defer
defer的行为规则,只有三条
规则一:延迟函数的参数在defer语句出现时就已经确定下来了
官方给出一个例子,如下所示:
func a() {
i := 0
defer fmt.Println(i)
i++
return
}
defer语句中的fmt.Println()参数i值在defer出现时就已经确定下来,实际上是拷贝了一份。后面对变量i的修改不会影响fmt.Println()函数的执行,仍然打印”0”。
注意:对于指针类型参数,规则仍然适用,只不过延迟函数的参数是一个地址值,这种情况下,defer后面的语句对变量的修改可能会影响延迟函数。
规则二:延迟函数执行按后进先出顺序执行,即先出现的defer最后执行
这个规则很好理解,定义defer类似于入栈操作,执行defer类似于出栈操作。
设计defer的初衷是简化函数返回时资源清理的动作,资源往往有依赖顺序,比如先申请A资源,再跟据A资源申请B资源,跟据B资源申请C资源,即申请顺序是:A–>B–>C,释放时往往又要反向进行。这就是把deffer设计成FIFO的原因。
每申请到一个用完需要释放的资源时,立即定义一个defer来释放资源是个很好的习惯。
规则三:延迟函数可能操作主函数的具名返回值
定义defer的函数,即主函数可能有返回值,返回值有没有名字没有关系,defer所作用的函数,即延迟函数可能会影响到返回值。
若要理解延迟函数是如何影响主函数返回值的,只要明白函数是如何返回的就足够了。
函数返回过程
有一个事实必须要了解,关键字return不是一个原子操作,实际上return只代理汇编指令ret,即将跳转程序执行。比如语句return i,实际上分两步进行,即将i值存入栈中作为返回值,然后执行跳转,而defer的执行时机正是跳转前,所以说defer执行时还是有机会操作返回值的。
func deferFuncReturn() (result int) {
i := 1
defer func() {
result++
}()
return i } 该函数的return语句可以拆分成下面两行:
result = i
return
而延迟函数的执行正是在return之前,即加入defer后的执行过程如下:
result = i
result++
return
所以上面函数实际返回i++值。
关于主函数有不同的返回方式,但返回机制就如上机介绍所说,只要把return语句拆开都可以很好的理解
主函数拥有匿名返回值,返回字面值
一个主函数拥有一个匿名的返回值,返回时使用字面值,比如返回”1”、”2”、”Hello”这样的值,这种情况下defer语句是无法操作返回值的。
一个返回字面值的函数,如下所示:
func foo() int {
var i int
defer func() {
i++
}()
return 1 }
上面的return语句,直接把1写入栈中作为返回值,延迟函数无法操作该返回值,所以就无法影响返回值。
主函数拥有匿名返回值,返回变量
一个主函数拥有一个匿名的返回值,返回使用本地或全局变量,这种情况下defer语句可以引用到返回值,但不会改变返回值。
一个返回本地变量的函数,如下所示:
func foo() int {
var i int
defer func() {
i++
}()
return i } 上面的函数,返回一个局部变量,同时defer函数也会操作这个局部变量。对于匿名返回值来说,可以假定仍然有一个变量存储返回值,假定返回值变量为"anony",上面的返回语句可以拆分成以下过程:
anony = i
i++
return
由于i是整型,会将值拷贝给anony,所以defer语句中修改i值,对函数返回值不造成影响。
主函数拥有具名返回值
主函声明语句中带名字的返回值,会被初始化成一个局部变量,函数内部可以像使用局部变量一样使用该返回值。如果defer语句操作该返回值,可能会改变返回结果。
一个影响函返回值的例子:
func foo() (ret int) {
defer func() {
ret++
}()
return 0 } 上面的函数拆解出来,如下所示:
ret = 0
ret++
return
函数真正返回前,在defer中对返回值做了+1操作,所以函数最终返回1。
defer实现原理
1 defer数据结构
源码包src/src/runtime/runtime2.go:_defer定义了defer的数据结构:
type _defer struct {
sp uintptr //函数栈指针
pc uintptr //程序计数器
fn *funcval //函数地址
link *_defer //指向自身结构的指针,用于链接多个defer
}
我们知道defer后面一定要接一个函数的,所以defer的数据结构跟一般函数类似,也有栈地址、程序计数器、函数地址等等。
与函数不同的一点是它含有一个指针,可用于指向另一个defer,每个goroutine数据结构中实际上也有一个defer指针,该指针指向一个defer的单链表,每次声明一个defer时就将defer插入到单链表表头,每次执行defer时就从单链表表头取出一个defer执行。
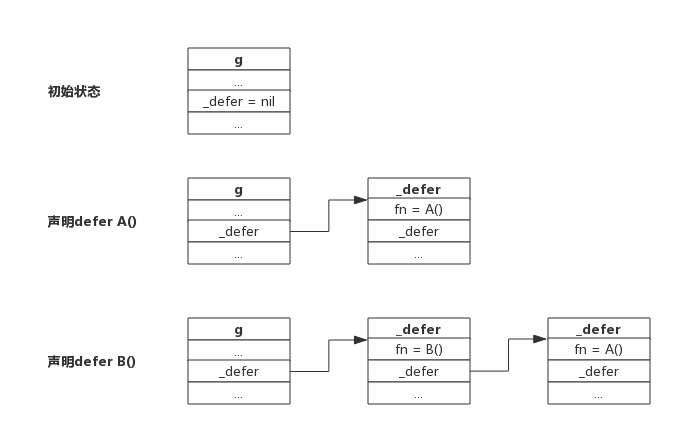
新声明的defer总是添加到链表头部。
函数返回前执行defer则是从链表首部依次取出执行
一个goroutine可能连续调用多个函数,defer添加过程跟上述流程一致,进入函数时添加defer,离开函数时取出defer,所以即便调用多个函数,也总是能保证defer是按FIFO方式执行的
