runtime
http://www.cs.columbia.edu/~aho/cs6998/reports/12-12-11_DeshpandeSponslerWeiss_GO.pdf
Runtime管理任务调度,垃圾收集及运行环境。大家知道Go语言程序是编译为机器代码来执行的。同时,Go提供了一些高级的功能,如goroutine, channel, 以及Garbage collection。这些高级功能需要一个runtime的支持。1.4之前,runtime还是由C语言所编写的,(按照Go dev team的规划,1.5版本将去除C的代码,runtime将完全由Go语言来完成。)不论何种方式,runtime和用户编译后的代码被linker静态链接起来,形成一个可执行文件。这个文件从操作系统角度来说是一个user space的独立的可执行文件。
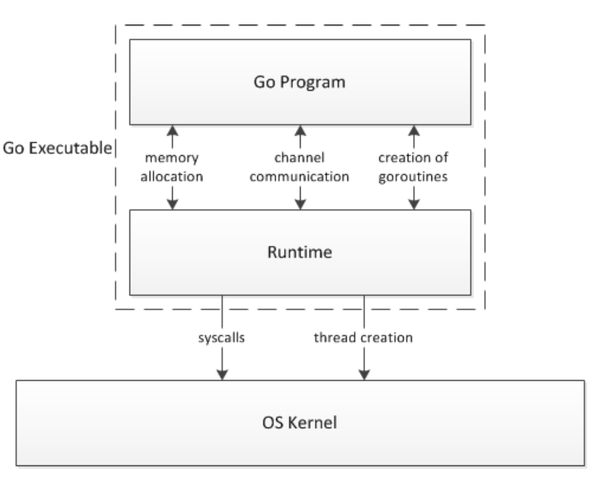
从运行的角度来说,这个文件由2部分组成,一部分是用户的代码,另一部分就是runtime。runtime通过接口函数调用来管理goroutine, channel及其他一些高级的功能。从用户代码发起的调用操作系统API的调用都会被runtime拦截并处理。
Go runtime的一个重要的组成部分是goroutine scheduler。他负责追踪,调度每个goroutine运行,实际上是从应用程序的process所属的thread pool中分配一个thread来执行这个goroutine。因此,和java虚拟机中的Java thread和OS thread映射概念类似,每个goroutine只有分配到一个OS thread才能运行。
runtime包含Go运行时的系统交互的操作,例如控制goruntine的功能。还有debug,pprof进行排查问题和运行时性能分析,tracer来抓取异常事件信息,如 goroutine的创建,加锁解锁状态,系统调用进入推出和锁定还有GC相关的事件,堆栈大小的改变以及进程的退出和开始事件等等;race进行竞态关系检查以及CGO的实现。总的来说运行时是调度器和GC
线程有自己的信号掩码,上下文环境以及各种控制信息等,但这些很多特征对于Go程序本身来说并不关心, 而且context上下文切换的耗时费时费力费资源,更重要的是GC的原因,也是本文下部分说的,就是Go的垃圾回收需要stop the world,所有的goroutine停止,才能使得内存保持在一个一致的状态。垃圾回收的时间会根据内存情况变化是不确定的,如果我们没有自己的scheduler我们交给了OS自己的scheduler,我们就失去了控制,并且会有大量的线程需要停止工作。所以Go就需要自己单独的开发一个自己使用的调度器,能够自己管理goruntines,并且知道在什么时候内存状态是一致的,也就是说,对于OS而言运行时只需要为当时正在CPU核上运行的那个线程等待即可,而不是等待所有的线程。
每一个Go程序都附带一个runtime,runtime负责与底层操作系统交互,也都会有scheduler对goruntines进行调度。在scheduler中有三个非常重要的概念:P,M,G。
查看源码/src/runtime/proc.go我们可以看到注释:
// Goroutine scheduler
// The scheduler’s job is to distribute ready-to-run goroutines over worker threads.
//
// The main concepts are:
// G - goroutine.
// M - worker thread, or machine.
