如何设计Twitter
如何设计Twitter?此问题同样也可以推广到如何设计Facebook、微博、微信朋友圈等
太阁冯沁原提出的SNAKE原则和九章算法东邪老师提出的4S原则都不能完全体现系统设计的真髓,SNAKE原则缺少了Storage(存储)部分的强调,4S原则缺少对系统参数的计算。在此我想总结两位前辈的经验,提炼出自己对于系统设计原则的理解:4SE原则。
设计一个可用的系统并不是一蹴而就的事情,而是随着整个业务逻辑的提升,系统的架构也会随之变化,所以在系统设计之前一定要明确系统设计的处于什么样的场景,需要多大的用户量,才能决定整个系统的架构,选择合适的存储系统。
Scenario
场景:首先明确系统设计所在的场景,具体要设计哪些功能,具有什么样的特性等等。
关键词:功能
Suppose
假设:假设用户量,QPS,DAU(日活跃用户)等。
关键词:QPS/DAU/PAU(高峰活跃用户)
Service
服务:将实现的整个系统拆分成小的服务和模块。
关键词:SOA/Push/Pull
Storage
存储:选择合适的存储系统。
关键词:SQL/NoSQL/File System
Evolve
扩展:解决可能会遇到的一些问题。
关键词:雪崩问题/单点失败/多点失败
Scenario
Twitter的功能如下:
注册/登录
用户信息显示/修改
加载图片/视频
搜索
发送/共享Tweet
Timeline/News Feed
关注/取消关注
系统设计中,我们往往关注系统的核心功能,Twitter的核心功能可以总结如下:
发送Tweet
Timeline
NewsFeed