2 defer的创建和执行
源码包src/runtime/panic.go定义了两个方法分别用于创建defer和执行defer。
deferproc(): 在声明defer处调用,其将defer函数存入goroutine的链表中;
deferreturn():在return指令,准确的讲是在ret指令前调用,其将defer从goroutine链表中取出并执行。
可以简单这么理解,在编译在阶段,声明defer处插入了函数deferproc(),在函数return前插入了函数deferreturn()。
defer定义的延迟函数参数在defer语句出时就已经确定下来了
defer定义顺序与实际执行顺序相反
return不是原子操作,执行过程是: 保存返回值(若有)–>执行defer(若有)–>执行ret跳转
申请资源后立即使用defer关闭资源是好习惯
.1. 结构
在介绍 defer 函数的执行过程与实现原理之前,我们首先来了解一下 defer 关键字在 Go 语言中存在的结构和形式,
type _defer struct {
siz int32
started bool
sp uintptr
pc uintptr
fn *funcval
_panic *_panic
link *_defer
}
在 _defer 结构中的 sp 和 pc 分别指向了栈指针和调用方的程序计数器,fn 存储的就是向 defer 关键字中传入的函数了。
2.2. 编译期间
defer 关键字是在 Go 语言编译期间的 SSA 阶段才被 stmt 函数处理的,我们能在 stmt 中的 switch/case 语句中找到处理 ODEFER 节点的相关逻辑,可以看到这段代码其实调用了 call 函数,这表示 defer 在编译器看来也是一次函数调用,它们的处理逻辑其实也是差不多的。
func (s *state) stmt(n *Node) {
switch n.Op {
case ODEFER:
s.call(n.Left, callDefer)
}
}
被调用的 call 函数其实负责了 Go 语言中所有函数和方法调用的 中间代码生成,它的工作主要包括以下内容:
获取需要执行的函数名、闭包指针、代码指针和函数调用的接收方;
获取栈地址并将函数或者方法的参数写入栈中;
使用 newValue1A 以及相关函数生成函数调用的中间代码;
如果当前调用的『函数』是 defer,那么就会单独生成相关的结束代码块;
最后会获取函数的返回值地址并结束当前方法的调用;
由于我们在这一节中主要关注的内容其实就是 defer 最终调用了什么方法,所以在这里删除了函数中不相关的内容:
func (s *state) call(n *Node, k callKind) *ssa.Value {
//…
var call *ssa.Value
switch {
case k == callDefer:
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, deferproc, s.mem())
// …
}
call.AuxInt = stksize
s.vars[&memVar] = call
// …
}
deferproc 就是 defer 关键字在运行期间会调用的函数,这个函数接收了两个参数,分别是参数的大小和闭包所在的地址。
除了将所有 defer 关键字的调用都转换成 deferproc 的函数调用之外,Go 语言的编译器其实还在 SSA 中间代码生成期间,为所有调用 defer 的函数末尾插入了调用 deferreturn 的语句,这一过程的实现其实分成三个部分
首先 walkstmt 函数在遇到 ODEFER 节点时会通过 Curfn.Func.SetHasDefer(true) 表达式设置当前函数的 hasdefer 属性;
SSA 中间代码生成阶段调用的 buildssa 函数其实会执行 s.hasdefer = fn.Func.HasDefer() 语句更新 state 的 hasdefer 属性;
最后在 exit 中会插入 deferreturn 的函数调用;
func (s *state) exit() *ssa.Block {
if s.hasdefer {
s.rtcall(Deferreturn, true, nil)
}
// ... } 在 Go 语言的编译期间,编译器不仅将 defer 转换成了 deferproc 的函数调用,还在所有调用 defer 的函数结尾(返回之前)插入了 deferreturn,接下来我们就需要了解 Go 语言的运行时都做了什么。
2.3. 运行时
每一个 defer 关键字都会被转换成 deferproc,在这个函数中我们会为 defer 创建一个新的 _defer 结构体并设置它的 fn、pc 和 sp 参数,除此之外我们会将 defer 相关的函数都拷贝到紧挨着结构体的内存空间中:
func deferproc(siz int32, fn *funcval) {
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
callerpc := getcallerpc()
d := newdefer(siz)
if d._panic != nil {
