json
go-simplejson,用来封装与解析匿名的JSON,说白了就是用map或者slice等来解析JSON,用的Golang自带的encoding/json库去做的解析
#JSON value
一个完整的JSON应该包含一个value,这个value的类型可能是null,true,false,number,string, array以及 object共6种。而array和object还有可能包含子value结构。这些类型的值映射到Golang当中,便是nil, bool, bool, int64/float64, string, []interface{}, map[string]interface{},用一个union结构便可以搞定。注意这里的number有可以转换成整数或者是浮点数,在JavaScript中,全部用64位双精度浮点数储存,所以最大的精确整数也就是非规约数是尾数部分2^53 - 1,已经远远大于int32了,所以这里将整数映射成了int64而不是int,因为在部分机器上可能溢出,严格的区分一个IEEE-754格式的整数和浮点数并不是一件轻松的事情
定义一个结构来保存一个JSON的value:
type struct Value {
value interface{}
}
结构中的value字段保存这个JSONValue的实际值,通过类型判定来确定其类型。因此会有很多的判定,赋值,以及取值函数,比如针对一个string类型的Value需要有判定是否为string的操作IsString(),赋值AsString(),以及获取真实值的操作String():
// 判定是否为string,如果是,则返回true,否则返回false
func (v *Value) IsString() bool {
if _, ok := v.value.(string); ok {
return true
}
return false
}
// 将一个Value赋值为一个string
func (v *Value) AsString(value string) {
v.value = value
}
// 从一个string类型的Value中取出String值
func (v *Value) String() string {
if value, ok := v.value.(string); ok {
return value
}
// 如果不是一个string类型,则报错,所以需要先判定是否为string类型
panic(“not a string value”)
}
#JSON parser
对于string, true, false, null, number这样的值,都属于字面量,即没有深层结构,可取直接读取,并且中间不可能被空白字符切断,所以可以直接读取。而对于一个array或者object,则是一个多层的树状结构。最直接的想法肯定是用递归,但是大家都知道这是不可行的,因为在解析大JSON的时候很可能栈溢出了,所以只能用栈+迭代的办法。
AST分析的时候首先要分析Token,然后再分析AST,在解析JSON的时候也应该这样,虽然Token比较少:只有几个字面量以及{, [, :, ], }几个界定符。
因为JSON是一棵树,其解析过程是从树根一直遍历到各个叶节点再返回树根的过程。自然就会涉及到栈的压入及弹出操作。具体来讲,就是在遇到array和object的子节点的时候要压入栈,遇到一个value的结束符的时候要弹出栈。同时还要保存栈结点对应的Value以及其状态信息。
一个栈结点结构:
type struct state {
state int
value *Value
parent *state
}
state表示当前栈节点的状态,value表示其所代表的值parent表示其父节点,根节点的父节点为nil。当要压入栈时,只需要新建一个节点,将其parent设置为当前节点即可,要弹出时,将当前结点设置为当前结点的parent。如果当前节点为nil,则表示遍历结束,JSON自身也应该结束,除了空白字符外,不应该还包含任何字符。
一个节点可能的状态有:
const (
// start of a value
stateNone = iota
stateString
// after [ must be a value or ]
stateArrayValueOrEnd
// after a value, must be a , or ]
stateArrayEndOrComma
// after a {, must be a key string or }
stateObjectKeyOrEnd
// after a key string must be a :
stateObjectColon
// after a : must be a value
// after a value, must be , or }
stateObjectEndOrComma
// after a , must be key string
stateObjectKey
)
对于状态stateArrayValueOrEnd表示当前栈节点遇到了一个array的起始标志[,在等待一个子Value或者一个array的结束符],而状态stateArrayEndOrComma表示一个array已经遇到了子Value,在等待结束符]或者Value的分隔符,。因此,在解析一个数组的时候,完整的栈操作过程是:遇到[,将当前结点的状态设置为stateArrayValueOrEnd,然后过滤空白字符,判定第一个字符是]还是其它字符,如果是],则array结束,弹出栈,如果不是,则将自身状态修改为stateArrayEndOrComma,并压入一个新栈结点,将其状态设置为stateNone,重新开始解析,此结点解析完成之后,弹出此结点,判定是,还是],如果是],则结束弹出,如果是,则不改变自身状态,并重新一个新栈结点,开始新的循环。完事的状态机如下:
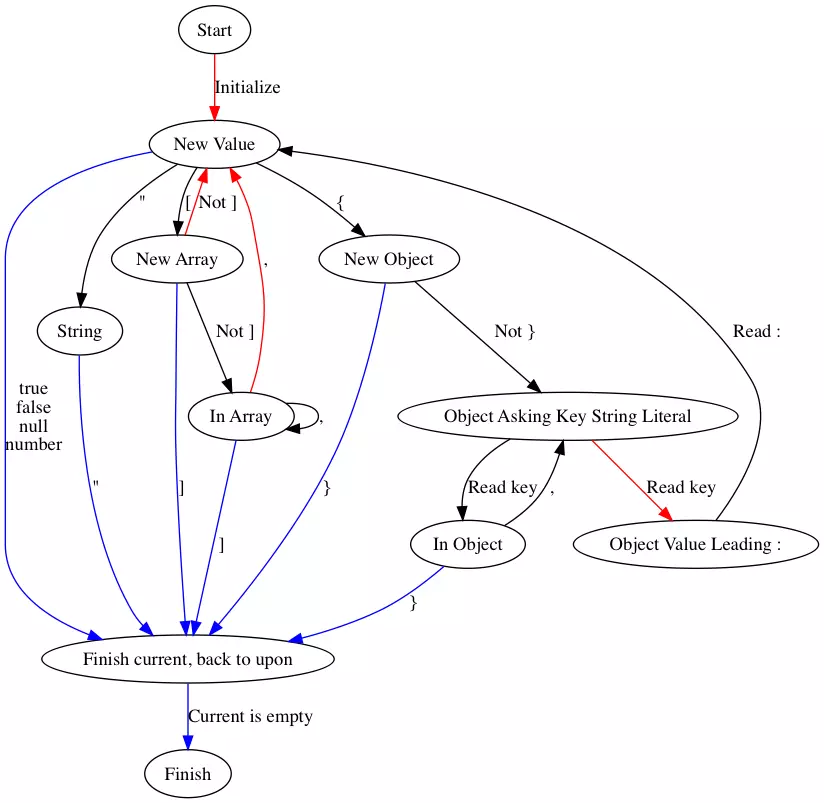