// P - processor, a resource that is required to execute Go code.
// M must have an associated P to execute Go code, however it can be
// blocked or in a syscall w/o an associated P.
//
// Design doc at https://golang.org/s/go11sched.
我们也看下Go程序的启动流程:
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
那么scheduler究竟解决了什么问题并如何管理goruntines呢?
想要自己解决调度,避不开一个问题那就是栈的管理,也就是说每个goroutine都有自己的栈,在创建goroutine时,就要同时创建对应的栈。那么可知goroutine在执行时,栈空间会不停增长。 栈通常是连续增长的,每个进程中的各个线程共享虚拟内存空间,当有多个线程时,就需要为每个线程分配不同起始地址的栈,这就需要在分配栈之前先预估每个线程栈的大小。为了解决这个问题,就有了Split Stacks技术: 创建栈时,只分配一块比较小的内存,如果进行某次函数调用导致栈空间不足时,就会在其他地方分配一块新的栈空间。 新的空间不需要和老的栈空间连续。函数调用的参数会拷贝到新的栈空间中,接下来的函数执行都在新栈空间中进行。runtime的栈管理方式与此类似,但是为了更高的效率,使用了连续栈 (Golang连续栈) 实现方式也是先分配一块固定大小的栈,在栈空间不足时,分配一块更大的栈,并把旧的栈全部拷贝到新栈中,这样避免了Split Stacks方法可能导致的频繁内存分配和释放。
既然要调度那么肯定要有自己的调度策略了,go使用抢占式调度,goroutine的执行是可以被抢占的。如果一个goroutine一直占用CPU,长时间没有被调度过, 就会被runtime抢占掉,把CPU时间交给其他goroutine。详见:Go Preemptive Scheduler Design Doc runtime在程序启动时,会自动创建一个系统线程,运行sysmon()函数, sysmon()函数在整个程序生命周期中一直执行,负责监视各个Goroutine的状态、判断是否要进行垃圾回收等,sysmon()会调用retake()函数,retake()函数会遍历所有的P,如果一个P处于执行状态, 且已经连续执行了较长时间,就会被抢占。
然后retake()调用preemptone()将P的stackguard0设为stackPreempt,这将导致该P中正在执行的G进行下一次函数调用时, 导致栈空间检查失败,进而触发morestack(),在goschedImpl()函数中,会通过调用dropg()将G与M解除绑定;再调用globrunqput()将G加入全局runnable队列中;最后调用schedule() 来用为当前P设置新的可执行的G。
go function 即可启动一个goroutine,所以每go出去一个语句被执行,runqueue队列就在其末尾加入一个goroutine,并在下一个调度点,就从runqueue中取出,一个goroutine执行。同时每个P可以转而投奔另一个OS线程,保证有足够的线程来运行所以的context P,也就是说goruntine可以在合适时机在多个OS线程间切换,也可以一直在一个线程,这由调度器决定。
GC优化之路:
1.3 以前,使用的是比较蠢的传统 Mark-Sweep 算法。
1.3 版本进行了一下改进,把 Sweep 改为了并行操作。
1.5 版本进行了较大改进,使用了改进三色标记算法,叫做“非分代的、非移动的、并发的、三色的标记清除垃圾收集器”,go 除了标准的三色收集以外,还有一个辅助回收功能,防止垃圾产生过快。分为两个主要阶段-markl阶段:GC对对象和不再使用的内存进行标记;sweep阶段,准备进行回收。这中间还分为两个子阶段,第一阶段,暂停应用,结束上一次sweep,接着进入并发mark阶段:找到正在使用的内存;第二阶段,mark结束阶段,这期间应用再一次暂停。最后,未使用的内存会被逐步回收,这个阶段是异步的,不会STW。
1.6中,finalizer的扫描被移到了并发阶段中,对于大量连接的应用来说,GC的性能得到了显著提升。
1.7号称史上改进最多的版本,在GC上的改进也很显著:并发的进行栈收缩,这样我们既实现了低延迟,又避免了对runtime进行调优,只要使用标准的runtime就可以。
1.8 消除了GC的“stop-the-world stack re-scanning”
导入方式:
import “runtime”
runtime包提供和go运行时环境的互操作,如控制go程的函数。它也包括用于reflect包的低层次类型信息;参见reflect报的文档获取运行时类型系统的可编程接口。
1.constant常量
const GOOS string = theGoos
GOOS是可执行程序的目标操作系统(将要在该操作系统的机器上执行):darwin、freebsd、linux等。
可以用来判断你的电脑的系统是什么,然后根据不同的系统实现不同的操作,比如你想要根据系统的不同来说明退出程序使用的不同的快捷键,就说可以使用该常量来判断:
复制代码
package main
import(
“fmt”
“runtime”
)
var prompt = “Enter a radius and an angle (in degrees), e.g., 12.5 90, “ +
“or %s to quit.”
