bipartite_graph_match
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
极大匹配(Maximal Matching)是指在当前已完成的匹配下,无法再通过增加未完成匹配的边的方式来增加匹配的边数。最大匹配(maximum matching)是所有极大匹配当中边数最大的一个匹配。选择这样的边数最大的子集称为图的最大匹配问题。
如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
求二分图匹配可以用最大流(Maximal Flow)或者匈牙利算法(Hungarian Algorithm)
注意匈牙利算法,除了二分图多重匹配外在二分图匹配中都可以使用。
注:二分图匹配中还有一个hk算法,复杂度为o(sqrt(n)*e)由于复杂度降低较低,代码量飙升而且绝大多数情况下没人会闲的卡个sqrt的复杂度。。首先我们讲解一下匈牙利算法的过程:
匈牙利算法:
匈牙利算法几乎是二分图匹配的核心算法,除了二分图多重匹配外均可使用
匈牙利算法实际上就是一种网络流的思想,其核心就是寻找增广路
匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理中充分性证明的思想,它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
#include
#include
#include
#include
#include
#include
#include
using namespace std;
const int N=505;
int line[N][N];
int girl[N],used[N];
int k,m,n;
bool found(int x)
{
for(int i=1; i<=n; i++)
{
if(line[x][i]&&!used[i])
{
used[i]=1;
if(girl[i]==0||found(girl[i]))
{
girl[i]=x;
return 1;
}
}
}
return 0;
}
int main()
{
int x,y;
while(scanf("%d",&k)&&k)
{
scanf("%d %d",&m,&n);
memset(line,0,sizeof(line));
memset(girl,0,sizeof(girl));
for(int i=0; i<k; i++)
{
scanf("%d %d",&x,&y);
line[x][y]=1;
}
int sum=0;
for(int i=1; i<=m; i++)
{
memset(used,0,sizeof(used));
if(found(i)) sum++;
}
printf("%d\n",sum);
}
return 0;
}
二分图最优匹配的km算法了
km算法理解起来着实很困难,我其实只能照着代码讲,不然根本讲不明白。不过听一个学长说要理解思想而不是代码。。。那就试着空讲一下吧。
一般对KM算法的描述,基本上可以概括成以下几个步骤:
(1) 初始化可行标杆
(2) 用匈牙利算法寻找完备匹配
(3) 若未找到完备匹配则修改可行标杆
(4) 重复(2)(3)直到找到相等子图的完备匹配
关于该算法的流程及实施,网上有很多介绍,基本上都是围绕可行标杆如何修改而进行的讨论,至于原理并没有给出深入的探讨。
KM算法是用于寻找带权二分图最佳匹配的算法。
二分图是这样一种图:所有顶点可以分成两个集:X和Y,其中X和Y中的任意两个在同一个集中的点都不相连,而来自X集的顶点与来自Y集的顶点有连线。当这些连线被赋于一定的权重时,这样的二分图便是带权二分图。
二分图匹配是指求出一组边,其中的顶点分别在两个集合中,且任意两条边都没有相同的顶点,这组边叫做二分图的匹配,而所能得到的最大的边的个数,叫做二分图的最大匹配。
我们也可以换个角度看二分图的最大匹配,即二分图的每条边的默认权重为1,我们求到的二分图的最大匹配的权重最大。对于带权二分图,其边有大于0的权重,找到一组匹配,使其权重最大,即为带权二分图的最佳匹配。
匈牙利算法一般用于寻找二分图的最大匹配。算法根据一定的规则选择二分图的边加入匹配子图中,其基本模式为:
初始化匹配子图为空
While 找得到增广路径
Do 把增广路径添加到匹配子图中
增广路径有如下特性:
- 有奇数条边
- 起点在二分图的X边,终点在二分图的Y边
- 路径上的点一定是一个在X边,一个在Y边,交错出现。
- 整条路径上没有重复的点
- 起点和终点都是目前还没有配对的点,其他的点都已经出现在匹配子图中
- 路径上的所有第奇数条边都是目前还没有进入目前的匹配子图的边,而所有第偶数条边都已经进入目前的匹配子图。奇数边比偶数边多一条边
- 于是当我们把所有第奇数条边都加到匹配子图并把条偶数条边都删除,匹配数增加了1.
蓝色的是当前的匹配子图,目前只有边x0y0,然后通过x1找到了增广路径:x1y0->y0x0->x0y2
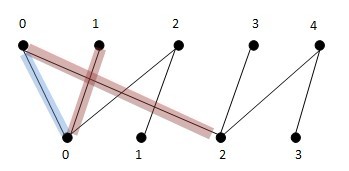
其中第奇数第边x1y0和x0y2不在当前的匹配子图中,而第偶数条边x0y0在匹配子图中,通过添加x1y0和x0y2到匹配子图并删除x0y0,使得匹配数由1增加到了2。每找到一条增广路径,通过添加删除边,我们总是能使匹配数加1.
增广路径有两种寻径方法,一个是深搜,一个是宽搜。例如从x2出发寻找增广路径,如果是深搜,x2找到y0匹配,但发现y0已经被x1匹配了,于是就深入到x1,去为x1找新的匹配节点,结果发现x1没有其他的匹配节点,于是匹配失败,x2接着找y1,发现y1可以匹配,于是就找到了新的增广路径。如果是宽搜,x1找到y0节点的时候,由于不能马上得到一个合法的匹配,于是将它做为候选项放入队列中,并接着找y1,由于y1已经匹配,于是匹配成功返回了。相对来说,深搜要容易理解些,其栈可以由递归过程来维护,而宽搜则需要自己维护一个队列,并对一路过来的路线自己做标记,实现起来比较麻烦。
| 对于带权重的二分图来说,我们可以把它看成一个所有X集合的顶点到所有Y集合的顶点均有边的二分图(把原来没有的边添加入二分图,权重为0即可),也就是说它必定存在完备匹配(即其匹配数为min( | X | , | Y | ))。为了使权重达到最大,我们实际上是通过贪心算法来选边,形成一个新的二分图(我们下面叫它二分子图好了),并在该二分图的基础上寻找最大匹配,当该最大匹配为完备匹配时,我们可以确定该匹配为最佳匹配。(在这里我们如此定义最大匹配:匹配边数最多的匹配和最佳匹配:匹配边的权重和最大的匹配。) |
贪心算法总是将最优的边优先加入二分子图,该最优的边将对当前的匹配子图带来最大的贡献,贡献的衡量是通过标杆来实现的。下面我们将通过一个实例来解释这个过程。
有带权二分图:
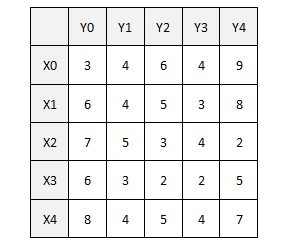
算法把权重转换成标杆,X集跟Y集的每个顶点各有一个标杆值,初始情况下权重全部放在X集上。由于每个顶点都将至少会有一个匹配点,贪心算法必然优先选择该顶点上权重最大的边(最理想的情况下,这些边正好没有交点,于是我们自然得到了最佳匹配)。最初的二分子图为:(可以看到初始化时X标杆为该顶点上的最大权重,而Y标杆为0)
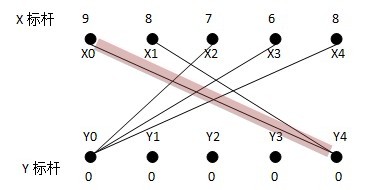
从X0找增广路径,找到X0Y4;从X1找不到增广路径,也就是说,必须往二分子图里边添加新的边,使得X1能找到它的匹配,同时使权重总和添加最大。由于X1通往Y4而Y4已经被X0匹配,所以有两种可能,一个是为X0找一个新的匹配点并把Y4让给X1,或者是为X1找一个新的匹配点,现在我们将要看到标杆的作用了。根据传统的算法描述,能够进入二分子图的边的条件为L(x)+L(y)>=weight(xy)。当找不到增广路径时,对于搜索过的路径上的XY点,设该路径上的X顶点集为S,Y顶点集为T,对所有在S中的点xi及不在T中的点yj,计算d=min{(L(xi)+L(yj)-weight(xiyj))},从S集中的X标杆中减去d,并将其加入到T集中的Y的标杆中,由于S集中的X标杆减少了,而不在T中的Y标杆不变,相当于这两个集合中的L(x)+L(y)变小了,也就是,有新的边可以加入二分子图了。从贪心选边的角度看,我们可以为X0选择新的边而抛弃原先的二分子图中的匹配边,也可以为X1选择新的边而抛弃原先的二分子图中的匹配边,因为我们不能同时选择X0Y4和X1Y4,因为这是一个不合法匹配,这个时候,d=min{(L(xi)+L(yj)-weight(xiyj))}的意义就在于,我们选择一条新的边,这条边将被加入匹配子图中使得匹配合法,选择这条边形成的匹配子图,将比原先的匹配子图加上这条非法边组成的非法匹配子图的权重和(如果它是合法的,它将是最大的)小最少,即权重最大了。好绕口的。用数学的方式表达,设原先的不合法匹配(它的权重最大,因为我们总是从权重最大的边找起的)的权重为W,新的合法匹配为W’,d为min{W-W’i}。在这个例子中,S={X0, X1},Y={Y4},求出最小值d=L(X1)+L(Y0)-weight(X1Y0)=2,得到新的二分子图:

重新为X1寻找增广路径,找到X1Y0,可以看到新的匹配子图的权重为9+6=15,比原先的不合法的匹配的权重9+8=17正好少d=2。
接下来从X2出发找不到增广路径,其走过的路径如蓝色的路线所示。形成的非法匹配子图:X0Y4,X1Y0及X2Y0的权重和为22。在这条路径上,只要为S={X0,X1,X2}中的任意一个顶点找到新的匹配,就可以解决这个问题,于是又开始求d。
d=L(X0)+L(Y2)-weight(X0Y2)=L(X2)+L(Y1)-weight(X2Y1)=1.
新的二分子图为:

重新为X2寻找增广路径,如果我们使用的是深搜,会得到路径:X2Y0->Y0X1->X1Y4->Y4X0->X0Y2,即奇数条边而删除偶数条边,新的匹配子图中由这几个顶点得到的新的权重为21;如果使用的是宽搜,会得到路径X2Y1,另上原先的两条匹配边,权重为21。假设我们使用的是宽搜,得到的新的匹配子图为:

接下来依次类推,直到为X4找到一个匹配点。
KM算法的最大特点在于利用标杆和权重来生成一个二分子图,在该二分子图上面找最大匹配,而且,当些仅当找到完备匹配,才能得到最佳匹配。标杆和权重的作用在于限制新边的加入,使得加入的新边总是能为子图添加匹配数,同时又令权重和得到最大的提高。
二分图多重匹配:
设源点汇点直接网络流即可,在此不细讲,会在网络流部分进行讲解