首先初始化一个空节点,状态设置为stateNone,然后判断第一个非空字符,如果是t/f/n/[-0-9],则直接解析字面量,然后弹出,如果是[,则将状态设置为stateArrayValueOrEnd,然后判定第一个字符,如果是],则结束弹出,否则压入新栈,并将自身状态设置为stateArrayEndOrComma,开始新的循环,如果是{,则将状态设置为stateObjectKeyOrEnd,如果下一个非空字符为},则结束弹出,否则解析key,完成之后,压入新栈,并将自身状态设置为stateObjectEndOrComma。
比较特殊的是stateString,按道理其也是一个字面量,不需要到一个新的循环里面去解析。但是因为一个object的key也是一个string,为了复用代码,并避免调用函数产生的性能开销,将string类型和object的key当作同一类型来处理,具体如下:
root := &state{&Value{nil}, stateNone, nil}
curr := root
for {
// ignore whitespace
// check curr is nil or not
switch curr.state {
case stateNone:
switch data[offset] {
case ‘”’:
// go to new loop
curr.state = stateString
continue
}
case stateObjectKey, stateString:
// parse string
if curr.state == stateObjectKey {
// create new stack node
} else {
// pop stack
}
}
}
此外比较特殊的是在解析完一个object的key之后,立即压入了一个新栈结点,并将其状态设置为stateObjectColon,同时将自身的状态设置为stateObjectEndOrComma,在解析完colon之后再这个节点的状态设置为stateNone,开始新的循环,具体来说:
if curr.state == stateObjectKey {
curr.state = stateObjectEndOrComma
curr = &state{&Value{nil}, stateObjectColon, nil}
continue
}
这是因为在:之前和之后都可能有空白字符,这里是为了复用代码逻辑:即在每一次迭代开始之时都把所有的空白过滤掉。
for {
LOOP_WS:
for ; offset < len(data); offset++ {
switch data[offset] {
case ‘\t’, ‘\r’, ‘\n’, ‘ ‘:
continue
default:
break LOOP_WS
}
// do staff
}
在过滤掉空白后,如果当前栈为nil,则不应该有字符存在,整个解析结束,否则一定有字符,并且需要进行解析:
for {
// ignore whitespace
if curr == nil {
if offset == len(data) {
return
} else {
// unexpected char data[offset] at offset
}
} else if offset == len(data) {
// unexpected EOF at offset
}
// do staff
}
#JSON解析基本原理
现在,假设我们没有任何现成的JSON解析库可用,我们要自己完成JSON的解析工作。JSON解析的工作主要分一下几步:
词法分析:这个过程把输入的JSON字符串分解为一系列词法单元(token)。比如以下JSON字符串:
{
“date” : 20160517,
“id” : 1
}
经过词法分析后,会被分解为以下token:“{”、 ”date“、 “:”、 “20160517”、 “,”、 “id”、 “:”、 “1”、 “}”。
语法分析:这一过程的输入是上一步得到的token序列。语法分析这一阶段完成的工作是把token构造成抽象语法单元。对于JSON的解析,这里的抽象语法对象就类似于org.json包中的JSONObject和JSONArray等。有了抽象语法对象,我们就可以进一步把它“映射到”Java数据类型。
- 词法分析
JSON字符串中,一共有几种token呢?根据http://www.json.org/对JSON格式的相关定义,我们可以把token分为以下类型:
STRING(字符串字面量)
NUMBER(数字字面量)
NULL(null)
START_ARRAY([)
END_ARRAY(])
START_OBJ({)
END_OBJ(})
COMMA(,)
COLON(:)
BOOLEAN(true或者false)
END_DOC(表示JSON数据的结束)
我们可以定义一个枚举类型来表示不同的token类型:
public enum TokenType {
START_OBJ, END_OBJ, START_ARRAY, END_ARRAY, NULL, NUMBER, STRING, BOOLEAN, COLON, COMMA, END_DOC
}
,词法分析器通常被称为lexer或是tokenizer。我们可以使用DFA(确定有限状态自动机)来实现tokenizer,也可以直接使用使用Java的regex包。
实现词法分析器(tokenizer)和语法分析器(parser)的依据都是JSON文法,完整的JSON文法如下
object = {} | { members }
members = pair | pair , members
pair = string : value
array = [] | [ elements ]
elements = value | value , elements
value = string | number | object | array | true | false | null
string = “” | “ chars “
chars = char | char chars
