Local vs Global Runnable Queue
Goroutine Scheduler Overview
Goroutine 是 Golang 世界里的 Lightweight Thread 。
Golang 在语言层面支持多线程,代码可以通过 go 关键字来启动 Goroutine ,调用者不需要关心调用栈的大小,函数上下文等等信息就可以完成并发或者并行操作,加快了我们的开发速度。
分析 Goroutine 调度有利于了解和分析 go binary 的工作状况,所以接下来的内容将分析 runtime 中关于 Goroutine 调度的逻辑。
以下内容涉及到的代码是基于 go1.9rc2 版本。
Scheduler Structure
整个调度模型由 Goroutine/Processor/Machine 以及全局调度信息 sched 组成。
Global Runnable Queue
runqueue
----------------------------
| G_10 | G_11 | G_12 | ...
----------------------------
P_0 Local Runnable Queue
+-----+ +-----+ ---------------
| M_3 | ---- | P_0 | <=== | G_8 | G_9 |
+-----+ +-----+ ---------------
|
+-----+
| G_3 | Running
+-----+
P_1 Local Runnable Queue
+-----+ +-----+ ---------------
| M_4 | ---- | P_1 | <=== | G_6 | G_7 |
+-----+ +-----+ ---------------
|
+-----+
| G_5 | Running
+-----+ <!-- more --> 1.1 Goroutine Goroutine 是 Golang 世界里的 线程 ,同样也是可调度的单元。
// src/runtime/runtime2.go
type g struct {
….
m *m
sched gobuf
goid int64
….
}
type gobuf struct {
sp uintptr
pc uintptr
….
}
runtime 为 Goroutine 引入了类似 PID 的属性 goid ,使得每一个 Goroutine 都有全局唯一的 goid 标识。
不过官方并没有提供接口能 直接 访问当前 Goroutine 的 goid,在这种情况下我们可以通过 汇编 或者 取巧 的方式得到 goid,有些第三方 package 会利用 goid 做一些有趣的事情,比如 Goroutine local storage ,后面会介绍 runtime 是如何生成唯一的 goid 。
在调度过程中,runtime 需要 Goroutine 释放当前的计算资源,为了保证下次能恢复现场,执行的上下文现场(指令地址 和 Stack Pointer 等)将会存储在 gobuf 这个数据结构中。
整体来说,Goroutine 仅代表任务的内容以及上下文,并不是具体的执行单元。
1.2 Machine
Machine 是 OS Thread,它负责执行 Goroutine。
// src/runtime/runtime2.go
type m struct {
….
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
tls [6]uintptr // thread-local storage (for x86 extern register)
p puintptr // attached p for executing go code (nil if not executing go code)
.... }
runtime 在做调度工作或者和当前 Goroutine 无关的任务时,Golang 会切换调用栈来进行相关的任务,就好像 Linux 的进程进入系统调用时会切换到内核态的调用栈一样,这么做也是为了避免影响到调度以及垃圾回收的扫描。
Machine 一般会调用 systemstack 函数 来切换调用栈。
从名字可以看出,Golang 对外部 go code 的调用栈称之为 user stack ,而将运行核心 runtime 部分代码的调用栈称之为 system stack。
Machine 需要维护这两个调用栈的上下文,所以 m 中 g0 用来代表 runtime 内部逻辑,而 curg 则是我们平时写的代码,更多详情可以关注 src/runtime/HACKING.md.
因为调用栈可以来回地切换,Machine 需要知道当前运行的调用栈信息,所以 Golang 会利用 Thread Local Storage 或者指定寄存器来存储当前运行的 g。
settls 汇编代码会将 g 的地址放到 m.tls 中,这样 Machine 就可以通过 getg 取出当前运行的 Goroutine。
不同平台 settls 的行为有一定差别。
// src/runtime/sys_linux_amd64.s
// set tls base to DI
TEXT runtime·settls(SB),NOSPLIT,$32
#ifdef GOOS_android
// Same as in sys_darwin_386.s:/ugliness, different constant.
// DI currently holds m->tls, which must be fs:0x1d0.
// See cgo/gcc_android_amd64.c for the derivation of the constant.
SUBQ $0x1d0, DI // In android, the tls base·
#else
ADDQ $8, DI // ELF wants to use -8(FS)
#endif
MOVQ DI, SI
MOVQ $0x1002, DI // ARCH_SET_FS
MOVQ $158, AX // arch_prctl
SYSCALL
CMPQ AX, $0xfffffffffffff001
JLS 2(PC)
MOVL $0xf1, 0xf1 // crash
RET
// src/runtime/stubs.go
// getg returns the pointer to the current g.
// The compiler rewrites calls to this function into instructions
// that fetch the g directly (from TLS or from the dedicated register).
func getg() *g
// src/runtime/go_tls.h
#ifdef GOARCH_amd64
#define get_tls(r) MOVQ TLS, r
#define g(r) 0(r)(TLS*1)
#endif
但是 Machine 想要执行一个 Goroutine,必须要绑定 Processor。
runtime 内部有些函数执行时会直接绑定 Machine,并不需要 Processor,比如 sysmon 。
1.3 Processor
Processor 可以理解成处理器,它会维护着本地 Goroutine 队列 runq ,并在新的 Goroutine 入队列时分配唯一的 goid。
type p struct {
…
m muintptr // back-link to associated m (nil if idle)
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
... } Processor 的数目代表着 runtime 能同时处理 Goroutine 的数目,GOMAXPROCS 环境变量是用来指定 Processor 的数目,默认状态会是 CPU 的个数。
也正是因为 Processor 的存在,runtime 并不需要做一个集中式的 Goroutine 调度,每一个 Machine 都会在 Processor 本地队列、Global Runnable Queue 或者其他 Processor 队列中找 Goroutine 执行,减少全局锁对性能的影响,后面会对此展开说明。
1.4 全局调度信息 sched
全局调度信息 sched 会记录当前 Global Runnable Queue、当前空闲的 Machine 和空闲 Processor 的数目等等。
后面说明这 goidgen 和 nmspinning 两个字段的作用。
// src/runtime/runtime2.go
var (
…
sched schedt
…
)
type schedt struct {
// accessed atomically. keep at top to ensure alignment on 32-bit systems.
goidgen uint64
lock mutex
midle muintptr // idle m's waiting for work
nmidle int32 // number of idle m's waiting for work
maxmcount int32 // maximum number of m's allowed (or die)
pidle puintptr // idle p's
npidle uint32
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
// Global runnable queue.
runqhead guintptr
runqtail guintptr
runqsize int32
.... } 2. Create a Goroutine 下面那段代码非常简单,在 main 函数中产生 Goroutine 去执行 do() 这个函数。
➜ main cat -n main.go
1 package main
2
3 func do() {
4 // nothing
5 }
6
7 func main() {
8 go do()
9 }
我们编译上述代码并反汇编看看 go 关键字都做了什么。
可以看到源代码的第 8 行 go do() 编译完之后会变成 runtime.newproc 方法,下面我们来看看 runtime.newproc 都做了些什么。
➜ main uname -m -s
Linux x86_64
➜ main go build
➜ main go tool objdump -s “main.main” main
TEXT main.main(SB) /root/workspace/main/main.go
main.go:7 0x450a60 64488b0c25f8ffffff MOVQ FS:0xfffffff8, CX
main.go:7 0x450a69 483b6110 CMPQ 0x10(CX), SP
main.go:7 0x450a6d 7630 JBE 0x450a9f
main.go:7 0x450a6f 4883ec18 SUBQ $0x18, SP
main.go:7 0x450a73 48896c2410 MOVQ BP, 0x10(SP)
main.go:7 0x450a78 488d6c2410 LEAQ 0x10(SP), BP
main.go:8 0x450a7d c7042400000000 MOVL $0x0, 0(SP)
main.go:8 0x450a84 488d05e5190200 LEAQ 0x219e5(IP), AX
main.go:8 0x450a8b 4889442408 MOVQ AX, 0x8(SP)
main.go:8 0x450a90 e88bb4fdff CALL runtime.newproc(SB) <==== I’m here.