throw("deferproc: d.panic != nil after newdefer")
}
d.fn = fn
d.pc = callerpc
d.sp = sp
switch siz {
case 0:
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
return0() } 上述函数最终会使用 return0 返回,这个函数的主要作用就是避免在 deferproc 函数中使用 return 返回时又会导致 deferreturn 函数的执行,这也是唯一一个不会触发 defer 的函数了。
deferproc 中调用的 newdefer 主要作用就是初始化或者取出一个新的 _defer 结构体:
func newdefer(siz int32) _defer {
var d *_defer
sc := deferclass(uintptr(siz))
gp := getg()
if sc < uintptr(len(p{}.deferpool)) {
pp := gp.m.p.ptr()
if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {
lock(&sched.deferlock)
for len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {
d := sched.deferpool[sc]
sched.deferpool[sc] = d.link
d.link = nil
pp.deferpool[sc] = append(pp.deferpool[sc], d)
}
unlock(&sched.deferlock)
}
if n := len(pp.deferpool[sc]); n > 0 {
d = pp.deferpool[sc][n-1]
pp.deferpool[sc][n-1] = nil
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
}
}
if d == nil {
total := roundupsize(totaldefersize(uintptr(siz)))
d = (_defer)(mallocgc(total, deferType, true))
}
d.siz = siz
d.link = gp._defer
gp._defer = d
return d
}
从最后的一小段代码我们可以看出,所有的 _defer 结构体都会关联到所在的 Goroutine 上并且每创建一个新的 _defer 都会追加到协程持有的 _defer 链表的最前面。
Golang-Goroutine-Defer-List
deferreturn 其实会从 Goroutine 的链表中取出链表最前面的 _defer 结构体并调用 jmpdefer 函数并传入需要执行的函数和参数:
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
if d == nil {
return
}
sp := getcallersp()
switch d.siz {
case 0:
case sys.PtrSize:
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default:
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0))) } jmpdefer 其实是一个用汇编语言实现的函数,在不同的处理器架构上的实现稍有不同,但是具体的执行逻辑都差不太多,它们的工作其实就是跳转到并执行 defer 所在的代码段并在执行结束之后跳转回 defereturn 函数。
TEXT runtime·jmpdefer(SB), NOSPLIT, $0-8
MOVL fv+0(FP), DX // fn
MOVL argp+4(FP), BX // caller sp
LEAL -4(BX), SP // caller sp after CALL
#ifdef GOBUILDMODE_shared
SUBL $16, (SP) // return to CALL again
#else
SUBL $5, (SP) // return to CALL again
#endif
MOVL 0(DX), BX
JMP BX // but first run the deferred function
defereturn 函数会多次判断当前 Goroutine 中是否有剩余的 _defer 结构直到所有的 _defer 都执行完毕,这时当前函数才会返回。
- 总结
defer 关键字会在编译阶段被转换成 deferproc 的函数调用并在函数返回之前插入 deferreturn 指令;在运行期间,每一次 deferproc 的调用都会将一个新的 _defer 结构体追加到当前 Goroutine 持有的链表头,而 deferreturn 会从 Goroutine 中取出 _defer 结构并依次执行,所有 _defer 结构执行成功之后当前函数才会返回。
https://draveness.me/golang/keyword/golang-defer.html
https://docs.kilvn.com/go-internals/03.4.html
