log 高性能 线程安全 zap logrus
zap是uber开源的Go高性能日志库
日志作为整个代码行为的记录,是程序执行逻辑和异常最直接的反馈。对于整个系统来说,日志是至关重要的组成部分。通过分析日志我们不仅可以发现系统的问题,同时日志中也蕴含了大量有价值可以被挖掘的信息,因此合理地记录日志是十分必要的。
我们部门的技术大牛做过精辟的总结:
拔高到哲学或方法论的角度来讲,无论是人或项目质量的进步,还是异常情况的及时发现和排查,至关重要的一点就是详细、正确、及时地反馈。而日志和监控就是用来提供反馈的最强有力的手段。当然,最差的情况就是什么都不管,等到用户发现问题来反馈,不过这样恐怕只能去人才市场了(这一段你可以当我在扯淡)。
我们的业务通常会记录大量的 Debug 日志,但在实际测试过程中,发现我们使用的日志库 seelog 性能存在严重的瓶颈,在我们的对比结果中发现:zap 表现非常突出,单线程 Qps 也是 logrus、seelog 的数倍。
在分析源码后 zap 设计与实现上的考量让我感到受益颇多,在这里我们主要分享一下以下几个方面:
zap 为何有这么高的性能
对于我们自己的开发有什么值得借鉴的地方
如何正确的使用 Go 开发高性能的组件
绝大多数的代码中的写日志通常通过各式各样的日志库来实现。日志库提供了丰富的功能,对于 Go 开发者来说大家常用的日志组件通常会有以下几种,下面简单的总结了常用的日志组件的特点:
seelog: 最早的日志组件之一,功能强大但是性能不佳,不过给社区后来的日志库在设计上提供了很多的启发。
logrus: 代码清晰简单,同时提供结构化的日志,性能较好。
zap: uber 开源的高性能日志库,面向高性能并且也确实做到了高性能。
Zap 代码并不是很多,不到 5000 行,比 seelog 少多了( 8000 行左右), 但比logrus(不到 2000 行)要多很多。为什么我们会选择 zap 呢?
Zap 跟 logrus 以及目前主流的 Go 语言 log 类似,提倡采用结构化的日志格式,而不是将所有消息放到消息体中,简单来讲,日志有两个概念:字段和消息。字段用来结构化输出错误相关的上下文环境,而消息简明扼要的阐述错误本身。
比如,用户不存在的错误消息可以这么打印:
log.Error(“User does not exist”, zap.Int(“uid”, uid))
上面 User does not exist 是消息, 而 uid 是字段。具体设计思想可以参考 logrus的文档 ,这里不再赘述。
其实我们最初的实践中并没有意识到日志框架的性能的重要性,直到开发后期进行系统的 benchmark 总是不尽人意,而且在不同的日志级别下性能差距明显。通过 go profiling 看到日志组件对于计算资源的消耗十分巨大,因此决心将其替换为一个高性能的日志框架,这也是选择用 zap 的一个重要的考量的点。
目前我们使用 zap 已有2年多的时间,zap 很好地解决了日志组件的低性能的问题。目前 zap 也从 beta 发布到了 1.8版本,对于 zap 我们不仅仅看到它的高性能,更重要的是理解它的设计与工程实践。日志属于 io 密集型的组件,这类组件如何做到高性能低成本,这也将直接影响到服务成本。
zap, how ?
zap 具体表现如何呢?抛开 zap 的设计我们不谈,现在让我们单纯来看一个日志库究竟需要哪些元素:
首先要有输入:输入的数据应该被良好的组织且易于编码,并且还要有高效的空间利用率,毕竟内存开辟回收是昂贵的。 无论是 formator 方式还是键值对 key-value 方式,本质上都是对于输入数据的组织形式。 实践中有格式的数据往往更有利于后续的分析与处理。 json 就是一种易用的日志格式
其次日志能够有不同的级别:对于日志来说,基本的的日志级别: debug info warning error fatal 是必不可少的。对于某些场景,我们甚至期待类似于 assert 的 devPanic 级别。同时除了每条日志的级别,还有日志组件的级别,这可以用于屏蔽掉某些级别的日志。
有了输入和不同的级别,接下来就需要组织日志的输出流:你需要一个 encoder 帮你把格式化的,经过了过滤的日志信息输出。也就是说不论你的输出是哪里,是 stdout ,还是文件,还是 NFS ,甚至是一个 tcp 连接。 Encoder 只负责高效的编码数据,其他的事情交给其他人来做。
有了这些以后,我们剩下的需求就是设计一套易用的接口,来调用这些功能输出日志。 这就包含了 logger 对象和 config。
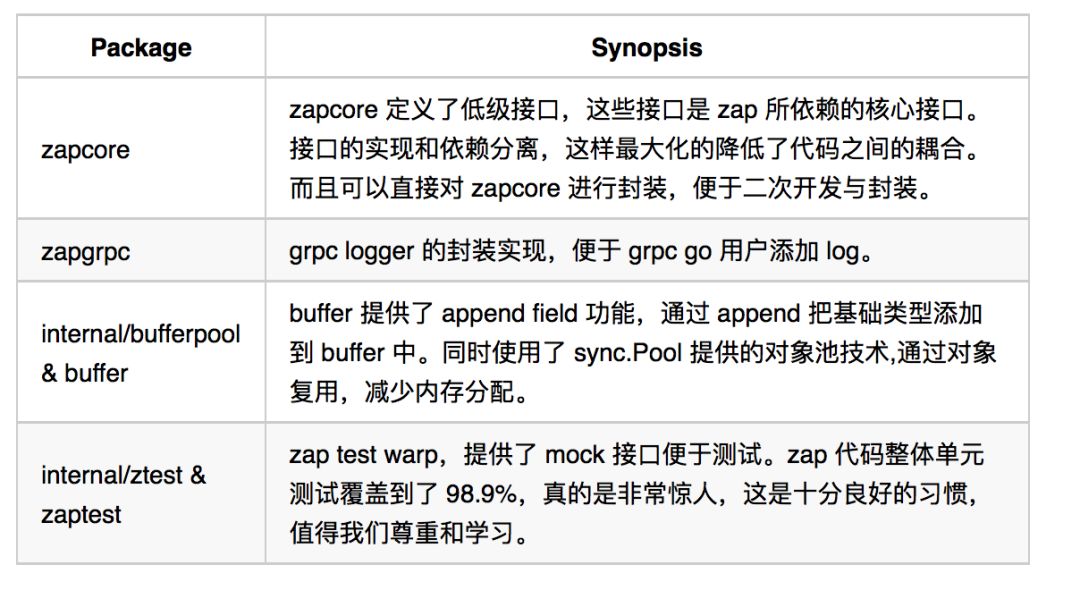
嗯,似乎我们已经知道我们要什么了,日志的组织和输出是分开的逻辑,但是这不妨碍 zapcore 将这些设计组合成 zap 最核心的接口。
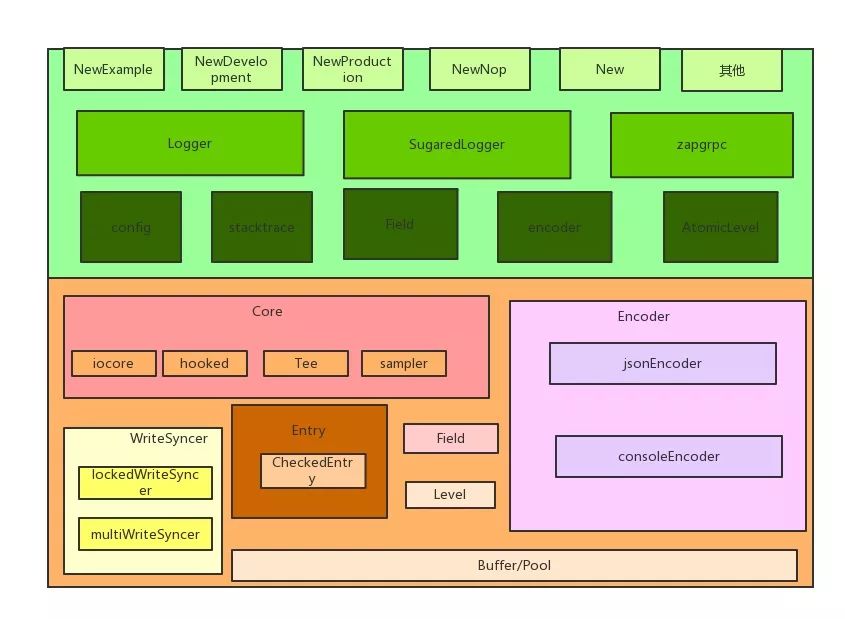
从上文中来看一个日志库的逻辑结构已经很清晰了。现在再来看下 zap ,通过 zap 打印一条结构化的日志大致包含5个过程:
分配日志 Entry: 创建整个结构体,此时虽然没有传参(fields)进来,但是 fields 参数其实创建了
检查级别,添加core: 如果 logger 同时配置了 hook,则 hook 会在 core check 后把自己添加到 cores 中
根据选项添加 caller info 和 stack 信息: 只有大于等于级别的日志才会创建checked entry
Encoder 对 checked entry 进行编码: 创建最终的 byte slice,将 fields 通过自己的编码方式(append)编码成目标串
Write 编码后的目标串,并对剩余的 core 执行操作, hook也会在这时被调用
接下来对于我们最感兴趣的几个部分进行更加具体的分析:
logger: zap 的接口层,包含Log 对象、Level 对象、Field 对象、config 等基本对象
zapcore: zap 的核心逻辑,包含field 的管理、level 的判断、encode 编码日志、输出日志
encoder: json 或者其它编码方式的实现
utils: SubLog,Hook,SurgarLog/grpclogger/stdlogger
logger: 对象 vs 接口
zap 对外提供的是 logger 对象和 field 和 level。 这是 zap 对外提供的基本语义: logger 对象打印 log,field 则是 log 的组织方式,level 跟打印的级别相关。 这些元素的组合是松散的但是联系确实紧密的。
有趣的是,zap 并没有定义接口。 大家可能也很容易联想到 Go 自身的 log 就不是接口。 在 go-dev 很多人曾经讨论过 Go 的接口,有人讨论为啥不提供接口 Standardization around logging and related concerns ,甚至有人提出过草案 Go Logging Design Proposal - Ross Light,然而最终也难逃被 Abandon 的命运。
归根到底,reddit 上的一条评论总结最为到位:
No one seems to be able to agree what such an interface should look like。
在 zap 的早期版本中并没有提供 zapcore 这个库。 zapcore提供了zap 最核心的设计的逻辑封装:执行级别判断,添加 field 和 core,进行级别判断返回 checked entry。
logger 是对象不是接口,但是 zapcore 却是接口,logger 依赖 core 接口实现功能,其实是 logger 定义了接口,而 core 提供了接口的实现。 core 作为接口体现的是 zap 核心逻辑的抽象和设计理念,因此只需要约定逻辑,而实现则是多种的也是可以替换的,甚至可以基于 core 进行自定义的开发,这大大增加了灵活性。
zap field: format vs field