main.go:9 0x450a95 488b6c2410 MOVQ 0x10(SP), BP
main.go:9 0x450a9a 4883c418 ADDQ $0x18, SP
main.go:9 0x450a9e c3 RET
main.go:7 0x450a9f e88c7dffff CALL runtime.morestack_noctxt(SB)
main.go:7 0x450aa4 ebba JMP main.main(SB)
2.1 创建 do() 的执行上下文
平时写代码的时候会发现,Goroutine 执行完毕之后便消失了。那么 do() 这个函数执行完毕之后返回到哪了呢?
➜ main go tool objdump -s “main.do” main
TEXT main.do(SB) /root/workspace/main/main.go
main.go:5 0x450a50 c3 RET
根据 Intel 64 IA 32 开发指南上 Chaptor 6.3 CALLING PROCEDURES USING CALL AND RET 的说明,RET 会将栈顶的指令地址弹出到 IP 寄存器上,然后继续执行 IP 寄存器上的指令。
为了保证 Machine 执行完 Goroutine 之后,能够正常地完成一些清理工作,我们需要在构建 Goroutine 的执行上下文时指定 RET 的具体地址。
下面的代码段会将准备好的调用栈内存保存到 newg.sched 中,其中 gostartcallfn 函数会把 do() 函数添加到 newg.sched.pc ,并将 goexit 函数地址推入栈顶 newg.sched.sp。
所以 Goroutine 执行完毕之后,Machine 会跳到 goexit 函数中做一些清理工作。
// src/runtime/proc.go @ func newproc1
if narg > 0 {
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg)
….
}
newg.sched.sp = sp
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.startpc = fn.fn
想了解 Intel 指令的更多细节,请查看 Intel® 64 and IA-32 Architectures Developer’s Manual: Vol. 1。
2.2 全局唯一的 goid
除了创建执行上下文以外,runtime 还会为 Goroutine 指定一个全局唯一的 id。
// src/runtime/proc.go
const (
// Number of goroutine ids to grab from sched.goidgen to local per-P cache at once.
// 16 seems to provide enough amortization, but other than that it’s mostly arbitrary number.
_GoidCacheBatch = 16
)
// src/runtime/proc.go @ func newproc1
if p.goidcache == p.goidcacheend {
// Sched.goidgen is the last allocated id,
// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
// At startup sched.goidgen=0, so main goroutine receives goid=1.
p.goidcache = atomic.Xadd64(&sched.goidgen, GoidCacheBatch)
_p.goidcache -= GoidCacheBatch - 1
_p.goidcacheend = p.goidcache + GoidCacheBatch
}
newg.goid = int64(_p.goidcache)
p.goidcache++
全局调度信息 sched.goidgen 是专门用来做发号器,Processor 每次可以从发号器那拿走 _GoidCacheBatch 个号,然后内部采用自增的方式来发号,这样就保证了每一个 Goroutine 都可以拥有全局唯一的 goid。
从全局调度信息那里取号的时候用原子操作来保证并发操作的正确性,而内部发号时却采用非原子操作,这是因为一个 Processor 只能被一个 Machine 绑定上,所以这里 p.goidcache 自增不需要要原子操作也能保证它的正确性。
2.3 Local vs Global Runnable Queue
当 Goroutine 创建完毕之后,它是放在当前 Processor 的 Local Runnable Queue 还是全局队列里?
runqput 这个函数会尝试把 newg 放到本地队列上,如果本地队列满了,它会将本地队列的前半部分和 newg 迁移到全局队列中。剩下的事情就等待 Machine 自己去拿任务了。
// src/runtime/proc.go @ func newproc1
runqput(p, newg, true)
2.4 小结
看到这里,一般都会有以下几个疑问:
main 函数是不是也是一个 Goroutine ?
Machine 怎么去取 Goroutine 来执行?
goexit 做完清理工作之后就让 Machine 退出吗?还是继续使用这个 Machine?
那么就继续往下读吧~
- main is a Goroutine
我们写的 main 函数在程序启动时,同样会以 Goroutine 身份被 Machine 执行,下面会查看 go binary 启动时都做了什么。
➜ main uname -m -s
Linux x86_64
➜ main go build –gcflags “-N -l”
➜ main gdb main
(gdb) info file
Symbols from “/root/workspace/main/main”.
Local exec file:
`/root/workspace/main/main’, file type elf64-x86-64.
Entry point: 0x44bb80
0x0000000000401000 - 0x0000000000450b13 is .text
0x0000000000451000 - 0x000000000047a6bc is .rodata
0x000000000047a7e0 - 0x000000000047afd4 is .typelink
0x000000000047afd8 - 0x000000000047afe0 is .itablink
0x000000000047afe0 - 0x000000000047afe0 is .gosymtab
0x000000000047afe0 - 0x00000000004a96c8 is .gopclntab
0x00000000004aa000 - 0x00000000004aaa38 is .noptrdata
0x00000000004aaa40 - 0x00000000004ab5b8 is .data
0x00000000004ab5c0 - 0x00000000004c97e8 is .bss
0x00000000004c9800 - 0x00000000004cbe18 is .noptrbss
0x0000000000400fc8 - 0x0000000000401000 is .note.go.buildid
(gdb) info symbol 0x44bb80
_rt0_amd64_linux in section .text
入口函数是 _rt0_amd64_linux,需要说明的是,不同平台的入口函数名称会有所不同,全局搜索该方法之后,发现该方法会调用 runtime.rt0_go 汇编。
省去了大量和硬件相关的细节后,rt0_go 做了大量的初始化工作,runtime.args 读取命令行参数、runtime.osinit 读取 CPU 数目,runtime.schedinit 初始化 Processor 数目,最大的 Machine 数目等等。
除此之外,我们还看到了两个奇怪的 g0 和 m0 变量。m0 Machine 代表着当前初始化线程,而 g0 代表着初始化线程 m0 的 system stack,似乎还缺一个 p0 ?
实际上所有的 Processor 都会放到 allp 里。runtime.schedinit 会在调用 procresize 时为 m0 分配上 allp[0] 。所以到目前为止,初始化线程运行模式是符合上文提到的 G/P/M 模型的。
大量的初始化工作做完之后,会调用 runtime.newproc 为 mainPC 方法生成一个 Goroutine。
虽然 mainPC 并不是我们平时写的那个 main 函数,但是它会调用我们写的 main 函数,所以 main 函数是会以 Goroutine 的形式运行。
有了 Goroutine 之后,那么 Machine 怎么执行呢?
// src/runtime/asm_amd64.s
TEXT runtime·rt0_go(SB),NOSPLIT,$0
…
// set the per-goroutine and per-mach “registers”
// save m->g0 = g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
MOVQ AX, g_m(CX)
...
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
PUSHQ $0 // arg size
CALL runtime·newproc(SB)
...
// start this M
CALL runtime·mstart(SB) <=== I'm here!