func init(){
if runtime.GOOS == “window” {
prompt = fmt.Sprintf(prompt, “Ctrl+Z, Enter”)
}else {
prompt = fmt.Sprintf(prompt, “Ctrl+D”)
}
}
func main() {
fmt.Println(prompt)
}
复制代码
因为我的系统是Unix,所以返回:
userdeMBP:go-learning user$ go run test.go
Enter a radius and an angle (in degrees), e.g., 12.5 90, or Ctrl+D to quit.
2.
func GOROOT
func GOROOT() string
GOROOT返回Go的根目录。如果存在GOROOT环境变量,返回该变量的值;否则,返回创建Go时的根目录。
func Version
func Version() string
返回Go的版本字符串。它要么是递交的hash和创建时的日期;要么是发行标签如”go1.3”。
func GC
func GC()
GC执行一次垃圾回收。
举例,说明sync.Pool缓存的期限只是两次gc之间这段时间。使用了runtime.GC(),缓存会被清空,那么结果就会变成:
复制代码
package main
import(
“fmt”
“sync”
“runtime”
)
func main() {
//创建一个对象,如果pool为空,就调用该New;如果没有定义New,则返回nil
pipe := &sync.Pool{
New: func() interface{} {
return “hello ,New”
},
}
fmt.Println(pipe.Get())//hello ,New
pipe.Put(“hello, put”)
runtime.GC() //作用是GC执行一次垃圾回收
fmt.Println(pipe.Get())//hello ,New,本来应该是hello, put
}
复制代码
runtime包中几个用于处理goroutine的函数:
func Goexit
func Goexit()
Goexit终止调用它的go程。其它go程不会受影响。Goexit会在终止该go程前执行所有defer的函数。
在程序的main go程调用本函数,会终结该go程,而不会让main返回。因为main函数没有返回,程序会继续执行其它的go程。如果所有其它go程都退出了,程序就会崩溃。
func Gosched
func Gosched()
Gosched使当前go程放弃处理器,以让其它go程运行。它不会挂起当前go程,因此当前go程未来会恢复执行。
其实就是让该goroutine让CPU把时间片让给别的goroutine,下次某个时候再继续执行,举例:
复制代码
package main
import(
“fmt”
“runtime”
)
func say(s string) {
for i := 0; i < 3; i++{
runtime.Gosched()
fmt.Println(s)
}
}
func main() {
go say(“world”)
say(“hello”)
}
复制代码
返回:
复制代码
userdeMacBook-Pro:go-learning user$ go run test.go
world
hello
world
hello
world
hello
复制代码
func NumGoroutine
func NumGoroutine() int
NumGoroutine返回当前存在的Go程数。
func NumCPU
func NumCPU() int
NumCPU返回本地机器的逻辑CPU个数。
func GOMAXPROCS
func GOMAXPROCS(n int) int
GOMAXPROCS设置可同时执行的最大CPU数,并返回先前的设置。 若 n < 1,它就不会更改当前设置。本地机器的逻辑CPU数可通过 NumCPU 查询。本函数在调度程序优化后会去掉。设置了同时运行逻辑代码的
复制代码
