Mutex
https://www.cl.cam.ac.uk/research/srg/netos/papers/2007-cpwl.pdf
1、概念
互斥锁(Mutex)是在原子操作API的基础上实现的信号量行为。互斥锁不能进行递归锁定或解锁,能用于交互上下文但是不能用于中断上下文,同一时间只能有一个任务持有互斥锁,而且只有这个任务可以对互斥锁进行解锁。当无法获取锁时,线程进入睡眠等待状态。
互斥锁是信号量的特例。信号量的初始值表示有多少个任务可以同时访问共享资源,如果初始值为1,表示只有1个任务可以访问,信号量变成互斥锁(Mutex)。但是互斥锁和信号量又有所区别,互斥锁的加锁和解锁必须在同一线程里对应使用,所以互斥锁只能用于线程的互斥;信号量可以由一个线程释放,另一个线程得到,所以信号量可以用于线程的同步。
2、数据结构
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters /
atomic_t count;
spinlock_t wait_lock;
struct list_head wait_list;
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_MUTEX_SPIN_ON_OWNER)
struct task_struct *owner;
#endif
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; / Spinner MCS lock */
#endif
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
结构体成员说明:
1、atomic_t count;
指示互斥锁的状态:1 没有上锁,可以获得;0 被锁定,不能获得。初始化为没有上锁。
2、spinlock_t wait_lock;
等待获取互斥锁中使用的自旋锁。在获取互斥锁的过程中,操作会在自旋锁的保护中进行。初始化为为锁定。
3、struct list_head wait_list;
等待互斥锁的进程队列。
二、如何使用互斥锁
1、初始化
mutex_init(&mutex); //动态初始化互斥锁
DEFINE_MUTEX(mutexname); //静态定义和初始化互斥锁
2、上锁
void mutex_lock(struct mutex *lock);
无法获得锁时,睡眠等待,不会被信号中断。
int mutex_trylock(struct mutex *lock);
此函数是 mutex_lock()的非阻塞版本,成功返回1,失败返回0。
int mutex_lock_interruptible(struct mutex *lock);
和mutex_lock()一样,也是获取互斥锁。在获得了互斥锁或进入睡眠直到获得互斥锁之后会返回0。如果在等待获取锁的时候进入睡眠状态收到一个信号(被信号打断睡眠),则返回_EINIR。
3、解锁
void mutex_unlock(struct mutex *lock);
三、什么时候使用互斥锁
1、互斥锁和信号量比较
