分布式系统常用思想和技术总结
一、分布式系统的难点
分布式系统比起单机系统存在哪些难点呢?
网络因素
由于服务和数据分布在不同的机器上,每次交互都需要跨机器运行,这带来如下几个问题:
网络延迟:性能、超时
同机房的网络IO还是比较块的,但是跨机房,尤其是跨IDC,网络IO就成为不可忽视的性能瓶颈了。并且,延迟不是带宽,带宽可以随便增加,千兆网卡换成万兆,只是成本的问题,但延迟是物理限制,基本不可能降低。
这带来的问题就是系统整体性能的降低,会带来一系列的问题,比如资源的锁住,所以系统调用一般都要设置一个超时时间进行自我保护,但是过度的延迟就会带来系统的RPC调用超时,引发一个令人头疼的问题:分布式系统调用的三态结果:成功、失败、超时。不要小看这个第三态,这几乎是所有分布式系统复杂性的根源。
针对这个问题有一些相应的解决方案:异步化,失败重试。 而对于跨IDC数据分布带来的巨大网络因素影响,则一般会采用数据同步,代理专线等处理方式。
网络故障:丢包、乱序、抖动。
这个可以通过将服务建立在可靠的传输协议上来解决,比如TCP协议。不过带来的是更多的网络交互。因此是性能和流量的一个trade off。这个在移动互联网中更需要考虑。
鱼与熊掌不可兼得——CAP定律
CAP理论是由Eric Brewer提出的分布式系统中最为重要的理论之一:
Consistency:[强]一致性,事务保障,ACID模型。
Availiablity:[高]可用性,冗余以避免单点,至少做到柔性可用(服务降级)。
Partition tolerance:[高]可扩展性(分区容忍性):一般要求系统能够自动按需扩展,比如HBase。
CAP原理告诉我们,这三个因素最多只能满足两个,不可能三者兼顾。对于分布式系统来说,分区容错是基本要求,所以必然要放弃一致性。对于大型网站来说,分区容错和可用性的要求更高,所以一般都会选择适当放弃一致性。对应CAP理论,NoSQL追求的是AP,而传统数据库追求的是CA,这也可以解释为什么传统数据库的扩展能力有限的原因。
在CAP三者中,“可扩展性”是分布式系统的特有性质。分布式系统的设计初衷就是利用集群多机的能力处理单机无法解决的问题。当需要扩展系统性能时,一种做法是优化系统的性能或者升级硬件(scale up),一种做法就是“简单”的增加机器来扩展系统的规模(scale out)。好的分布式系统总在追求”线性扩展性”,即性能可以随集群数量增长而线性增长。
可用性和可扩展性一般是相关联的,可扩展行好的系统,其可用性一般会比较高,因为有多个服务(数据)节点,不是整体的单点。所以分布式系统的所有问题,基本都是在一致性与可用性和可扩展性这两者之间的一个协调和平衡。对于没有状态的系统,不存在一致性问题,根据CAP原理,它们的可用性和分区容忍性都是很高,简单的添加机器就可以实现线性扩展。而对于有状态的系统,则需要根据业务需求和特性在CAP三者中牺牲其中的一者。一般来说,交易系统类的业务对一致性的要求比较高,一般会采用ACID模型来保证数据的强一致性,所以其可用性和扩展性就比较差。而其他大多数业务系统一般不需要保证强一致性,只要最终一致就可以了,它们一般采用BASE模型,用最终一致性的思想来设计分布式系统,从而使得系统可以达到很高的可用性和扩展性。
CAP定律其实也是衡量分布式系统的重要指标,另一个重要的指标是性能。
一致性模型
主要有三种:
Strong Consistency(强一致性):新的数据一旦写入,在任意副本任意时刻都能读到新值。比如:文件系统,RDBMS,Azure Table都是强一致性的。
Week Consistency(弱一致性):不同副本上的值有新有旧,需要应用方做更多的工作获取最新值。比如Dynamo。
Evantual Consistency(最终一致性):一旦更新成功,各副本的数据最终将达到一致。
从这三种一致型的模型上来说,我们可以看到,Weak和Eventually一般来说是异步冗余的,而Strong一般来说是同步冗余的(多写),异步的通常意味着更好的性能,但也意味着更复杂的状态控制。同步意味着简单,但也意味着性能下降。
以及其他变体:
Causal Consistency(因果一致性):如果Process A通知Process B它已经更新了数据,那么Process B的后续读取操作则读取A写入的最新值,而与A没有因果关系的C则可以最终一致性。
Read-your-writes Consistency(读你所写一致性):如果Process A写入了最新的值,那么 Process A的后续操作都会读取到最新值。但是其它用户可能要过一会才可以看到。
Session Consistency(会话一致性):一次会话内一旦读到某个值,不会读到更旧的值。
Monotonic Read Consistency(单调一致性):一个Process 一旦读到某个值,不会读到比这个值更旧的值,其他Process 不一定。