MOVL $0xf1, 0xf1 // crash
RET 4. Machine — Work Stealing 在上一节查看 rt0_go 汇编代码的时候,发现最后一段代码 CALL runtime.mstart(SB) 是用来启动 Machine。
因为在 Golang 的世界里,任务的执行需要 Machine 本身自己去获取。
每个 Machine 运行前都会绑定一个 Processor,Machine 会逐步消耗完当前 Processor 队列。
为了防止某些 Machine 没有事情可做,某些 Machine 忙死,所以 runtime 会做了两件事:
当前 Processor 队列已满,Machine 会将本地队列的部分 Goroutine 迁移到 Global Runnable Queue 中;
Machine 绑定的 Processor 没有可执行的 Goroutine 时,它会去 Global Runnable Queue、Net Network 和其他 Processor 的队列中抢任务。
这种调度模式叫做 Work Stealing。
4.1 如何执行 Goroutine?
// src/runtime/proc.go
func mstart() {
…
} else if g.m != &m0 {
acquirep(g.m.nextp.ptr()) // 绑定 Processor
g.m.nextp = 0
}
schedule()
}
mstart() => schedule() => execute() => xxx() => goexit()
runtime.mstart 函数会调用 schedule 函数去寻找可执行的 Goroutine,查找顺序大致是:
Local Runnable Queue
Global Runnable Queue
Net Network
Other Processor’s Runnable Queue
需找可执行的 Goroutine 的逻辑都在 findrunnable 里。
找到任何一个可执行的 Goroutine 之后,会调用 execute 去切换到 g.sched 相应的调用栈,这样 Machine 就会执行我们代码里创建 Goroutine。
执行完毕之后会 RET 到 goexit, goexit 会调用 goexit0 进行清理工作,
然后再进入 schedule 模式。如果这个时候释放了当前 Machine,那么每次执行 Goroutine 都要创建新的 OS-Thread,这样的代价略大。
所以 Machine 会不断地拿任务执行,直到没有任务。
当 Machine 没有可执行的任务时,它会在 findrunnable 中调用 stopm 进入休眠状态。
那么谁来激活这些休眠状态的 Machine ?
4.2 Wake Up
常见的激活时机就是新的 Goroutine 创建出来的时候。我们回头看看 runtime.newproc 返回前都做了什么。
// src/runtime/proc.go @ func newproc1
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && runtimeInitTime != 0 {
wakep()
}
当 Machine 找不到可执行的 Goroutine 时,但是还在努力地寻找可执行的 Goroutine,这段时间它属于 spinning 的状态。
它实在是找不到了,它才回释放当前 Processor 进入休眠状态。
atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 指的是有空闲的 Processor 而没有 spinning 状态的 Machine。
这个时候可能是有休眠状态的 Machine,可能是程序刚启动的时候并没有足够的 Machine。当遇到这种情况,当前 Machine 会执行 wakep,让程序能快速地消化 Goroutine。
在初始化过程中,为 runtime.main 函数创建的第一个 Goroutine 并不需要调用 wakep,所以在该判断条件里 runtimeInitTime != 0 会失败。
runtimeInitTime 会在 runtime.main 函数中被赋值,表明正式开始执行任务啦。
wakep 首先会查看有没有空闲的 Machine,如果找到而且状态合理,那么就会激活它。如果没有找到,那么会创建一个新的 spinning Machine。
在 Golang 世界里,新创建的 Machine 可以认为它属于 spinning,因为创建 OS-Thread 有一定代价,一旦创建出来了它就要去干活。
除此之外,Golang 创建新的线程并不会直接交付任务给它,而是让它调用 runtime.mstart 方法自己去找活做。
// src/runtime/proc.go
func wakep() {
// be conservative about spinning threads
if !atomic.Cas(&sched.nmspinning, 0, 1) {
return
}
startm(nil, true)
}
func mspinning() {
// startm’s caller incremented nmspinning. Set the new M’s spinning.
getg().m.spinning = true
}
func startm(p *p, spinning bool) {
lock(&sched.lock)
if p == nil {
p = pidleget()
if p == nil {
unlock(&sched.lock)
if spinning {
// The caller incremented nmspinning, but there are no idle Ps,
// so it’s okay to just undo the increment and give up.
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw(“startm: negative nmspinning”)
}
}
return
}
}
mp := mget()
unlock(&sched.lock)
if mp == nil {
var fn func()
if spinning {
// The caller incremented nmspinning, so set m.spinning in the new M.
fn = mspinning
}
newm(fn, p)
return
}
…
mp.spinning = spinning
mp.nextp.set(p)
notewakeup(&mp.park)
}
在 Linux 平台上,newm 会调用 newosproc 来产生新的 OS-Thread。
- Preemptive
Machine 会在全局范围内查找 Goroutine 来执行,似乎还缺少角色去通知 Machine 释放当前 Goroutine,总不能执行完毕再切换吧。
我们知道操作系统会根据时钟周期性地触发系统中断来进行调度,Golang 是用户态的线程调度,那它怎么通知 Machine 呢?
回忆上文, 提到了有些 Machine 执行任务前它并不需要绑定 Processor,它们都做什么任务呢?
// src/runtime/proc.go
func main() {
…
systemstack(func() {
newm(sysmon, nil)
})
…
}
在 runtime.main 函数中会启动新的 OS-Thread 去执行 sysmon 函数。
该函数会以一个上帝视角去查看 Goroutine/Machine/Processor 的运行情况,并会调用 retake 去让 Machine 释放正在运行的 Goroutine。
// src/runtime/proc.go
// forcePreemptNS is the time slice given to a G before it is
// preempted.
const forcePreemptNS = 10 * 1000 * 1000 // 10ms
func retake(now int64) uint32 {
for i := int32(0); i < gomaxprocs; i++ {
p := allp[i]
if p == nil {
continue
}
pd := &p.sysmontick
s := p.status
...
} else if s == _Prunning {
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
continue
}
if pd.schedwhen+forcePreemptNS > now {
continue
}
preemptone(_p_)
}
}
... }
Processor 在 Machine 上执行时间超过 10ms,Machine 会给调用 preemptone
给当前 Goroutine 加上标记:
// src/runtime/proc.go
func preemptone(p *p) bool {
…
gp.preempt = true
// Every call in a go routine checks for stack overflow by
// comparing the current stack pointer to gp->stackguard0.
// Setting gp->stackguard0 to StackPreempt folds
// preemption into the normal stack overflow check.
gp.stackguard0 = stackPreempt }
可以看到它并不是直接发信号给 Machine 让它立即释放,而是让 Goroutine 自己释放,那它什么时候会释放?
