂度都很低。
难道 Hierarchy 时间轮完美了?可惜还不是。
为了处理 60 秒之外的那些保存在 MINUTES ARRAY 和 HOUR ARRAY 中的 Timer,时钟中断处理还需要做一些额外的工作:每当 SECOND ARRAY 处理完毕,即 cursor 又回到 0 时,我们应该将 MINUTE ARRAY 的当前 cursor 加一,并查看该 cursor 指向的 bucket 是否为空,如果非空,则需要将这些 Timer 移动到前一个 bucket 中。此外 MINUTE ARRAY 的 bucket[0] 的 Timer 这时候应该都移动到 SECOND ARRAY 中。同样,当 MINUTE ARRAY 的 cursor 重新回到 0 时,我们还需要对 HOUR ARRAY 做类似的处理。这个操作是 O(m) 的,其中 m 是 MINUTE ARRAY 或者 HOUR ARRAY 的 bucket 中时钟的个数。多数情况下 m 远远小于系统中所有 active 的 Timer 个数,但的确,这还是一个费时的操作。
Linux 内核采用的就是 Hierarchy 时间轮算法,Linux 内核中用 jiffies 表示时间而不是时分秒,因此 Linux 没有采用 Hour/Minutes/Second 来分层,而是将 32bit 的 jiffies 值分成了 5 个部分,用来索引五个不同的数组(Linux 术语叫做 Timer Vector,简称 TV),分别表示五个不同范围的未来 jiffies 值。
这个时间轮的精度为 1 个 jiffy,或者说一个 tick。每个时钟中断中,Linux 处理 TV1 的当前 bucket 中的 Timer。当 TV1 处理完(类似 SECOND ARRAY 处理完时),Linux 需要处理 TV2,TV3 等。这个过程叫做 cascades。TV2 当前 bucket 中的时钟需要从链表中读出,重新插入 TV2;TV2->bucket[0] 里面的 timer 都被插入 TV1。这个过程和前面描述的时分秒的时间轮时一样的。cascades 操作会引起不确定的延迟,对于高精度时钟来讲,这还是一个致命的缺点。
但时间轮还是所有 Timer 实现的基础,在它的基础上,Linux 提供了间隔 Timer 和 POSIX Timer 供应用程序使用。
动态 Timer、Interval Timer 和 POSIX Timer
早期 Linux 考虑两种定时器:内核自身需要的 timer,也叫做动态定时器;其次是来自用户态的需要, 即 setitimer 定时器,也叫做间隔定时器。2.5.63 开始支持 POSIX Timer。2.6.16 引入了高精度 hrtimer。本节介绍 hrtimer 出现之前 Linux 内核中动态 Timer,间隔 Timer 和 POSIX Timer 的概念,发展和实现原理。
动态 Timer
动态 timer 由内核自身使用,其实也是其他 Timer 的实现基础。使用动态 Timer 的接口函数有三个:
add_timer()
del_timer()
init_timer()
使用时,先调用 init_timer() 初始化一个定时器,指定到期时间和到期处理函数;初始化完成后,内核代码可以用 add_timer() 启动定时器,或者用 del_timer() 来取消一个已经启动的定时器。
add_timer 采用时间轮算法将定时器加入 per CUP 变量 tvec_bases 中,根据其 expire 时间,可能被加入 5 个 Timer Vector 之一。此后,tick 中断将根据时间轮算法处理。当本 timer 到期时,触发其处理函数。
动态 Timer 有两个方面的用途:一是内核自己使用,比如某些驱动程序需要定时服务的时候使用它;二是用来实现用户层 Timer。下面首先讲解间隔 Timer。
间隔 timer
间隔 timer 就是应用程序调用setitimer建立的定时器。
Linux 的间隔 Timer 实现经历了一个简单的发展过程。
Linux2.4 版本内核在进程描述符中有以下这些数据结构,用来实现间隔 timer:
struct timer_list real_timer;
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_incr;
