drool rete 算法
1 产生背景
企业级管理者可能会在系统生产过程中调整生产策略、物料采购策略等,因此对企业IT系统的开发有着如下的要求:
为提高效率,管理流程必须自动化,即使现代商业规则异常复杂。
市场要求业务规则经常变化,IT系统必须依据业务规则的变化快速、低成本的更新。
为了快速、低成本的更新,业务人员应能直接管理IT系统中的规则,不需要程序开发人员参与。
而项目开发人员则碰到了以下问题:
程序=算法+数据结构,有些复杂的商业规则很难推导出算法和抽象出数据模型
软件工程要求从需求->设计->编码,然而业务规则常常在需求阶段可能还没有明确,在设计和编码后还在变化,业务规则往往嵌在系统各处代码中
对程序员来说,系统已经维护、更新困难,更不可能让业务人员来管理。
因此迫切需要分离商业决策者的商业决策逻辑和应用开发者的技术决策。把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时(即商务时间)可以动态地管理和修改从而提供软件系统的柔性和适应性。
规则引擎正是应用于上述动态环境中的一种解决方法。
2 定义
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据规则做出业务决策。
3 原理
规则引擎可以在系统工作时,将外部的业务规则加载到系统中,并使得系统按照该业务规则进行工作。接下来我们分别进行介绍。
3.1 业务规则
一个业务规则包含一组条件和在此条件下执行的操作,它们表示业务规则应用程序的一段业务逻辑。业务规则通常应该由业务分析人员和策略管理者开发和修改,但有些复杂的业务规则也可以由技术人员使用面向对象的技术语言或脚本来定制。业务规则的理论基础是:设置一个或多个条件,当满足这些条件时会触发一个或多个操作。
3.2 规则引擎的功能
由于规则引擎是软件组件,所以只有开发人员才能够通过程序接口的方式来使用和控制它,规则引擎的程序接口至少包含以下几种API:
加载和卸载规则集的API;
数据操作的API;
引擎执行的API。
开发人员在程序中使用规则引擎基本遵循以下5个典型的步骤:
创建规则引擎对象;
向引擎中加载规则集或更换规则集;
向引擎提交需要被规则集处理的数据对象集合;
命令引擎执行;
导出引擎执行结果,从引擎中撤出处理过的数据。
使用了规则引擎之后,许多涉及业务逻辑的程序代码基本被这五个典型步骤所取代。一个开放的业务规则引擎应该可以”嵌入”在应用程序的任何位置,不同位置的规则引擎可以使用不同的规则集,用于处理不同的数据对象。
此外,对使用引擎的数量没有限制。
3.3 规则引擎的架构
规则引擎的架构如下图所示:
规则引擎架构
规则引擎的推理步骤如下:
将初始数据(fact)输入至工作内存(Working Memory)。
使用Pattern Matcher将规则库(Rules repository)的规则(rule)和数据(fact)比较。
如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。
解决冲突,将激活的规则按顺序放入Agenda。
执行Agenda中的规则。
重复步骤2至5,直到执行完毕Agenda中的所有规则。
任何一个规则引擎都需要很好地解决规则的推理机制和规则条件匹配的效率问题。
当引擎执行时,会根据规则执行队列中的优先顺序逐条执行规则执行实例,由于规则的执行部分可能会改变工作区的数据对象,从而会使队列中的某些规则执行实例因为条件改变而失效,必须从队列中撤销,也可能会激活原来不满足条件的规则,生成新的规则执行实例进入队列。
于是就产生了一种”动态”的规则执行链,形成规则的推理机制。这种规则的”链式”反应完全是由工作区中的数据驱动的。
规则条件匹配的效率决定了引擎的性能,引擎需要迅速测试工作区中的数据对象,从加载的规则集中发现符合条件的规则,生成规则执行实例。
1982年美国卡耐基·梅隆大学的Charles L. Forgy发明了一种叫Rete算法,很好地解决了这方面的问题。目前世界顶尖的商用业务规则引擎产品基本上都使用Rete算法。
对于Rete算法,网络上有很多资料,理解起来不是太复杂。本文以介绍框架为主,因此不再详述。其中接下来要介绍的Drools也使用了Rate算法。
4 规则引擎框架
Java规则引擎主要有JRules/Drools/JLisa/QuickRules等。我们以开源项目Drools进行介绍。
