hystrix
https://github.com/afex/hystrix-go/
分布式系统中经常会出现某个基础服务不可用造成整个系统不可用的情况, 这种现象被称为服务雪崩效应. 为了应对服务雪崩, 一种常见的做法是手动服务降级. 而Hystrix的出现,给我们提供了另一种选择.
我把服务雪崩的参与者简化为 服务提供者 和 服务调用者, 并将服务雪崩产生的过程分为以下三个阶段来分析形成的原因:
服务提供者不可用
重试加大流量
服务调用者不可用
服务雪崩的每个阶段都可能由不同的原因造成, 比如造成 服务不可用 的原因有:
硬件故障
程序Bug
缓存击穿
用户大量请求
硬件故障可能为硬件损坏造成的服务器主机宕机, 网络硬件故障造成的服务提供者的不可访问.
缓存击穿一般发生在缓存应用重启, 所有缓存被清空时,以及短时间内大量缓存失效时. 大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用.
在秒杀和大促开始前,如果准备不充分,用户发起大量请求也会造成服务提供者的不可用.
而形成 重试加大流量 的原因有:
用户重试
代码逻辑重试
在服务提供者不可用后, 用户由于忍受不了界面上长时间的等待,而不断刷新页面甚至提交表单.
服务调用端的会存在大量服务异常后的重试逻辑.
这些重试都会进一步加大请求流量.
最后, 服务调用者不可用 产生的主要原因是:
同步等待造成的资源耗尽
当服务调用者使用 同步调用 时, 会产生大量的等待线程占用系统资源. 一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了.
服务雪崩的应对策略
针对造成服务雪崩的不同原因, 可以使用不同的应对策略:
流量控制
改进缓存模式
服务自动扩容
服务调用者降级服务
流量控制 的具体措施包括:
网关限流
用户交互限流
关闭重试
因为Nginx的高性能, 目前一线互联网公司大量采用Nginx+Lua的网关进行流量控制, 由此而来的OpenResty也越来越热门.
用户交互限流的具体措施有: 1. 采用加载动画,提高用户的忍耐等待时间. 2. 提交按钮添加强制等待时间机制.
改进缓存模式 的措施包括:
缓存预加载
同步改为异步刷新
服务自动扩容 的措施主要有:
AWS的auto scaling
服务调用者降级服务 的措施包括:
资源隔离
对依赖服务进行分类
不可用服务的调用快速失败
资源隔离主要是对调用服务的线程池进行隔离.
我们根据具体业务,将依赖服务分为: 强依赖和若依赖. 强依赖服务不可用会导致当前业务中止,而弱依赖服务的不可用不会导致当前业务的中止.
不可用服务的调用快速失败一般通过 超时机制, 熔断器 和熔断后的 降级方法 来实现.
使用Hystrix预防服务雪崩
Hystrix [hɪst’rɪks]的中文含义是豪猪, 因其背上长满了刺,而拥有自我保护能力. Netflix的 Hystrix 是一个帮助解决分布式系统交互时超时处理和容错的类库, 它同样拥有保护系统的能力.
Hystrix的设计原则包括:
资源隔离
熔断器
命令模式
资源隔离
货船为了进行防止漏水和火灾的扩散,会将货仓分隔为多个
这种资源隔离减少风险的方式被称为:Bulkheads(舱壁隔离模式).
Hystrix将同样的模式运用到了服务调用者上.
在一个高度服务化的系统中,我们实现的一个业务逻辑通常会依赖多个服务,比如:
商品详情展示服务会依赖商品服务, 价格服务, 商品评论服务.
调用三个依赖服务会共享商品详情服务的线程池. 如果其中的商品评论服务不可用, 就会出现线程池里所有线程都因等待响应而被阻塞, 从而造成服务雪崩.
Hystrix通过将每个依赖服务分配独立的线程池进行资源隔离, 从而避免服务雪崩.
当商品评论服务不可用时, 即使商品服务独立分配的20个线程全部处于同步等待状态,也不会影响其他依赖服务的调用
熔断器模式
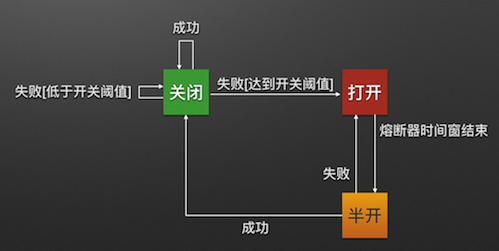
熔断器模式定义了熔断器开关相互转换的逻辑:
服务的健康状况 = 请求失败数 / 请求总数.
熔断器开关由关闭到打开的状态转换是通过当前服务健康状况和设定阈值比较决定的.
当熔断器开关关闭时, 请求被允许通过熔断器. 如果当前健康状况高于设定阈值, 开关继续保持关闭. 如果当前健康状况低于设定阈值, 开关则切换为打开状态.