package main
import(
“fmt”
“runtime”
)
func main() {
fmt.Println(runtime.GOROOT()) // /usr/local/Cellar/go/1.11.4/libexec
fmt.Println(runtime.Version()) //go1.11.4
fmt.Println(runtime.NumCPU()) //8
fmt.Println(runtime.GOMAXPROCS(runtime.NumCPU())) //8
}
Runtime
在$goroot/pkg/runtime/中有三个文件非常重要:
proc.c
stack.h
runtime.h
在runtime.h中你能看到许多的数据结构和接口
这里的数据结构就是go中的各种特定的结构对应的底层实现,比如slice:
struct Slice
{ // must not move anything
byte* array; // actual data
uint32 len; // number of elements
uint32 cap; // allocated number of elements
};
其中还有两个重要的结构:
G
G代表的是goroutine。开启一个goroutine实际就是实例化一个G
M
M代表的是Machine。M中存放go程序和机器CPU交互的数据结构
比如一个双核CPU,在主routine外开启了4个goroutine,那么实际上就有2个M结构,6个G结构(1个是主routine,4个开启的routine,最后一个是闲置的routine)
runtime和C标准库起的作用是一样的。都是为了语言的跨平台性。runtime可以运行在Windows和Unix平台,可以运行在Intel或ARM处理器上。
clip_image001[4]
一个go程序都附带一个Runtime,runtime负责与底层操作系统交互。
这篇文章给了一个清晰的runtime概念:http://pastebin.com/LEsB8FVW
启动流程
回到$goroot/pkg/runtime/proc.c
里面这么个注释:
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
明确告诉我们go程序的启动流程是:
1 调用osinit,操作系统级别的初始化
2 调用runtime·schedinit
在这个函数内做了许多预操作
获取程序运行参数
获取程序环境变量
(主要是有一个环境变量GOMAXPROCS,你可以使用runtime.GOMAXPROCS(int) 或者直接设置环境变量$GOMAXPROCS改变程序使用的CPU数量)
3 调用runtime·mstart启动M
4 调用runtime·main
在runtime.main中有这么两行:
main·init(); //调用main包中的init函数
main·main(); //调用main包中的main函数
用gdb调试看trace看到调用栈
尽管 Go 编译器产生的是本地可执行代码,这些代码仍旧运行在 Go 的 runtime(这部分的代码可以在 runtime 包中找到)当中。这个 runtime 类似 Java 和 .NET 语言所用到的虚拟机,它负责管理包括内存分配、垃圾回收(第 10.8 节)、栈处理、goroutine、channel、切片(slice)、map 和反射(reflection)等等。
runtime 调度器是个非常有用的东西,关于 runtime 包几个方法:
Gosched:让当前线程让出 cpu 以让其它线程运行,它不会挂起当前线程,因此当前线程未来会继续执行
NumCPU:返回当前系统的 CPU 核数量
GOMAXPROCS:设置最大的可同时使用的 CPU 核数
Goexit:退出当前 goroutine(但是defer语句会照常执行)
NumGoroutine:返回正在执行和排队的任务总数
GOOS:目标操作系统
Go 运行时的核心代码就位于该 Repository 的 src/runtime 目录中,包含如下几个主要模块:
内存分配(malloc.go)
垃圾回收(mgc.go)
Goroutine 调度(proc.go)
Go 复合类型的实现(slice.go、hashmap.go、chan.go、error.go)
总体而言,阅读这些代码时应当不会在语言方面遇到太多的阻力,源文件中也有大量的注释解释每个模块所使用的算法,本文的大多数内容也源自这些注释。但是完全理解这些代码需要读者十分了解操作系统底层的系统调用和优化方法
Goroutine 调度
熟悉 Go 并发编程的人都了解,Go 以 Goroutine 作为执行调度单位
http://morsmachine.dk/go-scheduler
Go 内存分配
Go 运行时的内存分配算法主要源自 Google 为 C 语言开发的 TCMalloc 算法,全称 Thread-Caching Malloc。该算法的特色在于其将可用的堆内存采用二级分配的形式进行管理:每个线程都会自行维护一个独立的内存池,进行内存分配时优先从该内存池中分配,当内存池不足时才向全局内存池申请,以避免不同线程对全局内存池的频繁竞争。除此以外,该算法会对小对象和大对象采用不同的内存分配过程。
Go 运行时的内存分配算法在很大程度上与该算法保持一致。首先,Go 在为小对象(大小小于 32 KB)分配内存时会对对象的实际大小向上取整,将对象分类到大约 70 个不同大小的 Size Class 中,并按照 Size Class 的大小为对象分配空间。每个 Size Class 的具体数值系考虑各项约束后自动生成,最小的 Size Class 为 8B,最大为 32KB。详见 mksizeclasses.go 和 sizeclasses.go。
在明确这一概念后,我们便可以开始了解 Go 内存分配算法主要使用的数据结构了:
mheap:代表 Go 程序所持有的所有堆空间,可视为由若干个大小为 8 KB 的内存页组成的数组
mspan:一个 mspan 从属于某个指定的 Size Class,在 mheap 上占据若干个连续的内存页,其内部根据所属 Size Class 的大小被平均划分为若干个 object。每个 mspan 会使用一个 bitmap 来标记其内部尚可用的 object
mcache:Goroutine 本地缓存的可用 mspan,是上一节所提到的 P 的一部分
mcentral:全局可用的 mspan 列表。Goroutine 在需要时会从 mcentral 获取 mspan
如此一来,Go 运行时进行内存分配的过程就十分清晰了。当 Go 需要为小对象分配对象时,小对象会被向上取整至最近的 Size Class,并执行如下步骤:
从当前 P 的 mcache 中获取属于该 Class 且仍有空闲位置的 mspan
若 mcache 已空,则从 mcentral 获取一整个 mspan 到当前 P 的 mcache 中
若 mcentral 已空,则从 mheap 中获取若干个连续内存页,构建新的 mspan 并放入到 mcentral 中
若 mheap 已空,则从操作系统申请若干个内存页到 mheap 中
对于大对象而言,Go 则会跳过 mcache 和 mcentral,直接在 mheap 上构建一个合适大小的 mspan 进行分配
Go 垃圾回收
在了解了 Go 如何为对象分配内存后,我们便可以开始学习 Go 是如何进行垃圾回收的了。
当前 Go 的最新版本为 1.8.3,Go 采用的是并发、三色的标记 - 清除垃圾收集器。这个垃圾收集器在 Go 1.5 版的时候引入,并在当时将 Go 的 GC Pause 时间缩短到了 1.4 版的几百分之一。尽管做出了不少的修改,Go 的垃圾收集算法参考了 Dijkstra 在 1978 年写的论文:《On-the-Fly Garbage Collection: An Exercise in Cooperation》。
标记 - 清除算法可以说是最经典的垃圾回收算法。该算法的回收过程分为两个步骤:
标记:从 GC Root 对象开始,沿着对象中包含的所有指针递归地标记所有可达的对象。GC Root 对象包括所有在标记前便确定可达的对象,如全局变量、位于栈帧中的本地变量等