关注/取消关注
Suppose
这部分主要估计系统的QPS,根据QPS决定整个系统的架构。
首先假设Twitter的 DAU=150m+, 每天的Tweet数为400m(这部分不清楚可以直接问面试官)。
QPS = 150m * 60 / 86400 ~ 100k
Peak QPS = QPS * 3 ~ 300k
对于Twitter这种增长比较快的系统,考虑QPS可以适当的加2倍或者3倍。
基于以上的估算结果我们大致可以得出:
Read Timeline QPS = 300k
Write Timeline QPS = 5k
Service
把Twitter的主要功能拆分成几个服务模块,Twitter系统的架构如下:
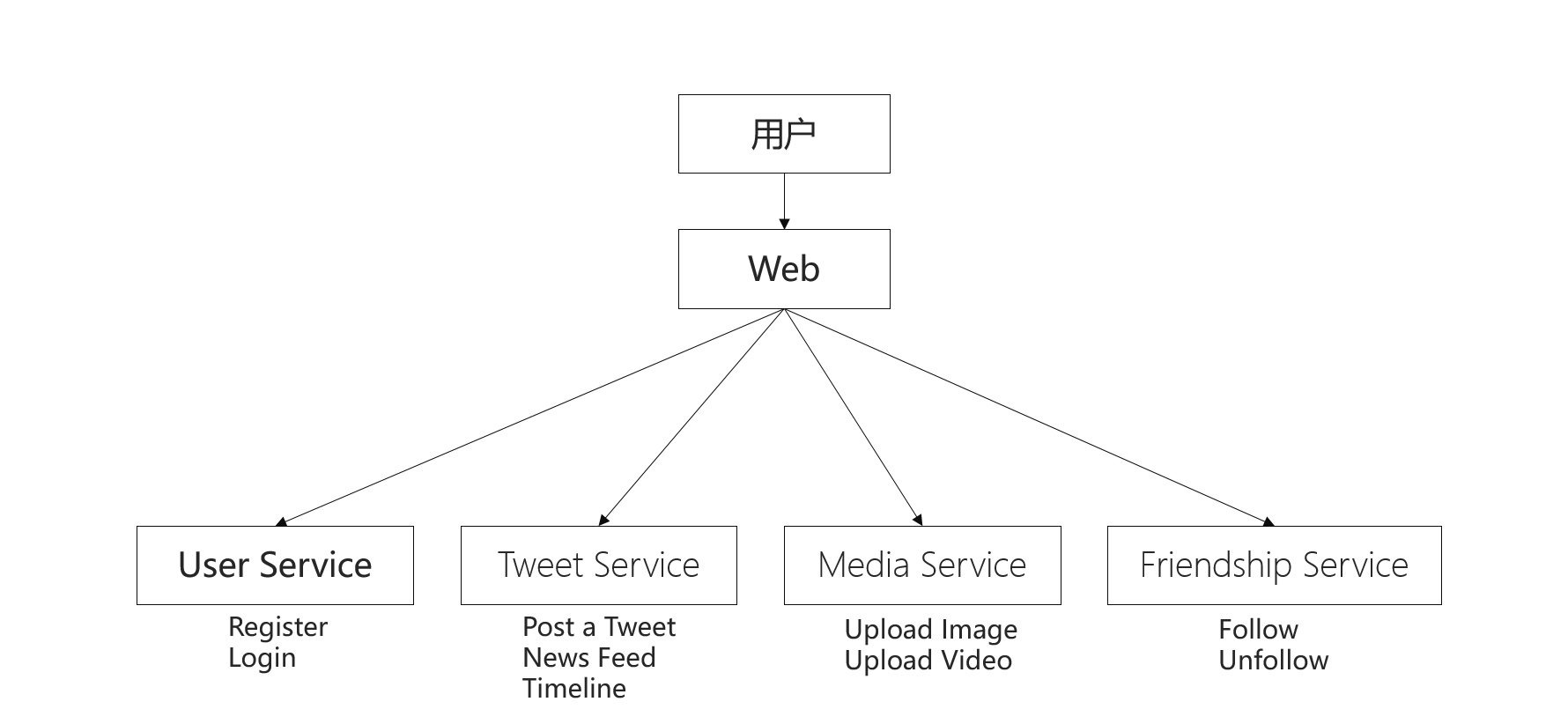
Twitter架构内部实现可以分为Push和Pull模型。
Push
Push模型的流程如下:
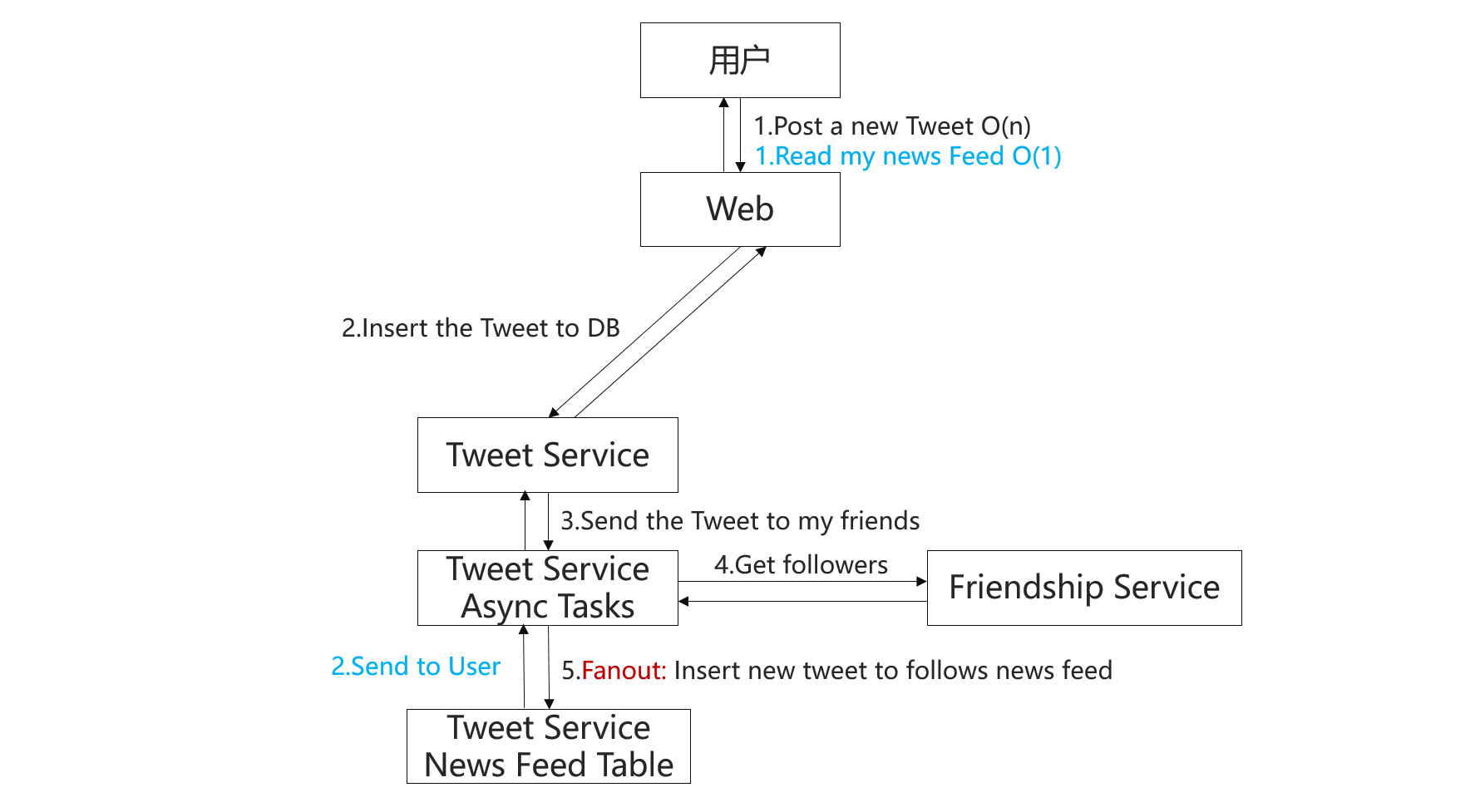
Push模型中,用户发送一条Tweet后Tweet服务将这个Tweet插入到关注该用户的News Feed中,是一个主动服务的过程。
问题:Push模型存在的问题是Lady Gaga的风暴问题,如果某个用户被关注的人数太多,生成这些用户的News Feed会占用比较长的时间,可以缓解这个问题的一个办法是先通知在线的用户,再去处理离线用户的News Feed。
Pull
Pull模型的流程如下:

Pull模型中,用户发送一条Tweet后立即存储在DB中,当用户需要自己的News Feed的时候,读取用户关注者的Tweet,然后根据时间戳合成该用户的News Feed,是一个用户主动请求的工程。