当熔断器开关打开时, 请求被禁止通过.
当熔断器开关处于打开状态, 经过一段时间后, 熔断器会自动进入半开状态, 这时熔断器只允许一个请求通过. 当该请求调用成功时, 熔断器恢复到关闭状态. 若该请求失败, 熔断器继续保持打开状态, 接下来的请求被禁止通过.
熔断器的开关能保证服务调用者在调用异常服务时, 快速返回结果, 避免大量的同步等待. 并且熔断器能在一段时间后继续侦测请求执行结果, 提供恢复服务调用的可能.
命令模式
Hystrix使用命令模式(继承HystrixCommand类)来包裹具体的服务调用逻辑(run方法), 并在命令模式中添加了服务调用失败后的降级逻辑(getFallback).
同时我们在Command的构造方法中可以定义当前服务线程池和熔断器的相关参数. 如下代码所示:
public class Service1HystrixCommand extends HystrixCommand
private Service1 service;
private Request request;
public Service1HystrixCommand(Service1 service, Request request){
supper(
Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey(“ServiceGroup”))
.andCommandKey(HystrixCommandKey.Factory.asKey(“servcie1query”))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey(“service1ThreadPool”))
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(20))//服务线程池数量
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withCircuitBreakerErrorThresholdPercentage(60)//熔断器关闭到打开阈值
.withCircuitBreakerSleepWindowInMilliseconds(3000)//熔断器打开到关闭的时间窗长度
))
this.service = service;
this.request = request;
);
}
@Override
protected Response run(){
return service1.call(request);
}
@Override
protected Response getFallback(){
return Response.dummy();
}
}
在使用了Command模式构建了服务对象之后, 服务便拥有了熔断器和线程池的功能.
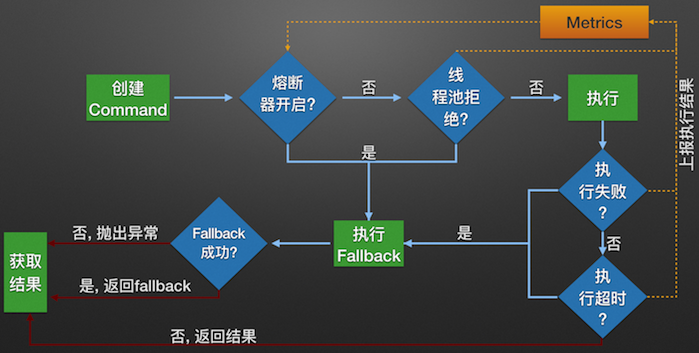
构建Hystrix的Command对象, 调用执行方法.
Hystrix检查当前服务的熔断器开关是否开启, 若开启, 则执行降级服务getFallback方法.
若熔断器开关关闭, 则Hystrix检查当前服务的线程池是否能接收新的请求, 若超过线程池已满, 则执行降级服务getFallback方法.
若线程池接受请求, 则Hystrix开始执行服务调用具体逻辑run方法.
若服务执行失败, 则执行降级服务getFallback方法, 并将执行结果上报Metrics更新服务健康状况.
若服务执行超时, 则执行降级服务getFallback方法, 并将执行结果上报Metrics更新服务健康状况.
若服务执行成功, 返回正常结果.
若服务降级方法getFallback执行成功, 则返回降级结果.
若服务降级方法getFallback执行失败, 则抛出异常.
Hystrix Metrics的实现
Hystrix的Metrics中保存了当前服务的健康状况, 包括服务调用总次数和服务调用失败次数等. 根据Metrics的计数, 熔断器从而能计算出当前服务的调用失败率, 用来和设定的阈值比较从而决定熔断器的状态切换逻辑. 因此Metrics的实现非常重要.
1.4之前的滑动窗口实现
Hystrix在这些版本中的使用自己定义的滑动窗口数据结构来记录当前时间窗的各种事件(成功,失败,超时,线程池拒绝等)的计数.
事件产生时, 数据结构根据当前时间确定使用旧桶还是创建新桶来计数, 并在桶中对计数器经行修改.
这些修改是多线程并发执行的, 代码中有不少加锁操作,逻辑较为复杂.
1.5之后的滑动窗口实现
Hystrix在这些版本中开始使用RxJava的Observable.window()实现滑动窗口.
RxJava的window使用后台线程创建新桶, 避免了并发创建桶的问题.
同时RxJava的单线程无锁特性也保证了计数变更时的线程安全. 从而使代码更加简洁.