Monotonic Write onsistency(单调写一致性):来自同一Process 的写操作被顺序地执行
等等。
其中最重要的变体是第二条:Read-your-Writes Consistency。特别适用于数据的更新同步,用户的修改马上对自己可见,但是其他用户可以看到他老的版本。Facebook的数据同步就是采用这种原则。
二、分布式系统常用技术和应用场景
consistent hashing [with virtual node]:一致性哈希,数据分布
vector clock:时钟向量,多版本数据修改
Quorum W+R>N [with vector clock]:抽屉原理,数据一致性的另一种解决方案。时钟向量,多版本数据修改。
Merkle tree [with anti-entropy]:数据复制
MVCC:copy-on-write与snapshot
2PC/3PC:分布式事务
Paxos:强一致性协议
Symmetry and Decentralization:对称性和去中心化。对称性(symmetry)简化了系统的配置和维护。去中心化是对对称性的延伸,可以避免master单点,同时方便集群scale out。
Map-Reduce:分而治之;移动数据不如移动计算。将计算尽量调度到与存储节点在同一台物理机器上的计算节点上进行,这称之为本地化计算。本地化计算是计算调度的一种重要优化。
Gossip协议:节点管理
Lease机制:
consistent hashing:一致性哈希,解决数据均衡分布问题
我们通常使用的hash算法是hash() mod n,但是如果发生某个节点失效时,无法快速切换到其他节点。为了解决单点故障的问题,我们为每个节点都增加一个备用节点,当某个节点失效时,就自动切换到备用节点上,类似于数据库的master和slave。但是依然无法解决增加或删除节点后,需要做hash重分布的问题,也就是无法动态增删节点。这时就引入了一致性hash的概念 ,将所有的节点分布到一个hash环上,每个请求都落在这个hash环上的某个位置,只需要按照顺时针方向找到的第一个节点,就是自己需要的服务节点。当某个节点发生故障时,只需要在环上找到下一个可用节点即可。
consistent hashing
一致性hash算法最常用于分布式cache中,比如注意的memcached。Dynamo也用其作为数据分布算法,并且对一致性算法进行了改进,提出了基于虚拟节点的改进算法,其核心思路是引入虚拟节点,每个虚拟节点都有一个对应的物理节点,而每个物理节点可以对应若干个虚拟节点。
virtual node
前面说过,有的Consistent Hashing的实现方法采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
Quorum W+R>N:抽屉原理,NWR模型,数据一致性的另一种解决方案
Amazon Dynamo的NWR模型。这个NWR模型把CAP的选择权交给了用户,让用户自己的选择你的CAP中的哪两个。所谓NWR模型。N代表N个备份,W代表要写入至少W份才认为成功,R表示至少读取R个备份。配置的时候要求W+R > N。 因为W+R > N, 所以 R > N-W 这个是什么意思呢?就是读取的份数一定要比总备份数减去确保写成功的倍数的差值要大。
也就是说,每次读取,都至少读取到一个最新的版本。从而不会读到一份旧数据。当我们需要高可写的环境的时候,我们可以配置W = 1 如果N=3 那么R = 3。 这个时候只要写任何节点成功就认为成功,但是读的时候必须从所有的节点都读出数据。如果我们要求读的高效率,我们可以配置 W=N R=1。这个时候任何一个节点读成功就认为成功,但是写的时候必须写所有三个节点成功才认为成功。
NWR模型的一些设置会造成脏数据的问题,因为这很明显不是像Paxos一样是一个强一致的东西,所以,可能每次的读写操作都不在同一个结点上,于是会出现一些结点上的数据并不是最新版本,但却进行了最新的操作。
所以,Amazon Dynamo引了数据版本的设计。也就是说,如果你读出来数据的版本是v1,当你计算完成后要回填数据后,却发现数据的版本号已经被人更新成了v2,那么服务器就会拒绝你。版本这个事就像“乐观锁”一样。
但是,对于分布式和NWR模型来说,版本也会有恶梦的时候——就是版本冲的问题,比如:我们设置了N=3 W=1,如果A结点上接受了一个值,版本由v1 -> v2,但还没有来得及同步到结点B上(异步的,应该W=1,写一份就算成功),B结点上还是v1版本,此时,B结点接到写请求,按道理来说,他需要拒绝掉,但是他一方面并不知道别的结点已经被更新到v2,另一方面他也无法拒绝,因为W=1,所以写一分就成功了。于是,出现了严重的版本冲突。
Amazon的Dynamo把版本冲突这个问题巧妙地回避掉了——版本冲这个事交给用户自己来处理。