问题:上帝视角,如果某个用户关注非常多的其他用户,合并过程会比较慢。
Push vs. Pull
Push和Pull模型各有各的问题,到底哪一个模型好呢?实际应用中Twitter和Facebook使用的是Pull模型,Instagram使用Pull和Push结合的模型,Pull模型相对于Push模型的好处有:逻辑比较简单,实现起来比较容易;上帝视角的问题较Lady Gaga的风暴问题来说出现的概率很低。
当然也可以将Push和Pull模型结合起来:
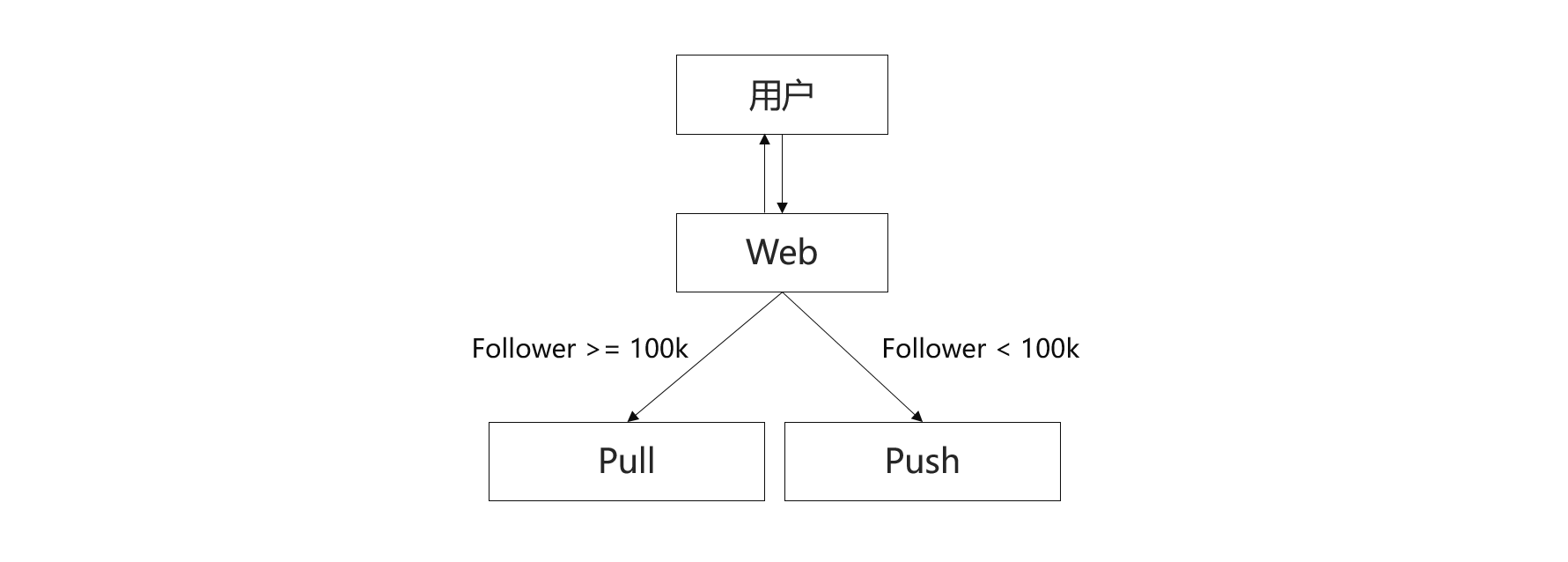
问题:摇摆问题,比如邓超有100k的粉丝,发了一条比较作的微博,一下子掉了好几十万的粉丝,不发微博又涨了几十万粉丝,这样处于中间不停的摇摆,系统会切换来切换去,可以采取的一个策略是,对于大于100k的使用Pull模型,只有当粉丝掉到90k以下是才是用Push模型。设置一个缓冲地带,可以缓解摇摆问题带来的影响。
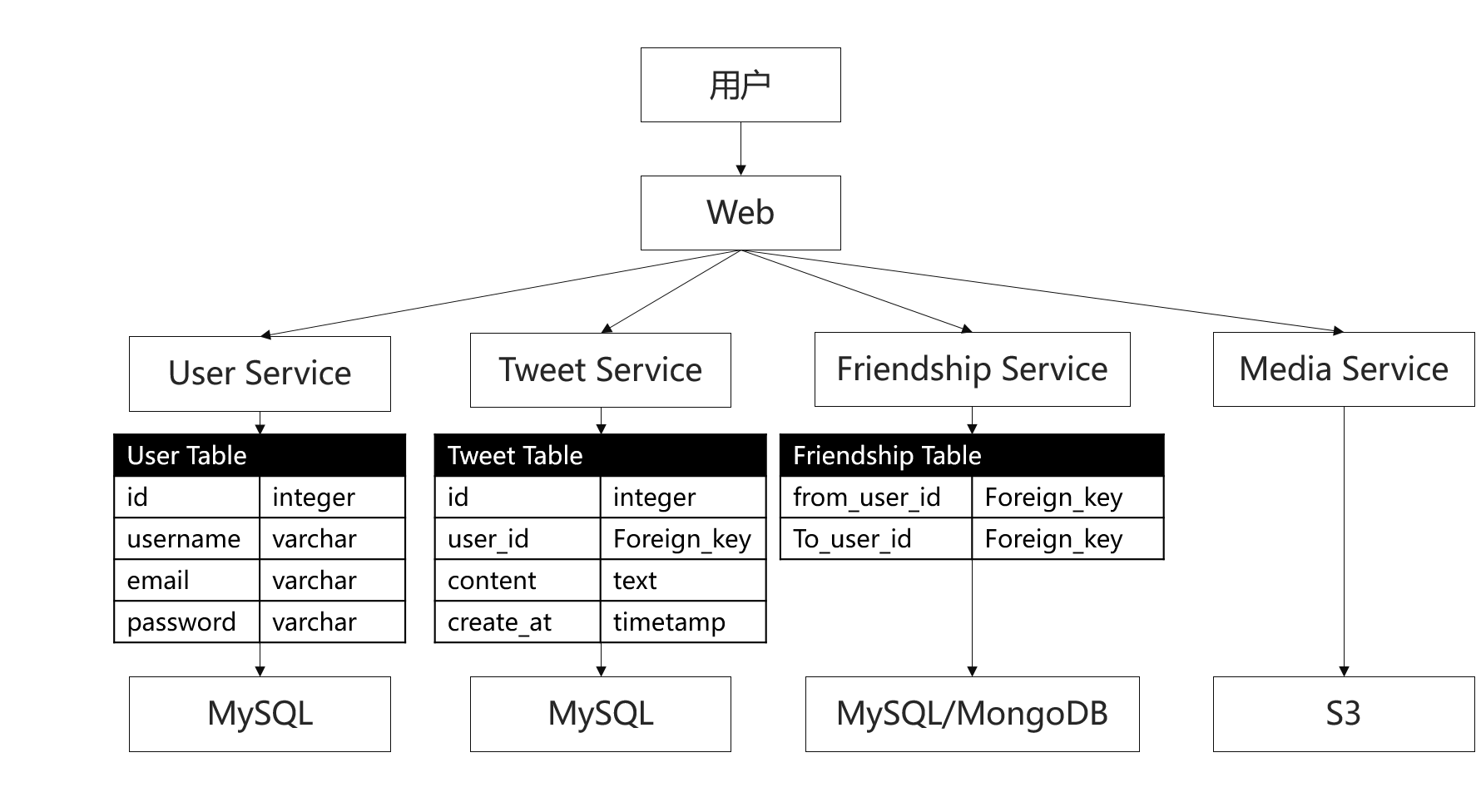
Storage
不管什么样的系统,本质上都是用户对数据的读取,所以存储这部分的设计比较关键。一般来说我们选择的存储类型有以下三个:
关系型数据库 SQL Database:用户信息 - MySQL
非关系型数据库 NoSQL Database:社交图谱 - MongoDB
文件系统 File System:图片、视频 - Amazon S3
Evolve
如何加速?