Golang 创建新的 Goroutine 时,都会分配有限的调用栈空间,按需进行拓展或者收缩。
所以在执行下一个函数时,它会检查调用栈是否溢出。
➜ main go tool objdump -s “main.main” main
TEXT main.main(SB) /root/workspace/main/main.go
main.go:7 0x450a60 64488b0c25f8ffffff MOVQ FS:0xfffffff8, CX
main.go:7 0x450a69 483b6110 CMPQ 0x10(CX), SP
main.go:7 0x450a6d 7630 JBE 0x450a9f <= I’m here!!
main.go:7 0x450a6f 4883ec18 SUBQ $0x18, SP
main.go:7 0x450a73 48896c2410 MOVQ BP, 0x10(SP)
main.go:7 0x450a78 488d6c2410 LEAQ 0x10(SP), BP
main.go:8 0x450a7d c7042400000000 MOVL $0x0, 0(SP)
main.go:8 0x450a84 488d05e5190200 LEAQ 0x219e5(IP), AX
main.go:8 0x450a8b 4889442408 MOVQ AX, 0x8(SP)
main.go:8 0x450a90 e88bb4fdff CALL runtime.newproc(SB)
main.go:9 0x450a95 488b6c2410 MOVQ 0x10(SP), BP
main.go:9 0x450a9a 4883c418 ADDQ $0x18, SP
main.go:9 0x450a9e c3 RET
main.go:7 0x450a9f e88c7dffff CALL runtime.morestack_noctxt(SB)
main.go:7 0x450aa4 ebba JMP main.main(SB)
gp.stackguard0 = stackPreempt 设置会让检查失败,进入 runtime.morestack_noctxt 函数。
它发现是因为 runtime.retake 造成,Machine 会保存当前 Goroutine 的执行上下文,重新进入 runtime.schedule。
你可能会问,如果这个 Goroutine 里面没有函数调用怎么办?请查看这个 issues/11462。
一般情况下,这样的函数不是死循环,就是很快就退出了,实际开发中这种的类型函数不会太多。
- 关于线程数目
Processor 的数目决定 go binary 能同时处理多少 Goroutine 的能力,感觉 Machine 的数目应该不会太多。
➜ scheduler cat -n main.go
1 package main
2
3 import (
4 “log”
5 “net/http”
6 “syscall”
7 )
8
9 func main() {
10 http.HandleFunc(“/sleep”, func(w http.ResponseWriter, r *http.Request) {
11 tspec := syscall.NsecToTimespec(1000 * 1000 * 1000)
12 if err := syscall.Nanosleep(&tspec, &tspec); err != nil {
13 panic(err)
14 }
15 })
16
17 http.HandleFunc(“/echo”, func(w http.ResponseWriter, r *http.Request) {
18 w.Write([]byte(“hello”))
19 })
20
21 log.Fatal(http.ListenAndServe(“:8080”, nil))
22 }
Golang 提供了 GODEBUG 环境变量来观察当前 Goroutine/Processor/Machine 的状态。
➜ scheduler go build
➜ scheduler GODEBUG=schedtrace=2000 ./scheduler
SCHED 0ms: gomaxprocs=4 idleprocs=1 threads=6 spinningthreads=1 idlethreads=0 runqueue=0 [0 0 0 0]
SCHED 2008ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 4016ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
GODEBUG=schedtrace=2000 会开启 schedtrace 模式,它会让 sysmon 中调用 schedtrace。
// src/runtime/proc.go
func schedtrace(detailed bool) {
…
print(“SCHED “, (now-starttime)/1e6, “ms: gomaxprocs=”, gomaxprocs, “ idleprocs=”, sched.npidle, “ threads=”, sched.mcount, “ spinningthreads=”, sched.nmspinning, “ idlethreads=”, sched.nmidle, “ runqueue=”, sched.runqsize)
…
}
gomaxprocs: 当前 Processor 的数目
idleprocs: 空闲 Processor 的数目
threads: 共创建了多少个 Machine
spinningthreads: spinning 状态的 Machine
nmidle: 休眠状态的 Machine 数目
runqueue: Global Runnable Queue 队列长度
[x, y, z..]: 每个 Processor 的 Local Runnable Queue 队列长度
下面我们会通过 wrk 对 sleep 和 echo 这两个 endpoint 进行压力测试,并关注 Machine 的数目变化。
➜ scheduler GODEBUG=schedtrace=2000 ./scheduler > echo_result 2>&1 &
[1] 6015
➜ scheduler wrk -t12 -c400 -d30s http://localhost:8080/echo
Running 30s test @ http://localhost:8080/echo
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 51.15ms 104.96ms 1.31s 89.35%
Req/Sec 4.97k 4.48k 20.53k 74.84%
1780311 requests in 30.08s, 205.44MB read
Requests/sec: 59178.76
Transfer/sec: 6.83MB
➜ scheduler head -n 20 echo_result
SCHED 0ms: gomaxprocs=4 idleprocs=1 threads=6 spinningthreads=2 idlethreads=0 runqueue=0 [0 0 0 0]
SCHED 2000ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 4005ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 6008ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 8014ms: gomaxprocs=4 idleprocs=0 threads=12 spinningthreads=0 idlethreads=6 runqueue=195 [20 53 6 32]
SCHED 10018ms: gomaxprocs=4 idleprocs=0 threads=12 spinningthreads=0 idlethreads=6 runqueue=272 [65 16 5 37]
SCHED 12021ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=218 [97 5 52 7]
SCHED 14028ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=41 [2 1 25 3]
SCHED 16029ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=178 [10 31 45 38]
SCHED 18033ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=144 [15 92 47 0]
SCHED 20034ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=195 [1 7 4 41]
SCHED 22035ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=159 [88 14 41 5]
SCHED 24038ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=231 [47 19 53 41]
SCHED 26046ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=6 [1 0 1 10]
SCHED 28049ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=133 [61 13 97 53]
SCHED 30049ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=220 [13 49 29 28]
SCHED 32058ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=138 [40 93 63 50]
SCHED 34062ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=266 [51 9 38 31]
SCHED 36068ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=189 [1 3 46 14]
SCHED 38084ms: gomaxprocs=4 idleprocs=4 threads=13 spinningthreads=0 idlethreads=10 runqueue=0 [0 0 0 0]
测试 localhost:8080/echo 30s 之后,发现当前线程数目为 13。接下来再看看 localhost:8080/sleep 的情况。
➜ scheduler GODEBUG=schedtrace=1000 ./scheduler > sleep_result 2>&1 &
[1] 8284
➜ scheduler wrk -t12 -c400 -d30s http://localhost:8080/sleep
Running 30s test @ http://localhost:8080/sleep
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.01s 13.52ms 1.20s 86.57%
Req/Sec 83.06 89.44 320.00 79.12%
11370 requests in 30.10s, 1.26MB read
Requests/sec: 377.71
Transfer/sec: 42.79KB
➜ scheduler cat sleep_result
SCHED 0ms: gomaxprocs=4 idleprocs=1 threads=6 spinningthreads=2 idlethreads=0 runqueue=0 [0 0 0 0]
SCHED 1000ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 2011ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 3013ms: gomaxprocs=4 idleprocs=4 threads=282 spinningthreads=0 idlethreads=1 runqueue=0 [0 0 0 0]
SCHED 4020ms: gomaxprocs=4 idleprocs=4 threads=400 spinningthreads=0 idlethreads=1 runqueue=0 [0 0 0 0]
SCHED 5028ms: gomaxprocs=4 idleprocs=4 threads=401 spinningthreads=0 idlethreads=2 runqueue=0 [0 0 0 0]
SCHED 6037ms: gomaxprocs=4 idleprocs=4 threads=401 spinningthreads=0 idlethreads=2 runqueue=0 [0 0 0 0]