以下为我使用RxJava的window方法实现的一个简易滑动窗口Metrics, 短短几行代码便能完成统计功能,足以证明RxJava的强大:
@Test
public void timeWindowTest() throws Exception{
Observable
source.window(1, TimeUnit.SECONDS).subscribe(window -> {
int[] metrics = new int[2];
window.subscribe(i -> metrics[i]++,
InternalObservableUtils.ERROR_NOT_IMPLEMENTED,
() -> System.out.println("窗口Metrics:" + JSON.toJSONString(metrics)));
});
TimeUnit.SECONDS.sleep(3);
}
熔断器为资源和失败率提供更多的控制。断路器被设计为在不等待TCP连接超时的情况下快速而优雅地处理错误。这种快速失败机制将保护下游服务。这个机制最重要的部分是熔断器能够快速对下游服务作出一些响应。线程池不会因为慢请求而阻塞,没有超时,而且也可能会给终端用户更有意义的返回数据。熔断器也给了下游服务足够的时间恢复正常。完全避免报错是很困难的,但是减少错误的影响完全可行。
在熔断器里面有3种主要的状态:
关闭:让请求通过的默认状态。如果请求成功/失败但低于阈值,则状态保持不变。可能出现的错误是超过最大并发数和超时错误。
打开:当熔断器打开的时候,所有的请求都会被标记为失败;这是故障快速失败机制,而不需要等待超时时间完成。
半开:定期的尝试发起请求来确认系统是否恢复。如果恢复了,熔断器将转为关闭状态或者保持打开。
理论上的熔断器
这里有5个控制熔断设置的主要参数。
阀值可以从两个服务的SLA中得到。当测试服务与其它依赖的稳定性时,这些值应该合理设置。
一个好的熔断器命名应该指明相应的服务连接报错了。实际上,你可能有许多API endpoint在同一个服务。所以针对每个API endpoint需要配置单独的熔断器。
生产环境的熔断器
一个熔断器通常被部署在多个节点。即使熔断器提供一个快速报错机制,我们依然需要确认备用的降级逻辑是生效的。因为我们觉得这是一个小概率事件而不测试对应的降级策略是冒险的行为。在最简单的运行中,我们也需要确定阀值是合理的。从我的个人经历来说,在日志里面打印出配置参数将让调试更加简单。
状态转换逻辑
初始为closed状态,一旦遇到请求失败时,会触发熔断检测(见下方的 ShouldTrip),熔断检测来决定是否将状态从closed转为open。
当熔断器为open状态时,会熔断所有当前服务要发出去的请求,直到冷却时间(见下方的CoolingTimeout)结束,会从open转变为half-open状态。
当熔断器为half-open状态时,以检测时间(见下方的 DetectTimeout)为周期去发送请求。请求成功则计数器加1,当计数器达到一定阈值时则转为closed状态;请求失败则转为open状态。
熔断器内部数据结构
type Breaker struct {
Container // contains all success, error and timeout
sync.RWMutex
state State
openTime time.Time // the time when the breaker become OPEN
lastRetryTime time.Time // last retry time when in HALFOPEN state
halfopenSuccess int // consecutive successes when HALFOPEN
options Options
now func() time.Time }
Breaker是暴露在最外层的struct,由以下属性组成:
Container:是一个interface,被 window 实现,负责熔断器请求失败,成功的相关计算和统计
RW锁:在http-gateway中,针对每个cmd有一个熔断器,每个 cmd 同时会有多个goroutine并发请求,需要RW锁来保持熔断器中计数器,状态等等的同步
state:熔断器三种状态,closed,open 和 half-open
openTime:当熔断器变为 open 状态时,记录下的时间
lastRetryTime:在 half-open 状态时,会有个检测周期,即每隔这个周期之后,熔断器会放请求出去,同时更新这个 lastRetryTime。
halfopenSuccess:在 half-open状态时,当请求成功时,halfopenSuccess 会+1,当 halfopenSuccess 等于一个阈值时(默认为2),则变为 closed 状态
options:Breaker 的配置项,包括桶持有数量持有时间,冷却时间,检测周期,熔断检测回调和状态变化回调等等
// Options for Breaker
type Options struct {
// parameters for container
BucketTime time.Duration // the time each bucket holds
BucketNums int // the number of buckets the breaker have
// parameters for breaker
BreakerRate float64
BreakerMinQPS int // when instance > 1, if qps is over this value, the breaker trip will work
BreakerMinSamples int // for RateTrip callback
CoolingTimeout time.Duration // fixed when create
DetectTimeout time.Duration // fixed when create
HalfOpenSuccess int
ShouldTrip TripFunc // trip callback, default is RateTrip func
StateChangeHandler StateChangeHandler