于是,Dynamo引入了Vector Clock(矢量钟?!)这个设计。这个设计让每个结点各自记录自己的版本信息,也就是说,对于同一个数据,需要记录两个事:1)谁更新的我,2)我的版本号是什么。
下面,我们来看一个操作序列:
1)一个写请求,第一次被节点A处理了。节点A会增加一个版本信息(A,1)。我们把这个时候的数据记做D1(A,1)。 然后另外一个对同样key的请求还是被A处理了于是有D2(A,2)。这个时候,D2是可以覆盖D1的,不会有冲突产生。
2)现在我们假设D2传播到了所有节点(B和C),B和C收到的数据不是从客户产生的,而是别人复制给他们的,所以他们不产生新的版本信息,所以现在B和C所持有的数据还是D2(A,2)。于是A,B,C上的数据及其版本号都是一样的。
3)如果我们有一个新的写请求到了B结点上,于是B结点生成数据D3(A,2; B,1),意思是:数据D全局版本号为3,A升了两新,B升了一次。这不就是所谓的代码版本的log么?
4)如果D3没有传播到C的时候又一个请求被C处理了,于是,以C结点上的数据是D4(A,2; C,1)。
5)好,最精彩的事情来了:如果这个时候来了一个读请求,我们要记得,我们的W=1 那么R=N=3,所以R会从所有三个节点上读,此时,他会读到三个版本:
A结点:D2(A,2)
B结点:D3(A,2; B,1);
C结点:D4(A,2; C,1)
6)这个时候可以判断出,D2已经是旧版本(已经包含在D3/D4中),可以舍弃。
7)但是D3和D4是明显的版本冲突。于是,交给调用方自己去做版本冲突处理。就像源代码版本管理一样。
很明显,上述的Dynamo的配置用的是CAP里的A和P。
我非常推荐大家都去看看这篇论文:《Dynamo:Amazon’s Highly Available Key-Value Store》
vector clock:时钟向量,多版本数据修改
同上。
lease机制
租约(lease)在英文中的含义是“租期”、“承诺”,在分布式中一般描述如下:
Lease 是由授权者授予的在一段时间内的承诺。
授权者一旦发出 lease,则无论接受方是否收到,也无论后续接收方处于何种状态,只要 lease 不过期,授权者一定遵守承诺,按承诺的时间、内容执行。
接收方在有效期内可以使用颁发者的承诺,只要 lease 过期,接收方放弃授权,不再继续执行,要重新申请Lease。
可以通过版本号、时间周期,或者到某个固定时间点认为Lease证书失效
关于Lease最经典的解释来源于Lease的原始论文«Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency»lease
a lease is a contract that gives its holder specific rights over property for a limited period of time 即Lease是一种带期限的契约,在此期限内拥有Lease的节点有权利操作一些预设好的对象。从更深 层次上来看,Lease就是一把带有超时机制的分布式锁,如果没有Lease,分布式环境中的锁可能会因为锁拥有者的失败而导致死锁,有了lease死锁 会被控制在超时时间之内。
租约的示意如下图所示:
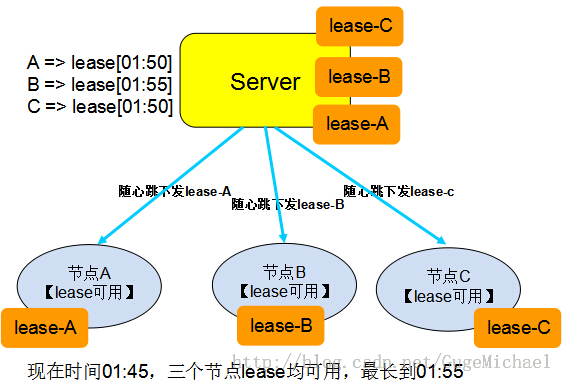
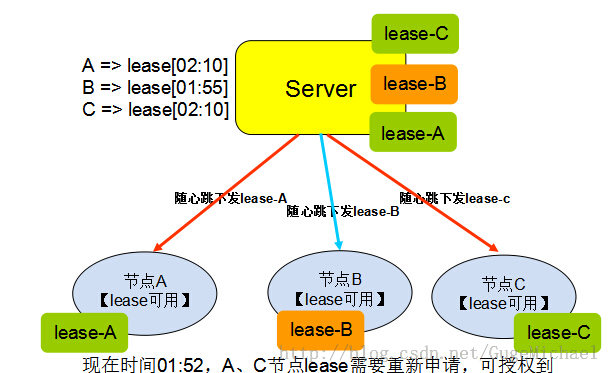
应用场景
那么租约机制在分布式中如何使用呢,我们罗列了以下三种使用场景供参考:
使用场景一:现有一个类似DNS服务的系统,数据的规律是改动很少,大量的读操作。客户端从服务端获取数据, 如果每次都去服务器查询,则量比较大。可以把数据缓存在本地,当数据有变动的时候重新拉取。现在服务器以lease的形式,把数据和lease一同推送给 客户端,在lease中存放承诺该数据的不变的时间,然后客户端就可以一直放心的使用这些数据(数据不发生变更)。如果有客户端修改了数据,则把这些数据 推送给服务器,服务器会阻塞一直到已发布的所有lease都已经超时用完,然后后面发送数据和lease时,更新现在的数据。这里可以优化为当服务器收到 数据更新需要等所有已经下发的lease超时的这段时间,直接发送让数据和lease失效的指令到客户端,减小服务器等待时间,如果并非所有的lease 都失效成功,则退化为前面的等待方案(概率小)。
但是在上述等lease失效的过程中,可能有新的请求元数据的请求到达,这时服务器又会继续颁发新的lease,使得lease一直不结束,形成“活锁”,即修改请求等待lease失效,而又源源不断颁发新lease而一直无法完成。此问题形成了“活锁”,解决活锁的办法:当有修改请求在等待着lease失效时,如果后续有读请求,则只返回请求数据而不颁发新lease,或者是只颁发目前最长的lease。