SCHED 7038ms: gomaxprocs=4 idleprocs=4 threads=402 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 8039ms: gomaxprocs=4 idleprocs=4 threads=402 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 9046ms: gomaxprocs=4 idleprocs=4 threads=402 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 10049ms: gomaxprocs=4 idleprocs=4 threads=402 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 11056ms: gomaxprocs=4 idleprocs=4 threads=402 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 12058ms: gomaxprocs=4 idleprocs=4 threads=402 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 13058ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 14062ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 15064ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 16066ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 17068ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 18072ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 19083ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 20084ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 21086ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 22088ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 23096ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 24100ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 25100ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 26100ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 27103ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 28110ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
SCHED 33131ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=396 runqueue=0 [0 0 0 0]
SCHED 34137ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=400 runqueue=0 [0 0 0 0]
SCHED 35140ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=400 runqueue=0 [0 0 0 0]
SCHED 36150ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=400 runqueue=0 [0 0 0 0]
SCHED 37155ms: gomaxprocs=4 idleprocs=4 threads=403 spinningthreads=0 idlethreads=400 runqueue=0 [0 0 0 0]
压力测试完毕之后,创建的线程明显比 localhost:8080/echo 多不少。在压测过程中采用 gdb attach + thread apply all bt 查看这些线程都在做什么:
…
Thread 152 (Thread 0x7f4744fb1700 (LWP 27863)):
#0 syscall.Syscall () at /usr/local/go/src/syscall/asm_linux_amd64.s:27
#1 0x000000000047151f in syscall.Nanosleep (time=0xc42119ac90,
#2 0x000000000060f042 in main.main.func1 (w=…, r=0xc4218d8900)
#3 0x00000000005e8974 in net/http.HandlerFunc.ServeHTTP (f=
#4 0x00000000005ea020 in net/http.(ServeMux).ServeHTTP (
#5 0x00000000005eafa4 in net/http.serverHandler.ServeHTTP (sh=…, rw=…,
#6 0x00000000005e7a5d in net/http.(conn).serve (c=0xc420263360, ctx=…)
#7 0x0000000000458e31 in runtime.goexit ()
#8 0x000000c420263360 in ?? ()
#9 0x00000000007cf100 in crypto/elliptic.p224ZeroModP63 ()
#10 0x000000c421180ec0 in ?? ()
#11 0x0000000000000000 in ?? ()
Thread 151 (Thread 0x7f47457b2700 (LWP 27862)):
#0 syscall.Syscall () at /usr/local/go/src/syscall/asm_linux_amd64.s:27
#1 0x000000000047151f in syscall.Nanosleep (time=0xc4206bcc90,
#2 0x000000000060f042 in main.main.func1 (w=…, r=0xc4218cd300)
#3 0x00000000005e8974 in net/http.HandlerFunc.ServeHTTP (f=
#4 0x00000000005ea020 in net/http.(ServeMux).ServeHTTP (
#5 0x00000000005eafa4 in net/http.serverHandler.ServeHTTP (sh=…, rw=…,
#6 0x00000000005e7a5d in net/http.(conn).serve (c=0xc42048afa0, ctx=…)
#7 0x0000000000458e31 in runtime.goexit ()
#8 0x000000c42048afa0 in ?? ()
#9 0x00000000007cf100 in crypto/elliptic.p224ZeroModP63 ()
#10 0x000000c4204fd080 in ?? ()
#11 0x0000000000000000 in ?? ()
…
Red Hat 系列的机器可以直接使用 pstack 去 Dump 当前主进程内部的调用栈情况,可惜 Ubuntu 64 Bit 没有这样的包,只能自己写一个脚本去调用 gdb 来 Dump。
截取两个线程的调用栈信息,发现它们都在休眠状态,几乎都卡在 /usr/local/go/src/syscall/asm_linux_amd64.s 上。如果都阻塞了,那么它是怎么处理新来的请求?
// src/syscall/asm_linux_amd64.s
TEXT ·Syscall(SB),NOSPLIT,$0-56
CALL runtime·entersyscall(SB)
MOVQ a1+8(FP), DI
MOVQ a2+16(FP), SI
MOVQ a3+24(FP), DX
MOVQ $0, R10
MOVQ $0, R8
MOVQ $0, R9
MOVQ trap+0(FP), AX // syscall entry
SYSCALL
CMPQ AX, $0xfffffffffffff001
JLS ok
MOVQ $-1, r1+32(FP)
MOVQ $0, r2+40(FP)
NEGQ AX
MOVQ AX, err+48(FP)
CALL runtime·exitsyscall(SB)
RET
ok:
MOVQ AX, r1+32(FP)
MOVQ DX, r2+40(FP)
MOVQ $0, err+48(FP)
CALL runtime·exitsyscall(SB)
RET
Syscall 会调用 runtime.entersyscall 会将当前 Processor 的状态设置为 _Psyscall。
当进入系统调用时间过长时,retake 函数在这些 _Psyscall Processor 的状态改为 _Pidle,防止长时间地占用 Processor 导致整体不工作。
进入空闲状态的 Processor 可能会被 wakep 函数创建出来的新进程绑定上,然而新的 Goroutine 可能还会陷入长时间的系统调用,这一来就进入恶性循环,导致 go binary 创建出大量的线程。
当然,Golang 会限制这个线程数目。
// src/runtime/proc.go
func checkmcount() {
// sched lock is held
if sched.mcount > sched.maxmcount {
print(“runtime: program exceeds “, sched.maxmcount, “-thread limit\n”)
throw(“thread exhaustion”)
}
}
当 Machine 从内核态回来之后,会进入 runtime.exitsyscall。
如果执行时间很短,它会尝试地夺回之前的 Processor ;或者是尝试绑定空闲的 Processor,一旦绑定上了 Processor ,它便会继续运行当前的 Goroutine。
如果都失败了,Machine 因为没有可绑定的 Processor 而将当前的 Goroutine 放回到全局队列中,将自己进入休眠状态,等待其他 Machine 来唤醒。
一般情况下,go binary 不会创建特别多的线程,但是上线的代码还是需要做一下压测,了解一下代码的实际情况。
一旦真的创建大量的线程了,Golang 目前的版本是不会回收这些空闲的线程。
不过好在 Go10/Go11 会改进这一缺点,详情请查看 issues/14592。
- 总结
本文粗粒度地介绍了 Golang Goroutine Scheduler 的工作流程,并没有涉及到垃圾回收,Netpoll 以及 Channel Send/Receive 对调度的影响,希望能让读者有个大体的认识。
runtime.mstart 内部的细节很多,而且很多并发操作都建立在无锁的基础上,这样能减少锁对性能的影响,感兴趣的朋友可以根据上文提到的函数一步一步地查看,应该会有不少的收获。
- Reference
Rob Pike’s 2012 Concurrency is not Parallelism
A Quick Guide to Go’s Assembler
Scalable Go Scheduler Design Doc
Debugging performance issues in Go programs
前一章我们详细分析了调度器的调度策略,即调度器如何选取下一个进入运行的goroutine,但我们还不清楚什么时候以及什么情况下会发生调度,从这一章开始我们就来讨论这个问题。
总体说来,go语言的调度器会在以下三种情况下对goroutine进行调度:
goroutine执行某个操作因条件不满足需要等待而发生的调度;
goroutine主动调用Gosched()函数让出CPU而发生的调度;
goroutine运行时间太长或长时间处于系统调用之中而被调度器剥夺运行权而发生的调度。
本章主要分析我们称之为被动调度的第1种调度,剩下的两种调度将在后面两章分别进行讨论。
Demo例子
我们以一个demo程序为例来分析因阻塞而发生的被动调度。
package main
func start(c chan int) {
c<-100
}
func main() {
c:=make(chan int)
go start(c)
<-c } 该程序启动时,main goroutine首先会创建一个无缓存的channel,然后启动一个goroutine(为了方便讨论我们称它为g2)向channel发送数据,而main自己则去读取这个channel。
这两个goroutine读写channel时一定会发生一次阻塞,不是main goroutine读取channel时发生阻塞就是g2写入channel时发生阻塞。
创建g2 goroutine
首先用gdb反汇编一下main函数,看看汇编代码。
0x44f4d0<+0>: mov %fs:0xfffffffffffffff8,%rcx
0x44f4d9<+9>: cmp 0x10(%rcx),%rsp
0x44f4dd<+13>: jbe 0x44f549 <main.main+121>
0x44f4df<+15>: sub $0x28,%rsp
0x44f4e3<+19>: mov %rbp,0x20(%rsp)
0x44f4e8<+24>: lea 0x20(%rsp),%rbp
0x44f4ed<+29>: lea 0xb36c(%rip),%rax
0x44f4f4<+36>: mov %rax,(%rsp)
0x44f4f8<+40>: movq $0x0,0x8(%rsp)
0x44f501<+49>: callq 0x404330
0x44f506<+54>: mov 0x10(%rsp),%rax
0x44f50b<+59>: mov %rax,0x18(%rsp)
0x44f510<+64>: movl $0x8,(%rsp)
0x44f517<+71>: lea 0x240f2(%rip),%rcx
0x44f51e<+78>: mov %rcx,0x8(%rsp)
0x44f523<+83>: callq 0x42c1b0
0x44f528<+88>: mov 0x18(%rsp),%rax
0x44f52d<+93>: mov %rax,(%rsp)
0x44f531<+97>: movq $0x0,0x8(%rsp)
0x44f53a<+106>: callq 0x405080
0x44f53f<+111>: mov 0x20(%rsp),%rbp
0x44f544<+116>: add $0x28,%rsp
0x44f548<+120>: retq
0x44f549<+121>: callq 0x447390
0x44f54e<+126>: jmp 0x44f4d0
从main函数的汇编代码我们可以看到,创建goroutine的go关键字被编译器翻译成了对runtime.newproc函数的调用,第二章我们对这个函数的主要流程做过详细分析,这里简单的回顾一下:
切换到g0栈;
分配g结构体对象;
初始化g对应的栈信息,并把参数拷贝到新g的栈上;
设置好g的sched成员,该成员包括调度g时所必须pc, sp, bp等调度信息;
调用runqput函数把g放入运行队列;
返回
因为当时我们的主要目标是调度器的初始化部分,所以并没有详细分析上述流程中的第5步,也就是runqput是如何把goroutine放入运行队列的,现在就回头分析一下这个过程,下面我们直接从runqput函数开始。
通过runqput函数把goroutine挂入运行队列
runtime/proc.go : 4746
// runqput tries to put g on the local runnable queue.