对于 zap 来说,为了性能其实牺牲掉了一定的易用性。例如 log.Printf(“%s”, &s) format 这种方式是最自然的 log 姿势,然而对于带有反射的 Go 是致命的: 反射太过耗时。
下面让我们先来看看反射和 cast 的性能对比,结果是惊人的。
通过 fmt.Sprintf() 来组合 string 是最慢的,这因为 fmt.Printf 函数族使用反射来判断类型.
fmt.Sprintf(“%s”, “hello world”)
相比之下 string 的 + 操作基就会快很多,因为 Go 中的 string 类型本质上是一个特殊的 []byte。 执行 + 会将后续的内容追加在 string 对象的后面:
_ = s + “hello world”
然而对于追求极致的 zap 而言还不够,如果是 []byte 的 append 则还要比 + 快2倍以上。 尽管这里其实不是准确的,因为分配 []byte 时,如果不特殊指定 capacity 是会按照 2 倍的容量预分配空间。append 追加的 slice 如果容量不足,依然会引发一次 copy, 而 我们可以通过预分配足够大容量的 slice 来避免该问题。zap 默认分配 1k 大小的 byte slice。
buf = append(buf, []byte(“hello world”)…)
表格的最下面是接口反射和直接转换的性能对比,field 通过指明类型避免了反射,zap 又针对每种类型直接提供了转换 []byte + append 的函数,这样的组合效率是极其高的。明确的调用对应类型的函数避免运行时刻的反射,可以看到 规避反射 这种类型操作是贯穿在整个 zap 的逻辑中的。
zap 的 append 家族函数封装了 strconv.AppendX 函数族,该函数用于将类型转换为 []byte 并 append 到给定的 slice 上。
zap 高性能的秘诀
对于大部分人来说,标准库提供了覆盖最全的工具和函数。 但是标准库 为了通用有时候其实做了一些性能上的牺牲 。 而 zap 在细节上的性能调优确实下足了功夫,我们可以借鉴这些调优的思路和经验。
避免 GC: 对象复用
Go 是提供了 gc 的语言。 gc 就像双刃剑,给你了快捷的同时又会增加系统的负担。 尽管 Go 官方宣称 gc 性能很好,但是仍然无法绕开 Stop-The-World 的难题,一旦内存中的碎片较多 gc 仍然会有明显尖峰,这种尖峰对于重 io 的业务来说是致命的。 zap 每打印1条日志,至少需要2次内存分配:
创建 field 时分配内存。
将组织好的日志格式化成目标 []byte 时分配内存。
zap 通过 sync.Pool 提供的对象池,复用了大量可以复用的对象,避开了 gc 这个大麻烦。
Go 的 sync.Pool 实现上提供的是 runtime 级别的绑定到 Processor 的对象池。 对象池是否高效依赖于这个池的竞争是否过多,对此我曾经做过一次对比,使用 channel 实现了一个最简单的对象池,但是 benchmark 的结果却不尽如人意,完全不如 sync.Pool 高效。 究其原因,其实也可以理解,因为使用 channel 实现的对象池在多个 Processor 之间会有强烈的并发。尽管使用 sync.Pool 涉及到一次接口的转换,性能依然是非常可观的。
zap 也是使用了sync.Pool 提供的标准对象池。自身的 runtime 包含了 P 的处理逻辑,每个 P 都有自己的池在调度时不会发生竞争。 这个比起代码中的软实现更加高效,是用户代码做不到的逻辑。
sync.Pool 是Go提供给大家的一种优化 gc 的方式好方式尽管 Go 的 gc 已经有了长足的进步但是仍然不能够绕开 gc 的 STW,因此合理的使用 pool 有助于提高代码的性能,防止过多碎片化的内存分配与回收。
之前我们对于 pool 对象的讨论中,最痛苦的一点就是是否应该包暴露 Free 函数。 最终的结论是如同 C/C++,资源的申请者应该决定何时释放。 zap 的对象池管理也深谙此道。
buffer 实现了 io.Writer
Put 时并不执行 Reset
buffer 对象包含其对象池,因此可以在任何时刻将自己释放(放回对象池)
内建的 Encoder: 避免反射
反射是 Go 提供给我们的另一个双刃剑,方便但是不够高效。 对于 zap ,规避反射贯穿在整个代码中。 对于我们来说,创建json 对象只需要简单的调用系统库即可:
b, err := json.Marshal(&obj)
对于 zap 这还不够。标准库中的 json.Marshaler 提供的是基于类型反射的拼接方式,代价是高昂的:
func (e *encodeState) marshal(v interface{}, opts encOpts) (err error) {
…
e.reflectValue(reflect.ValueOf(v), opts) //reflect 根据 type 进行 marshal
…
}
反射的整体性能并不够高,因此通过 Go 的反射可能导致额外的性能开销。 zap 选择了自己实现 json Encoder。 通过明确的类型调用,直接拼接字符串,最小化性能开销。
zap 的 json Encoder 设计的高效且较为易用,完全可以替换在代码中。 另一方面,这也是 Go 长期以来缺乏泛型的一个痛点 。对于一些性能要求高的操作,如果标准库偏向于易用性。那么我们完全可以绕开标准库,通过自己的实现,规避掉额外性能开销。 同样,上文提到的 field 也是这个原因。 通过一个完整的自建类型系统,zap 提供了从组合日志到编码日志的整体逻辑,整个过程中都是可以。
ps. 据说 Go 在2.0 中就会加入泛型啦, 很期待
避免竞态
zap 的高效还体现在对于并发的控制上。 zap 选择了 写时复制机制。 zap 把每条日志都抽象成了 entry。 对于 entry 还分为2种不同类型:
Entry : 包含原始的信息 但是不包含 field
CheckedEntry: 经过级别检查后的生成 CheckedEntry,包含了 Entry 和 Core。
CheckedEntry 的引入解决了组织日志,编码日志的竟态问题。只有经过判断的对象才会进入后续的逻辑,所有的操作 写时触发复制 ,没有必要的操作不执行预分配。将操作与对象组织在一起,不进行资源的竞争,避免多余的竟态条件。
对于及高性能的追求者来说,预先分配的 field 尽管有 pool 加持仍然是多余的,因此 zap 提供了更高性能的接口,可以避免掉 field 的分配:
if ent := log.Check(zap.DebugLevel, “foo”); ent != nil {
ent.Write(zap.String(“foo”, “bar”))
}
通过这一步判断,如果该级别日志不需要打印,那么连 field 都不必生成。 避免一切不必要的开销,zap 确实做到了而且做得很好。
多样的功能与简单的设计理念
level handler:
level handler 是 zap 提供的一种 level 的处理方式,通过 http 请求动态改变日志组件级别。
对于日志组件的动态修改,seelog 最早就有提供类似功能,基于 xml 文件修改捕获新的级别。 但是 xml 文件显然不够 golang。
zap 的解决方案是 http 请求。http 是大家广泛应用的协议,zap 定义了 level handler 实现了 http.Handler 接口
Go 自身的 http 服务实现起来非常的简洁:
http.HandleFunc(“/handle/level”, zapLevelHandler)
if err := http.ListenAndServe(addr, nil); err != nil {
panic(err)
}
简单几行代码就能实现 http 请求控制日志级别的能力。 通过 GET获取当前级别,PUT 设置新的级别。
zap 的 surgar log 和易用 config 接口封装
