Thrift 源码
Thrift之代码生成器Compiler这个功能是一个单独的工具程序,它会独立的生成一个可执行文件。
第一节 类关系图
类关系图如下所示:
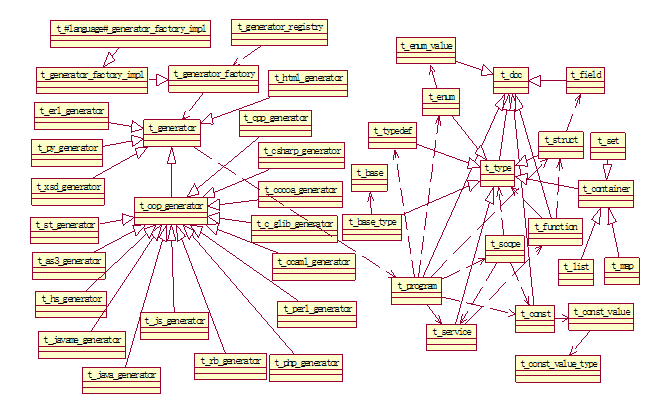
注意:实线代表继承关系;而虚线代表依赖关系。
由类关系图可以看出Compiler功能模块主要分为两个部分,一个是图的右边展示了各种语言代码生成的类。它们的共同基类都是t_generator类,但是面向对象的语言并不是直接从它继承,而是又把面向对象的共同特性提取出来用一个类来实现,这个类就是t_oop_generator,其他面向对象语言的生成类都是从这个类继承。总基类的实现是依赖于左边的t_program类,这个类表示一个程序代码需要的所有特征和要素。左边部分就是解决一个程序需要拥有的数据类型和函数,根据接口定义语言(IDL)解析和生成相应的数据和函数等。左边部分就显示thrift定义的中间语言(IDL)能够支持的数据类型,t_type类是所有数据类型类的基类。
第二节 程序流程图
这个部分整体的流程图如下图所示:

以上流程图简要的说明了Compiler运行的一个过程,通过这个流程图可以让我们知道了根据中间定义语言生成各种程序代码的整体思路和流程。下一节将根据源代码详细分析整个过程的原理及实现方案,这个里面涉及到一些编译原理的知识,不深入分析这一部分,它里面的词法分析程序是用linux上的工具flex自动生成c语言程序,解析中间定义语言的时候直接调用yyparse函数即可。另一部分重点内容就是生成各种程序语言代码的功能,每一种语言用一个类来生成,后面不会详细分析每一种语言的生成实现的代码,主要分析三种主流语言(C++、java、python)。
第三节 源代码详细分析
1 Main.cc文件
这个文件是这个部分的入口文件,因为它定义main函数。除了main函数以外还定义了其它很多的全局函数和变量,其中比较重要的函数有:parse解析函数、generate生成代码的函数;比较重要的全局变量主要是:g_program程序类的变量和各种数据类型的类的变量。
(1)main函数
首先定义一个用于存放源代码输出路径的字符串变量:std::string out_path;然后生成一个基于时间的字符串保存到一个全局变量中,如下代码实现
ime_t now = time(NULL);
g_time_str = ctime(&now);
然后检查参数个数是否满足最低要求,不满足就调用使用说明函数,这个函数就是简单打印这个工具的使用说明,然后退出程序。代码如下:
if (argc < 2) {
usage();
}
下面定义一个用于保存需要生成语言的代表字符串的向量数组:vector
下面的代码开始根据参数得到中间语言定义的文件,然后根据文件名生成一个t_program的对象来代表整个程序的解析树,接着根据文件名找到文件所在的目录并设置包含文件的目录,最后初始化一些全局变量(为这些变量分别内存资源),中间还设置了生成代码输出的路径。
if (saferealpath(argv[i], rp) == NULL) {
failure("Could not open input file with realpath: %s", argv[i]);
}
string input_file(rp);
t_program* program = new t_program(input_file);
if (out_path.size()) {
program->set_out_path(out_path);
}
string input_filename = argv[i];
string include_prefix;
string::size_type last_slash = string::npos;
if ((last_slash = input_filename.rfind(“/”)) != string::npos) {
include_prefix = input_filename.substr(0, last_slash);
}
program->set_include_prefix(include_prefix);
g_type_void = new t_base_type(“void”, t_base_type::TYPE_VOID);
g_type_string = new t_base_type(“string”, t_base_type::TYPE_STRING);
g_type_binary = new t_base_type(“string”, t_base_type::TYPE_STRING);
((t_base_type*)g_type_binary)->set_binary(true);
g_type_slist = new t_base_type(“string”, t_base_type::TYPE_STRING);
((t_base_type*)g_type_slist)->set_string_list(true);
g_type_bool = new t_base_type(“bool”, t_base_type::TYPE_BOOL);
g_type_byte = new t_base_type(“byte”, t_base_type::TYPE_BYTE);
g_type_i16 = new t_base_type(“i16”, t_base_type::TYPE_I16);
g_type_i32 = new t_base_type(“i32”, t_base_type::TYPE_I32);
g_type_i64 = new t_base_type(“i64”, t_base_type::TYPE_I64);
g_type_double = new t_base_type(“double”, t_base_type::TYPE_DOUBLE);
后然调用解析函数和代码生成函数如下:
parse(program, NULL);
generate(program, generator_strings);
最后删除申请到资源。
(2)parse函数
这个函数的主要功能就是调用词法分析程序来进行词法分析,后面会根据词法分析的结果来生产程序代码。下面将详细分析这个函数的功能。
首先从program得到中间文件的全路径并初始化当前文件路径的全局变量,然后根据文件的全路径得到目录来初始化当前目录全局变量,实现代码如下:
string path = program->get_path();
g_curdir = directory_name(path);
g_curpath = path;
接着根据上面得到的文件路径打开这个文件作为词法分析程序的分析对象:yyin = fopen(path.c_str(), “r”);
下面开始第一次进行词法分析,这次词法分析的主要目的提取里面内嵌的IDL文件,所以设置解析的模式为INCLUDES,解析完成以后关闭文件。词法分析的结果都存放到program中。以便后面使用到的地方直接从program就可以得到。词法分析的时候可能发生异常,所以需要处理异常。实现代码如下:
g_parse_mode = INCLUDES;
g_program = program;
g_scope = program->scope();
try {
yylineno = 1;
if (yyparse() != 0) {
failure("Parser error during include pass.");
}
} catch (string x) {
failure(x.c_str());
}
fclose(yyin);
分析出内嵌的IDL文件以后就对这些IDL文件进行递归调用parse函数来对每一个IDL文件进行词法分析,因为每一个IDL文件里面可能包括多个IDL文件,所以需要用一个for循环对没有一个IDL都进行递归词法分析,具体实现如下:
vector<t_program*>& includes = program->get_includes();
vector<t_program*>::iterator iter;
for (iter = includes.begin(); iter != includes.end(); ++iter) {
parse(*iter, program);
}
最后一部分是重点,将进行第二次词法分析,这次分析就是真正的对IDL文件中定义的数据类型和服务(函数)进行词法分析和语法分析,所以首先需要设置词法分析的模式为PROGRAM。还需要初始化一些全局变量,和第一次词法分析一样需要打开IDL文件为词法分析程序提供分析源、异常处理和最后关闭文件,实现的主要代码如下:
g_parse_mode = PROGRAM;
g_program = program;
g_scope = program->scope();
g_parent_scope = (parent_program != NULL) ? parent_program->scope() : NULL;
g_parent_prefix = program->get_name() + “.”;
g_curpath = path;
yyin = fopen(path.c_str(), “r”);
yylineno = 1;
try {
if (yyparse() != 0) {
failure("Parser error during types pass.");
}
} catch (string x) {
failure(x.c_str());
}
fclose(yyin);
到此这个函数完成了所有自己的功能,所有词法分析的结果都保存到program中了,同时g_program也保存同样的一份内容,以便后面的生成代码函数使用。
(3)generate函数
本函数主要功能就是根据parse函数生成的各种数据类型和服务生成各种代码文件。首先递归调用每一个内嵌的t_program来生成代码,实现代码如下:
const vector<t_program*>& includes = program->get_includes();
for (size_t i = 0; i < includes.size(); ++i) {
includes[i]->set_out_path(program->get_out_path());
generate(includes[i], generator_strings);
}
后面部分就是真正生成代码文件的功能了。首先为每一个结构体、枚举和异常生成一个在thrift中全球唯一的识别指纹(其实就是字符串,这个字符串是根据具体类型信息的字符串经过MD5处理后的字符串,如枚举就是根据”enum”生成的)。然后根据需要决定是否打印所有的调试信息。接着根据需要生成的语言循环生成每一种语言的代码,这个是根据在main函数中存放代表语言的字符串(generator_strings)来决定,根据t_program和代表语言的字符串得到一个代码生成器的对象(每一种语言都有一个独立的生成语言的类),然最后就调用这个代码生成器对象的代码生成函数生成具体的代码文件,代码如下:
generate_all_fingerprints(program);
if (dump_docs) {
dump_docstrings(program);
}
vector
for (iter = generator_strings.begin(); iter != generator_strings.end(); ++iter) {
t_generator* generator = t_generator_registry::get_generator(program, *iter);
if (generator == NULL) {
pwarning(1, "Unable to get a generator for \"%s\".\n", iter->c_str());
} else {
pverbose("Generating \"%s\"\n", iter->c_str());
generator->generate_program();
delete generator;
}
}
本函数实现的功能就是以上这些功能,至于具体生成语言代码的功能在各种语言生成的类中实现,后面会详细分析java、C++和python的生成实现。
(4)其它函数
这个主程序文件中还有其他许多函数,下面简单介绍每一个函数的功能,就不分析详细的实现了,具体的实现可以查看源代码。
函数名称
函数功能
saferealpath
根据文件的相对路径得到文件真实而安全的文件绝对路径
yyerror
词法分析程序的错误信息输出程序
pdebug
解析器打印调试信息
pverbose
打印一个详细的输出模式的消息
pwarning
打印警告消息
failure
打印失败的消息并且退出程序
program_name
转换一个字符串的文件名为thrift的program名称
directory_name
根据一个文件的路径得到目录路径
include_file
从给定的文件名查找相应的文件路径
clear_doctext
清除任何以前存储的文档的文本字符串。
clean_up_doctext
清理文本通常类似doxygen的注释
dump_docstrings
输出程序文档字符串到stdout
generate_all_fingerprints
为program的每一个结构体和枚举生成唯一的“指纹”
version
打印thrift的版本信息
usage
打印使用信息并且退出程序
validate_const_rec
验证常量类型是否有效
validate_const_type
检查常量类型的声明类型
validate_field_value
检查分配给一个字段默认值的类型。
validate_throws
检查所有元素抛出的异常是真实的异常
2 t_generator类和t_generator_registry类
这个两个类的主要功能就是为生成所有语言的代码提供基础信息和提供具体代码生成器对象,上面就是调用这个两个类的方法来生成具体语言的代码生成器对象和执行生成代码的功能函数。下面主要分析两个函数的功能,一个是t_generator_registry类的get_generator函数,这个是一个静态的函数可以直接通过类调用;另一个是t_generator类的generate_program函数。