使用场景二:现有一个系统,有三个角色,选主模块Manager,唯一的Master,和其他salver节 点。slaver都向Maganer注册自己,并由manager选出唯一的Master节点并告知其他slaver节点。当网络出现异常时,例如 Master和Manager之间的链路断了,Maganer认为Master已经死掉了,则会再选出一个Master,然而原来的Master对其他网 络链路可能都还是正常的,原来的Master认为自己还是主节点,继续提供服务。此时系统中就出现了”双主“,俗称”脑裂“。解决这个问题的方式可以通过 Lease,来规定节点可以当Master的时间,如果没有可用的Lease,则自动退化为Slaver。如果出现”双主“,原Master会因为 Lease到期而放弃当Master,退化为Slaver,恢复了一个Master的情况。在某些场景下,双主是一定不能发生的,否则会导致分布式系统灾 难性的后果。怎么保证呢?我们可以将Master自动失效租约设置为t,而Manager记录Master租约失效为T,只要保证T>t,则可以保 证Manager选择新Master时,原Master已租约失效(下面 lease机制的特点第三点详细描述)。实际工程实现时要考虑失效Master资源释放的时间。
使用场景三:众所周知,一般会采用Proxy的方式加速对Web资源的访问速度,而Proxy也是HTTP协 议里面的一个标准组件,其基本原理就是对远程 Server上的资源进行Cache,Client在访问Proxy时如果所需的内容在Proxy Cache中不存在,则访问Server;否则直接把Cache中的内容返回给Client。通过Proxy既提高了用户体验,又降低了Server负 载。当然,一个Server会存在很多个Proxy。因此,保证Cache中的数据与Server一致成为Proxy Cache能正确工作的前提。之前,一般互联网数据不需要很强的一致性,但随着支付、股票等应用的发展,强一致性成为比不可少的要求,Lease就是解决 这类强一致性的折中方案。在不需要强一致性的环境中,Cache只要每隔一段时间与Server同步一下即可,但在需要强一致性的环境这种做法不能满足需求
lease机制的特点
lease颁发过程只需要网络可以单向通信,同一个lease可以被颁发者不断重复向接受方发送。即使颁发者偶尔发送lease失败,颁发者也可以简单的通过重发的办法解决。
机器宕机对lease机制的影响不大。如果颁发者宕机,则宕机的颁发者通常无法改变之前的承诺,不会影响lease的正确性。在颁发者机恢复后,如果颁发者恢复出了之前的lease 信息,颁发者可以继续遵守lease的承诺。如果颁发者无法恢复lease信息,则只需等待一个最大的lease超时时间就可以使得所有的lease都失效,从而不破坏lease机制。
lease机制依赖于有效期,这就要求颁发者和接收者的时钟是同步的。
如果颁发者的时钟比接收者的时钟慢,则当接收者认为lease已经过期的时候,颁发者依旧认为lease有效。接收者可以用在lease到期前申请新的lease的方式解决这个问题。
如果颁发者的时钟比接收者的时钟快,则当颁发者认为lease已经过期的时候,可能将lease颁发给其他节点,造成承诺失效,影响系统的正确性。对于这种时钟不同步,实践中的通常做法是将颁发者的有效期设置得比接收者的略大,只需大过时钟误差就可以避免对lease的有效性的影响。
实际工程实现时要考虑失效Master资源释放的时间
工程中,常选择的lease时长是10秒级别,这是一个经过验证的经验值,实践中可以作为参考并综合选择合适的时长。
实际应用
GFS中,Master通过lease机制决定哪个是主副本,lease在给各节点的心跳响应消息中携带。收不到心跳时,则等待lease过期,再颁发给其他节点。
Niobe中,主副本持有从副本颁发的lease,当lease过期时,主从分别会在中心节点上标记对方不可用,而中心节点是全局一致的,两者只有一个会成功。如果主成功了,从不可用,需要重新与主同步才能可用;如果从成功了,则自己成为新主。
在实际系统中,若用一个节点作为Manager发送lease也有很大的风险。实际系统总是使用多个节点互为副本,成为一个小的集群,该小集群具有高可用性,对外提供颁发lease的功能。chubby和zookeeper都是基于这样的设计。chubby一般有五台机器组成一个集群,可以部署成两地三机房。chubby内部的五台机器需要通过Paxos协议选取一个chubby master机器,其它机器是chubby slave,同一时刻只有一个chubby master。chubby相关的数据,比如锁信息,客户端的session信息等都需要同步到整个集群,采用半同步的做法,超过一半的机器成功就可以回复客户端。最后可以确保只有一个和原有的chubby master保持完全同步的chubby slave被选取为新的chubby master。