我们的库往往希望提供事无巨细的控制能力。但是对于简单的使用者就不够友好,繁杂的配置往往容易使人第一次使用即失去耐心。同时,一个全新的 log 接口设计也容易让长期使用 format 方式打印日志的人产生疑问。在工作中发现较多的用户有这样的需求: 你的这个库怎么用?
显然只有 godoc 还不够。
zap 的 Config 非常的繁琐也非常强大,可以控制打印 log 的所有细节,因此对于我们开发者是友好的,有利于二次封装。但是对于初学者则是噩梦。因此 zap 提供了一整套的易用配置,大部分的姿势都可以通过一句代码生成需要的配置。
func NewDevelopmentEncoderConfig() zapcore.EncoderConfig
func NewProductionEncoderConfig() zapcore.EncoderConfig
type SamplingConfig
同样,对于不想付出代价学习使用 field 写格式化 log 的用户,zap 提供了 sugar log。 sugarlog 字面含义就是加糖。 给 zap 加点糖,sugar log 提供了 formatter 接口,可以通过 format的方式来打印日志。sugar 的实现封装了 zap log,这样既满足了使用 printf 格式串的兼容性需求,同时也提供了更多的选择,对于不那么追求极致性能的场景提供了易用的方式。
sugar := log.Sugar()
sugar.Debugf(“hello, world %s”, “foo”)
zap logger 提供的 utils
zap 还在 logger 这层提供了丰富的工具包,这让整个 zap 库更加的易用:
grpc logger:封装 zap logger 可以直接提供给 grpc 使用,对于大多数的 Go 分布式程序,grpc 都是默认的 rpc 方案,grpc 提供了 SetLogger 的接口。 zap 提供了对这个接口的封装。
hook:作为 zap。Core 的实现,zap 提供了 hook。 使用方实现 hook 然后注册到 logger,zap在合适的时机将日志进行后续的处理,例如写 kafka,统计日志错误率 等等。
std Logger: zap 提供了将标准库提供的 logger 对象重定向到 zap logger 中的能力,也提供了封装 zap 作为标准库 logger 输出的能力。 整体上十分易用。
sublog: 通过创建 绑定了 field 的子logger,实现了更加易用的功能。
zap 的好帮手: RollingWriter
zap 本身提供的是设置 writer 的接口,为此我实现了一套 io.Writer,通过rolling writer 实现了 log rotate 的功能。
rollingWriter 是一个 Go ioWriter 用于按照需求自动滚动文件。 目的在于内置的实现 logrotate 的功能而且更加高效和易用。
具体可以见
https://github.com/arthurkiller/rollingWrite
总结
zap 在整体设计上有非常多精细的考量,不仅仅是在高性能上面的出色表现,更多的意义是其设计和工程实践上。此处总结下 zap 的代码之道:
合理的代码组织结构,结构清晰的抽象关系
写实复制,避免加锁
对象内存池,避免频繁创建销毁对象
避免使用 fmt json/encode 使用字符编码方式对日志信息编码,适用byte slice 的形式对日志内容进行拼接编码操作
https://studygolang.com/articles/14220?fr=sidebar
golang日志库
golang标准库的日志框架非常简单,仅仅提供了print,panic和fatal三个函数对于更精细的日志级别、日志文件分割以及日志分发等方面并没有提供支持。所以催生了很多第三方的日志库,但是在golang的世界里,没有一个日志库像slf4j那样在Java中具有绝对统治地位。golang中,流行的日志框架包括logrus、zap、zerolog、seelog等。
logrus是目前Github上star数量最多的日志库,目前(2018.08,下同)star数量为8119,fork数为1031。logrus功能强大,性能高效,而且具有高度灵活性,提供了自定义插件的功能。很多开源项目,如docker,prometheus等,都是用了logrus来记录其日志。
zap是Uber推出的一个快速、结构化的分级日志库。具有强大的ad-hoc分析功能,并且具有灵活的仪表盘。zap目前在GitHub上的star数量约为4.3k。
seelog提供了灵活的异步调度、格式化和过滤功能。目前在GitHub上也有约1.1k。
logrus特性
logrus具有以下特性:
完全兼容golang标准库日志模块:logrus拥有六种日志级别:debug、info、warn、error、fatal和panic,这是golang标准库日志模块的API的超集。如果您的项目使用标准库日志模块,完全可以以最低的代价迁移到logrus上。
可扩展的Hook机制:允许使用者通过hook的方式将日志分发到任意地方,如本地文件系统、标准输出、logstash、elasticsearch或者mq等,或者通过hook定义日志内容和格式等。
可选的日志输出格式:logrus内置了两种日志格式,JSONFormatter和TextFormatter,如果这两个格式不满足需求,可以自己动手实现接口Formatter,来定义自己的日志格式。
Field机制:logrus鼓励通过Field机制进行精细化的、结构化的日志记录,而不是通过冗长的消息来记录日志。
logrus是一个可插拔的、结构化的日志框架。
logrus的使用
第一个示例
最简单的使用logrus的示例如下:
package main
import (
log “github.com/sirupsen/logrus”
)
func main() {
log.WithFields(log.Fields{
“animal”: “walrus”,
}).Info(“A walrus appears”)
}
1
2
3
4
5
6
7
8
9
10
11
上面代码执行后,标准输出上输出如下:
time=”2018-08-11T15:42:22+08:00” level=info msg=”A walrus appears” animal=walrus
1
logrus与golang标准库日志模块完全兼容,因此您可以使用log“github.com/sirupsen/logrus”替换所有日志导入。
logrus可以通过简单的配置,来定义输出、格式或者日志级别等。
package main
import (
“os”
log “github.com/sirupsen/logrus”
)
func init() {
// 设置日志格式为json格式
log.SetFormatter(&log.JSONFormatter{})
// 设置将日志输出到标准输出(默认的输出为stderr,标准错误)
// 日志消息输出可以是任意的io.writer类型
log.SetOutput(os.Stdout)
// 设置日志级别为warn以上
log.SetLevel(log.WarnLevel) }
func main() {
log.WithFields(log.Fields{
“animal”: “walrus”,
“size”: 10,
}).Info(“A group of walrus emerges from the ocean”)
log.WithFields(log.Fields{
"omg": true,
"number": 122,
}).Warn("The group's number increased tremendously!")
log.WithFields(log.Fields{
"omg": true,
"number": 100,