a、互斥锁功能上基本与二元信号量一样,但是互斥锁占用空间比信号量小,运行效率比信号量高。所以,如果要用于线程间的互斥,优先选择互斥锁。
2、互斥锁和自旋锁比较
a、互斥锁在无法得到资源时,内核线程会进入睡眠阻塞状态,而自旋锁处于忙等待状态。因此,如果资源被占用的时间较长,使用互斥锁较好,因为可让CPU调度去做其它进程的工作。
b、如果被保护资源需要睡眠的话,那么只能使用互斥锁或者信号量,不能使用自旋锁。而互斥锁的效率又比信号量高,所以这时候最佳选择是互斥锁。
c、中断里面不能使用互斥锁,因为互斥锁在获取不到锁的情况下会进入睡眠,而中断是不能睡眠的。
mutex的严格语法信息:
a. 在同一时刻只能有一个task获得互斥锁
b. 只有锁的获得者才能有资格释放锁
c. 多处释放锁是不允许的
d. 递归获取锁是不允许的
e. 互斥锁必须使用系统的API初始化,不允许直接操作使用memset/memcpy
f. 获得锁的task是不允许退出
g. 持有锁驻留的内存区域不能被释放
h. 互斥锁不能用于中断上下文中, spin_lock是可以用于中断上下文的 。
再解释下struct mutex成员的含义:
count: count是一个原子变量,(关于原子变量不懂的,可以看前面的原子变量文章)。 当count=1代表资源可用,等于0代表资源不可用,加锁状态。 负值代表有等待者。
wait_lock: 是一个自旋锁变量, 用于对wait_list的操作变为原子变量
wait_list : 用于管理那些在获取mutex的进程,在无法获取互斥锁的时候,进入wait_List睡眠。
是不是和semaphore一样。 既然一样,互斥锁的定义和初始化也不能直接操作,必须使用系统提供的API
互斥锁还是分为三类:快速互斥锁/递归互斥锁/检测互斥锁
futex
要想了解互斥锁的内部实现,先来了解一下futex(fast Userspace mutexes)的作用。
内核态和用户态的混合机制。
还没有futex的时候,内核是如何维护同步与互斥的呢?系统内核维护一个对象,这个对象对所有进程可见,这个对象是用来管理互斥锁并且通知阻塞的进程。如果进程A要进入临界区,先去内核查看这个对象,有没有别的进程在占用这个临界区,出临界区的时候,也去内核查看这个对象,有没有别的进程在等待进入临界区。
互斥锁是并发程序中对共享资源进行访问控制的主要手段,对此Go语言提供了非常简单易用的Mutex,Mutex为一结构体类型,对外暴露两个方法Lock()和Unlock()分别用于加锁和解锁。
Mutex使用起来非常方便,但其内部实现却复杂得多,这包括Mutex的几种状态。另外,我们也想探究一下Mutex重复解锁引起panic的原因。
按照惯例,本节内容从源码入手,提取出实现原理,又不会过分纠结于实现细节。
- Mutex数据结构
2.1 Mutex结构体
源码包src/sync/mutex.go:Mutex定义了互斥锁的数据结构:
type Mutex struct {
state int32
sema uint32
}
Mutex.state表示互斥锁的状态,比如是否被锁定等。
Mutex.sema表示信号量,协程阻塞等待该信号量,解锁的协程释放信号量从而唤醒等待信号量的协程。