(1)t_generator_registry类的get_generator函数
这个函数有两个参数,一个是表示程序的对象program,另一个是语言字符串参数(包括代表语言的简短字符串和可选项的组合,有的没有)。函数首先解析语言字符串参数,参数字符串中是这样组织的:在冒号(:)之前是代表语言的字符串,冒号之后是可选项的参数,每一个可选项参数用逗号(,)分割,每一个可选项参数都是键值对并且键和值是用等号(=)分割。按照上面的字符串格式解析各个参数部分就可以了,可选项参数用map来保存键值对,代码实现如下:
string::size_type colon = options.find(‘:’);
string language = options.substr(0, colon);
map<string, string> parsed_options;
if (colon != string::npos) {
string::size_type pos = colon+1;
while (pos != string::npos && pos < options.size()) {
string::size_type next_pos = options.find(',', pos);
string option = options.substr(pos, next_pos-pos);
pos = ((next_pos == string::npos) ? next_pos : next_pos+1);
string::size_type separator = option.find('=');
string key, value;
if (separator == string::npos) {
key = option;
value = "";
} else {
key = option.substr(0, separator);
value = option.substr(separator+1);
}
parsed_options[key] = value;
}
}
然后调用get_generator_map函数得到一个代表语言字符串和产生这种语言生成器对象的工厂对象的map对象:gen_map_t& the_map = get_generator_map(); gen_map_t的定义如下:
typedef std::map<std::string, t_generator_factory*> gen_map_t;
get_generator_map函数只有两句代码,一个是定义一个静态局部变量并初始化(因为静态局部变量必须并初始化并且只有第一次会执行初始化,因为不初始化链接程序的时候会报错),第二句就是返回这个静态局部变量给调用者,代码如下:
static gen_map_t* the_map = new gen_map_t();
return *the_map;
然后在这个map对象中找到对应语言的工厂对象,然后用这个工厂对象生产一个这种语言的代码生成器对象并返回给调用者,代码如下所示:
gen_map_t::iterator iter = the_map.find(language);
return iter->second->get_generator(program, parsed_options, options);
本函数的功能已经分析完毕,但是还存在着两个问题(或是困难)。一个是最后一条返回一句是根据具体的语言来使用具体语言生产器的工厂对象生产代码生成器,具体又是怎么生成的了?第二个就是从main函数执行到现在还没有发现在哪儿为get_generator_map函数里定义的静态局部变量添加过任何键值对,那么我们查找具体语言必定会失败,那么会返回一个NULL给调用者,那么程序就会执行不下去了,但是程序确实能够完完整整的执行下去,这个问题困扰了我好一会儿。下面就这两个问题继续分析相关代码并且解决问题。
第一个应该不算是问题,但是必须要解决第二个问题以后才能够解释,因为没有解决第二个问题,那么根本就不会执行到最后一条返回语句这儿来,所以我先解决第二个问题。
第二个问题分析和解决思路如下:
我们通常认为main函数是程序的入口函数,那么所以程序的执行都是从main函数开始的,所以我也选择从main函数开始分析这部分的代码,根据程序的执行流程阅读和分析代码是我一贯的思路。但是这种情况在C++里面有例外,记得我在学习MFC的时候,分析MFC执行过程就发现一个问题,那就是全局变量的初始化是在main函数开始之前的,也就是说全局类对象的构造函数也是在main执行之前执行的。由于我反复从main开始一直详细的阅读每一行代码,所以可以确定确实没有在执行的过程中初始化the_map静态局部变量,所以唯一的可能就是在main函数开始之前已经初始化好了。根据这一点思路自己开始着手查找初始化the_map的代码,发现t_generator_registry类的register_generator函数为the_map添加键值对了,这个函数定义如下:
void t_generator_registry::register_generator(t_generator_factory* factory) {
gen_map_t& the_map = get_generator_map();
if (the_map.find(factory->get_short_name()) != the_map.end()) {
failure("Duplicate generators for language \"%s\"!\n", factory->get_short_name().c_str());
}
the_map[factory->get_short_name()] = factory;
}
这个函数也首先调用get_generator_map函数得到那个静态局部变量,然后查找要注册的工程是否已经在the_map中存在,如果存在就提示失败信息,否则就把工厂的名字和工厂对象作为键值对添加到the_map中。
虽然找到了为the_map添加键值对的地方,但是还没有找到调用这个注册工厂函数的地方,所以继续在代码中搜索调用这个函数的地方。整个代码就只有一处调用了这个函数,而且是在一个类的构造函数中,代码如下:
t_generator_factory::t_generator_factory(const std::string& short_name, const std::string& long_name,
const std::string& documentation) : short_name_(short_name)
, long_name_(long_name) , documentation_(documentation)
{
t_generator_registry::register_generator(this);
}