清除:在标记阶段结束后,未被标记的对象意味着不可达。清除阶段将清除所有未被标记的对象,释放它们所占用的内存。
标记 - 清除算法作为最经典也是最基础的算法存在着它的不足,最主要的不足在于它在清除阶段会对未被标记的对象原地进行释放,被释放对象所留下的空隙便形成了内存碎片,而内存碎片的存在会导致程序的内存空间利用率下降。
实际上,Go 所谓的并发、三色的标记 - 清除垃圾收集算法并不新鲜,JVM 和 V8 中都有类似的收集算法。在 JVM 中,该收集器被称为 CMS 收集器(Concurrent Mark-Sweep)。JVM 的 CMS 收集器执行过程与 Go 的收集器类似,也有着和 Go 的收集器相似的特性:以降低程序计算吞吐量为代价,减少 GC Pause 的时间。
Go 垃圾收集器的一次收集过程可归纳为如下几个步骤:
_GcOff:两次 GC 间,Go 程序将处于 _GcOff 状态。GC 发生的过程中会把所有处于 mcache 中的 mspan 放回 mcentral,以让 Goroutine 申请内存时需要重新从 mcentral 获取 mspan。Goroutine 获取 mspan 时会 lazy 地清除 mspan 中在上一次 GC 中未被标记的对象。除此以外,另一个 GC Bg Worker Goroutine 也会主动地清扫未被清扫地 mspan;
清除终止:开始 GC 前的准备工作。此时程序会 Stop the world,并清扫所有仍未被清扫的 mspan。通常 GC 会在程序的内存占用达到一定阈值时被触发,通常此时应当已经不存在仍未被清扫的 mspan。若此次 GC 是由 runtime.GC() 等方式手动触发的则情况可能有所不同;
_GcMark:标记阶段。此时 Go 收集器会利用之前开启的 Stop the world,为所有用户 Goroutine 启动写屏障(Write Barrier)。然后,Go 收集器会把 GC Root 对象的标记工作放入到标记作业队列(置为灰色)。之后 Go 收集器便会恢复用户 Goroutine 的执行。开启了写屏障的 Goroutine 在每次修改指针变量的值时会使得新旧指针指向的对象均被置为灰色,而新创建的对象这会直接被置为黑色(已标记)。除此以外,位于后台运行的 Mark Worker Goroutine 会开始从标记作业队列中获取颜色为灰色的对象,对其进行标记(置为黑色),并将其指向的其他结点置为灰色(放入标记作业队列),直到作业队列被耗尽;
_GcMarkTermination:标记阶段的收尾工作。Stop the world,并完成队列中剩余的标记作业。通常此时队列已为空。完成标记作业后将继续完成其他 GC 收尾工作,如将 Goroutine mcache 中的 mspan 放回到 mcentral;
_GcOff:GC 结束,恢复用户 Goroutine 的执行,由用户 Goroutine 和 GC Worker Goroutine 对 mspan 中未被标记的对象进行回收
比较无奈的是,Go 现在所采用的垃圾回收算法存在着一定的不足。原因主要在于 Go 没有对堆中的对象进行分代,每次 GC 发生时都需要对堆中的所有对象进行标记工作,因此标记的工作量将与堆的大小呈线性相关。Go 的垃圾回收算法的目标是降低 GC Pause 时间,但需要做的工作并不会因为 GC Pause 变短而消失不见,因此在这种情况下,Go 的 GC Bg Mark Worker 可能会占用不少的计算资源来完成全堆的标记工作
runtime
Package runtime contains operations that interact with Go’s runtime system, such as functions to control goroutines. It also includes the low-level type information used by the reflect package; see reflect’s documentation for the programmable interface to the run-time type system.