我们看到Mutex.state是32位的整型变量,内部实现时把该变量分成四份,用于记录Mutex的四种状态。
下图展示Mutex的内存布局:
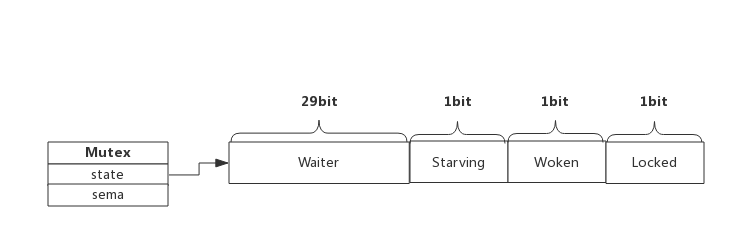
Locked: 表示该Mutex是否已被锁定,0:没有锁定 1:已被锁定。
Woken: 表示是否有协程已被唤醒,0:没有协程唤醒 1:已有协程唤醒,正在加锁过程中。
Starving:表示该Mutex是否处理饥饿状态, 0:没有饥饿 1:饥饿状态,说明有协程阻塞了超过1ms。
Waiter: 表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量。
协程之间抢锁实际上是抢给Locked赋值的权利,能给Locked域置1,就说明抢锁成功。抢不到的话就阻塞等待Mutex.sema信号量,一旦持有锁的协程解锁,等待的协程会依次被唤醒。
Woken和Starving主要用于控制协程间的抢锁过程,后面再进行了解。
2.2 Mutex方法
Mutext对外提供两个方法,实际上也只有这两个方法:
Lock() : 加锁方法
Unlock(): 解锁方法
下面我们分析一下加锁和解锁的过程,加锁分成功和失败两种情况,成功的话直接获取锁,失败后当前协程被阻塞,同样,解锁时跟据是否有阻塞协程也有两种处理。
- 加解锁过程
3.1 简单加锁
假定当前只有一个协程在加锁,没有其他协程干扰,那么过程如下图所示:
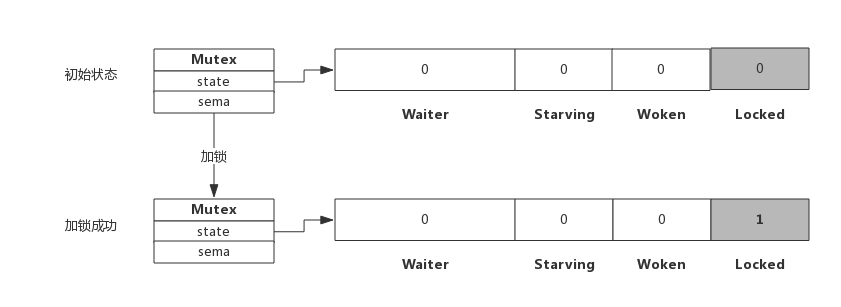
加锁过程会去判断Locked标志位是否为0,如果是0则把Locked位置1,代表加锁成功。从上图可见,加锁成功后,只是Locked位置1,其他状态位没发生变化。
3.2 加锁被阻塞
假定加锁时,锁已被其他协程占用了,此时加锁过程如下图所示:
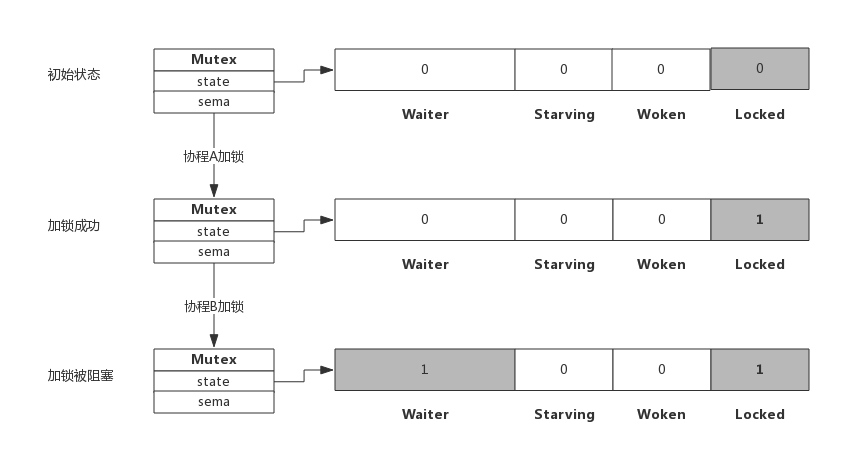
从上图可看到,当协程B对一个已被占用的锁再次加锁时,Waiter计数器增加了1,此时协程B将被阻塞,直到Locked值变为0后才会被唤醒。
3.3 简单解锁
假定解锁时,没有其他协程阻塞,此时解锁过程如下图所示:
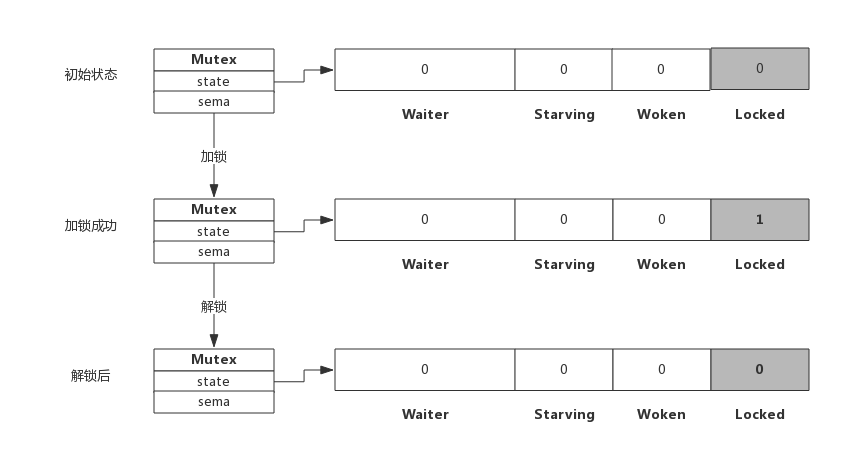
由于没有其他协程阻塞等待加锁,所以此时解锁时只需要把Locked位置为0即可,不需要释放信号量。
3.4 解锁并唤醒协程
假定解锁时,有1个或多个协程阻塞,此时解锁过程如下图所示:
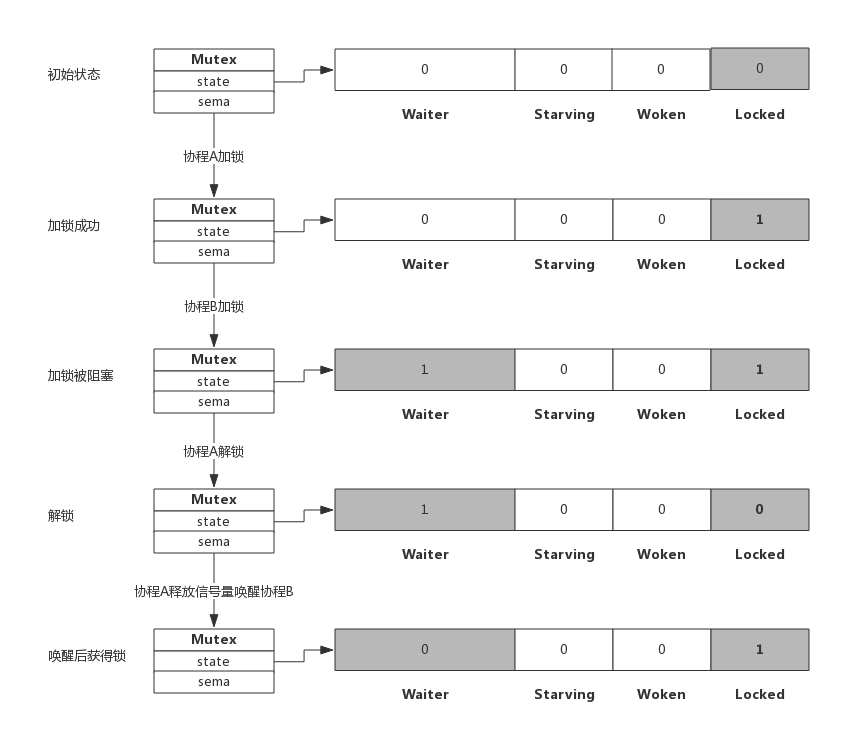
协程A解锁过程分为两个步骤,一是把Locked位置0,二是查看到Waiter>0,所以释放一个信号量,唤醒一个阻塞的协程,被唤醒的协程B把Locked位置1,于是协程B获得锁。
- 自旋过程
加锁时,如果当前Locked位为1,说明该锁当前由其他协程持有,尝试加锁的协程并不是马上转入阻塞,而是会持续的探测Locked位是否变为0,这个过程即为自旋过程。
自旋时间很短,但如果在自旋过程中发现锁已被释放,那么协程可以立即获取锁。此时即便有协程被唤醒也无法获取锁,只能再次阻塞。