加速的第一个思路就是Cache,将所有的内容都放在内存中,加速访问。
仅仅Cache一周之内访问Twitter的用户,并只Cache最新的800条Tweet。
Assumption:
Weekly active users: 300 million
Average news feed size: 80 tweets
Average timeline size: 500 tweets
Tweet size: 200B
Average follower : 20
Momory need:
Size of timeline = 300 million * 500 * 200 = 30T
Size of news feed = 300 million * 80 * 200 = 4.8T
Size of social graph = 300 million * 20 * 2 * 8 = 64G
如何节省空间?
将Tweet内容隔离出来,Timline只存Tweet的ID,这样可以去掉很多重复的Tweet。
Assumption:
Tweet size: 20B = userID(8)+tweetID(8)+Indicators(4)
Momory need:
Size of timeline = 300 million * 500 * 20 = 3T
Size of news feed = 300 million * 80 * 20 = 480G
参考资料:
冯沁原:How to design Feed/Chat System
东邪:Introducing System Design & News Feed System
timeline是最典型的feed流展示方式,按照feed流内容更新的时间先后顺序,将内容展示给用户,早期的微博、朋友圈都是典型的timeline。
rank即按照某些因素计算内容的权重,从而决定内容展示的先后顺序。
微博主要是被营销号垃圾高屏内容占据太多了,所以开始采用权重算法,从而鼓励原创积极性。要不你一刷屏幕全是你转我的,我转你的,一天发40多条的营销号你都不想看了。
要说什么产品适合时间线形式我觉得是动态较少,并且你关注的人都对你有价值的产品,例如朋友圈
rank就比较普遍了,广场类的都比较适合rank,抖音、微博都是这样
说答案的时候,总的来说,最注意把控的就是平衡细节的知识和大局的构架。什么意思?一,别有太多细节你自己说出来了你自己答不上,比如你说要用redis 结果redis数据放哪不知道。那就gg了。二, 别说一个细节说了十分多钟忘了之前到哪了。
有个培训机构叫太阁 他们用的方法是SNAKE 原则。
Scenario - Necessary - Application - Kilobit - Evolve
先说哪里用得到,再说我们需要解决问题多大规模。然后说基本解里头Application里面都有啥,然后说说相对应的数据放哪里怎么放。最后这些都说完了(20-25分钟左右)来具体谈怎么让我的基本解在哪些方面做的更好。
还有个培训机构叫九章, 他们用的方法是4S原则,啥意思啊?
Scenario - Service - Storage - Scale
先说哪里用得到 要解决什么问题,然后说我们一个大系统对吧,怎么写出对应的micro services, 然后再说我们的数据放哪里怎么放,最后(也是20-25分钟后)说我们怎么样向上scale
Scenario 场景
问清楚自己要做哪些功能(也就是说,45分钟内不聊哪些功能)
问清楚或者说清楚自己要handle多大用户量,面试官起码得给你确认这么几个信息,否则聊不下去。
一个是你平均每天handle多少用户
一个是你峰值(最多?不太精确但是形容一下)每天handle多少用户
- 自己把自己要算的东西都算出来, QPS啊,存储size啊,不非得一口气全部算完,但是记住最基本的用户量,然后再说然后的。
Implementation 实现
搭架子,我的系统要干嘛,为了做这件事情,我们需要什么组件,怎么安排。这里一切最简单,保证这个东西可以work,不要有明显的优化还不做。
按照架子一个一个实现具体功能,如果发现有问题了,改改架子。记住。改架子的时候一定要想想别的东西动没动,动了,赶紧拿个纸记下来。数据放哪可以这里说可以分开说,这都不要紧。
架子流程实现完了想想数据放哪里怎么放,那么些个数据库呢,好好挑挑。
Enhancement 提高
7.根据确认的问题或者优化点慢慢优化。这里的话,不懂就说不懂。为啥?基本分已经有了,大好局面来之不易,千万不要不懂装懂暴露问题。比如你之前说的都挺好,然后到优化了把load balancer放到dispatch service还要靠前端的地方,这不扯么?
场景 Scenario
用户在twitter/facebook/weibo上面都干啥?
社交网络是吧,定义一下,是每个用户(人)对社交群体(人)的信息(帖子)分享。
人和帖子,俩基本点,所以说呢?
好友关系,加好友,删好友, (改好友),查好友
帖子关系,加帖子,删帖子,改帖子,查(谁的)帖子
具体点呢?
增删帖子
timeline (所有好友/单个好友的最近N个帖子。为啥N个?一屏放不下,数据发不完)
新闻(理解成厂家小编名义发送的帖子,是为新闻 news feed)
好友管理(增删改查,想到什么了没)
用户管理(登陆、注册、profile)
第二个问题,也没啥说的,
我需要考虑多大的数据量?
《=多大用户量以及用户都怎么用的?
具体下来是这么几个:
- 日活用户多少啊?(How many daily active user(DAU) should I expect)
根据不完全调查,一般来说:
twitter: DAU 10M
facebook: DAU 1.2B
weibo: MAU 340M, DAU 11M
- 每天每个用户要expect多少个新帖子啊,多少次阅读啊?(How many daily new posts/reads should I expect per user)
大坑预警: 不是直接问总共多少个,咱不是产品经理,问每人多少个
twitter/facebook/weibo: 20min *25 read/min = 500 reads per user per day. (亲测差不多) 5 writes per user per day(亲测比这个少,但是自己跟朋友平均下来,这个数字也靠谱)
- 知道这几个数字了,能算QPS了不?
大坑预警:QPS的S是啥?DAU的D是啥?两者啥关系?
一天多少秒?246060 = 86400秒
就先拿weibo来算好了,中国人关注中国企业
Read QPS: 500 * 11,000,000/ 86,400 .= 70K
Write QPS: 5 *11,000,000/86,400 = 700 QPS
啥概念?咱一会儿说 别忘了哈!
实现 Implementation
来 先画图
我的架子怎么搭?
关键点是? 人和帖子?
人需要几个service? 好友管理和用户登陆
帖子需要几个service?帖子管理和大文件存储
所以一共?四个service
User service
每个用户的基本资料
注册 登陆
Posting Service
每个帖子的内容和资料
大坑预警:可别在这里放图片/文件/视频哈,说挂立刻就挂!! 那要放放哪?attachment service 能让别人打架绝不自己动手:)
Friendship Service
放每个用户的好友关系
facebook 你是我好友 我肯定是你好友 双向保存也可以,单向保存也可以
twitter/weibo不一定哦 分关注和被关注,这里到底是保存关注,保存被关注,还是都需要保存,就看具体实现了,设计的时候要有意识
Attachment service 统一存放所有的大文件(图片,视频,pdf 等)
如果多个人有同一个文件 正好!