t_generator_factory类是所有生产代码生产器对象工厂的基类,每一种具体的语言都有自己的代码生成器类和生产这种类的工厂类,上面的代码是它的构造函数,功能就是把自己注册到the_map中。看到这里是否有一种逐渐清晰的感觉,但是总是感觉还有少点什么,就是这个构造函数被调用也必须有这个类的对象被定义或其子类的对象被定义。于是我又开始搜索哪些类是从这个类继承的,发现两处很重要的代码,一处如下:
template
class t_generator_factory_impl : public t_generator_factory {
public:
t_generator_factory_impl(const std::string& short_name, const std::string& long_name,
const std::string& documentation) : t_generator_factory(short_name, long_name, documentation)
{}
virtual t_generator* get_generator(t_program* program,
const std::map<std::string, std::string>& parsed_options, const std::string& option_string) {
return new generator(program, parsed_options, option_string);
}
……//此处省略了一些代码
};
t_generator_factory_impl类继承了t_generator_factory类,而且在构造函数的时候也调用了父类的构造函数,因为是带参数的构造函数所以必须手动调用父类的构造函数。这个类是一个模板类,模板参数就是一个代码生成器类,所以函数get_generator就能够根据这个模板参数生成new一个对应语言的代码生成器对象了。这里就把上面提到的第一个问题也解决了,每一个工厂类把自己注册到the_map,然后使用者通过代表语言的键(key)在the_map找到对应的工厂对象,然后调用get_generator函数就生成具体的代码生成器对象了,这就是第一个问题提到的最后一句返回语句的代码执行情况。
但是还是没有看到定义具体的工厂对象呀,那么还需要看下面一处的代码
#define THRIFT_REGISTER_GENERATOR(language, long_name, doc) \
class t_##language##_generator_factory_impl \
: public t_generator_factory_impl<t_##language##_generator> \
{ \
public: \
t_##language##_generator_factory_impl() \
: t_generator_factory_impl<t_##language##_generator>( \
#language, long_name, doc) \
{} \
}; \
static t_##language##_generator_factory_impl _registerer;
这是一个宏定义,它根据参数language定义一个生产具体语言的代码生成器的工厂类,并从t_generator_factory_impl类继承,传递的模板参数也是对应语言的代码生成器类,构造函数同样调用了父类的构造函数;最后还定义了一个对应的静态的类全局变量(千呼万唤始出来,终于找到定义类的全局变量了)。但是还是存在同样的问题就是定义了宏函数还是需要调用才执行吧,所以就在代码中搜索调用了这个宏函数的代码,最终发现这个每一个具体的语言代码生成器的文件都调用了一次,如下面是C++的文件t_cpp_generator.cc中调用的代码
THRIFT_REGISTER_GENERATOR(cpp, “C++”,
” pure_enums: Generate pure enums instead of wrapper classes.\n”
” dense: Generate type specifications for the dense protocol.\n”
” include_prefix: Use full include paths in generated files.\n”
)
其他语言的代码生成器类的定义文件中都有类似的调用,这样每一个语言生成器对象的生产工厂就被注册到the_map中了,由此问题得到解决。
(2)t_generator类的generate_program函数
这个函数是生成具体语言代码的顶层函数,它会调用子类定义的各个子函数来做具体代码的生成过程,后面会详细解析C++、java和python代码生成的过程。
首先调用代码生成器的初始化函数来初始化代码生成器,然后依次调用各种基本数据类型和服务的生成函数来生成相应的代码,最后关闭代码生成器。代码实现如下
init_generator();
vector<t_enum*> enums = program_->get_enums();
vector<t_enum*>::iterator en_iter;
for (en_iter = enums.begin(); en_iter != enums.end(); ++en_iter) {
generate_enum(*en_iter);
}
vector<t_typedef*> typedefs = program_->get_typedefs();
vector<t_typedef*>::iterator td_iter;
for (td_iter = typedefs.begin(); td_iter != typedefs.end(); ++td_iter) {
generate_typedef(*td_iter);
}
vector<t_const*> consts = program_->get_consts();
generate_consts(consts);
vector<t_struct*> objects = program_->get_objects();
vector<t_struct*>::iterator o_iter;
for (o_iter = objects.begin(); o_iter != objects.end(); ++o_iter) {
if ((*o_iter)->is_xception()) {
generate_xception(*o_iter);
} else {
generate_struct(*o_iter);
}
}
vector<t_service*> services = program_->get_services();
vector<t_service*>::iterator sv_iter;
for (sv_iter = services.begin(); sv_iter != services.end(); ++sv_iter) {