chubby中,paxos选主后,从节点会给主颁发lease,在期限内不选其他节点为主。另一方面,主节点给每个client节点发送lease,用于判断client死活。
zookeeper中,选主不用lease,而是直接发现没有主则选主。其余和chubby一致。
Gossip协议
Gossip是一种去中心化、容错并保证最终一致性的协议。Gossip是为了解决分布式遇到的问题而设计的。由于服务和数据分布在不同的机器上,节点之间的每次交互都伴随着网络延迟、网络故障等的性能问题。可见,分布式系统会比单机系统遇到更多的难题。
SWIM:最终一致性
前面提到Gossip解决的问题就是在分布式环境下信息高效分发的问题,这个问题的解决决定着系统的一致性程度。而Gossip协议是基于一种叫做SWIM的协议( S calable W eakly-consistent I nfection-style Process Group M embership Protocol)。SWIM是一种无中心的分布式协议,各个节点之间通过p2p实现信息交流同步各节点状态的方法。看名字也知道这是一种弱一致性的实现。
SWIM协议给每个进程组成员在本地维护一个成员表,记录该组存活的进程。该协议通过失效检测器(Failure Detector)和传播组件(Dissemination Component)来完成工作。
SWIM的失效检测器会检测失效的节点并将失效节点的更新信息发送给传播组件。SWIM的传播组件通过多播(multicast)的形式将失效信息传播给组内的其他成员。
协议的可扩展性体现在:新成员的加入和退出也以同样的方式进行多播通信。而在基本的时间周期内进行失效检测能够保证在限定的时间范围内完成完备性检查,即每个失效的进程都能最终被检测到(最终一致性)。通过多播方式传输协议消的问题在于效率不好也不可靠,通过在ping和ack消息中捎带成员更新信息能够降低丢包率和减少传输时延。这种传播方式被称为可传导的方式(Infection-style)。
Gossip:办公室八卦
我们的办公室八卦一般都是从一次交谈开始,只要一个人八卦一下,在有限的时间内办公室的的人都会知道该八卦的信息,这种方式也与病毒传播类似。因此 Gossip也有“病毒感染算法”、“谣言传播算法”之称。
Gossip来源于流行病学的研究(括号里就是Gossip协议):
在总数为n+1的人群中,被感染(infected)的人数初始化为1,并向周围传播。(一个节点状态发生变化,并向临近节点发送更新信息)
在每个周期内总有未被感染(uninfected)的人转变成被感染的人,方式委每个被感染的人随机感染b个人。(对于节点状态变化的信息随机发送给b个节点,图例中的b值为2)
经过足够的时间,所有的人都会被感染。(随着时间推移,信息能够传达到所有的节点,证明略)
可以看到,协议的核心内容就是节点通过将信息随机发送到b个节点来完成本次信息的传播,其涉及到周期性、配对、交互模式。Gossip的交互模式分为两种:Anti-entropy和Rumor mongering。
Anti-entropy:每个节点周期性地随机选择其他节点,然后通过相互交换自己的所有数据来消除两者之间的差异。
Rumor mongering:当一个节点有来新信息后,该节点变成活跃状态,并周期性地联系其他节点向其发送新信息。
每个节点维护一个自己的信息表 <key, (value, version)> ,即属性的值以及版本号;和一个记录其他节点的信息表 <node, <key, (value, version)» 。每个节点和系统中的某个节点相互配对成为peer。而节点的信息交换方式主要有3种。
Push:拥有状态新信息的节点随机选择联系节点并想起发送自己得到信息。
Pull:发起信息交换的节点随机选择联系节点并从对方获取信息。
Push-Pull混合模式:发起信息交换的节点向选择的节点发送信息。
其实节点中还有一些种子节点。种子节点的作用主要是在有新节点加入系统时体现。新节点加入系统中,先与种子节点八卦,新节点获得系统信息,种子节点知道系统中多了新节点。其他节点定期与种子节点八卦的时候就知道有新节点加入了。 各个节点互相八卦的过程中,如果发现某个节点的状态很长时间都没更新,就认为该节点已经宕机了。
Dynamo使用了Gossip协议来做会员和故障检测,Cassandra的集群内部用gossip的协议来做位置发现和状态信息共享。
Cassandra中Gossip实例
当一个节点启动的时候,它会从配置文件中读取配置信息,这样它就知道它属于哪个集群,它需要跟哪个节点通信以获取其他节点信息(这个通信节点称为种子节点)。这些信息是必须在每个节点的cassandra.yaml里配置的。