Drools是用Java语言编写的开放源码规则引擎,使用Rete算法对所编写的规则求值。Drools允许使用声明方式表达业务逻辑。可以使用非XML的本地语言编写规则,从而便于学习和理解。
并且,还可以将Java代码直接嵌入到规则文件中,这令Drools的学习更加吸引人。Drools有如下特点;
完整的实现了Rete算法;
提供了强大的Eclipse Plugin开发支持;
通过使用其中的DSL(Domain Specific Language),可以实现用自然语言方式来描述业务规则,使得业务分析人员也可以看懂业务规则代码;
提供了基于WEB的BRMS——Guvnor,Guvnor提供了规则管理的知识库,通过它可以实现规则的版本控制,及规则的在线修改与编译,使得开发人员和系统管理人员可以在线管理业务规则。
规则引擎的原理简图如下:
规则引擎原理简图
Drools规则文件有一个或多个rule声明。每个rule声明由一个或多个conditional元素以及要执行的一个或多个consequences或actions组成。
一个规则文件还可以有多个(即0个或多个)import声明、多个global声明以及多个 function 声明。下面我们看一个规则文件的示例:
rule “Tests for type1 machine”
salience 100
when
machine : Machine( type == “Type1” )
then
Test test1 = testDAO.findByKey(Test.TEST1);
Test test2 = testDAO.findByKey(Test.TEST2);
Test test5 = testDAO.findByKey(Test.TEST5);
machine.getTests().add(test1);
machine.getTests().add(test2);
machine.getTests().add(test5);
insert( test1 );
insert( test2 );
insert( test5 );
end
其中:
rule 声明有一个惟一标识它的 name
salience属性可以让规则执行引擎知道应该启动规则的结果语句的顺序。
when 关键词定义规则中的条件块
then 关键词定义结果块。当其上部的条件满足时,该结果块的规则被执行。
因此,整个规则的定义非常简单,便于使用。
https://zhuanlan.zhihu.com/p/51296996
规则引擎drools的rete算法实现原理和事实匹配过程
4、drools源码,一个事实匹配规则过程的原理介绍
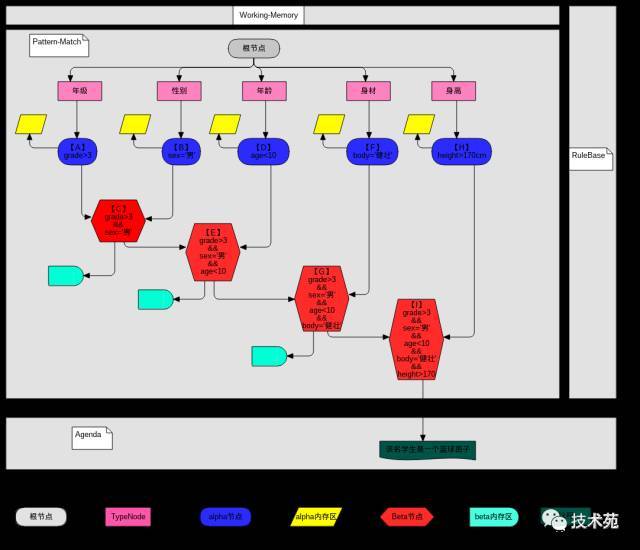
一个Fact通过Session添加到规则网络中,如何进行规则匹配的大致过程如下:
(1)、通过根结点对象从EntryPointNode的Map集合中找到相应的EntryPointNode对象;
(2)、EntryPointNode对象有一个ObjectTypeNode的Map集合,把fact的class转化成ClassObjectType,从该集合中找到ObjectTypeNode;
(3)、OjectTypeNode对象的sink属性引用着这个fact事实的规则网络;
(4)、从sink属性中的链表中拿出一个alphaNode进行匹配,递归遍历所有alphaNode的子节点(sink属性),根据alphaNode中的条件对Fact数据进行比较。
==>(向下(子节点)是试图完整匹配一条规则),如果向下有不匹配的,表示该规则不符合当前fact,退出递归,开始向右匹配。
==>(向右(nextRightTupleSinkNode属性)开始试图匹配另一条规则)。
===>向下(当前AlphaNode子节点代表的规则的所有条件模式)匹配,如果所有的子节点alphaNode中隐藏的条件都符合, 则完全匹配一条规则,形成议程加入冲突集合,待匹配完所有的规则,再根据规则的优先级执行匹配上的规则的结果部分,更改Fact的数据。
===>向右(进行另一个规则的匹配),如果所有的子节点alphaNode中隐藏的条件都符合,则完全匹配一条规则,形成议程加入冲突集合,待匹配完所有的规则,再根据规则的优先级执行匹配上的规则的结果部分,更改Fact的数据。
https://cloud.tencent.com/developer/article/1477434
Rete 算法是卡内基梅隆大学的 Charles L.Forgy 博士在 1974 年发表的论文中所阐述的算法。 该算法提供了专家系统的一个高效实现。