service_name_ = get_service_name(*sv_iter);
generate_service(*sv_iter);
}
close_generator();
此函数使用的是词法和语法分析结果的一些符号,这些符号都保持在t_program对象的对于数据结构里面,所以上面的函数依次从t_program对象中取得各种数据类型的符号和服务的符号,并依次生成。
(3)t_generator类的其它功能简介
这个类是所有具体语言代码生成器的共同基类,所以定义了很多各种语言代码生成需要的共同功能,例如生成代码的格式控制、命名空间的有效性检查、驼峰标识符和下划线标识符的相互转换等等。这些功能比较简单,需要可以直接查看源代码。
3 生成C++语言代码的代码详解
这个功能是由t_cpp_generator类实现(在文件t_cpp_generator.cc定义和实现),直接继承至t_oop_generator类(这个类是所有面向对象语言生成器类的直接基类,封装了面向对象语言生成器共有的特征与行为),而t_oop_generator又从t_generator继承(上面已经介绍),下面详细分析这个类是怎样生成C++语言的代码文件的。这个还有从上面介绍的generate_program函数开始说起,因为这个函数才是控制整个代码生成的总枢纽。
首先执行的是构造函数,这个构造函数做了一些最基本的初始化,一个是传递拥有生成代码的符号资源的t_program对象到父类,第二个功能就是根据可选项参数初始化一些bool变量,以便后面根据这些bool变量做相应的处理,代码很简单就不列出来了,下面用一个表格说明各个bool变量的作用(或功能)
gen_pure_enums_
是否生成纯净的枚举类型,而不是采用类包装的形式
gen_dense_
是否应该为TDenseProtocol生成本地反射的元数据。
gen_templates_
是否要生成模板化的读/写方法
use_include_prefix_
是否应该为了thrift生成的其他头文件在#include中使用前缀路径
gen_cob_style_
是否应该生成继承扩展功能类(主要是异步)
gen_no_client_completion_
是否应该省略客户端类调用completion__()
构造函数只是做了最基本的初始化,更详细的初始化是上面介绍的代码生成器初始化函数init_generator,那我们看看C++代码生成器是怎么详细初始化的,都做了一些什么样的工作和实现了一些什么的功能。我们分步骤介绍这一个函数:
第一步:制作代码文件的输出目录:MKDIR(get_out_dir().c_str());MKDIR是一个宏函数,调用了mkdir来创建目录;
第二部:创建代码头文件和实现文件,如果需要生成模板化的读和写的方法还会创建一个文件单独实现,代码如下:
string f_types_name = get_out_dir()+program_name_+”_types.h”;
f_types_.open(f_types_name.c_str());
string f_types_impl_name = get_out_dir()+program_name_+”_types.cpp”;
f_types_impl_.open(f_types_impl_name.c_str());
if (gen_templates_) {
string f_types_tcc_name = get_out_dir()+program_name_+"_types.tcc";
f_types_tcc_.open(f_types_tcc_name.c_str());
}
这里需要说明几个用于输出流的成员变量,之所以定义成员变量是因为很多函数会用到,这样就不用用参数来传递它们了,它们定义和说明如下:
std::ofstream f_types_;//专门用于类型声明的输出流,也就是头文件(.h文件)
std::ofstream f_types_impl_;//专门用于类型实现的输出流,也就是实现文件(.cpp文件)
std::ofstream f_types_tcc_;//专门用于模板化的读和写方法实现的输出流
std::ofstream f_header_;//专门用于服务声明生成的输出流
std::ofstream f_service_;//专门用于服务实现生成的输出流
std::ofstream f_service_tcc_;//专门用于模板的服务的输出流
第三步:为每个文件打印头部注释,注释的作用就是说明这个文件是由Thrift自动生成的,代码如下:
f_types_ « autogen_comment();
f_types_impl_ « autogen_comment();
f_types_tcc_ « autogen_comment();
第四步:开始ifndef
第五步:包含各种头文件
第六步:打开命名空间,生成的代码都是在一个命令空间里面的。
以上步骤的功能都比较简单,主要就是注意输出格式和逻辑处理。通过这些功能基本内容都做好了,下面就是真正开始生成具体类型和服务的时候了,每一种数据类型都由一个单独的函数来负责生成为代码。
(1)枚举类型生成函数generate_enum
首先在头文件中生成定义枚举类型的代码,具体的过程就是得到枚举的所有常量值和枚举类型的名称,然后根据C++定义枚举类型的语法输出代码到头文件,输出过程中根据是否需要用类来包装而所有不同,同时生成的代码也需要格式控制。具体实现如下:
vector<t_enum_value*> constants = tenum->get_constants();
std::string enum_name = tenum->get_name();
if (!gen_pure_enums_) {
enum_name = "type";
f_types_ << indent() << "struct " << tenum->get_name() << " {" << endl;
indent_up();
}
f_types_ « indent() « “enum “ « enum_name;
generate_enum_constant_list(f_types_, constants, “”, “”, true);
if (!gen_pure_enums_) {
indent_down();
f_types_ << "};" << endl;
}
f_types_ « endl;
接着在后面在实现文件中定义一个整型数组和一个字符的数组并用定义的枚举类型的常量值来初始化这两个数组,后然在说这两个数组的值初始化一个map,其实这么做的目的就是为了测试这个枚举类型定义是否正确。
最后调用函数generate_local_reflection决定是否为TDenseProtocol协议生成对应类型的本地反射类型。这个函数功能比较复杂,后面单独详细讲解。
(2)类型定义生成函数generate_typedef
此函数功能简单,就是在头文件中生成一个typedef的定义,就只有一句实现:
f_types_ « indent() « “typedef “ « type_name(ttypedef->get_type(), true) « ” “
