MapReduce
原 MapReduce 程序的流程及设计思路:
首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程。
可以看得出原来的 map-reduce 架构是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限。
在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
从操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是适用新的 Hadoop 版本而浪费大量时间。
新 Hadoop Yarn 框架原理及运作机制
从业界使用分布式系统的变化趋势和 hadoop 框架的长远发展来看,MapReduce 的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性,内存消耗,线程模型,可靠性和性能上的缺陷。在过去的几年中,hadoop 开发团队做了一些 bug 的修复,但是最近这些修复的成本越来越高,这表明对原框架做出改变的难度越来越大。
为从根本上解决旧 MapReduce 框架的性能瓶颈,促进 Hadoop 框架的更长远发展,从 0.23.0 版本开始,Hadoop 的 MapReduce 框架完全重构,发生了根本的变化。新的 Hadoop MapReduce 框架命名为 MapReduceV2 或者叫 Yarn:
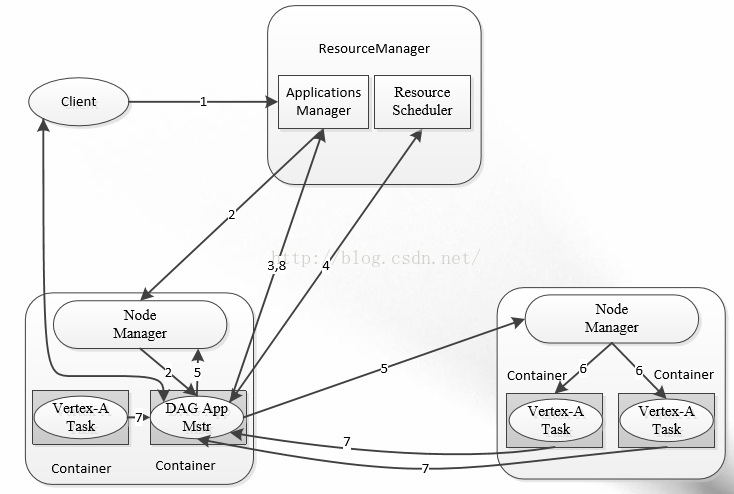
重构根本的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的 MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager 和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。
事实上,每一个应用的 ApplicationMaster 是一个详细的框架库,它结合从 ResourceManager 获得的资源和 NodeManager 协同工作来运行和监控任务。
上图中 ResourceManager 支持分层级的应用队列,这些队列享有集群一定比例的资源。从某种意义上讲它就是一个纯粹的调度器,它在执行过程中不对应用进行监控和状态跟踪。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
ResourceManager 是基于应用程序对资源的需求进行调度的 ; 每一个应用程序需要不同类型的资源因此就需要不同的容器。资源包括:内存,CPU,磁盘,网络等等。可以看出,这同现 Mapreduce 固定类型的资源使用模型有显著区别,它给集群的使用带来负面的影响。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。
上图中 NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
每一个应用的 ApplicationMaster 的职责有:向调度器索要适当的资源容器,运行任务,跟踪应用程序的状态和监控它们的进程,处理任务的失败原因。
新旧 Hadoop MapReduce 框架比对
让我们来对新旧 MapReduce 框架做详细的分析和对比,可以看到有以下几点显著变化:
首先客户端不变,其调用 API 及接口大部分保持兼容,这也是为了对开发使用者透明化,使其不必对原有代码做大的改变 ( 详见 2.3 Demo 代码开发及详解),但是原框架中核心的 JobTracker 和 TaskTracker 不见了,取而代之的是 ResourceManager, ApplicationMaster 与 NodeManager 三个部分。
我们来详细解释这三个部分,首先 ResourceManager 是一个中心的服务,它做的事情是调度、启动每一个 Job 所属的 ApplicationMaster、另外监控 ApplicationMaster 的存在情况。细心的读者会发现:Job 里面所在的 task 的监控、重启等等内容不见了。这就是 AppMst 存在的原因。ResourceManager 负责作业与资源的调度。接收 JobSubmitter 提交的作业,按照作业的上下文 (Context) 信息,以及从 NodeManager 收集来的状态信息,启动调度过程,分配一个 Container 作为 App Mstr
NodeManager 功能比较专一,就是负责 Container 状态的维护,并向 RM 保持心跳。
ApplicationMaster 负责一个 Job 生命周期内的所有工作,类似老的框架中 JobTracker。但注意每一个 Job(不是每一种)都有一个 ApplicationMaster,它可以运行在 ResourceManager 以外的机器上。
Yarn 框架相对于老的 MapReduce 框架什么优势呢?我们可以看到:
这个设计大大减小了 JobTracker(也就是现在的 ResourceManager)的资源消耗,并且让监测每一个 Job 子任务 (tasks) 状态的程序分布式化了,更安全、更优美。