// If next is false, runqput adds g to the tail of the runnable queue.
// If next is true, runqput puts g in the p.runnext slot.
// If the run queue is full, runnext puts g on the global queue.
// Executed only by the owner P.
func runqput(p *p, gp *g, next bool) {
if randomizeScheduler && next && fastrand() % 2 == 0 {
next = false
}
if next {
//把gp放在_p_.runnext成员里,
//runnext成员中的goroutine会被优先调度起来运行
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
//有其它线程在操作runnext成员,需要重试
goto retryNext
}
if oldnext == 0 { //原本runnext为nil,所以没任何事情可做了,直接返回
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr() //原本存放在runnext的gp需要放入runq的尾部
}
retry:
//可能有其它线程正在并发修改runqhead成员,所以需要跟其它线程同步
h := atomic.LoadAcq(&p.runqhead) // load-acquire, synchronize with consumers
t := p.runqtail
if t - h < uint32(len(p.runq)) { //判断队列是否满了
//队列还没有满,可以放入
p.runq[t % uint32(len(p.runq))].set(gp)
// store-release, makes it available for consumption
//虽然没有其它线程并发修改这个runqtail,但其它线程会并发读取该值以及p的runq成员
//这里使用StoreRel是为了:
//1,原子写入runqtail
//2,防止编译器和CPU乱序,保证上一行代码对runq的修改发生在修改runqtail之前
//3,可见行屏障,保证当前线程对运行队列的修改对其它线程立马可见
atomic.StoreRel(&_p_.runqtail, t + 1)
return
}
//p的本地运行队列已满,需要放入全局运行队列
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry } runqput函数流程很清晰,它首先尝试把gp放入_p_的本地运行队列,如果本地队列满了,则通过runqputslow函数把gp放入全局运行队列。
runtime/proc.go : 4784
// Put g and a batch of work from local runnable queue on global queue.
// Executed only by the owner P.
func runqputslow(p p, gp *g, h, t uint32) bool {
var batch [len(_p_.runq) / 2 + 1]g //gp加上_p_本地队列的一半
// First, grab a batch from local queue.
n := t - h
n = n / 2
if n != uint32(len(_p_.runq) / 2) {
throw("runqputslow: queue is not full")
}
for i := uint32(0); i < n; i++ { //取出p本地队列的一半
batch[i] = _p_.runq[(h+i) % uint32(len(_p_.runq))].ptr()
}
if !atomic.CasRel(&_p_.runqhead, h, h + n) { // cas-release, commits consume
//如果cas操作失败,说明已经有其它工作线程从_p_的本地运行队列偷走了一些goroutine,所以直接返回
return false
}
batch[n] = gp
if randomizeScheduler {
for i := uint32(1); i <= n; i++ {
j := fastrandn(i + 1)
batch[i], batch[j] = batch[j], batch[i]
}
}
// Link the goroutines.
//全局运行队列是一个链表,这里首先把所有需要放入全局运行队列的g链接起来,
//减少后面对全局链表的锁住时间,从而降低锁冲突
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
var q gQueue
q.head.set(batch[0])
q.tail.set(batch[n])
// Now put the batch on global queue.
lock(&sched.lock)
globrunqputbatch(&q, int32(n+1))
unlock(&sched.lock)
return true } runqputslow函数首先使用链表把从_p_的本地队列中取出的一半连同gp一起串联起来,然后在加锁成功之后通过globrunqputbatch函数把该链表链入全局运行队列(全局运行队列是使用链表实现的)。值的一提的是runqputslow函数并没有一开始就把全局运行队列锁住,而是等所有的准备工作做完之后才锁住全局运行队列,这是并发编程加锁的基本原则,需要尽量减小锁的粒度,降低锁冲突的概率。
分析完runqput函数是如何把goroutine放入运行队列之后,接下来我们继续分析main goroutine因读取channel而发生的阻塞流程。
因读取channel阻塞而发生的被动调度
从代码逻辑的角度来说,我们不能确定main goroutine和新创建出来的g2谁先运行,但对于我们分析来说我们可以假定某个goroutine先运行,因为不管谁先运行,都会阻塞在channel的读或则写上,所以这里我们假设main创建好g2后首先阻塞在了对channel的读操作上。下面我们看看读取channel的过程。
从前面的反汇编代码我们知道读取channel是通过调用runtime.chanrecv1函数来完成的,我们就从它开始分析,不过在分析过程中我们不会把精力放在对channel的操作上,而是分析这个过程中跟调度有关的细节。
runtime/chan.go : 403
// entry points for <- c from compiled code
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
// runtime/chan.go : 415
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
……
//省略部分的代码逻辑主要在判断读取操作是否可以立即完成,如果不能立即完成
//就需要把g挂在channel c的读取队列上,然后调用goparkunlock函数阻塞此goroutine
goparkunlock(&c.lock, waitReasonChanReceive, traceEvGoBlockRecv, 3)
……
}
chanrecv1直接调用chanrecv函数实现读取操作,chanrecv首先会判断channel是否有数据可读,如果有数据则直接读取并返回,但如果没有数据,则需要把当前goroutine挂入channel的读取队列之中并调用goparkunlock函数阻塞该goroutine.
runtime/proc.go : 304
// Puts the current goroutine into a waiting state and unlocks the lock.