« ttypedef->get_symbolic() « ”;” « endl « endl;
(3)常量类型生成函数generate_consts
常量类型的实现是采用一个类来包装所有的常量并且使用单独的文件来实现,所有首先创建常量类型定义头文件和实现文件,代码如下:
string f_consts_name = get_out_dir()+program_name_+”_constants.h”;
ofstream f_consts;
f_consts.open(f_consts_name.c_str());
string f_consts_impl_name = get_out_dir()+program_name_+”_constants.cpp”;
ofstream f_consts_impl;
f_consts_impl.open(f_consts_impl_name.c_str());
接着按照就开始按照类的定义格式在头文件中生成定义类的代码并在实现文件中定义这个类的常量类型;在这个类的构造函数中给定义的数据类型赋值:
f_consts_impl « “const “ « program_name_ « “Constants g_” « program_name_ « “_constants;” « endl «
endl << program_name_ << "Constants::" << program_name_ << "Constants() {" << endl;
indent_up();
for (c_iter = consts.begin(); c_iter != consts.end(); ++c_iter) {
print_const_value(f_consts_impl, (*c_iter)->get_name(), (*c_iter)->get_type(), (*c_iter)->get_value());
}
indent_down();
indent(f_consts_impl) « ”}” « endl;
其中调用了print_const_value函数来根据数据类型来赋值,这些定义在类中的成员变量本身不是常量类型,只是在实现文件中定义了一个类的全局常量对象,在头文件中声明,以便其他地方可以被使用。
(4)异常类型生成函数generate_xception
这个函数其实调用下面需要详细分析的一个函数实现的,就是generate_struct函数,因为异常也是通过结构体来定义和实现的。不过C++语言生成器中也自己实现了这个函数,不过它是调用generate_cpp_struct函数实现,C++的generate_struct函数也是调用这个函数实现,只是传递一个bool变量来区分是否是异常类型,具体的实现在分析generate_struct函数时一起详细分析了,因为它们的基本实现功能都是相同的。
(5)结构体类型生成函数generate_struct
上面已经说了这个函数也是调用generate_cpp_struct函数实现,也就是说异常类型和结构体类型都是用同样的流程实现的,它们都是定义为一个类,只是异常都从TException继承,而一般的结构体没有。首先调用函数generate_struct_definition在头文件中生成定义类的代码,这个过程如下:
第一步:得到所有的成员变量;
第二步:根据是否有可选成员决定是否定义一个结构体_XXX_isset,这个结果主要针对需要定义的类的可选成员而定义一些bool变量,来标识这些可选成员变量是否存在。设计这个功能的目的是为了灵活控制数据传输的结构;
第三步:开始生成定义类(IDL文件中定义的struct在C++都是用class来实现)的代码,生成的代码主要包括默认的构造函数、析构函数、各个字段、比较函数(等于、不等于和小于)等;
第四步:最后一步生成一个模板的读和写数据的函数的声明,模板参数是协议类型,实现代码如下:
if (read) {//读数据的模板函数
if (gen_templates_) {
out <<indent() << "template <class Protocol_>" << endl <<
indent() << "uint32_t read(Protocol_* iprot);" << endl;
} else {
out << indent() << "uint32_t read(" << "::apache::thrift::protocol::TProtocol* iprot);" << endl;
}
}
if (write) {//写数据的模板函数
if (gen_templates_) {
out << indent() << "template <class Protocol_>" << endl <<
indent() << "uint32_t write(Protocol_* oprot) const;" << endl;
} else {
out << indent() << "uint32_t write(" << "::apache::thrift::protocol::TProtocol* oprot) const;" << endl;
}
}
然后调用函数generate_struct_fingerprint在实现文件中初始化两个静态变量,一个是字符串,一个是8位的整型数组,这两个变量都是用来唯一的标识一个类。这个歌标识符的作用就是用于生成本地的反射类型,当使用TDenseProtocol协议传输数据时会用到。
接着两次调用generate_local_reflection函数分别来声明和定义用于类的本地反射的类型,调用generate_local_reflection_pointer函数来生成一个类的静态指针的本地反射类型。
最后分别调用函数generate_struct_reader和generate_struct_writer实现数据读和写函数。到此整个IDL定义的struct类型生成为C++的代码就完成了。
(6)服务类型生成函数generate_service
这个函数的功能是最复杂的,它会做很多的工作(分别调用其它函数来实现),也会生成单独的头文件和实现文件。生成头文件的代码如下:
string f_header_name = get_out_dir()+svcname+”.h”;
f_header_.open(f_header_name.c_str());
下面就开始在头文件中生成一些包含头文件的代码。
生成实现文件的代码:
string f_service_name = get_out_dir()+svcname+”.cpp”; f_service_.open(f_service_name.c_str());
后面也是生成一些包含头文件的代码。接着就开始生成正在的各种实现这个服务的代码了,如下:
generate_service_interface(tservice, “”);//生成服务的接口类(在C++为抽象类)
generate_service_null(tservice, “”);//生成一个空实现服务接口类的类