}).Fatal("The ice breaks!") } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 Logger logger是一种相对高级的用法, 对于一个大型项目, 往往需要一个全局的logrus实例,即logger对象来记录项目所有的日志。如:
package main
import (
“github.com/sirupsen/logrus”
“os”
)
// logrus提供了New()函数来创建一个logrus的实例。
// 项目中,可以创建任意数量的logrus实例。
var log = logrus.New()
func main() {
// 为当前logrus实例设置消息的输出,同样地,
// 可以设置logrus实例的输出到任意io.writer
log.Out = os.Stdout
// 为当前logrus实例设置消息输出格式为json格式。
// 同样地,也可以单独为某个logrus实例设置日志级别和hook,这里不详细叙述。
log.Formatter = &logrus.JSONFormatter{}
log.WithFields(logrus.Fields{
"animal": "walrus",
"size": 10,
}).Info("A group of walrus emerges from the ocean") }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Fields
前一章提到过,logrus不推荐使用冗长的消息来记录运行信息,它推荐使用Fields来进行精细化的、结构化的信息记录。
例如下面的记录日志的方式:
log.Fatalf(“Failed to send event %s to topic %s with key %d”, event, topic, key)
1
在logrus中不太提倡,logrus鼓励使用以下方式替代之:
log.WithFields(log.Fields{
“event”: event,
“topic”: topic,
“key”: key,
}).Fatal(“Failed to send event”)
1
2
3
4
5
前面的WithFields API可以规范使用者按照其提倡的方式记录日志。但是WithFields依然是可选的,因为某些场景下,使用者确实只需要记录仪一条简单的消息。
通常,在一个应用中、或者应用的一部分中,都有一些固定的Field。比如在处理用户http请求时,上下文中,所有的日志都会有request_id和user_ip。为了避免每次记录日志都要使用log.WithFields(log.Fields{“request_id”: request_id, “user_ip”: user_ip}),我们可以创建一个logrus.Entry实例,为这个实例设置默认Fields,在上下文中使用这个logrus.Entry实例记录日志即可。
requestLogger := log.WithFields(log.Fields{“request_id”: request_id, “user_ip”: user_ip})
requestLogger.Info(“something happened on that request”) # will log request_id and user_ip
requestLogger.Warn(“something not great happened”)
1
2
3
Hook
logrus最令人心动的功能就是其可扩展的HOOK机制了,通过在初始化时为logrus添加hook,logrus可以实现各种扩展功能。
Hook接口
logrus的hook接口定义如下,其原理是每此写入日志时拦截,修改logrus.Entry。
// logrus在记录Levels()返回的日志级别的消息时会触发HOOK,
// 按照Fire方法定义的内容修改logrus.Entry。
type Hook interface {
Levels() []Level
Fire(*Entry) error
}
1
2
3
4
5
6
一个简单自定义hook如下,DefaultFieldHook定义会在所有级别的日志消息中加入默认字段appName=”myAppName”。
type DefaultFieldHook struct {
}
func (hook *DefaultFieldHook) Fire(entry *log.Entry) error {
entry.Data[“appName”] = “MyAppName”
return nil
}
func (hook *DefaultFieldHook) Levels() []log.Level {
return log.AllLevels
}
1
2
3
4
5
6
7
8
9
10
11
hook的使用也很简单,在初始化前调用log.AddHook(hook)添加相应的hook即可。
logrus官方仅仅内置了syslog的hook。
此外,但Github也有很多第三方的hook可供使用,文末将提供一些第三方HOOK的连接。
记录文件名和行号
logrus的一个很致命的问题就是没有提供文件名和行号,这在大型项目中通过日志定位问题时有诸多不便。Github上的logrus的issue#63:Log filename and line number创建于2014年,四年过去了仍是open状态~~~
网上给出的解决方案分位两类,一就是自己实现一个hook;二就是通过装饰器包装logrus.Entry。两种方案网上都有很多代码,但是大多无法正常工作。但总体来说,解决问题的思路都是对的:通过标准库的runtime模块获取运行时信息,并从中提取文件名,行号和调用函数名。
标准库runtime模块的Caller(skip int)函数可以返回当前goroutine调用栈中的文件名,行号,函数信息等,参数skip表示表示返回的栈帧的层次,0表示runtime.Caller的调用着。返回值包括响应栈帧层次的pc(程序计数器),文件名和行号信息。为了提高效率,我们先通过跟踪调用栈发现,从runtime.Caller()的调用者开始,到记录日志的生成代码之间,大概有8到11层左右,所有我们在hook中循环第8到11层调用栈应该可以找到日志记录的生产代码。
此外,runtime.FuncForPC(pc uintptr) *Func可以返回指定pc的函数信息。
所有我们要实现的hook也是基于以上原理,使用runtime.Caller()依次循环调用栈的第7~11层,过滤掉sirupsen包内容,那么第一个非siupsenr包就认为是我们的生产代码了,并返回pc以便通过runtime.FuncForPC()获取函数名称。然后将文件名、行号和函数名组装为source字段塞到logrus.Entry中即可。
import (
“fmt”
log “github.com/sirupsen/logrus”
“runtime”
“strings”
)
// line number hook for log the call context,
type lineHook struct {
Field string
// skip为遍历调用栈开始的索引位置
Skip int
levels []log.Level
}
// Levels implement levels
func (hook lineHook) Levels() []log.Level {
return log.AllLevels
}
// Fire implement fire
func (hook lineHook) Fire(entry *log.Entry) error {
entry.Data[hook.Field] = findCaller(hook.Skip)
return nil
}
func findCaller(skip int) string {
file := “”
line := 0
var pc uintptr
// 遍历调用栈的最大索引为第11层.