char = any-Unicode-character-except-“-or--or- control-character | " | \ | \/ | \b | \f | \n | \r | \t | \u four-hex-digits
number = int | int frac | int exp | int frac exp
int = digit | digit1-9 digits | - digit | - digit1-9 digits
frac = . digits
exp = e digits
digits = digit | digit digits
e = e | e+ | e- | E | E+ | E-
- 语法分析
经过前一步的词法分析,我们已经得到了一个token序列,现在让我们来用这个序列构造出类似于org.json包的JSONObject与JSONArray对象。现在我们的任务就是编写一个语法分析器(parser),以词法分析得到的token序列为输入,产生JSONObject或是JSONArray抽象语法对象。语法分析的依据同样是上面我们贴出的JSON文法。
object = {} | { members }
members = pair | pair , members
pair = string : value
array = [] | [ elements ]
elements = value | value , elements
value = string | number | object | array | true | false | null
JSON的优势除了文法很简单之外,还有一个很重要的地方是,我们逐个字符地解析JSON,在不考虑错误处理的情况下,甚至都不需要前瞻!举个例子,在JSON解析的一开始,如果发现是字符’n’,可以立马断定是null;是’{‘,就是对象。这给我们解析器的编写带来了很大的方便。其实不管是JSON、XML还是YAML,其核心都是要描绘一种树状类型的结构。原因是生活中的大部分信息都是以这种形式保存的。有树,就会有结点。而不同的标记语言,这个结点里包含的东西也就不同。但是这种树状的结构是基本相同的。把源字符串转换成我们定义好的数据结构的过程,也就是所谓的解析。那么解析的难点在哪里呢?如果一个JSON字符串里的内容仅仅是“true”四个字符,一次strcmp即可完成,你还觉得难吗?是任意数量的空格吗?貌似也不是。不知道题主初学编程时有没有写过那种“统计输入中空格的数量”的程序。如果有,其实排除空格的原理差不多。
作者:知乎用户
链接:https://www.zhihu.com/question/24640264/answer/80500016
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我们写一个JSON解析器的目的是让杂乱的字符串变成C/Java/Python…等语言能够识别的数据结构。我们所做的工作仅仅是“保存”,没有“解释”,更不是“编译”。外加前面说的根本不需要前瞻一个字符的特性,我们编写JSON Parser其实连词法分析都不用。在这里,我们先定义好一个JSON数据结构的结点类型。struct json_node {
enum {
NUMBER,
STRING,
ARRAY,
OBJECT,
TRUE,
FALSE,
NUL,
UNKNOWN
} type;
char name;
union {
double number;
struct json_node *child_head;
char *val_str;
};
};定义好了这个结构体,我们的工作其实就已经完成一半了。根据上面完整定义的文法,再来写解释基本类型的代码。struct json_node *
parse_json(void)
{
struct json_node *res = malloc(sizeof(struct json_node));
char ch = getchar();
switch (ch) {
case ‘t’:
while (isalpha(ch)) {
ch = getchar();
}
res->type = TRUE;
break;
/ 对于null和false也一样 /
case ‘"’:
res->type = STRING;
/ 寻找到第一个不是转义字符的双引号 “ /
break;
case ‘+’:
case ‘-‘:
case ‘1’:
/ 1-9 /
res->type = NUMBER;
/ 缓冲区存储字符直到停止,然后用系统库函数转换 */
default:
res->type = UNKNOWN;
break;
}
return res;
}
编写一个JSON解析器实际上就是一个函数,它的输入是一个表示JSON的字符串,输出是结构化的对应到语言本身的数据结构。
和XML相比,JSON本身结构非常简单,并且仅有几种数据类型,以Java为例,对应的数据结构是:
“string”:Java的String;
number:Java的Long或Double;
true/false:Java的Boolean;
null:Java的null;
[array]:Java的List
本质上解析器就是一个状态机,只要按照JSON定义的格式(参考http://www.json.org,正确实现状态转移即可。但是为了简化代码,我们也没必要完整地实现一个字符一个字符的状态转移。
解析器的输入应该是一个字符流,所以,第一步是获得Reader,以便能不断地读入下一个字符。
在解析的过程中,我们经常要根据下一个字符来决定状态跳转,此时又涉及到回退的问题,就是某些时候不能用next()取下一个字符,而是用peek()取下一个字符,但字符流的指针不移动。所以,Reader接口不能满足这个需求,应当进一步封装一个CharReader,它可以实现:
char next():读取下一个字符,移动Reader指针;
char peek():读取下一个字符,不移动Reader指针;
String next(int size):读取指定的N个字符并移动指针;