自旋的好处是,当加锁失败时不必立即转入阻塞,有一定机会获取到锁,这样可以避免协程的切换。
4.1 什么是自旋
自旋对应于CPU的”PAUSE”指令,CPU对该指令什么都不做,相当于CPU空转,对程序而言相当于sleep了一小段时间,时间非常短,当前实现是30个时钟周期。
自旋过程中会持续探测Locked是否变为0,连续两次探测间隔就是执行这些PAUSE指令,它不同于sleep,不需要将协程转为睡眠状态。
4.1 自旋条件
加锁时程序会自动判断是否可以自旋,无限制的自旋将会给CPU带来巨大压力,所以判断是否可以自旋就很重要了。
自旋必须满足以下所有条件:
自旋次数要足够小,通常为4,即自旋最多4次
CPU核数要大于1,否则自旋没有意义,因为此时不可能有其他协程释放锁
协程调度机制中的Process数量要大于1,比如使用GOMAXPROCS()将处理器设置为1就不能启用自旋
协程调度机制中的可运行队列必须为空,否则会延迟协程调度
可见,自旋的条件是很苛刻的,总而言之就是不忙的时候才会启用自旋。
4.2 自旋的优势
自旋的优势是更充分的利用CPU,尽量避免协程切换。因为当前申请加锁的协程拥有CPU,如果经过短时间的自旋可以获得锁,当前协程可以继续运行,不必进入阻塞状态。
4.3 自旋的问题
如果自旋过程中获得锁,那么之前被阻塞的协程将无法获得锁,如果加锁的协程特别多,每次都通过自旋获得锁,那么之前被阻塞的进程将很难获得锁,从而进入饥饿状态。
为了避免协程长时间无法获取锁,自1.8版本以来增加了一个状态,即Mutex的Starving状态。这个状态下不会自旋,一旦有协程释放锁,那么一定会唤醒一个协程并成功加锁。
- Mutex模式
前面分析加锁和解锁过程中只关注了Waiter和Locked位的变化,现在我们看一下Starving位的作用。
每个Mutex都有两个模式,称为Normal和Starving。下面分别说明这两个模式。
4.1 normal模式
默认情况下,Mutex的模式为normal。
该模式下,协程如果加锁不成功不会立即转入阻塞排队,而是判断是否满足自旋的条件,如果满足则会启动自旋过程,尝试抢锁。
4.2 starvation模式
自旋过程中能抢到锁,一定意味着同一时刻有协程释放了锁,我们知道释放锁时如果发现有阻塞等待的协程,还会释放一个信号量来唤醒一个等待协程,被唤醒的协程得到CPU后开始运行,此时发现锁已被抢占了,自己只好再次阻塞,不过阻塞前会判断自上次阻塞到本次阻塞经过了多长时间,如果超过1ms的话,会将Mutex标记为”饥饿”模式,然后再阻塞。
处于饥饿模式下,不会启动自旋过程,也即一旦有协程释放了锁,那么一定会唤醒协程,被唤醒的协程将会成功获取锁,同时也会把等待计数减1。
Woken状态
Woken状态用于加锁和解锁过程的通信,举个例子,同一时刻,两个协程一个在加锁,一个在解锁,在加锁的协程可能在自旋过程中,此时把Woken标记为1,用于通知解锁协程不必释放信号量了,好比在说:你只管解锁好了,不必释放信号量,我马上就拿到锁了。
为什么重复解锁要panic
可能你会想,为什么Go不能实现得更健壮些,多次执行Unlock()也不要panic?