for i := 0; i < 11; i++ {
file, line, pc = getCaller(skip + i)
// 过滤掉所有logrus包,即可得到生成代码信息
if !strings.HasPrefix(file, “logrus”) {
break
}
}
fullFnName := runtime.FuncForPC(pc)
fnName := ""
if fullFnName != nil {
fnNameStr := fullFnName.Name()
// 取得函数名
parts := strings.Split(fnNameStr, ".")
fnName = parts[len(parts)-1]
}
return fmt.Sprintf("%s:%d:%s()", file, line, fnName) }
func getCaller(skip int) (string, int, uintptr) {
pc, file, line, ok := runtime.Caller(skip)
if !ok {
return “”, 0, pc
}
n := 0
// 获取包名
for i := len(file) - 1; i > 0; i-- {
if file[i] == '/' {
n++
if n >= 2 {
file = file[i+1:]
break
}
}
}
return file, line, pc } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 效果如下:
time=”2018-08-11T19:10:15+08:00” level=warning msg=”postgres_exporter is ready for scraping on 0.0.0.0:9295…” source=”postgres_exporter/main.go:60:main()”
time=”2018-08-11T19:10:17+08:00” level=error msg=”!!!msb info not found” source=”postgres/postgres_query.go:63:QueryPostgresInfo()”
time=”2018-08-11T19:10:17+08:00” level=error msg=”get postgres instances info failed, scrape metrics failed, error:msb env not found” source=”collector/exporter.go:71:Scrape()”
1
2
3
日志本地文件分割
logrus本身不带日志本地文件分割功能,但是我们可以通过file-rotatelogs进行日志本地文件分割。 每次当我们写入日志的时候,logrus都会调用file-rotatelogs来判断日志是否要进行切分。关于本地日志文件分割的例子网上很多,这里不再详细介绍,奉上代码:
import (
“github.com/lestrrat-go/file-rotatelogs”
“github.com/rifflock/lfshook”
log “github.com/sirupsen/logrus”
“time”
)
func newLfsHook(logLevel *string, maxRemainCnt uint) log.Hook {
writer, err := rotatelogs.New(
logName+”.%Y%m%d%H”,
// WithLinkName为最新的日志建立软连接,以方便随着找到当前日志文件
rotatelogs.WithLinkName(logName),
// WithRotationTime设置日志分割的时间,这里设置为一小时分割一次
rotatelogs.WithRotationTime(time.Hour),
// WithMaxAge和WithRotationCount二者只能设置一个,
// WithMaxAge设置文件清理前的最长保存时间,
// WithRotationCount设置文件清理前最多保存的个数。
//rotatelogs.WithMaxAge(time.Hour*24),
rotatelogs.WithRotationCount(maxRemainCnt),
)
if err != nil {
log.Errorf("config local file system for logger error: %v", err)
}
level, ok := logLevels[*logLevel]
if ok {
log.SetLevel(level)
} else {
log.SetLevel(log.WarnLevel)
}
lfsHook := lfshook.NewHook(lfshook.WriterMap{
log.DebugLevel: writer,
log.InfoLevel: writer,
log.WarnLevel: writer,
log.ErrorLevel: writer,
log.FatalLevel: writer,
log.PanicLevel: writer,
}, &log.TextFormatter{DisableColors: true})
return lfsHook } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 使用上述本地日志文件切割的效果如下:
将日志发送到elasticsearch
将日志发送到elasticsearch是很多日志监控系统的选择,将logrus日志发送到elasticsearch的原理是在hook的每次fire调用时,使用golang的es客户端将日志信息写到elasticsearch。elasticsearch官方没有提供golang客户端,但是有很多第三方的go语言客户端可供使用,我们选择elastic。elastic提供了丰富的文档,以及Java中的流式接口,使用起来非常方便。
client, err := elastic.NewClient(elastic.SetURL(“http://localhost:9200”))
if err != nil {
log.Panic(err)
}
// Index a tweet (using JSON serialization)
tweet1 := Tweet{User: “olivere”, Message: “Take Five”, Retweets: 0}
put1, err := client.Index().
Index(“twitter”).
Type(“tweet”).
Id(“1”).
BodyJson(tweet1).