// The goroutine can be made runnable again by calling goready(gp).
func goparkunlock(lock*mutex, reasonwaitReason, traceEvbyte, traceskipint) {
gopark(parkunlock_c, unsafe.Pointer(lock), reason, traceEv, traceskip)
}
// runtime/proc.go : 276
// Puts the current goroutine into a waiting state and calls unlockf.
// If unlockf returns false, the goroutine is resumed.
// unlockf must not access this G’s stack, as it may be moved between
// the call to gopark and the call to unlockf.
// Reason explains why the goroutine has been parked.
// It is displayed in stack traces and heap dumps.
// Reasons should be unique and descriptive.
// Do not re-use reasons, add new ones.
func gopark(unlockffunc(*g, unsafe.Pointer) bool, lockunsafe.Pointer, reason waitReason, traceEvbyte, traceskipint) {
……
// can’t do anything that might move the G between Ms here.
mcall(park_m) //切换到g0栈执行park_m函数
}
goparkunlock函数直接调用gopark函数,gopark则调用mcall从当前main goroutine切换到g0去执行park_m函数(mcall前面我们分析过,其主要作用就是保存当前goroutine的现场,然后切换到g0栈去调用作为参数传递给它的函数)
runtime/proc.go : 2581
// park continuation on g0.
func park_m(gp*g) {
g := getg()
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
casgstatus(gp, _Grunning, _Gwaiting)
dropg() //解除g和m之间的关系
......
schedule() } park_m首先把当前goroutine的状态设置为_Gwaiting(因为它正在等待其它goroutine往channel里面写数据),然后调用dropg函数解除g和m之间的关系,最后通过调用schedule函数进入调度循环,schedule函数我们也详细分析过,它首先会从运行队列中挑选出一个goroutine,然后调用gogo函数切换到被挑选出来的goroutine去运行。因为main goroutine在读取channel被阻塞之前已经把创建好的g2放入了运行队列,所以在这里schedule会把g2调度起来运行,这里完成了一次从main goroutine到g2调度(我们假设只有一个工作线程在进行调度)。
唤醒阻塞在channel上的goroutine
g2 goroutine的入口是start函数,下面我们就从该函数开始分析g2写channel的流程,看它如何唤醒正在等待着读取channel的main goroutine。还是先来反汇编一下start函数的代码:
0x44f480<+0>:mov %fs:0xfffffffffffffff8,%rcx
0x44f489<+9>:cmp 0x10(%rcx),%rsp
0x44f48d<+13>:jbe 0x44f4c1 <main.start+65>
0x44f48f<+15>:sub $0x18,%rsp
0x44f493<+19>:mov %rbp,0x10(%rsp)
0x44f498<+24>:lea 0x10(%rsp),%rbp
0x44f49d<+29>:mov 0x20(%rsp),%rax
0x44f4a2<+34>:mov %rax,(%rsp)
0x44f4a6<+38>:lea 0x2d71b(%rip),%rax
0x44f4ad<+45>:mov %rax,0x8(%rsp)
0x44f4b2<+50>:callq 0x404560
0x44f4b7<+55>:mov 0x10(%rsp),%rbp
0x44f4bc<+60>:add $0x18,%rsp
0x44f4c0<+64>:retq
0x44f4c1<+65>:callq 0x447390
0x44f4c6<+70>:jmp 0x44f480
可以看到,编译器把对channel的发送操作翻译成了对runtime.chansend1函数的调用
runtime/chan.go : 124
/ entry point for c <- x from compiled code
//go:nosplit
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
// runtime/chan.go : 142
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
……
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
//可以直接发送数据给sg
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
……
}
// runtime/chan.go : 269
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
……
goready(gp, skip+1)
}
// runtime/proc.go : 310
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
channel发送和读取的流程类似,如果能够立即发送则立即发送并返回,如果不能立即发送则需要阻塞,在我们这个场景中,因为main goroutine此时此刻正挂在channel的读取队列上等待数据,所以这里直接调用send函数发送给main goroutine,send函数则调用goready函数切换到g0栈并调用ready函数来唤醒sg对应的goroutine,即正在等待读channel的main goroutine。
runtime/proc.go : 639
// Mark gp ready to run.
func ready(gp *g, traceskip int, next bool) {
……
// Mark runnable.
g := getg()
……
// status is Gwaiting or Gscanwaiting, make Grunnable and put on runq
casgstatus(gp, Gwaiting, _Grunnable)
runqput(_g.m.p.ptr(), gp, next) //放入运行队列
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
//有空闲的p而且没有正在偷取goroutine的工作线程,则需要唤醒p出来工作
wakep()
}
……
}
ready函数首先把需要唤醒的goroutine的状态设置为_Grunnable,然后把其放入运行队列之中等待调度器的调度。
对于本章我们分析的场景,执行到这里main goroutine已经被放入了运行队列,但还未被调度起来运行,而g2 goroutine在向channel写完数据之后就从这里的ready函数返回并退出了,从第二章我们对goroutine的退出流程的分析可以得知,在g2的退出过程中将会在goexit0函数中调用schedule函数进入下一轮调度,从而把刚刚放入运行队列的main goroutine调度起来运行。
在上面分析ready函数时我们略过了一种情况:如果当前有空闲的p而且没有工作线程正在尝试从各个工作线程的本地运行队列偷取goroutine的话(没有处于spinning状态的工作线程),那么就需要通过wakep函数把空闲的p唤醒起来工作。为了不让篇幅过长,下一节我们再来分析wakep如何去唤醒和创建新的工作线程
作者:知乎用户
链接:https://www.zhihu.com/question/20862617/answer/27964865
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Go runtime的调度器:在了解Go的运行时的scheduler之前,需要先了解为什么需要它,因为我们可能会想,OS内核不是已经有一个线程scheduler了嘛?熟悉POSIX API的人都知道,POSIX的方案在很大程度上是对Unix process进场模型的一个逻辑描述和扩展,两者有很多相似的地方。 Thread有自己的信号掩码,CPU affinity等。但是很多特征对于Go程序来说都是累赘。 尤其是context上下文切换的耗时。另一个原因是Go的垃圾回收需要所有的goroutine停止,使得内存在一个一致的状态。垃圾回收的时间点是不确定的,如果依靠OS自身的scheduler来调度,那么会有大量的线程需要停止工作。 单独的开发一个GO得调度器,可以是其知道在什么时候内存状态是一致的,也就是说,当开始垃圾回收时,运行时只需要为当时正在CPU核上运行的那个线程等待即可,而不是等待所有的线程。用户空间线程和内核空间线程之间的映射关系有:N:1,1:1和M:NN:1是说,多个(N)用户线程始终在一个内核线程上跑,context上下文切换确实很快,但是无法真正的利用多核。1:1是说,一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文switch很慢。M:N是说, 多个goroutine在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。 Go的调度器内部有三个重要的结构:M,P,SM:代表真正的内核OS线程,和POSIX里的thread差不多,真正干活的人G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。P:代表调度的上下文,可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键。