now func() time.Time }
options是Breaker的配置项,有以下属性组成:
BucketTime:桶的在线时间
BucketNums:window下持有桶的数量
BrekaerRate:熔断检测回调RateTrip的阈值
BreakerMinQPS:当实例数量大于1时,并且开启了动态策略时,用于计算BreakerMinSamples
BreakerMinSamples:最小采样数,配合RateTrip熔断检测回调使用
CoolingTimeout:保持 open 状态直到冷却时间结束,会从 open 转变为 half-open 状态,默认为5秒
DetectTimeout:half-open 状态时,每隔这个周期之后,熔断器会放请求出去
HalfOpenSuccess:half-open状态变为closed状态的判断指标
ShouldTrip:熔断检测回调,为nil则代表不启用熔断功能
StateChangeHandler:状态变化回调
type window struct {
sync.Mutex
oldest int // oldest bucket index
latest int // latest bucket index
buckets []*bucket // buckets this window has
bucketTime time.Duration // time each bucket holds
bucketNums int // the largest number of buckets of window could have
expireTime time.Duration // expire time of this window, equals to window size
inWindow int // the number of buckets in the window currently
conseErr int64 //consecutive errors }
window负责熔断器请求失败,成功的相关计算和统计,有以下属性组成:
互斥锁:保证内部数据同步
oldest:最老的桶,由 latest 桶变化而来,用于窗口下所有请求结果的存储
latest:最新的桶,每次统计请求结果时,用最新的桶来存储
buckets:所有桶
bucketTime:latest 桶的在线时间,一旦 latest 桶下线,则变为 oldest 桶
bucketNums:窗口最大持有桶的数量
expireTime:oldest 桶的过期时间,一旦 oldest 桶过期,则从 window 中“移去”,expireTime = bucketTime*bucketNums
inWindow:窗口当下持有桶的数量
conseErr:连续错误数量,每次请求结果为成功时便清零
熔断检测回调:
ThresholdTripFunc:当失败和超时的总数超过阈值,则熔断
ConsecutiveTripFunc:当连续错误总数(conseErr)超过阈值,则熔断
RateTripFunc:当窗口内请求总数大于最小采样数且错误率(失败+超时数量/请求总数)大于一定值时,则熔断
api
InitCircuitBreakers方法作为初始化熔断器使用,这里用cmd来区分各个breaker
BreakerWhitelist 可以配置熔断白名单,在白名单中的cmd不参与熔断
IsTriggerBreaker 判断当前cmd的熔断器的状态,并告诉上层
实现原理讲起来很简单,其实就是不让客户端“裸调“服务器的rpc接口,而是在客户端包装一层。就在这个包装层里面,实现熔断逻辑。
HystrixCommand是被扔到一个线程中执行的,也就是说,缺省是线程隔离策略。
还有一种策略就是不搞线程池,直接在调用者线程中执行,也就是信号量的隔离策略。
熔断的参数配置
Hystrix提供了如下的几个关键参数,来对一个熔断器进行配置:
circuitBreaker.requestVolumeThreshold //滑动窗口的大小,默认为20
circuitBreaker.sleepWindowInMilliseconds //过多长时间,熔断器再次检测是否开启,默认为5000,即5s钟
circuitBreaker.errorThresholdPercentage //错误率,默认50%
3个参数放在一起,所表达的意思就是:
每当20个请求中,有50%失败时,熔断器就会打开,此时再调用此服务,将会直接返回失败,不再调远程服务。直到5s钟之后,重新检测该触发条件,判断是否把熔断器关闭,或者继续打开。
服务降级
有了熔断,就得有降级。所谓降级,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。
这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强,当然这也要看适合的业务场景。
服务限流
比如在Hystrix中,如果是线程隔离,可以通过线程数 + 队列大小限制;如果是信号量隔离,可以设置最大并发请求数。
另外一个常见的策略就是根据QPS限制,比如我知道我调用的一个db服务,qps是3000,那如果不限制,超过3000,db就可能被打爆。这个时候,我可用在服务端做这个限流逻辑,也可以在客户端做。
现在一般成熟的RPC框架,都有参数直接设置这个。
还有一些场景下,可用限制总数:比如连接数,业务层面限制“库存“总量等等。。
限流的技术原理 -令牌桶算法
关于限流的原理,相信很多人都听说过令牌桶算法,Guava的RateLimiter也已经有成熟做法,这个自己去搜索之。
此处想强调的是,令牌桶算法针对的是限制“速率“。至于其他限制策略,比如限制总数,限制某个业务量的count值,则要具体业务场景具体分析。
异步RPC
异步RPC主要目的是提高并发,比如你的接口,内部调用了3个服务,时间分别为T1, T2, T3。如果是顺序调用,则总时间是T1 + T2 + T3;如果并发调用,总时间是Max(T1,T2,T3)。
当然,这里有1个前提条件,这3个调用直接,互相不依赖。
同样,一般成熟的RPC框架,本身都提高了异步化接口,Future或者Callback形式。
https://go-chassis.readthedocs.io/en/v0.6/user-guides/cb-and-fallback.html
