ceph的CRUSH数据分布算法
CRUSH全称Controlled Replication Under Scalable Hashing,是一种数据分发算法,类似于哈希和一致性哈希。哈希的问题在于数据增长时不能动态加Bucket,一致性哈希的问题在于加Bucket时数据迁移量比较大,其他数据分发算法依赖中心的Metadata服务器来存储元数据效率较低,CRUSH则是通过计算、接受多维参数的来解决动态数据分发的场景。
数据分布算法面临了几个挑战:
数据分布和负载的均衡。数据分布的均衡是指算法要能够将数据均匀的存储到各个节点和磁盘上。负载均衡指的是数据的访问的等操作的负载在各个节点之间负载均衡。 扩展性和高可用性。系统方便的增加或者删除存储设备。当增删设备之后,数据恢复和数据迁移,将会使得数据重新均衡,算法需要是这样的移动、迁移的数据量尽可能的少。 支持大规模集群。为了支持大规模的存储集群,要求数据分布算法维护的元数据要相对较小,且计算量不能太大。
传统的存储使用数据中心式的元数据/索引表来保存有关客户端的数据如何存放的问题。而Ceph使用CRUSH按需计算出元数据,因此它消除了对中心式的服务器/网关的需求(去中心化)。
Ceph设计了CRUSH(一个可扩展的伪随机数据分布算法),用在分布式对象存储系统上,可以有效映射数据对象到存储设备上(不需要中心设备)。因为大型系统的结构式动态变化的,CRUSH能够处理存储设备的添加和移除,并最小化由于存储设备的的添加和移动而导致的数据迁移。
CRUSH有两个关键优点:
任何组件都可以独立计算出每个object所在的位置(去中心化)。 只需要很少的元数据(cluster map),只要当删除添加设备时,这些元数据才需要改变。
CRUSH 算法的基本原理
CRUSH算法全称为可控的、可扩展的、分布式的副本数据放置算法。
CRUSH算法解决的是PG如何映射到OSD列表中的问题,也就是 给定一个输入x,CRUSH 算法将输出一个确定的有序的储存目标向量 ?R 。其中x为要计算的PG的pg _id,存储向量列表就是OSD列表,即选择的OSD,这些OSD通常都会在不同的故障域。
CRUSH(x)-> (OSD1,OSD2,…,OSDn)
当输入x,CRUSH利用强大的多重整数hash函数根据Hierachical Cluster Map(集群的拓扑结构)、Placement Rules(定位规则、选择策略)、以及x计算出独立的完全确定可靠的映射关系。
随着大规模分布式系统的出现,系统必须能够平均的分布数据和负载,最大化系统的利用率,并且能够处理系统的扩展和系统故障。一般的分布式系统都会采用一个或者多个中心服务用来控制数据的分布,这种机制使得每次IO操作都会先去一个地方查询数据在集群中的元数据信息。当集群的规模变大或者系统的workload比较大时,这些中心服务器必然会成为性能上的瓶颈。Ceph摒弃了这种做法,而是通过引入CRUSH算法,将数据分布的查询操作变成了计算操作,并且是在client端完成。
CRUSH是受控复制的分布式hash算法,是ceph里面用于控制数据分布的一种方法,能够高效稳定的将数据分布在普通的结构化的集群中。它是一种伪随机的算法,在相同的环境下,相似的输入得到的结果之间没有相关性,相同的输入得到的结果是确定的。它只需要一个集群的描述地图和一些规则就可以根据一个整型的输入得到存放数据的一个设备列表。Client在有IO操作的时候,可能会执行CRUSH算法。
随着大规模分布式系统的出现,系统必须能够平均的分布数据和负载,最大化系统的利用率,并且能够处理系统的扩展和系统故障。一般的分布式系统都会采用一个或者多个中心服务用来控制数据的分布,这种机制使得每次IO操作都会先去一个地方查询数据在集群中的元数据信息。当集群的规模变大或者系统的workload比较大时,这些中心服务器必然会成为性能上的瓶颈。Ceph摒弃了这种做法,而是通过引入CRUSH算法,将数据分布的查询操作变成了计算操作,并且是在client端完成。
CRUSH是受控复制的分布式hash算法,是ceph里面用于控制数据分布的一种方法,能够高效稳定的将数据分布在普通的结构化的集群中。它是一种伪随机的算法,在相同的环境下,相似的输入得到的结果之间没有相关性,相同的输入得到的结果是确定的。它只需要一个集群的描述地图和一些规则就可以根据一个整型的输入得到存放数据的一个设备列表。Client在有IO操作的时候,可能会执行CRUSH算法。
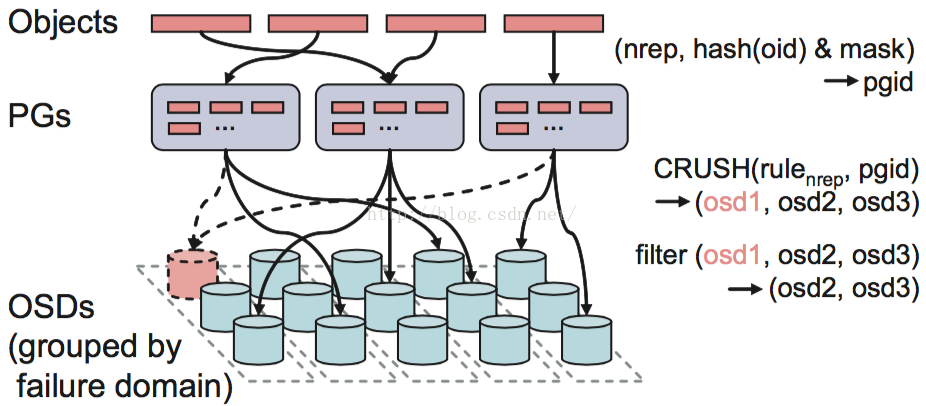