当一个节点启动时,获取配置文件(cassandra.yaml)中的seeds配置,从而知道集群中所有的seed节点。
Cassandra内部有一个Gossiper,每隔一秒运行一次(在Gossiper.Java的start方法中),按照以下规则向其他节点发送同步消息:
1、随机取一个当前活着的节点,并向它发送同步请求
2、向随机一台不可达的机器发送同步请求
3、如果第一步中所选择的节点不是seed,或者当前活着的节点数少于seed数,则向随意一台seed发送同步请求
如果没有这个判断,考虑这样一种场景,有4台机器,{A, B, C, D},并且配置了它们都是seed,如果它们同时启动,可能会出现这样的情形:
1、A节点起来,发现没有活着的节点,走到第三步,和任意一个种子同步,假设选择了B
2、B节点和A完成同步,则认为A活着,它将和A同步,由于A是种子,B将不再和其他种子同步
3、C节点起来,发现没有活着的节点,同样走到第三步,和任意一个种子同步,假设这次选择了D
4、C节点和D完成同步,认为D活着,则它将和D同步,由于D也是种子,所以C也不再和其他种子同步
这时就形成了两个孤岛,A和B互相同步,C和D之间互相同步,但是{A,B}和{C,D}之间将不再互相同步,它们也就不知道对方的存在了。
加入第二个判断后,A和B同步完,发现只有一个节点活着,但是seed有4个,这时会再和任意一个seed通信,从而打破这个孤岛。
Two/Three Phase Commit
2PC
二阶段提交(Two-phaseCommit)是指,在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。通常,二阶段提交也被称为是一种协议。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
所谓的两个阶段是指:第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。
第一阶段:准备阶段
事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交,到达一种“万事俱备,只欠东风”的状态。
可以进一步将准备阶段分为以下三个步骤:
1)协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响应。
2)参与者节点执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志。(注意:若成功这里其实每个参与者已经执行了事务操作)
3)各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返回一个”同意”消息;如果参与者节点的事务操作实际执行失败,则它返回一个”中止”消息。
第二阶段:提交阶段
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
接下来分两种情况分别讨论提交阶段的过程。
(1)当协调者节点从所有参与者节点获得的相应消息都为”同意”时:
success
1)协调者节点向所有参与者节点发出”正式提交(commit)”的请求。
2)参与者节点正式完成操作,并释放在整个事务期间内占用的资源。
3)参与者节点向协调者节点发送”完成”消息。
4)协调者节点受到所有参与者节点反馈的”完成”消息后,完成事务。
(2)如果任一参与者节点在第一阶段返回的响应消息为”中止”,或者 协调者节点在第一阶段的询问超时之前无法获取所有参与者节点的响应消息时:
fail
1)协调者节点向所有参与者节点发出”回滚操作(rollback)”的请求。
2)参与者节点利用之前写入的Undo信息执行回滚,并释放在整个事务期间内占用的资源。
3)参与者节点向协调者节点发送”回滚完成”消息。
4)协调者节点受到所有参与者节点反馈的”回滚完成”消息后,取消事务。
不管最后结果如何,第二阶段都会结束当前事务。
二阶段提交看起来确实能够提供原子性的操作,但是不幸的事,二阶段提交还是有几个缺点的:
1、同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2、单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作,参与者将处于“状态未知”阶段,参与者完全不知道要怎么办。比如:如果所有的参与者完成第一阶段的回复后(可能全部yes,可能全部no,可能部分yes部分no),如果协调者在这个时候挂掉了。那么所有的结点完全不知道怎么办(问别的参与者都不行)。为了一致性,要么死等协调者,要么重发第一阶段的yes/no命令。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
3、数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