generate_service_helpers(tservice);//生成一些帮助类,如参数类、返回结果类等
generate_service_client(tservice, “”);//生成一个客户类
generate_service_processor(tservice, “”);//生成处理数据的类(就是生成用于远程调用)
generate_service_multiface(tservice);//生成一个实现多接口的单一的服务器类
generate_service_skeleton(tservice);//生成一个服务器的框架文件
如果gen_cob_style_为true,还会生成一些扩展功能的类,代码如下:
if (gen_cob_style_) {
generate_service_interface(tservice, "CobCl");
generate_service_interface(tservice, "CobSv");
generate_service_null(tservice, "CobSv");
generate_service_client(tservice, "Cob");
generate_service_processor(tservice, "Cob");
generate_service_async_skeleton(tservice);
}
到此C++的代码的生成全部结束,最后调用close_generator函数来完成收尾工作和清理一些资源,如果关闭文件。
(7)总结
对于生成C++代码这一块内容把基本的生成过程详细分析了一遍,主要集中在整个流程中。但是很多功能还没有详细分析或还没有涉及到,因为整个代码有4千多行,要完全详细用文字分析下来工作量很多(代码肯定都看了一遍),而且也觉得没有必要,因为很多功能实现都挺简单,只要一看代码便能够理解。
上面分析过程没有提到的功能主要包括:数据的序列化和反序列化、具体生成服务需要的每一个类等等。其实整个代码并没有什么难点,主要是必须要思考周全,还有就是注意生成C++代码的合理性。
Thrift的核心组件有:
TProtocol 协议和编解码组件
TTransport 传输组件
TProcessor 服务调用组件
TServer,Client 服务器和客户端组件
IDL 服务描述组件,负责生产跨平台客户端
传输层 TTransport:
TTransport:客户端传输层抽象基础类,read、write、flush、close 等方法
TSocket 与 TNonBlockingSocket:分别是基于 BIO 和 NIO 客户端传输类
TServerSocket 与 TNonBlockingServerSocket:分别是基于 BIO 和 NIO 服务端传输类
TZlibTransport:
TSaslClientTransport 与 TSaslServerTransport:提供 SSL 校验
协议层 Protocol:
TBinaryProtocol:二进制流传输协议类,把各类型转换成 byte 数组,交给 TTransport 传输
TCompactProtocol:使用 Variable-Length Quantity(VLQ)编码对数据进行压缩(压缩方法二进制协议类,将 Integer 按 ZigZag 压缩)
TTupleProtocol:继承自 TCompactProtocol,Struct 使用时更省空间
TJSONProtocol:JSON 格式协议类,将数据封装成 JSON 格式,再转成 byte 数组交给传输层
TSimpleJSONProtocol:JSON 格式协议类,但只支持写的功能
处理层 Processor:
TProcessor:基础接口,process(TProtocol in, TProtocol out)
TBaseProcessor:基础抽象类,持有 processMap 对象,key 为方法名,value 为方法
Processor:由声明的 IDL 生成,实现 TProcessor 接口并继承了 TBaseProcessor 类
TAsyncProcessor:异步处理接口
TBaseAsyncProcessor:异步处理抽象类
AsyncProcessor:由声明的 IDL 生成,实现 TAsyncProcessor 接口并继承 TAsyncProcessor 类
服务层 Server:
TServer:基础抽象类,类似一个容器,持有 TProcessor、TTransport、TProtocol 的工厂对象,提供 server() 方法,用于启动服务,stop() 用于停止服务
TSimpleServer:单线程阻塞式服务
TNonblockingServer:支持非阻塞单线程服务模型,基于 NIO 的 select 实现
TThreadPoolServer:专门的线程接受请求并交给线程池处理,阻塞式线程池模型
TProtocol主要做了两个事情:
- 关联TTransport对象
2.定义一系列读写消息的编解码接口,包括两类,一类是复杂数据结构比如readMessageBegin, readMessageEnd, writeMessageBegin, writMessageEnd.还有一类是基本数据结构,比如readI32, writeI32, readString, writeString
从TProtocol的定义我们可以看出Thrift的协议约定如下事情:
先writeMessageBegin表示开始传输消息了,写消息头。Message里面定义了方法名,调用的类型,版本号,消息seqId
接下来是写方法的参数,实际就是写消息体。如果参数是一个类,就writeStructBegin
接下来写字段,writeFieldBegin, 这个方法会写接下来的字段的数据类型和顺序号。这个顺序号是Thrfit对要传输的字段的一个编码,从1开始
如果是一个集合就writeListBegin/writeMapBegin,如果是一个基本数据类型,比如int, 就直接writeI32
每个复杂数据类型写完都调用writeXXXEnd,直到writeMessageEnd结束
读消息时根据数据类型读取相应的长度
先看看TTransport这个基类有哪些common的抽象函数:
isOpen:用户判断底层传输链路是否是ready的;
open:用于打开底层的传输链路;
close:用于关闭底层传输链路;
read:用于从链路中读取数据;
write:用于往链路中写入数据;
flush:用于将内存中的buffer数据写到链路中;
getBufferPosition:返回链路底层buffer数据当前read位置;
getBuffer:用于返回底层buffer数据
getBytesRemainingInBuffer:用于返回当前底层buffer中还有多少数据没有读取;
consumeBuffer:从底层buffer数据中读取一些数据;
具体传输层协议解析
常用的传输层协议有如下一些:
TSocket:阻塞式socket;