Do(context.Background())
1
2
3
4
5
6
7
8
9
10
11
12
13
考虑到logrus的Fields机制,可以实现如下数据格式:
msg := struct {
Host string
Timestamp string json:"@timestamp"
Message string
Data logrus.Fields
Level string
}
1
2
3
4
5
6
7
其中Host记录产生日志主机信息,在创建hook是指定。其他数据需要从logrus.Entry中取得。测试过程我们选择按照此原理实现的第三方HOOK:elogrus。其使用如下:
import (
“github.com/olivere/elastic”
“gopkg.in/sohlich/elogrus”
)
func initLog() {
client, err := elastic.NewClient(elastic.SetURL(“http://localhost:9200”))
if err != nil {
log.Panic(err)
}
hook, err := elogrus.NewElasticHook(client, “localhost”, log.DebugLevel, “mylog”)
if err != nil {
log.Panic(err)
}
log.AddHook(hook)
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
从Elasticsearch查询得到日志存储,效果如下:
GET http://localhost:9200/mylog/_search
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
transfer-encoding: chunked
{
“took”: 1,
“timed_out”: false,
“shards”: {
“total”: 5,
“successful”: 5,
“failed”: 0
},
“hits”: {
“total”: 2474,
“max_score”: 1.0,
“hits”: [
{
“_index”: “mylog”,
“_type”: “log”,
“_id”: “AWUw13jWnMZReb-jHQup”,
“_score”: 1.0,
“_source”: {
“Host”: “localhost”,
“@timestamp”: “2018-08-13T01:12:32.212818666Z”,
“Message”: “!!!msb info not found”,
“Data”: {},
“Level”: “ERROR”
}
},
{
“_index”: “mylog”,
“_type”: “log”,
“_id”: “AWUw13jgnMZReb-jHQuq”,
“_score”: 1.0,
“_source”: {
“Host”: “localhost”,
“@timestamp”: “2018-08-13T01:12:32.223103348Z”,
“Message”: “get postgres instances info failed, scrape metrics failed, error:msb env not found”,
“Data”: {
“source”: “collector/exporter.go:71:Scrape()”
},
“Level”: “ERROR”
}
},
//…
{
“_index”: “mylog”,
“_type”: “log”,
“_id”: “AWUw2f1enMZReb-jHQu”,
“_score”: 1.0,
“_source”: {
“Host”: “localhost”,
“@timestamp”: “2018-08-13T01:15:17.212546892Z”,
“Message”: “!!!msb info not found”,
“Data”: {
“source”: “collector/exporter.go:71:Scrape()”
},
“Level”: “ERROR”
}
},
{
“_index”: “mylog”,
“_type”: “log”,
“_id”: “AWUw2NhmnMZReb-jHQu1”,
“_score”: 1.0,
“_source”: {
“Host”: “localhost”,
“@timestamp”: “2018-08-13T01:14:02.21276903Z”,
“Message”: “!!!msb info not found”,
“Data”: {},
“Level”: “ERROR”
}
}
]
}
}
Response code: 200 (OK); Time: 16ms; Content length: 3039 bytes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
将日志发送到其他位置
将日志发送到日志中心也是logrus所提倡的,虽然没有提供官方支持,但是目前Github上有很多第三方hook可供使用:
logrus_amqp:Logrus hook for Activemq。
logrus-logstash-hook:Logstash hook for logrus。
mgorus:Mongodb Hooks for Logrus。
logrus_influxdb:InfluxDB Hook for Logrus。
logrus-redis-hook:Hook for Logrus which enables logging to RELK stack (Redis, Elasticsearch, Logstash and Kibana)。
等等,上述第三方hook我这里没有具体验证,大家可以根据需要自行尝试。
其他注意事项
Fatal处理
和很多日志框架一样,logrus的Fatal系列函数会执行os.Exit(1)。但是logrus提供可以注册一个或多个fatal handler函数的接口logrus.RegisterExitHandler(handler func() {} ),让logrus在执行os.Exit(1)之前进行相应的处理。fatal handler可以在系统异常时调用一些资源释放api等,让应用正确的关闭。
线程安全
默认情况下,logrus的api都是线程安全的,其内部通过互斥锁来保护并发写。互斥锁工作于调用hooks或者写日志的时候,如果不需要锁,可以调用logger.SetNoLock()来关闭之。可以关闭logrus互斥锁的情形包括:
没有设置hook,或者所有的hook都是线程安全的实现。
写日志到logger.Out已经是线程安全的了,如logger.Out已经被锁保护,或者写文件时,文件是以O_APPEND方式打开的,并且每次写操作都小于4k。
Golang 标准库log的实现
1.Logger结构
首先来看下类型Logger的定义:
1
2
3
4
5
6
7
type Logger struct {
mu sync.Mutex // ensures atomic writes; protects the following fields
prefix string // prefix to write at beginning of each line
flag int // properties
out io.Writer // destination for output
buf []byte // for accumulating text to write
}
主要有5个成员,其中3个我们比较熟悉,分别是表示Log前缀的 “prefix”,表示Log头标签的 “flag” ,以及Log的输出目的地out。 buf是一个字节数组,主要用来存放即将刷入out的内容,相当于一个临时缓存,在对输出内容进行序列化时作为存储目的地。 mu是一个mutex主要用来作线程安全的实习,当有多个goroutine同时往一个目的刷内容的时候,通过mutex保证每次写入是一条完整的信息。
2.std及整体结构
在前一篇文章中我们提到了log模块提供了一套包级别的简单接口,使用该接口可以直接将日志内容打印到标准错误。那么该过程是怎么实现的呢?其实就是通过一个内置的Logger类型的变量 “std” 来实现的。该变量使用:
1
var std = New(os.Stderr, “”, LstdFlags)
进行初始化,默认输出到系统的标准输出 “os.Stderr” ,前缀为空,使用日期加时间作为Log抬头。
当我们调用 log.Print的时候是怎么执行的呢?我们看其代码:
1
2
3
func Print(v …interface{}) {
std.Output(2, fmt.Sprint(v…))
}
这里实际就是调用了Logger对象的 Output方法,将日志内容按照fmt包中约定的格式转义后传给Output。Output定义如下 :
1
func (l *Logger) Output(calldepth int, s string) error
其中s为日志没有加前缀和Log抬头的具体内容,xxxxx 。该函数执行具体的将日志刷入到对应的位置。
3.核心函数的实现
Logger.Output是执行具体的将日志刷入到对应位置的方法。
该方法首先根据需要获得当前时间和调用该方法的文件及行号信息。然后调用formatHeader方法将Log的前缀和Log抬头先格式化好 放入Logger.buf中,然后再将Log的内容存入到Logger.buf中,最后调用Logger.out.Write方法将完整的日志写入到输出目的地中。
由于写入文件以及拼接buf的过程是线程非安全的,因此使用mutex保证每次写入的原子性。
1
2
l.mu.Lock()
defer l.mu.Unlock()
将buf的拼接和文件的写入放入这个后面,使得在多个goroutine使用同一个Logger对象是,不会弄乱buf,也不会杂糅的写入。
该方法的第一个参数最终会传递给runtime.Caller的skip,指的是跳过的栈的深度。这里我记住给2就可以了。这样就会得到我们调用log 是所处的位置。
在golang的注释中说锁住 runtime.Caller的过程比较重,这点我还是不很了解,只是从代码中看到其在这里把锁打开了。
1
2
3
4
5
6
7
8
9
10
11
if l.flag&(Lshortfile|Llongfile) != 0 {
// release lock while getting caller info - it’s expensive.
l.mu.Unlock()
var ok bool
_, file, line, ok = runtime.Caller(calldepth)
if !ok {
file = “???”