Go的调度器内部有三个重要的结构:M,P,SM:代表真正的内核OS线程,和POSIX里的thread差不多,真正干活的人G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。P:代表调度的上下文,可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键。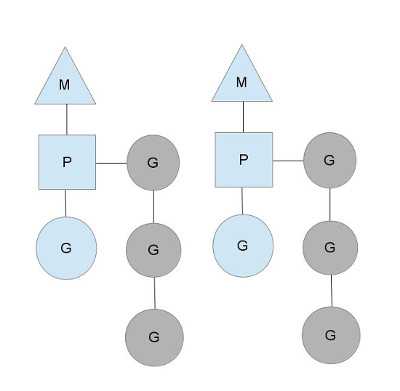 图中看,有2个物理线程M,每一个M都拥有一个context(P),每一个也都有一个正在运行的goroutine。P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。为何要维护多个上下文P?因为当一个OS线程被阻塞时,P可以转而投奔另一个OS线程!图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所以的context P。
图中看,有2个物理线程M,每一个M都拥有一个context(P),每一个也都有一个正在运行的goroutine。P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。为何要维护多个上下文P?因为当一个OS线程被阻塞时,P可以转而投奔另一个OS线程!图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所以的context P。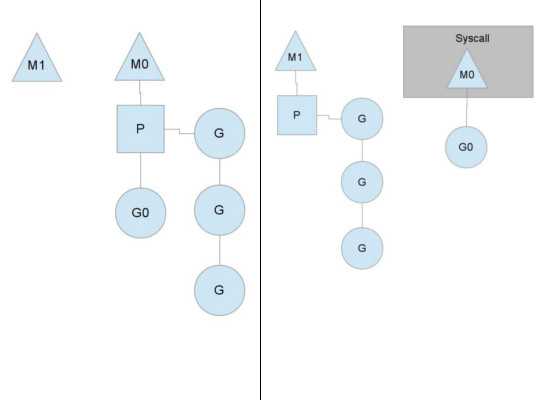 图中的M1可能是被创建,或者从线程缓存中取出。当MO返回时,它必须尝试取得一个context P来运行goroutine,一般情况下,它会从其他的OS线程那里steal偷一个context过来,如果没有偷到的话,它就把goroutine放在一个global runqueue里,然后自己就去睡大觉了(放入线程缓存里)。Contexts们也会周期性的检查global runqueue,否则global runqueue上的goroutine永远无法执行。
图中的M1可能是被创建,或者从线程缓存中取出。当MO返回时,它必须尝试取得一个context P来运行goroutine,一般情况下,它会从其他的OS线程那里steal偷一个context过来,如果没有偷到的话,它就把goroutine放在一个global runqueue里,然后自己就去睡大觉了(放入线程缓存里)。Contexts们也会周期性的检查global runqueue,否则global runqueue上的goroutine永远无法执行。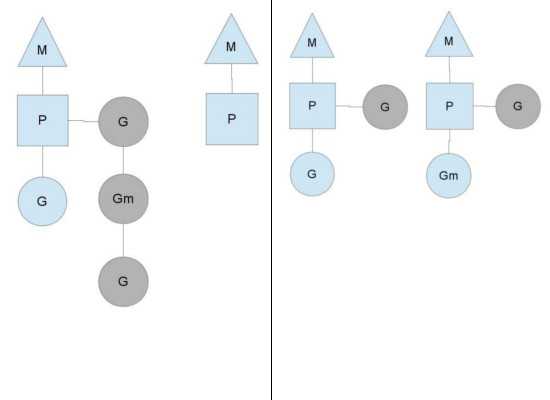 另一种情况是P所分配的任务G很快就执行完了(分配不均),这就导致了一个上下文P闲着没事儿干而系统却任然忙碌。但是如果global runqueue没有任务G了,那么P就不得不从其他的上下文P那里拿一些G来执行。一般来说,如果上下文P从其他的上下文P那里要偷一个任务的话,一般就‘偷’run queue的一半,这就确保了每个OS线程都能充分的使用。
另一种情况是P所分配的任务G很快就执行完了(分配不均),这就导致了一个上下文P闲着没事儿干而系统却任然忙碌。但是如果global runqueue没有任务G了,那么P就不得不从其他的上下文P那里拿一些G来执行。一般来说,如果上下文P从其他的上下文P那里要偷一个任务的话,一般就‘偷’run queue的一半,这就确保了每个OS线程都能充分的使用。
作者:知乎用户
链接:https://www.zhihu.com/question/20862617/answer/18582460
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
《go中的调度分析》《goroutine背后的系统知识》还有一个是Columbia University的三个家伙发表的一篇paper,《Analysis of the Go runtime scheduler》 最后还有Golang核心成员写一个Goroutine Scheduler的设计。《 Scalable Go Scheduler Design Doc》以及对其详细解释的《The Go scheduler》Goroutines are part of making concurrency easy to use. The idea, which has been around for a while, is to multiplex independently executing functions—coroutines—onto a set of threads. When a coroutine blocks, such as by calling a blocking system call, the run-time automatically moves other coroutines on the same operating system thread to a different, runnable thread so they won’t be blocked. The programmer sees none of this, which is the point. The result, which we call goroutines, can be very cheap: unless they spend a lot of time in long-running system calls, they cost little more than the memory for the stack, which is just a few kilobytes.To make the stacks small, Go’s run-time uses segmented stacks. A newly minted goroutine is given a few kilobytes, which is almost always enough. When it isn’t, the run-time allocates (and frees) extension segments automatically. The overhead averages about three cheap instructions per function call. It is practical to create hundreds of thousands of goroutines in the same address space. If goroutines were just threads, system resources would run out at a much smaller number.—————– 我是分割线———————————-我对goroutine的理解类似于C/C++下常用的线程池技术。但是goroutine要在这基础上大大的前进了好多。首先,go关键字极大的简化了C/C++下往线程池投递任务的操作。虽然C++11引入了lambda,但是因为没有GC的缘故用起来还是稍微蛋疼的。其次就是goroutine的调度器解决了一般线程池常见的问题,就是遇到阻塞或者同步动作时,怎么让线程池更容易扩展,不会因为其中一个任务的阻塞或者同步独占线程,甚至怎么避免由此问题带来的死锁。而在C/C++语言里,想做到这点非常的困难,没有类似Golang的runtime,做起来会非常痛苦。 Golang在这点上做的也是非常的漂亮。发起的同步或者channel动作,哪怕网络操作,都会把自身goroutine切换出去,让下一个预备好的goroutine去运行。而且Golang其本身还在此基础上很容易的做到对线程池的扩展,根据程序行为自动扩展或者收缩线程,尽可能的让线程保持在一个合适的数目。
https://www.zhihu.com/question/20862617?sort=created
http://www.cs.columbia.edu/~aho/cs6998/reports/12-12-11_DeshpandeSponslerWeiss_GO.pdf
http://www.sizeofvoid.net/goroutine-under-the-hood/
http://bbs.mygolang.com/thread-163-1-1.html
http://www.imooc.com/article/291974?block_id=tuijian_wz
https://blog.csdn.net/NNnora/article/details/80944719
https://www.jianshu.com/p/69704cdf6674
https://www.cnblogs.com/abozhang/p/10825342.html
https://zhuanlan.zhihu.com/p/65738076
https://blog.csdn.net/qq_25504271/article/details/81000217
https://www.cnblogs.com/maji233/p/11044913.html
https://www.bookstack.cn/read/qcrao-Go-Questions/goroutine%20%E8%B0%83%E5%BA%A6%E5%99%A8-g0%20%E6%A0%88%E4%BD%95%E7%94%A8%E6%88%B7%E6%A0%88%E5%A6%82%E4%BD%95%E5%88%87%E6%8D%A2.md
https://www.jianshu.com/p/be04990895c7
https://studygolang.com/articles/10115
https://www.cnblogs.com/wdliu/p/9272220.html
https://www.zhihu.com/question/20862617/answer/27964865
https://blog.csdn.net/xclyfe/article/details/50563048
https://segmentfault.com/a/1190000019172554