仔细想想Unlock的逻辑就可以理解,这实际上很难做到。Unlock过程分为将Locked置为0,然后判断Waiter值,如果值>0,则释放信号量。
如果多次Unlock(),那么可能每次都释放一个信号量,这样会唤醒多个协程,多个协程唤醒后会继续在Lock()的逻辑里抢锁,势必会增加Lock()实现的复杂度,也会引起不必要的协程切换。
- 编程Tips
7.1 使用defer避免死锁
加锁后立即使用defer对其解锁,可以有效的避免死锁。
7.2 加锁和解锁应该成对出现
加锁和解锁最好出现在同一个层次的代码块中,比如同一个函数。
重复解锁会引起panic,应避免这种操作的可能性。
https://rainbowmango.gitbook.io/go/chapter05
go 语言以并发作为其特性之一,并发必然会带来对于资源的竞争,这时候我们就需要使用 go 提供的 sync.Mutex 这把互斥锁来保证临界资源的访问互斥。
既然经常会用这把锁,那么了解一下其内部实现,就能了解这把锁适用什么场景,特性如何了。
引子
在我第一次看这段代码的时候,感觉真的是惊为天人,特别是整个 Mutex 只用到了两个私有字段,以及一次 CAS 就加锁的过程,这其中设计以及编程的理念真的让我感觉自愧不如。
在看 sync.Mutex 的代码的时候,一定要记住,同时会有多个 goroutine 会来要这把锁,所以锁的状态 state 是可能会一直更改的。
锁的性质
先说结论:sync.Mutex 是把公平锁。
在源代码中,有一段注释:
// Mutex fairness.
//
// Mutex can be in 2 modes of operations: normal and starvation.
// In normal mode waiters are queued in FIFO order, but a woken up waiter
// does not own the mutex and competes with new arriving goroutines over
// the ownership. New arriving goroutines have an advantage – they are
// already running on CPU and there can be lots of them, so a woken up
// waiter has good chances of losing. In such case it is queued at front
// of the wait queue. If a waiter fails to acquire the mutex for more than 1ms,
// it switches mutex to the starvation mode.
//
// In starvation mode ownership of the mutex is directly handed off from
// the unlocking goroutine to the waiter at the front of the queue.
// New arriving goroutines don’t try to acquire the mutex even if it appears
// to be unlocked, and don’t try to spin. Instead they queue themselves at
// the tail of the wait queue.
//
// If a waiter receives ownership of the mutex and sees that either
// (1) it is the last waiter in the queue, or (2) it waited for less than 1 ms,
// it switches mutex back to normal operation mode.
//
// Normal mode has considerably better performance as a goroutine can acquire
// a mutex several times in a row even if there are blocked waiters.
// Starvation mode is important to prevent pathological cases of tail latency.
看懂这段注释对于我们理解 mutex 这把锁有很大的帮助,这里面讲了这把锁的设计理念。大致意思如下:
// 公平锁
//
// 锁有两种模式:正常模式和饥饿模式。
// 在正常模式下,所有的等待锁的goroutine都会存在一个先进先出的队列中(轮流被唤醒)
// 但是一个被唤醒的goroutine并不是直接获得锁,而是仍然需要和那些新请求锁的(new arrivial)
// 的goroutine竞争,而这其实是不公平的,因为新请求锁的goroutine有一个优势——它们正在CPU上
// 运行,并且数量可能会很多。所以一个被唤醒的goroutine拿到锁的概率是很小的。在这种情况下,
// 这个被唤醒的goroutine会加入到队列的头部。如果一个等待的goroutine有超过1ms(写死在代码中)
// 都没获取到锁,那么就会把锁转变为饥饿模式。
//
// 在饥饿模式中,锁的所有权会直接从释放锁(unlock)的goroutine转交给队列头的goroutine,
// 新请求锁的goroutine就算锁是空闲状态也不会去获取锁,并且也不会尝试自旋。它们只是排到队列的尾部。
//
// 如果一个goroutine获取到了锁之后,它会判断以下两种情况:
// 1. 它是队列中最后一个goroutine;
// 2. 它拿到锁所花的时间小于1ms;
// 以上只要有一个成立,它就会把锁转变回正常模式。
// 正常模式会有比较好的性能,因为即使有很多阻塞的等待锁的goroutine,
// 一个goroutine也可以尝试请求多次锁。
// 饥饿模式对于防止尾部延迟来说非常的重要。
在下一步真正看源代码之前,我们必须要理解一点:当一个 goroutine 获取到锁的时候,有可能没有竞争者,也有可能会有很多竞争者,那么我们就需要站在不同的 goroutine 的角度上去考虑 goroutine 看到的锁的状态和实际状态、期望状态之间的转化。
字段定义
sync.Mutex 只包含两个字段:
// A Mutex is a mutual exclusion lock.
// The zero value for a Mutex is an unlocked mutex.
//
// A Mutex must not be copied after first use.