Ceph的后端是一个对象存储(RADOS),所以所有的数据都会按照一个特定的size(ceph系统默认是4M)被切分成若干个对象,也就是上面的Objects。每一个Object都有一个Objectid(oid),Objectid的命名规则是数据所在image的block_name_prefix再跟上一个编号,这个编号是顺序递增的。通过(poolid, hash(oid) & mask),每个object都可以得到它对应的pgid。有了这个pgid之后,Client就会执行CRUSH算法得到一个OSD列表(OSD1,OSD2,OSD3)。然后对它们进行筛选,根据副本数找出符合要求的OSD,比如OSD不能是failed、overloaded的。知道数据要存在哪些OSD上之后,Client会向列表中的第一个OSD(primary osd)发起IO请求。然后这个OSD按照读写请求分别做相应的处理。
所以一句话说明CRUSH的作用就是,根据pgid得到一个OSD列表。
CRUSH算法
Ceph分布数据的过程:首先计算数据x的Hash值并将结果和PG数目取余,以得到数据x对应的PG编号。然后,通过CRUSH算法将PG映射到一组OSD中。最后把数据x存放到PG对应的OSD中。这个过程中包含了两次映射,第一次是数据x到PG的映射。如果把PG当作存储节点,那么这和文章开头提到的普通Hash算法一样。不同的是,PG是抽象的存储节点,它不会随着物理节点的加入或则离开而增加或减少,因此数据到PG的映射是稳定的。
在这个过程中,PG起到了两个作用:第一个作用是划分数据分区。每个PG管理的数据区间相同,因而数据能够均匀地分布到PG上;第二个作用是充当Dyanmo中Token的角色,即决定分区位置。实际上,这和Dynamo中固定分区数目,以及维持分区数目和虚拟节点数目相等的原则是同一回事。
在没有多副本的情况下,Dynamo中分区的数据直接存储到Token,而每个Token对应唯一的一个物理存储节点。在多副本(假设副本数目为N)的情况下,分区的数据会存储到连续的N个Token中。但这会引入一个新问题:因为副本必须保持在不同的物理节点,但是如果这组Token中存在两个或多个Token对应到同个物理存储节点,那么就必须要跳过这样的节点。Dynamo采用Preference列表来记录每个分区对应的物理节点。然而,Dynmao论文中没有详述分区的Preference列表如何选取物理节点,以及选取物理节点时该如何隔离故障域等问题。
(osd0, osd1, osd2 … osdn) = CRUSH(x)
Ceph的PG担当起Dynamo中Token、固定分区以及Preference列表的角色,解决的是同样的问题。PG的Acting集合对应于Dynamo的Preference列表。CRUSH算法解决了Dynamo论文中未提及的问题。
OSD层级结构和权重大小
CRUSH算法的目的是,为给定的PG(即分区)分配一组存储数据的OSD节点。选择OSD节点的过程,要考虑以下几个因素:
1) PG在OSD间均匀分布。假设每个OSD的磁盘容量都相同,那么我们希望PG在每个OSD节点上是均匀分布的,也就是说每个OSD节点包含相同数目的PG。假如节点的磁盘容量不等,那么容量大的磁盘的节点能够处理更多数量的PG。
2) PG的OSD分布在不同的故障域。因为PG的OSD列表用于保存数据的不同副本,副本分布在不同的OSD中可以降低数据损坏的风险。
Ceph使用树型层级结构描述OSD的空间位置以及权重(同磁盘容量相关)大小。如上图所示,层级结构描述了OSD所在主机、主机所在机架以及机架所在机房等空间位置。这些空间位置隐含了故障区域,例如使用不同电源的不同的机架属于不同的故障域。CRUSH能够依据一定的规则将副本放置在不同的故障域。
OSD节点在层级结构中也被称为Device,它位于层级结构的叶子节点,所有非叶子节点称为Bucket。Bucket拥有不同的类型,如上图所示,所有机架的类型为Rack,所有主机的类型为Host。使用者还可以自己定义Bucket的类型。Device节点的权重代表存储节点的性能,磁盘容量是影响权重大小的重要参数。Bucket节点的权重是其子节点的权重之和。
CRUSH通过重复执行Take(bucketID)和Select(n, bucketType)两个操作选取副本位置。Take(bucketID)指定从给定的bucketID中选取副本位置,例如可以指定从某台机架上选取副本位置,以实现将不同的副本隔离在不同的故障域; Select(n, bucketType)则在给定的Bucket下选取n个类型为bucketType的Bucket,它选取Bucket主要考虑层级结构中节点的容量,以及当节点离线或者加入时的数据迁移量。