real_timer 是一个动态 timer,用于 ITIMER_REAL 时钟。其他的 unsigned long 类型的值分别用来维护各种时钟的到期时间和到期后的 interval 时间,用 jiffies 值表示。
ITIMER_REAL 是用内核动态 Timer 来实现的,每次创建 ITIMER_REAL 时钟时,内核调用 init_timer 创建一个定时器对象,并用 add_timer 将该定时器添加到系统 Timer 时间轮中,该定时器的到期处理函数被设定为 it_real_fn()。此函数将向当前进程发送 SIGALRM 信号,并重新调用 add_timer() 重新启动自身。这样便实现了 ITIMER_REAL 时钟。进程描述符中的 it_real_value 仅用于读取,以便用户通过 /proc 读取时钟信息。
另外两种间隔 Timer 则不能简单地依靠动态 Timer 来实现。因为它们参照的是进程的时间而非实时时间,因此要依赖进程的时间统计。实现原理如下:
每次时钟中断产生时,内核判断中断触发时进程是否正处于内核态,如果在内核态,则将 it_prof_value 和 it_virt_value 都减一;如果在用户态,则只对 it_prof_value 减一,而 it_virt_value 不变。当 it_prof_value 为 0 时,对当前进程发送 SIGPROF 信号,并把 it_prof_incr 的值重新填入 it_prof_value,等待下次到期触发。当 it_virt_value为 0 时,则对当前进程发送 SIGVTALRM 信号,并用it_virt_incr的值重新填充 it_virt_value。这样就实现了 POSIX 对 setitimer 所定义的 ITIMER_VIRTUAL 和 ITIMER_PROF 时钟。
不过这种实现有一个问题:在 Linux 中线程是一个单独的调度实体,即轻量级进程。因此一个进程中的每个线程都拥有自己的进程描述符。这意味着每个线程都有自己的 it_virt_value 和 it_prof_value。因此 ITIMER_VIRTUAL,ITIMER_PROF 的计时范围是 per-thread,而 POSIX 规定间隔 Timer 必须是 per-process 的。
比如某进程有 2 个线程,现在建立一个 2 秒到期的 ITIMER_VIRTUAL,假设第一个线程得到了 1 秒的 CPU 时间,此时线程 2 也得到了 1 秒的 CPU 时间。按照 POSIX 标准,此时定时器应该到期。但是根据我们前面所描述的原理,这个时候 ITIMER_VIRTUAL 并没有被触发。如果是在 Thread1 中调用 setitimer,则线程 2 的进程描述符中 it_virt_value 为 0,线程 1 进程描述符中的 it_virt_value 此时为 1 秒,还没有到期,因此进程则必须等到线程 1 运行到 2 秒才能触发这个定时器。这不符合 POSIX 标准,因此从 2.6.12 开始,对上述基本实现进行了一定的改进,虽然从原理上说,这个改进很小,但代码却有比较大的改变。
Per-process ITIMER_VIRTUAL 和 ITIMER_PROF
2.6.12 中合并了 Roland McGrath 的 per-process timer 系列 Patch。使得 itimer.c,posix-timer.c 有了不少改变,还多了一个 posix-cpu-timer.c 文件。虽然代码实现上有很大的不同,但实际上基本的实现思路还是和之前介绍的差不多,不过进一步考虑了对多线程情况下的修正。这里简单介绍一下实现的思路。
每个进程描述符中,引入了两个计数器:utime 和 stime。utime 代表当前进程(也可能是一个线程)花费在用户态的时间。
在时钟中断中,如果内核发现中断时当前进程(线程)正在用户态,则 utime 增加一个 jiffies;如果在内核态则 utime 不增加,stime 增加。总的说来,就是统计好当前进程或线程的运行时间。现在,按下时钟中断暂且不表。
创建 ITIMER_VIRTUAL时 (内核响应函数为do_setitimer),内核将该 Timer 的value 和 interval 分别设置到当前进程描述符的 signal->it_virt_value 和 signal->it_virt_incr 中。假设一个程序有 2 个线程,Thread1 和 Thread2。内核将有两个进程描述符对应这两个线程,taskStruct1 和 taskStruct2。再假设程序是在 Thread1 中调用 setitimer。那么 taskStrcut1的signal->it_virt_value 和 signal->it_virt_incr 被设置;而 taskStruct2 的相应数据则保持为 0。让我们再回到时钟中断。