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 « iota // mutex is locked
mutexWoken
mutexStarving
mutexWaiterShift = iota
starvationThresholdNs = 1e6 ) 其中 state 是一个表示锁的状态的字段,这个字段会同时被多个 goroutine 所共用(使用 atomic.CAS 来保证原子性),第 0 个 bit(1)表示锁已被获取,也就是已加锁,被某个 goroutine 拥有;第 1 个 bit(2)表示有 goroutine 被唤醒,尝试获取锁;第 2 个 bit(4)标记这把锁是否为饥饿状态。
sema 字段就是用来唤醒 goroutine 所用的信号量。
Lock
在看代码之前,我们需要有一个概念:每个 goroutine 也有自己的状态,存在局部变量里面(也就是函数栈里面),goroutine 有可能是新到的、被唤醒的、正常的、饥饿的。
atomic.CAS
先瞻仰一下惊为天人的一行代码加锁的 CAS 操作:
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
…
}
这是第一段代码,这段代码调用了 atomic 包中的 CompareAndSwapInt32 这个方法来尝试快速获取锁,这个方法的签名如下:
// CompareAndSwapInt32 executes the compare-and-swap operation for an int32 value.
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
意思是,如果 addr 指向的地址中存的值和 old 一样,那么就把 addr 中的值改为 new 并返回 true;否则什么都不做,返回 false。由于是 atomic 中的函数,所以是保证了原子性的。
我们来具体看看 CAS 的实现(src/runtime/internal/atomic/asm_amd64.s):
// bool Cas(int32 val, int32 old, int32 new)
// Atomically:
// if(val == old){
// val = new;
// return 1;
// } else
// return 0;
// 这里参数及返回值大小加起来是17,是因为一个指针在amd64下是8字节,
// 然后int32分别是占用4字节,最后的返回值是bool占用1字节,所以加起来是17
TEXT runtime∕internal∕atomic·Cas(SB),NOSPLIT,$0-17
// 为什么不把val指针放到AX中呢?因为AX有特殊用处,
// 在下面的CMPXCHGL里面,会从AX中读取要比较的其中一个数
MOVQ ptr+0(FP), BX
// 所以AX要用来存参数old
MOVL old+8(FP), AX
// 把new中的数存到寄存器CX中
MOVL new+12(FP), CX
// 注意这里了,这里使用了LOCK前缀,所以保证操作是原子的
LOCK
// 0(BX) 可以理解为 *val
// 把 AX中的数 和 第二个操作数 0(BX)——也就是BX寄存器所指向的地址中存的值 进行比较
// 如果相等,就把 第一个操作数 CX寄存器中存的值 赋给 第二个操作数 BX寄存器所指向的地址
// 并将标志寄存器ZF设为1
// 否则将标志寄存器ZF清零
CMPXCHGL CX, 0(BX)
// SETE的作用是:
// 如果Zero Flag标志寄存器为1,那么就把操作数设为1
// 否则把操作数设为0
// 也就是说,如果上面的比较相等了,就返回true,否则为false
// ret+16(FP)代表了返回值的地址
SETEQ ret+16(FP)
RET
如果看不懂也没太大关系,只要知道这个函数的作用,以及这个函数是原子性的即可。
那么这段代码的意思就是:先看看这把锁是不是空闲状态,如果是的话,直接原子性地修改一下 state 为已被获取就行了。多么简洁(虽然后面的代码并不是……)!
主流程
接下来具体看主流程的代码,代码中有一些位运算看起来比较晕,我会试着用伪代码在边上注释。
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// 用来存当前goroutine等待的时间
var waitStartTime int64
// 用来存当前goroutine是否饥饿
starving := false
// 用来存当前goroutine是否已唤醒
awoke := false
// 用来存当前goroutine的循环次数(想一想一个goroutine如果循环了2147483648次咋办……)
iter := 0
// 复制一下当前锁的状态
old := m.state
// 自旋
for {
// 如果是饥饿情况之下,就不要自旋了,因为锁会直接交给队列头部的goroutine
// 如果锁是被获取状态,并且满足自旋条件(canSpin见后文分析),那么就自旋等锁
// 伪代码:if isLocked() and isNotStarving() and canSpin()
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// 将自己的状态以及锁的状态设置为唤醒,这样当Unlock的时候就不会去唤醒其它被阻塞的goroutine了
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
// 进行自旋(分析见后文)
runtime_doSpin()
iter++
// 更新锁的状态(有可能在自旋的这段时间之内锁的状态已经被其它goroutine改变)
old = m.state
continue
}
// 当走到这一步的时候,可能会有以下的情况:
// 1. 锁被获取+饥饿
// 2. 锁被获取+正常
// 3. 锁空闲+饥饿
// 4. 锁空闲+正常
// goroutine的状态可能是唤醒以及非唤醒