下一个问题:
数据怎么放?
首先 基本概念,每个service考虑自己的就行。
为啥?做成SOA(Service Oriented Architecture) 不就是为了每个service可以自己做事情么 而且每个service的数据存储模式是不一样的。既然不一样,那就分开放。
下一个问题: 那你倒是放呀?
好好 不着急不着急。。。
User Info: 读远大于写,经典的SQL应用。
Post Info: 内容不定,读写频繁,除时间外无法排序,适合NoSQL
Attachment Info: 大文件 这就没啥可说的,只能放在文件系统里面。
Friendship info: 关系确定(好友呗,最多再分一个类),有时排序,读远大于写。这个就不好说了。你想存SQL也行,你想存NoSQL也行。
关于这几个数据库之间的关系,什么时候该用哪一个。我就将来另写一篇文章说这个问题了。感觉谁都会用到的。
下一个问题: 该有的有了 该存的存了,
流程啥样?
用户注册:没啥可说的,user table里加一个entry
用户注销: 别愣着直接删,标记不活跃就可以了
用户登陆:关键字,不要原样传输密码,不要原样储存密码
发帖:发帖。。。
讲究就大了
单纯发帖好说,post table里面加一个entry。如果有大文件,entry里面自动添加链接,attachment table里面加一个节点或者重用已有文件。
可是我要怎么让关注我的人(不管是单向的还是双向的知道我发帖了呢)?
首先 要想到有两种做法(想到一种不是你的错,但是认为没有别的路就是你要准备好被挂了)
Push model: 用户发帖以后更新自己的记录以外,遍历所有follow自己的人,把这条帖子推送给他们对应的user service。user service 保存推送来的消息,用户显示朋友圈的时候,在接收到的消息里面选取topK个显示。
Pull model: 用户发帖以后更新自己的记录。用户显示朋友圈的时候,把遍历所有自己follow的人拿topN个显示(N和K的关系可以另外算),截取topK个显示。
所有培训机构的图都是有版权的不能用。我给大家放一个不完全准确的图。简单说,这里面都有一个遍历关系。
push:遍历所有follow自己的人,每个人推送自己的更新
pull:遍历所有自己follow的人,每次显示朋友圈的时候询问更新
那我要怎么选择呢?上课都会讲怎么选择的,我们先从各自的优缺点开始。
push:如果follow自己的人不多,省!
pull:如果自己follow的人不多,省!
push:如果自己follow的人不都活跃,省!
pull:如果follow自己的人不都活跃,省!
push:会带来一个特定的问题,叫做惊群效应 就是如果今天王宝强发了一个帖子,我的天爷,大家是不是纷纷点赞纷纷转发纷纷评论,这个如果用push的话,fanout结束怎么也得好几个小时吧?
这个问题为啥难,因为所有的人修改的都是同一个帖子。什么caching,sharding,根本都不管用。我贴的链接不是关于网络系统设计的,是关于计算机系统设计的。这个问题不分软件固件,大家都能碰到。解决的办法说起来也只有慢慢fanout了,只要在用户的视角里面显示自己评论就可以了。
pull:这个问题就不是特定了,为啥,因为王宝强少,看王宝强的人多。不论已婚与否,我们今天基本上男性劳苦大众都是关注的人比被关注的多。所以我们的问题就现打不赊着,如果不做任何优化,我们每次更新都要很慢,因为每次看朋友圈都要二重循环
提高 Enhancement
我自己这个破记性 能够把基本点记下来就不容易了,接下来你说要提高,那我们从提高开始,要记住什么要点呢?
就从奥林匹克精神开始吧。更高咱先不说,先说后面两个
更快:前面分析完了并发性 现在可以开始说说速度了,怎么样更快得到结果,让前端尽可能的不要等?
更强:就是面对可能出现的各种问题是否有更好的准备和更好的解决办法。
接下来我们就一个一个说我这里可能会想到的问题。
我们先说更快,因为基本解来说,更快还是相对比较容易做到的。
我们之前在基本解说了这么多,我们自己每天也都在用社交网络,我们要优化东西,就要牺牲东西。可以牺牲的东西一定是我们不太看重,或者不太感觉得到的东西,对吧?那么我们什么可以牺牲?什么不那么重要?
答案:实时性(Real-time-ness)
为啥?你今天分析你一个交恶的原密友发的不利于你的消息。你就关心他消息是什么时候发出来的,对不对?什么时候到你这里的,只要别太慢,你自己也没感觉,对吧?
所以,只要保证时序性(最先发出来的帖子,最后在用户这里显示是显示在前面的),可以允许有些消息先显示出来,然后等到别人的消息来了再整理就好了。
这样,对于pull来说,就有一个特别好的消息了。 我可以用缓存了。
我先把缓存里面的信息先放出来,然后有消息来了我一点一点加进去(大家用微信看消息是不是就是这个感觉?消息在一点一点的更新?这就是pull+cache的用户体验)
那push呢?
王宝强级别的明星必须用pull,没说的。否则没有别的任何招数。普通人可以用push,反正不伤。
那是吧,我们结合一下,如果明星用pull,普通人用push,是不是就两全其美了呢?
不能说不是,但是会带来新的问题。叫摇摆效应。啥叫摇摆效应?
比如说吧,咱划个线,粉丝一万以上叫明星,一万以下叫普通人
要是有人本来10001个粉丝,今天掉了两个粉,我怎么办?如果明天又涨回来两个粉,我又怎么办?
后台可以在这俩之间切来切去,但是这样不是要反复通知上下游的其他service吗?
解决这个问题的办法来说,比较容易想到的就是设置一个过渡期,先默认是明星,如果普通人变成了明星,立刻改,如果明星变成了普通人,等待一段时间。
下一个问题,取关怎么处理?
还是那句话,你取关谁你看不见就行!
所以我们就可以异步操作,先立刻删除缓存,在本机禁止显示关于被取关好友的消息,然后再异步发送给服务器来删除服务器上的好友记录。
下一个话题, 更强, 也就是不能有东西挂掉
单点failure怎么办?(有一台数据中心或者服务器down了)
一,数据要复制,一份数据不能只放在一个地方(replica)
二,数据要分散,不能所有的数据只放在一个地方(sharding)
如何识别虚假用户?