line = 0
}
l.mu.Lock()
}
在formatHeader里面首先将前缀直接复制到Logger.buf中,然后根据flag选择Log抬头的内容,这里用到了一个log模块实现的 itoa的方法,作用类似c的itoa,将一个整数转换成一个字符串。只是其转换后将结果直接追加到了buf的尾部。
纵观整个实现,最值得学习的就是线程安全的部分。在什么位置合适做怎样的同步操作。
4.对外接口的实现
在了解了核心格式化和输出结构后,在看其封装就非常简单了,几乎都是首先用Output进行日志的记录,然后在必要的时候 做os.exit或者panic的操作,这里看下Fatal的实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
func (l *Logger) Fatal(v …interface{}) {
l.Output(2, fmt.Sprint(v…))
os.Exit(1)
}
// Fatalf is equivalent to l.Printf() followed by a call to os.Exit(1).
func (l *Logger) Fatalf(format string, v …interface{}) {
l.Output(2, fmt.Sprintf(format, v…))
os.Exit(1)
}
// Fatalln is equivalent to l.Println() followed by a call to os.Exit(1).
func (l *Logger) Fatalln(v …interface{}) {
l.Output(2, fmt.Sprintln(v…))
os.Exit(1)
}
这里也验证了我们之前做的Panic的结果,先做输出日志操作。再进行panic。
5.Golang的log模块设计
Golang的log模块主要提供了三类接口 :
Print : 一般的消息输出
Fatal : 类似assert一般的强行退出
Panic : 相当于OO里面常用的异常捕获
与其说log模块提供了三类日志接口,不如说log模块仅仅是对类C中的 printf、assert、try…catch…的简单封装。Golang的log模块 并没有对log进行分类、分级、过滤等其他类似log4j、log4c、zlog当中常见的概念。当然在使用中你可以通过添加prefix,来进行简单的 分级,或者改变Logger.out改变其输出位置。但这些并没有在API层面给出直观的接口。
Golang的log模块就像是其目前仅专注于为服务器编程一样,他的log模块也专注于服务器尤其是基础组件而服务。就像nginx、redis、lighttpd、keepalived自己为自己写了一个简单的日志模块而没有实现log4c那样庞大且复杂的日志模块一样。他的日志模块仅仅需要为 本服务按照需要的格式和方式提供接口将日志输出到目的地即可。
Golang的log模块可以进行一般的信息记录,assert时的信息输出,以及出现异常时的日志记录,通过对其Print的包装可以实现更复杂的 输出。因此这个log模块可谓是语言层面上非常基础的一层库,反应的是语言本身的特征而不是一个服务应该怎样怎样。
glog简介
glog是著名的google开源C++日志库glog的golang版本,glog是一个轻量级的日志库,上手简单不需要配置文件并且稳定高效,但是可以自定义控制的内容就少了。 glog主要有以下几个特点:
glog有四种日志等级INFO < WARING < ERROR < FATAL,不同等级的日志是打印到不同文件的,低等级的日志文件中(INFO)会包含高等级的日志信息(ERROR)
通过命令行传递参数 –log_dir指定日志文件的存放目录,默认为os.TempDir()
可以根据文件大小切割日志文件,但是不能根据日期切割日志文件
日志输出格式是固定的(Lmmdd hh:mm:ss.uuuuuu threadid file:line] msg…)不可以自定义
在程序开始时需要调用flag.Parse()解析命令行参数,在程序退出时需要调用glog.Flush() 确保将缓存区中的内容输出到文件中。
使用事例
func main() {
//初始化命令行参数
flag.Parse()
//退出时调用,确保日志写入文件中
defer glog.Flush()
glog.Info("hello, glog")
glog.Warning("warning glog")
glog.Error("error glog")
glog.Infof("info %d", 1)
glog.Warningf("warning %d", 2)
glog.Errorf("error %d", 3)
}
//假设编译后的可执行程序名为demo,运行时指定log_dir参数将日志文件保存到特定的目录
// ./demo –log_dir=./log
源码分析
我们顺着事例代码中的 glog.Error(“error glog”) 这行代码来看下,来看下日志内容是如何输出到文件中去的。
func Error(args …interface{}) {
logging.print(errorLog, args…)
}
//errorLog是glog定义的日志等级标记,底层是一个int32类型的变量
type severity int32
const (
infoLog severity = iota
warningLog
errorLog
fatalLog
numSeverity = 4
)
// Error函数实际只是做了一层简单的封装,实际调用的是loggering对象的print函数,loggering是一个loggingT类型的全局变量
func (l *loggingT) print(s severity, args …interface{}) {
l.printDepth(s, 1, args…)
}
//printDepth可以指定输出日志栈的调用层次
func (l *loggingT) printDepth(s severity, depth int, args …interface{}) {
//header构造格式化的附加信息 Lmmdd hh:mm:ss.uuuuuu threadid file:line],glog在这个过程中做了很多优化,具体查看源码
//header函数中会从一个freeList中取buffer对象,如果不存在则会创建新的buffer对象,在使用完后调用 putBuffer将buffer放回到freeList中
buf, file, line := l.header(s, depth)
fmt.Fprint(buf, args…)
if buf.Bytes()[buf.Len()-1] != ‘\n’ {
buf.WriteByte(‘\n’)
}
l.output(s, buf, file, line, false)
}
func (l *loggingT) output(s severity, buf *buffer, file string, line int, alsoToStderr bool) {
data := buf.Bytes()
//glog会为每个级别的日志创建不同的日志文件,打印日志时首先要保证该级别的日志文件已存在
if l.file[s] == nil {
if err := l.createFiles(s); err != nil {
os.Stderr.Write(data)
l.exit(err)
}
}
//glog会将高级别的日志信息打印到低级别的日志文件中
//去掉代码段中的 fallthrough,则可以实现error日志只输出到error文件中,而不会继续输出到info级别的日志文件中
switch s {
case fatalLog:
l.file[fatalLog].Write(data)
fallthrough
case errorLog:
l.file[errorLog].Write(data)
fallthrough
case warningLog:
l.file[warningLog].Write(data)
fallthrough
case infoLog:
l.file[infoLog].Write(data)
}
if s == fatalLog {
//如果是FATAL日志信息,则退出程序
os.Exit(255)
}
//将使用完的buffer对象放到缓冲池中
l.putBuffer(buf)
}
//loggingT.file是一个flushSyncWriter接口类型的数组,在glog中实际的对象是syncBuffer,syncBuffer封装了底层的写文件操作,增加了缓冲区避免过于频繁的系统调用提高写日志效率
type syncBuffer struct {
*bufio.Writer
file *os.File
sev severity
nbytes uint64 // The number of bytes written to this file
}
//写入日志前会判断日志文件是否已经超过指定的最大尺寸,如果超过则创建新的日志文件
//日志内容会先写入到内存中 sb.Writer = bufio.NewWriterSize(sb.file, bufferSize)
func (sb *syncBuffer) Write(p []byte) (n int, err error) {
if sb.nbytes+uint64(len(p)) >= MaxSize {
if err := sb.rotateFile(time.Now()); err != nil {
sb.logger.exit(err)
}
}
n, err = sb.Writer.Write(p)
sb.nbytes += uint64(n)
return
}
//我们通过调用syncBuffer.Write函数将日志内容输出,但是syncBuffer缓冲区中的内容是在什么时候输出到文件中的呢
//glog的init函数中会开启一个 goroutine定时的调用 flushSyncWriter的Flush函数将内存中的日志内容刷到文件中
func init() {
go logging.flushDaemon()
}
func (l *loggingT) flushDaemon() {