在新的 Yarn 中,ApplicationMaster 是一个可变更的部分,用户可以对不同的编程模型写自己的 AppMst,让更多类型的编程模型能够跑在 Hadoop 集群中,可以参考 hadoop Yarn 官方配置模板中的 mapred-site.xml 配置。
对于资源的表示以内存为单位 ( 在目前版本的 Yarn 中,没有考虑 cpu 的占用 ),比之前以剩余 slot 数目更合理。
老的框架中,JobTracker 一个很大的负担就是监控 job 下的 tasks 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,而 ResourceManager 中有一个模块叫做 ApplicationsMasters( 注意不是 ApplicationMaster),它是监测 ApplicationMaster 的运行状况,如果出问题,会将其在其他机器上重启。
Container 是 Yarn 为了将来作资源隔离而提出的一个框架。这一点应该借鉴了 Mesos 的工作,目前是一个框架,仅仅提供 java 虚拟机内存的隔离 ,hadoop 团队的设计思路应该后续能支持更多的资源调度和控制 , 既然资源表示成内存量,那就没有了之前的 map slot/reduce slot 分开造成集群资源闲置的尴尬情况。
新的 Yarn 框架相对旧 MapRduce 框架而言,其配置文件 , 启停脚本及全局变量等也发生了一些变化,主要的改变如下:
表 1. 新旧 Hadoop 脚本 / 变量 / 位置变化表
改变项 原框架中
配置文件位置 ${hadoop_home_dir}/conf
启停脚本 ${hadoop_home_dir}/bin/start(stop)-all.sh
JAVA_HOME 全局变量 ${hadoop_home_dir}/bin/start-all.sh 中
HADOOP_LOG_DIR 全局变量 不需要配置
由于新的 Yarn 框架与原 Hadoop MapReduce 框架相比变化较大,核心的配置文件中很多项在新框架中已经废弃,而新框架中新增了很多其他配置项,看下表所示会更加清晰:
表 2. 新旧 Hadoop 框架配置项变化表
配置文件 配置项 Hadoop 0.20.X 配置
core-site.xml 系统默认分布式文件 URI fs.default.name
hdfs-site.xml DFS name node 存放 name table 的目录 dfs.name.dir
DFS data node 存放数据 block 的目录 dfs.data.dir
分布式文件系统数据块复制数 dfs.replication
mapred-site.xml Job 监控地址及端口 mapred.job.tracker
第三方 MapReduce 框架 无
Yarn-site.xml The address of the applications manager interface in the RM 无
The address of the scheduler interface 无
The address of the RM web application 无
The address of the resource tracker interface 无
。在hadoop1.0不能满足多系统集成的背景下孕育了yarn的产生。由于多分布式系统可以很好的集成,因此yarn的出现使得整个集群的运维成本大大降低。同时,yarn可以很好的利用集群资源,避免资源的浪费。除此之外,yarn的出现实现了集群的数据共享问题。不同的分布式计算框架可以实现数据的共享,比如hadoop的mapreduce输出可以作为storm的输入。
client发出请求到resourceManager,resourceManager启动Appication master为任务分配相关的资源,分配完成后返回信息到resource Manager,再由resourceManager将任务分发到不同的NodeManager。NodeManager启动Container执行需要的MapReduce工作。 <img src="https://xiazemin.github.io/MyBlog/img/yarn.png"/>
下面根据yarn的工作流程对yarn的工作机制进行解读。首先,client向ResourceManager发出任务请求。Resource Manager指定一个NodeManager启动其ApplicationMaster。ApplicationMaster将计算任务反馈给Resource Manager。ApplicationMaster将任务分割分发到不同的NodeManager。NodeManager启动Task执行work。
yarn具有双层调度策略,ResourceManager将资源分配给ApplicationMaster,ApplicationMaster再将资源分配给NodeManager。而且,yarn具有预留的调度策略。资源不够时,会为Task预留资源,知道积累充足。
yarn具有较好的容错机制。当任务失败,ResourceManager将失败任务告诉ApplicationMaster。由ApplicationMaster处理失败任务。ApplicationMaster会保存已经执行的Task,重启不会重新执行。