一,用户举报机制
二,这是一个典型的supervised learning/classification, 用machine learning辅助判断
评分标准
可行解 Work Solution 15%
特定问题 Special Case 20%
分析能力 Analysis 25%
权衡 Trade-off 15%
知识储备 Knowledge 25%
SNAKE分析法
Scenario
哪些功能?Feature/Interface?
Needs
多强的系统?Constrains/Hypothesis/QPS/DAU
Application
主要组成模块?Service/Module
Kilobyte
如何存储数据和访问?Data/Storage/SQL vs. NoSQL/File System/Schema
Evolve
如何进化,解决缺陷,处理问题?Optimize/Special Case
Design a Twitter – 例子
Scenario
Step 1 – Enumerate 罗列功能
Register/Login
User Profile Display/Edit
Upload Image/Video
Search
Post/Share a tweet
Timeline/News Feed
Follow/Unfollow a user
Step 2 – Sort 选出核心功能
Post a tweet
Timeline
News Feed
Follow/Unfollow
Register/Login
Needs
Step 1 – Ask
DAU – Daily Active Users – 日活跃用户数量 – 评价系统牛逼的标准
Twitter: MAU 320M, DAU ~150M+
Read More: http://bit.ly/1Knl0M7
Step 2 – Predict
Concurrent Users – 并发用户
Avg Concurrent Users = 日活跃用户数量 * 每个用户平均请求次数 / 一天多少秒 = 150M * 60 / 86400 ~= 100k
峰值:Peak Users = Avg Concurrent Users * 3 ~ 300k
快速增长的产品:Fast Growing = Peak Users * 2 ~ 600k
Read QPS(Queries Per Second) 读频率:300k
Write QPS(Queries Per Second) 写频率:5k
Application – Service/Module
Receptionist
User Service: Register/Login
Tweet Service: Post a tweet/News Feed/Timeline
Media Service: Upload Picture/Video
Friendship Service: Follow/Unfollow
Replay – 重放需求
Merge – 归并需求
Kilobyte – Data/Storage
基本知识
关系型数据库 SQL Database:User Table
非关系型数据库 NoSQL Database:Tweets, Social Graph (Followers)
文件系统 File System: Images, Videos, other media files
程序 = 算法 + 数据结构
系统 = 服务 + 数据存储
User Service: SQL
Tweet Service: NoSQL
Media Service: File System
Friendship Service: SQL/NoSQL
Select
为每个App/Service选择合适的存储结构
Schema
细化Database结构
Please Design Schema
User Table
userId integer
username varchar
email varchar
password varchar
Friendship Table
relationshipId integer
from_userId foreign key
to_userId foreign key
Tweet Table
tweetId integer
userId foreign key
time timestamp
content text
News Feed 如何存取?
Pull vs. Push (明星问题、僵尸粉问题)
Pull Model
获取每个好友的前k条tweets,合并出k条news feed
K路归并算法:Merge K sorted arrays
假设有N个好友,则时间为 ==>
N次DB Read的时间 + K路归并时间(可忽略)
Post a tweet ==>
1次DB Write的时间
Pull Work Flow 原理图
Client —->send get News Feed request to—-> Server
Server <—-get Following from—-> Friendship Table
Server <—-get Tweets of Followings from—-> Tweet Table
Server —->Merge Tweets and return to—-> Client
Pull模型的缺陷
读取慢(N次DB Reads,非常慢)
发生在用户获得News Feed的请求过程中,有延迟
Push Model
算法
为每个用户建一个List存储他的News Feed;
当他post一个tweet的时候,将该推文逐个推送(Fanout)到每个Follower的List中;
当他查看News Feed时,从List中读取最新的100条即可
复杂度
每次News Feed,只用一次DB Read;
每次Post Tweet,会Fanout到N个Follower,需要N次DB Writes;
不过对于Post Tweet,可以用异步任务后台执行,用户无须等待
postTweet(POST, tweet_info) {
tweet = DB.insertTweet(userId, tweet_info); //userId对应这个用户的News Feed List
AsyncService.fanoutTweet(userId, tweet);
return success;
}
AsyncService::fanoutTweet(userId, tweet) {
followers = DB.getFollowers(userId);
for (follower: followers) {
DB.insertNewsFeed(follower.userId, tweet);
}
}
Push Model的缺陷
postTweet()的异步执行;而fanoutTweet()可能遇到followers数目太大的问题。
Push和Pull的比较
Facebook Pull
Twitter Pull
Instagram Pull + Push
Evolve 优化:Optimize/Maintenance
Step 1: Optimize
Solve Problems: Push vs. Pull; Normalize vs. De-normalize
More Features: Edit; Delete; Media; Ads
Special Cases: 大V,热推,不活跃用户
Step 2: Maintenance
Robust 鲁棒性:如果有一台server/DB挂了怎么处理
Scalability 扩展性:如果有流量暴增,如何扩展
解决Pull的缺陷 DB Reads
在访问DB之前加入Cache;
Cache每个用户的Timeline
N次DB Reads,所以Cache最近的100条
Cache每个用户的News Feed
最近没有Cache过News Feed的用户:归并N个好友每人最近的100条Tweets,取出前100条;
最近Cache过的用户:归并某个时间戳之后的tweets
解决Push的缺陷
浪费更多Disk存储空间
与Pull模型存在Memory中相比,虽然Disk很便宜
其实对于实时性要求而言,Push的效果不如Pull
所以对于不活跃用户,可以采用粉丝排序
follower数目远大于following数目时,加几台push任务的机器
如果加server无法解决:针对长期的fast growing,进行评估,转换push模型为pull模型
Tradeoff:对于明星用户,采用pull;对于普通用户,采用push(朋友圈);
如何实现Follow和Unfollow
Follow之后:异步将他的Timeline合并到你的News Feed中
Unfollow之后:异步将他的Tweets从你的News Feed中移除
异步的好处:用户迅速得到反馈,以为succeess了,无须等待异步操作的真正完成
异步的坏处:如果unfollow之后刷新,发现他的Tweets还在
如何存储Likes
标准化操作:Normalize:两个tables,使用Join操作,时间更多
所以,使用去标准化操作:De-normalize
大V发一条tweet之后的问题
对于同一条数据短时间出现大量请求:
load balancer, sharing, consistent hashing都不是很有效;
加入cache可以完美解决;
Follow Up 1:
Like, Retweet, Comment都会改变该tweet的基本信息,如何更新?