Rete 在拉丁语中译为”net”(即网络)。Rete 是一种进行大量模式集合和大量对象集合间比较的高效方法,通过网络筛选的方法找出所有匹配各个模式的对象和规则。
其核心思想是用分离的匹配项构造匹配网络,同时缓存中间结果。以空间换时间。规则编译(rule compilation)和运行时执行(runtime execution)。
- 规则编译(rule compilation)
规则编译是指根据规则集生成高效推理网络的过程
2.1. 相关概念:
Fact(事实):对象之间及对象属性之间的关系
Rule(规则):是由条件和结论构成的推理语句,一般表示为if…Then。一个规则的if部分称为LHS(left-hand-side),then部分称为RHS(right hand side)。
Module(模式):就是指IF语句的条件。这里IF条件可能是有几个更小的条件组成的大条件。模式就是指的不能在继续分割下去的最小的原子条件。
https://www.jianshu.com/p/3e9afe9e0617
https://github.com/mmavcy/reteonstorm
ETE的优点在于:
通过节点共享(node sharing)减少了规则中重复模式(pattern)的计算;
存储了部分匹配fact联合join匹配的结果,这样当facts少量变化时,免去未变化的计算量。
了解优点后,我们也很容易总结发现RETE相对于传统的线性匹配的优势点或优化场景在于:
大量规则(规则间具有某些重复pattern的情况),少量变化(规则判定的facts不是每次都重新assert)
在这样的场景下RETE规则匹配算法会得到更好的效果,这对规则的设计与开发者是有些指导意义的。
https://blog.abstiger.com/introduce-rete-algorithm/
http://reports-archive.adm.cs.cmu.edu/anon/1995/CMU-CS-95-113.pdf
http://clipsrules.sourceforge.net/
https://www.drools.org/
https://github.com/kiegroup/drools
https://docs.jboss.org/drools/release/6.0.0.Beta5/drools-expert-docs/html/ch01.html#d0e515
https://www.xttblog.com/?p=2632
规则引擎的优点
声明式编程
规则可以很容易地解决困难的问题,并得到解决方案的验证。与代码不同,规则以较不复杂的语言编写; 业务分析师可以轻松阅读和验证一套规则。
逻辑和数据分离
数据位于“域对象”中,业务逻辑位于“规则”中。根据项目的种类,这种分离是非常有利的。
速度和可扩展性
写入Drools的Rete OO算法已经是一个成熟的算法。在Drools的帮助下,您的应用程序变得非常可扩展。如果频繁更改请求,可以添加新规则,而无需修改现有规则。
知识集中化
通过使用规则,您创建一个可执行的知识库(知识库)。这是商业政策的一个真理点。理想情况下,规则是可读的,它们也可以用作文档。
https://www.jianshu.com/p/e713860b128e
https://cloud.tencent.com/developer/article/1015427
Grule is a Rule Engine library for the Golang programming language. Inspired by the acclaimed JBOSS Drools, done in a much simple manner.
https://github.com/hyperjumptech/grule-rule-engine
https://github.com/hyperjumptech/grule-rule-engine/blob/master/docs/RuleEngine_en.md
https://github.com/hyperjumptech/grule-rule-engine/blob/master/docs/Tutorial_en.md
https://github.com/hyperjumptech/grule-rule-engine/blob/master/docs/RETE_en.md