4、二阶段无法解决的问题:协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
由于二阶段提交存在着诸如同步阻塞、单点问题、脑裂等缺陷,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。
3PC
三阶段提交(Three-phase commit),也叫三阶段提交协议(Three-phase commit protocol),是二阶段提交(2PC)的改进版本。
3
与两阶段提交不同的是,三阶段提交有两个改动点。
1、引入超时机制。同时在协调者和参与者中都引入超时机制。
2、在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
CanCommit阶段
3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
1.事务询问 协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
2.响应反馈 参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No
PreCommit阶段
协调者根据参与者的反应情况来决定是否可以记性事务的PreCommit操作。根据响应情况,有以下两种可能。
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
1.发送预提交请求 协调者向参与者发送PreCommit请求,并进入Prepared阶段。
2.事务预提交 参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
3.响应反馈 如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
1.发送中断请求 协调者向所有参与者发送abort请求。
2.中断事务 参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
doCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况。
执行提交
1.发送提交请求 协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。
2.事务提交 参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
3.响应反馈 事务提交完之后,向协调者发送Ack响应。
4.完成事务 协调者接收到所有参与者的ack响应之后,完成事务。
中断事务 协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
1.发送中断请求 协调者向所有参与者发送abort请求
2.事务回滚 参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
3.反馈结果 参与者完成事务回滚之后,向协调者发送ACK消息
4.中断事务 协调者接收到参与者反馈的ACK消息之后,执行事务的中断。
!!!在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。(其实这个应该是基于概率来决定的,当进入第三阶段时,说明参与者在第二阶段已经收到了PreCommit请求,那么协调者产生PreCommit请求的前提条件是他在第二阶段开始之前,收到所有参与者的CanCommit响应都是Yes。(一旦参与者收到了PreCommit,意味他知道大家其实都同意修改了)所以,一句话概括就是,当进入第三阶段时,由于网络超时等原因,虽然参与者没有收到commit或者abort响应,但是他有理由相信:成功提交的几率很大。 )
2PC与3PC的区别
相对于2PC,3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
了解了2PC和3PC之后,我们可以发现,无论是二阶段提交还是三阶段提交都无法彻底解决分布式的一致性问题。Google Chubby的作者Mike Burrows说过, there is only one consensus protocol, and that’s Paxos” – all other approaches are just broken versions of Paxos.意即世上只有一种一致性算法,那就是Paxos,所有其他一致性算法都是Paxos算法的不完整版。
Paxos算法
Wikipedia上的各种Paxos算法的描述非常详细,大家可以去围观一下。详细介绍也可看另一篇博客分布式一致性算法–Paxos
