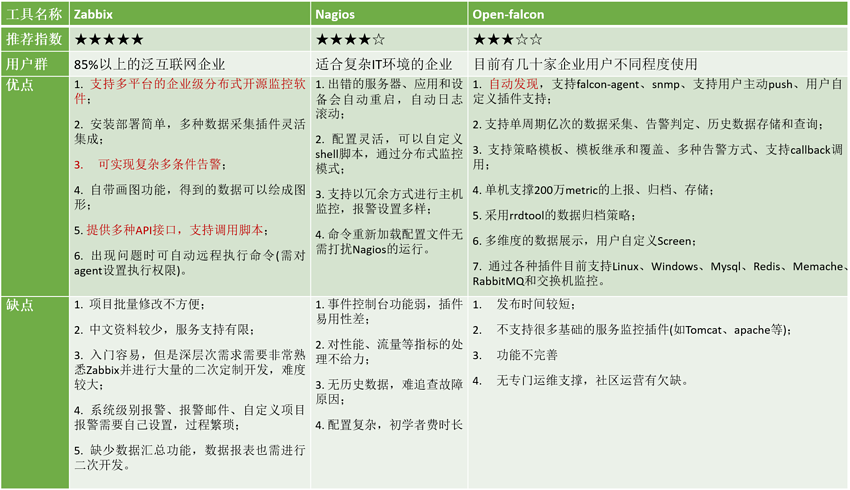
openfalcon
1、监控系统,可以从运营级别(基本配置即可),以及应用级别(二次开发,通过端口进行日志上报),对服务器、操作系统、中间件、应用进行全面的监控,及报警,对我们的系统正常运行的作用非常重要。
2、基础监控
CPU、Load、内存、磁盘、IO、网络相关、内核参数、ss 统计输出、端口采集、核心服务的进程存活信息采集、关键业务进程资源消耗、NTP offset采集、DNS解析采集,这些指标,都是open-falcon的agent组件直接支持的。
Linux运维基础采集项:http://book.open-falcon.org/zh/faq/linux-metrics.html
对于这些基础监控选项全部理解透彻的时刻,也就是对Linux运行原理及命令进阶的时刻。
3、第三方监控
术业有专攻,运行在OS上的应用甚多,Open-Falcon的开发团队不可能把所有的第三方应用的监控全部做完,这个就需要开源社区提供更多的插件,当前对于很多常用的第三方应用都有相关插件了。
4、JVM监控
对于Java作为主要开发语言的大多数公司,对于JVM的监控不可或缺。
每个JVM应用的参数,比如GC、类加载、JVM内存、进程、线程,都可以上报给Falcon,而这些参数的获得,都可以通过MxBeans实现。
使用 Java 平台管理 bean:http://www.ibm.com/developerworks/cn/java/j-mxbeans/
5、业务应用监控
对于业务需要监控的接口,比如响应时间等。可以根据业务的需要,上报相关数据到Falcon,并通过Falcon查看结果。
https://github.com/open-falcon/falcon-plus
特点:
数据采集免配置:agent自发现、支持Plugin、主动推送模式
容量水平扩展:生产环境每秒50万次数据收集、告警、存储、绘图,可持续水平扩展。
告警策略自发现:Web界面、支持策略模板、模板继承和覆盖、多种告警方式、支持回调动作。
告警设置人性化:支持最大告警次数、告警级别设置、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期,支持告警合并。
历史数据高效查询:秒级返回上百个指标一年的历史数据。
Dashboard人性化:多维度的数据展示,用户自定义Dashboard等功能。
架构设计高可用:整个系统无核心单点,易运维,易部署
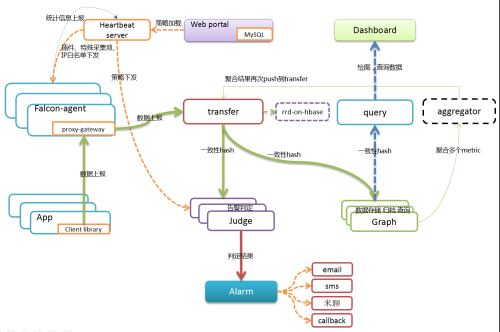
架构图:
https://github.com/open-falcon-archive/agent
Open-Falcon,采用和 OpenTSDB 相似的数据格式:metric、endpoint 加多组 key value tags,举两个例子:
{
metric: load.1min,
endpoint: open-falcon-host,
tags: srv=falcon,idc=aws-sgp,group=az1,
value: 1.5,
timestamp: date +%s,
counterType: GAUGE,
step: 60
}
{
metric: net.port.listen,
endpoint: open-falcon-host,
tags: port=3306,
value: 1,
timestamp: date +%s,
counterType: GAUGE,
step: 60
}
下面是一段 Python 上报数据的代码,其中涉及到的参数都是必须传的。
#!-- coding:utf8 --
import requests
import time
import json
ts = int(time.time())
payload = [
{
“endpoint”: “test-endpoint”,
“metric”: “test-metric”,
“timestamp”: ts,
“step”: 60,
“value”: 1,
“counterType”: “GAUGE”,
“tags”: “idc=lg,loc=beijing”,
},
{
"endpoint": "test-endpoint",
"metric": "test-metric2",
"timestamp": ts,
"step": 60,
"value": 2,
"counterType": "GAUGE",
"tags": "idc=lg,loc=beijing",
}, ]
r = requests.post(“http://127.0.0.1:1988/v1/push”, data=json.dumps(payload))
print r.text
metric: 最核心的字段,监控指标名称,代表这个采集项具体度量的是什么,比如是 cpu_idle 呢,还是 memory_free, 还是 qps
endpoint: 标明 Metric 的主体(属主),比如 metric 是 cpu_idle,那么 Endpoint 就表示这是哪台机器的 cpu_idle,一般使用机器的 hostname
timestamp: 表示上报该数据时的 unix 时间戳,注意是整数,代表的是秒
value: 代表该 metric 在当前时间点的值,float64
step: 表示该数据采集项的上报周期,这对于后续的配置监控策略很重要,必须明确指定。
counterType: 是 Open Falcon 定义的数据类型,取值只能是COUNTER或者GAUGE二选一,前者表示该数据采集项为计时器类型,后者表示其为原值 (注意大小写)
- GAUGE:即用户上传什么样的值,就原封不动的存储
- COUNTER:指标在存储和展现的时候,会被计算为 speed,即(当前值 - 上次值)/ 时间间隔
tags: 监控数据的属性标签,一组逗号分割的键值对,对 metric 进一步描述和细化,可以是空字符串。比如 idc=lg,比如 service=xbox 等,多个 tag 之间用逗号分割
说明:这 7 个字段都是必须指定
然后仔细查看文档之后,发现 OpenFalcon 有一个 Nodata 配置,Nodata 的配置正好解决了上面的需求,当机器一段时间内中断上报时,Nodata 配置会上报一个指定的值,然后报警函数就能够根据 Nodata 上报的值来报警。
Nodata 的配置在 OpenFalcon 的后台,在 Nodata 页面添加 Nodata ,填写
name nodata 的名字,标示什么中断了
endpoint 选择 Endpoint ,机器列表,一行一个
metric 指定 metric
tags 指定 tags
type 暂时只支持 GAUGE
周期 秒,与原始监控指标一致
上报中断时补发值
当自定义上报中断的时候 Nodata 就会补发,通过补发的值,比如正常的取值是 >0 的正数值,那么补发的值可以写上 -1 ,然后通过最近连续的三个 -1 来触发报警。
https://github.com/open-falcon/falcon-plus/blob/master/README.md
https://github.com/open-falcon/falcon-plus