boolean hasMore():判断流是否结束。
JSON解析比其他文本解析要简单的地方在于,任何JSON数据类型,只需要根据下一个字符即可确定,仔细总结可以发现,如果peek()返回的字符是某个字符,就可以期望读取的数据类型:
{:期待一个JSON object;
::期待一个JSON object的value;
,:期待一个JSON object的下一组key-value,或者一个JSON array的下一个元素;
[:期待一个JSON array;
t:期待一个true;
f:期待一个false;
n:期待一个null;
“:期待一个string;
0~9:期待一个number。
但是单个字符要匹配的状态太多了,需要进一步把字符流变为Token,可以总结出如下几种Token:
END_DOCUMENT:JSON文档结束;
BEGIN_OBJECT:开始一个JSON object;
END_OBJECT:结束一个JSON object;
BEGIN_ARRAY:开始一个JSON array;
END_ARRAY:结束一个JSON array;
SEP_COLON:读取一个冒号;
SEP_COMMA:读取一个逗号;
STRING:一个String;
BOOLEAN:一个true或false;
NUMBER:一个number;
NULL:一个null。
然后,将CharReader进一步封装为TokenReader,提供以下接口:
Token readNextToken():读取下一个Token;
boolean readBoolean():读取一个boolean;
Number readNumber():读取一个number;
String readString():读取一个string;
void readNull():读取一个null。
由于JSON的Object和Array可以嵌套,在读取过程中,使用一个栈来存储Object和Array是必须的。每当我们读到一个BEGIN_OBJECT时,就创建一个Map并压栈;每当读到一个BEGIN_ARRAY时,就创建一个List并压栈;每当读到一个END_OBJECT和END_ARRAY时,就弹出栈顶元素,并根据新的栈顶元素判断是否压栈。此外,读到Object的Key也必须压栈,读到后面的Value后将Key-Value压入栈顶的Map。
如果读到END_DOCUMENT时,栈恰好只剩下一个元素,则读取正确,将该元素返回,读取结束。如果栈剩下不止一个元素,则JSON文档格式不正确。
| 最后,JsonReader的核心解析代码parse()就是负责从TokenReader中不断读取Token,根据当前状态操作,然后设定下一个Token期望的状态,如果与期望状态不符,则JSON的格式无效。起始状态被设定为STATUS_EXPECT_SINGLE_VALUE | STATUS_EXPECT_BEGIN_OBJECT | STATUS_EXPECT_BEGIN_ARRAY,即期望读取到单个value、{或[。循环的退出点是读取到END_DOCUMENT时。 |
public class JsonReader {
TokenReader reader;
public Object parse() {
Stack stack = new Stack();
int status = STATUS_EXPECT_SINGLE_VALUE | STATUS_EXPECT_BEGIN_OBJECT | STATUS_EXPECT_BEGIN_ARRAY;
for (;;) {
Token currentToken = reader.readNextToken();
switch (currentToken) {
case BOOLEAN:
if (hasStatus(STATUS_EXPECT_SINGLE_VALUE)) {
// single boolean:
Boolean bool = reader.readBoolean();
stack.push(StackValue.newJsonSingle(bool));
status = STATUS_EXPECT_END_DOCUMENT;
continue;
}
if (hasStatus(STATUS_EXPECT_OBJECT_VALUE)) {
Boolean bool = reader.readBoolean();
String key = stack.pop(StackValue.TYPE_OBJECT_KEY).valueAsKey();
stack.peek(StackValue.TYPE_OBJECT).valueAsObject().put(key, bool);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_OBJECT;
continue;
}
if (hasStatus(STATUS_EXPECT_ARRAY_VALUE)) {
Boolean bool = reader.readBoolean();
stack.peek(StackValue.TYPE_ARRAY).valueAsArray().add(bool);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_ARRAY;
continue;
}
throw new JsonParseException("Unexpected boolean.", reader.reader.readed);
case NULL:
if (hasStatus(STATUS_EXPECT_SINGLE_VALUE)) {
// single null:
reader.readNull();
stack.push(StackValue.newJsonSingle(null));
status = STATUS_EXPECT_END_DOCUMENT;
continue;
}
if (hasStatus(STATUS_EXPECT_OBJECT_VALUE)) {
reader.readNull();