Paxos 算法解决的问题是在一个可能发生上述异常的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决议的一致性。常见的有Basic-Paxos算法和Multi-paxos算法两种
Basic-Paxos算法
简单说来,Paxos的目的是让整个集群的结点对某个值的变更达成一致。Paxos算法基本上来说是个民主选举的算法——大多数的决定会成个整个集群的统一决定。任何一个点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的结点同意(所以Paxos算法需要集群中的结点是单数)。
这个算法有两个阶段(假设这个有三个结点:A,B,C):
第一阶段:Prepare阶段
A把申请修改的请求Prepare Request发给所有的结点A,B,C。注意,Paxos算法会有一个Sequence Number(你可以认为是一个提案号,这个数不断递增,而且是唯一的,也就是说A和B不可能有相同的提案号),这个提案号会和修改请求一同发出,任何结点在“Prepare阶段”时都会拒绝其值小于当前提案号的请求。所以,结点A在向所有结点申请修改请求的时候,需要带一个提案号,越新的提案,这个提案号就越是是最大的。
如果接收结点收到的提案号n大于其它结点发过来的提案号,这个结点会回应Yes(本结点上最新的被批准提案号),并保证不接收其它<n的提案。这样一来,结点上在Prepare阶段里总是会对最新的提案做承诺。
优化:在上述 prepare 过程中,如果任何一个结点发现存在一个更高编号的提案,则需要通知 提案人,提醒其中断这次提案。
第二阶段:Accept阶段
如果提案者A收到了超过半数的结点返回的Yes,然后他就会向所有的结点发布Accept Request(同样,需要带上提案号n),如果没有超过半数的话,那就返回失败。
当结点们收到了Accept Request后,如果对于接收的结点来说,n是最大的了,那么,它就会修改这个值,如果发现自己有一个更大的提案号,那么,结点就会拒绝修改。
我们可以看以,这似乎就是一个“两段提交”的优化。其实,2PC/3PC都是分布式一致性算法的残次版本,Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。
我们还可以看到:对于同一个值的在不同结点的修改提案就算是在接收方被乱序收到也是没有问题的。
关于一些实例,你可以看一下Wikipedia中文中的“Paxos样例”一节,我在这里就不再多说了。对于Paxos算法中的一些异常示例,大家可以自己推导一下。你会发现基本上来说只要保证有半数以上的结点存活,就没有什么问题。
Multi-paxos算法
Paxos是对一个值达成一致,Multi-Paxos是连续多个paxos instance来对多个值达成一致,这里最核心的原因是multi-paxos协议中有一个Leader。Leader是系统中唯一的Proposal,在lease租约周期内所有提案都有相同的ProposalId,可以跳过prepare阶段,议案只有accept过程,一个ProposalId可以对应多个Value,所以称为Multi-Paxos。
Multi Paxos一边先运行一次完整的paxos算法选举出leader,有leader处理所有的读写请求,然后省略掉prepare过程.
ZAB协议
zookeeper中用到的分布式一致性协议,详细内容可以查看另一篇博客Zookeeper ZAB协议详解
MVCC:多版本并发控制
这个是很多RDMS存储引擎实现高并发修改的一个重要实现机制。具体可以参考:
多版本并发控制(MVCC)在分布式系统中的应用
MVCC (Oracle, Innodb, Postgres).pdf
Map-Reduce思想
- 分而治之
- 移动数据不如移动计算
如果计算节点和存储节点位于不同的物理机器则计算的数据需要通过网络传输,此种方式的开销很大。另一种思路是,将计算尽量调度到与存储节点在同一台物理机器上的计算节点上进行,这称之为本地化计算。本地化计算是计算调度的一种重要优化。
经典论文和分布式系统学习
Dynamo
HBase
LSM Tree
LSM(Log Structured Merge Trees)是B+ Tree一种改进
牺牲了部分读性能,用来大幅提高写性能
思路:拆分树
首先写WAL,然后记录数据到入到内存中,构建一颗有序子树(memstore)
随着子树越来越大,内存的子树会flush到磁盘上(storefile)
读取数据:必须遍历所有的有序子树(不知数据在哪棵子树)
Compact:后台线程对磁盘中的子树进行归并,变成大树(子树多了读得慢)
事实上,lucene的索引机制也类似HBase的LSM树。也是写的时候分别写在单独的segment,后台进行segement合并。