Write through; Write back; Look aside
Follow Up 2:
Cache失效怎么办,例如内存不够或者Cache决策失误,导致tweet
Answer: http://www.cs.utah.edu/~stuts…
While building, maintaining, and evolving our system we have learned the following lessons. (1) Separating cache and persistent storage sys- tems allows us to independently scale them. (2) Features that improve monitoring, debugging and operational ef- ficiency are as important as performance. (3) Managing stateful components is operationally more complex than stateless ones. As a result keeping logic in a stateless client helps iterate on features and minimize disruption. (4) The system must support gradual rollout and roll- back of new features even if it leads to temporary het- erogeneity of feature sets. (5) Simplicity is vital.
How to maintenance? How to scale?
http://blog.gainlo.co/index.php/2016/02/17/system-design-interview-question-how-to-design-twitter-part-1/
http://blog.gainlo.co/index.php/2016/02/17/system-design-interview-question-how-to-design-twitter-part-2/
新浪微博在2014年3月公布的月活跃用户(MAU)已经达到1.43亿,2014年新年第一分钟发送的微博达808298条,如此巨大的用户规模和业务量,需要高可用(HA)、高并发访问、低延时的强大后台系统支撑。
微博平台第一代架构为LAMP架构,数据库使用的MyIsam,后台用的php,缓存为Memcache。
随着应用规模的增长,衍生出的第二代架构对业务功能模块化、服务化、组件化,后台系统从php替换为Java,逐渐形成面向服务的SOA架构,在很长一段时间支撑微博平台业务发展。
在此基础上又经过长时间的重构、线上运行、思索与沉淀,平台形成了第三代架构体系。
我们先看一张微博的核心业务图(如下),是不是非常复杂,但这已经是一个简化的不能再简化的业务图啦,第三代技术体系就是为了保障在微博核心业务上快速、高效、可靠的发布新产品新功能。
第三代技术体系
微博平台的第三代技术体系,使用正交分解法建立模型,在水平方向,采用典型的三级分层模型,即接口层、服务层与资源层,在垂直方向,进一步细分为业务架构、技术架构、监控平台与服务治理平台,接着看一下平台的整体架构图。
水平分层
水平维度的划分,在大中型互联网后台业务系统的设计中非常基础,在平台的每一代技术体系中都有体现,这里还是简单介绍一下,为后续垂直维度的延伸讲解做铺垫:
接口层主要实现与Web页面、移动客户端的接口交互,定义统一的接口规范,平台最核心的三个接口服务分别是内容(Feed)服务、用户关系服务以及通讯服务(单发私信、群发、群聊)。
服务层主要把核心业务模块化、服务化,这里又分为两类服务,一类为原子服务,定义是不依赖任何其他服务的服务模块,比如常用的短链服务、发号器服务都属于这一类,图中使用泳道隔离,表示它们的独立性,另外一类为组合服务,通过各种原子服务和业务逻辑的组合,完成的Composite服务,比如Feed服务、通讯服务除了本身的业务逻辑,还依赖于短链、用户、以及发号器服务。
资源层主要数据模型的存,包含通用的缓存资源Redis和MC,以及持久化数据库存储MySQL、HBase,或者分布式文件系统TFS以及Sina S3服务。
水平分层有一个特点,依赖关系都是从上往下,上层的服务依赖下层,下层的服务不会依赖上层,构建了一种简单直接的依赖关系。
与分层模型对应的,微博系统中的服务器主要包括三种类型:前端机(提供 API 接口服务),队列机(处理上行业务逻辑,主要是数据写入),存储(mc、mysql、mcq、redis 、HBase等)。
垂直延伸技术架构
随着业务架构的发展和优化,平台研发实现了许多卓越的中间件产品,用来支撑核心业务,这些中间件由业务驱动产生,随着技术组件越来越丰富,形成完备的平台技术框架,大大提升了平台的产品研发效率和业务运行稳定性。
区别于水平方向上层依赖下层的关系,垂直方向以技术框架为地基支撑点,向两侧驱动影响业务架构、监控平台、服务治理平台,下面介绍一下其中的核心组件。
接口层Web V4框架
接口框架简化和规范了业务接口开发工作,将通用的接口层功能打包到框架中,采用了Spring的面向切面(AOP)设计理念。接口框架基于jersey 进行二次开发,基于annotation定义接口(url, 参数),内置Auth、频次控制、访问日志、降级功能,支撑接口层监控平台与服务治理,同时还有自动化的Bean-json/xml序列化。
服务层框架
服务层主要涉及RPC远程调用框架以及消息队列框架,这是微博平台在服务层使用最为广泛的两个框架。
MCQ消息队列
消息队列提供一种先入先出的通讯机制,在平台内部,最常见的场景是将数据的落地操作异步写入队列,队列处理程序批量读取并写入DB,消息队列提供的异步机制加快了前端机的响应时间,其次,批量的DB操作也间接的提高了DB操作性能,另外一个应用场景,平台通过消息队列,向搜索、大数据、商业运营部门提供实时数据。
微博平台内部大量使用的MCQ(SimpleQueue Service Over Memcache)消息队列服务,基于MemCache协议,消息数据持久化写入BerkeleyDB,只有get/set两个命令,同时也非常容易做监控(stats queue),丰富的client library,线上运行多年,性能比通用的MQ高很多倍。
Motan RPC框架