统计完 utime 和 stime 之后,时钟中断开始检查当前进程描述符的 signal->it_virt_value 值,如果该值非零,则表明有一个 ITIMER_VITURAL,到期时间为 signal->it_virt_value。老的内核实现在这里就判断 utime 是否大于 it_virt_value,如果大于则表明时钟到期。为了统计多线程情况,从 2.6.12 开始,时钟中断在这里不仅要查看当前进程描述符的 utime,还要加上当前进程组中所有线程的 utime,然后再判断总的 utime 是否大于 signal->it_virt_value。比如前面所假设的例子,Thread2 被时钟中断打断时,统计自己的 utime,但由于其 signal->it_virt_value 为 0,因此没有其他的工作需要做了。当 Thread1 被时钟中断打断时,其 signal->it_virt_value 大于 0,因此中断处理中要遍历线程组中所有的线程,将每个线程的 utime 汇总,即总的 utime=taskStruct1->utime+taskStruct2->utime。再用这个总的 utime 和 signal->it_virt_value(即时钟到期时间)进行比较是否到期。仅此而已。
ITIMER_PROF 的思路类似,但它不仅要比较 utime,还要比较 stime。不再赘述。
Posix timer
从 2.5.63 开始,内核能够支持 posix timer 了,之前,其支持是有限的:只支持 CLOCK_REALTIME 和 CLOCK_MONOTONIC 两种 clock ID。这两种 POSIX Timer 建立在内核动态 Timer 之上,精度是一个 tick。比如,创建 realtime 定时器,内核将调用 init_timer() 创建一个动态 Timer,并制定其到期处理函数位 posix_timer_fn;当启动该定时器时,内核将调用 add_timer() 启动该内核动态 Timer;当该定时器到期时,将触发 posix_timer_fn,该函数采用定时器注册的通知方式进行处理,比如 SIGEV_SIGNAL,该函数就会调用 sigaddset 发送一个信号。
其他两种 Timer(CLOCK_PROCESS_CPUTIME_ID 和 CLOCK_THREAD_CPUTIME_ID) 的实现有点儿复杂。因为用户可以创建任意多的 POSIX Timer。CLOCK_REALTIME 和 CLOCK_MONOTONIC 基于数量不限的动态 Timer,因此可以创建任意数目的定时器。
但 CLOCK_PROCESS_CPUTIMER_ID 和 CLOCK_THREAD_CPUTIME_ID,并不依赖动态 Timer,必须在进程描述符中想办法。
2.6.12 在进程描述符中引入了两个 cpu_timers 数组 (所谓 CPU TIME,即进程/线程真正在 CPU 上执行的时间,包括内核态时间和用户态的时间):
一个在进程描述符 task_stuct 中。另一个放在进程描述符的 signal 数据结构中。用 task 表示进程描述符,两个 cpu timers 数组如下:
task->cpu_timers[3]:用来维护 per-thread 的 CPU Timer
task->signal->cpu_timers[3]:用来维护 per-process 的 CPU Timer.
该数组的每个元素都维护一个 Timer 列表。如下图所示:
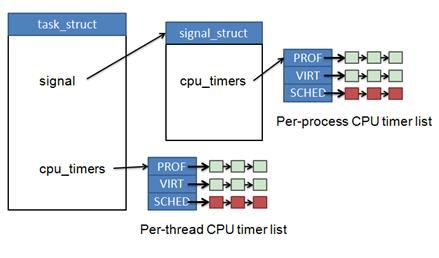
图 5. 进程控制块中的 CPU-TIMER
进程控制块中的 CPU-TIMER
可以看到 Linux 采用排序列表来存放 CLOCK_PROCESS_CPUTIMER_ID 和 CLOCK_THREAD_CPUTIME_ID 的 Timer,即上图中红色的列表(cpu_timer[CPUCLOCK_SCHED])。每当定时中断发生时,会检查这两个链表,如果发现有到期的定时器就触发它们。通过这两个数组,内核支持用户创建任意多 CLOCK_PROCESS_CPUTIMER_ID/CLOCK_THREAD_CPUTIME_ID 类型的 POSIX 定时器。