// 复制一份当前的状态,目的是根据当前状态设置出期望的状态,存在new里面,
// 并且通过CAS来比较以及更新锁的状态
// old用来存锁的当前状态
new := old
// 如果说锁不是饥饿状态,就把期望状态设置为被获取(获取锁)
// 也就是说,如果是饥饿状态,就不要把期望状态设置为被获取
// 新到的goroutine乖乖排队去
// 伪代码:if isNotStarving()
if old&mutexStarving == 0 {
// 伪代码:newState = locked
new |= mutexLocked
}
// 如果锁是被获取状态,或者饥饿状态
// 就把期望状态中的等待队列的等待者数量+1(实际上是new + 8)
// (会不会可能有三亿个goroutine等待拿锁……)
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// 如果说当前的goroutine是饥饿状态,并且锁被其它goroutine获取
// 那么将期望的锁的状态设置为饥饿状态
// 如果锁是释放状态,那么就不用切换了
// Unlock期望一个饥饿的锁会有一些等待拿锁的goroutine,而不只是一个
// 这种情况下不会成立
if starving && old&mutexLocked != 0 {
// 期望状态设置为饥饿状态
new |= mutexStarving
}
// 如果说当前goroutine是被唤醒状态,我们需要reset这个状态
// 因为goroutine要么是拿到锁了,要么是进入sleep了
if awoke {
// 如果说期望状态不是woken状态,那么肯定出问题了
// 这里看不懂没关系,wake的逻辑在下面
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
// 这句就是把new设置为非唤醒状态
// &^的意思是and not
new &^= mutexWoken
}
// 通过CAS来尝试设置锁的状态
// 这里可能是设置锁,也有可能是只设置为饥饿状态和等待数量
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 如果说old状态不是饥饿状态也不是被获取状态
// 那么代表当前goroutine已经通过CAS成功获取了锁
// (能进入这个代码块表示状态已改变,也就是说状态是从空闲到被获取)
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
// 如果之前已经等待过了,那么就要放到队列头
queueLifo := waitStartTime != 0
// 如果说之前没有等待过,就初始化设置现在的等待时间
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 既然获取锁失败了,就使用sleep原语来阻塞当前goroutine
// 通过信号量来排队获取锁
// 如果是新来的goroutine,就放到队列尾部
// 如果是被唤醒的等待锁的goroutine,就放到队列头部
runtime_SemacquireMutex(&m.sema, queueLifo)
// 这里sleep完了,被唤醒
// 如果当前goroutine已经是饥饿状态了
// 或者当前goroutine已经等待了1ms(在上面定义常量)以上
// 就把当前goroutine的状态设置为饥饿
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
// 再次获取一下锁现在的状态
old = m.state
// 如果说锁现在是饥饿状态,就代表现在锁是被释放的状态,当前goroutine是被信号量所唤醒的
// 也就是说,锁被直接交给了当前goroutine
if old&mutexStarving != 0 {
// 如果说当前锁的状态是被唤醒状态或者被获取状态,或者说等待的队列为空
// 那么是不可能的,肯定是出问题了,因为当前状态肯定应该有等待的队列,锁也一定是被释放状态且未唤醒
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 当前的goroutine获得了锁,那么就把等待队列-1
delta := int32(mutexLocked - 1<<mutexWaiterShift)
// 如果当前goroutine非饥饿状态,或者说当前goroutine是队列中最后一个goroutine
// 那么就退出饥饿模式,把状态设置为正常
if !starving || old>>mutexWaiterShift == 1 {
// Exit starvation mode.
// Critical to do it here and consider wait time.
// Starvation mode is so inefficient, that two goroutines
// can go lock-step infinitely once they switch mutex
// to starvation mode.
delta -= mutexStarving
}
// 原子性地加上改动的状态
atomic.AddInt32(&m.state, delta)
break
}
// 如果锁不是饥饿模式,就把当前的goroutine设为被唤醒
// 并且重置iter(重置spin)
awoke = true
iter = 0
} else {
// 如果CAS不成功,也就是说没能成功获得锁,锁被别的goroutine获得了或者锁一直没被释放
// 那么就更新状态,重新开始循环尝试拿锁
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
} } 以上为什么 CAS 能拿到锁呢?因为 CAS 会原子性地判断 old state 和当前锁的状态是否一致;而总有一个 goroutine 会满足以上条件成功拿锁。
canSpin
接下来我们来看看上文提到的 canSpin 条件如何:
// Active spinning for sync.Mutex.