TFramedTransport:使用非阻塞方式,以frame为单位进行传输。
TFileTransport:以文件形式进行传输。
TMemoryTransport:将内存用于I/O,java实现时内部实际使用了简单的ByteArrayOutputStream。
TZlibTransport:使用zlib进行压缩, 与其他传输方式联合使用。
TNonblockingTransport:使用非阻塞方式,用于构建异步客户端
read操作:先从readBuffer中读取指定长度的数据,如果读取到的数据长度大于0,说明成功读取到数据,直接返回;如果读不到数据,则需要从帧中load数据,从帧中load数据时,先读出头部的四个字节,表示后面数据的总长度size,然后再读取后面长度的size的数据,存储到readBuffer中。
write操作:write操作直接调用原声java的接口将数据暂时写到writeBuffer中;
flush操作:flush操作才是真正将内存缓存中的数据通过网络发送出去的操作,首先计算writeBuffer的总长度size,写到头部的四个字节中,然后再将全量数据写到剩余的size个字节中,最后调用底层Transport(比如TSocket)的flush操作将数据发送出去。显然,这个操作和read操作是相反的~
所以总结一下:TFramedTransport的数据流形式是:4字节数据长度+ 数据
Thrift的方法调用模型很简单,就是通过方法名和实际方法实现类的注册完成,没有使用反射机制,类加载机制。
和方法调用相关的几个核心类:
自动生成的Iface接口,是远程方法的顶层接口
自动生成的Processor类及相关父类,包括TProcessor接口,TBaseProcess抽象类
ProcessFunction抽象类,抽象了一个具体的方法调用,包含了方法名信息,调用方法的抽象过程等
TNonblcokingServer,是NIO服务器的默认实现,通过Args参数来配置Processor等信息
FrameBuffer类,服务器NIO的缓冲区对象,这个对象在服务器端收到全包并解码后,会调用Processor去完成实际的方法调用
服务器端的方法的具体实现类,实现Iface接口
来看TProcess相关类和接口
TProcessor就定义了一个顶层的调用方法process,参数是输入流和输出流
抽象类TBaseProcessor提供了TProcessor的process的默认实现,先读消息头,拿到要调用的方法名,然后从维护的一个Map中取ProcessFunction对象。ProcessFunction对象是实际方法的抽象,调用它的process方法,实际是调用了实际的方法。
Processor类是自动生成了,它依赖Iface接口,负责把实际的方法实现和方法的key关联起来,放到Map中维护
FrameBuffer是Thrift NIO服务器端的一个核心组件,它一方面承担了NIO编程中的缓冲区的功能,另一方面还承担了RPC方法调用的职责。
FrameBuffer读数据时,
先读4字节的Frame消息头,
然后改变FrameBufferState,从READING_FRMAE_SIZE到READING_FRAME,并根据读到的Frame长度修改Buffer的长度
再次读Frame消息体,如果读完就修改状态到READ_FRAME_COMPLETE,否则还是把FrameBuffer绑定到SelectionKey,下次继续读
在看写缓冲时的情况
写之前必须把FrameBuffer的状态改成WRITING,后面会有具体例子
如果没写任何数据,就返回false
如果写完了,就需要把SelectionKey注册的写事件取消。Thrift是直接把SelectionKey注册事件改成读了,而常用的做法一般是把写事件取消就行了。关于更多NIO写事件的注册问题
TTransport作为顶层的抽象,使用了抽象类,没有使用接口。个人感觉这种做法还是没有使用接口作为顶层抽象来得好,接口扩展性更好。
有几个关注点:
TIOStreamTransport和TSocket这两个类的结构对应着阻塞同步IO, TSocket封装了Socket接口
TNonblockingTrasnsort,TNonblockingSocket这两个类对应着非阻塞IO
TMemoryInputTransport封装了一个字节数组byte[]来做输入流的封装
TMemoryBuffer使用字节数组输出流ByteArrayOutputStream做输出流的封装
TFramedTransport则封装了TMemoryInputTransport做输入流,封装了TByteArryOutPutStream做输出流,作为内存读写缓冲区的一个封装。TFramedTransport的flush方法时,会先写4个字节的输出流的长度作为消息头,然后写消息体。和FrameBuffer的读消息对应起来。FrameBuffer对消息时,先读4个字节的长度,再读消息体
- TFastFramedTransport是内存利用率更高的一个内存读写缓存区,它使用自动增长的byte,而不是每次都new一个byte[],提高了内存的使用率。其他和TFramedTransport一样,flush时也会写4个字节的消息头表示消息长度。
再看TServer的类层次结构,主要也是两类,非阻塞IO和同步IO
非阻塞IO的Server有:
TNonblockingServer是单线程的,只有一个SelectAcceptThread线程来轮询IO就绪事件,调用就绪的channel来相应Accept, Read, Write事件,并且还是使用这个线程来同步调用实际的方法实现。
THsHaServer是所谓的半同步半异步的服务器。所谓半同步是说使用一个SelectAcceptThread线程来轮询IO就绪事件,调用就绪的channel来相应Accept, Read, Write事件。所谓的半异步是说方法的调用是封装成一个Runnable交给线程池来执行的,交给线程池立刻返回,不同步等待方法执行完毕,方法执行完毕的写返回是有线程池中的线程来做的,实现了所谓的异步访问的模式。
- TThreadSelectorServer,这个服务器类比较有意思,是多线程Reactor模式的一种实现。
3.1 采用了一个AcceptorThread来专门监听端口,处理Accept事件,然后创建SocketChannel。创建完成之后交给一个线程池来处理后续动作,将SocketChannel放到SelecotrThread的阻塞队列acceptedQueue中
3.2 采用多个SelectorThread来处理创建好的SocketChannel。每个SelectorThread绑定一个Selector,这样将SocketChannel分给多个Selector。同时SelectorThread又维护了一个阻塞队列acceptedQueue,从acceptedQueue中拿新创建好的SocketChannel,来注册读事件
同步的TServer有TThreadPoolServer,关联一个TServerSocket,采用同步IO的方式来Accept,然后交给一个线程池来处理后续动作