for _ = range time.NewTicker(flushInterval).C {
for s := fatalLog; s >= infoLog; s– {
file := l.file[s]
if file != nil {
file.Flush()
file.Sync()
}
}
}
vlog简介
一般的日志库会提供日志输出级别,当日志信息的级别低于输出级别时则不会输出该日志信息。我们使用其他日志库时会使用log.Debug()打印出调试信息,在测试环境下将日志库的输出级别设置为DEBUG,调试信息就会输出便于我们查看程序的具体运行情况,而在线上程序中将日志的输出级别设置为INFO调试信息就不会输出。 glog则采用另外一种方式实现这种功能,glog提供让用户自定义分级信息的功能,用户自定义分级与glog自带的日志等级(INFO ERROR)是完全分离的,在命令行参数设置中独立设置“v”或“vmodule”参数来控制。
if glog.V(1) {
glog.Info(“Starting transaction…”)
}
glog.V(1).Infoln(“Processed”, nItems, “elements”)
在测试环境下我们运行程序时指定用户自定义级别为1 (–v=1),上面的日志信息就会输出。 而在线上环境中指定自定义级别为0(–v=0),上面的日志信息则不会输出。
func init(){
flag.Var(&logging.verbosity, “v”, “log level for V logs”)
}
type Verbose bool
func V(level Level) Verbose {
if logging.verbosity.get() >= level {
return Verbose(true)
}
return Verbose(false)
}
func (v Verbose) Info(args …interface{}) {
if v {
logging.print(infoLog, args…)
}
}
修改glog源码
glog有些功能与我们常用的日志库不太一样或者没有我们期望的功能,可以修改glog的源码来实现我们的需求。比如我们之前使用的日志库是有DEBUG INFO ERROR FATAL级别的,我们可以修改glog源码增加DEBUG级别,删除WARN级别,已于我们的原有系统保持一致。 具体修改内容查看github源码
设置等级控制日志的输出 实现原理:定义一个输出等级变量,提供接口给用户可以设置该变量的值,默认为INFO,在输出日志时检查日志信息的等级是否大于输出等级,如果大于则输出日志信息否则不输出
var outputSeverity severity
//outputLevel 必须为INFO ERROR等字符串,否则panic
//SetLevelString 不是线程安全的,主要是因为我都是在程序开启时在主进程中调用一次SetLevelString函数,而不会在程序运行中随意调用
func SetLevelString(outputLevel string) {
severity, ok := severityByName(outputLevel)
if !ok {
panic(fmt.Errorf(“unknown severity name %s”, outputLevel))
}
outputSeverity = severity
}
func (l *loggingT) println(s severity, args …interface{}) {
if s < outputSeverity {
return
}
buf, file, line := l.header(s, 0)
fmt.Fprintln(buf, args…)
l.output(s, buf, file, line, false)
}
//用户在测试环境下调用 SetLevelString(“DEBUG”)则调试信息能够正常输出到文件中,而在线上环境下调用SetLevelString(“INFO”)屏蔽调试信息
每天自动切割日志文件
实现原理:在创建日志文件时记录下创建文件的日期(MMDD),输出每条日志信息时判断当前日期与日志文件的创建日期是否一致,如果不一致则创建新的日志文件。
func init() {
flag.BoolVar(&logging.dailyRolling, "dailyRolling", false, " weather to handle log files daily")
}
func (sb *syncBuffer) Write(p []byte) (n int, err error) {
if logging.dailyRolling {
if sb.createdDate != string(p[1:5]) {
if err := sb.rotateFile(time.Now()); err != nil {
sb.logger.exit(err)
}
}
}
//写日志信息
}
func (sb *syncBuffer) rotateFile(now time.Time) error {
sb.createdDate = fmt.Sprintf(“%02d%02d”, month, day)
//创建新的日志文件
}
https://studygolang.com/articles/7267
https://www.cnblogs.com/Paul-watermelon/p/12190893.html
http://udn.yyuap.com/thread-61521-1-1.html
http://www.mamicode.com/info-detail-10334.html
golang log日志里为什么需要加锁?
有天同事跟我说,原来go log在写入的时候也有锁,我寻思不应该呀,为啥加锁呀。在我想来写个日志没必要加锁, 但事实来说不是这样的。 好多一些语言的日志模块也有加锁,比如 python logging 。 他加锁的目的在于 避免logrotate日志切割的时候,多线程发生冲突。 我们需要说明的是,单纯的写日志不需要加锁的,因为写日志采用了文件的O_APPEND模式,原子方式一直追加后面。
那么golang 标准库里的log为啥加锁? 看下面的代码,我们在调用log.Print的时候,其实在调用Output。 output方法里有各种行为加锁,总结一句话,他写日志的对象是共享的,而不是每条日志分别一个Logger.buf 对象,既然不是分离的,那么要保护好buf了,要不然写串了。
xiaorui.cc
func (l *Logger) Output(calldepth int, s string) error {
now := time.Now() // get this early.
var file string
var line int
l.mu.Lock()
defer l.mu.Unlock()
if l.flag&(Lshortfile|Llongfile) != 0 {
// Release lock while getting caller info - it’s expensive.
l.mu.Unlock()
var ok bool
_, file, line, ok = runtime.Caller(calldepth)
if !ok {
file = “???”
line = 0
}
l.mu.Lock()
}
l.buf = l.buf[:0]
l.formatHeader(&l.buf, now, file, line)
l.buf = append(l.buf, s…)
if len(s) == 0 || s[len(s)-1] != ‘\n’ {
l.buf = append(l.buf, ‘\n’)
}
_, err := l.out.Write(l.buf)
return err
}
func (l *Logger) Printf(format string, v …interface{}) {
l.Output(2, fmt.Sprintf(format, v…))
}
func (l *Logger) Print(v …interface{}) { l.Output(2, fmt.Sprint(v…)) }
Logger 结构体对象
xiaorui.cc
type Logger struct {
mu sync.Mutex // ensures atomic writes; protects the following fields
prefix string // prefix to write at beginning of each line
flag int // properties
out io.Writer // destination for output
buf []byte // for accumulating text to write
}
日志加锁操作,听起来没啥问题,但如果你的日志很疯狂输出,那么问题就来了,这么多的syscall对于性能来说很是有杀伤力。 当然,正常线上系统肯定也没人去疯狂的benchmark日志,我这边只是为了测试说明问题,syscall 是有 代价的。
http://xiaorui.cc/archives/5195
https://blog.csdn.net/u013435183/article/details/76136141
https://download.csdn.net/download/cstringw/10294191
https://blog.csdn.net/mu_x/article/details/7672139
https://bbs.csdn.net/topics/390705018?page=1
https://go.ctolib.com/HardySimpson-zlog.html
http://www.itkeyword.com/doc/7490651695794867013
https://zhuanlan.zhihu.com/p/29694027?from_voters_page=true
https://blog.csdn.net/weixin_33726318/article/details/91941346
https://my.oschina.net/evilunix/blog/1142754