String key = stack.pop(StackValue.TYPE_OBJECT_KEY).valueAsKey();
stack.peek(StackValue.TYPE_OBJECT).valueAsObject().put(key, null);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_OBJECT;
continue;
}
if (hasStatus(STATUS_EXPECT_ARRAY_VALUE)) {
reader.readNull();
stack.peek(StackValue.TYPE_ARRAY).valueAsArray().add(null);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_ARRAY;
continue;
}
throw new JsonParseException("Unexpected null.", reader.reader.readed);
case NUMBER:
if (hasStatus(STATUS_EXPECT_SINGLE_VALUE)) {
// single number:
Number number = reader.readNumber();
stack.push(StackValue.newJsonSingle(number));
status = STATUS_EXPECT_END_DOCUMENT;
continue;
}
if (hasStatus(STATUS_EXPECT_OBJECT_VALUE)) {
Number number = reader.readNumber();
String key = stack.pop(StackValue.TYPE_OBJECT_KEY).valueAsKey();
stack.peek(StackValue.TYPE_OBJECT).valueAsObject().put(key, number);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_OBJECT;
continue;
}
if (hasStatus(STATUS_EXPECT_ARRAY_VALUE)) {
Number number = reader.readNumber();
stack.peek(StackValue.TYPE_ARRAY).valueAsArray().add(number);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_ARRAY;
continue;
}
throw new JsonParseException("Unexpected number.", reader.reader.readed);
case STRING:
if (hasStatus(STATUS_EXPECT_SINGLE_VALUE)) {
// single string:
String str = reader.readString();
stack.push(StackValue.newJsonSingle(str));
status = STATUS_EXPECT_END_DOCUMENT;
continue;
}
if (hasStatus(STATUS_EXPECT_OBJECT_KEY)) {
String str = reader.readString();
stack.push(StackValue.newJsonObjectKey(str));
status = STATUS_EXPECT_COLON;
continue;
}
if (hasStatus(STATUS_EXPECT_OBJECT_VALUE)) {
String str = reader.readString();
String key = stack.pop(StackValue.TYPE_OBJECT_KEY).valueAsKey();
stack.peek(StackValue.TYPE_OBJECT).valueAsObject().put(key, str);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_OBJECT;
continue;
}
if (hasStatus(STATUS_EXPECT_ARRAY_VALUE)) {
String str = reader.readString();
stack.peek(StackValue.TYPE_ARRAY).valueAsArray().add(str);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_ARRAY;
continue;
}
throw new JsonParseException("Unexpected char \'\"\'.", reader.reader.readed);
case SEP_COLON: // :
if (status == STATUS_EXPECT_COLON) {
status = STATUS_EXPECT_OBJECT_VALUE | STATUS_EXPECT_BEGIN_OBJECT | STATUS_EXPECT_BEGIN_ARRAY;
continue;
}
throw new JsonParseException("Unexpected char \':\'.", reader.reader.readed);
case SEP_COMMA: // ,
if (hasStatus(STATUS_EXPECT_COMMA)) {
if (hasStatus(STATUS_EXPECT_END_OBJECT)) {
status = STATUS_EXPECT_OBJECT_KEY;
continue;
}
if (hasStatus(STATUS_EXPECT_END_ARRAY)) {