//go:linkname sync_runtime_canSpin sync.runtime_canSpin
//go:nosplit
func sync_runtime_canSpin(i int) bool {
// 这里的active_spin是个常量,值为4
// 简单来说,sync.Mutex是有可能被多个goroutine竞争的,所以不应该大量自旋(消耗CPU)
// 自旋的条件如下:
// 1. 自旋次数小于active_spin(这里是4)次;
// 2. 在多核机器上;
// 3. GOMAXPROCS > 1并且至少有一个其它的处于运行状态的P;
// 4. 当前P没有其它等待运行的G;
// 满足以上四个条件才可以进行自旋。
if i >= active_spin || ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 {
return false
}
if p := getg().m.p.ptr(); !runqempty(p) {
return false
}
return true
}
所以可以看出来,并不是一直无限自旋下去的,当自旋次数到达 4 次或者其它条件不符合的时候,就改为信号量拿锁了。
doSpin
然后我们来看看 doSpin 的实现(其实也没啥好看的):
//go:linkname sync_runtime_doSpin sync.runtime_doSpin
//go:nosplit
func sync_runtime_doSpin() {
procyield(active_spin_cnt)
}
这是一个汇编实现的函数,简单看两眼 amd64 上的实现:
TEXT runtime·procyield(SB),NOSPLIT,$0-0
MOVL cycles+0(FP), AX
again:
PAUSE
SUBL $1, AX
JNZ again
RET
看起来没啥好看的,直接跳过吧。
Unlock
接下来我们来看看 Unlock 的实现,对于 Unlock 来说,有两个比较关键的特性:
如果说锁不是处于 locked 状态,那么对锁执行 Unlock 会导致 panic;
锁和 goroutine 没有对应关系,所以我们完全可以在 goroutine 1 中获取到锁,然后在 goroutine 2 中调用 Unlock 来释放锁(这是什么骚操作!)(虽然不推荐大家这么干……)
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// Fast path: drop lock bit.
// 这里获取到锁的状态,然后将状态减去被获取的状态(也就是解锁),称为new(期望)状态
// 注意以上两个操作是原子的,所以不用担心多个goroutine并发的问题
new := atomic.AddInt32(&m.state, -mutexLocked)
// 如果说,期望状态加上被获取的状态,不是被获取的话
// 那么就panic
// 在这里给大家提一个问题:干嘛要这么大费周章先减去再加上,直接比较一下原来锁的状态是否被获取不就完事了?
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
// 如果说new状态(也就是锁的状态)不是饥饿状态
if new&mutexStarving == 0 {
// 复制一下原先状态
old := new
for {
// 如果说锁没有等待拿锁的goroutine
// 或者锁被获取了(在循环的过程中被其它goroutine获取了)
// 或者锁是被唤醒状态(表示有goroutine被唤醒,不需要再去尝试唤醒其它goroutine)
// 或者锁是饥饿模式(会直接转交给队列头的goroutine)
// 那么就直接返回,啥都不用做了
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 走到这一步的时候,说明锁目前还是空闲状态,并且没有goroutine被唤醒且队列中有goroutine等待拿锁
// 那么我们就要把锁的状态设置为被唤醒,等待队列-1
new = (old - 1<<mutexWaiterShift) | mutexWoken
// 又是熟悉的CAS
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 如果状态设置成功了,我们就通过信号量去唤醒goroutine
runtime_Semrelease(&m.sema, false)
return
}
// 循环结束的时候,更新一下状态,因为有可能在执行的过程中,状态被修改了(比如被Lock改为了饥饿状态)
old = m.state
}
} else {
// 如果是饥饿状态下,那么我们就直接把锁的所有权通过信号量移交给队列头的goroutine就好了
// handoff = true表示直接把锁交给队列头部的goroutine
// 注意:在这个时候,锁被获取的状态没有被设置,会由被唤醒的goroutine在唤醒后设置
// 但是当锁处于饥饿状态的时候,我们也认为锁是被获取的(因为我们手动指定了获取的goroutine)
// 所以说新来的goroutine不会尝试去获取锁(在Lock中有体现)
runtime_Semrelease(&m.sema, true)
} } 总结 根据以上代码的分析,可以看出,sync.Mutex 这把锁在你的工作负载(所需时间)比较低,比如只是对某个关键变量赋值的时候,性能还是比较好的,但是如果说对于临界资源的操作耗时很长(特别是单个操作就大于 1ms)的话,实际上性能上会有一定的问题,这也就是我们经常看到 “的锁一直处于饥饿状态” 的问题,对于这种情况,可能就需要另寻他法了。
在学习 C++11 中新增的原子操作以及相应的 memory model 之后; 再看 golang 中的 sync/atomic, 可以发现 sync/atomic 提供的是纯粹的原子操作, 等同于 c++11 中的 std::memory_order_relaxed. 所以 The Go Memory Model 在介绍 golang memory model 并未提及到 atomic 可以实现同步语义.
按我理解 C++11 中的原子操作自带各种同步语义是由于目前硬件限制决定的: CPU 在实现缓存机制时无法做到完全透明, 所以开发者在开发时不得不考虑 CPU 缓存所带来的各种副作用, 这由此导致了 C++11 的原子操作除了操作是原子的之外, 还自带了同步光环. 所以从长远来讲我觉得 golang 中的原子操作才是正宗的原子操作.