yarn支持多类型资源调度,其基于DRF算法实现(论文:“Dominant Resource Fairness: Fair Allocation of Multiple Resource Types”)。而且,其支持多种资源调度器FIFO、Fair Scheduler以及Capacity Scheduler 。最后,yarn支持多租户资源调度器包括支持资源按比例分配、层级队列划分方式以及支持资源抢占 。
yarn支持内存和CPU两种资源隔离。内存是一种“决定生死”的资源。CPU是一种“影响快慢”的资源。其中,内存隔离包括基于线程监控的方案和基于Cgroups的方案。而CPU隔离包括默认不对CPU资源进行隔离和基于Cgroups的方案。
yarn支持的调度语义包括请求某个特定节点/机架上的特定资源量、将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资 源以及请求归还某些资源。不支持的语义包括请求任意节点/机架上的特定资源量、请求一组或几组符合某种特质的资源、超细粒度资源以及动态调整Container资源 。
yarn是通用的统一资源管理系统,同时运行长应用程序和短应用程序 。长应用程序通常情况下,指永不停止运行的程序 ervice、HTTP Server等。短应用程序指短时间(秒级、分钟级、小时级)内会运行结束的程序 MR job、Spark Job等 。如下图所示,yarn使得集群中各种任务的执行成为可能。
1、MapReduce On YARN
MapReduce的执行过程如上图。首先,client向ResourceManager发出任务请求。Resource Manager指定一个NodeManager启动其ApplicationMaster。ApplicationMaster将计算任务反馈给Resource Manager。ApplicationMaster将任务分割分发到不同的NodeManager。NodeManager启动Task执行work。
2、DAG计算框架Tez
多个作业之间存在数据依赖关系,并形成一个依赖关系有向 图( Directed Acyclic Graph ),该图的计算称为“DAG计算”。Apache Tez是基于YARN的DAG计算框架其运行在YARN之上,充分利用YARN的资源管理和容错等功能;Tez提供了丰富的数据流(dataflow)API、扩展性良好的“Input-Processor-Output”运行时模型以及动态生成物理数据流关系。

如上图所示,在MapReduce情况下,如果执行wordcount和topK需要启动两个MapReduce Job。但是,如果用Tez只需要启动一个任务。第一个MapReduce实现wordcount,紧接着执行一个reduce作业实现topK。Tez执行的作业类似于树状拓扑结构。Tez的工作原理类似于上述hadoop的执行流程,如下图所示。
Tez 优化技术 包括:
1、ApplicationMaster缓冲池:
(1).作业提交到AMPoolServer服务上;
(2).预启动若干个ApplicationMaster,形成一个 ApplicationMaster缓冲池.
2、预先启动Container :ApplicationMaster启动时可以预先启动若干个Container 。
3、Container重用:任务运行完成后,ApplicationMaster不会马上注销它使 用的Container,而是将它重新分配给其他未运行的任务。
Tez 应用场景
1、直接编写应用程序
(1).Tez提供了一套通用编程接口;
(2).适合编写有依赖关系的作业。
2、优化Pig、Hive等引擎
(1).下一代Hive:Stinger ;
(2).好处1:避免查询语句转换成过多的MapReduce作业后产 生大量不必要的网络和磁盘IO;
(3).好处2:更加智能的任务处理引擎。
3、流式计算框架Storm
流式(Streaming)计算,是指被处理的数据像流水一样不断流入系统,而系统需要针对每条数据进行实时处理和计算, 并永不停止(直到用户显式杀死进程);传统做法:由消息队列和消息处理者组成的实时处理网络进行实时计算其缺乏自动化、健壮性并且伸缩性差 。因此,storm孕育而生。
如上图所示,Nimbus相当于ResourceManager。Supervisor相当于NodeManager。Nimbus不直接调度Supervisor,而是通过Zookeeper调度。Task中,Spout和Blot相当于Map/Reduce。整个作业是一种拓扑结构。执行以作业流的方式执行。运行在yarn上的storm运行机制类似于hadoop,如下图所示。 <img src="https://xiazemin.github.io/MyBlog/img/storm_yarn.png"/>
4、内存计算框架Spark
spark克服了MapReduce在迭代式计算和交互式计算方面的不足,引入RDD(Resilient Distributed Datasets)数据表示模型。RDD是一个有容错机制,可以被并行操作的数据集合,能够被缓存到内存或磁盘上。
spark如上图所示,可以执行多个stage,最后不同的stage的结果可以合并进行下一步的计算。
Spark在Yarn上的运行机制同样类似于hadoop。
上图为Spark的生态系统。Shark是spark的类sql流语句。sparkStreaming是spark的流式分布式计算框架。Graphx是spark的图计算库MLBase是spark的机器学习库。