status = STATUS_EXPECT_ARRAY_VALUE | STATUS_EXPECT_BEGIN_ARRAY | STATUS_EXPECT_BEGIN_OBJECT;
continue;
}
}
throw new JsonParseException("Unexpected char \',\'.", reader.reader.readed);
case END_ARRAY:
if (hasStatus(STATUS_EXPECT_END_ARRAY)) {
StackValue array = stack.pop(StackValue.TYPE_ARRAY);
if (stack.isEmpty()) {
stack.push(array);
status = STATUS_EXPECT_END_DOCUMENT;
continue;
}
int type = stack.getTopValueType();
if (type == StackValue.TYPE_OBJECT_KEY) {
// key: [ CURRENT ] ,}
String key = stack.pop(StackValue.TYPE_OBJECT_KEY).valueAsKey();
stack.peek(StackValue.TYPE_OBJECT).valueAsObject().put(key, array.value);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_OBJECT;
continue;
}
if (type == StackValue.TYPE_ARRAY) {
// xx, xx, [CURRENT] ,]
stack.peek(StackValue.TYPE_ARRAY).valueAsArray().add(array.value);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_ARRAY;
continue;
}
}
throw new JsonParseException("Unexpected char: \']\'.", reader.reader.readed);
case END_OBJECT:
if (hasStatus(STATUS_EXPECT_END_OBJECT)) {
StackValue object = stack.pop(StackValue.TYPE_OBJECT);
if (stack.isEmpty()) {
// root object:
stack.push(object);
status = STATUS_EXPECT_END_DOCUMENT;
continue;
}
int type = stack.getTopValueType();
if (type == StackValue.TYPE_OBJECT_KEY) {
String key = stack.pop(StackValue.TYPE_OBJECT_KEY).valueAsKey();
stack.peek(StackValue.TYPE_OBJECT).valueAsObject().put(key, object.value);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_OBJECT;
continue;
}
if (type == StackValue.TYPE_ARRAY) {
stack.peek(StackValue.TYPE_ARRAY).valueAsArray().add(object.value);
status = STATUS_EXPECT_COMMA | STATUS_EXPECT_END_ARRAY;
continue;
}
}
throw new JsonParseException("Unexpected char: \'}\'.", reader.reader.readed);
case END_DOCUMENT:
if (hasStatus(STATUS_EXPECT_END_DOCUMENT)) {
StackValue v = stack.pop();
if (stack.isEmpty()) {
return v.value;
}
}
throw new JsonParseException("Unexpected EOF.", reader.reader.readed);
case BEGIN_ARRAY:
if (hasStatus(STATUS_EXPECT_BEGIN_ARRAY)) {
stack.push(StackValue.newJsonArray(this.jsonArrayFactory.createJsonArray()));
status = STATUS_EXPECT_ARRAY_VALUE | STATUS_EXPECT_BEGIN_OBJECT | STATUS_EXPECT_BEGIN_ARRAY | STATUS_EXPECT_END_ARRAY;
continue;
}
throw new JsonParseException("Unexpected char: \'[\'.", reader.reader.readed);
case BEGIN_OBJECT:
if (hasStatus(STATUS_EXPECT_BEGIN_OBJECT)) {
stack.push(StackValue.newJsonObject(this.jsonObjectFactory.createJsonObject()));
status = STATUS_EXPECT_OBJECT_KEY | STATUS_EXPECT_BEGIN_OBJECT | STATUS_EXPECT_END_OBJECT;
continue;
}
throw new JsonParseException("Unexpected char: \'{\'.", reader.reader.readed);
}
}
} }