上面是官方文档的介绍,我们看到几个关键字:
runtime system
control goroutines
low-level information
golang程序并没有像java一样自带虚拟机,而是和c类似。
每一个go程序都带有一个runtime,runtime负责和底层操作系统交互。
一个go程序运行所经过的几个主要步骤:
调用osinit,操作系统级别的初始化
调用runtime·schedinit(获取程序运行参数、获取程序环境变量)
调用runtime·mstart启动M(在runtime中定义的数据结构)
调用runtime·main
runtime实现比较复杂,在这里我们使用网上的一张图片
golang 是一门较为简单的语言,简单的语言并不代表不是优秀的语言。golang主要有三个feature。
协程(进程 线程)
进程:
进程是“程序执行的一个实例” ,担当分配系统资源的实体。进程创建必须分配一个完整的独立地址空间。
进程切换只发生在内核态,
线程:线程是进程的一个执行流,独立执行它自己的程序代码。
协程:协程不是进程或线程,其执行过程更类似于子例程,或者说不带返回值的函数调用。
在语言级别可以创建并发协程,然后编写代码去进行管理。go将这一步承包下来,使协程并发运行成本更低。
channel
channel是Go语言在语言级别提供的goroutine间的通信方式。我们可以使用channel在两个或 多个goroutine之间传递消息。
channel 会某种情况下出现阻塞,通过控制channel的阻塞来管理协程的并发与流程控制。
interface
非侵入式接口。golang则采取了完全不同的设计理念,在Go语言中,一个类只需要实现了接口要求的所有函数,我们就说这个类实现了该接口
golang不支持完整的面向对象思想,它没有继承,多态则完全依赖接口实现。golang只能模拟继承,其本质是组合
main.go及其汇编码
一个main函数
package main
import (
“fmt”
“time”
)
func mikk() {
fmt.Println(“kk”)
}
func main() {
fmt.Println(“hello”)
// go mikk()
mikk()
time.Sleep(1000 * 1000)
}
上面的代码是一个比较简单的main函数,不赘述。关键的地方,在于go mikk()和mikk()这两行,如果代码使用mikk()而注释go mikk()(正如当前代码所示),那么就只有一个goroutine;反之,则通过go关键字把mikk()放到了另一个goroutine运行。
汇编main函数
我们可以通过下面的指令把main.go进行汇编,生成相应的汇编文件main.S。
go tool compile -S main.go > main.S
对比
当使用mikk()的时候,得到的汇编片段如下:
0x0058 00088 (main.go:12) CALL fmt.Println(SB)
0x005d 00093 (main.go:14) PCDATA $0, $0
0x005d 00093 (main.go:14) CALL "".mikk(SB)
0x0062 00098 (main.go:15) MOVQ $1000000, (SP) 当使用go mikk()的时候,得到的汇编片段如下:
0x0058 00088 (main.go:12) CALL fmt.Println(SB)
0x005d 00093 (main.go:13) MOVL $0, (SP)
0x0064 00100 (main.go:13) LEAQ "".mikk·f(SB), AX
0x006b 00107 (main.go:13) MOVQ AX, 8(SP)
0x0070 00112 (main.go:13) PCDATA $0, $0
0x0070 00112 (main.go:13) CALL runtime.newproc(SB)
0x0075 00117 (main.go:14) MOVQ $1000000, (SP) 简单说明一下: "". 代表的是这个函数的命名空间,SB是个伪寄存器,全名为Static Base,代表对应函数的地址
通过对比可以发现,如果没有使用go关键词,会直接调用mikk(SB)函数;如果使用了go关键词,会调用runtime.newproc(SB)函数。
通过查看runtime.newproc(SB)的源码func newproc(siz int32, fn *funcval),我们可以知道这个函数需要两个参数,一个是参数个数,一个是方法地址,在汇编代码中分别通过MOVL $0, (SP)和MOVQ AX, 8(SP)实现的,0个参数,AX地址所指向的函数。
runtime.newproc
通过查看go/proc.go源码中的newproc主要调用了newproc1函数。这里会把调用方(caller)所在的goroutine和pc作为参数传给newproc1 。
func newproc(siz int32, fn funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
systemstack(func() {
newproc1(fn, (uint8)(argp), siz, gp, pc)
})
}
创建goroutine的工作大部分在newproc1中完成。它会首先从freeG列表中尝试获取一个free的goroutine(重复利用资源,可以减少malloc的次数,降低时间消耗),只有获取不到的时候才会重新在堆栈中搞一块新的内存并初始化gouroutine。
把goroutine的栈初始化,并把各项属性设置适当的值以后,就可以把这个goroutine加入到当前P的G队列了。
// 创建一个新的goroutine运行fn,参数开始于argp,共有narg个字节
// 最后把创建的g放到g队列等待运行
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
// 获得当前的G
g := getg()
…
// 从P的freeG队列中拿一个G
p := g.m.p.ptr()
newg := gfget(p)
…
// 将G加入P的runnable G队列
runqput(p, newg, true)
…
}