微博的Motan RPC服务,底层通讯引擎采用了Netty网络框架,序列化协议支持Hessian和Java序列化,通讯协议支持Motan、http、tcp、mc等,Motan框架在内部大量使用,在系统的健壮性和服务治理方面,有较为成熟的技术解决方案,健壮性上,基于Config配置管理服务实现了High Availability与Load Balance策略(支持灵活的FailOver和FailFast HA策略,以及Round Robin、LRU、Consistent Hash等Load Balance策略),服务治理方面,生成完整的服务调用链数据,服务请求性能数据,响应应时间(Response Time)、QPS以及标准化Error、Exception日志信息。
资源层框架
资源层的框架非常多,有封装MySQL与HBase的Key-List DAL中间件、有定制化的计数组件,有支持分布式MC与Redis的Proxy,在这些方面业界有较多的经验分享,我在这里分享一下平台架构的对象库与SSD Cache组件。
对象库
对象库支持便捷的序列化与反序列化微博中的对象数据,序列化时,将JVM内存中的对象序列化写入在HBase中并生成唯一的ObjectID,当需要访问该对象时,通过ObjectID读取,对象库支持任意类型的对象,支持PB、JSON、二进制序列化协议,微博中最大的应用场景将微博中引用的视频、图片、文章统一定义为对象,一共定义了几十种对象类型,并抽象出标准的对象元数据Schema,对象的内容上传到对象存储系统(Sina S3)中,对象元数据中保存Sina S3的下载地址。
SSDCache
随着SSD硬盘的普及,其优越的IO性能被越来越多的替换传统的SATA和SAS磁盘,常见的应用场景有三种:1)替换MySQL数据库的硬盘,目前社区还没有针对SSD优化的MySQL版本,即使这样,直接升级SSD硬盘也能带来8倍左右的IOPS提升;2)替换Redis的硬盘,提升其性能;3)用在CDN中,加快静态资源加载速度。
微博平台将SSD应用在分布式缓存场景中,将传统的Redis/MC + Mysql方式,扩展为 Redis/MC + SSD Cache + Mysql方式,SSD Cache作为L2缓存使用,第一降低了MC/Redis成本过高,容量小的问题,也解决了穿透DB带来的数据库访问压力。
垂直的监控与服务治理
随着服务规模和业务变得越来越复杂,即使业务架构师也很难准确的描述服务之间的依赖关系,服务的管理运维变得越来难,在这个背景下,参考google的dapper和twitter的zipkin,平台实现了自己的大型分布式追踪系统WatchMan。
WatchMan大型分布式追踪系统
如其他大中型互联网应用一样,微博平台由众多的分布式组件构成,用户通过浏览器或移动客户端的每一个HTTP请求到达应用服务器后,会经过很多个业务系统或系统组件,并留下足迹(footprint)。但是这些分散的数据对于问题排查,或是流程优化都帮助有限。对于这样一种典型的跨进程/跨线程的场景,汇总收集并分析这类日志就显得尤为重要。另一方面,收集每一处足迹(footprint)的性能数据,并根据策略对各子系统做流控或降级也是确保微博平台高可用的重要因素。要能做到追踪每个请求的完整调用链路;收集调用链路上每个服务的性能数据;能追踪系统中所有的Error和Exception;通过计算性能数据和比对性能指标(SLA)再回馈到控制流程(control flow)中,基于这些目标就诞生了微博的Watchman系统。
其系统设计一个核心原则就是低侵入性(non-invasivenss):作为非业务组件,应当尽可能少侵入或者不侵入其他业务系统,保持对使用方的透明性,可以大大减少开发人员的负担和接入门槛。基于此考虑,所有的日志采集点都分布在技术框架中间件中,包括接口框架、RPC框架以及其他资源中间件。
WatchMan由技术团队搭建框架,应用在所有业务场景中,运维基于此系统完善监控平台,业务和运维共同使用此系统,完成分布式服务治理,包括服务扩容与缩容,服务降级,流量切换,服务发布与灰度。
微博发布模式
同步推模式
早期的架构中,用户发表微博后,系统会立即将这条微博插入到数据库所有分析的订阅列表中。当用户量较大时,特别是明星用户发布微博时,会引起大量的数据库写操作,系统性能急剧下降,发布微博延迟加剧。
异步推拉模式
用户发表微博后,系统将微博写入消息队列后立即返回,用户响应迅速。消息队列的消费者任务将微博推送给所有当前在线的粉丝的订阅列表中,非在线用户在登录后再根据关注列表拉去微博订阅列表。
我们再看一下目前即将推出的微博平台的新架构。我们知道API大部分的请求都为了获取最新的数据。API请求有一个特点,它大目前调用都是空返回的,比如说一款手机的客户端每隔一分钟它都要调用服务器一下,就是有没有新数据,大目前的调用都是空返回,就是说不管服务器有没有数据都要调用一次。这次询问到下一次询问中间,如果有新的数据来了,你是不会马上知道的。因此我们想API能不能改用推的方式,就是客户端不需要持续的调用,如果有新数据就会推过去。技术特点,显而易见低延迟,就是从发表到接受1秒内完成,实际上可能用不了1秒。然后服务端的连接就是高并发长连接服务,就是多点都连接在我们的服务器上,这个比传统的API要大。
我们再看一下内部细节,就是我们收到数据之后首先要经过最上面RECEIVER。然后推到我们的引擎里面,这个引擎会做两个事情,首先会把用户的关系拿过来,然后按照用户关系马上推送给他相应的粉丝。所以我们调用方已经在那儿等待了,我们需要有一个唤醒操作,就是说在接口这儿把它唤醒,然后把它发送过去。最后是一个高并发的长连服务器,就是一台服务器支持10万以上的并发连接。最右边中间有一个圆圈叫做Stream Buffer,我们需要Stream Buffer是要保存用户最近的数据。因为用户可能会有断线的,比如说他发送数据的时候断线半分钟,我们需要把这半分钟补给他。这就是我们的推送架构。
第二部分:设计原则
用户规模影响设计,具体是指用户数每上一个数量级,许多设计需要重新考虑。
10万用户级别
单服务器,前端、后端、cache、db在一起。
百万级
db和cache单独部署服务器,db或按业务进行拆分(sharding)。
cache或使用一致性hash扩展。
前端后端还是在一起,但是根据业务拆分,每个业务可分配不同数量的服务器
千万级
开始重视架构设计,有专门技术架构师
需跨机房部署,前端在远程增加反向代理加速,数据库在异地机房使用slave数据库副本
后端拆分出来,系统内部需要远程调用,内部需远程调用协议。
亿级
架构更细分,或增加数据架构师,cache架构师,分布式架构师
数据库sharding碰到烦恼,开始考虑分布式数据服务
数据访问需要根据业务特点细分。
开发、运维、测量、调优具备有自己的专有工具。
所有服务需要地理多机房分布,具备IDC容灾设计。
服务可降级
